
 Peranti teknologi
AI
Kerja baharu oleh Tian Yuandong dan lain-lain: Menembusi kesesakan memori dan membenarkan model besar 7B 4090 terlatih
Peranti teknologi
AI
Kerja baharu oleh Tian Yuandong dan lain-lain: Menembusi kesesakan memori dan membenarkan model besar 7B 4090 terlatih
Kerja baharu oleh Tian Yuandong dan lain-lain: Menembusi kesesakan memori dan membenarkan model besar 7B 4090 terlatih

Meta FAIR Projek penyelidikan yang disertai Tian Yuandong menerima pujian meluas bulan lepas. Dalam kertas kerja mereka "MobileLLM: Mengoptimumkan Model Bahasa Parameter Sub-bilion untuk Kes Penggunaan Pada Peranti", mereka mula meneroka cara mengoptimumkan model kecil dengan kurang daripada 1 bilion parameter, bertujuan untuk mencapai matlamat menjalankan model bahasa besar pada peranti mudah alih .
Pada 6 Mac, pasukan Tian Yuandong mengeluarkan hasil penyelidikan terkini, kali ini memfokuskan pada meningkatkan kecekapan memori LLM. Selain Tian Yuandong sendiri, pasukan penyelidik juga termasuk penyelidik dari California Institute of Technology, University of Texas di Austin, dan CMU. Penyelidikan ini bertujuan untuk mengoptimumkan lagi prestasi memori LLM dan memberikan sokongan dan bimbingan untuk pembangunan teknologi masa hadapan.
Mereka bersama-sama mencadangkan strategi latihan yang dipanggil GaLore (Gradient Low-Rank Projection), yang membolehkan pembelajaran parameter penuh Berbanding dengan kaedah penyesuaian peringkat rendah biasa seperti LoRA, GaLore mempunyai kecekapan Memori yang lebih tinggi.
Kajian ini menunjukkan buat kali pertama bahawa model 7B boleh dilatih dengan jayanya pada GPU pengguna dengan memori 24GB (cth. NVIDIA RTX 4090) tanpa menggunakan strategi selari model, pemeriksaan atau pemunggahan. . Kandungan utama artikel.
 Pada masa ini, Model Bahasa Besar (LLM) telah menunjukkan potensi yang luar biasa dalam banyak bidang, tetapi kita juga mesti menghadapi masalah sebenar, iaitu pra-latihan dan penalaan halus LLM bukan sahaja memerlukan sejumlah besar sumber pengkomputeran, tetapi juga memerlukan sejumlah besar sokongan memori.
Pada masa ini, Model Bahasa Besar (LLM) telah menunjukkan potensi yang luar biasa dalam banyak bidang, tetapi kita juga mesti menghadapi masalah sebenar, iaitu pra-latihan dan penalaan halus LLM bukan sahaja memerlukan sejumlah besar sumber pengkomputeran, tetapi juga memerlukan sejumlah besar sokongan memori.
Keperluan memori LLM termasuk bukan sahaja parameter dalam berbilion-bilion, tetapi juga kecerunan dan Keadaan Pengoptimum (seperti momentum kecerunan dan varians dalam Adam), yang boleh lebih besar daripada storan itu sendiri. Contohnya, LLaMA 7B, dipralatih dari awal menggunakan saiz kelompok tunggal, memerlukan sekurang-kurangnya 58 GB memori (14 GB untuk parameter boleh dilatih, 42 GB untuk Adam Optimizer States dan kecerunan berat dan 2 GB untuk pengaktifan). Ini menjadikan latihan LLM tidak dapat dilaksanakan pada GPU gred pengguna seperti NVIDIA RTX 4090 dengan memori 24GB.
Untuk menyelesaikan masalah di atas, penyelidik terus membangunkan pelbagai teknik pengoptimuman untuk mengurangkan penggunaan memori semasa pra-latihan dan penalaan halus.
Kaedah ini mengurangkan penggunaan memori sebanyak 65.5% di bawah Negeri Pengoptimum, sambil mengekalkan kecekapan dan prestasi pra-latihan pada seni bina LLaMA 1B dan 7B menggunakan set data C4 dengan token sehingga 19.7B, dan dalam GLUE Penalaan Halus kecekapan dan prestasi RoBERTa pada tugas. Berbanding dengan garis dasar BF16, GaLore 8-bit seterusnya mengurangkan memori pengoptimum sebanyak 82.5% dan jumlah memori latihan sebanyak 63.3%.
