
 Peranti teknologi
AI
Mengatasi tiga masalah utama 'model berasaskan graf' buat kali pertama! OpenGraph sumber terbuka HKU: pembelajaran sampel sifar menyesuaikan diri dengan pelbagai tugas hiliran
Peranti teknologi
AI
Mengatasi tiga masalah utama 'model berasaskan graf' buat kali pertama! OpenGraph sumber terbuka HKU: pembelajaran sampel sifar menyesuaikan diri dengan pelbagai tugas hiliran
Mengatasi tiga masalah utama 'model berasaskan graf' buat kali pertama! OpenGraph sumber terbuka HKU: pembelajaran sampel sifar menyesuaikan diri dengan pelbagai tugas hiliran

Teknologi pembelajaran graf telah digunakan secara meluas dalam pelbagai bidang, termasuk sistem pengesyoran, analisis rangkaian sosial, rangkaian petikan dan rangkaian pengangkutan. Teknologi ini boleh melombong dan mempelajari data hubungan yang kompleks dengan berkesan, menyediakan alat yang berkuasa untuk saintis data dan jurutera. Melalui algoritma pembelajaran graf, kami lebih memahami perkaitan dan perkaitan antara data, dengan itu membantu kami menemui undang-undang dan corak yang tersembunyi di sebalik data. Dalam aplikasi praktikal, teknologi pembelajaran graf boleh membantu kami membina lebih tepat dan
Graph Neural Networks (GNNs) menggunakan mekanisme penghantaran mesej berulang untuk menangkap perhubungan aras tinggi yang kompleks dalam data berstruktur graf, dalam pelbagai pencapaian luar biasa telah dibuat dalam aplikasi pembelajaran graf.
Biasanya, rangkaian neural graf hujung ke hujung jenis ini memerlukan sejumlah besar data anotasi berkualiti tinggi untuk mencapai hasil latihan yang baik.
Dalam beberapa tahun kebelakangan ini, beberapa kerja telah mencadangkan mod pra-latihan dan penalaan halus (Pra-latihan dan Penalaan Halus) model graf, menggunakan pelbagai tugas pembelajaran diselia sendiri untuk melatih terlebih dahulu pada data graf tidak berlabel , dan kemudian melakukan latihan pada sejumlah kecil Penalaan halus dilakukan pada data berlabel untuk memerangi masalah isyarat pengawasan yang tidak mencukupi. Tugas pembelajaran penyeliaan sendiri di sini termasuk kaedah seperti pembelajaran kontrastif, pembinaan semula topeng, dan pemaksimuman maklumat bersama tempatan dan global.
Walaupun kaedah pra-latihan sedemikian berjaya pada tahap tertentu, ia mempunyai batasan tertentu dalam keupayaan generalisasi, terutamanya apabila peralihan pengedaran berlaku antara tugas pra-latihan dan hiliran.
Dalam sistem pengesyoran, model pra-latihan dilatih berdasarkan data awal, tetapi pilihan pengguna dan populariti produk sering berubah, yang memerlukan model sentiasa dikemas kini untuk menyesuaikan diri dengan maklumat baharu.
Untuk menangani cabaran ini, penyelidikan baru-baru ini telah mencadangkan kaedah penalaan halus petunjuk untuk model graf, supaya model pra-latihan boleh menyesuaikan diri dengan lebih berkesan kepada tugasan dan data hiliran yang berbeza.
Walaupun penyelidikan di atas telah mempromosikan prestasi generalisasi model rangkaian saraf graf, model ini adalah berdasarkan andaian: data latihan dan data ujian mempunyai set nod dan ruang ciri yang sama.
Ini sangat mengehadkan skop aplikasi model graf pra-latihan. Oleh itu, artikel ini meneroka kaedah untuk meningkatkan lagi keupayaan generalisasi model grafik.
Kami menjangkakan OpenGraph dapat menangkap corak struktur topologi biasa dan mencapai ramalan sifar pukulan pada data ujian. Ini bermakna melalui proses penyebaran ke hadapan, ciri boleh diekstrak dengan cekap dan data graf ujian diramalkan dengan tepat.
Proses latihan model dijalankan pada data graf yang berbeza sepenuhnya, dan tiada unsur graf ujian, termasuk nod, tepi dan vektor ciri, disentuh semasa fasa latihan.

