
 Peranti teknologi
AI
Menggunakan video pendek AI untuk 'memberi maklum balas' pemahaman video yang panjang, rangka kerja MovieLLM Tencent menyasarkan penjanaan bingkai berterusan peringkat filem
Peranti teknologi
AI
Menggunakan video pendek AI untuk 'memberi maklum balas' pemahaman video yang panjang, rangka kerja MovieLLM Tencent menyasarkan penjanaan bingkai berterusan peringkat filem
Menggunakan video pendek AI untuk 'memberi maklum balas' pemahaman video yang panjang, rangka kerja MovieLLM Tencent menyasarkan penjanaan bingkai berterusan peringkat filem

Dalam bidang pemahaman video, walaupun model berbilang modal telah membuat kejayaan dalam analisis video pendek dan menunjukkan keupayaan pemahaman yang kukuh, mereka kelihatan tidak berkuasa apabila berhadapan dengan video panjang peringkat filem. Oleh itu, analisis dan pemahaman video panjang, terutamanya pemahaman kandungan filem berjam-jam, telah menjadi cabaran besar hari ini.
Kesukaran model dalam memahami video panjang terutamanya berpunca daripada kekurangan sumber data video yang panjang, yang mempunyai kecacatan dalam kualiti dan kepelbagaian. Selain itu, mengumpul dan melabelkan data ini memerlukan banyak kerja.
Menghadapi masalah sedemikian, pasukan penyelidik dari Tencent dan Universiti Fudan mencadangkan MovieLLM, rangka kerja penjanaan AI yang inovatif. MovieLLM mengguna pakai kaedah inovatif yang bukan sahaja menjana data video yang berkualiti tinggi dan pelbagai, tetapi juga secara automatik menjana sejumlah besar set data soal jawab yang berkaitan, memperkayakan dimensi dan kedalaman data, dan keseluruhan proses automatik juga sangat Dadi mengurangkan pelaburan manusia.

- Alamat kertas: https://arxiv.org/abs/2403.01422
- Alamat halaman utama: https://deaddawn Perkembangan penting ini bukan sahaja meningkatkan pemahaman model tentang naratif video yang kompleks, tetapi juga meningkatkan keupayaan analisis model apabila memproses kandungan filem selama berjam-jam. Pada masa yang sama, ia mengatasi batasan kekurangan dan berat sebelah set data sedia ada dan menyediakan cara baharu dan berkesan untuk memahami kandungan video ultra panjang.
MovieLLM dengan bijak menggunakan keupayaan penjanaan berkuasa GPT-4 dan model resapan, dan menggunakan strategi penjanaan penerangan bingkai berterusan "mengembangkan cerita". Kaedah "penyongsangan tekstual" digunakan untuk membimbing model resapan untuk menghasilkan imej adegan yang konsisten dengan penerangan teks, dengan itu mencipta bingkai berterusan bagi filem lengkap.
 Gambaran Keseluruhan Kaedah
Gambaran Keseluruhan Kaedah
MovieLLM menggabungkan GPT-4 dan model resapan untuk meningkatkan pemahaman model besar tentang video panjang. Gabungan pintar ini menghasilkan data video panjang yang berkualiti tinggi dan pelbagai serta soal jawab QA, membantu mempertingkatkan keupayaan generatif model.
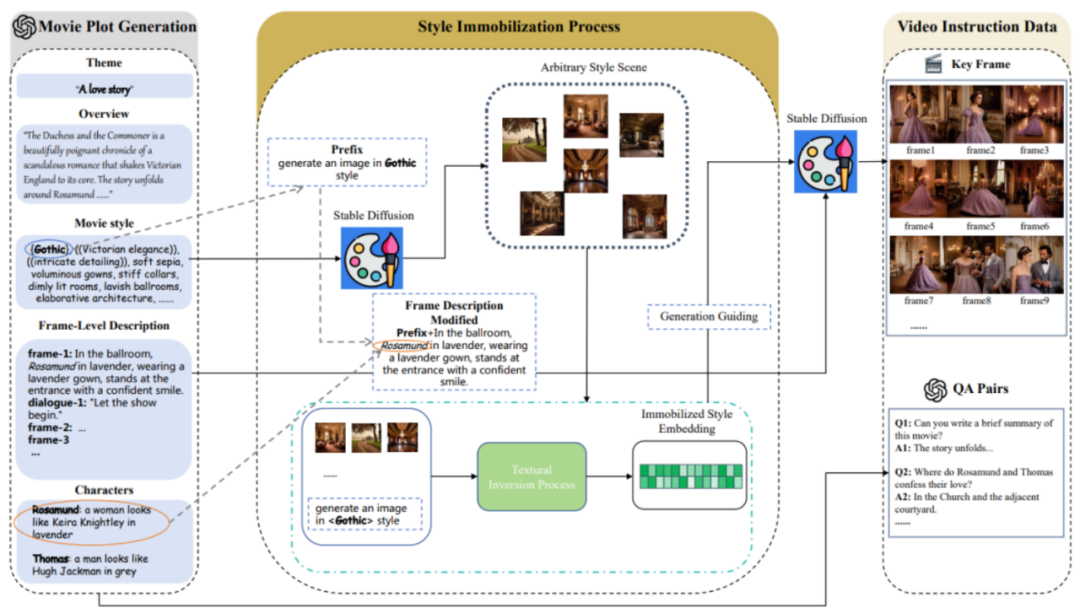 MovieLLM terutamanya merangkumi tiga peringkat:
MovieLLM terutamanya merangkumi tiga peringkat:
1.
