

Tidak lama lagi, laporan teknikal Stable Diffusion 3, "raja baharu grafik Vincentian", di sini.
Teks penuh mempunyai sejumlah 28 muka surat dan penuh dengan keikhlasan.

"Peraturan lama", poster promosi (⬇️) dijana secara langsung dengan model dan mempamerkan keupayaan pemaparan teks mereka:
Jadi, SD3 mempunyai teks dan arahan yang lebih kuat berbanding DALL·E v6 dan Midjourney 3 Bagaimanakah kemahiran berikut menyala?
Laporan teknikal mendedahkan:
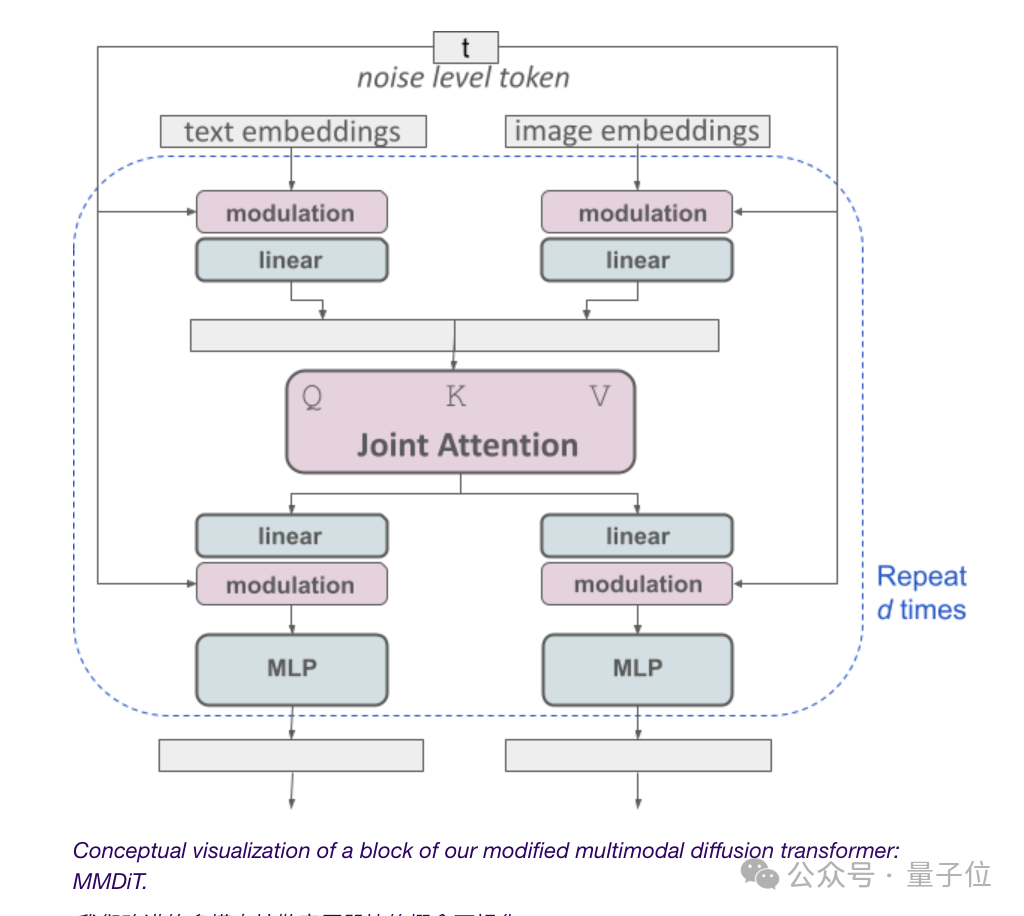
Semuanya bergantung pada seni bina Transformer resapan pelbagai mod MMDiT.
Mencapai peningkatan prestasi yang lebih besar daripada versi sebelumnya dengan menggunakan set pemberat yang berbeza masing-masing pada perwakilan imej dan teks, yang merupakan kunci kejayaan.
Untuk geometri khusus, mari buka laporan dan lihat.
Pada permulaan keluaran SD3, pegawai itu mendedahkan bahawa seni binanya mempunyai asal yang sama seperti Sora dan merupakan Transformer-DiT resapan.
Kini jawapannya terbongkar:
Memandangkan model rajah Vincent perlu mempertimbangkan kedua-dua mod teks dan imej, Stability AI melangkah lebih jauh daripada DiT dan mencadangkan MMDiT seni bina baharu.
"MM" di sini merujuk kepada "multimodal".
Seperti versi Stable Diffusion sebelumnya, pegawai itu menggunakan dua model terlatih untuk mendapatkan representasi teks dan imej yang sesuai.
Pengekodan perwakilan teks dilakukan menggunakan tiga pembenam teks berbeza (pembenam), termasuk dua model CLIP dan model T5.
Pengekodan token imej dilengkapkan menggunakan model pengekod automatik yang dipertingkatkan.
Memandangkan pembenaman teks dan imej secara konsep bukan perkara yang sama, SD3 menggunakan dua set pemberat bebas untuk kedua-dua mod ini.
(Sesetengah netizen mengeluh: Gambar rajah seni bina ini seolah-olah memulakan "Projek Penyiapan Manusia", ya, sesetengah orang hanya "melihat maklumat mengenai "Neon Genesis Evangelion" dan mengklik pada laporan ini")
Berbalik kepada subjek, seperti yang ditunjukkan dalam rajah di atas, ini adalah bersamaan dengan mempunyai dua transformer bebas untuk setiap modaliti, tetapi jujukan mereka akan disambungkan untuk operasi perhatian.
Dengan cara ini kedua-dua perwakilan boleh berfungsi dalam ruang mereka sendiri sambil tetap mengambil kira yang lain.
Akhirnya, melalui kaedah ini, maklumat boleh "mengalir" antara imej dan token teks, meningkatkan pemahaman keseluruhan model dan keupayaan rendering teks semasa mengeluarkan.
Dan seperti yang ditunjukkan oleh kesan sebelumnya, seni bina ini juga boleh diperluaskan dengan mudah kepada berbilang mod seperti video.

