
 Peranti teknologi
AI
Penyelidikan baharu Google tentang kecerdasan yang terkandung: RT-H, yang lebih baik daripada RT-2, ada di sini
Peranti teknologi
AI
Penyelidikan baharu Google tentang kecerdasan yang terkandung: RT-H, yang lebih baik daripada RT-2, ada di sini
Penyelidikan baharu Google tentang kecerdasan yang terkandung: RT-H, yang lebih baik daripada RT-2, ada di sini

Memandangkan model bahasa besar seperti GPT-4 semakin disepadukan dengan robotik, kecerdasan buatan secara beransur-ansur bergerak ke dunia nyata. Oleh itu, penyelidikan yang berkaitan dengan kecerdasan yang terkandung juga telah menarik perhatian lebih banyak. Di antara banyak projek penyelidikan, siri robot "RT" Google sentiasa berada di barisan hadapan dan trend ini telah mula berkembang pesat baru-baru ini (lihat "Model Besar Sedang Membina Semula Robot, Bagaimana Google Deepmind Mentakrifkan Kecerdasan Terwujud di Masa Depan" untuk butiran).

Pada Julai tahun lalu, Google DeepMind melancarkan RT-2, model pertama di dunia yang mampu mengawal robot untuk interaksi visual-language-action (VLA). Hanya dengan memberi arahan dalam cara perbualan, RT-2 boleh mengenal pasti Swift dalam sejumlah besar gambar dan menghantar setin Coke kepadanya.
Kini, robot ini telah berkembang semula. Versi terkini robot RT dipanggil "RT-H". Ia boleh meningkatkan ketepatan pelaksanaan tugas dan kecekapan pembelajaran dengan menguraikan tugasan yang kompleks kepada arahan bahasa mudah dan kemudian menukar arahan ini kepada tindakan robot. Sebagai contoh, diberi tugasan, seperti "meletakkan penutup pada balang pistachio" dan imej pemandangan, RT-H akan menggunakan model bahasa visual (VLM) untuk meramalkan tindakan bahasa (gerakan), seperti "gerakkan lengan ke hadapan. " dan "Putar lengan ke kanan", dan kemudian ramalkan tindakan robot berdasarkan tindakan lisan ini.

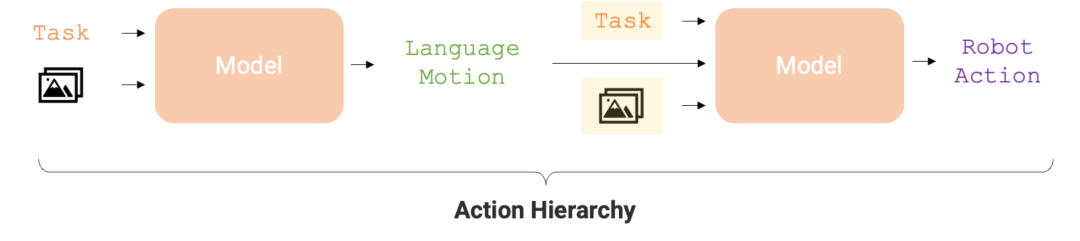
Tahap tindakan adalah penting untuk mengoptimumkan ketepatan dan kecekapan pembelajaran pelaksanaan tugas robot. Struktur hierarki ini menjadikan RT-H berprestasi lebih baik daripada RT-2 dalam pelbagai tugas robot, menyediakan laluan pelaksanaan yang lebih cekap untuk robot.

Berikut ialah butiran kertas tersebut. Pautan org/pdf/ 2403.01823 .pdf
Pautan projek: https://rt-hierarchy.github.io/
 Bahasa ialah enjin penaakulan manusia, yang membolehkan kita memecahkan konsep yang kompleks kepada komponen yang lebih mudah , salah faham kita, dan generalisasi konsep dalam konteks baharu. Dalam beberapa tahun kebelakangan ini, robot juga telah mula menggunakan struktur bahasa yang cekap dan gabungan untuk memecahkan konsep peringkat tinggi, menyediakan pembetulan bahasa, atau mencapai generalisasi dalam persekitaran baharu.
Bahasa ialah enjin penaakulan manusia, yang membolehkan kita memecahkan konsep yang kompleks kepada komponen yang lebih mudah , salah faham kita, dan generalisasi konsep dalam konteks baharu. Dalam beberapa tahun kebelakangan ini, robot juga telah mula menggunakan struktur bahasa yang cekap dan gabungan untuk memecahkan konsep peringkat tinggi, menyediakan pembetulan bahasa, atau mencapai generalisasi dalam persekitaran baharu.
