
 Peranti teknologi
AI
Jangan tunggu OpenAI, yang pertama seperti Sora di dunia adalah sumber terbuka dahulu! Semua butiran latihan/berat model didedahkan sepenuhnya dan kosnya hanya $10,000
Peranti teknologi
AI
Jangan tunggu OpenAI, yang pertama seperti Sora di dunia adalah sumber terbuka dahulu! Semua butiran latihan/berat model didedahkan sepenuhnya dan kosnya hanya $10,000
Jangan tunggu OpenAI, yang pertama seperti Sora di dunia adalah sumber terbuka dahulu! Semua butiran latihan/berat model didedahkan sepenuhnya dan kosnya hanya $10,000

Tidak lama dahulu, OpenAI Sora dengan cepat menjadi popular dengan kesan penjanaan video yang menakjubkan, menyerlahkan perbezaannya dengan model video Vincent yang lain dan menjadi tumpuan perhatian global.
Susulan pelancaran proses pengeluaran semula inferens latihan Sora dengan pengurangan kos sebanyak 46% 2 minggu lalu, pasukan Colossal-AI membuat sumber terbuka sepenuhnya model penjanaan video seni bina seperti Sora pertama di dunia "Open-Sora 1.0" - meliputi Seluruh proses latihan, termasuk pemprosesan data, semua butiran latihan dan berat model, berganding bahu dengan peminat AI global untuk mempromosikan era baharu penciptaan video.
Alamat sumber terbuka Open-Sora: https://github.com/hpcaitech/Open-Sora
Untuk gambaran sekilas, mari lihat" yang dikeluarkan oleh-Sora video syot kilat janaan model 1.0" pasukan Colossal-AI tentang bandar yang sibuk.

Sebuah gambar bandar sibuk yang dijana oleh Open-Sora 1.0
Ini hanyalah sebahagian kecil daripada bongkah ais teknologi pembiakan Sora, tentang model pemberat pengeluaran, dan model pemberat terlatih di atas Wensheng video Butiran latihan, proses prapemprosesan data, paparan demo dan tutorial permulaan terperinci, pasukan Colossal-AI telah dibuka sepenuhnya di GitHub secara percuma.
Xinzhiyuan menghubungi pasukan secepat mungkin dan mengetahui bahawa mereka akan terus mengemas kini penyelesaian berkaitan Open-Sora dan perkembangan terkini. Rakan-rakan yang berminat boleh terus mengikuti komuniti sumber terbuka Open-Sora.
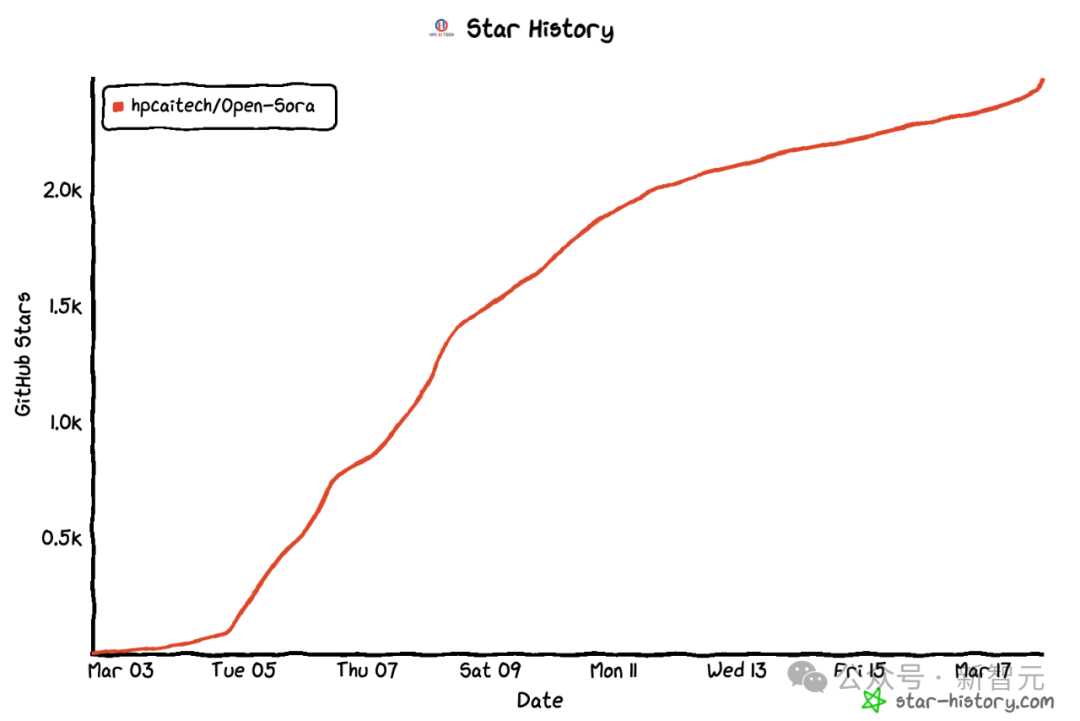
Seterusnya, kami akan mentafsir dengan mendalam pelbagai dimensi utama penyelesaian replikasi Sora, termasuk reka bentuk seni bina model, penyelesaian replikasi latihan, prapemprosesan data dan paparan penjanaan model yang cekap strategi pengoptimuman.

