
 Peranti teknologi
AI
Selesaikan tugasan 'Penjanaan Kod'! Fudan et al. melepaskan rangka kerja StepCoder: Pembelajaran pengukuhan daripada isyarat maklum balas pengkompil
Peranti teknologi
AI
Selesaikan tugasan 'Penjanaan Kod'! Fudan et al. melepaskan rangka kerja StepCoder: Pembelajaran pengukuhan daripada isyarat maklum balas pengkompil
Selesaikan tugasan 'Penjanaan Kod'! Fudan et al. melepaskan rangka kerja StepCoder: Pembelajaran pengukuhan daripada isyarat maklum balas pengkompil

Kemajuan model bahasa besar (LLM) telah memacu pembangunan bidang penjanaan kod ke tahap yang besar. Dalam penyelidikan terdahulu, pembelajaran pengukuhan (RL) dan isyarat maklum balas pengkompil telah digabungkan untuk meneroka ruang keluaran LLM untuk mengoptimumkan kualiti penjanaan kod.
but masih terdapat dua masalah:
1 ujian unit mungkin tidak meliputi kod kompleks, mengoptimumkan LLM menggunakan coretan kod yang tidak dilaksanakan adalah tidak berkesan.
Untuk menangani cabaran ini, penyelidik mencadangkan rangka kerja pembelajaran pengukuhan baharu yang dipanggil StepCoder, yang dibangunkan bersama oleh pakar dari Universiti Fudan, Universiti Sains dan Teknologi Huazhong dan Institut Teknologi Diraja. StepCoder mengandungi dua komponen utama yang direka untuk meningkatkan kecekapan dan kualiti penjanaan kod.
1. -pengoptimuman berbutir.
Pautan kertas: https://arxiv.org/pdf/2402.01391.pdf
Pautan projek: https://github.com/Ablustrund/APPS_Plus set data yang digunakan untuk latihan pembelajaran pengukuhan, disahkan secara manual untuk memastikan ketepatan ujian unit.
Hasil eksperimen menunjukkan bahawa kaedah itu meningkatkan keupayaan untuk meneroka ruang keluaran dan mengatasi prestasi kaedah terkini pada penanda aras yang sepadan.
Dalam proses penjanaan kod, penerokaan pembelajaran pengukuhan biasa (penerokaan) sukar untuk mengendalikan "persekitaran dengan ganjaran dan kelewatan yang jarang" dan "keperluan kompleks yang melibatkan urutan yang panjang".
Dalam peringkat CCCS (Curriculum of Code Completion Subtasks), penyelidik menguraikan masalah penerokaan yang kompleks kepada satu siri subtugas. Menggunakan sebahagian daripada penyelesaian kanonik sebagai gesaan, LLM boleh mula meneroka daripada jujukan mudah.
Pengiraan ganjaran hanya berkaitan dengan serpihan kod boleh laku, jadi adalah tidak tepat untuk menggunakan keseluruhan kod (bahagian merah dalam gambar) untuk mengoptimumkan LLM (bahagian kelabu dalam gambar).
Dalam peringkat FGO (Fine-Grained Optimization), penyelidik menutup token yang tidak dilaksanakan (bahagian merah) dalam ujian unit dan hanya menggunakan token yang dilaksanakan (bahagian hijau) untuk mengira fungsi kehilangan, yang boleh memberikan Butiran terperinci pengoptimuman.
Pengetahuan awal 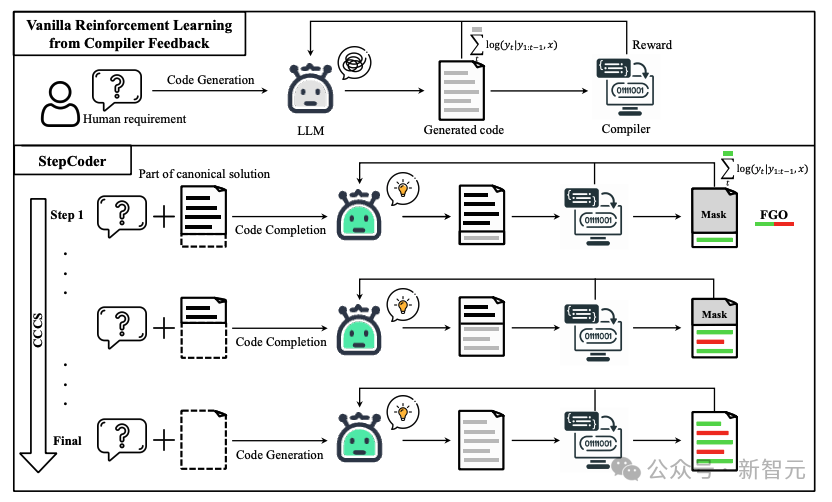
Andaikan
ialah set data latihan untuk penjanaan kod, di mana x, y, u mewakili keperluan manusia (iaitu perihalan ujian tugasan), penyelesaian standard dan sampel unit masing-masing .
