

Sejak model besar menjadi popular dalam industri, keinginan orang ramai untuk memampatkan model besar tidak pernah berkurangan. Ini kerana, walaupun model besar menunjukkan keupayaan yang sangat baik dalam banyak aspek, kos penggunaan yang tinggi sangat meningkatkan ambang penggunaannya. Kos ini terutamanya datang daripada pendudukan ruang dan jumlah pengiraan. "Kuantisasi model" menjimatkan ruang dengan menukar parameter model besar kepada perwakilan lebar bit rendah. Pada masa ini, kaedah arus perdana boleh memampatkan model sedia ada kepada 4 bit dengan hampir tiada kehilangan prestasi model. Walau bagaimanapun, pengkuantitian di bawah 3 bit adalah seperti dinding yang tidak dapat diatasi yang menakutkan penyelidik. . halangan Harapan telah menarik perhatian ramai dalam kalangan akademik di dalam dan luar negara. Kertas kerja ini juga disenaraikan sebagai kertas hangat di huggingface seminggu yang lalu dan disyorkan oleh pengesyor kertas terkenal AK. Pasukan penyelidik terus melepasi tahap kuantifikasi 2-bit dan dengan berani mencuba kuantifikasi 1-bit, yang merupakan kali pertama dalam penyelidikan kuantifikasi model
. . dipanggil "OneBit" menerangkan intipati kerja ini dengan sangat tepat:Mampatkan model besar yang telah dilatih kepada 1bit sebenar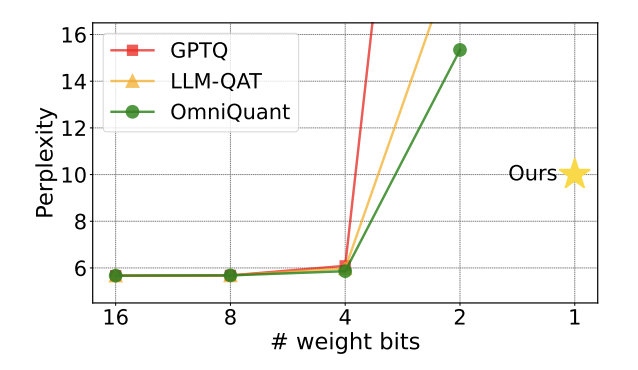 . Kertas kerja ini mencadangkan kaedah baharu perwakilan 1-bit parameter model, serta kaedah permulaan untuk parameter model terkuantum, dan memindahkan keupayaan model pra-latihan berketepatan tinggi kepada model terkuantum 1-bit melalui latihan sedar pengkuantitian ( QAT). Eksperimen menunjukkan bahawa kaedah ini boleh memampatkan parameter model dengan hebat sambil memastikan sekurang-kurangnya 83% prestasi model LLaMA.
. Kertas kerja ini mencadangkan kaedah baharu perwakilan 1-bit parameter model, serta kaedah permulaan untuk parameter model terkuantum, dan memindahkan keupayaan model pra-latihan berketepatan tinggi kepada model terkuantum 1-bit melalui latihan sedar pengkuantitian ( QAT). Eksperimen menunjukkan bahawa kaedah ini boleh memampatkan parameter model dengan hebat sambil memastikan sekurang-kurangnya 83% prestasi model LLaMA.
Pengarang menegaskan bahawa apabila parameter model dimampatkan kepada 1 bit, "pendaraban elemen" dalam pendaraban matriks tidak akan wujud lagi, dan akan digantikan dengan operasi "tugasan bit" yang lebih pantas, yang akan meningkatkan pengkomputeran. kecekapan. Kepentingan penyelidikan ini ialah ia bukan sahaja melepasi jurang kuantifikasi 2-bit, tetapi juga memungkinkan untuk menggunakan model besar pada PC dan telefon pintar.
Keterbatasan kerja sedia ada
Kuantisasi model terutamanya mencapai pemampatan ruang dengan menukar lapisan nn.Linear model (kecuali lapisan Embedding dan lapisan Lm_head) kepada perwakilan ketepatan rendah. Asas kerja sebelumnya [1,2] adalah menggunakan kaedah Pusingan-Ke-Terdekat (RTN) untuk lebih kurang memetakan nombor titik terapung berketepatan tinggi kepada grid integer berdekatan. Ini boleh dinyatakan sebagai 
.