Reka bentuk seni bina model
Model ini menggunakan seni bina Diffusion Transformer (DiT) [1] yang popular pada masa ini.
Pasukan pengarang menggunakan model graf Vincent sumber terbuka berkualiti tinggi PixArt-α [2], yang turut menggunakan seni bina DiT, sebagai asas, memperkenalkan lapisan perhatian sementara atas dasar ini, dan memanjangkannya kepada data video .
Secara khusus, keseluruhan seni bina termasuk VAE terlatih, pengekod teks dan model STDiT (Spatial Temporal Diffusion Transformer) yang menggunakan mekanisme perhatian spatial-temporal.
Antaranya, struktur setiap lapisan STDiT ditunjukkan dalam rajah di bawah. Ia menggunakan kaedah bersiri untuk menindih modul perhatian temporal satu dimensi pada modul perhatian spatial dua dimensi untuk memodelkan hubungan temporal.
Selepas modul perhatian temporal, modul perhatian silang digunakan untuk menyelaraskan semantik teks. Berbanding dengan mekanisme perhatian penuh, struktur sedemikian sangat mengurangkan overhed latihan dan inferens.
Berbanding dengan model Latte [3], yang turut menggunakan mekanisme perhatian spatial-temporal, STDiT boleh menggunakan pemberat imej pra-latihan DiT dengan lebih baik untuk meneruskan latihan mengenai data video.
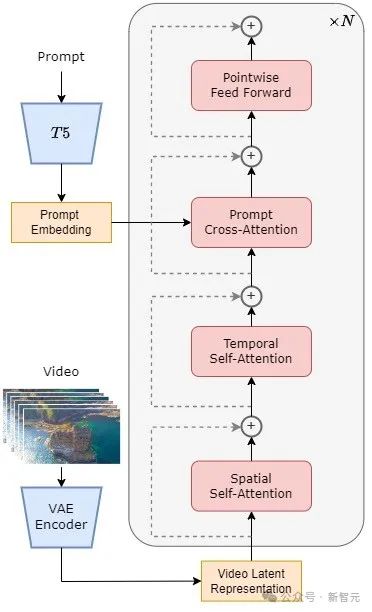
Rajah struktur STDiT
Proses latihan dan inferens keseluruhan model adalah seperti berikut. Difahamkan bahawa dalam fasa latihan, pengekod Variational Autoencoder (VAE) yang telah dilatih terlebih dahulu digunakan untuk memampatkan data video, dan kemudian model resapan STDiT dilatih bersama-sama dengan pembenaman teks dalam ruang pendam termampat.
Dalam peringkat inferens, hingar Gaussian diambil secara rawak daripada ruang terpendam VAE, dan dimasukkan ke dalam STDiT bersama-sama dengan pembenaman segera untuk mendapatkan ciri yang disingkirkan Akhirnya, ia dimasukkan ke penyahkod VAE dan dinyahkod untuk mendapatkan video. Proses Latihan Model Rancangan Replikasi yang dipelajari dari pasukan bahawa skim replikasi Open-Sora merujuk kepada kerja penyebaran video yang stabil (SVD) [3]. , iaitu:

