
 Peranti teknologi
AI
Model besar Apple MM1 memasuki pasaran: 30 bilion parameter, multi-modal, seni bina MoE, lebih separuh daripada pengarang adalah orang Cina
Peranti teknologi
AI
Model besar Apple MM1 memasuki pasaran: 30 bilion parameter, multi-modal, seni bina MoE, lebih separuh daripada pengarang adalah orang Cina
Model besar Apple MM1 memasuki pasaran: 30 bilion parameter, multi-modal, seni bina MoE, lebih separuh daripada pengarang adalah orang Cina

Sejak tahun ini, Apple jelas telah meningkatkan penekanan dan pelaburannya dalam kecerdasan buatan generatif (GenAI). Pada mesyuarat pemegang saham Apple baru-baru ini, Ketua Pegawai Eksekutif Apple Tim Cook berkata bahawa syarikat itu merancang untuk membuat kemajuan yang ketara dalam bidang GenAI tahun ini. Di samping itu, Apple mengumumkan bahawa ia telah meninggalkan projek pembuatan kereta selama 10 tahun, yang menyebabkan beberapa ahli pasukan yang pada asalnya terlibat dalam pembuatan kereta mula beralih ke bidang GenAI.
Melalui inisiatif ini, Apple telah menunjukkan kepada dunia luar keazaman mereka untuk mengukuhkan GenAI. Pada masa ini, teknologi dan produk GenAI dalam bidang pelbagai modal telah menarik banyak perhatian, terutamanya Sora OpenAI. Apple sememangnya berharap untuk membuat satu kejayaan dalam bidang ini.
Dalam kertas penyelidikan yang dikarang bersama "MM1: Kaedah, Analisis & Insights daripada Pra-latihan LLM Multimodal", Apple mendedahkan hasil penyelidikan mereka berdasarkan pra-latihan multimodal dan melancarkan perpustakaan yang mengandungi sehingga 30B siri multimodal Parametrik LLM model.

Alamat kertas: https://arxiv.org/pdf/2403.09611.pdf
Dalam penyelidikan, pasukan menjalankan perbincangan mendalam tentang kritikal komponen seni bina pemilihan dan data yang berbeza. Melalui pemilihan pengekod imej yang teliti, penyambung bahasa visual dan pelbagai data pra-latihan, mereka meringkaskan beberapa garis panduan reka bentuk yang penting. Secara khusus, sumbangan utama kajian ini merangkumi aspek-aspek berikut.
Pertama, penyelidik menjalankan eksperimen ablasi berskala kecil pada keputusan seni bina model dan pemilihan data pra-latihan, dan menemui beberapa trend yang menarik. Kepentingan aspek reka bentuk pemodelan adalah dalam susunan berikut: peleraian imej, kehilangan dan kapasiti pengekod visual, dan data pra-latihan pengekod visual.
Kedua, penyelidik menggunakan tiga jenis data pra-latihan yang berbeza: kapsyen imej, teks imej bersilang dan data teks biasa. Mereka mendapati bahawa mengenai prestasi beberapa tangkapan dan teks sahaja, data latihan berjalin dan teks sahaja adalah sangat penting, manakala untuk prestasi tangkapan sifar, data sari kata adalah yang paling penting. Arah aliran ini berterusan selepas penalaan halus diselia (SFT), menunjukkan bahawa keputusan prestasi dan pemodelan yang dibentangkan semasa pra-latihan dikekalkan selepas penalaan halus.
Akhirnya, penyelidik membina MM1, siri model pelbagai mod dengan parameter sehingga 30 bilion (yang lain 3 bilion dan 7 bilion), yang terdiri daripada model padat dan varian pakar campuran (MoE), Bukan sahaja mencapai SOTA dalam metrik pra-latihan, ia juga mengekalkan prestasi kompetitif selepas menyelia penalaan halus pada siri penanda aras pelbagai mod sedia ada.
Model MM1 pra-latihan berprestasi cemerlang pada sari kata dan tugasan soal jawab dalam senario beberapa syot, mengatasi prestasi Emu2, Flamingo dan IDEFICS. MM1 selepas penalaan halus diselia juga menunjukkan daya saing yang kukuh pada 12 penanda aras pelbagai mod.
Terima kasih kepada pra-latihan berbilang modal berskala besar, MM1 mempunyai prestasi yang baik dalam ramalan konteks, penaakulan berbilang imej dan rantaian pemikiran. Begitu juga, MM1 menunjukkan keupayaan pembelajaran beberapa pukulan yang kuat selepas penalaan arahan.