- Kajian ini biasanya mengikut paradigma biasa: berdepan dengan tugas peringkat tinggi yang diterangkan dalam bahasa (seperti "ambil tin Coke"), mereka mempelajari strategi untuk memetakan pemerhatian dan penerangan tugas dalam bahasa kepada robot peringkat rendah actions , yang perlu dicapai melalui set data berbilang tugas berskala besar. Kelebihan bahasa dalam senario ini ialah ia mengekodkan struktur yang dikongsi antara tugasan yang serupa (cth., "ambil tin Coke" lwn. "angkat epal"), sekali gus mengurangkan data yang diperlukan untuk mempelajari pemetaan daripada tugasan kepada tindakan. Walau bagaimanapun, apabila tugasan menjadi lebih pelbagai, bahasa yang digunakan untuk menerangkan setiap tugasan juga menjadi lebih pelbagai (cth., "Ambil tin Coke" berbanding "isi segelas air"), menjadikan pembelajaran antara tugasan yang berbeza semata-mata melalui bahasa peringkat tinggi Ia menjadi lebih sukar untuk berkongsi struktur antara Untuk mempelajari tugasan yang pelbagai, penyelidik menyasarkan untuk menangkap persamaan antara tugasan ini dengan lebih tepat.
- Mereka mendapati bahawa bahasa bukan sahaja boleh menerangkan tugasan peringkat tinggi, tetapi juga menerangkan secara terperinci cara menyelesaikan tugasan - perwakilan jenis ini lebih halus dan lebih dekat dengan tindakan tertentu. Sebagai contoh, tugas "mengambil tin Coke" boleh dipecahkan kepada beberapa langkah yang lebih terperinci, iaitu "gerakan bahasa": pertama "mencapai lengan ke hadapan", kemudian "menggenggam tin", dan akhirnya "mengangkat lengan ke atas" ”. Wawasan teras penyelidik ialah dengan menggunakan tindakan lisan sebagai lapisan perantaraan yang menghubungkan perihalan tugas peringkat tinggi dan tindakan peringkat rendah, tindakan tersebut boleh digunakan untuk membina hierarki tindakan yang dibentuk melalui tindakan lisan.
- Terdapat beberapa faedah untuk mewujudkan tahap tindakan ini:
- Ia membolehkan perkongsian data yang lebih baik pada tahap tindakan bahasa antara tugasan yang berbeza, membolehkan gabungan tindakan bahasa dan generalisasi dalam set data berbilang tugas dipertingkatkan. Sebagai contoh, walaupun "tuang segelas air" dan "angkat tin Coke" berbeza secara semantik, tindakan lisan mereka adalah sama sehingga mereka dilaksanakan untuk mengambil objek.
- Tindakan bahasa bukanlah primitif tetap yang mudah, tetapi dipelajari melalui arahan dan pemerhatian visual berdasarkan spesifik tugas dan adegan semasa. Contohnya, "jangkau tangan ke hadapan" tidak menyatakan kelajuan atau arah pergerakan, yang bergantung pada tugas dan pemerhatian tertentu. Pergantungan konteks dan fleksibiliti tindakan lisan yang dipelajari memberi kita keupayaan baharu: membenarkan orang ramai membuat pengubahsuaian kepada tindakan lisan apabila strategi tidak berjaya 100% (lihat kawasan jingga dalam Rajah 1). Selanjutnya, robot juga boleh belajar daripada pembetulan manusia ini. Sebagai contoh, semasa menjalankan tugas "mengambil tin Coke", jika robot menutup pencengkam terlebih dahulu, kita boleh mengarahkannya untuk "memastikan lengan dipanjangkan ke hadapan lebih lama". hanya mudah untuk bimbingan manusia, dan lebih mudah untuk robot belajar.

Memandangkan kelebihan tindakan bahasa di atas, penyelidik dari Google DeepMind mereka bentuk rangka kerja hujung ke hujung - RT-H (Pengubah Robot dengan Hierarki Tindakan, iaitu Transformer robot menggunakan tahap tindakan) , memfokuskan untuk mempelajari tahap tindakan ini. RT-H memahami cara melaksanakan tugas pada tahap terperinci dengan menganalisis pemerhatian dan huraian tugas peringkat tinggi untuk meramalkan arahan tindakan lisan semasa. Kemudian, menggunakan pemerhatian, tugasan dan tindakan lisan yang disimpulkan ini, RT-H meramalkan tindakan yang sepadan untuk setiap langkah Tindakan lisan menyediakan konteks tambahan dalam proses untuk membantu meramalkan tindakan tertentu dengan lebih tepat (kawasan ungu dalam Rajah 1).