Untuk mencapai matlamat ini, artikel ini perlu menyelesaikan tiga cabaran berikut:
C1 perubahan set token merentas set data
graf-sampley yang ketara. tugasnya ialah, Data graf yang berbeza biasanya mempunyai set token graf yang berbeza sama sekali. Khususnya, set nod daripada graf yang berbeza selalunya tidak bertindih dan set data graf yang berbeza sering menggunakan ciri nod yang berbeza sama sekali. Ini menghalang model daripada melaksanakan tugas ramalan silang set data dengan mempelajari parameter yang terikat pada token graf bagi set data tertentu.
C2. Pemodelan hubungan yang cekap antara nod
Dalam bidang pembelajaran graf, selalunya terdapat kebergantungan yang rumit antara nod, dan model perlu mempertimbangkan secara menyeluruh hubungan kejiranan tempatan dan global nod. Apabila membina model graf umum, tugas penting ialah dapat memodelkan perhubungan antara nod dengan cekap, yang boleh meningkatkan kesan model dan kebolehskalaan apabila memproses sejumlah besar data graf.
C3 Kekurangan data latihan
Disebabkan oleh perlindungan privasi, kos pengumpulan data dan sebab-sebab lain, masalah kekurangan data berleluasa dalam banyak bidang hiliran pembelajaran graf, yang menjadikan latihan model graf umum terdedah kepada kekurangan sokongan untuk hasil latihan Suboptimum tertentu kerana kurangnya pemahaman tentang domain hiliran.
Untuk menangani cabaran di atas, penyelidik dari Universiti Hong Kong mencadangkan OpenGraph, model yang baik dalam pembelajaran sifar pukulan dan boleh mengenal pasti corak struktur topologi boleh dipindahkan antara domain hiliran yang berbeza.

Pautan kertas: https://arxiv.org/pdf/2403.01121.pdf
Pautan kod sumber: https://github.com/HKUDS/OpenGraph
a atasByware unjuran Tokenizer graf yang dicadangkan menyelesaikan cabaran C1, dengan itu menghasilkan token graf bersatu.
Untuk menangani cabaran C2, Transformer graf boleh skala direka bentuk, yang dilengkapi dengan mekanisme perhatian kendiri yang cekap berdasarkan pensampelan anchor, dan termasuk pensampelan jujukan token untuk mencapai latihan yang lebih cekap.
Untuk menangani cabaran C3, kami memanfaatkan model bahasa yang besar untuk penambahan data untuk memperkayakan pra-latihan kami, menggunakan algoritma pepohon petunjuk dan pensampelan Gibbs untuk mensimulasikan data hubungan berstruktur graf dunia sebenar. Ujian meluas kami pada berbilang set data graf menunjukkan keupayaan generalisasi unggul OpenGraph dalam pelbagai tetapan.
Pengenalan modelKeseluruhan seni bina model ditunjukkan dalam rajah di bawah, yang boleh dibahagikan kepada tiga bahagian, iaitu 1) Tokenizer graf bersatu, 2) Transformer graf boleh skala, 3) penyulingan pengetahuan model bahasa besar .

Tokenizer graf bersatu
Untuk mengatasi perbezaan besar dan ciri-ciri graf kami yang berbeza dalam set graf pertama tokenizer , yang boleh memetakan data graf berbeza ke dalam urutan token bersatu dengan berkesan. Dalam tokenizer kami, setiap token mempunyai vektor semantik yang menerangkan maklumat nod yang sepadan.
Dengan mengguna pakai ruang perwakilan nod bersatu dan struktur data jujukan yang fleksibel, kami berharap dapat melaksanakan tokenisasi piawai dan cekap untuk data graf yang berbeza.
Untuk mencapai matlamat ini, tokenizer kami menggunakan maklumat topologi terlicin dan fungsi pemetaan daripada ruang nod ke ruang perwakilan terpendam.
Matriks bersebelahan lancar tertib tinggi
Dalam proses tokenisasi graf, kuasa tertib tinggi matriks bersebelahan digunakan sebagai salah satu input yang tinggi. susunan hubungan sambungan struktur graf, tetapi juga menyelesaikan masalah Masalah keterlaluan sambungan dalam matriks bersebelahan asal.
Normalisasi Laplacian dilakukan semasa proses pengiraan, dan semua kuasa matriks bersebelahan susunan berbeza diambil kira Kaedah pengiraan khusus adalah seperti berikut.