Gambaran keseluruhan kaedah: Rahsia membina MM1
Membina MLLM (Model Bahasa Besar Berbilang Modal) ialah satu model bahasa besar berbilang mod. Walaupun reka bentuk seni bina peringkat tinggi dan proses latihan adalah jelas, kaedah pelaksanaan khusus tidak selalunya jelas. Dalam kerja ini, penyelidik menerangkan secara terperinci ablasi yang dilakukan untuk membina model berprestasi tinggi. Mereka meneroka tiga arah keputusan reka bentuk utama:
- Seni bina: Para penyelidik melihat pengekod imej pra-latihan yang berbeza dan meneroka pelbagai kaedah menyambungkan LLM dengan pengekod ini.
- Data: Para penyelidik mempertimbangkan pelbagai jenis data dan berat campuran relatifnya.
- Prosedur latihan: Para penyelidik meneroka cara melatih MLLM, termasuk hiperparameter dan bahagian model mana yang dilatih apabila.
Tetapan ablasi
Memandangkan latihan MLLM yang besar menggunakan banyak sumber, para penyelidik menggunakan tetapan ablasi yang dipermudahkan. Konfigurasi asas ablasi adalah seperti berikut:
- Pengekod imej: Model ViT-L/14 dilatih dengan kehilangan CLIP pada DFN-5B dan VeCap-300M saiz imej ialah 336×336.
- Penyambung bahasa visual: C-Abstractor, mengandungi 144 token imej.
- Data pra-latihan: imej sari kata bercampur (45%), dokumen teks imej bersilang (45%) dan data teks biasa (10%).
- Model Bahasa: Model Bahasa Penyahkod Transformer 1.2B.
Untuk menilai keputusan reka bentuk yang berbeza, penyelidik menggunakan prestasi sifar pukulan dan beberapa pukulan (4 dan 8 sampel) pada pelbagai tugasan VQA dan penerangan imej: COCO Captioning, NoCaps, TextCaps, VQAv2 , TextVQA, VizWiz , GQA dan OK-VQA.
Eksperimen Ablasi Seni Bina Model