Selain itu, mereka membangunkan kaedah automatik untuk mengekstrak set tindakan bahasa yang dipermudahkan daripada proprioception robot, membina pangkalan data yang kaya dengan lebih daripada 2500 tindakan bahasa tanpa memerlukan anotasi manual. Seni bina model
RT-H menggunakan RT-2, yang merupakan model bahasa visual berskala besar (VLM) yang dilatih bersama mengenai data visual dan bahasa berskala Internet untuk meningkatkan kesan pembelajaran dasar. RT-H menggunakan model tunggal untuk mengendalikan kedua-dua tindakan bahasa dan pertanyaan tindakan, memanfaatkan pengetahuan berskala internet yang meluas untuk menggerakkan setiap peringkat hierarki tindakan.
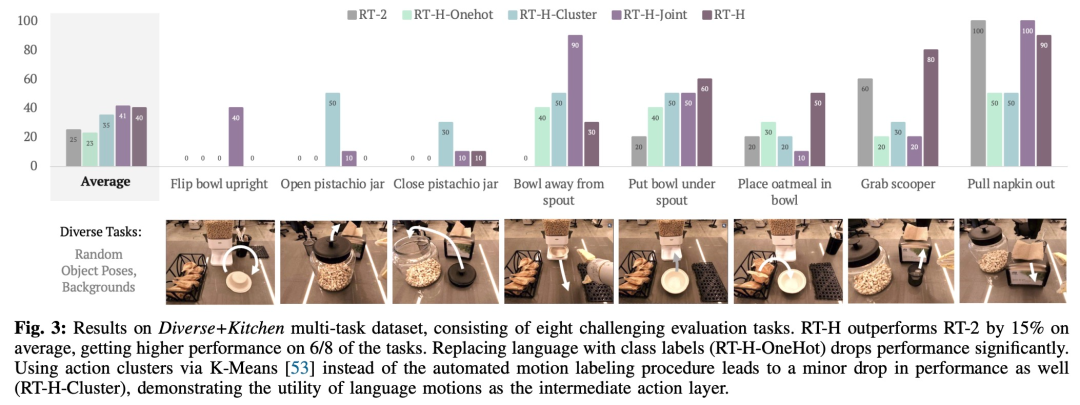
Dalam eksperimen, penyelidik mendapati bahawa menggunakan hierarki tindakan bahasa boleh membawa peningkatan yang ketara apabila memproses set data berbilang tugas yang pelbagai, meningkatkan prestasi sebanyak 15% pada julat tugas berbanding RT-2. Mereka juga mendapati bahawa mengubah suai pergerakan pertuturan menghasilkan kadar kejayaan yang hampir sempurna pada tugas yang sama, menunjukkan fleksibiliti dan kebolehsuaian situasi pergerakan pertuturan yang dipelajari. Tambahan pula, dengan memperhalusi model untuk intervensi tindakan bahasa, prestasinya melebihi kaedah pembelajaran tiruan interaktif SOTA (seperti IWR) sebanyak 50%. Akhirnya, mereka membuktikan bahawa tindakan bahasa dalam RT-H boleh menyesuaikan diri dengan perubahan adegan dan objek dengan lebih baik, menunjukkan prestasi generalisasi yang lebih baik daripada RT-2.
RT-H Architecture Terperinci
Untuk menangkap struktur dikongsi dengan berkesan merentas set data berbilang tugas (tidak diwakili oleh huraian tugas peringkat tinggi), RT-H bertujuan untuk belajar mengeksploitasi dasar peringkat tindakan secara eksplisit.
