
 Peranti teknologi
AI
UniVision yang tiada tandingan: Pengesanan BEV dan rangka kerja bersatu Occ bersama, dwi SOTA!
Peranti teknologi
AI
UniVision yang tiada tandingan: Pengesanan BEV dan rangka kerja bersatu Occ bersama, dwi SOTA!
UniVision yang tiada tandingan: Pengesanan BEV dan rangka kerja bersatu Occ bersama, dwi SOTA!

Ditulis di hadapan & pemahaman peribadi
Dalam beberapa tahun kebelakangan ini, persepsi 3D berpusatkan penglihatan dalam teknologi pemanduan autonomi telah mencapai kemajuan pesat. Walaupun pelbagai model persepsi 3D mempunyai banyak persamaan struktur dan konsep, masih terdapat beberapa perbezaan dalam perwakilan ciri, format data dan matlamat, yang membawa cabaran kepada reka bentuk rangka kerja persepsi 3D yang bersatu dan cekap. Oleh itu, penyelidik bekerja keras untuk mencari penyelesaian untuk mengintegrasikan perbezaan antara model yang berbeza dengan lebih baik untuk membina sistem persepsi 3D yang lebih lengkap dan cekap. Usaha seperti ini dijangka membawa teknologi yang lebih andal dan canggih kepada bidang pemanduan autonomi, menjadikannya lebih berkuasa dalam persekitaran yang kompleks Terutama untuk tugas pengesanan dan tugasan penghunian di bawah BEV, masih sukar untuk melakukan latihan bersama , ketidakstabilan kesan yang tidak terkawal menyebabkan sakit kepala untuk banyak aplikasi. UniVision ialah rangka kerja yang mudah dan cekap yang menyatukan dua tugas utama dalam persepsi 3D bertumpu penglihatan, iaitu ramalan penghunian dan pengesanan objek. Titik teras ialah modul transformasi paparan eksplisit-implisit untuk transformasi ciri 2D-3D pelengkap UniVision mencadangkan modul pengekstrakan dan gabungan ciri tempatan dan global untuk pengekstrakan, peningkatan dan Interaksi ciri voxel dan BEV yang cekap dan adaptif.
Dalam bahagian peningkatan data, UniVision turut mencadangkan strategi peningkatan data pengesanan penghunian bersama dan strategi pelarasan berat badan yang progresif untuk meningkatkan kecekapan dan kestabilan latihan rangka kerja pelbagai tugas. Eksperimen meluas dijalankan pada tugas persepsi yang berbeza pada empat penanda aras awam, termasuk segmentasi lidar bebas adegan, pengesanan bebas adegan, OpenOccupancy dan Occ3D. UniVision mencapai SOTA dengan keuntungan +1.5 mIoU, +1.8 NDS, +1.5 mIoU dan +1.8 mIoU pada setiap penanda aras, masing-masing. Rangka kerja UniVision boleh berfungsi sebagai garis asas berprestasi tinggi untuk tugas persepsi 3D berpusatkan penglihatan bersatu.
Jika anda tidak biasa dengan tugas BEV dan Pendudukan, anda dialu-alukan untuk mengkaji lebih lanjut
tutorial persepsi BEVdan Tutorial rangkaian penghunian kami untuk mengetahui lebih lanjut butiran teknikal!
Keadaan semasa bidang persepsi 3DPersepsi 3D ialah tugas utama sistem pemanduan autonomi Tujuannya adalah untuk menggunakan data yang diperoleh daripada satu siri penderia (seperti lidar, radar dan kamera) untuk memahami secara menyeluruh. adegan pemanduan untuk perancangan dan membuat keputusan penggunaan seterusnya. Pada masa lalu, bidang persepsi 3D telah didominasi oleh model berasaskan lidar disebabkan oleh maklumat 3D yang tepat yang diperoleh daripada data awan titik. Walau bagaimanapun, sistem berasaskan lidar adalah mahal, terdedah kepada cuaca buruk dan menyusahkan untuk digunakan. Sebaliknya, sistem berasaskan penglihatan mempunyai banyak kelebihan, seperti kos rendah, penggunaan mudah dan kebolehskalaan yang baik. Oleh itu, persepsi tiga dimensi yang berpusatkan penglihatan telah menarik perhatian yang meluas daripada penyelidik.