Para penyelidik menganalisis komponen yang membolehkan LLM memproses data visual. Secara khusus, mereka mengkaji (1) cara untuk melatih pengekod visual secara optimum, dan (2) cara menyambungkan ciri visual ke ruang LLM (lihat Rajah 3 kiri).
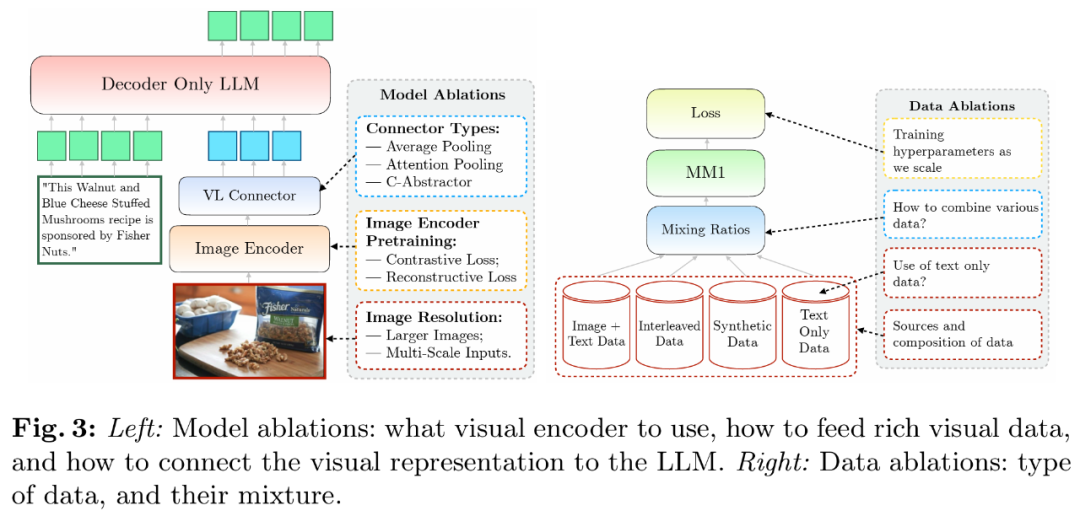
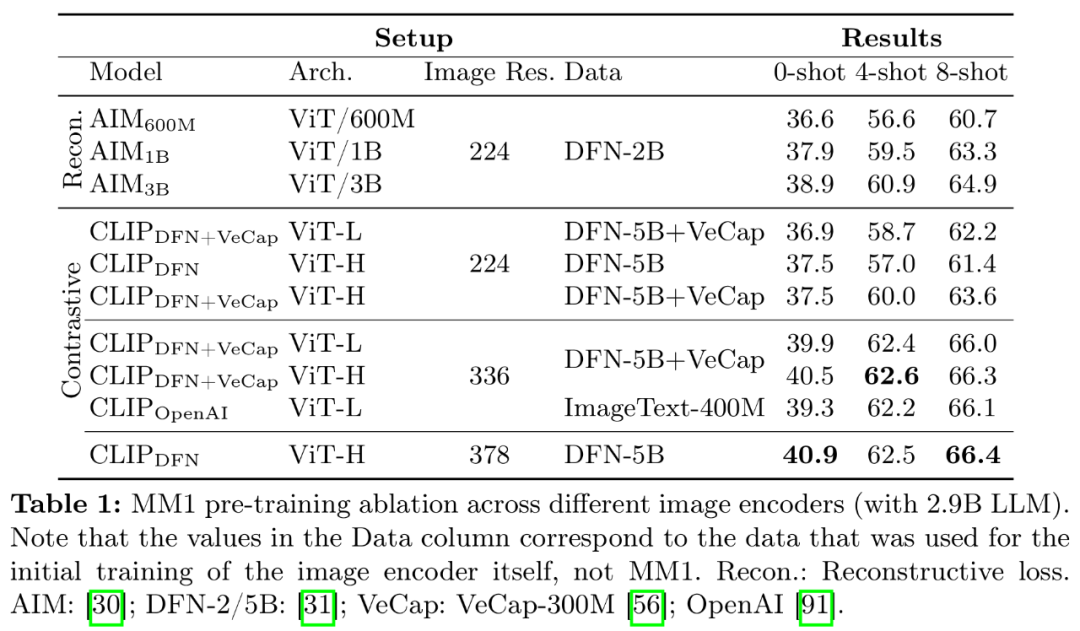
- Latihan pra pengekod imej. Dalam proses ini, penyelidik terutamanya menyimpulkan kepentingan resolusi imej dan matlamat pra-latihan pengekod imej. Perlu diingatkan bahawa tidak seperti eksperimen ablasi lain, penyelidik menggunakan 2.9B LLM (bukannya 1.2B) untuk memastikan kapasiti yang mencukupi untuk menggunakan beberapa pengekod imej yang lebih besar.
- Pengalaman pengekod: Peleraian imej mempunyai impak yang paling besar, diikuti dengan saiz model dan komposisi data latihan. Seperti yang ditunjukkan dalam Jadual 1, meningkatkan resolusi imej daripada 224 kepada 336 meningkatkan semua metrik untuk semua seni bina sebanyak lebih kurang 3%. Meningkatkan saiz model daripada ViT-L kepada ViT-H menggandakan parameter, tetapi peningkatan prestasi adalah sederhana, biasanya kurang daripada 1%. Akhir sekali, menambah VeCap-300M, set data kapsyen sintetik, meningkatkan prestasi lebih daripada 1% dalam senario beberapa tangkapan.
- Penyambung bahasa visual dan resolusi imej. Matlamat komponen ini adalah untuk mengubah perwakilan visual ke ruang LLM. Memandangkan pengekod imej ialah ViT, outputnya adalah sama ada satu pembenaman tunggal atau satu set penyusunan grid yang sepadan dengan segmen imej input. Oleh itu, susunan ruang token imej perlu ditukar kepada susunan berjujukan LLM. Pada masa yang sama, perwakilan token imej sebenar juga mesti dipetakan ke ruang pembenaman perkataan.