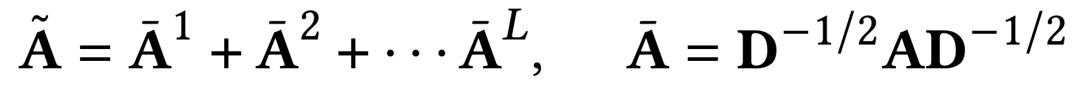
Pemetaan graf sewenang-wenangnya berdasarkan topologi
Matriks bersebelahan set data yang berbeza mempunyai perbezaan besar dalam dimensi, yang menghalang kita daripada mengambil masukan tetap dan kemudian matriks secara langsung Pemprosesan rangkaian saraf dimensi. . Untuk mengurangkan kehilangan maklumat dalam proses pemetaan, kami mencadangkan kaedah pemetaan sedar topologi.
Pertama sekali, julat nilai pemetaan sedar topologi kami ialah ruang perwakilan terpendam berdimensi lebih tinggi. Beberapa karya terdahulu telah menunjukkan bahawa pemetaan rawak selalunya boleh menghasilkan perwakilan yang memuaskan apabila menggunakan dimensi ruang terpendam yang lebih besar.
Untuk mengekalkan maklumat struktur graf dan mengurangkan kesan rawak, kami menggunakan penguraian nilai eigen (SVD) pantas untuk membina fungsi pemetaan kami. Dalam eksperimen sebenar, dua pusingan penguraian nilai eigen yang pantas boleh mengekalkan maklumat topologi dengan berkesan, dan overhed pengiraan yang terhasil boleh diabaikan berbanding dengan modul lain.
Scalable Graph Transformer
Selepas proses tokenisasi graf tanpa parameter, OpenGraph memperuntukkan ciri-ciri data graf sedar topologi bersatu dengan perwakilan data token graf yang berbeza. Tugas seterusnya ialah memodelkan kebergantungan kompleks antara nod menggunakan rangkaian neural yang boleh dilatih.
OpenGraph mengguna pakai seni bina transformer untuk memanfaatkan keupayaan hebatnya dalam memodelkan hubungan yang kompleks. Untuk memastikan kecekapan dan prestasi model, kami memperkenalkan dua teknik persampelan berikut. Persampelan jujukan token perhubungan berpasangan antara token dalam satu masa mengurangkan bilangan pasangan perhubungan yang perlu dimodelkan daripada kuasa dua bilangan nod kepada kuasa dua saiz kelompok latihan, sekali gus mengurangkan masa dan ruang overhed pengubah graf dalam latihan. fasa. Selain itu, kaedah persampelan ini membolehkan model memberi perhatian lebih kepada kumpulan latihan semasa semasa latihan.
Walaupun data input dijadikan sampel, memandangkan perwakilan token graf awal kami mengandungi perhubungan topologi antara nod, jujukan token sampel masih boleh mencerminkan maklumat semua nod dalam keseluruhan graf pada tahap tertentu.
Kaedah pensampelan anchor dalam perhatian sendiri
Walaupun pensampelan jujukan token mengurangkan kerumitan daripada kuasa dua bilangan nod kepada kuasa dua saiz kelompok, kerumitan aras kuasa dua mempunyai kesan yang lebih besar pada saiz kelompok Pengehadan menjadikannya mustahil untuk menggunakan kelompok yang lebih besar untuk latihan model, sekali gus menjejaskan keseluruhan masa latihan dan kestabilan latihan.
Untuk mengurangkan masalah ini, bahagian pengubah OpenGraph tidak lagi memodelkan hubungan berpasangan antara semua token, sebaliknya, ia mengambil contoh beberapa titik anchor dan membahagikan pembelajaran hubungan antara semua nod kepada dua kali.
Penyulingan Pengetahuan Model Bahasa Besar
Disebabkan privasi data dan sebab-sebab lain, adalah sangat mencabar untuk mendapatkan data dari pelbagai bidang untuk melatih model graf umum. Merasai keupayaan pengetahuan dan pemahaman yang menakjubkan yang ditunjukkan oleh model bahasa besar (LLM), kami memanfaatkan kuasanya untuk menjana pelbagai data berstruktur graf untuk latihan model graf am. Mekanisme penambahan data yang kami reka bentuk membolehkan data graf dipertingkat LLM untuk menganggarkan ciri graf dunia sebenar dengan lebih baik, dengan itu meningkatkan perkaitan dan kegunaan data ditambah.
Penjanaan nod berasaskan LLM
Apabila menjana graf, langkah awal kami ialah mencipta set nod yang sesuai untuk senario aplikasi tertentu. Setiap nod mempunyai huraian ciri berasaskan teks yang memudahkan proses penjanaan kelebihan seterusnya.
Walau bagaimanapun, apabila berhadapan dengan senario dunia sebenar, tugas ini boleh menjadi sangat mencabar kerana saiz set nod yang besar. Contohnya, pada platform e-dagang, data graf mungkin mengandungi berbilion produk. Oleh itu, dengan cekap membolehkan LLM menjana sejumlah besar nod menjadi cabaran yang ketara.
