
 Peranti teknologi
AI
Bagaimanakah model penyebaran membina ejen pembuat keputusan generasi baharu? Di luar autoregresi, pada masa yang sama menjana trajektori perancangan jujukan yang panjang
Peranti teknologi
AI
Bagaimanakah model penyebaran membina ejen pembuat keputusan generasi baharu? Di luar autoregresi, pada masa yang sama menjana trajektori perancangan jujukan yang panjang
Bagaimanakah model penyebaran membina ejen pembuat keputusan generasi baharu? Di luar autoregresi, pada masa yang sama menjana trajektori perancangan jujukan yang panjang

Bayangkan apabila anda berdiri di dalam bilik dan bersiap untuk berjalan ke arah pintu, adakah anda secara beransur-ansur merancang laluan melalui autoregresi? Sebenarnya, laluan anda dijana secara keseluruhan sekali gus.
Penyelidikan terkini menunjukkan bahawa modul perancangan menggunakan model resapan boleh menjana perancangan trajektori jujukan panjang pada masa yang sama, yang lebih selari dengan pembuatan keputusan manusia. Selain itu, model resapan juga boleh menyediakan penyelesaian yang lebih optimum untuk algoritma risikan membuat keputusan sedia ada dari segi perwakilan dasar dan sintesis data.
Kertas ulasan "Model Penyebaran untuk Pembelajaran Pengukuhan: Satu Tinjauan" yang ditulis oleh pasukan dari Universiti Jiao Tong Shanghai meringkaskan aplikasi model resapan dalam bidang yang berkaitan dengan pembelajaran pengukuhan. Kajian semula menunjukkan bahawa algoritma pembelajaran pengukuhan sedia ada menghadapi cabaran seperti pengumpulan ralat dalam perancangan urutan panjang, keupayaan ekspresi dasar yang terhad, dan data interaktif yang tidak mencukupi Model resapan telah menunjukkan kelebihan dalam menyelesaikan masalah pembelajaran pengukuhan dan telah digunakan untuk menangani perkara di atas masalah. Cabaran yang berpanjangan membawa idea baharu. Pautan kertas: https://arxiv.org/abs/2311.01223

Ini adalah percanggahan yang diperkukuhkan model Peranan dalam pembelajaran dikelaskan, dan kes-kes kejayaan model resapan dalam senario pembelajaran pengukuhan yang berbeza diringkaskan. Akhir sekali, semakan mengharapkan hala tuju pembangunan masa hadapan menggunakan model resapan untuk menyelesaikan masalah pembelajaran pengukuhan.
Angka tersebut menunjukkan peranan model resapan dalam kitaran kolam ulangan ejen-persekitaran-pengalaman klasik. Berbanding dengan penyelesaian tradisional, model resapan memperkenalkan elemen baharu ke dalam sistem dan menyediakan interaksi maklumat dan peluang pembelajaran yang lebih komprehensif. Dengan cara ini, ejen boleh menyesuaikan diri dengan perubahan persekitaran dengan lebih baik dan mengoptimumkan pembuatan keputusannya
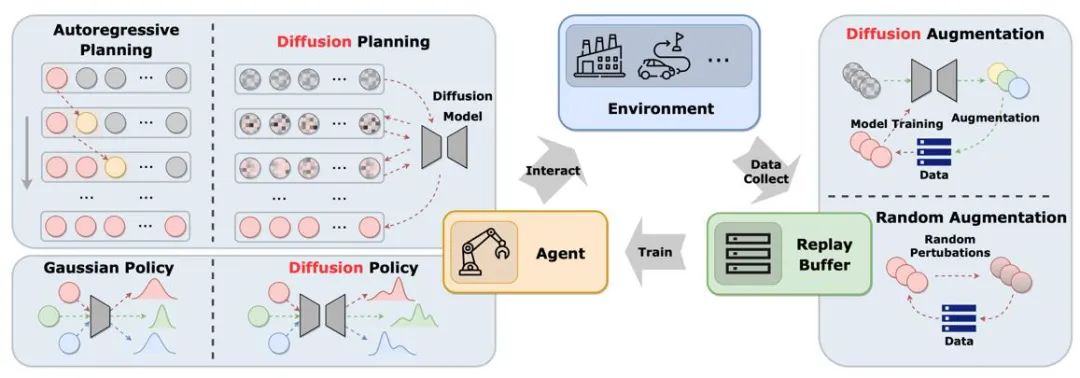 Peranan model resapan dalam pembelajaran peneguhan
Peranan model resapan dalam pembelajaran peneguhan
Artikel dikelaskan mengikut peranan model resapan dalam pembelajaran pengukuhan kaedah aplikasi dan ciri-ciri model resapan dibandingkan.
