
 Peranti teknologi
AI
Karya baharu oleh Yan Shuicheng/Cheng Mingming! Latihan DiT, komponen teras Sora, dipercepatkan sebanyak 10 kali, dan Masked Diffusion Transformer V2 ialah sumber terbuka
Peranti teknologi
AI
Karya baharu oleh Yan Shuicheng/Cheng Mingming! Latihan DiT, komponen teras Sora, dipercepatkan sebanyak 10 kali, dan Masked Diffusion Transformer V2 ialah sumber terbuka
Karya baharu oleh Yan Shuicheng/Cheng Mingming! Latihan DiT, komponen teras Sora, dipercepatkan sebanyak 10 kali, dan Masked Diffusion Transformer V2 ialah sumber terbuka

Sebagai salah satu teknologi teras Sora yang menarik, DiT menggunakan Diffusion Transformer untuk menskalakan model generatif kepada skala yang lebih besar untuk mencapai kesan penjanaan imej yang cemerlang.
Namun, saiz model yang lebih besar menyebabkan kos latihan melambung tinggi.
Pasukan penyelidik Yan Shuicheng dan Cheng Mingming dari Sea AI Lab, Nankai University, dan Institut Penyelidikan Kunlun Wanwei 2050 mencadangkan model baharu yang dipanggil Masked Diffusion Transformer pada persidangan ICCV 2023. Model ini menggunakan teknologi pemodelan topeng untuk mempercepatkan latihan Diffusion Transformer dengan mempelajari maklumat perwakilan semantik, dan mencapai keputusan SoTA dalam bidang penjanaan imej. Inovasi ini membawa penemuan baharu kepada pembangunan model penjanaan imej dan menyediakan penyelidik kaedah latihan yang lebih cekap. Dengan menggabungkan kepakaran dan teknologi dari pelbagai bidang, pasukan penyelidik berjaya mencadangkan penyelesaian yang meningkatkan kelajuan latihan dan meningkatkan hasil penjanaan. Kerja mereka telah menyumbang idea inovatif yang penting kepada pembangunan bidang kecerdasan buatan dan memberikan inspirasi berguna untuk penyelidikan dan amalan masa depan 2303.14389
Alamat GitHub: https://github.com/sail-sg/MDT
 Baru-baru ini. , Masked Diffusion Transformer V2 telah menyegarkan semula SoTA Berbanding dengan DiT, kelajuan latihan meningkat lebih daripada 10 kali ganda, dan ia telah mencapai penanda aras ImageNet 1.58.
Baru-baru ini. , Masked Diffusion Transformer V2 telah menyegarkan semula SoTA Berbanding dengan DiT, kelajuan latihan meningkat lebih daripada 10 kali ganda, dan ia telah mencapai penanda aras ImageNet 1.58.
Sebagai contoh, seperti yang ditunjukkan dalam gambar di atas, DiT telah belajar untuk menjana tekstur rambut anjing pada langkah latihan ke-50, dan kemudian belajar untuk menjana salah satu daripada mata anjing pada ke-200. langkah latihan dan mulut, tetapi mata lain hilang.
 Walaupun pada langkah latihan 300k, kedudukan relatif dua telinga anjing yang dijana oleh DiT tidak begitu tepat.
Walaupun pada langkah latihan 300k, kedudukan relatif dua telinga anjing yang dijana oleh DiT tidak begitu tepat.
Seperti yang ditunjukkan dalam rajah di atas, MDT memperkenalkan strategi pembelajaran model topeng sambil mengekalkan proses latihan penyebaran. Dengan menutup token imej bising, MDT menggunakan seni bina Pengubah Resapan asimetri (Pengubah Resapan Asymmetric) untuk meramalkan token imej bertopeng daripada token imej bising yang belum bertopeng, sekali gus mencapai proses latihan pemodelan topeng dan resapan.