Untuk menangani cabaran di atas, kami menggunakan strategi membahagikan nod umum secara berterusan kepada subkategori yang lebih terperinci.Sebagai contoh, apabila menjana nod produk dalam senario e-dagang, mula-mula gunakan gesaan pertanyaan LLM yang serupa dengan "Senaraikan subkategori semua produk pada platform e-dagang seperti Taobao." LLM menjawab dengan senarai subkategori seperti "Pakaian," "Perkakas Dapur Rumah" dan "Elektronik."
Kemudian, kami meminta LLM untuk memperhalusi lagi setiap subkategori untuk meneruskan proses pemisahan berulang ini. Proses ini diulang sehingga kita mempunyai nod yang menyerupai contoh dunia sebenar, seperti nod dengan label "pakaian", "pakaian wanita", "sweater", "sweater berpoket" dan "sweter berpoket putih" Produk.
Algoritma Pokok Prompt
Proses pembahagian nod kepada subkategori dan menjana entiti berbutir halus mengikut struktur seperti pokok. Nod am awal (cth. "produk", "kertas pembelajaran mendalam") berfungsi sebagai akar dan entiti berbutir halus berfungsi sebagai nod daun. Kami menggunakan strategi pembayang pokok untuk melintasi dan menjana nod ini.
Penjanaan tepi berdasarkan persampelan LLM dan Gibbs
 Untuk menjana tepi, kami menggunakan algoritma pensampelan Gibbs dengan set nod yang dijana di atas. Algoritma bermula daripada sampel rawak dan berulang Setiap kali, berdasarkan sampel semasa, sampel yang diperoleh dengan menukar salah satu dimensi data dijadikan sampel.
Untuk menjana tepi, kami menggunakan algoritma pensampelan Gibbs dengan set nod yang dijana di atas. Algoritma bermula daripada sampel rawak dan berulang Setiap kali, berdasarkan sampel semasa, sampel yang diperoleh dengan menukar salah satu dimensi data dijadikan sampel.
Kunci kepada algoritma ini adalah untuk menganggarkan kebarangkalian bersyarat bagi dimensi data tertentu yang berubah di bawah syarat sampel semasa. Kami mencadangkan untuk melaksanakan anggaran kebarangkalian oleh LLM berdasarkan ciri teks yang diperoleh apabila nod dijana.
Memandangkan ruang set tepi adalah besar, untuk mengelakkan overhed besar yang disebabkan oleh membiarkan LLM menerokanya, kami mula-mula menggunakan LLM untuk mencirikan set nod, dan kemudian menggunakan operator persamaan mudah untuk mencirikan set nod berdasarkan pada vektor perwakilan. Kira hubungan antara mereka. Dalam rangka kerja penjanaan kelebihan di atas, kami juga mengguna pakai tiga teknik penting berikut untuk pelarasan. Normalisasi kebarangkalian dinamik Kaedah.
Kaedah ini secara dinamik mengekalkan nilai anggaran persamaan T' terkini semasa proses pensampelan, mengira min dan sisihan piawai mereka, dan akhirnya memetakan anggaran persamaan semasa kepada julat taburan dua sisihan piawai di atas dan di bawah min Ini menghasilkan anggaran kebarangkalian lebih kurang [0, 1].
Memperkenalkan lokaliti nod
Kaedah penjanaan kelebihan berdasarkan LLM secara berkesan boleh menentukan potensi hubungan sambungan mereka berdasarkan persamaan semantik nod.
Walau bagaimanapun, ia cenderung mencipta terlalu banyak perkaitan antara semua nod yang berkaitan secara semantik, mengabaikan konsep lokaliti yang penting dalam graf dunia sebenar.
Di dunia nyata, nod lebih berkemungkinan disambungkan kepada subset nod yang berkaitan kerana ia biasanya hanya mempunyai interaksi terhad dengan subset nod. Untuk memodelkan sifat penting ini, kaedah yang mengambil kira lokaliti semasa penjanaan kelebihan diperkenalkan.Setiap nod diberikan indeks lokaliti secara rawak Kebarangkalian interaksi antara dua nod dipengaruhi oleh pengecilan perbezaan mutlak indeks lokaliti Semakin besar perbezaan indeks lokaliti nod, semakin serius pengecilan akan jadi.