Rajah 2: Peranan berbeza yang dimainkan oleh model resapan dalam pembelajaran pengukuhan.
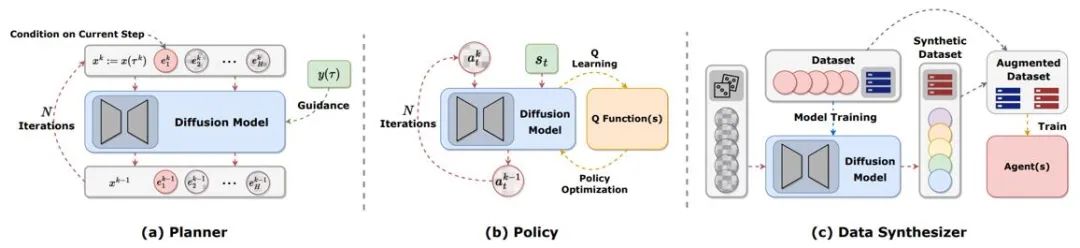
Perancangan dalam pembelajaran pengukuhan merujuk kepada membuat keputusan dalam imaginasi dengan menggunakan model dinamik, dan kemudian memilih tindakan yang sesuai untuk memaksimumkan ganjaran terkumpul. Proses perancangan sering meneroka urutan tindakan dan menyatakan untuk meningkatkan keberkesanan jangka panjang keputusan. Dalam rangka kerja pembelajaran tetulang berasaskan model (MBRL), jujukan perancangan selalunya disimulasikan secara autoregresif, mengakibatkan ralat terkumpul. Model resapan boleh menjana urutan perancangan berbilang langkah secara serentak. Sasaran yang dijana oleh artikel sedia ada menggunakan model penyebaran sangat pelbagai, termasuk (s,a,r), (s,a), hanya s, hanya a, dsb. Untuk menjana trajektori ganjaran tinggi semasa penilaian dalam talian, banyak karya menggunakan teknik pensampelan berpandu dengan atau tanpa pengelas. . Diffusion-QL mula-mula menggabungkan strategi resapan dengan rangka kerja Q-pembelajaran. Oleh kerana model resapan jauh lebih berkeupayaan untuk menyesuaikan taburan berbilang mod daripada model tradisional, strategi resapan berprestasi baik dalam set data berbilang mod yang disampel oleh berbilang strategi tingkah laku. Strategi resapan adalah sama seperti strategi biasa, biasanya menggunakan keadaan sebagai syarat untuk menjana tindakan sambil mempertimbangkan untuk memaksimumkan fungsi Q (s,a). Kaedah seperti Diffusion-QL menambah istilah fungsi nilai wajaran apabila melatih model resapan, manakala CEP membina sasaran regresi berwajaran dari perspektif tenaga dan menggunakan fungsi nilai sebagai faktor untuk melaraskan pengagihan tindakan yang dipelajari oleh model resapan.
Sintesis data
Model penyebaran boleh digunakan sebagai pensintesis data untuk mengurangkan masalah data jarang dalam pembelajaran pengukuhan luar talian atau dalam talian. Kaedah peningkatan data pembelajaran pengukuhan tradisional biasanya hanya boleh mengganggu sedikit data asal, manakala keupayaan pemasangan pengedaran yang berkuasa model resapan membolehkannya mempelajari secara langsung pengedaran keseluruhan set data dan kemudian sampel data berkualiti tinggi baharu.
Jenis lain
Selain kategori di atas, terdapat juga beberapa karya bertaburan menggunakan model resapan dengan cara lain. Sebagai contoh, DVF menganggarkan fungsi nilai menggunakan model resapan. LDCQ mula-mula mengekod trajektori ke dalam ruang terpendam dan kemudian menggunakan model resapan pada ruang terpendam. PolyGRAD menggunakan model resapan untuk memindahkan persekitaran pembelajaran secara dinamik, membenarkan interaksi dasar dan model untuk meningkatkan kecekapan pembelajaran dasar.