Setiap peringkat akan meneruskan latihan berdasarkan berat peringkat sebelumnya. Berbanding dengan latihan satu peringkat dari awal, latihan berbilang peringkat mencapai matlamat penjanaan video berkualiti tinggi dengan lebih cekap dengan mengembangkan data secara beransur-ansur. . bantuan model graf Vincentian yang matang, dengan berkesan Mengurangkan kos pra-latihan video.
Pasukan pengarang mendedahkan kepada kami bahawa melalui data imej berskala besar yang kaya di Internet dan teknologi graf Vincent yang canggih, kami boleh melatih model graf Vincent berkualiti tinggi, yang akan berfungsi sebagai pemberat permulaan untuk peringkat seterusnya video pra-latihan .
Pada masa yang sama, memandangkan pada masa ini tiada VAE spatio-temporal berkualiti tinggi, mereka menggunakan imej VAE yang telah dilatih oleh model Stable Diffusion [5]. Strategi ini bukan sahaja memastikan prestasi unggul model awal, tetapi juga mengurangkan kos keseluruhan pra-latihan video dengan ketara.
Peringkat kedua: pra-latihan video berskala besar
Peringkat kedua melaksanakan pra-latihan video berskala besar untuk meningkatkan keupayaan generalisasi model dan memahami siri masa dengan berkesan. Kami faham bahawa peringkat ini memerlukan penggunaan sejumlah besar data video untuk latihan bagi memastikan kepelbagaian tema video, dengan itu meningkatkan keupayaan generalisasi model. Model peringkat kedua menambah modul perhatian temporal pada model graf Vincentian peringkat pertama untuk mempelajari hubungan temporal dalam video.
Modul yang selebihnya adalah konsisten dengan peringkat pertama dan memuatkan pemberat peringkat pertama sebagai permulaan Pada masa yang sama, output modul perhatian temporal dimulakan kepada sifar untuk mencapai penumpuan yang lebih cekap dan lebih cepat.