Suntikan corak topologi graf
Untuk menjadikan data graf yang dijana lebih konsisten dengan corak struktur topologi, kami menjana perwakilan nod yang diubah suai sekali lagi semasa proses penjanaan graf pertama.
Perwakilan nod ini diperolehi pada graf yang dijana awal menggunakan rangkaian konvolusi graf ringkas Ia boleh mematuhi ciri pengedaran data berstruktur graf dan mengelakkan peralihan pengedaran antara ruang graf dan teks. Akhir sekali, berdasarkan perwakilan nod yang disemak semula, kami melakukan pensampelan graf sekali lagi untuk mendapatkan data struktur graf akhir. Pengesahan eksperimen
Dalam percubaan, kami hanya menggunakan set data yang dijana berdasarkan LLM untuk latihan model OpenGraph, dan set data ujian adalah semua set data sebenar dalam pelbagai senario aplikasi, dan termasuk klasifikasi nod dan rantaian Terdapat dua jenis tugas ramalan jalan. Tetapan khusus percubaan adalah seperti berikut:
0-shot tetapan
Untuk mengesahkan keupayaan ramalan sampel sifar OpenGraph, OpenGraph telah diuji pada set data latihan yang dihasilkan menggunakan set data ujian sebenar yang berbeza sama sekali Menjalankan ujian keberkesanan. Tiada pertindihan antara set data latihan dan set data ujian dari segi nod, tepi, ciri dan label.
Tetapan beberapa syot
Oleh kerana kebanyakan kaedah sedia ada tidak dapat melaksanakan ramalan sifar syot yang berkesan, kami menggunakan ramalan beberapa syot untuk mengujinya. Kaedah garis dasar boleh dilatih terlebih dahulu pada data pra-latihan dan kemudian dilatih, diperhalusi, atau diisyaratkan untuk ditala halus menggunakan sampel k-shot.
Perbandingan kesan keseluruhan
Hasil ujian ke atas 2 tugasan dan sejumlah 8 set data ujian adalah seperti berikut.
Ia boleh diperhatikan:
1) Dalam kes set data silang, kesan ramalan sampel sifar OpenGraph mempunyai kelebihan yang lebih besar daripada kaedah sedia ada. 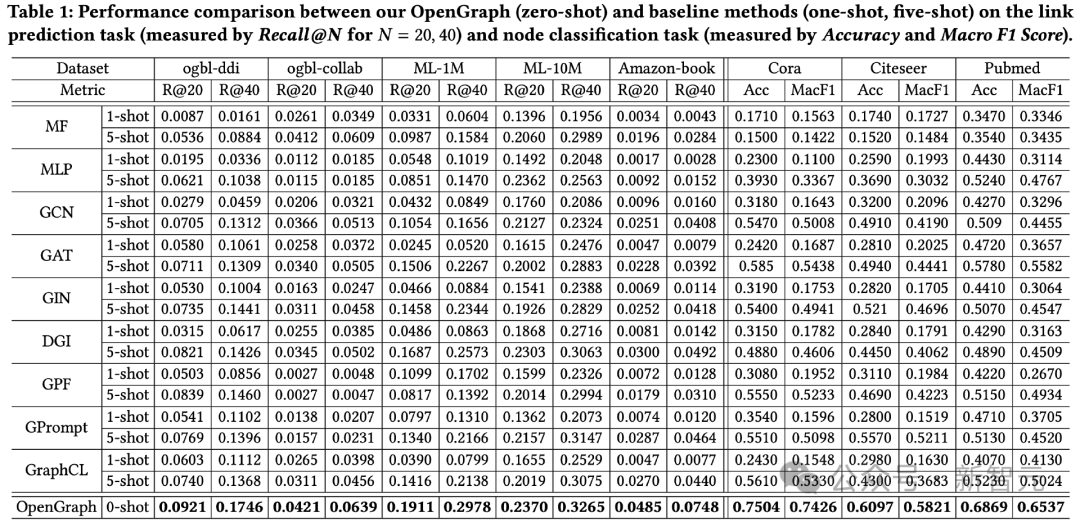
Penyelidikan Tokenizer Grafik
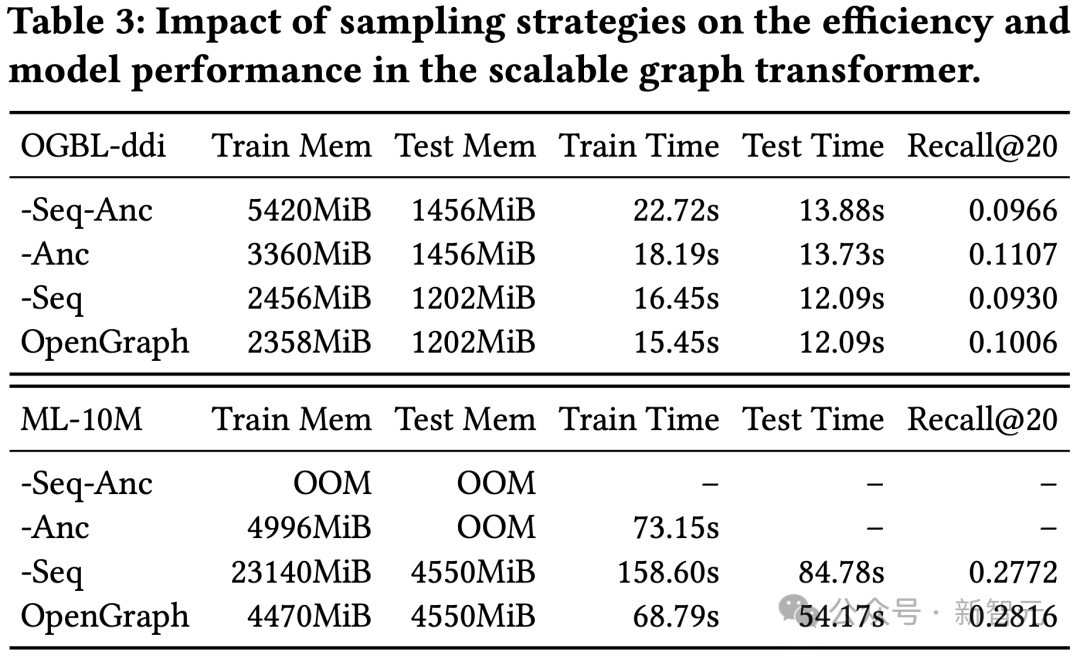
Seterusnya kita meneroka kesan reka bentuk tokenizer imej pada kesannya. Mula-mula kami melaraskan hujung pelicinan matriks bersebelahan dan menguji kesannya terhadap kesannya. Kesannya dilemahkan teruk pada tertib 0, menunjukkan kepentingan menggunakan pelicinan tertib lebih tinggi. Kedua, kami menggantikan fungsi pemetaan sedar topologi dengan kaedah mudah lain, termasuk perwakilan id satu panas yang boleh dipelajari merentas set data, pemetaan rawak dan perwakilan boleh dipelajari berdasarkan darjah nod. Hasilnya menunjukkan bahawa ketiga-tiga alternatif adalah kurang berkesan. Antaranya, perwakilan id pembelajaran merentasi set data mempunyai kesan yang paling teruk semua kaedah alternatif berprestasi terbaik, tetapi masih jauh daripada pemetaan mengetahui topologi kami. Untuk mengesahkan keberkesanan kaedah penyulingan pengetahuan berasaskan LLM, kami menggunakan set data ujian pra-latihan yang berbeza dan mengujinya pada set OpenGraph yang berbeza pada kesannya. Set data pra-latihan yang dibandingkan dalam percubaan ini termasuk versi yang mengalih keluar helah tertentu dalam kaedah penjanaan kami sahaja, dua set data sebenar Yelp2018 dan Gowalla yang tidak berkaitan dengan set data ujian, dan ML berkaitan dengan set data ujian. set data 10M, ia boleh dilihat daripada keputusan: 1) Secara keseluruhannya, set data yang kami hasilkan boleh menghasilkan keputusan yang lebih baik pada semua data ujian. 2) Teknik tiga generasi yang diuji semuanya mempunyai kesan peningkatan yang ketara. 3) Menggunakan set data sebenar (Yelp, Gowalla) untuk latihan mungkin mempunyai kesan negatif, yang mungkin disebabkan oleh perbezaan pengedaran antara set data sebenar yang berbeza. 