Walau bagaimanapun, kaedah berdasarkan RTN mempunyai masalah kehilangan ketepatan yang serius pada lebar bit yang sangat rendah (di bawah 3 bit), dan kehilangan keupayaan model selepas pengkuantitian adalah sangat serius. Khususnya, apabila parameter terkuantisasi dinyatakan dalam 1 bit, pekali skala s dan titik sifar z dalam RTN akan kehilangan makna praktikalnya. Ini menyebabkan kaedah pengkuantitian berasaskan RTN hampir tidak berkesan pada pengkuantitian 1-bit, menjadikannya sukar untuk mengekalkan prestasi model asal dengan berkesan.
Selain itu, kajian terdahulu juga telah meneroka struktur yang boleh diguna pakai oleh model 1bit. Kerja dari beberapa bulan lalu di BitNet [3] melaksanakan perwakilan 1bit dengan menghantar parameter model melalui fungsi Tanda (・) dan menukarnya kepada + 1/-1. Walau bagaimanapun, kaedah ini mengalami kehilangan prestasi yang serius dan proses latihan yang tidak stabil, yang mengehadkan penggunaan praktikalnya. Rangka Kerja OneBit
Rangka kerja kaedah OneBit merangkumi struktur lapisan 1bit baharu, kaedah pemulaan parameter berasaskan SVID dan pemindahan pengetahuan berdasarkan penyulingan pengetahuan sedar pengkuantitian.
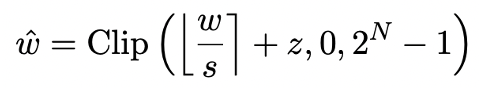
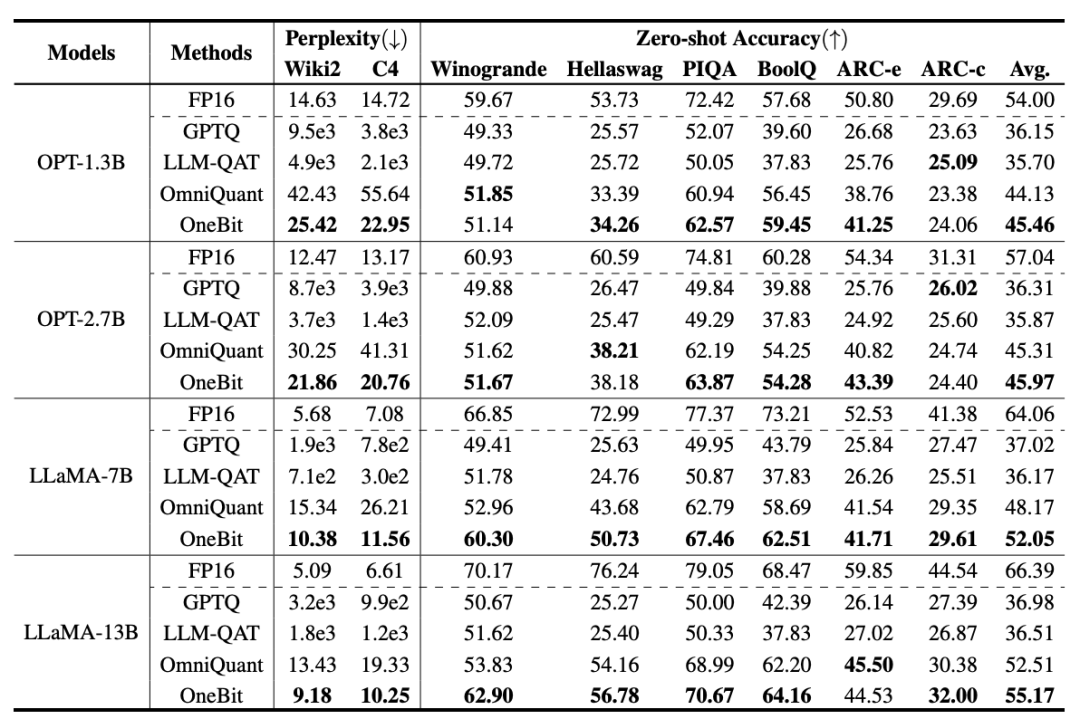
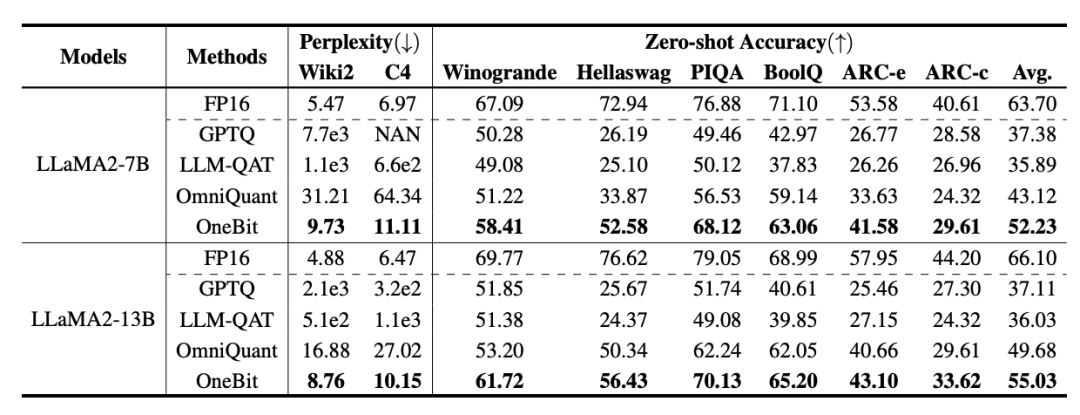
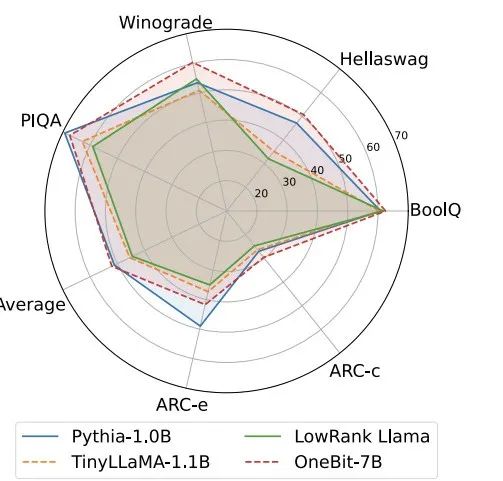
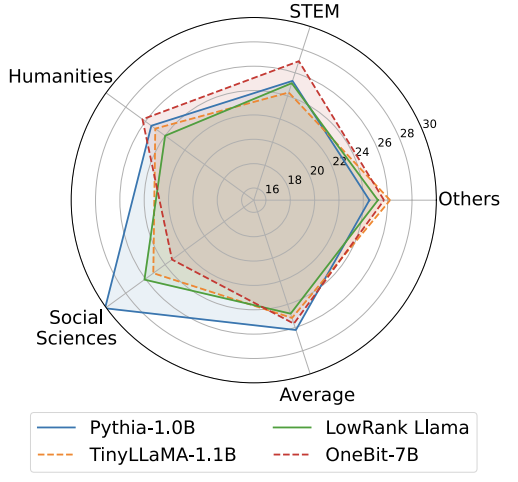
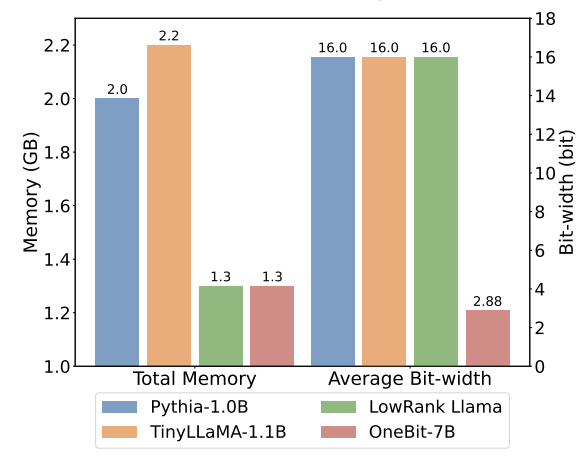
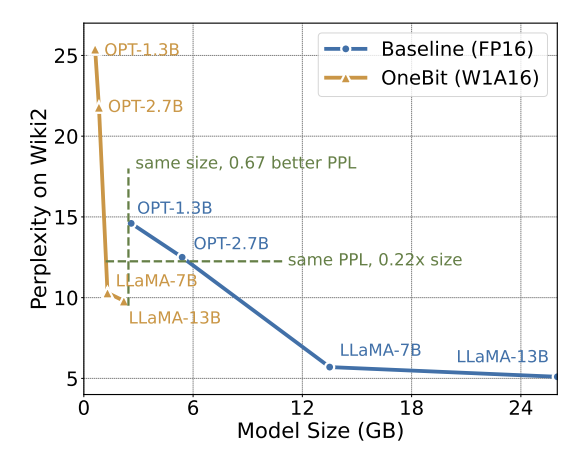
Oleh itu, penulis memperkenalkan dua vektor nilai dalam format FP16 untuk mengimbangi kehilangan ketepatan akibat pengkuantitian. Reka bentuk ini bukan sahaja mengekalkan kedudukan tinggi matriks berat asal, tetapi juga menyediakan ketepatan titik terapung yang diperlukan melalui vektor nilai, yang memudahkan latihan model dan pemindahan pengetahuan. Perbandingan antara struktur lapisan linear 1bit dan struktur lapisan