Selepas melihat penyelidikan ini, netizen berkata: "Sudah tiba masanya untuk melupakan awan dan HPC. Dengan GaLore, semua AI4Science akan disiapkan pada GPU gred pengguna $2,000
berkata: "Dengan GaLore, kini mungkin untuk melatih model 7B dalam NVidia RTX 4090s dengan memori 24G.
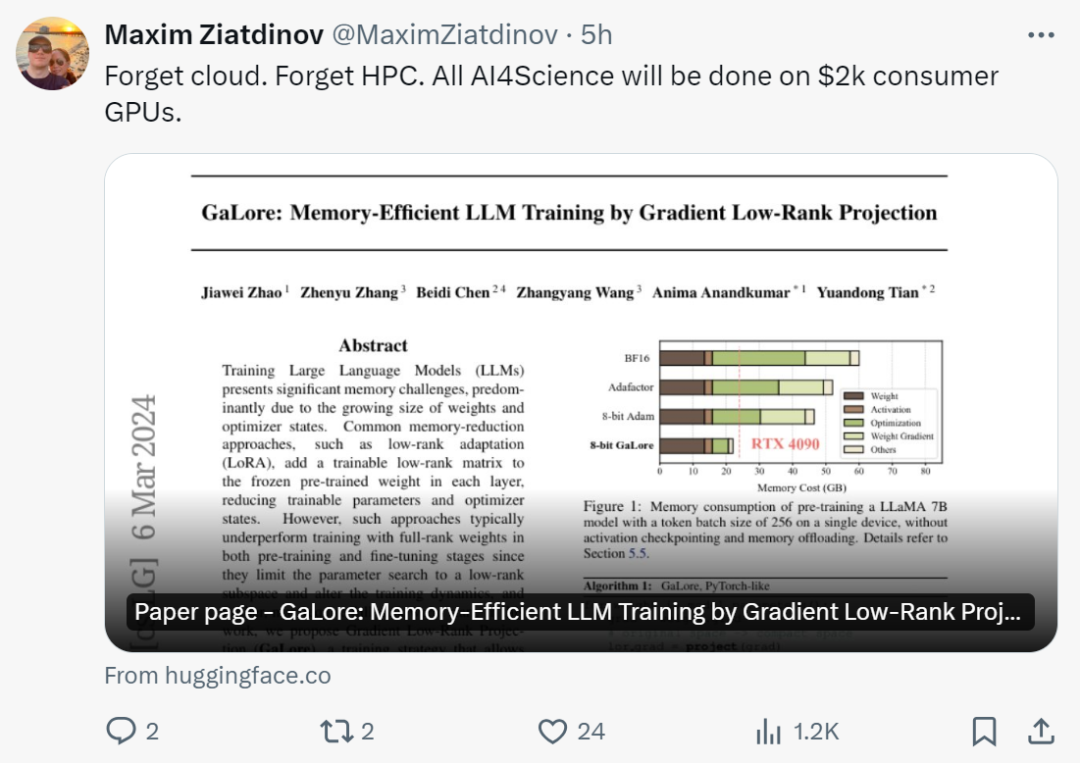 Kami tidak menganggap struktur berat peringkat rendah seperti LoRA, tetapi membuktikan bahawa kecerunan berat secara semula jadi rendah- rank , dan dengan itu boleh diunjurkan ke dalam ruang dimensi rendah (berbeza-beza) Oleh itu, kami pada masa yang sama menyimpan memori untuk kecerunan, momentum Adam dan varians
Kami tidak menganggap struktur berat peringkat rendah seperti LoRA, tetapi membuktikan bahawa kecerunan berat secara semula jadi rendah- rank , dan dengan itu boleh diunjurkan ke dalam ruang dimensi rendah (berbeza-beza) Oleh itu, kami pada masa yang sama menyimpan memori untuk kecerunan, momentum Adam dan varians
Oleh itu, tidak seperti LoRA, GaLore tidak mengubah dinamik latihan dan boleh. digunakan dari awal. Mulakan pra-latihan model 7B tanpa sebarang pemanasan yang memakan memori juga boleh digunakan untuk penalaan halus, menghasilkan hasil yang setanding dengan LoRA.