MovieLLM tidak bergantung pada web atau set data sedia ada untuk menjana plot, sebaliknya memanfaatkan sepenuhnya kuasa GPT-4 untuk menghasilkan data sintetik. Dengan menyediakan elemen khusus seperti tema, gambaran keseluruhan dan gaya, GPT-4 dibimbing untuk menghasilkan perihalan rangka utama sinematik yang disesuaikan dengan proses penjanaan seterusnya.
2.
MovieLLM bijak menggunakan teknologi "inversi tekstual" untuk membetulkan perihalan gaya yang dijana dalam skrip ke ruang terpendam model resapan. Kaedah ini membimbing model untuk menghasilkan adegan dengan gaya tetap dan mengekalkan kepelbagaian sambil mengekalkan estetika bersatu.
3.
Berdasarkan dua langkah pertama, pembenaman gaya tetap dan penerangan rangka utama telah diperolehi. Berdasarkan ini, MovieLLM menggunakan pembenaman gaya untuk membimbing model resapan untuk menjana bingkai utama yang mematuhi huraian bingkai utama dan secara beransur-ansur menjana pelbagai pasangan soalan dan jawapan pengajaran mengikut plot filem.
 Selepas langkah di atas, MovieLLM mencipta gaya yang berkualiti tinggi, pelbagai, bingkai filem yang koheren dan data pasangan soalan dan jawapan yang sepadan. Pengedaran terperinci jenis data filem adalah seperti berikut:
Selepas langkah di atas, MovieLLM mencipta gaya yang berkualiti tinggi, pelbagai, bingkai filem yang koheren dan data pasangan soalan dan jawapan yang sepadan. Pengedaran terperinci jenis data filem adalah seperti berikut:
Hasil eksperimen
Dengan menggunakan data yang dibina berdasarkan MovieLLM untuk penalaan halus pada LLaMA-VID, model besar yang memfokuskan pada pemahaman video yang panjang, kertas kerja ini meningkatkan keupayaan model untuk memahami kandungan video pelbagai panjang dengan ketara. Untuk pemahaman video yang panjang, pada masa ini tiada kerja yang mencadangkan penanda aras ujian, jadi artikel ini juga mencadangkan penanda aras untuk menguji keupayaan pemahaman video yang panjang.
Walaupun MovieLLM tidak secara khusus membina data video pendek untuk latihan, melalui latihan, peningkatan prestasi pada pelbagai penanda aras video pendek masih diperhatikan:
Dalam MSVD-QA dan MSRVTT- Berbanding dengan. model asas, QA telah bertambah baik dengan ketara pada kedua-dua set data ujian ini.

Pada penanda aras prestasi berasaskan penjanaan video, peningkatan prestasi dicapai dalam kelima-lima bidang penilaian.