Aplikasi dalam masalah berkaitan pembelajaran pengukuhan yang berbeza
Pembelajaran pengukuhan luar talian
Pengenalan model penyebaran membantu strategi pembelajaran pengukuhan luar talian dan strategi pembelajaran pengukuhan pelbagai mod kebolehan. Penyebar pertama kali mencadangkan algoritma penjanaan trajektori ganjaran tinggi berdasarkan panduan pengelas dan mengilhamkan banyak kerja seterusnya. Pada masa yang sama, model resapan juga boleh diaplikasikan dalam senario pembelajaran pengukuhan pelbagai tugas dan pelbagai agen.
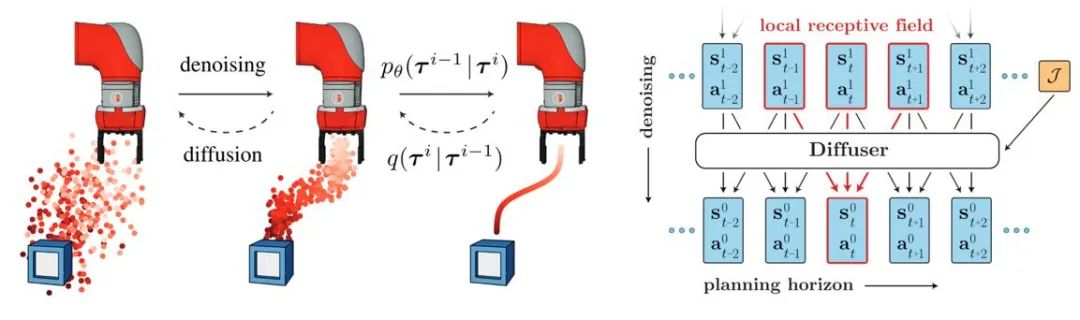
Figure 3: gambarajah skematik proses penjanaan trajektori penyebar dan model penguatkuasaan penguatkuasaan
Penyelaras yang membuktikan bahawa model penyebaran juga mempunyai keupayaan untuk mengoptimumkan fungsi dan strategi nilai dalam pembelajaran pengukuhan dalam talian. Sebagai contoh, DIPO melabel semula data tindakan dan menggunakan latihan model resapan untuk mengelakkan ketidakstabilan latihan berpandukan nilai CPQL telah mengesahkan bahawa model resapan pensampelan satu langkah sebagai strategi boleh mengimbangi penerokaan dan penggunaan semasa interaksi.
Pembelajaran tiruan
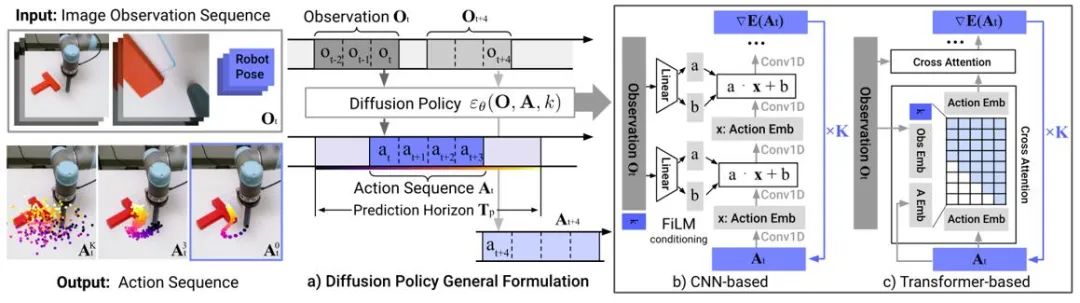
Pembelajaran tiruan membina semula tingkah laku pakar dengan belajar daripada data demonstrasi pakar. Aplikasi model penyebaran membantu meningkatkan keupayaan perwakilan dasar dan mempelajari kemahiran tugas yang pelbagai. Dalam bidang kawalan robot, penyelidikan telah mendapati bahawa model penyebaran boleh meramalkan urutan tindakan gelung tertutup sambil mengekalkan kestabilan temporal. Dasar Resapan menggunakan model resapan input imej untuk menjana urutan tindakan robot. Eksperimen menunjukkan bahawa model resapan boleh menjana urutan tindakan gelung tertutup yang berkesan sambil memastikan ketekalan pemasaan.