Baru-baru ini, pengesanan 3D berasaskan penglihatan telah dipertingkatkan dengan ketara melalui transformasi perwakilan ciri, gabungan temporal dan reka bentuk isyarat yang diselia, secara berterusan menutup jurang dengan model berasaskan lidar. Di samping itu, tugas penghunian berasaskan penglihatan telah berkembang pesat dalam beberapa tahun kebelakangan ini. Tidak seperti menggunakan kotak 3D untuk mewakili beberapa objek, penghunian boleh menerangkan geometri dan semantik adegan pemanduan dengan lebih komprehensif dan kurang terhad kepada bentuk dan kategori objek.
Walaupun kaedah pengesanan dan kaedah penghunian berkongsi banyak persamaan struktur dan konsep, pengendalian kedua-dua tugas secara serentak dan meneroka perkaitan mereka belum dikaji dengan baik. Model penghunian dan model pengesanan sering mengeluarkan perwakilan ciri yang berbeza. Tugas ramalan penghunian memerlukan pertimbangan semantik dan geometri yang menyeluruh di lokasi spatial yang berbeza, jadi perwakilan voxel digunakan secara meluas untuk mengekalkan maklumat 3D yang terperinci. Dalam tugas pengesanan, perwakilan BEV lebih disukai kerana kebanyakan objek berada pada satah mendatar yang sama dengan pertindihan yang lebih kecil.
Berbanding dengan perwakilan BEV, perwakilan voxel diperhalusi tetapi kurang cekap. Selain itu, banyak pengendali lanjutan terutamanya direka bentuk dan dioptimumkan untuk ciri 2D, menjadikan penyepaduan mereka dengan perwakilan voxel 3D tidak begitu mudah. Perwakilan BEV adalah lebih cekap masa dan ingatan, tetapi ia adalah suboptimum untuk ramalan spatial padat kerana ia kehilangan maklumat struktur dalam dimensi ketinggian. Selain perwakilan ciri, tugas persepsi yang berbeza juga berbeza dalam format dan matlamat data. Oleh itu, memastikan keseragaman dan kecekapan melatih rangka kerja persepsi 3D berbilang tugas adalah satu cabaran besar.
Struktur rangkaian UniVisionStruktur keseluruhan rangka kerja UniVision ditunjukkan dalam Rajah 1. Rangka kerja menerima imej berbilang paparan daripada N kamera sekeliling sebagai input dan mengekstrak ciri imej melalui rangkaian pengekstrakan ciri imej. Seterusnya, ciri imej 2D dinaik taraf kepada ciri voxel 3D menggunakan modul transformasi paparan Ex-Im, yang menggabungkan peningkatan ciri eksplisit berpandukan kedalaman dan pensampelan ciri tersirat berpandukan pertanyaan. Ciri voxel diproses oleh pengekstrakan ciri global tempatan dan blok gabungan untuk mengekstrak ciri voxel sedar konteks tempatan dan ciri BEV menyedari konteks global masing-masing. Selepas itu, ciri voxel dan ciri BEV yang digunakan untuk tugas persepsi hiliran yang berbeza ditukar melalui modul interaksi ciri perwakilan silang. Dalam fasa latihan, rangka kerja UniVision mengguna pakai strategi gabungan peningkatan data Occ-Det dan pelarasan beransur-ansur berat kehilangan untuk melatih dengan berkesan.
1) Transformasi Ex-Im View
Peningkatan ciri eksplisit berpandukan kedalaman. Pendekatan LSS diikuti di sini:
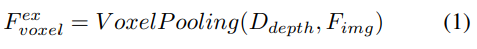
2) Pensampelan ciri tersirat berpandukan pertanyaan. Walau bagaimanapun, terdapat beberapa kelemahan dalam mewakili maklumat 3D. Ketepatan sangat berkorelasi dengan ketepatan anggaran taburan kedalaman. Tambahan pula, mata yang dijana oleh LSS tidak diagihkan sama rata. Titik padat padat berhampiran kamera dan jarang pada jarak. Oleh itu, kami selanjutnya menggunakan pensampelan ciri berpandukan pertanyaan untuk mengimbangi kekurangan di atas.