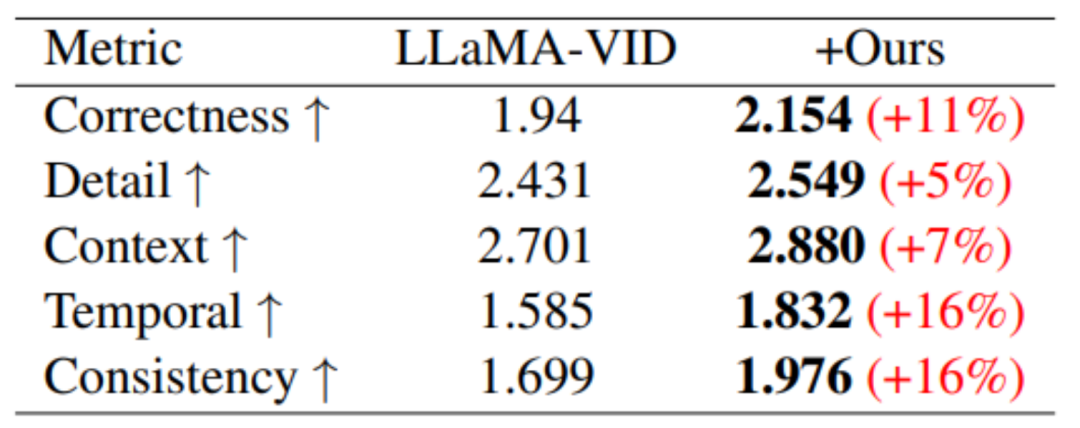
Dari segi pemahaman video yang panjang, melalui latihan MovieLLM, pemahaman model tentang ringkasan, plot dan pemasaan telah dipertingkatkan dengan ketara.

Selain itu, MovieLLM juga mempunyai hasil yang lebih baik dari segi kualiti penjanaan berbanding kaedah penjanaan imej gaya tetap yang serupa.
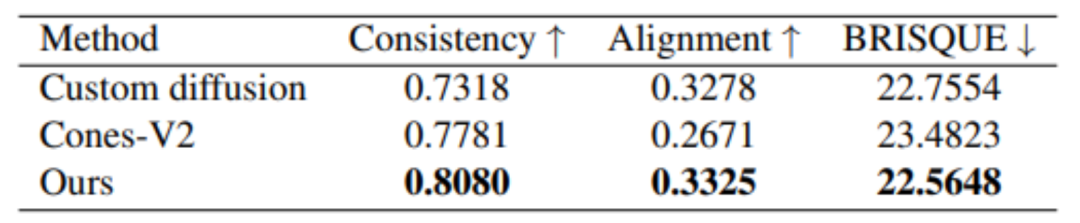
Ringkasnya, aliran kerja penjanaan data yang dicadangkan oleh MovieLLM mengurangkan dengan ketara cabaran untuk menghasilkan data video peringkat filem untuk model dan meningkatkan kawalan dan kepelbagaian kandungan yang dijana. Pada masa yang sama, MovieLLM dengan ketara meningkatkan keupayaan model berbilang modal untuk memahami video panjang peringkat filem, memberikan rujukan berharga untuk bidang lain untuk menggunakan kaedah penjanaan data yang serupa.
Pembaca yang berminat dengan penyelidikan ini boleh membaca teks asal kertas untuk mengetahui lebih lanjut tentang kandungan penyelidikan.
Atas ialah kandungan terperinci Menggunakan video pendek AI untuk 'memberi maklum balas' pemahaman video yang panjang, rangka kerja MovieLLM Tencent menyasarkan penjanaan bingkai berterusan peringkat filem. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Artikel ini menerangkan cara menyesuaikan tahap pembalakan pelayan Apacheweb dalam sistem Debian. Dengan mengubah suai fail konfigurasi, anda boleh mengawal tahap maklumat log yang direkodkan oleh Apache. Kaedah 1: Ubah suai fail konfigurasi utama untuk mencari fail konfigurasi: Fail konfigurasi apache2.x biasanya terletak di direktori/etc/apache2/direktori. Nama fail mungkin apache2.conf atau httpd.conf, bergantung pada kaedah pemasangan anda. Edit Fail Konfigurasi: Buka Fail Konfigurasi dengan Kebenaran Root Menggunakan Editor Teks (seperti Nano): Sudonano/ETC/APACHE2/APACHE2.CONF
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Menguruskan Log Hadoop pada Debian, anda boleh mengikuti langkah-langkah berikut dan amalan terbaik: Agregasi log membolehkan pengagregatan log: tetapkan benang.log-agregasi-enable untuk benar dalam fail benang-site.xml untuk membolehkan pengagregatan log. Konfigurasikan dasar pengekalan log: tetapkan yarn.log-aggregasi.Retain-seconds Untuk menentukan masa pengekalan log, seperti 172800 saat (2 hari). Nyatakan Laluan Penyimpanan Log: Melalui Benang