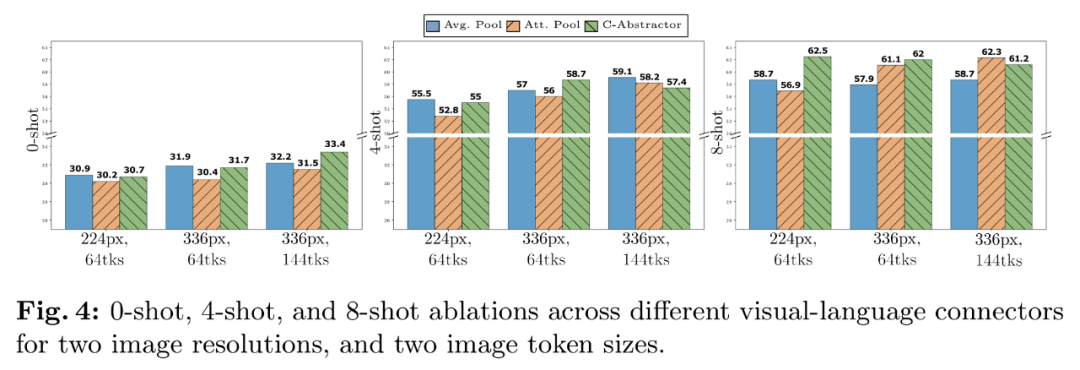
- Pengalaman penyambung VL: Bilangan token visual dan peleraian imej adalah yang paling penting, manakala jenis penyambung VL mempunyai sedikit impak. Seperti yang ditunjukkan dalam Rajah 4, apabila bilangan token visual atau/dan resolusi imej meningkat, kadar pengecaman sampel sifar dan beberapa sampel akan meningkat.
Percubaan ablasi data pra-latihan
Secara amnya, latihan model dibahagikan kepada dua peringkat: pra-latihan dan penalaan arahan. Peringkat pertama menggunakan data skala rangkaian, dan peringkat terakhir menggunakan data susun khusus misi. Perkara berikut memfokuskan pada fasa pra-latihan artikel ini dan memperincikan pemilihan data penyelidik (Rajah 3 kanan).
Terdapat dua jenis data yang biasa digunakan untuk melatih MLLM: data kapsyen yang terdiri daripada perihalan pasangan imej dan teks dan dokumen bersilang teks imej daripada web. Jadual 2 ialah senarai lengkap set data:

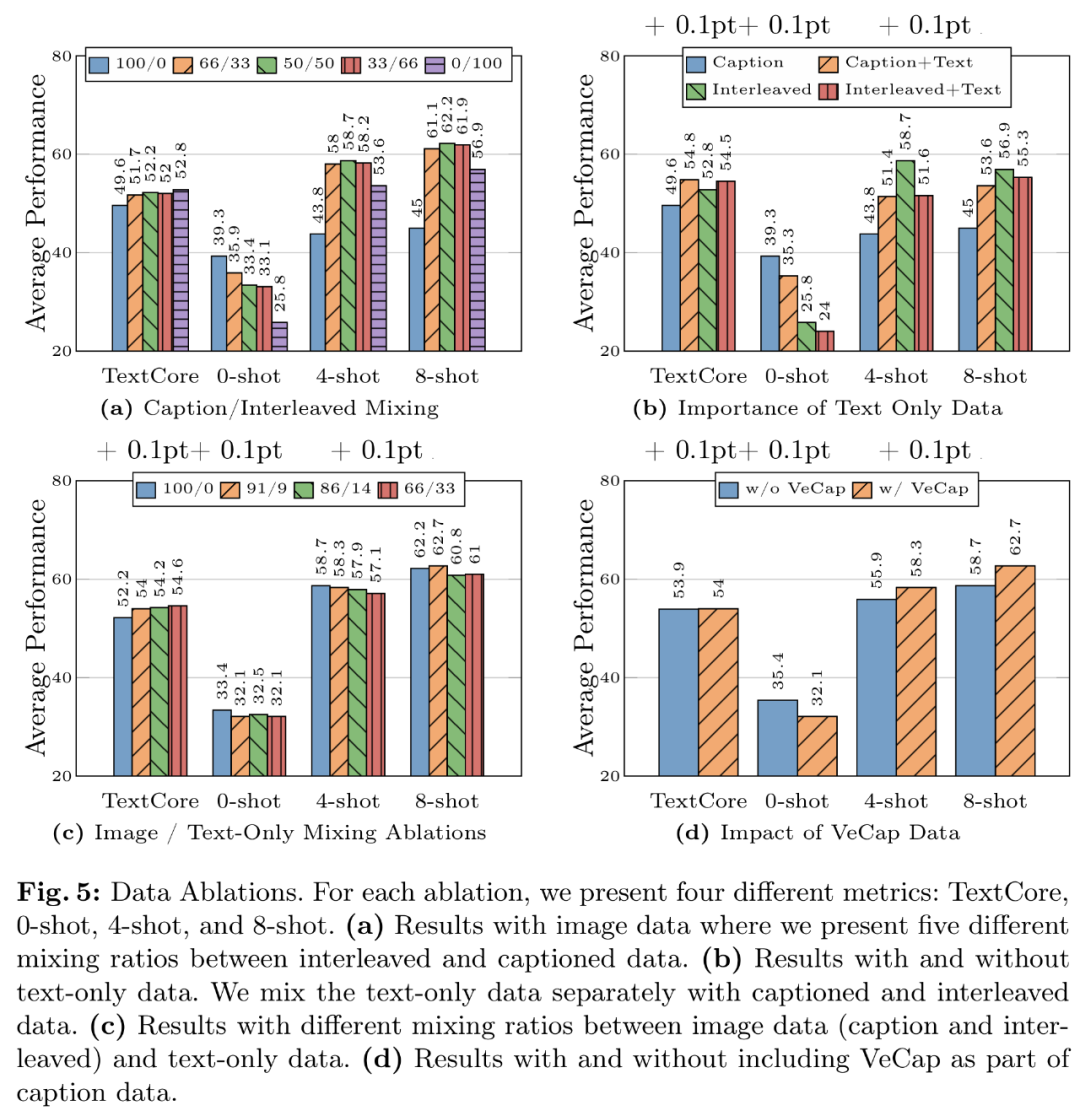
- Pengalaman data 1: Data bersilang membantu meningkatkan prestasi beberapa sampel dan teks biasa, manakala data sari kata meningkatkan prestasi sifar sampel. Rajah 5a menunjukkan keputusan untuk gabungan berbeza data bersilang dan sari kata.
- Pengalaman data 2: Data teks biasa membantu meningkatkan prestasi beberapa sampel dan teks biasa. Seperti yang ditunjukkan dalam Rajah 5b, menggabungkan data teks biasa dan data sari kata meningkatkan prestasi beberapa tangkapan.
- Data Pelajaran 3: Campurkan data imej dan teks dengan teliti untuk mendapatkan prestasi berbilang modal terbaik dan mengekalkan prestasi teks yang kukuh. Rajah 5c mencuba beberapa nisbah pencampuran antara imej (tajuk dan berjalin) dan data teks biasa.
- Pengalaman data 4: Data sintetik membantu dengan pembelajaran beberapa pukulan. Seperti yang ditunjukkan dalam Rajah 5d, data sintetik meningkatkan prestasi pembelajaran beberapa pukulan dengan ketara, dengan nilai mutlak masing-masing 2.4% dan 4%.