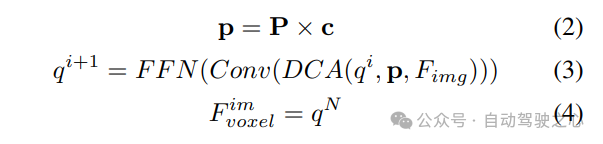
Berbanding dengan mata yang dijana daripada LSS, pertanyaan voxel diedarkan secara seragam dalam ruang 3D, dan ia dipelajari daripada sifat statistik semua sampel latihan, yang tidak bergantung pada kedalaman maklumat terdahulu yang digunakan dalam LSS. Oleh itu, dan saling melengkapi, sambungkannya sebagai ciri keluaran modul transformasi paparan:
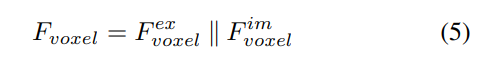
2) Pengekstrakan dan gabungan ciri global tempatan
Memandangkan ciri voxel input, letakkan dahulu ciri pada Z- paksi , dan gunakan lapisan konvolusi untuk mengurangkan saluran untuk mendapatkan ciri BEV:
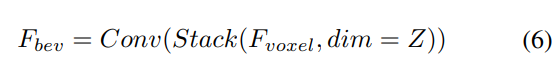
Kemudian, model dibahagikan kepada dua cabang selari untuk pengekstrakan dan peningkatan ciri. Pengekstrakan ciri tempatan + pengekstrakan ciri global, dan interaksi ciri perwakilan silang terakhir! Seperti yang ditunjukkan dalam Rajah 1(b).
3) Fungsi kehilangan dan kepala pengesan
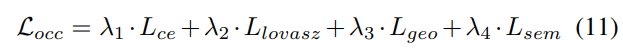
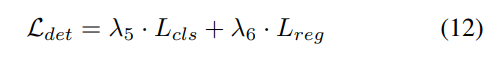
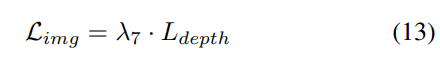
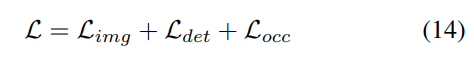
Strategi pelarasan berat badan yang progresif. Dalam amalan, didapati bahawa menggabungkan kerugian di atas secara langsung sering menyebabkan proses latihan gagal dan rangkaian gagal untuk menumpu. Pada peringkat awal latihan, ciri voxel Fvoxel diedarkan secara rawak, dan penyeliaan dalam kepala penghunian dan kepala pengesan menyumbang kurang daripada kerugian lain dalam penumpuan. Pada masa yang sama, item kehilangan seperti Lcls kehilangan klasifikasi dalam tugas pengesanan adalah sangat besar dan mendominasi proses latihan, menjadikannya sukar untuk mengoptimumkan model. Untuk mengatasi masalah ini, strategi pelarasan berat badan progresif dicadangkan untuk melaraskan berat badan secara dinamik. Khususnya, parameter kawalan δ ditambahkan pada kerugian bukan peringkat imej (iaitu, kehilangan penghunian dan kehilangan pengesanan) untuk melaraskan berat kehilangan dalam zaman latihan yang berbeza. Berat kawalan δ ditetapkan kepada nilai Vmin yang kecil pada permulaan dan secara beransur-ansur meningkat kepada Vmax dalam N zaman latihan:
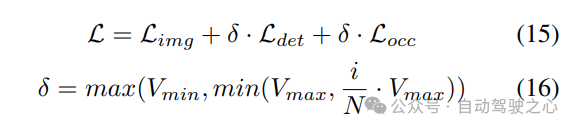
4) Penambahan data spatial Occ-Det Bersama
dalam tugas pengesanan 3D kepada pembesaran data peringkat imej biasa, peringkat spatial, penambahan data juga berkesan dalam meningkatkan model, prestasi. Walau bagaimanapun, menggunakan peningkatan tahap spatial dalam tugas penghunian adalah tidak mudah. Apabila kami menggunakan penambahan data (seperti penskalaan rawak dan putaran) pada label penghunian diskret, adalah sukar untuk menentukan semantik voxel yang terhasil. Oleh itu, kaedah sedia ada hanya menggunakan pembesaran spatial mudah seperti flipping rawak dalam tugasan penghunian.