Pengenalan Kaedah
 Seperti yang dinyatakan sebelum ini, GaLore ialah strategi latihan yang membolehkan pembelajaran parameter penuh, tetapi lebih cekap memori daripada kaedah penyesuaian peringkat rendah biasa (seperti LoRA). Idea utama GaLore adalah untuk menggunakan struktur peringkat rendah yang berubah secara perlahan bagi kecerunan
Seperti yang dinyatakan sebelum ini, GaLore ialah strategi latihan yang membolehkan pembelajaran parameter penuh, tetapi lebih cekap memori daripada kaedah penyesuaian peringkat rendah biasa (seperti LoRA). Idea utama GaLore adalah untuk menggunakan struktur peringkat rendah yang berubah secara perlahan bagi kecerunan
matriks berat W, dan bukannya cuba menganggarkan secara langsung matriks berat ke dalam bentuk peringkat rendah.
Artikel ini terlebih dahulu secara teori membuktikan bahawa matriks kecerunan G akan menjadi peringkat rendah semasa proses latihan Berdasarkan teori, artikel ini menggunakan GaLore untuk mengira dua matriks unjuran 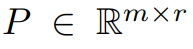 dan
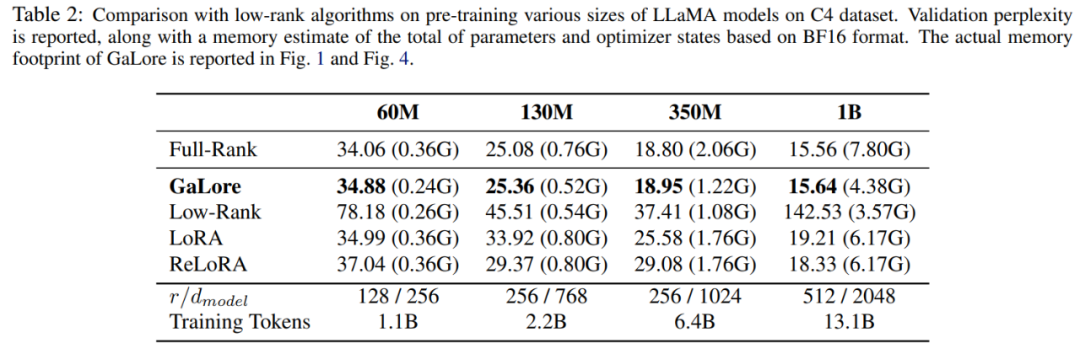
dan 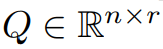 untuk menayangkan matriks kecerunan G ke dalam. Borang peringkat rendah P^⊤GQ. Dalam kes ini, kos memori Negeri Pengoptimum yang bergantung pada statistik kecerunan komponen boleh dikurangkan dengan ketara. Seperti yang ditunjukkan dalam Jadual 1, GaLore lebih cekap ingatan daripada LoRA. Malah, ini boleh mengurangkan ingatan sehingga 30% semasa pra-latihan berbanding LoRA.
untuk menayangkan matriks kecerunan G ke dalam. Borang peringkat rendah P^⊤GQ. Dalam kes ini, kos memori Negeri Pengoptimum yang bergantung pada statistik kecerunan komponen boleh dikurangkan dengan ketara. Seperti yang ditunjukkan dalam Jadual 1, GaLore lebih cekap ingatan daripada LoRA. Malah, ini boleh mengurangkan ingatan sehingga 30% semasa pra-latihan berbanding LoRA.

Artikel ini membuktikan bahawa GaLore menunjukkan prestasi yang baik dalam pra-latihan dan penalaan halus. Semasa pra-latihan LLaMA 7B pada set data C4, GaLore 8-bit menggabungkan teknologi kemas kini berat 8-bit dan lapisan demi lapisan untuk mencapai prestasi yang setanding dengan kedudukan penuh dengan kos memori kurang daripada 10% dalam keadaan pengoptimum.