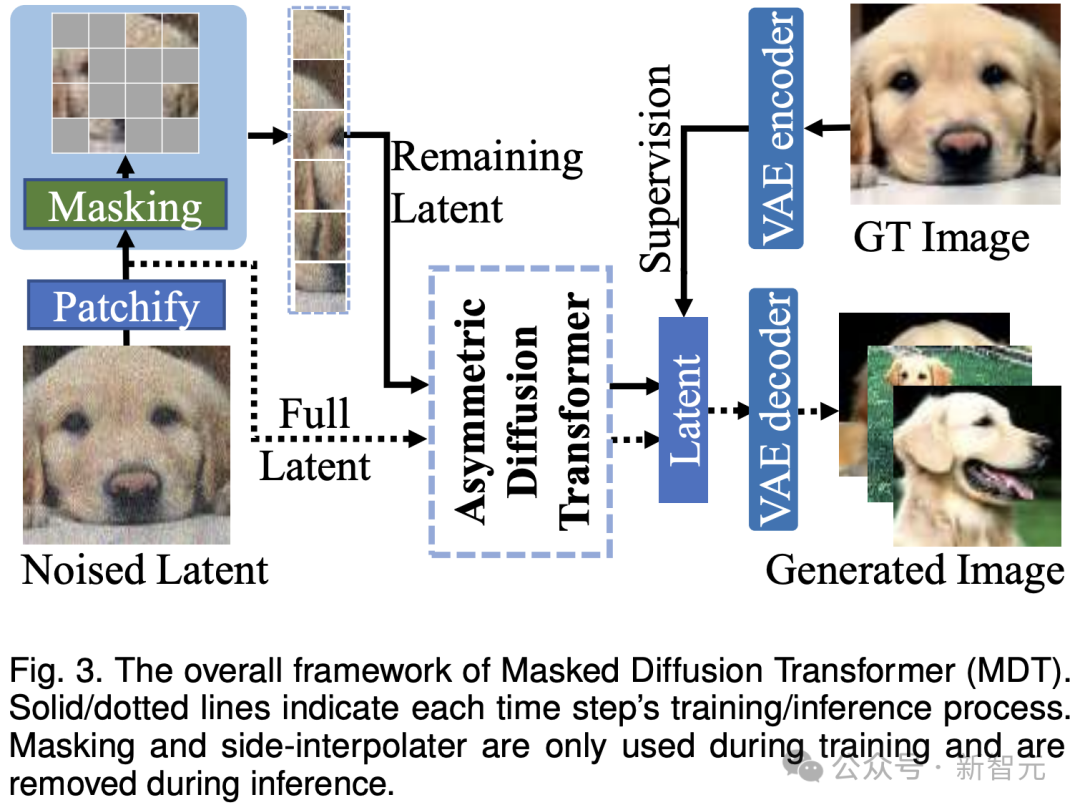
Semasa proses inferens, MDT masih mengekalkan proses penjanaan resapan piawai. Reka bentuk MDT membantu Diffusion Transformer mempunyai kedua-dua keupayaan ekspresi maklumat semantik yang dibawa oleh pembelajaran perwakilan model topeng dan keupayaan model resapan untuk menjana butiran imej.
Secara khusus, MDT memetakan imej ke ruang terpendam melalui pengekod VAE dan memprosesnya dalam ruang terpendam untuk menjimatkan kos pengkomputeran.
Semasa proses latihan, MDT mula-mula menutup sebahagian daripada token imej selepas menambah hingar, dan menghantar token yang tinggal ke Transformer Resapan Asymmetric untuk meramalkan semua token imej selepas menafikan.
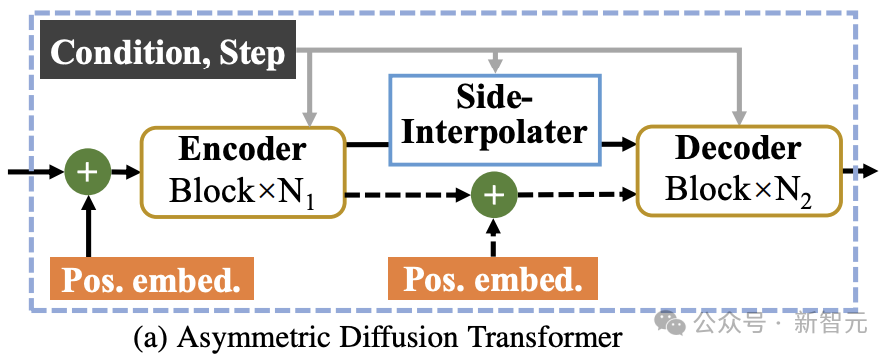
Seni bina Asymmetric Diffusion Transformer
 Picture
Picture
Seperti yang ditunjukkan dalam rajah di atas, Asymmetric Diffusion epolcoder Transformer (polycoder.auxili) termasuk Asymmetric Diffusion Intercoder Transformer
 Gambar
Gambar
Semasa proses latihan, Pengekod hanya memproses token yang tidak bertopeng semasa proses inferens, kerana tiada langkah topeng, ia memproses semua token.