Figure 4: Model Dasar Penyebaran Skematik
Trajektori Generasi
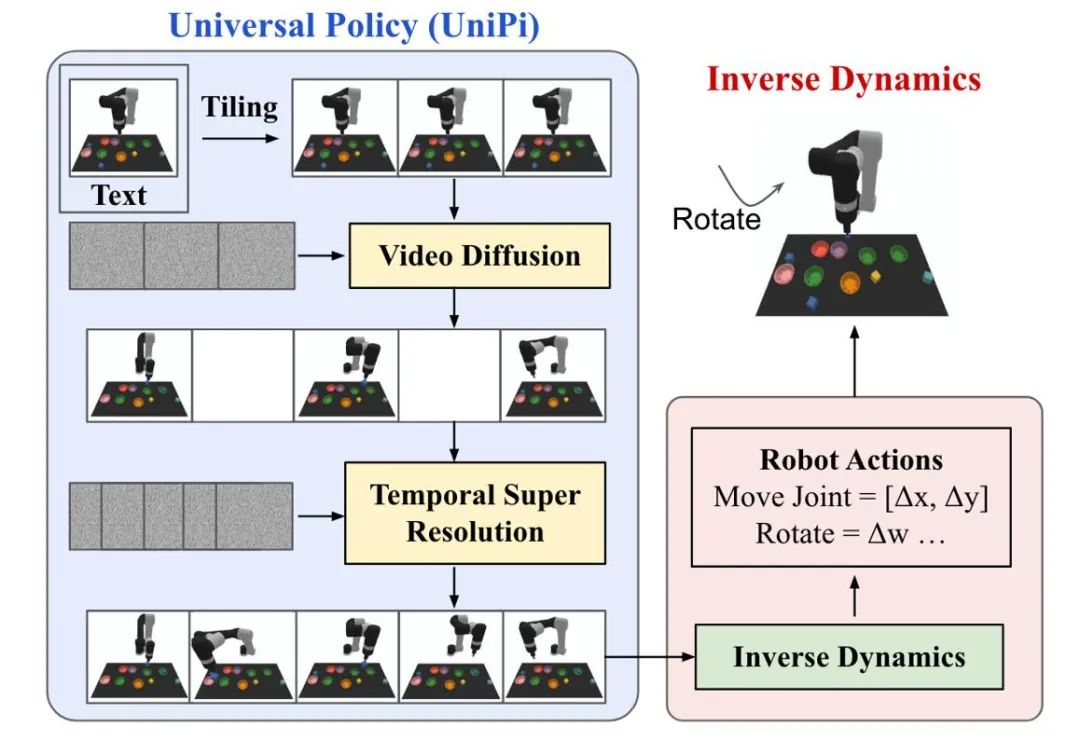
Generasi trajektori model penyebaran dalam pembelajaran tetulang terutamanya memberi tumpuan kepada dua jenis tugas: penjanaan tindakan manusia dan kawalan robot . Data tindakan atau data video yang dijana oleh model resapan digunakan untuk membina simulator simulasi atau melatih model membuat keputusan hiliran. UniPi melatih model penyebaran penjanaan video sebagai strategi umum, dan mencapai kawalan robot merentas badan dengan mengakses model dinamik songsang yang berbeza untuk mendapatkan arahan kawalan asas.
Rajah 5: Gambarajah skematik proses membuat keputusan UniPi.
Peningkatan data
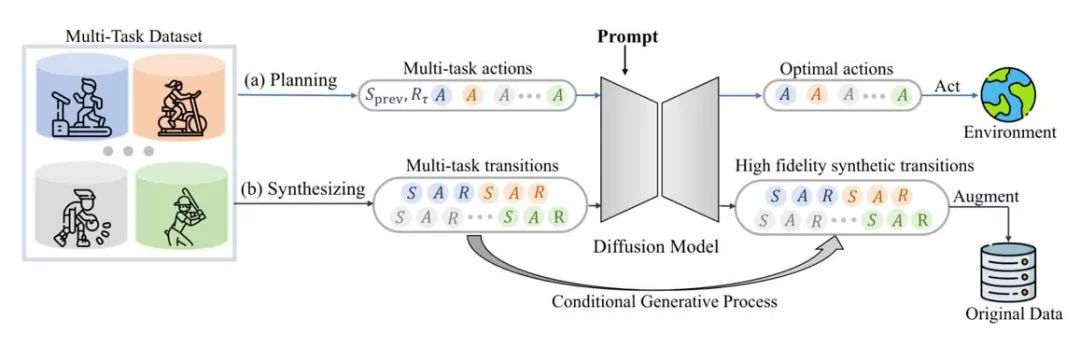
Model penyebaran juga boleh menyesuaikan secara langsung dengan pengedaran data asal, menyediakan pelbagai data yang dikembangkan secara dinamik sambil mengekalkan keaslian. Contohnya, SynthER dan MTDiff-s menjana maklumat pemindahan persekitaran yang lengkap bagi tugas latihan melalui model penyebaran dan menggunakannya pada penambahbaikan dasar, dan keputusan menunjukkan bahawa kepelbagaian dan ketepatan data yang dijana adalah lebih baik daripada kaedah sejarah.