Untuk menyelesaikan masalah ini, UniVision mencadangkan penambahan data spatial Occ-Det bersama untuk membolehkan peningkatan serentak tugas pengesanan 3D dan tugas penghunian dalam rangka kerja. Memandangkan label kotak 3D adalah nilai berterusan dan kotak 3D yang dipertingkatkan boleh dikira terus untuk latihan, kaedah peningkatan dalam BEVDet diikuti untuk pengesanan. Walaupun label penghunian adalah diskret dan sukar untuk dimanipulasi, ciri voxel boleh dianggap sebagai berterusan dan boleh diproses melalui operasi seperti pensampelan dan interpolasi. Oleh itu, adalah disyorkan untuk mengubah ciri voxel dan bukannya beroperasi secara langsung pada label penghunian untuk penambahan data.
Secara khusus, penambahan data spatial diambil pertama kali dan matriks transformasi 3D yang sepadan dikira. Untuk label penghunian dan indeks voxelnya , kami mengira koordinat tiga dimensinya. Kemudian, ia akan digunakan dan dinormalkan untuk mendapatkan indeks voxel dalam ciri voxel yang dipertingkatkan:
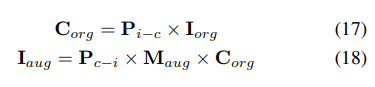
Perbandingan keputusan percubaan
Menggunakan berbilang set data untuk pengesahan, NuScenes LiDAR Segmentation3D, NuScenes LiDAR Segmentation3D OpenOccupancy dan Occ3D.
Segmentasi LiDAR NuScenes: Menurut OccFormer dan TPVFormer baru-baru ini, imej kamera digunakan sebagai input untuk tugas pembahagian lidar, dan data lidar hanya digunakan untuk menyediakan lokasi 3D untuk menanyakan ciri output. Gunakan mIoU sebagai metrik penilaian.
Pengesanan Objek 3D NuScenes: Untuk tugas pengesanan, gunakan metrik rasmi nuScenes, Skor Pengesanan nuScene (NDS), iaitu jumlah wajaran purata mAP dan beberapa metrik, termasuk ralat terjemahan purata (ATE), ralat skala purata ( ASE) ), ralat orientasi purata (AOE), ralat halaju purata (AVE) dan ralat atribut purata (AAE).
OpenOccupancy: Penanda aras OpenOccupancy adalah berdasarkan set data nuScenes dan menyediakan label penghunian semantik pada resolusi 512×512×40. Kelas berlabel adalah sama seperti yang terdapat dalam tugas pembahagian lidar, menggunakan mIoU sebagai metrik penilaian!
Occ3D: Penanda aras Occ3D adalah berdasarkan set data nuScenes dan menyediakan label penghunian semantik pada resolusi 200×200×16. Occ3D seterusnya menyediakan topeng yang boleh dilihat untuk latihan dan penilaian. Kelas berlabel adalah sama seperti yang terdapat dalam tugas pembahagian lidar, menggunakan mIoU sebagai metrik penilaian!
1) Segmentasi Nuscenes LiDAR
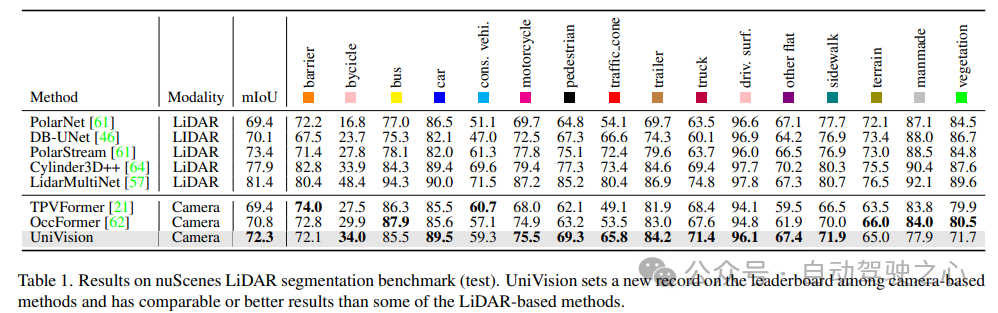
Jadual 1 menunjukkan keputusan penanda aras segmentasi nuScenes LiDAR. UniVision dengan ketara mengatasi prestasi OccFormer kaedah berasaskan penglihatan terkini sebanyak 1.5% mIoU dan menetapkan rekod baharu untuk model berasaskan penglihatan pada papan pendahulu. Terutama, UniVision juga mengatasi beberapa model berasaskan lidar seperti PolarNe dan DB-UNet.