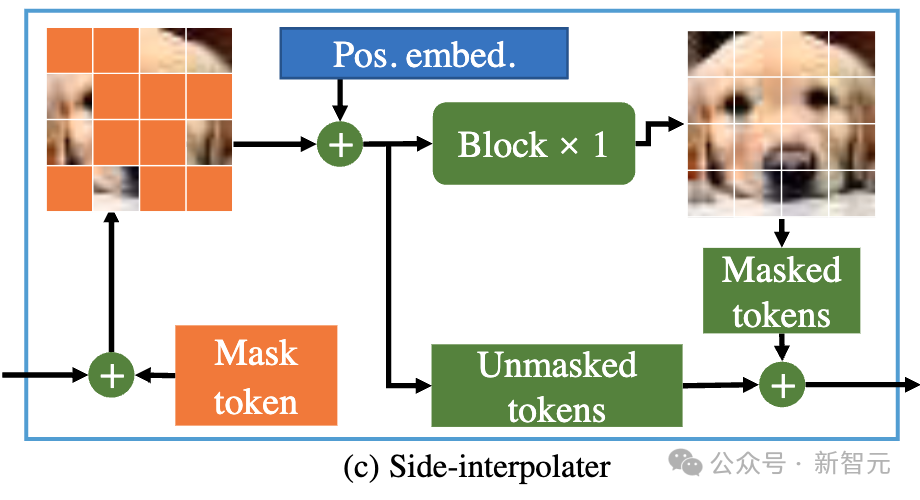
Oleh itu, untuk memastikan penyahkod sentiasa boleh memproses semua token semasa fasa latihan atau inferens, penyelidik mencadangkan penyelesaian: semasa proses latihan, melalui interpolator tambahan yang terdiri daripada blok DiT (seperti yang ditunjukkan dalam rajah di atas ), interpolasi dan ramalkan token bertopeng daripada output pengekod, dan alih keluarnya semasa peringkat inferens tanpa menambah sebarang overhed inferens.
Pengekod dan penyahkod MDT memasukkan maklumat pengekodan kedudukan global dan tempatan ke dalam blok DiT standard untuk membantu meramalkan token di bahagian topeng.
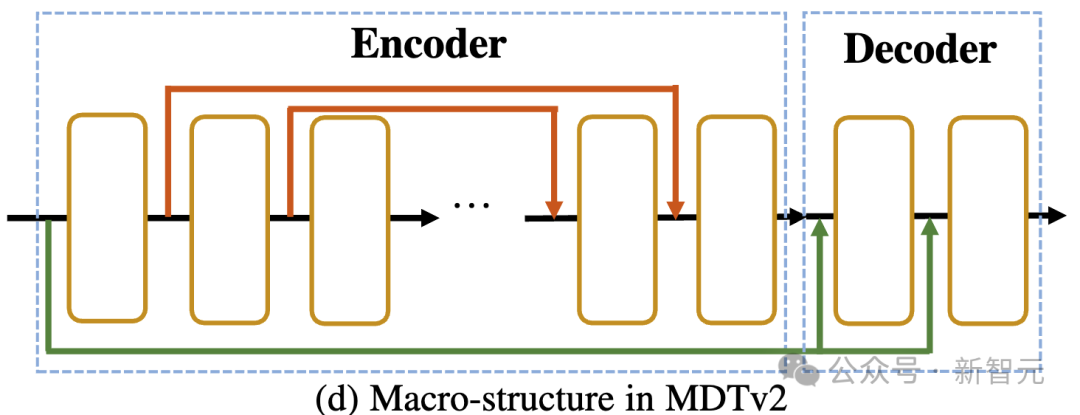
Asymmetric Diffusion Transformer V2
 Pictures
Pictures
Seperti yang ditunjukkan dalam gambar di atas, MDTv2 terus mengoptimumkan proses difducing dan diffusion yang lebih cekap proses pemodelan.
Ini termasuk menyepadukan pintasan panjang gaya U-Net dalam pengekod dan pintasan input padat dalam penyahkod.
Antaranya, pintasan input padat menghantar token bertopeng selepas menambah bunyi pada penyahkod, mengekalkan maklumat hingar yang sepadan dengan token bertopeng, sekali gus memudahkan latihan proses penyebaran.
Selain itu, MDT juga telah memperkenalkan strategi latihan yang lebih baik termasuk penggunaan pengoptimum Adan yang lebih pantas, berat kehilangan berkaitan langkah masa, dan nisbah topeng yang diperluas untuk mempercepatkan lagi proses latihan model Resapan Bertopeng. .
Jelas sekali bahawa MDT mencapai markah FID yang lebih tinggi dengan kos latihan yang lebih rendah pada semua saiz model.