Figure 6: Gambarajah skematik mtdiff untuk perancangan multi-tugas dan peningkatan data
Potor Outlook
Generative Simulation Environment
As ditunjukkan dalam Rajah 1, penyelidikan sedia ada terutamanya Model resapan digunakan untuk mengatasi batasan ejen dan mengalami kumpulan main semula, dan terdapat sedikit kajian tentang menggunakan model resapan untuk meningkatkan persekitaran simulasi. Gen2Sim menggunakan model penyebaran graf Vincentian untuk menjana objek boleh manipulasi yang pelbagai dalam persekitaran simulasi untuk meningkatkan keupayaan generalisasi operasi robot ketepatan. Model resapan juga mempunyai potensi untuk menjana fungsi peralihan keadaan, fungsi ganjaran atau tingkah laku musuh dalam interaksi berbilang ejen dalam persekitaran simulasi.
Tambahkan kekangan keselamatan
Dengan menggunakan kekangan keselamatan sebagai syarat pensampelan model, ejen berdasarkan model resapan boleh membuat keputusan yang memenuhi kekangan tertentu. Persampelan berpandu model resapan membolehkan kekangan keselamatan baharu ditambah secara berterusan dengan mempelajari pengelas tambahan, manakala parameter model asal kekal tidak berubah, sekali gus menjimatkan overhed latihan tambahan.
Penjanaan yang dipertingkatkan semula
Teknologi penjanaan dipertingkatkan semula boleh meningkatkan keupayaan model dengan mengakses set data luaran dan digunakan secara meluas dalam model bahasa besar. Prestasi model keputusan berasaskan resapan di negeri ini juga boleh dipertingkatkan dengan mendapatkan semula trajektori yang berkaitan dengan keadaan semasa ejen dan memasukkannya ke dalam model. Jika set data perolehan sentiasa dikemas kini, ejen mungkin mempamerkan tingkah laku baharu tanpa dilatih semula.
Menggabungkan pelbagai kemahiran
Digabungkan dengan bimbingan pengelas atau tiada bimbingan pengelas, model resapan boleh menggabungkan berbilang kemahiran mudah untuk menyelesaikan tugasan yang kompleks. Keputusan awal dalam pembelajaran peneguhan luar talian juga mencadangkan bahawa model resapan boleh berkongsi pengetahuan antara kemahiran yang berbeza, menjadikannya mungkin untuk mencapai pemindahan pukulan sifar atau pembelajaran berterusan dengan menggabungkan kemahiran yang berbeza.