linear berketepatan tinggi FP16 adalah seperti berikut: Rajah 3: Perbandingan antara lapisan linear FP16 dan lapisan linear OneBit (a) sebelah kiri ialah Struktur model ketepatan FP16, (b) di sebelah kanan ialah lapisan linear rangka kerja OneBit. Ia boleh dilihat bahawa dalam rangka kerja OneBit, hanya vektor nilai g dan h kekal dalam format FP16, manakala matriks berat sepenuhnya terdiri daripada ±1. Struktur sedemikian mengambil kira ketepatan dan kedudukan, dan sangat bermakna untuk memastikan proses pembelajaran yang stabil dan berkualiti tinggi. Berapa banyakkah OneBit memampatkan model? Penulis memberikan pengiraan dalam kertas. Dengan mengandaikan lapisan linear 4096*4096 dimampatkan, OneBit memerlukan matriks 1-bit 4096*4096 dan dua vektor nilai 16-bit 4096*1. Jumlah bilangan bit ialah 16,908,288, dan jumlah parameter ialah 16,785,408 Secara purata, setiap parameter hanya menduduki kira-kira 1.0073 bit. Pemampatan jenis ini tidak pernah berlaku sebelum ini, dan ia boleh dikatakan sebagai model besar yang benar-benar 1-bit. . kaedah pemfaktoran dipanggil "pemfaktoran matriks bebas tanda nilai (SVID)". Kaedah penguraian matriks ini memisahkan simbol dan nilai mutlak, dan melaksanakan penghampiran kedudukan-1 pada nilai mutlak Kaedahnya untuk menganggarkan parameter matriks asal boleh dinyatakan sebagai: Penghampiran pangkat-1 di sini boleh digunakan oleh. pemfaktoran Matriks biasa dilaksanakan, seperti penguraian nilai tunggal (SVD) dan pemfaktoran matriks bukan negatif (NMF). Kemudian, pengarang secara matematik menunjukkan bahawa kaedah SVID ini boleh memadankan rangka kerja model 1-bit dengan menukar susunan operasi, dengan itu mencapai pemulaan parameter. Selain itu, kertas itu juga membuktikan bahawa matriks simbolik memainkan peranan dalam menghampiri matriks asal semasa proses penguraian. 