Parameter dan kos inferens MDT pada asasnya adalah sama dengan DiT, kerana seperti yang dinyatakan di atas, proses resapan piawai yang konsisten dengan DiT masih dikekalkan dalam proses inferens MDT. 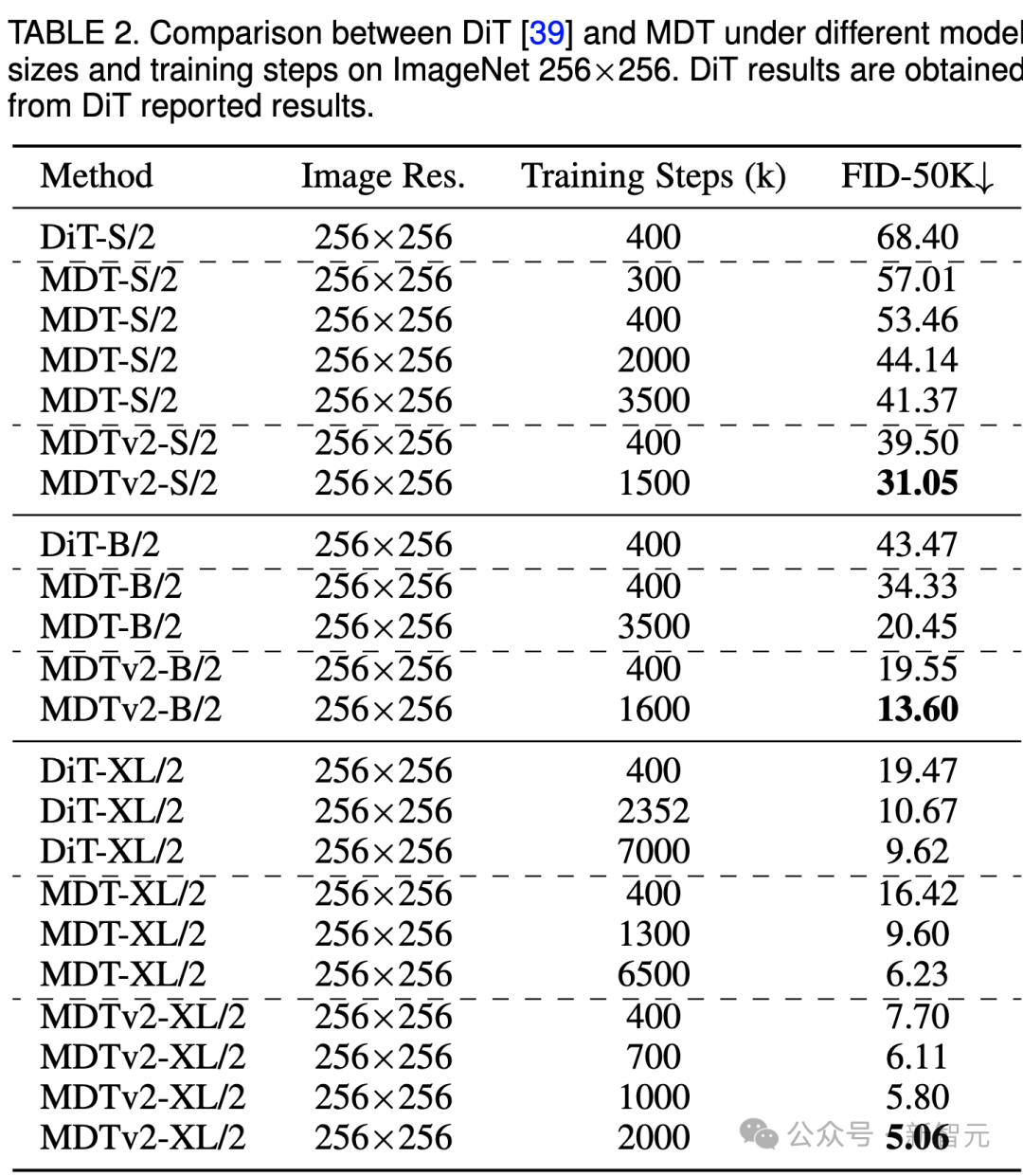
Untuk model kecil, MDTv2-S/2 masih mencapai prestasi yang jauh lebih baik daripada DiT-S/2 dengan langkah latihan yang jauh lebih sedikit. Sebagai contoh, dengan latihan yang sama sebanyak 400k langkah, MDTv2 mempunyai indeks FID 39.50, yang jauh mendahului indeks FID DiT sebanyak 68.40.