Perlu diingat bahawa untuk pra-latihan, GaLore mengekalkan daya ingatan yang rendah sepanjang proses latihan tanpa memerlukan latihan peringkat penuh seperti ReLoRA. Terima kasih kepada kecekapan memori GaLore, buat pertama kalinya, LLaMA 7B boleh dilatih dari awal pada satu GPU dengan memori 24GB (cth., pada NVIDIA RTX 4090) tanpa memerlukan sebarang teknik pemunggahan memori yang mahal (Rajah 1).
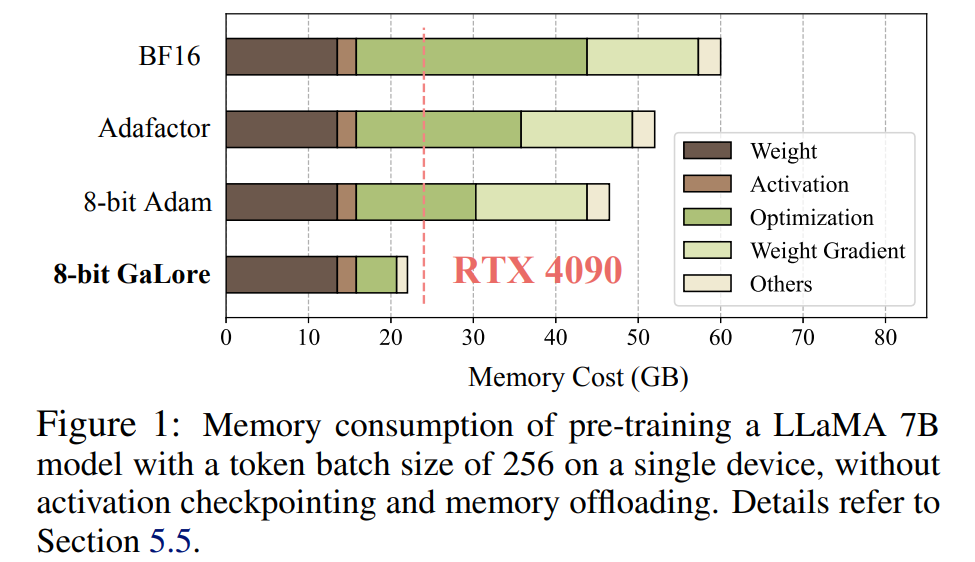
Sebagai kaedah unjuran kecerunan, GaLore adalah bebas daripada pilihan pengoptimum dan boleh dipalamkan dengan mudah ke pengoptimum sedia ada dengan hanya dua baris kod, seperti yang ditunjukkan dalam Algoritma 1.

Angka berikut menunjukkan algoritma untuk menggunakan GaLore kepada Adam:

Eksperimen dan keputusan
Penyelidik yang telah menguji dan menilai. Semua eksperimen dilakukan pada NVIDIA A100 GPU.
Untuk menilai prestasinya, para penyelidik menggunakan GaLore untuk melatih model bahasa besar berdasarkan LLaMA pada set data C4. Set data C4 ialah versi korpus rangkak web Common Crawl yang besar dan bersih, digunakan terutamanya untuk melatih model bahasa dan perwakilan perkataan. Untuk mensimulasikan terbaik senario pra-latihan sebenar, para penyelidik melatih jumlah data yang cukup besar tanpa menduplikasi data, dengan saiz model antara sehingga 7 bilion parameter.
Makalah ini mengikuti persediaan percubaan Lialin et al., menggunakan seni bina berasaskan LLaMA3 dengan pengaktifan RMSNorm dan SwiGLU. Untuk setiap saiz model, kecuali untuk kadar pembelajaran, mereka menggunakan set hiperparameter yang sama dan menjalankan semua eksperimen dalam format BF16 untuk mengurangkan penggunaan memori sambil melaraskan kadar pembelajaran untuk setiap kaedah dengan belanjawan pengiraan yang sama dan melaporkan prestasi optimum.
Selain itu, para penyelidik menggunakan tugas GLUE sebagai penanda aras untuk penalaan halus GaLore dan LoRA yang cekap ingatan. GLUE ialah penanda aras untuk menilai prestasi model NLP dalam pelbagai tugas, termasuk analisis sentimen, menjawab soalan dan korelasi teks.