Model akhir dan kaedah latihan
Para penyelidik mengumpul keputusan ablasi sebelum ini dan menentukan resipi akhir untuk latihan pra-latihan pelbagai mod MM1:
- encoder imej mengambil kira encoder: Disebabkan kepentingan kadar, penyelidik menggunakan model ViT-H dengan resolusi 378x378px dan menggunakan sasaran CLIP untuk pra-latihan pada DFN-5B
- Penyambung bahasa visual: Memandangkan bilangan token visual ialah; yang paling penting, kajian Penulis menggunakan penyambung VL dengan 144 token. Seni bina sebenar nampaknya kurang penting, dan penyelidik memilih C-Abstract
- Data: Untuk mengekalkan prestasi sampel sifar dan beberapa sampel, penyelidik menggunakan data gabungan berikut dengan teliti: 45% imej; -dokumen berselang teks, 45 % dokumen teks imej dan 10% dokumen teks biasa.
Untuk meningkatkan prestasi model, penyelidik mengembangkan saiz LLM kepada parameter 3B, 7B dan 30B. Semua model tidak dibekukan sepenuhnya dengan pralatihan dengan saiz kelompok 512 jujukan dengan panjang jujukan 4096, sehingga 16 imej setiap jujukan dan resolusi 378 × 378. Semua model telah dilatih menggunakan rangka kerja AXLearn.
Mereka melakukan carian grid pada kadar pembelajaran pada skala kecil, 9M, 85M, 302M dan 1.2B, menggunakan regresi linear dalam ruang log untuk membuat kesimpulan perubahan daripada model yang lebih kecil kepada yang lebih besar (lihat Rajah 6), hasilnya ialah ramalan daripada kadar pembelajaran puncak optimum η memandangkan bilangan parameter (tidak terbenam) N:
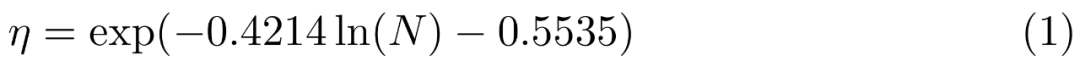
dilanjutkan oleh Campuran Pakar (KPM). Dalam eksperimen, penyelidik meneroka lebih lanjut cara untuk melanjutkan model padat dengan menambah lebih ramai pakar pada lapisan FFN model bahasa.