Lebih penting lagi, keputusan ini juga melebihi prestasi model DiT-B/2 yang lebih besar pada 400k langkah latihan (39.50 vs 43.47).
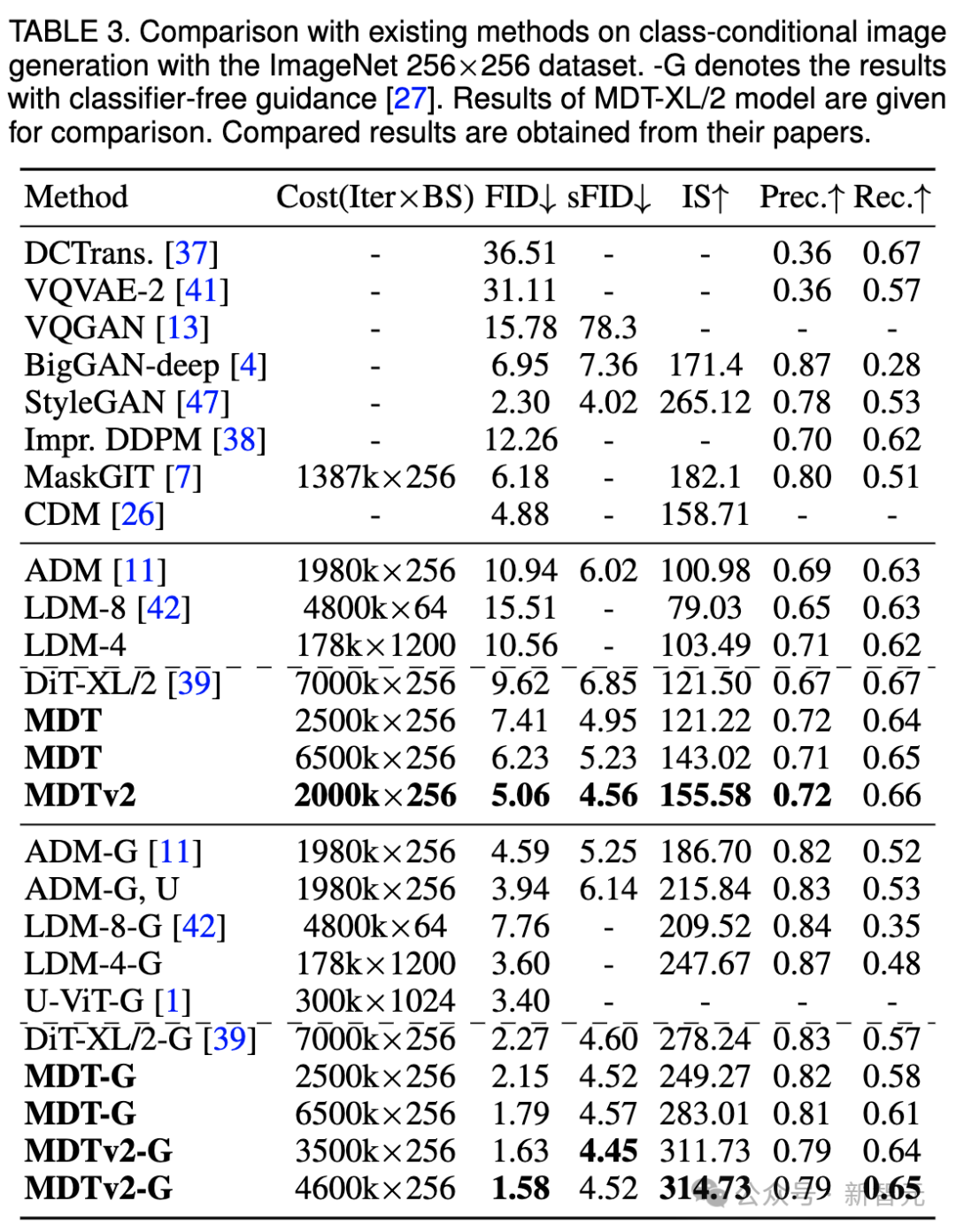
ImageNet 256 penanda aras perbandingan kualiti penjanaan CFG
 imej
imej
Kami juga membandingkan prestasi penjanaan imej MDT dengan kaedah sedia ada di bawah bimbingan tanpa pengelas dalam jadual di atas.
MDT mengatasi SOTA DiT sebelumnya dan kaedah lain dengan skor FID 1.79. MDTv2 meningkatkan lagi prestasi, melonjakkan skor SOTA FID untuk penjanaan imej ke paras terendah baharu 1.58 dengan langkah latihan yang lebih sedikit.