Kertas ini mula-mula menggunakan pengoptimum Adam untuk membandingkan GaLore dengan kaedah peringkat rendah sedia ada, dan hasilnya ditunjukkan dalam Jadual 2.
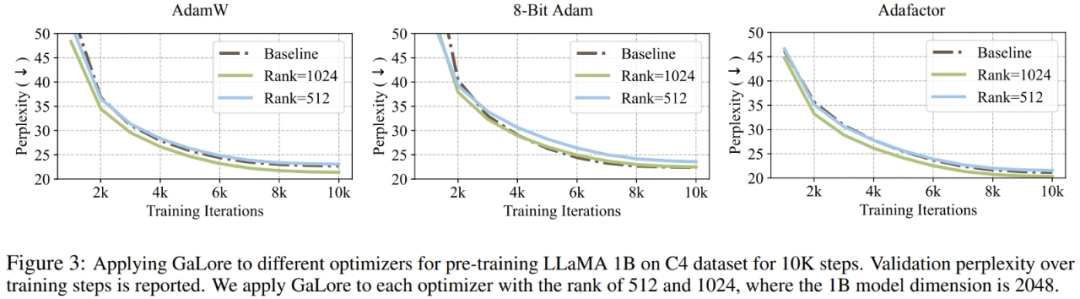
Penyelidik telah membuktikan bahawa GaLore boleh digunakan untuk pelbagai algoritma pembelajaran, terutamanya pengoptimum yang cekap memori, untuk mengurangkan lagi penggunaan memori. Para penyelidik menggunakan GaLore pada pengoptimum AdamW, 8-bit Adam, dan Adafactor. Mereka menggunakan Adafaktor statistik pesanan pertama untuk mengelakkan kemerosotan prestasi.
Percubaan menilai mereka pada seni bina LLaMA 1B dengan 10K langkah latihan, menala kadar pembelajaran untuk setiap tetapan dan melaporkan prestasi terbaik. Seperti yang ditunjukkan dalam Rajah 3, graf di bawah menunjukkan bahawa GaLore berfungsi dengan pengoptimum popular seperti AdamW, Adam 8-bit dan Adafactor. Tambahan pula, memperkenalkan sangat sedikit hiperparameter tidak menjejaskan prestasi GaLore.
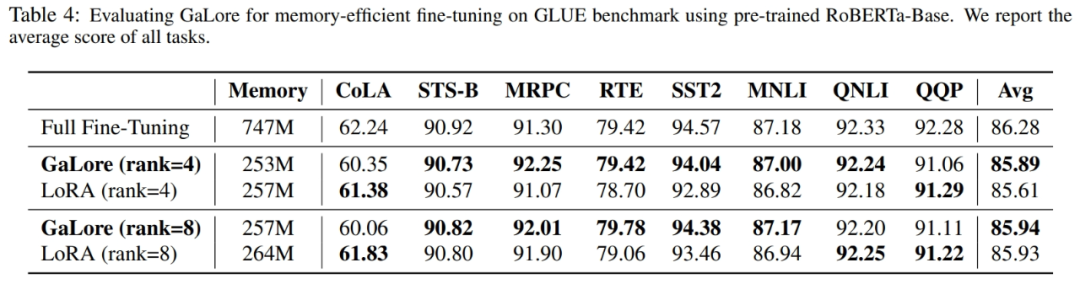
Seperti yang ditunjukkan dalam Jadual 4, GaLore boleh mencapai prestasi yang lebih tinggi daripada LoRA dengan penggunaan memori yang kurang dalam kebanyakan tugas. Ini menunjukkan bahawa GaLore boleh digunakan sebagai strategi latihan cekap memori tindanan penuh untuk pra-latihan dan penalaan halus LLM.