Untuk menukar model padat kepada MoE, cuma gantikan penyahkod bahasa padat dengan penyahkod bahasa MoE. Untuk melatih MoE, para penyelidik menggunakan hiperparameter latihan yang sama dan tetapan latihan yang sama seperti Dense Backbone 4, termasuk data latihan dan token latihan.
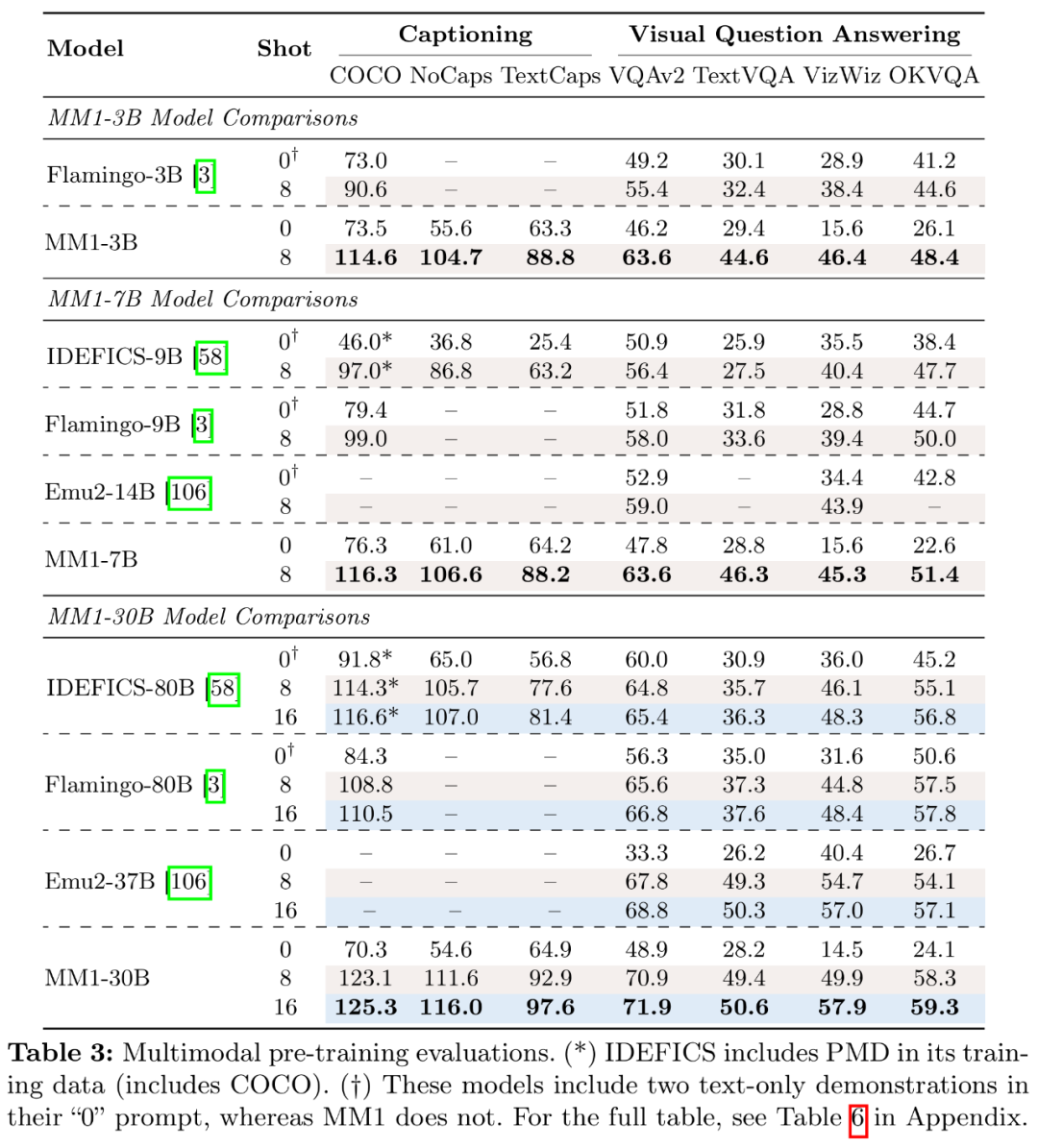
Berkenaan keputusan pra-latihan berbilang modal, para penyelidik menilai model pra-latihan pada tugasan sempadan atas dan VQA dengan gesaan yang sesuai. Jadual 3 menilai keputusan sifar sampel dan beberapa sampel:
Hasil penalaan halus diselia
Akhir sekali, penyelidik memperkenalkan penalaan halus diselia (SFT) yang dilatih di bahagian atas model.