3. Pindahkan keupayaan model asal melalui penyulingan pengetahuan Pengarang menunjukkan bahawa cara yang berkesan untuk menyelesaikan pengkuantitian lebar bit ultra-rendah bagi model besar mungkin latihan QAT yang menyedari pengkuantitian. Di bawah struktur model OneBit, penyulingan pengetahuan digunakan untuk belajar daripada model yang tidak terkuantisasi untuk merealisasikan penghijrahan keupayaan kepada model terkuantisasi. Secara khusus, model pelajar terutamanya dipandu oleh logit dan keadaan tersembunyi model guru. Semasa latihan, nilai vektor nilai dan matriks akan dikemas kini. Selepas kuantifikasi model selesai, parameter selepas Tanda (・) disimpan terus dan digunakan secara langsung semasa inferens dan penggunaan. . . Di samping itu, memandangkan pada masa ini tiada penyelidikan tentang pengkuantitian berat 1-bit, pengarang hanya menggunakan pengkuantitian berat 1-bit untuk rangka kerja OneBitnya, dan menggunakan tetapan pengkuantitian 2-bit untuk kaedah lain, yang merupakan "kemenangan lemah yang tipikal ke atas kuat". Dari segi pemilihan model, penulis turut memilih model yang berbeza saiz dari 1.3B hingga 13B, OPT dan LLaMA-1/2 dalam siri berbeza untuk membuktikan keberkesanan OneBit. Dari segi penunjuk penilaian, penulis mengikuti dua dimensi penilaian utama kuantifikasi model sebelumnya: kebingungan set pengesahan dan ketepatan pukulan sifar penaakulan akal. Jadual 1: Perbandingan kesan OneBit dan kaedah garis dasar (model OPT dan model LLaMA-1) Jadual 2: Perbandingan dan kesan kaedah OneBit asas 2 model) Jadual 1 dan Jadual 2 menunjukkan kelebihan OneBit berbanding kaedah lain dalam kuantisasi 1-bit. Dari segi mengukur kebingungan model pada set pengesahan, OneBit paling hampir dengan model FP16. Dari segi ketepatan tangkapan sifar, model terkuantisasi OneBit mencapai hampir prestasi terbaik kecuali set data individu model OPT. Kaedah pengkuantitian 2-bit yang selebihnya menunjukkan