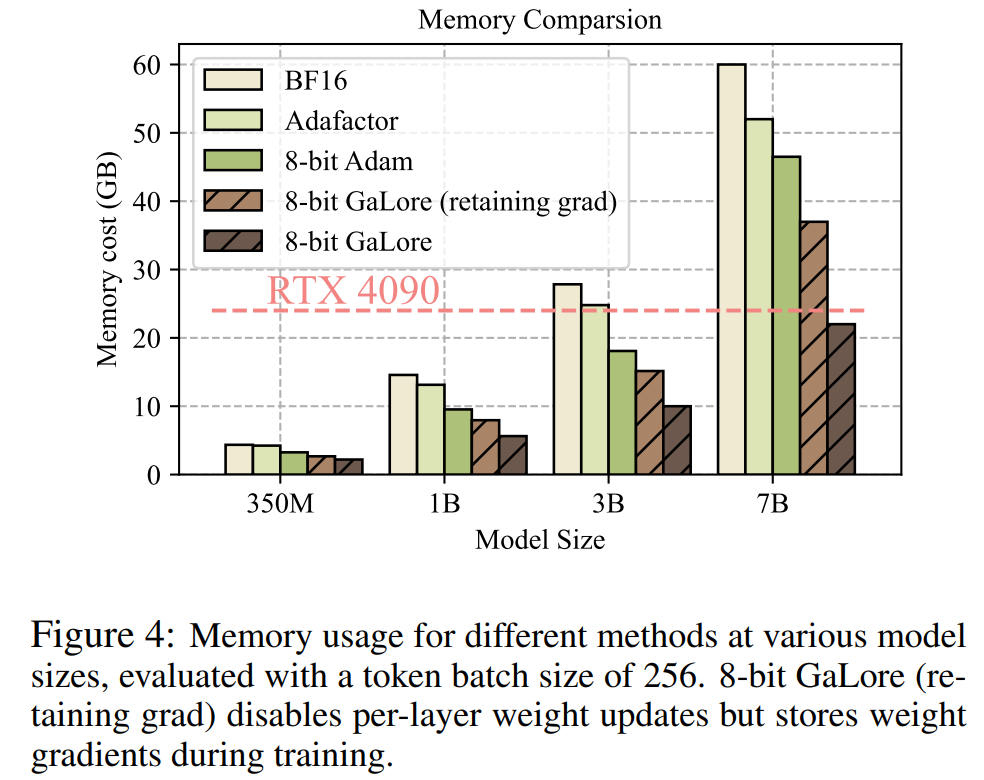
Seperti yang ditunjukkan dalam Rajah 4, berbanding dengan penanda aras BF16 dan 8 bit Adam, 8 bit GaLore memerlukan lebih sedikit memori, hanya memerlukan memori 22.0G apabila pra-latihan LLaMA 7B, dan setiap saiz kumpulan GPU adalah token lebih kecil (sehingga 500 token).
Untuk butiran lanjut teknikal, sila baca kertas asal.
Atas ialah kandungan terperinci Kerja baharu oleh Tian Yuandong dan lain-lain: Menembusi kesesakan memori dan membenarkan model besar 7B 4090 terlatih. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Cara menyempurnakan deepseek di dalam negara
Feb 19, 2025 pm 05:21 PM
Cara menyempurnakan deepseek di dalam negara
Feb 19, 2025 pm 05:21 PM
Penalaan setempat model kelas DeepSeek menghadapi cabaran sumber dan kepakaran pengkomputeran yang tidak mencukupi. Untuk menangani cabaran-cabaran ini, strategi berikut boleh diterima pakai: Kuantisasi model: Menukar parameter model ke dalam bilangan bulat ketepatan rendah, mengurangkan jejak memori. Gunakan model yang lebih kecil: Pilih model pretrained dengan parameter yang lebih kecil untuk penalaan halus tempatan yang lebih mudah. Pemilihan data dan pra-proses: Pilih data berkualiti tinggi dan lakukan pra-proses yang sesuai untuk mengelakkan kualiti data yang lemah yang mempengaruhi keberkesanan model. Latihan Batch: Untuk set data yang besar, beban data dalam kelompok untuk latihan untuk mengelakkan limpahan memori. Percepatan dengan GPU: Gunakan kad grafik bebas untuk mempercepatkan proses latihan dan memendekkan masa latihan.
 Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori
May 09, 2024 am 11:10 AM
Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori
May 09, 2024 am 11:10 AM
1. Mula-mula, masukkan pelayar Edge dan klik tiga titik di penjuru kanan sebelah atas. 2. Kemudian, pilih [Sambungan] dalam bar tugas. 3. Seterusnya, tutup atau nyahpasang pemalam yang anda tidak perlukan.