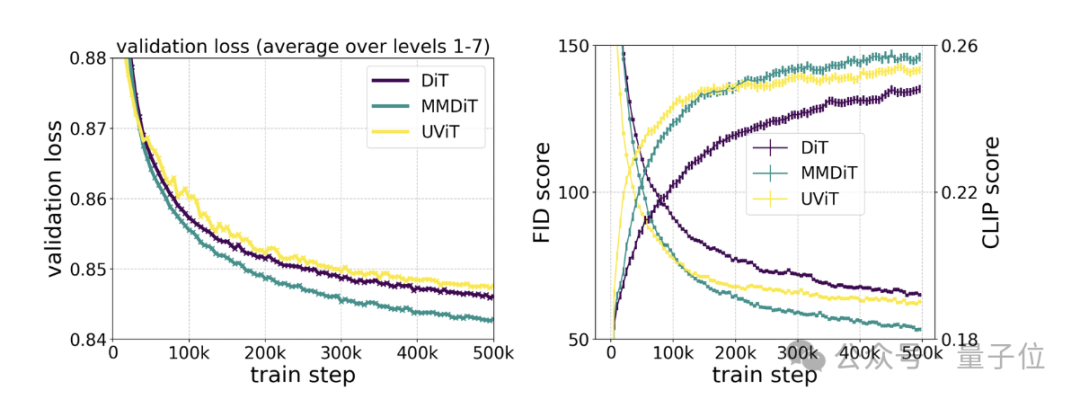
Ujian khusus menunjukkan bahawa MMDiT adalah berdasarkan DiT tetapi lebih baik daripada DiT:
Kesetiaan visual dan penjajaran teks semasa proses latihan adalah lebih baik daripada tulang belakang teks ke imej sedia ada, seperti UViT dan DiT .
Pada permulaan keluaran, sebagai tambahan kepada seni bina Transformer penyebaran, pegawai itu juga mendedahkan bahawa SD3 menggabungkan padanan aliran.
Apakah "aliran"?
Seperti yang didedahkan dalam tajuk kertas yang dikeluarkan hari ini, SD3 menggunakan "Rectified Flow" (RF).