Untuk keperluan manusia x, penyelesaian piawainya y boleh dinyatakan sebagai
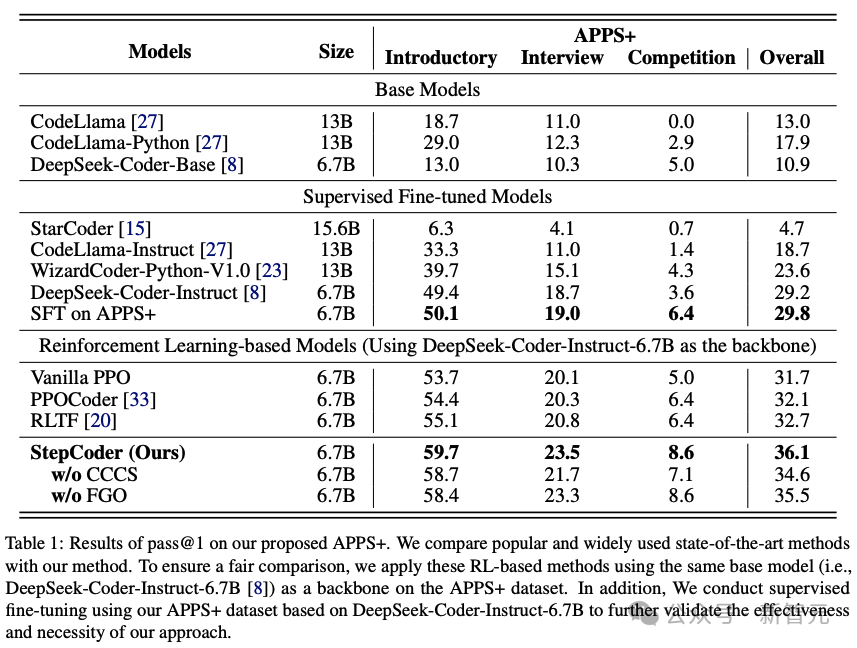
; dalam fasa penjanaan kod, memandangkan keperluan manusia x, keadaan terakhir ialah koleksi kod yang lulus ujian unit u. Butiran kaedah ; FGO direka untuk tugas penjanaan kod dan menyediakan pengoptimuman terperinci dengan mengira kerugian hanya untuk serpihan kod yang dilaksanakan. CCCS Semasa proses penjanaan kod, menyelesaikan keperluan manusia yang kompleks selalunya memerlukan model dasar untuk mengambil urutan tindakan yang panjang. Pada masa yang sama, maklum balas pengkompil ditangguhkan dan jarang, iaitu model dasar hanya menerima ganjaran selepas keseluruhan kod dijana. Dalam kes ini, penerokaan adalah sangat sukar. Inti kaedah ini adalah untuk menguraikan senarai panjang masalah penerokaan kepada satu siri subtugasan yang pendek dan mudah diterokai Para penyelidik memudahkan penjanaan kod menjadi subtugasan penyelesaian kod, di mana subtugasan diwakili oleh biasa. contoh dalam set data latihan Penyelesaian dibina secara automatik. Untuk keperluan manusia x, pada peringkat latihan awal CCCS, titik permulaan s* untuk penerokaan ialah negeri berhampiran keadaan akhir. Secara khusus, penyelidik menyediakan permintaan manusia x dan separuh pertama penyelesaian standard Dengan mengandaikan bahawa y^ ialah jujukan gabungan xp dan trajektori output τ, iaitu, yˆ=(xp,τ), model ganjaran menyediakan ganjaran r berdasarkan ketepatan serpihan kod τ dengan y^ sebagai input. Para penyelidik menggunakan algoritma pengoptimuman dasar proksimal (PPO) untuk mengoptimumkan model dasar πθ dengan memanfaatkan ganjaran r dan trajektori τ. Semasa fasa pengoptimuman, segmen kod penyelesaian kanonik xp yang digunakan untuk memberikan pembayang akan bertopeng supaya ia tidak memberi kesan pada kecerunan kemas kini model dasar πθ. CCCS mengoptimumkan model dasar πθ dengan memaksimumkan fungsi pembangkang, dengan π^ref ialah model rujukan dalam PPO, yang dimulakan oleh model SFT. Semasa latihan berlangsung, titik permulaan s* penerokaan akan beransur-ansur menuju ke titik permulaan penyelesaian standard Secara khusus, ambang ρ ditetapkan untuk setiap sampel latihan, dan pengumpulan segmen kod yang dihasilkan setiap. masa πθ Apabila kadar ketepatan lebih besar daripada ρ, titik permulaan dialihkan ke permulaan. Pada peringkat latihan kemudian, proses penerokaan kaedah ini adalah setara dengan pembelajaran peneguhan asal, iaitu, s*=0, dan model dasar hanya menjana kod dengan keperluan manusia sebagai input. Sampel titik pengecaman awal s* pada kedudukan permulaan pernyataan bersyarat untuk melengkapkan segmen kod tidak bertulis yang tinggal. Secara khusus, lebih banyak pernyataan bersyarat, lebih banyak laluan bebas yang ada pada program, dan lebih tinggi kerumitan logiknya kerap. Kaedah pensampelan ini boleh mengekstrak struktur kod perwakilan secara sama rata sambil mengambil kira kedua-dua struktur semantik yang kompleks dan mudah dalam set data latihan. Untuk mempercepatkan fasa latihan, penyelidik menetapkan