4) ML-10M mencapai keputusan terbaik pada kedua-dua ML-1M dan ML-10M, yang menunjukkan bahawa menggunakan set data latihan yang serupa boleh menghasilkan hasil yang lebih baik. . Hasil kajian menunjukkan bahawa kedua-dua kaedah pensampelan boleh mengoptimumkan ruang dan masa overhed model semasa proses latihan dan ujian. Dari segi kesan, pensampelan jujukan token memberi kesan positif terhadap kesan model, manakala keputusan pada set data ddi menunjukkan pensampelan hidangan anchor memberi kesan negatif terhadap kesan model. Kesimpulan
Fokus utama penyelidikan ini adalah untuk membangunkan rangka kerja yang sangat boleh disesuaikan yang mampu menangkap dan memahami corak topologi kompleks dengan tepat dalam pelbagai struktur graf. Dengan memanfaatkan potensi model yang dicadangkan, kami menyasarkan untuk meningkatkan dengan ketara keupayaan generalisasi model untuk berprestasi baik dalam tugasan pembelajaran graf sifar termasuk pelbagai aplikasi hiliran. Melalui eksperimen yang meluas pada berbilang set data penanda aras, kami mengesahkan keupayaan generalisasi cemerlang model itu. Kajian ini membuat percubaan penerokaan awal ke arah model asas graf. Dalam kerja akan datang, kami merancang untuk memperkasakan rangka kerja kami untuk menemui sambungan dan struktur bising secara automatik dengan pengaruh pembelajaran berlawanan, sambil mempelajari corak struktur umum dan boleh dipindahkan untuk pelbagai graf. 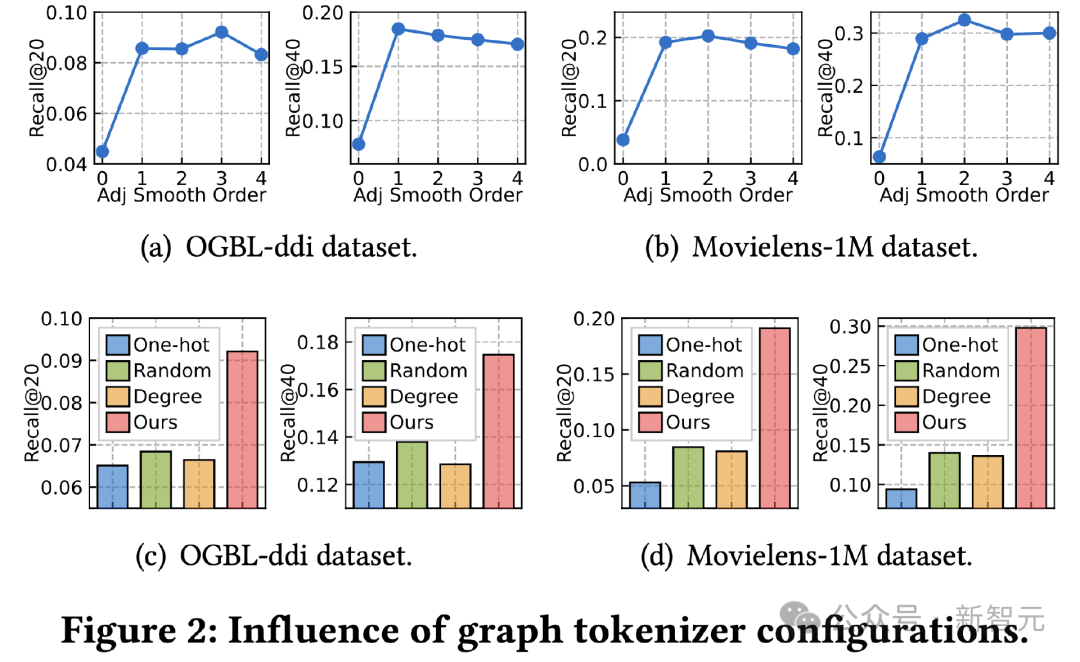
Penyelidikan set data pra-latihan
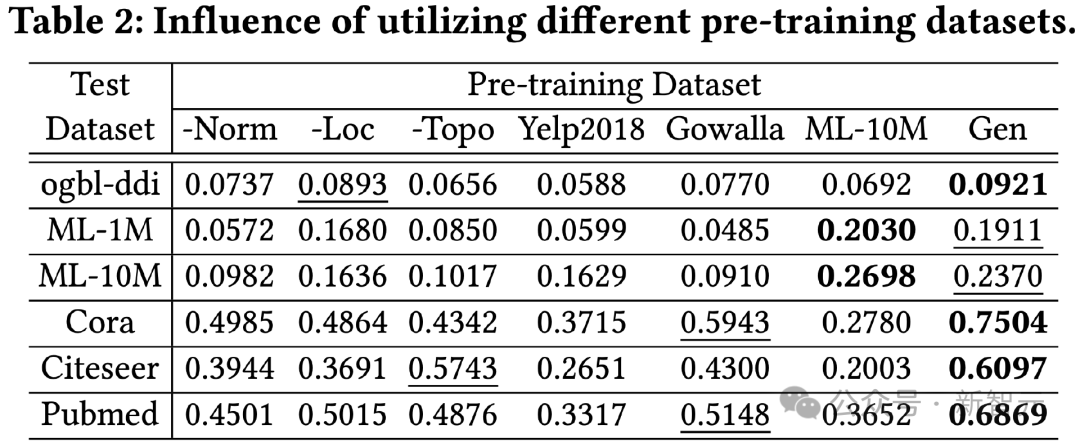
Untuk meningkatkan lagi kecekapan dan keteguhan OpenGraph, kami membina model kami berdasarkan seni bina pengubah graf boleh skala dan mekanisme penambahan data berasaskan LLM.