kerugian yang lebih besar pada kedua-dua metrik penilaian. Perlu diingat bahawa OneBit cenderung untuk berprestasi lebih baik apabila model lebih besar. Iaitu, apabila saiz model bertambah, model ketepatan FP16 mempunyai sedikit kesan ke atas pengurangan kebingungan, tetapi OneBit menunjukkan lebih banyak pengurangan kebingungan. Di samping itu, pengarang juga menunjukkan bahawa latihan sedar kuantisasi mungkin diperlukan untuk kuantisasi lebar bit ultra-rendah. Rajah 4: Perbandingan tugas penaakulan akal Rajah 5: Perbandingan pengetahuan dunia dan lebar bit purata beberapa model Rajah 4 - Rajah 6 juga membandingkan pendudukan ruang dan kehilangan prestasi beberapa jenis model kecil, yang diperoleh melalui saluran berbeza: termasuk dua model terlatih sepenuhnya Pythia-1.0B dan TinyLLaMA-1.1B, dan melalui peringkat rendah LowRank Llama dan OneBit-7B diperoleh melalui penguraian. Ia boleh dilihat bahawa walaupun OneBit-7B mempunyai lebar bit purata terkecil dan menduduki ruang terkecil, ia masih lebih baik daripada model lain dari segi keupayaan penaakulan akal. Penulis juga menegaskan bahawa model menghadapi lupa pengetahuan yang serius dalam bidang sains sosial. Secara keseluruhannya, OneBit-7B menunjukkan nilai praktikalnya. Seperti yang ditunjukkan dalam Rajah 7, model LLaMA-7B terkuantisasi OneBit menunjukkan keupayaan penjanaan teks yang lancar selepas arahan penalaan halus. Rajah 7: Keupayaan model LLaMA-7B dikira mengikut rangka kerja OneBit
Jadual 3: OneBit dalam Mampatan berbeza nisbah model LLaMA Selain itu, penulis juga menunjukkan kelebihan pengiraan model pengkuantitian 1-bit. Oleh kerana parameter adalah binari semata-mata, ia boleh diwakili dalam 1 bit dengan 0/1, yang sudah pasti menjimatkan banyak ruang. Pendaraban elemen pendaraban matriks dalam model berketepatan tinggi boleh diubah menjadi operasi bit yang cekap produk Matriks boleh diselesaikan dengan hanya tugasan dan penambahan bit, yang mempunyai prospek aplikasi yang hebat. 