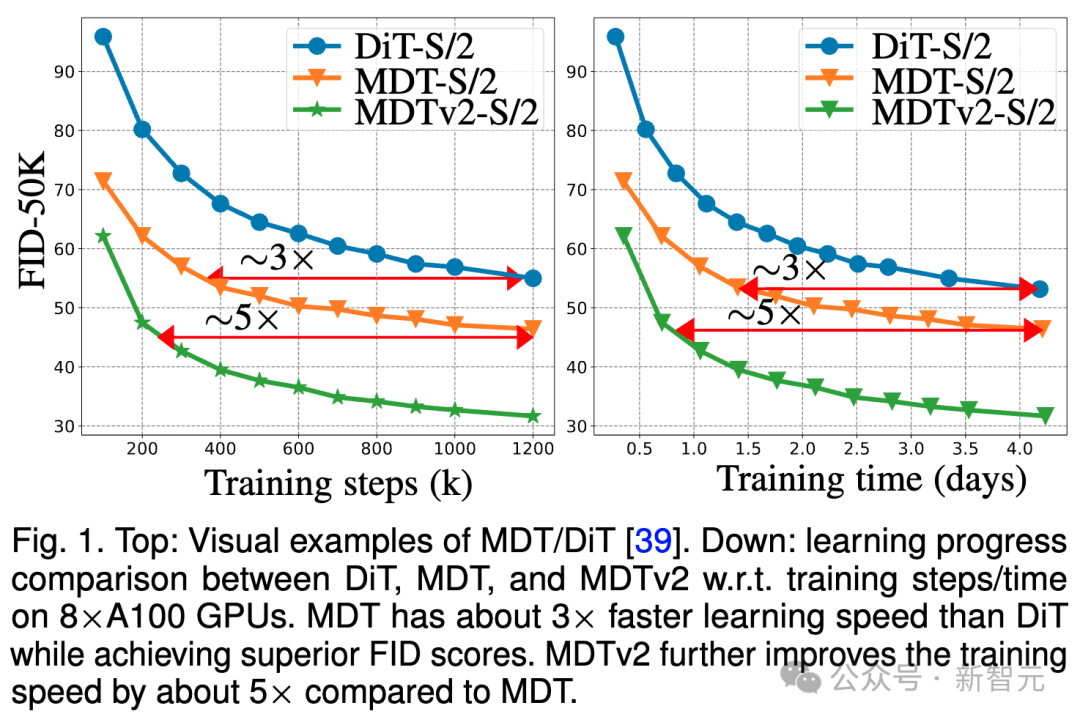
Sama seperti DiT, kami tidak melihat ketepuan skor FID model semasa latihan semasa kami meneruskan latihan. . 256 penanda aras DiT-S/ pada GPU 2 FID prestasi garis dasar, MDT-S/2 dan MDTv2-S/2 di bawah langkah latihan/masa latihan yang berbeza.
Terima kasih kepada keupayaan pembelajaran kontekstual yang lebih baik, MDT mengatasi DiT dalam kedua-dua prestasi dan kelajuan penjanaan. Kelajuan penumpuan latihan MDTv2 adalah lebih daripada 10 kali lebih tinggi daripada DiT. 
 Ringkasan & Perbincangan
Ringkasan & Perbincangan
MDT memperkenalkan skema pembelajaran perwakilan model topeng yang serupa dengan MAE dalam proses latihan resapan, yang boleh menggunakan maklumat kontekstual objek imej untuk membina semula maklumat lengkap imej input yang tidak lengkap, dengan itu belajar semantik dalam imej Kolerasi antara bahagian, dengan itu meningkatkan kualiti penjanaan imej dan kelajuan pembelajaran.
Penyelidik percaya bahawa meningkatkan pemahaman semantik dunia fizikal melalui pembelajaran perwakilan visual boleh meningkatkan kesan simulasi model generatif pada dunia fizikal. Ini bertepatan dengan visi Sora untuk membina simulator dunia fizikal melalui model generatif. Semoga karya ini akan memberi inspirasi kepada lebih banyak kerja untuk menyatukan pembelajaran perwakilan dan pembelajaran generatif.