2) Tugas Pengesanan Objek 3D NuScenes
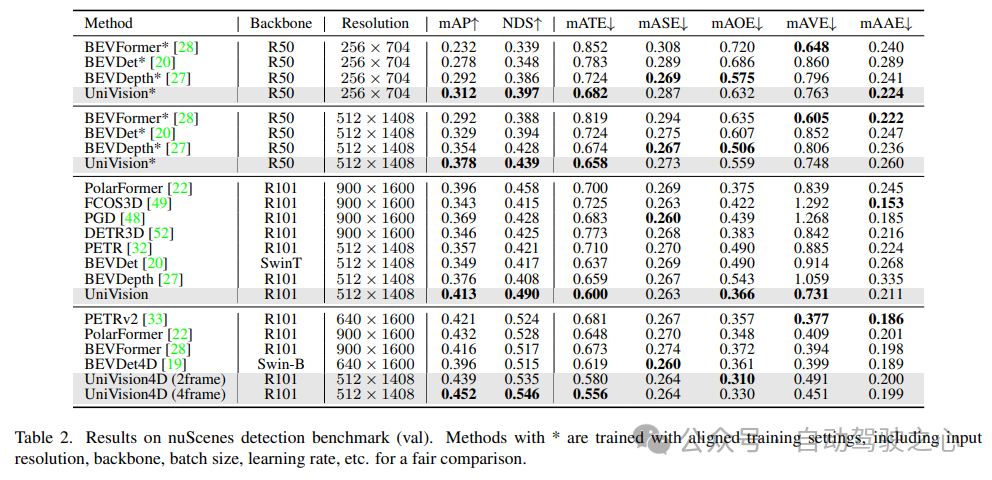
Seperti yang ditunjukkan dalam Jadual 2, UniVision ditunjukkan untuk mengatasi kaedah lain apabila menggunakan tetapan latihan yang sama untuk perbandingan yang adil. Berbanding dengan BEVDepth pada resolusi imej 512×1408, UniVision masing-masing mencapai keuntungan sebanyak 2.4% dan 1.1% dalam mAP dan NDS. Apabila model ditingkatkan dan UniVision digabungkan dengan input temporal, ia terus mengatasi pengesan temporal berasaskan SOTA dengan margin yang ketara. UniVision mencapai ini dengan resolusi input yang lebih kecil, dan ia tidak menggunakan CBGS.
3) Perbandingan keputusan OpenOccupancy
Keputusan ujian penanda aras OpenOccupancy ditunjukkan dalam Jadual 3. UniVision dengan ketara mengatasi kaedah penghunian berasaskan penglihatan terkini termasuk MonoScene, TPVFormer dan C-CONet dari segi mIoU masing-masing sebanyak 7.3%, 6.5% dan 1.5%. Tambahan pula, UniVision mengatasi beberapa kaedah berasaskan lidar seperti LMSCNet dan JS3C-Net.
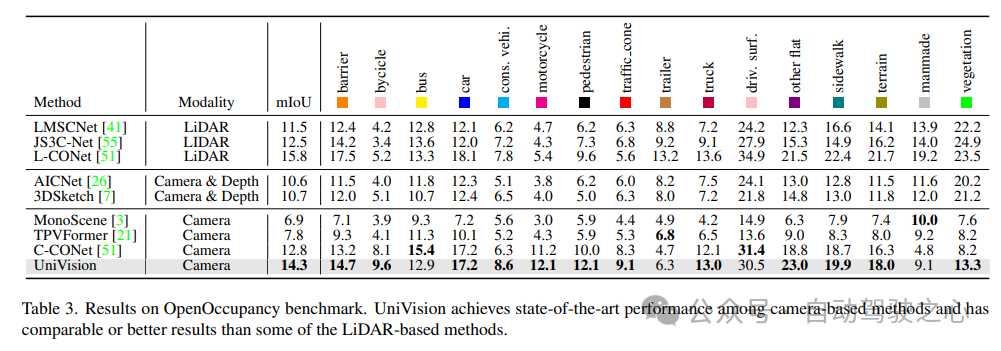
4) Keputusan Eksperimen Occ3D
Jadual 4 menyenaraikan keputusan penanda aras Occ3D. UniVision dengan ketara mengatasi kaedah berasaskan penglihatan terkini dari segi mIoU di bawah resolusi imej input yang berbeza, masing-masing lebih daripada 2.7% dan 1.8%. Perlu diingat bahawa BEVFormer dan BEVDet-stereo memuatkan pemberat pra-latihan dan menggunakan input temporal dalam inferens, manakala UniVision tidak menggunakannya tetapi masih mencapai prestasi yang lebih baik.