Ini ialah kaedah penjanaan model resapan baharu yang "sangat mudah, generasi satu langkah", yang dipilih untuk ICLR2023.
Ia membolehkan data dan hingar model disambungkan dalam trajektori linear semasa latihan, menghasilkan laluan inferens yang lebih "lurus" yang boleh menggunakan lebih sedikit langkah untuk pensampelan.
Berdasarkan RF, SD3 memperkenalkan pensampelan trajektori baharu semasa proses latihan.
Ia memfokuskan untuk memberi lebih berat pada bahagian tengah trajektori, kerana penulis menganggap bahagian ini akan menyelesaikan tugas ramalan yang lebih mencabar.
Menguji kaedah penjanaan ini terhadap 60 kaedah trajektori resapan lain (seperti LDM, EDM dan ADM) merentas berbilang set data, metrik dan konfigurasi pensampel mendapati bahawa:
Walaupun kaedah RF sebelumnya berprestasi buruk dalam skim pensampelan beberapa langkah memberikan prestasi yang baik, tetapi prestasi relatif mereka berkurangan apabila bilangan langkah meningkat.
Sebaliknya, varian RF wajaran semula SD3 terus meningkatkan prestasi.
Pegawai menjalankan kajian penskalaan pada penjanaan teks-ke-imej menggunakan kaedah RF wajaran semula dan seni bina MMDiT.
Model terlatih terdiri daripada 15 modul dengan 450 juta parameter hingga 38 modul dengan 8 bilion parameter.
Daripada ini mereka memerhati: Apabila saiz model dan langkah latihan meningkat, kehilangan pengesahan menunjukkan aliran menurun yang lancar, iaitu model menyesuaikan diri dengan data yang lebih kompleks melalui pembelajaran berterusan.
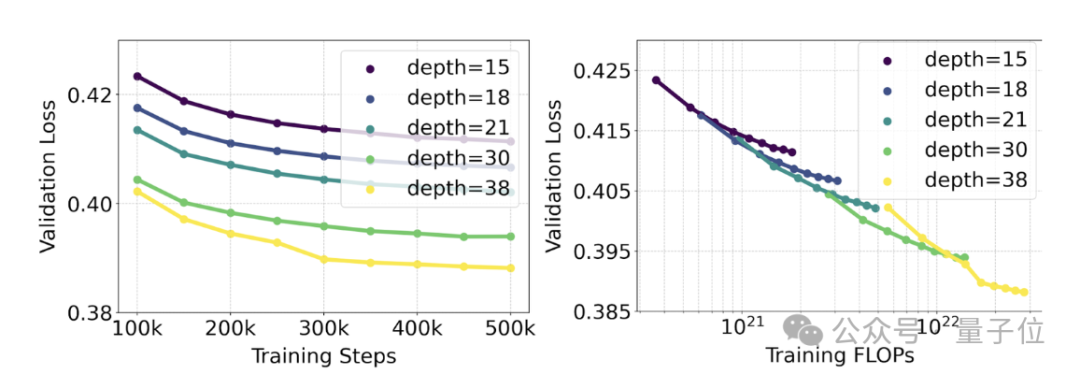
Untuk menguji sama ada ini diterjemahkan kepada peningkatan yang lebih bermakna dalam output model, kami juga menilai metrik penjajaran imej automatik (GenEval) serta skor keutamaan manusia (ELO) .
Hasilnya ialah:
Terdapat perkaitan yang kuat antara keduanya. Iaitu, kehilangan pengesahan boleh digunakan sebagai penunjuk yang sangat berkuasa untuk meramal prestasi model keseluruhan.
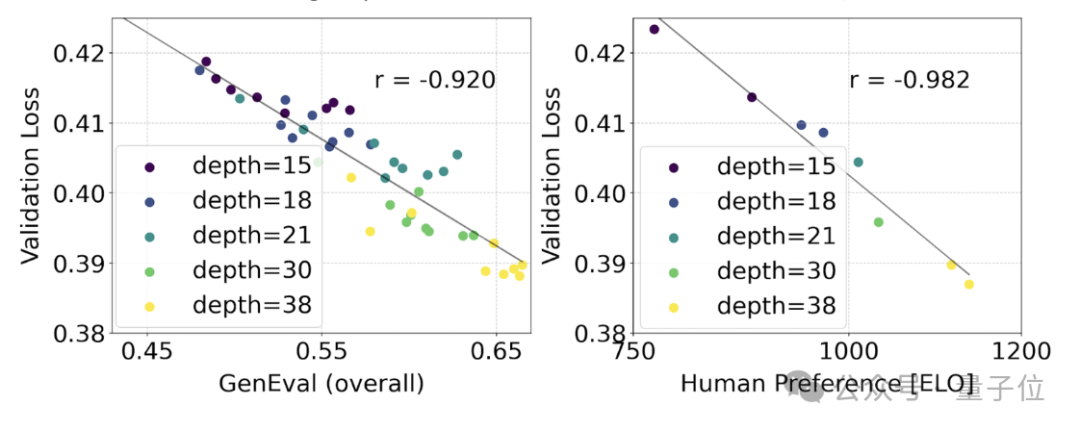
Selain itu, memandangkan trend pengembangan di sini tidak menunjukkan tanda-tanda tepu (iaitu, apabila saiz model meningkat, prestasi masih bertambah baik dan belum mencapai had), pegawai itu sangat optimistik:
prestasi SD3 pada masa hadapan masih boleh dipertingkatkan.
Akhirnya, laporan teknikal juga menyebut isu pengekod teks:
Dengan mengalih keluar parameter 4.7 bilion, pengekod teks T5 intensif memori yang digunakan untuk inferens, keperluan memori SD3 boleh dikurangkan dengan ketara, tetapi pada masa yang sama, kehilangan prestasi adalah kecil (kadar kemenangan menurun daripada 50% kepada 46%).
Namun, demi keupayaan pemaparan teks, syor rasmi adalah untuk tidak mengalih keluar T5, kerana tanpanya, kadar kemenangan perwakilan teks akan turun kepada 38%.