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Pemula AI secara kolektif menukar pekerjaan kepada OpenAI, dan pasukan keselamatan berkumpul semula selepas Ilya pergi!
Jun 08, 2024 pm 01:00 PM
Pemula AI secara kolektif menukar pekerjaan kepada OpenAI, dan pasukan keselamatan berkumpul semula selepas Ilya pergi!
Jun 08, 2024 pm 01:00 PM
Minggu lalu, di tengah gelombang peletakan jawatan dalaman dan kritikan luar, OpenAI dibelenggu oleh masalah dalaman dan luaran: - Pelanggaran kakak balu itu mencetuskan perbincangan hangat global - Pekerja menandatangani "fasal tuan" didedahkan satu demi satu - Netizen menyenaraikan " Ultraman " tujuh dosa maut" ” Pembasmi khabar angin: Menurut maklumat dan dokumen bocor yang diperolehi oleh Vox, kepimpinan kanan OpenAI, termasuk Altman, sangat mengetahui peruntukan pemulihan ekuiti ini dan menandatanganinya. Di samping itu, terdapat isu serius dan mendesak yang dihadapi oleh OpenAI - keselamatan AI. Pemergian lima pekerja berkaitan keselamatan baru-baru ini, termasuk dua pekerjanya yang paling terkemuka, dan pembubaran pasukan "Penjajaran Super" sekali lagi meletakkan isu keselamatan OpenAI dalam perhatian. Majalah Fortune melaporkan bahawa OpenA
 LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
Ditulis di atas & pemahaman peribadi pengarang: Kertas kerja ini didedikasikan untuk menyelesaikan cabaran utama model bahasa besar multimodal semasa (MLLM) dalam aplikasi pemanduan autonomi, iaitu masalah melanjutkan MLLM daripada pemahaman 2D kepada ruang 3D. Peluasan ini amat penting kerana kenderaan autonomi (AV) perlu membuat keputusan yang tepat tentang persekitaran 3D. Pemahaman spatial 3D adalah penting untuk AV kerana ia memberi kesan langsung kepada keupayaan kenderaan untuk membuat keputusan termaklum, meramalkan keadaan masa depan dan berinteraksi dengan selamat dengan alam sekitar. Model bahasa besar berbilang mod semasa (seperti LLaVA-1.5) selalunya hanya boleh mengendalikan input imej resolusi rendah (cth.) disebabkan oleh had resolusi pengekod visual, had panjang jujukan LLM. Walau bagaimanapun, aplikasi pemanduan autonomi memerlukan
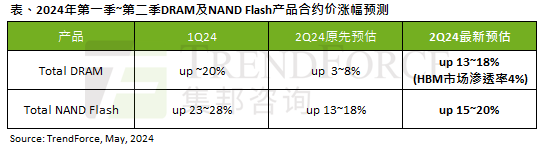 Kesan gelombang AI adalah jelas TrendForce telah menyemak semula ramalannya untuk memori DRAM dan harga kontrak memori kilat NAND meningkat pada suku ini.
May 07, 2024 pm 09:58 PM
Kesan gelombang AI adalah jelas TrendForce telah menyemak semula ramalannya untuk memori DRAM dan harga kontrak memori kilat NAND meningkat pada suku ini.
May 07, 2024 pm 09:58 PM
Menurut laporan tinjauan TrendForce, gelombang AI mempunyai impak yang besar pada memori DRAM dan pasaran memori flash NAND. Dalam berita laman web ini pada 7 Mei, TrendForce berkata dalam laporan penyelidikan terbarunya hari ini bahawa agensi itu telah meningkatkan kenaikan harga kontrak untuk dua jenis produk storan pada suku ini. Secara khusus, TrendForce pada asalnya menganggarkan bahawa harga kontrak memori DRAM pada suku kedua 2024 akan meningkat sebanyak 3~8%, dan kini menganggarkannya pada 13~18% dari segi memori kilat NAND, anggaran asal akan meningkat sebanyak 13~ 18%, dan anggaran baharu ialah 15%. ~20%, hanya eMMC/UFS mempunyai peningkatan yang lebih rendah sebanyak 10%. ▲Sumber imej TrendForce TrendForce menyatakan bahawa agensi itu pada asalnya menjangkakan untuk meneruskan