Peringkat ketiga: Penalaan halus data video berkualiti tinggi
Peringkat ketiga memperhalusi data video berkualiti tinggi untuk meningkatkan kualiti penjanaan video dengan ketara.Pasukan pengarang menyebut bahawa saiz data video yang digunakan pada peringkat ketiga adalah satu urutan magnitud kurang daripada itu pada peringkat kedua, tetapi tempoh, resolusi dan kualiti video lebih tinggi. Dengan penalaan halus dengan cara ini, mereka mencapai penskalaan penjanaan video yang cekap daripada pendek ke panjang, daripada peleraian rendah ke tinggi dan dari kesetiaan rendah ke tinggi.
Pasukan pengarang menyatakan bahawa dalam proses pembiakan Open-Sora, mereka menggunakan 64 blok H800 untuk latihan.
Jumlah latihan di peringkat kedua ialah 2808 jam GPU, iaitu lebih kurang AS$7,000. Jumlah latihan peringkat ketiga ialah 1920 jam GPU, iaitu kira-kira 4500 dolar AS. Selepas anggaran awal, keseluruhan pelan latihan berjaya mengawal proses pembiakan Open-Sora kepada kira-kira AS$10,000.
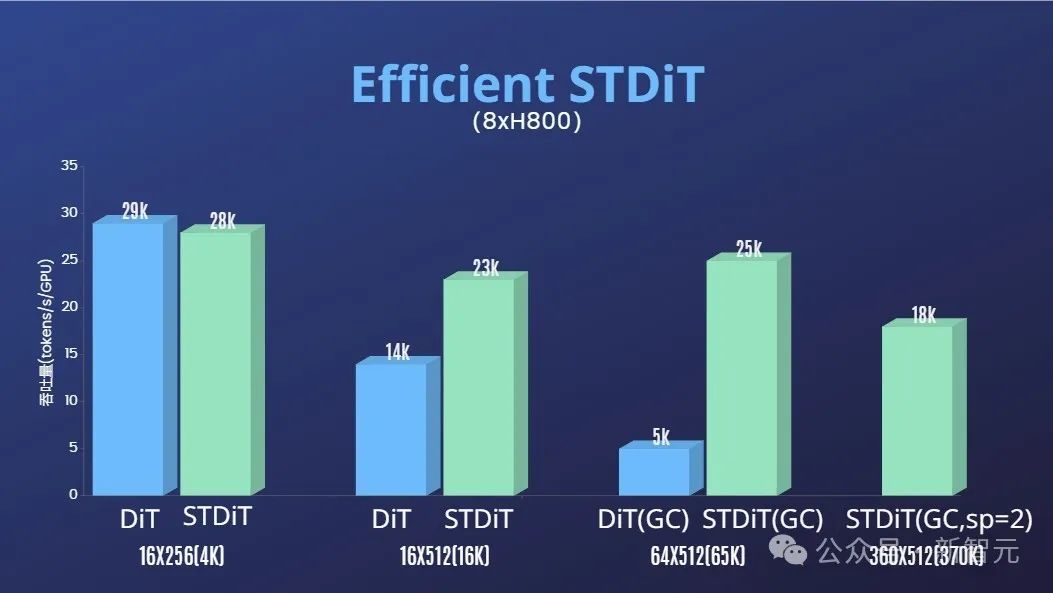
Untuk mengurangkan lagi ambang dan kerumitan pengulangan Sora, pasukan Colossal-AI juga menyediakan skrip prapemprosesan data video yang mudah dalam gudang kod, supaya semua orang boleh memulakan pra-latihan ulangan Sora dengan mudah , termasuk muat turun set data video awam, video panjang dibahagikan kepada klip video pendek berdasarkan kesinambungan tangkapan, dan model bahasa besar sumber terbuka LLaVA [7] digunakan untuk menjana perkataan segera yang tepat. Pasukan pengarang menyebut bahawa kod penjanaan tajuk video kumpulan yang mereka berikan boleh menganotasi video dalam masa 3 saat dengan dua kad, dan kualitinya hampir dengan GPT-4V. Pasangan video/teks yang terhasil boleh digunakan terus untuk latihan. Dengan kod sumber terbuka yang mereka sediakan di GitHub, kami boleh dengan mudah dan cepat menjana pasangan video/teks yang diperlukan untuk latihan pada set data kami sendiri, dengan ketara mengurangkan ambang teknikal dan persediaan awal untuk memulakan projek replikasi Sora . Gandingan video/teks dijana secara automatik berdasarkan skrip prapemprosesan data Mari kita lihat kesan penjanaan video Open-Sora sebenar. Sebagai contoh, biarkan Open-Sora menjana rakaman udara air laut yang menghantam batu di pantai tebing. Biarkan Open-Sora merakam pemandangan indah gunung dan air terjun yang turun dari cenuram dan akhirnya mengalir ke dalam tasik. Selain pergi ke langit, anda juga boleh masuk ke laut dengan pantas dan biarkan Open-Sora menjana gambar dunia bawah air terumbu karang. Open-Sora juga boleh menunjukkan kepada kita Bima Sakti yang berbintang melalui fotografi selang masa. Jika anda mempunyai idea yang lebih menarik untuk penjanaan video, anda boleh melawati komuniti sumber terbuka Open-Sora untuk mendapatkan berat model untuk pengalaman percuma. Pautan: https://github.com/hpcaitech/Open-Sora Perlu diperhatikan bahawa pasukan pengarang menyebut di Github bahawa versi semasa hanya menggunakan 400K data latihan, model kedua-dua kualiti generasi dan kebolehan mengikuti teks perlu dipertingkatkan. Sebagai contoh, dalam video penyu di atas, penyu yang terhasil mempunyai kaki tambahan. Open-Sora 1.0 juga tidak pandai menghasilkan potret dan imej yang kompleks. Pasukan pengarang menyenaraikan satu siri rancangan yang perlu dilakukan di Github, bertujuan untuk terus menyelesaikan kecacatan sedia ada dan meningkatkan kualiti pengeluaran. Selain mengurangkan dengan ketara ambang teknikal untuk pembiakan Sora dan meningkatkan kualiti penjanaan video dalam pelbagai dimensi seperti tempoh, resolusi dan kandungan, pasukan pengarang Colossal juga menyediakan -Pecutan AI Sistem menyediakan sokongan latihan yang cekap untuk pengulangan Sora. Melalui strategi latihan yang cekap seperti pengoptimuman operator dan keselarian hibrid, kesan pecutan 1.55x telah dicapai dalam latihan memproses video 64 bingkai, resolusi 512x512. Pada masa yang sama, terima kasih kepada sistem pengurusan memori heterogen Colossal-AI, tugas latihan video definisi tinggi 1080p 1 minit boleh dilakukan tanpa halangan pada satu pelayan (8 x H800). Selain itu, dalam laporan pasukan pengarang, kami juga mendapati bahawa seni bina model STDiT juga menunjukkan kecekapan yang sangat baik semasa latihan. Berbanding dengan DiT menggunakan mekanisme perhatian penuh, STDiT mencapai pecutan sehingga 5 kali ganda apabila bilangan bingkai bertambah, yang amat kritikal dalam tugas dunia sebenar seperti memproses jujukan video yang panjang. huan Prapemprosesan data

Paparan kesan penjanaan model





Sokongan latihan yang cekap

Sepintas lalu kesan penjanaan video model Open-Sora
Atas ialah kandungan terperinci Jangan tunggu OpenAI, yang pertama seperti Sora di dunia adalah sumber terbuka dahulu! Semua butiran latihan/berat model didedahkan sepenuhnya dan kosnya hanya $10,000. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