Jadual
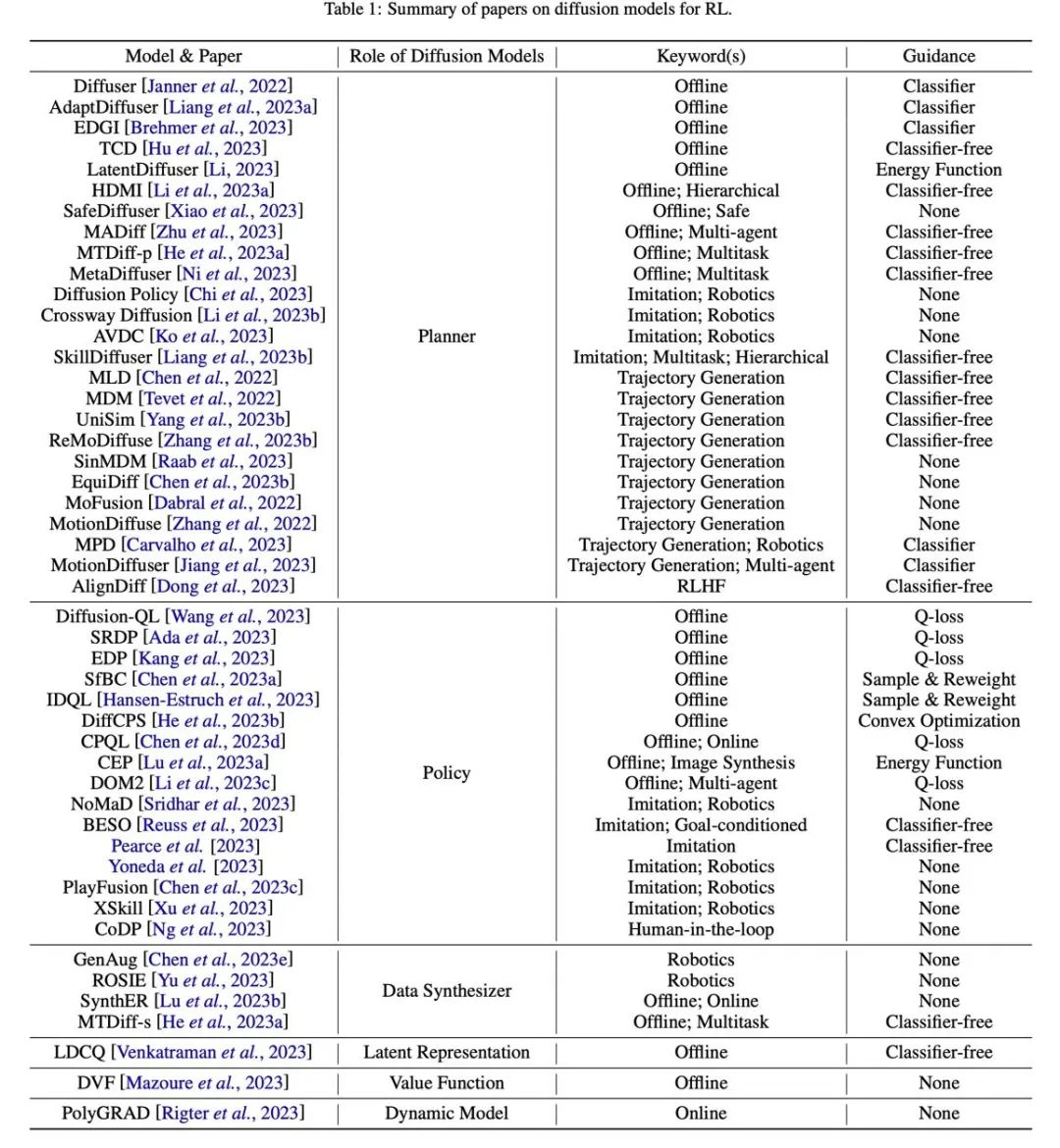
Rajah 7: Ringkasan dan jadual klasifikasi kertas berkaitan.
Atas ialah kandungan terperinci Bagaimanakah model penyebaran membina ejen pembuat keputusan generasi baharu? Di luar autoregresi, pada masa yang sama menjana trajektori perancangan jujukan yang panjang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 Pengenalan kepada cara menggunakan simulator joiplay
May 04, 2024 pm 06:40 PM
Pengenalan kepada cara menggunakan simulator joiplay
May 04, 2024 pm 06:40 PM
Simulator jojplay ialah simulator telefon mudah alih yang sangat mudah digunakan Ia menyokong permainan komputer untuk dijalankan pada telefon mudah alih dan mempunyai keserasian yang sangat baik Beberapa pemain tidak tahu cara menggunakannya . Cara menggunakan simulator joiplay 1. Mula-mula, anda perlu memuat turun pemalam Joiplay body dan RPGM Sebaik-baiknya pasangkannya mengikut urutan pemalam badan Pakej apk boleh didapati di bar Joiplay (klik untuk mendapatkan >>>). 2. Selepas Android selesai, anda boleh menambah permainan di sudut kiri bawah. 3. Isikan nama secara santai, dan tekan CHOOSE pada executablefile untuk memilih fail game.exe permainan. 4. Ikon boleh dibiarkan kosong atau anda boleh memilih gambar kegemaran anda.