Mereka mengikuti LLaVA-1.5 dan LLaVA-NeXT dan mengumpul kira-kira 1 juta sampel SFT daripada set data yang berbeza. Memandangkan resolusi imej yang lebih tinggi secara intuitif membawa kepada prestasi yang lebih baik, para penyelidik juga menggunakan kaedah SFT yang dilanjutkan kepada resolusi tinggi.
Hasil penalaan halus yang diselia adalah seperti berikut:
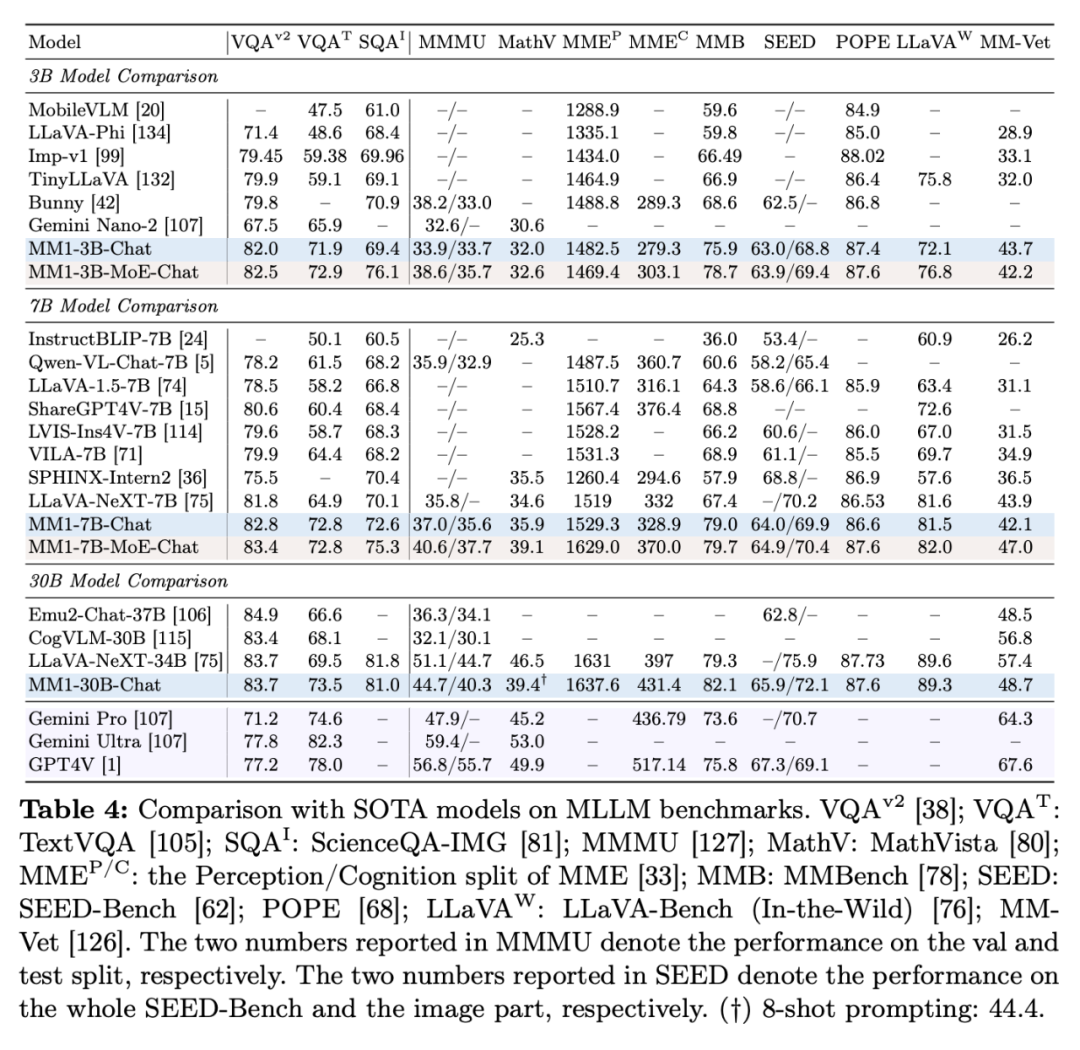
Jadual 4 menunjukkan perbandingan dengan SOTA, "-Chat" mewakili model MM1 selepas penalaan halus diselia.