Atas ialah kandungan terperinci Mengatasi tiga masalah utama 'model berasaskan graf' buat kali pertama! OpenGraph sumber terbuka HKU: pembelajaran sampel sifar menyesuaikan diri dengan pelbagai tugas hiliran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1663
1663
 14
1419
52
1313
25
1264
29
1237
24
14
1419
52
1313
25
1264
29
1237
24

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
 Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Baru-baru ini, bulatan tentera telah terharu dengan berita: jet pejuang tentera AS kini boleh melengkapkan pertempuran udara automatik sepenuhnya menggunakan AI. Ya, baru-baru ini, jet pejuang AI tentera AS telah didedahkan buat pertama kali, mendedahkan misterinya. Nama penuh pesawat pejuang ini ialah Variable Stability Simulator Test Aircraft (VISTA). Ia diterbangkan sendiri oleh Setiausaha Tentera Udara AS untuk mensimulasikan pertempuran udara satu lawan satu. Pada 2 Mei, Setiausaha Tentera Udara A.S. Frank Kendall berlepas menggunakan X-62AVISTA di Pangkalan Tentera Udara Edwards Ambil perhatian bahawa semasa penerbangan selama satu jam, semua tindakan penerbangan telah diselesaikan secara autonomi oleh AI! Kendall berkata - "Sejak beberapa dekad yang lalu, kami telah memikirkan tentang potensi tanpa had pertempuran udara-ke-udara autonomi, tetapi ia sentiasa kelihatan di luar jangkauan." Namun kini,
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
Ditulis di atas & pemahaman peribadi pengarang: Kertas kerja ini didedikasikan untuk menyelesaikan cabaran utama model bahasa besar multimodal semasa (MLLM) dalam aplikasi pemanduan autonomi, iaitu masalah melanjutkan MLLM daripada pemahaman 2D kepada ruang 3D. Peluasan ini amat penting kerana kenderaan autonomi (AV) perlu membuat keputusan yang tepat tentang persekitaran 3D. Pemahaman spatial 3D adalah penting untuk AV kerana ia memberi kesan langsung kepada keupayaan kenderaan untuk membuat keputusan termaklum, meramalkan keadaan masa depan dan berinteraksi dengan selamat dengan alam sekitar. Model bahasa besar berbilang mod semasa (seperti LLaVA-1.5) selalunya hanya boleh mengendalikan input imej resolusi rendah (cth.) disebabkan oleh had resolusi pengekod visual, had panjang jujukan LLM. Walau bagaimanapun, aplikasi pemanduan autonomi memerlukan
 Pemula AI secara kolektif menukar pekerjaan kepada OpenAI, dan pasukan keselamatan berkumpul semula selepas Ilya pergi!
Jun 08, 2024 pm 01:00 PM
Pemula AI secara kolektif menukar pekerjaan kepada OpenAI, dan pasukan keselamatan berkumpul semula selepas Ilya pergi!
Jun 08, 2024 pm 01:00 PM
Minggu lalu, di tengah gelombang peletakan jawatan dalaman dan kritikan luar, OpenAI dibelenggu oleh masalah dalaman dan luaran: - Pelanggaran kakak balu itu mencetuskan perbincangan hangat global - Pekerja menandatangani "fasal tuan" didedahkan satu demi satu - Netizen menyenaraikan " Ultraman " tujuh dosa maut" ” Pembasmi khabar angin: Menurut maklumat dan dokumen bocor yang diperolehi oleh Vox, kepimpinan kanan OpenAI, termasuk Altman, sangat mengetahui peruntukan pemulihan ekuiti ini dan menandatanganinya. Di samping itu, terdapat isu serius dan mendesak yang dihadapi oleh OpenAI - keselamatan AI. Pemergian lima pekerja berkaitan keselamatan baru-baru ini, termasuk dua pekerjanya yang paling terkemuka, dan pembubaran pasukan "Penjajaran Super" sekali lagi meletakkan isu keselamatan OpenAI dalam perhatian. Majalah Fortune melaporkan bahawa OpenA
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