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Panduan Simulator Hidup Semula
May 07, 2024 pm 05:28 PM
Panduan Simulator Hidup Semula
May 07, 2024 pm 05:28 PM
Life Restart Simulator adalah permainan simulasi yang sangat menarik Permainan ini telah menjadi sangat popular baru-baru ini strategi ada? Panduan Panduan Simulator Hidup Semula Ciri-ciri Simulator Mulakan Semula Kehidupan Ini adalah permainan yang sangat kreatif di mana pemain boleh bermain mengikut idea mereka sendiri. Terdapat banyak tugas yang perlu diselesaikan setiap hari, dan anda boleh menikmati kehidupan baru di dunia maya ini. Terdapat banyak lagu dalam permainan, dan semua jenis kehidupan yang berbeza sedang menunggu untuk anda alami. Hidup Semula Simulator Kandungan Permainan Kad Lukisan Bakat: Bakat: Anda mesti memilih kotak kecil misteri untuk menjadi abadi. Pelbagai kapsul kecil tersedia untuk mengelak daripada mati di tengah jalan. Cthulhu boleh memilih
 Pengenalan kepada kaedah tetapan fon simulator joiplay
May 09, 2024 am 08:31 AM
Pengenalan kepada kaedah tetapan fon simulator joiplay
May 09, 2024 am 08:31 AM
Simulator jojplay sebenarnya boleh menyesuaikan fon permainan, dan boleh menyelesaikan masalah kehilangan aksara dan aksara berkotak dalam teks Saya rasa ramai pemain masih tidak tahu cara mengendalikannya fon simulator jojplay. Cara menetapkan fon simulator joiplay 1. Mula-mula buka simulator joiplay, klik pada tetapan (tiga titik) di sudut kanan atas, dan cari. 2. Dalam lajur RPGMSettings, klik untuk memilih fon tersuai CustomFont dalam baris ketiga. 3. Pilih fail fon dan klik OK Berhati-hati untuk tidak mengklik ikon "Simpan" di sudut kanan bawah, jika tidak tetapan lalai akan dipulihkan. 4. Pengasas dan Quasi-Yuan aksara Cina ringkas disyorkan (sudah dalam folder permainan Fuxing dan Rebirth). joi
 Bagaimana untuk memadam aplikasi simulator guruh dan kilat? -Bagaimana untuk memadam aplikasi dalam Simulator Thunderbolt?
May 08, 2024 pm 02:40 PM
Bagaimana untuk memadam aplikasi simulator guruh dan kilat? -Bagaimana untuk memadam aplikasi dalam Simulator Thunderbolt?
May 08, 2024 pm 02:40 PM
Versi rasmi Thunderbolt Simulator ialah alat emulator Android yang sangat profesional. Jadi bagaimana untuk memadam aplikasi simulator guruh dan kilat? Bagaimana untuk memadam aplikasi dalam Simulator Thunderbolt? Biarkan editor memberi anda jawapan di bawah! Bagaimana untuk memadam aplikasi simulator guruh dan kilat? 1. Klik dan tahan ikon apl yang ingin anda padamkan. 2. Tunggu sebentar sehingga pilihan untuk menyahpasang atau memadam aplikasi muncul. 3. Seret apl ke pilihan nyahpasang. 4. Dalam tetingkap pengesahan yang muncul, klik OK untuk menyelesaikan pemadaman aplikasi.
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Baru-baru ini, bulatan tentera telah terharu dengan berita: jet pejuang tentera AS kini boleh melengkapkan pertempuran udara automatik sepenuhnya menggunakan AI. Ya, baru-baru ini, jet pejuang AI tentera AS telah didedahkan buat pertama kali, mendedahkan misterinya. Nama penuh pesawat pejuang ini ialah Variable Stability Simulator Test Aircraft (VISTA). Ia diterbangkan sendiri oleh Setiausaha Tentera Udara AS untuk mensimulasikan pertempuran udara satu lawan satu. Pada 2 Mei, Setiausaha Tentera Udara A.S. Frank Kendall berlepas menggunakan X-62AVISTA di Pangkalan Tentera Udara Edwards Ambil perhatian bahawa semasa penerbangan selama satu jam, semua tindakan penerbangan telah diselesaikan secara autonomi oleh AI! Kendall berkata - "Sejak beberapa dekad yang lalu, kami telah memikirkan tentang potensi tanpa had pertempuran udara-ke-udara autonomi, tetapi ia sentiasa kelihatan di luar jangkauan." Namun kini,