Pertama sekali, secara purata, MM1-3B-Chat dan MM1-7B-Chat mengatasi semua model tersenarai dengan saiz yang sama. MM1-3B-Chat dan MM1-7B-Chat berprestasi baik pada VQAv2, TextVQA, ScienceQA, MMBench dan penanda aras terkini (MMMU dan MathVista).
Kedua, penyelidik meneroka dua model KPM: 3B-MoE (64 pakar) dan 6B-MoE (32 pakar). Model MoE Apple mencapai prestasi yang lebih baik daripada model padat dalam hampir semua penanda aras. Ini menunjukkan potensi besar untuk pengembangan lanjut KPM.
Ketiga, untuk model saiz 30B, MM1-30B-Chat berprestasi lebih baik daripada Emu2-Chat37B dan CogVLM-30B pada TextVQA, SEED dan MMMU. MM1 juga mencapai prestasi keseluruhan yang kompetitif berbanding LLaVA-NeXT.
Walau bagaimanapun, LLaVA-NeXT tidak menyokong inferens berbilang imej, dan juga tidak menyokong petunjuk beberapa tangkapan, kerana setiap imej diwakili sebagai 2880 token yang dihantar kepada LLM, manakala jumlah bilangan token dalam MM1 hanyalah 720. Ini mengehadkan aplikasi tertentu yang melibatkan berbilang imej.
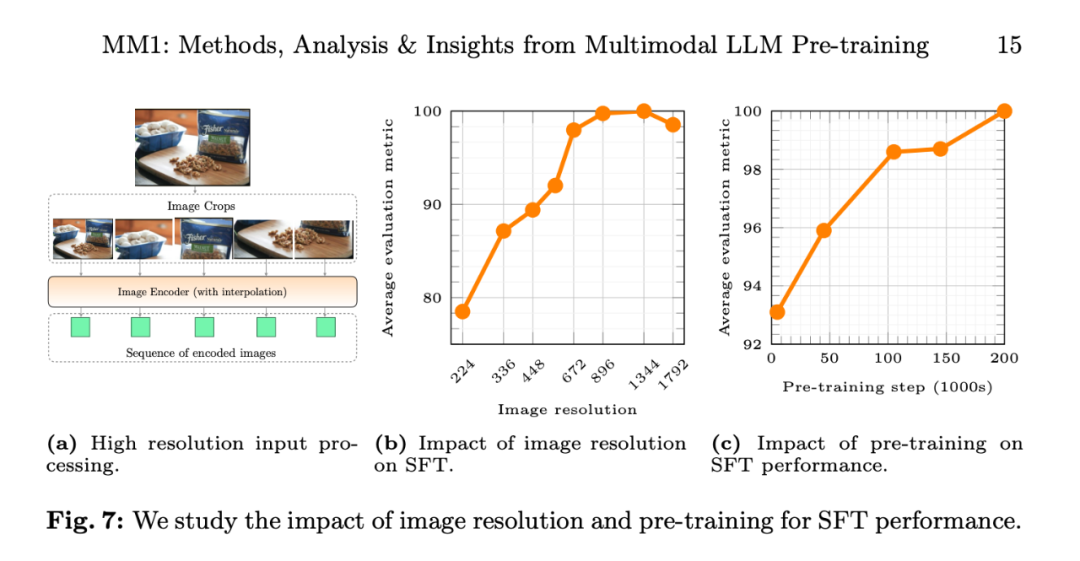
Rajah 7b menunjukkan kesan resolusi imej input pada prestasi purata metrik penilaian SFT, dan Rajah 7c menunjukkan bahawa apabila data pra-latihan meningkat, prestasi model terus bertambah baik.
Impak peleraian imej. Rajah 7b menunjukkan kesan resolusi imej input ke atas prestasi purata metrik penilaian SFT.
Impak pra-latihan: Rajah 7c menunjukkan bahawa apabila data pra-latihan meningkat, prestasi model terus bertambah baik.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Model besar Apple MM1 memasuki pasaran: 30 bilion parameter, multi-modal, seni bina MoE, lebih separuh daripada pengarang adalah orang Cina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