Rujukan:
https://arxiv.org/abs/2303.14389
Atas ialah kandungan terperinci Karya baharu oleh Yan Shuicheng/Cheng Mingming! Latihan DiT, komponen teras Sora, dipercepatkan sebanyak 10 kali, dan Masked Diffusion Transformer V2 ialah sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Pengenalan kepada cara menggunakan simulator joiplay
May 04, 2024 pm 06:40 PM
Pengenalan kepada cara menggunakan simulator joiplay
May 04, 2024 pm 06:40 PM
Simulator jojplay ialah simulator telefon mudah alih yang sangat mudah digunakan Ia menyokong permainan komputer untuk dijalankan pada telefon mudah alih dan mempunyai keserasian yang sangat baik Beberapa pemain tidak tahu cara menggunakannya . Cara menggunakan simulator joiplay 1. Mula-mula, anda perlu memuat turun pemalam Joiplay body dan RPGM Sebaik-baiknya pasangkannya mengikut urutan pemalam badan Pakej apk boleh didapati di bar Joiplay (klik untuk mendapatkan >>>). 2. Selepas Android selesai, anda boleh menambah permainan di sudut kiri bawah. 3. Isikan nama secara santai, dan tekan CHOOSE pada executablefile untuk memilih fail game.exe permainan. 4. Ikon boleh dibiarkan kosong atau anda boleh memilih gambar kegemaran anda.
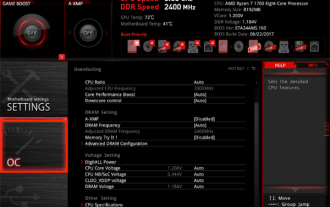 Bagaimana untuk mendayakan vt pada papan induk MSI
May 01, 2024 am 09:28 AM
Bagaimana untuk mendayakan vt pada papan induk MSI
May 01, 2024 am 09:28 AM
Bagaimana untuk mendayakan VT pada papan induk MSI? Apakah kaedahnya? Laman web ini telah menyusun kaedah pemboleh VT papan induk MSI dengan teliti untuk kebanyakan pengguna Selamat datang untuk membaca dan berkongsi! Langkah pertama ialah memulakan semula komputer dan masuk ke BIOS Apakah yang perlu saya lakukan jika kelajuan permulaan terlalu cepat dan saya tidak boleh memasuki BIOS? Selepas skrin menyala, teruskan menekan "Del" untuk memasuki halaman BIOS Langkah kedua ialah mencari pilihan VT dalam menu dan menghidupkannya Model komputer yang berbeza mempunyai antara muka BIOS yang berbeza dan nama yang berbeza untuk VT : 1. Enter Selepas memasuki halaman BIOS, cari pilihan "OC (atau overclocking)" - "CPU Features" - "SVMMode (atau Intel Virtualization Technology)" dan tukar pilihan "Disabled"
 Bagaimana untuk mendayakan vt pada papan induk ASRock
May 01, 2024 am 08:49 AM
Bagaimana untuk mendayakan vt pada papan induk ASRock
May 01, 2024 am 08:49 AM
Bagaimana untuk membolehkan VT pada papan induk ASRock, apakah kaedah dan cara mengendalikannya. Laman web ini telah menyusun kaedah ASRock motherboard vt enable untuk pengguna membaca dan berkongsi! Langkah pertama adalah untuk memulakan semula komputer Selepas skrin menyala, teruskan menekan kekunci "F2" untuk memasuki halaman BIOS. Langkah kedua ialah mencari pilihan VT dalam menu dan menghidupkannya Model papan induk yang berbeza mempunyai antara muka BIOS yang berbeza dan nama yang berbeza untuk VT 1. Selepas memasuki halaman BIOS, cari "Advanced (Advanced)" - "CPU Configuration (CPU) Konfigurasi)" - pilihan "SVMMOD (teknologi penmayaran)", tukar "Dilumpuhkan" kepada "Didayakan"
 Emulator Android disyorkan yang lebih lancar (pilih emulator Android yang anda mahu gunakan)
Apr 21, 2024 pm 06:01 PM
Emulator Android disyorkan yang lebih lancar (pilih emulator Android yang anda mahu gunakan)
Apr 21, 2024 pm 06:01 PM
Ia boleh memberikan pengguna pengalaman permainan dan pengalaman penggunaan yang lebih baik Emulator Android ialah perisian yang boleh mensimulasikan perjalanan sistem Android pada komputer. Terdapat banyak jenis emulator Android di pasaran, dan kualitinya berbeza-beza, walau bagaimanapun. Untuk membantu pembaca memilih emulator yang paling sesuai untuk mereka, artikel ini akan memfokuskan pada beberapa emulator Android yang lancar dan mudah digunakan. 1. BlueStacks: Kelajuan larian yang pantas Dengan kelajuan larian yang sangat baik dan pengalaman pengguna yang lancar, BlueStacks ialah emulator Android yang popular. Membenarkan pengguna bermain pelbagai permainan dan aplikasi mudah alih, ia boleh mencontohi sistem Android pada komputer dengan prestasi yang sangat tinggi. 2. NoxPlayer: Menyokong berbilang bukaan, menjadikannya lebih menyeronokkan untuk bermain permainan Anda boleh menjalankan permainan yang berbeza dalam berbilang emulator pada masa yang sama