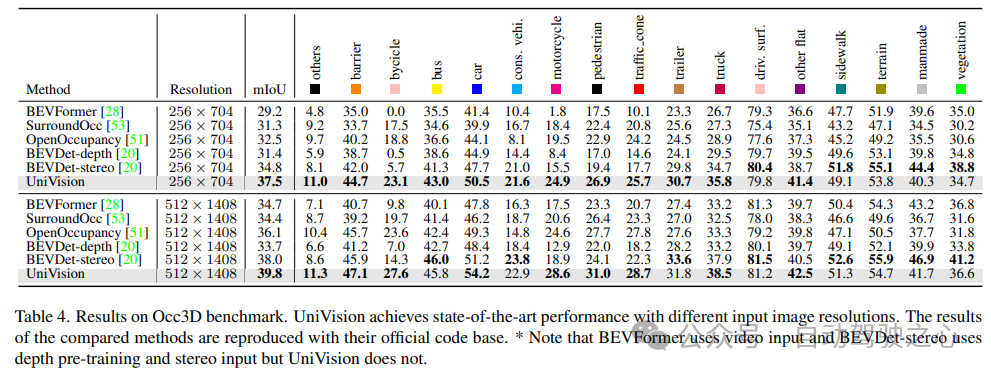
5) Keberkesanan komponen dalam tugas pengesanan
Kajian ablasi untuk tugas pengesanan ditunjukkan dalam Jadual 5. Apabila cawangan pengekstrakan ciri global berasaskan BEV dimasukkan ke dalam model garis dasar, prestasi meningkat sebanyak 1.7% mAP dan 3.0% NDS. Apabila tugas penghunian berasaskan voxel ditambahkan pada pengesan sebagai tugas tambahan, keuntungan mAP model meningkat sebanyak 1.6%. Apabila interaksi perwakilan silang diperkenalkan secara eksplisit daripada ciri voxel, model mencapai prestasi terbaik, meningkatkan mAP dan NDS masing-masing sebanyak 3.5% dan 4.2% berbanding garis dasar
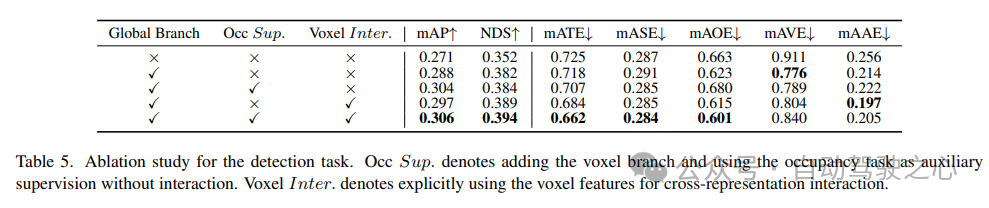
6) Keberkesanan menduduki komponen dalam tugas; daripada
ditunjukkan dalam Jadual 6 untuk kajian ablasi mengenai tugas penghunian. Rangkaian pengekstrakan ciri tempatan berasaskan voxel membawa peningkatan 1.96% keuntungan mIoU kepada model garis dasar. Apabila tugas pengesanan diperkenalkan sebagai isyarat penyeliaan tambahan, prestasi model bertambah baik sebanyak 0.4% mIoU.