bilangan kursus untuk sampel ke-i kepada Titik utama CCC boleh diringkaskan seperti berikut: 1 untuk memulakan penerokaan dari negeri yang jauh dari jantina matlamat, tetapi penerokaan menjadi lebih mudah jika anda boleh memanfaatkan keadaan telah mempelajari cara mencapai matlamat anda. FGO Hubungan antara ganjaran dan tindakan dalam penjanaan kod adalah berbeza daripada tugasan pembelajaran pengukuhan yang lain (seperti Atari dalam penjanaan kod, satu set ganjaran yang tidak relevan untuk mengira ganjaran). kod yang dihasilkan boleh dikecualikan tindakan. Secara khusus, untuk ujian unit, maklum balas pengkompil hanya berkaitan dengan serpihan kod yang dilaksanakan Walau bagaimanapun, dalam matlamat pengoptimuman RL biasa, semua tindakan pada trajektori akan mengambil bahagian dalam pengiraan kecerunan dan pengiraan kecerunan adalah tidak tepat. Untuk meningkatkan ketepatan pengoptimuman, para penyelidik melindungi tindakan yang tidak dilaksanakan (iaitu token) dalam ujian unit dan kehilangan model strategi. APPS+dataset Pembelajaran pengukuhan memerlukan sejumlah besar data latihan berkualiti tinggi di kalangan penyelidik yang ada pada masa ini mendapati bahawa semasa penyiasatan. hanya APPS yang memenuhi keperluan ini Satu permintaan. Tetapi terdapat beberapa kejadian yang tidak betul dalam APPS, seperti input, output atau penyelesaian standard yang hilang, di mana penyelesaian standard mungkin tidak menyusun atau melaksanakan, atau terdapat perbezaan dalam output pelaksanaan. Untuk menambah baik set data APPS, penyelidik menapis contoh dengan input, output atau penyelesaian standard yang hilang, dan kemudian menyeragamkan format input dan output untuk memudahkan pelaksanaan dan perbandingan ujian unit, kemudian, untuk setiap contoh Ujian unit dan analisis manual dilakukan untuk menghapuskan kejadian kod yang tidak lengkap atau tidak berkaitan, ralat sintaks, penyalahgunaan API atau kebergantungan perpustakaan yang hilang. Untuk perbezaan dalam output, penyelidik menyemak huraian masalah secara manual, membetulkan output yang dijangkakan atau menghapuskan kejadian tersebut. Akhir sekali, kami membina set data APPS+, yang mengandungi 7456 kejadian Setiap kejadian termasuk penerangan masalah pengaturcaraan, penyelesaian standard, nama fungsi, ujian unit (iaitu input dan output) dan kod permulaan (iaitu penyelesaian standard) bahagian permulaan) . Untuk menilai prestasi LLM dan StepCoder lain dalam penjanaan kod, penyelidik menjalankan eksperimen pada set data APPS+. Hasilnya menunjukkan bahawa model berasaskan RL mengatasi model bahasa lain, termasuk model asas dan model SFT. Para penyelidik berpendapat bahawa pembelajaran pengukuhan boleh meningkatkan lagi kualiti penjanaan kod dengan meneroka ruang keluaran model dengan lebih cekap, berpandukan maklum balas pengkompil. Selain itu, StepCoder melepasi semua model garis dasar, termasuk kaedah berasaskan RL lain, dan mencapai skor tertinggi. Secara khusus, kaedah ini mencapai markah tinggi masing-masing 59.7%, 23.5% dan 8.6% dalam soalan ujian peringkat "Pengenalan", "Temuduga" dan "Pertandingan". Berbanding dengan kaedah berasaskan pembelajaran pengukuhan yang lain, kaedah ini cemerlang dalam meneroka ruang keluaran dengan memudahkan tugas penjanaan kod yang kompleks kepada subtugas pelengkap kod, dan proses FGO memainkan peranan penting dalam mengoptimumkan kesan model dasar dengan tepat. Ia juga boleh didapati bahawa pada set data APPS+ berdasarkan rangkaian seni bina yang sama, StepCoder berprestasi lebih baik daripada LLM yang diselia untuk penalaan halus berbanding dengan rangkaian tulang belakang, yang kedua hampir tidak meningkatkan kadar lulus kod yang dijana; yang Ia juga secara langsung menunjukkan bahawa menggunakan maklum balas pengkompil untuk mengoptimumkan model boleh meningkatkan kualiti kod yang dijana lebih daripada ramalan token seterusnya dalam penjanaan kod. 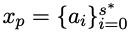 , dan melatih model dasar untuk melengkapkan kod mengikut x'=(x, xp).
, dan melatih model dasar untuk melengkapkan kod mengikut x'=(x, xp). 
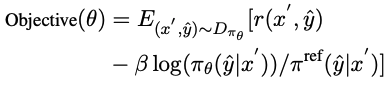
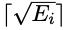 , di mana Ei ialah bilangan pernyataan bersyaratnya. Jangka masa kursus latihan sampel ke-i ialah
, di mana Ei ialah bilangan pernyataan bersyaratnya. Jangka masa kursus latihan sampel ke-i ialah 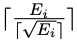 , bukan 1.
, bukan 1. 
Bahagian eksperimen

Hasil eksperimen
Atas ialah kandungan terperinci Selesaikan tugasan 'Penjanaan Kod'! Fudan et al. melepaskan rangka kerja StepCoder: Pembelajaran pengukuhan daripada isyarat maklum balas pengkompil. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Apabila menukar rentetan ke objek dalam vue.js, json.parse () lebih disukai untuk rentetan json standard. Untuk rentetan JSON yang tidak standard, rentetan boleh diproses dengan menggunakan ungkapan biasa dan mengurangkan kaedah mengikut format atau url yang dikodkan. Pilih kaedah yang sesuai mengikut format rentetan dan perhatikan isu keselamatan dan pengekodan untuk mengelakkan pepijat.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Untuk menetapkan masa untuk Vue Axios, kita boleh membuat contoh Axios dan menentukan pilihan masa tamat: dalam tetapan global: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dalam satu permintaan: ini. $ axios.get ('/api/pengguna', {timeout: 10000}).
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
 Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Ringkasan: Terdapat kaedah berikut untuk menukar array rentetan vue.js ke dalam tatasusunan objek: Kaedah asas: Gunakan fungsi peta yang sesuai dengan data yang diformat biasa. Permainan lanjutan: Menggunakan ungkapan biasa boleh mengendalikan format yang kompleks, tetapi mereka perlu ditulis dengan teliti dan dipertimbangkan. Pengoptimuman Prestasi: Memandangkan banyak data, operasi tak segerak atau perpustakaan pemprosesan data yang cekap boleh digunakan. Amalan Terbaik: Gaya Kod Jelas, Gunakan nama dan komen pembolehubah yang bermakna untuk memastikan kod ringkas.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