Secara khusus, pasukan penyelidik memperkenalkan lapisan ramalan tindakan bahasa perantaraan ke dalam pembelajaran dasar. Tindakan linguistik yang menerangkan tingkah laku terperinci robot boleh menangkap maklumat berguna daripada set data berbilang tugas dan boleh menjana dasar berprestasi tinggi. Tindakan lisan boleh dimainkan semula apabila dasar yang dipelajari sukar dilaksanakan: ia menyediakan antara muka intuitif untuk pembetulan manusia dalam talian yang berkaitan dengan senario tertentu. Dasar yang dilatih tentang tindakan pertuturan secara semula jadi boleh mengikut pembetulan manusia peringkat rendah dan berjaya menyelesaikan tugasan yang diberikan data pembetulan. Tambahan pula, strategi ini juga boleh dilatih mengenai data yang diperbetulkan bahasa dan seterusnya meningkatkan prestasinya.
Seperti yang ditunjukkan dalam Rajah 2, RT-H mempunyai dua peringkat utama: pertama meramalkan tindakan lisan berdasarkan penerangan tugasan dan pemerhatian visual, dan kemudian membuat kesimpulan tindakan tepat berdasarkan tindakan lisan yang diramalkan, tugasan khusus dan hasil pemerhatian.
RT-H menggunakan rangkaian tulang belakang VLM dan mengikuti proses latihan RT-2 untuk instantiasi. Sama seperti RT-2, RT-H memanfaatkan pengetahuan terdahulu yang luas dalam bahasa semula jadi dan pemprosesan imej daripada data berskala Internet melalui latihan kolaboratif. Untuk memasukkan pengetahuan terdahulu ini ke dalam semua peringkat hierarki tindakan, model tunggal mempelajari tindakan lisan dan pertanyaan tindakan secara serentak.
Hasil eksperimen
Untuk menilai secara menyeluruh prestasi RT-H, pasukan penyelidik menetapkan empat soalan eksperimen utama:
- S1 (Prestasi): Berapa tahap tindakan dengan bahasa dipertingkatkan? Prestasi dasar pada set data tugas?
- S2 (Situasi): Adakah tindakan bahasa yang dipelajari oleh RT-H berkaitan dengan konteks tugas dan adegan?
- Q3 (Pembetulan): Adakah latihan mengenai pembetulan pergerakan pertuturan lebih baik daripada pembetulan teleoperasi?
- S4 (Ringkasan): Bolehkah hierarki tindakan meningkatkan keteguhan dalam tetapan luar pengedaran?
Dari segi set data, kajian ini menggunakan set data pelbagai tugas yang besar mengandungi 100,000 sampel demonstrasi dengan pose dan latar belakang objek rawak. Set data ini menggabungkan set data berikut:
- Kitchen: set data yang digunakan oleh RT-1 dan RT-2, yang terdiri daripada 6 kategori tugasan semantik daripada 70K sampel.
- Pelbagai: Set data baharu yang terdiri daripada tugasan yang lebih kompleks, dengan lebih daripada 24 kategori tugasan semantik, tetapi hanya 30K sampel.
Kajian ini memanggil set data gabungan ini set data Diverse+Kitchen (D+K) dan menggunakan atur cara automatik untuk melabelkannya untuk tindakan lisan. Untuk menilai prestasi RT-H yang dilatih pada set data Diverse+Kitchen penuh, kajian itu menilai lapan tugas khusus, termasuk:
1) Meletakkan mangkuk tegak di atas kaunter
2) Buka balang pistachio 3) Tutup balang pistachio
7) Dapatkan sudu dari bakul
8) Tarik napkin dari dispenser
Lapan tugasan ini dipilih kerana ia memerlukan urutan pergerakan yang kompleks dan ketepatan yang tinggi.
Jadual di bawah memberikan MSE minimum untuk pusat pemeriksaan latihan RT-H, RT-H-Joint dan RT-2 apabila berlatih pada set data Diverse+Kitchen atau set data Dapur. MSE RT-H adalah lebih kurang 20% lebih rendah daripada RT-2, dan MSE RTH-Joint adalah 5-10% lebih rendah daripada RT-2, menunjukkan bahawa hierarki tindakan boleh membantu meningkatkan ramalan tindakan luar talian dalam berbilang besar. - set data tugas. RT-H (GT) menggunakan metrik MSE kebenaran asas dan mencapai jurang 40% daripada MSE hujung ke hujung, menunjukkan bahawa tindakan bahasa yang dilabel dengan betul mempunyai nilai maklumat yang tinggi untuk meramalkan tindakan.
Rajah 4 menunjukkan beberapa contoh tindakan kontekstual yang diambil daripada penilaian dalam talian RT-H. Seperti yang dapat dilihat, tindakan lisan yang sama sering mengakibatkan perubahan halus dalam tindakan untuk menyelesaikan tugas, sambil tetap menghormati tindakan lisan peringkat lebih tinggi.