2. Kekukuhan Rangkaian binari secara amnya menghadapi masalah latihan yang tidak stabil dan penumpuan yang sukar. Terima kasih kepada vektor nilai ketepatan tinggi yang diperkenalkan oleh pengarang, kedua-dua pengiraan hadapan dan pengiraan belakang latihan model adalah sangat stabil. BitNet mencadangkan struktur model 1-bit lebih awal, tetapi struktur ini menghadapi kesukaran untuk memindahkan keupayaan daripada model ketepatan tinggi yang terlatih sepenuhnya. Seperti yang ditunjukkan dalam Rajah 9, penulis mencuba pelbagai kadar pembelajaran yang berbeza untuk menguji keupayaan pembelajaran pemindahan BitNet, dan mendapati penumpuannya sukar di bawah bimbingan seorang guru, yang juga membuktikan nilai latihan OneBit yang stabil. . Sebagai contoh, cari kaedah permulaan parameter yang lebih baik, kos latihan yang kurang, atau pertimbangkan selanjutnya pengkuantitian nilai pengaktifan. 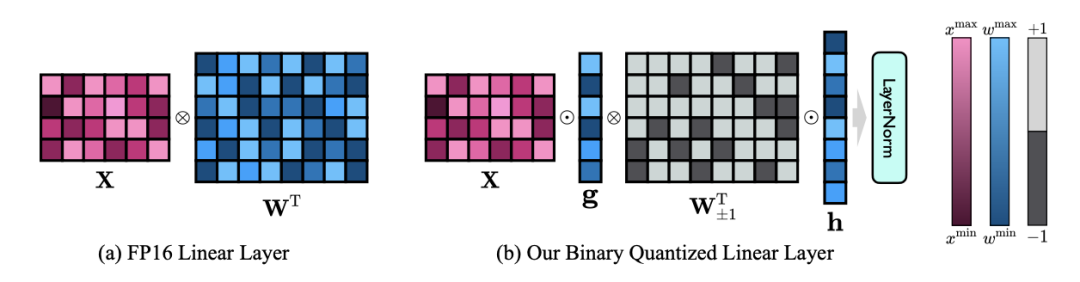
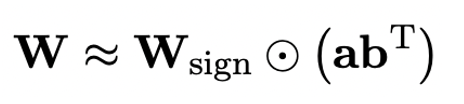

Perbincangan dan analisis
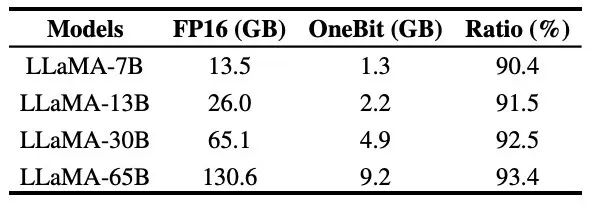
 Jadual 3 menunjukkan nisbah mampatan OneBit untuk model LLaMA dengan saiz yang berbeza. Ia boleh dilihat bahawa nisbah mampatan OneBit untuk model melebihi 90%, yang tidak pernah berlaku sebelum ini. Perlu diingat bahawa apabila model meningkat, nisbah mampatan OneBit menjadi lebih tinggi Ini kerana bahagian parameter dalam lapisan Embedding yang tidak mengambil bahagian dalam kuantisasi menjadi lebih kecil dan lebih kecil. Seperti yang dinyatakan sebelum ini, lebih besar model, lebih besar keuntungan prestasi yang dibawa oleh OneBit, yang menunjukkan kelebihan OneBit pada model yang lebih besar. . . Penulis percaya bahawa memampatkan saiz model adalah penting, terutamanya apabila menggunakan model pada peranti mudah alih.