 Bagaimana untuk memasang sistem Windows pada komputer tablet
May 03, 2024 pm 01:04 PM
Bagaimana untuk memasang sistem Windows pada komputer tablet
May 03, 2024 pm 01:04 PM
Bagaimana untuk menyalakan sistem Windows pada tablet BBK Cara pertama ialah memasang sistem pada cakera keras. Selagi sistem komputer tidak ranap, anda boleh memasuki sistem, dan memuat turun perkara, anda boleh menggunakan cakera keras komputer untuk memasang sistem. Kaedahnya adalah seperti berikut: Bergantung pada konfigurasi komputer anda, anda boleh memasang sistem pengendalian WIN7. Kami memilih untuk memuat turun sistem pemasangan semula satu klik Xiaobai dalam vivopad untuk memasangnya Mula-mula, pilih versi sistem yang sesuai untuk komputer anda, dan klik "Pasang sistem ini" ke langkah seterusnya. Kemudian kami menunggu dengan sabar untuk sumber pemasangan dimuat turun, dan kemudian menunggu persekitaran digunakan dan dimulakan semula. Langkah-langkah untuk memasang win11 pada vivopad ialah: mula-mula gunakan perisian untuk menyemak sama ada win11 boleh dipasang. Selepas melepasi pengesanan sistem, masukkan tetapan sistem. Pilih pilihan Kemas Kini & Keselamatan di sana. klik
 Panduan Simulator Hidup Semula
May 07, 2024 pm 05:28 PM
Panduan Simulator Hidup Semula
May 07, 2024 pm 05:28 PM
Life Restart Simulator adalah permainan simulasi yang sangat menarik Permainan ini telah menjadi sangat popular baru-baru ini strategi ada? Panduan Panduan Simulator Hidup Semula Ciri-ciri Simulator Mulakan Semula Kehidupan Ini adalah permainan yang sangat kreatif di mana pemain boleh bermain mengikut idea mereka sendiri. Terdapat banyak tugas yang perlu diselesaikan setiap hari, dan anda boleh menikmati kehidupan baru di dunia maya ini. Terdapat banyak lagu dalam permainan, dan semua jenis kehidupan yang berbeza sedang menunggu untuk anda alami. Hidup Semula Simulator Kandungan Permainan Kad Lukisan Bakat: Bakat: Anda mesti memilih kotak kecil misteri untuk menjadi abadi. Pelbagai kapsul kecil tersedia untuk mengelak daripada mati di tengah jalan. Cthulhu boleh memilih
 Bagaimana untuk membungkus pycharm ke dalam apk
Apr 18, 2024 am 05:57 AM
Bagaimana untuk membungkus pycharm ke dalam apk
Apr 18, 2024 am 05:57 AM
Bagaimana untuk membungkus apl Android sebagai APK menggunakan PyCharm? Pastikan projek disambungkan ke peranti Android atau emulator. Konfigurasikan jenis binaan: Tambahkan jenis binaan dan tandakan "Jana APK bertandatangan". Klik "Bina APK" dalam bar alat binaan, pilih jenis binaan anda dan mulakan binaan.
 Pengenalan kepada kaedah tetapan fon simulator joiplay
May 09, 2024 am 08:31 AM
Pengenalan kepada kaedah tetapan fon simulator joiplay
May 09, 2024 am 08:31 AM
Simulator jojplay sebenarnya boleh menyesuaikan fon permainan, dan boleh menyelesaikan masalah kehilangan aksara dan aksara berkotak dalam teks Saya rasa ramai pemain masih tidak tahu cara mengendalikannya fon simulator jojplay. Cara menetapkan fon simulator joiplay 1. Mula-mula buka simulator joiplay, klik pada tetapan (tiga titik) di sudut kanan atas, dan cari. 2. Dalam lajur RPGMSettings, klik untuk memilih fon tersuai CustomFont dalam baris ketiga. 3. Pilih fail fon dan klik OK Berhati-hati untuk tidak mengklik ikon "Simpan" di sudut kanan bawah, jika tidak tetapan lalai akan dipulihkan. 4. Pengasas dan Quasi-Yuan aksara Cina ringkas disyorkan (sudah dalam folder permainan Fuxing dan Rebirth). joi