Seperti yang ditunjukkan dalam Rajah 5, pasukan penyelidik menunjukkan fleksibiliti RT-H dengan campur tangan dalam talian dengan pergerakan bahasa dalam RT-H. . Sendi mempunyai kesan berbeza pada adegan Perubahan nyata lebih mantap: Malah, terdapat beberapa struktur dikongsi antara tugas yang kelihatan berbeza, contohnya setiap tugasan ini memerlukan beberapa gelagat memilih untuk memulakan tugas, dan dengan mempelajari struktur perkongsian tindakan bahasa merentas tugasan yang berbeza, RT-H boleh mencapai Pick up peringkat tanpa sebarang pembetulan.
Walaupun RT-H tidak lagi dapat menyamaratakan ramalan tindakan lisannya, pembetulan tindakan lisan selalunya boleh digeneralisasikan, jadi hanya beberapa pembetulan diperlukan untuk berjaya menyelesaikan tugasan itu. Ini menunjukkan potensi tindakan lisan untuk mengembangkan pengumpulan data pada tugasan baharu.
Pembaca yang berminat boleh membaca teks asal kertas untuk mengetahui lebih lanjut tentang kandungan penyelidikan.

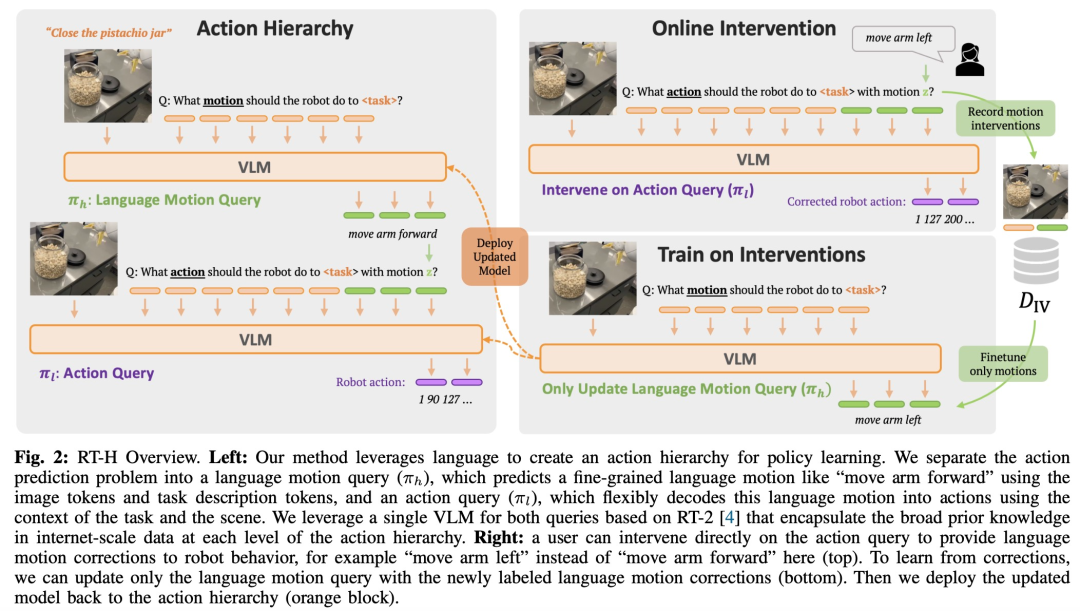
 Seperti yang ditunjukkan dalam Rajah 5, pasukan penyelidik menunjukkan fleksibiliti RT-H dengan campur tangan dalam talian dengan pergerakan bahasa dalam RT-H. . Sendi mempunyai kesan berbeza pada adegan Perubahan nyata lebih mantap:
Seperti yang ditunjukkan dalam Rajah 5, pasukan penyelidik menunjukkan fleksibiliti RT-H dengan campur tangan dalam talian dengan pergerakan bahasa dalam RT-H. . Sendi mempunyai kesan berbeza pada adegan Perubahan nyata lebih mantap: 
Atas ialah kandungan terperinci Penyelidikan baharu Google tentang kecerdasan yang terkandung: RT-H, yang lebih baik daripada RT-2, ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Artikel ini memperkenalkan proses pendaftaran versi web Web Open Exchange (GATE.IO) dan aplikasi Perdagangan Gate secara terperinci. Sama ada pendaftaran web atau pendaftaran aplikasi, anda perlu melawat laman web rasmi atau App Store untuk memuat turun aplikasi tulen, kemudian isi nama pengguna, kata laluan, e -mel, nombor telefon bimbit dan maklumat lain, dan lengkap e -mel atau pengesahan telefon bimbit.
 WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
Pengenalan terperinci kepada operasi log masuk versi Web Open Exchange, termasuk langkah masuk dan proses pemulihan kata laluan.
 Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung? Bybit adalah pertukaran cryptocurrency yang menyediakan perkhidmatan perdagangan kepada pengguna. Aplikasi mudah alih Exchange tidak boleh dimuat turun terus melalui AppStore atau GooglePlay untuk sebab -sebab berikut: 1. Aplikasi pertukaran cryptocurrency sering tidak memenuhi keperluan ini kerana ia melibatkan perkhidmatan kewangan dan memerlukan peraturan dan standard keselamatan tertentu. 2. Undang -undang dan Peraturan Pematuhan di banyak negara, aktiviti yang berkaitan dengan urus niaga cryptocurrency dikawal atau terhad. Untuk mematuhi peraturan ini, aplikasi bybit hanya boleh digunakan melalui laman web rasmi atau saluran yang diberi kuasa lain
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Artikel ini mencadangkan sepuluh platform perdagangan cryptocurrency teratas yang memberi perhatian kepada, termasuk Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI dan Xbit yang desentralisasi. Platform ini mempunyai kelebihan mereka sendiri dari segi kuantiti mata wang transaksi, jenis urus niaga, keselamatan, pematuhan, dan ciri khas. Memilih platform yang sesuai memerlukan pertimbangan yang komprehensif berdasarkan pengalaman perdagangan anda sendiri, toleransi risiko dan keutamaan pelaburan. Semoga artikel ini membantu anda mencari saman terbaik untuk diri sendiri
 Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Adalah penting untuk memilih saluran rasmi untuk memuat turun aplikasi dan memastikan keselamatan akaun anda.
 Bitget Trading Platform Rasmi App Muat turun dan Alamat Pemasangan
Feb 25, 2025 pm 02:42 PM
Bitget Trading Platform Rasmi App Muat turun dan Alamat Pemasangan
Feb 25, 2025 pm 02:42 PM
Panduan ini menyediakan langkah muat turun dan pemasangan terperinci untuk aplikasi Bitget Exchange rasmi, sesuai untuk sistem Android dan iOS. Panduan ini mengintegrasikan maklumat dari pelbagai sumber yang berwibawa, termasuk laman web rasmi, App Store, dan Google Play, dan menekankan pertimbangan semasa muat turun dan pengurusan akaun. Pengguna boleh memuat turun aplikasinya dari saluran rasmi, termasuk App Store, muat turun APK laman web rasmi dan melompat laman web rasmi, dan lengkap pendaftaran, pengesahan identiti dan tetapan keselamatan. Di samping itu, panduan itu merangkumi soalan dan pertimbangan yang sering ditanya, seperti
 Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Panduan ini menyediakan langkah muat turun dan pemasangan terperinci untuk aplikasi Bitget Exchange rasmi, sesuai untuk sistem Android dan iOS. Panduan ini mengintegrasikan maklumat dari pelbagai sumber yang berwibawa, termasuk laman web rasmi, App Store, dan Google Play, dan menekankan pertimbangan semasa muat turun dan pengurusan akaun. Pengguna boleh memuat turun aplikasinya dari saluran rasmi, termasuk App Store, muat turun APK laman web rasmi dan melompat laman web rasmi, dan lengkap pendaftaran, pengesahan identiti dan tetapan keselamatan. Di samping itu, panduan itu merangkumi soalan dan pertimbangan yang sering ditanya, seperti
 Mengapa Bittensor dikatakan sebagai 'Bitcoin' di trek AI?
Mar 04, 2025 pm 04:06 PM
Mengapa Bittensor dikatakan sebagai 'Bitcoin' di trek AI?
Mar 04, 2025 pm 04:06 PM
Tajuk Asal: Bittensor = Aibitcoin? Bittensor mengamalkan model subnet yang membolehkan kemunculan penyelesaian AI yang berbeza dan memberi inspirasi kepada inovasi melalui token TAO. Walaupun pasaran AI matang, Bittensor menghadapi risiko yang kompetitif dan mungkin tertakluk kepada sumber terbuka yang lain