7) Lain-lain
Jadual 5 dan Jadual 6 menunjukkan bahawa dalam rangka kerja UniVision, tugas pengesanan dan tugasan penghunian adalah pelengkap antara satu sama lain. Untuk tugas pengesanan, penyeliaan penghunian boleh meningkatkan metrik mAP dan mATE, menunjukkan bahawa pembelajaran semantik voxel secara berkesan meningkatkan persepsi pengesan terhadap geometri objek, iaitu, kepusatan dan skala. Untuk tugasan penghunian, penyeliaan pengesanan meningkatkan prestasi kategori latar depan dengan ketara (iaitu, kategori pengesanan), menghasilkan peningkatan keseluruhan.
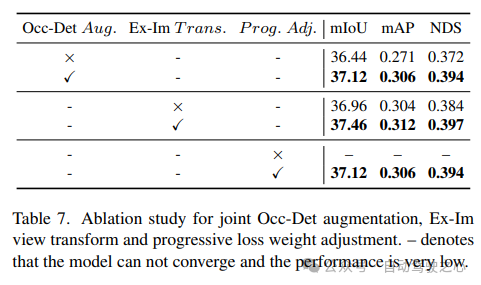
Keberkesanan gabungan peningkatan spatial Occ-Det, modul penukaran paparan Ex-Im dan strategi pelarasan berat kehilangan progresif ditunjukkan dalam Jadual 7. Dengan cadangan penambahan ruang dan modul transformasi paparan yang dicadangkan, ia menunjukkan peningkatan yang ketara dalam tugas pengesanan dan tugasan penghunian pada metrik mIoU, mAP dan NDS. Strategi pelarasan berat badan boleh melatih rangka kerja pelbagai tugas dengan berkesan. Tanpa ini, latihan rangka kerja bersatu tidak dapat bersatu dan prestasinya sangat rendah.
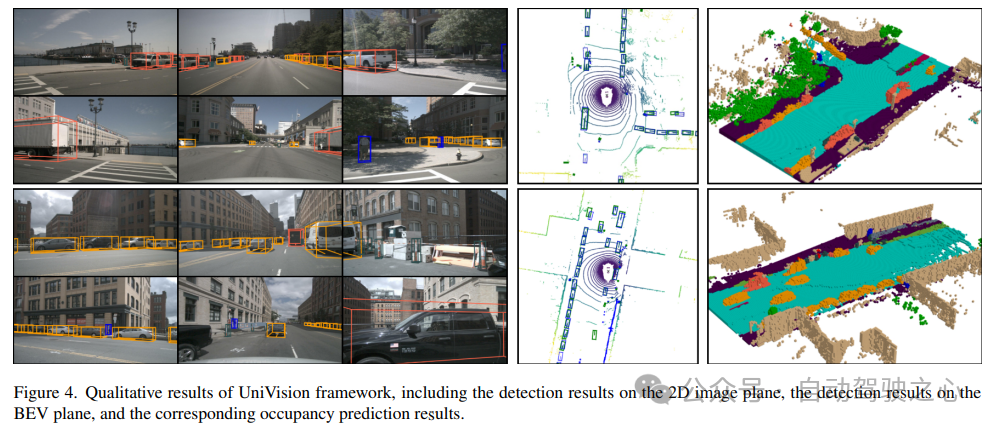
Rujukan
Pautan kertas: https://arxiv.org/pdf/2401.06994.pdf
Nama kertas: UniVision: A Unified Perception Framework for Vision-Centric🜎
3DAtas ialah kandungan terperinci UniVision yang tiada tandingan: Pengesanan BEV dan rangka kerja bersatu Occ bersama, dwi SOTA!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Ditulis di atas & pemahaman peribadi pengarang Gaussiansplatting tiga dimensi (3DGS) ialah teknologi transformatif yang telah muncul dalam bidang medan sinaran eksplisit dan grafik komputer dalam beberapa tahun kebelakangan ini. Kaedah inovatif ini dicirikan oleh penggunaan berjuta-juta Gaussians 3D, yang sangat berbeza daripada kaedah medan sinaran saraf (NeRF), yang terutamanya menggunakan model berasaskan koordinat tersirat untuk memetakan koordinat spatial kepada nilai piksel. Dengan perwakilan adegan yang eksplisit dan algoritma pemaparan yang boleh dibezakan, 3DGS bukan sahaja menjamin keupayaan pemaparan masa nyata, tetapi juga memperkenalkan tahap kawalan dan pengeditan adegan yang tidak pernah berlaku sebelum ini. Ini meletakkan 3DGS sebagai penukar permainan yang berpotensi untuk pembinaan semula dan perwakilan 3D generasi akan datang. Untuk tujuan ini, kami menyediakan gambaran keseluruhan sistematik tentang perkembangan dan kebimbangan terkini dalam bidang 3DGS buat kali pertama.