Jadual 3 menunjukkan nisbah mampatan OneBit untuk model LLaMA dengan saiz yang berbeza. Ia boleh dilihat bahawa nisbah mampatan OneBit untuk model melebihi 90%, yang tidak pernah berlaku sebelum ini. Perlu diingat bahawa apabila model meningkat, nisbah mampatan OneBit menjadi lebih tinggi Ini kerana bahagian parameter dalam lapisan Embedding yang tidak mengambil bahagian dalam kuantisasi menjadi lebih kecil dan lebih kecil. Seperti yang dinyatakan sebelum ini, lebih besar model, lebih besar keuntungan prestasi yang dibawa oleh OneBit, yang menunjukkan kelebihan OneBit pada model yang lebih besar. . . Penulis percaya bahawa memampatkan saiz model adalah penting, terutamanya apabila menggunakan model pada peranti mudah alih. 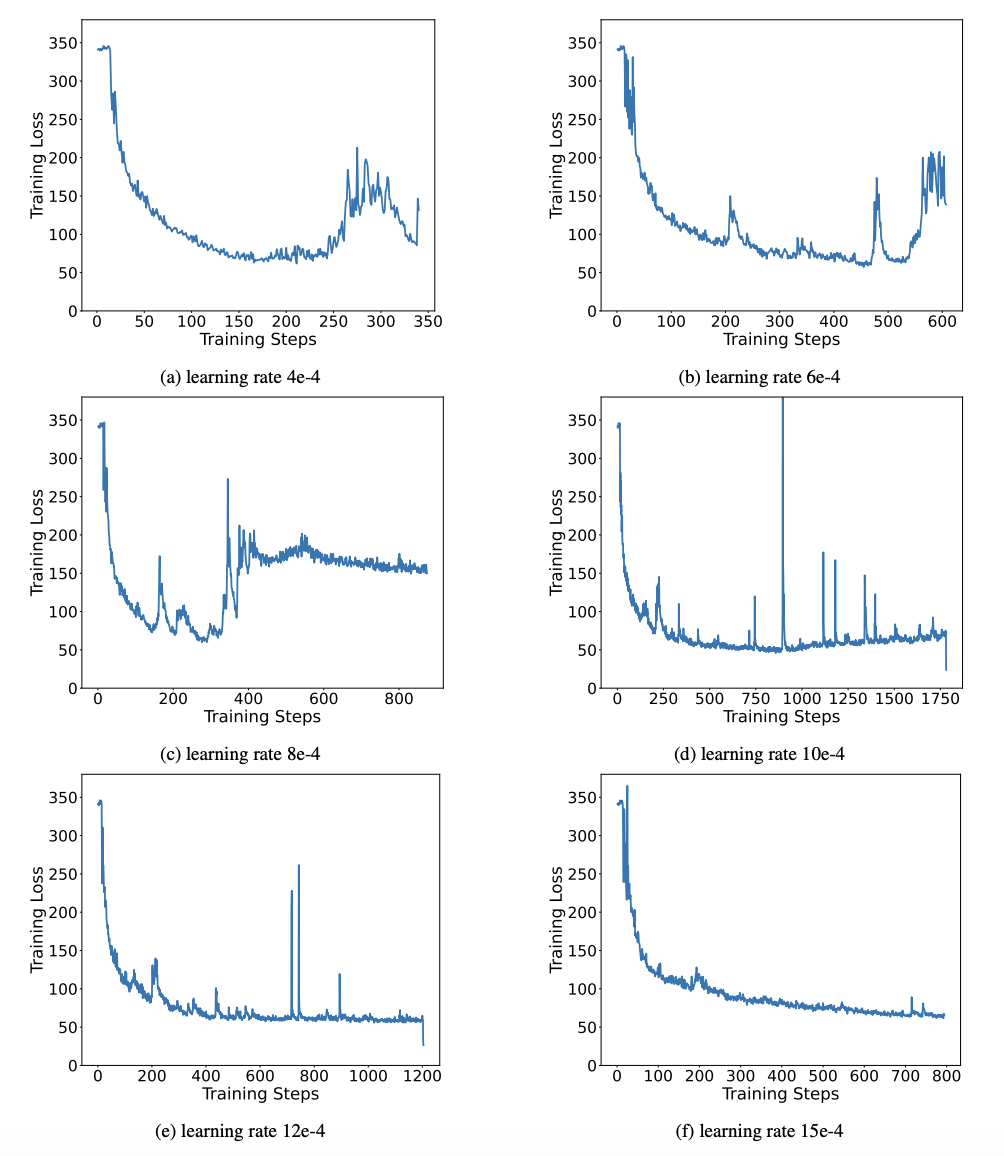 Sila lihat kertas asal untuk butiran lanjut teknikal.
Sila lihat kertas asal untuk butiran lanjut teknikal.
Atas ialah kandungan terperinci Universiti Tsinghua dan Institut Teknologi Harbin telah memampatkan model besar kepada 1 bit, dan keinginan untuk menjalankan model besar pada telefon mudah alih akan menjadi kenyataan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