Jadi untuk meringkaskan: antara tiga pengekod teks SD3, T5 memberikan sumbangan terbesar apabila menjana imej dengan teks (dan imej penerangan pemandangan yang sangat terperinci).
Sebaik sahaja laporan SD3 keluar, ramai netizen berkata:
Stability AI sangat berbesar hati kerana komitmen sumber terbuka telah ditunaikan seperti yang dijadualkan, dan saya harap mereka dapat terus menyelenggara dan mengendalikannya untuk jangka masa yang lama.

Sesetengah orang tidak dapat menuntut nama OpenAI:

Apa yang lebih menggembirakan ialah seseorang menyebut dalam ruangan komen:
Semua berat SD3, dan model boleh dimuat turun. rancangan semasa ialah 800 juta parameter, 2 bilion parameter dan 8 bilion parameter.


Bagaimana kelajuannya?
Ahem, laporan teknikal menyebut:
8 bilion SD3 mengambil masa 34s untuk menjana imej 1024*1024 pada 24GB RTX 4090 (50 langkah pensampelan) - tetapi ini hanyalah keputusan awal ujian yang tidak dioptimumkan.
Teks penuh laporan: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf.
Pautan rujukan:
[1]https://stability.ai/news/stable-diffusion-3-research-paper.
[2]https://news.ycombinator.com/item?id=39599958.
Atas ialah kandungan terperinci Laporan teknikal Stable Diffusion 3 dikeluarkan: mendedahkan butiran seni bina Sora yang sama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 apa maksud oem
apa maksud oem
 kaedah pencetus tambah oracle
kaedah pencetus tambah oracle
 Bagaimana untuk membaiki sistem win7 jika ia rosak dan tidak boleh boot
Bagaimana untuk membaiki sistem win7 jika ia rosak dan tidak boleh boot
 Peranan kad rangkaian pelayan
Peranan kad rangkaian pelayan
 Jadual perkataan tersebar di seluruh halaman
Jadual perkataan tersebar di seluruh halaman
 Kaedah penugasan tatasusunan rentetan
Kaedah penugasan tatasusunan rentetan
 Pengenalan kepada kandungan kerja utama bahagian belakang
Pengenalan kepada kandungan kerja utama bahagian belakang
 Apakah maksud versi ts?
Apakah maksud versi ts?
 Perbezaan antara versi rumah win10 dan versi profesional
Perbezaan antara versi rumah win10 dan versi profesional








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