 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Ramalan trajektori memainkan peranan penting dalam pemanduan autonomi Ramalan trajektori pemanduan autonomi merujuk kepada meramalkan trajektori pemanduan masa hadapan kenderaan dengan menganalisis pelbagai data semasa proses pemanduan kenderaan. Sebagai modul teras pemanduan autonomi, kualiti ramalan trajektori adalah penting untuk kawalan perancangan hiliran. Tugas ramalan trajektori mempunyai timbunan teknologi yang kaya dan memerlukan kebiasaan dengan persepsi dinamik/statik pemanduan autonomi, peta ketepatan tinggi, garisan lorong, kemahiran seni bina rangkaian saraf (CNN&GNN&Transformer), dll. Sangat sukar untuk bermula! Ramai peminat berharap untuk memulakan ramalan trajektori secepat mungkin dan mengelakkan perangkap Hari ini saya akan mengambil kira beberapa masalah biasa dan kaedah pembelajaran pengenalan untuk ramalan trajektori! Pengetahuan berkaitan pengenalan 1. Adakah kertas pratonton teratur? A: Tengok survey dulu, hlm
 SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
Tajuk asal: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper pautan: https://arxiv.org/pdf/2402.02519.pdf Pautan kod: https://github.com/HKUST-Aerial-Robotics/SIMPL Unit pengarang: Universiti Sains Hong Kong dan Teknologi Idea Kertas DJI: Kertas kerja ini mencadangkan garis dasar ramalan pergerakan (SIMPL) yang mudah dan cekap untuk kenderaan autonomi. Berbanding dengan agen-sen tradisional
 SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
Ditulis di hadapan & titik permulaan Paradigma hujung ke hujung menggunakan rangka kerja bersatu untuk mencapai pelbagai tugas dalam sistem pemanduan autonomi. Walaupun kesederhanaan dan kejelasan paradigma ini, prestasi kaedah pemanduan autonomi hujung ke hujung pada subtugas masih jauh ketinggalan berbanding kaedah tugasan tunggal. Pada masa yang sama, ciri pandangan mata burung (BEV) padat yang digunakan secara meluas dalam kaedah hujung ke hujung sebelum ini menyukarkan untuk membuat skala kepada lebih banyak modaliti atau tugasan. Paradigma pemanduan autonomi hujung ke hujung (SparseAD) tertumpu carian jarang dicadangkan di sini, di mana carian jarang mewakili sepenuhnya keseluruhan senario pemanduan, termasuk ruang, masa dan tugas, tanpa sebarang perwakilan BEV yang padat. Khususnya, seni bina jarang bersatu direka bentuk untuk kesedaran tugas termasuk pengesanan, penjejakan dan pemetaan dalam talian. Di samping itu, berat
 Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Pada bulan lalu, atas sebab-sebab yang diketahui umum, saya telah mengadakan pertukaran yang sangat intensif dengan pelbagai guru dan rakan sekelas dalam industri. Topik yang tidak dapat dielakkan dalam pertukaran secara semula jadi adalah hujung ke hujung dan Tesla FSDV12 yang popular. Saya ingin mengambil kesempatan ini untuk menyelesaikan beberapa buah fikiran dan pendapat saya pada masa ini untuk rujukan dan perbincangan anda. Bagaimana untuk mentakrifkan sistem pemanduan autonomi hujung ke hujung, dan apakah masalah yang sepatutnya dijangka diselesaikan hujung ke hujung? Menurut definisi yang paling tradisional, sistem hujung ke hujung merujuk kepada sistem yang memasukkan maklumat mentah daripada penderia dan secara langsung mengeluarkan pembolehubah yang membimbangkan tugas. Sebagai contoh, dalam pengecaman imej, CNN boleh dipanggil hujung-ke-hujung berbanding kaedah pengekstrak ciri + pengelas tradisional. Dalam tugas pemanduan autonomi, masukkan data daripada pelbagai penderia (kamera/LiDAR
