

Bagaimana untuk menulis kod LoRA dari awal, berikut adalah tutorial

LoRA (Penyesuaian Kedudukan Rendah) ialah teknik popular yang direka untuk memperhalusi model bahasa besar (LLM). Teknologi ini pada asalnya dicadangkan oleh penyelidik Microsoft dan dimasukkan ke dalam kertas kerja "LORA: ADAPTASI RENDAH MODEL BAHASA BESAR". LoRA berbeza daripada teknik lain kerana bukannya melaraskan semua parameter rangkaian saraf, ia memfokuskan pada mengemas kini sebilangan kecil matriks peringkat rendah, dengan ketara mengurangkan jumlah pengiraan yang diperlukan untuk melatih model.
Memandangkan kualiti penalaan halus LoRA adalah setanding dengan penalaan halus model penuh, ramai orang memanggil kaedah ini sebagai artifak penalaan halus. Sejak dikeluarkan, ramai yang ingin tahu tentang teknologi dan ingin menulis kod untuk lebih memahami penyelidikan. Pada masa lalu, kekurangan dokumentasi yang betul telah menjadi isu, tetapi kini, kami mempunyai tutorial untuk membantu.
Pengarang tutorial ini ialah Sebastian Raschka, seorang penyelidik pembelajaran mesin dan AI yang terkenal Dia berkata bahawa antara pelbagai kaedah penalaan halus LLM yang berkesan, LoRA masih menjadi pilihan pertamanya. Untuk tujuan ini, Sebastian menulis blog "Code LoRA From Scratch" untuk membina LoRA dari awal Pada pendapatnya, ini adalah kaedah pembelajaran yang baik.
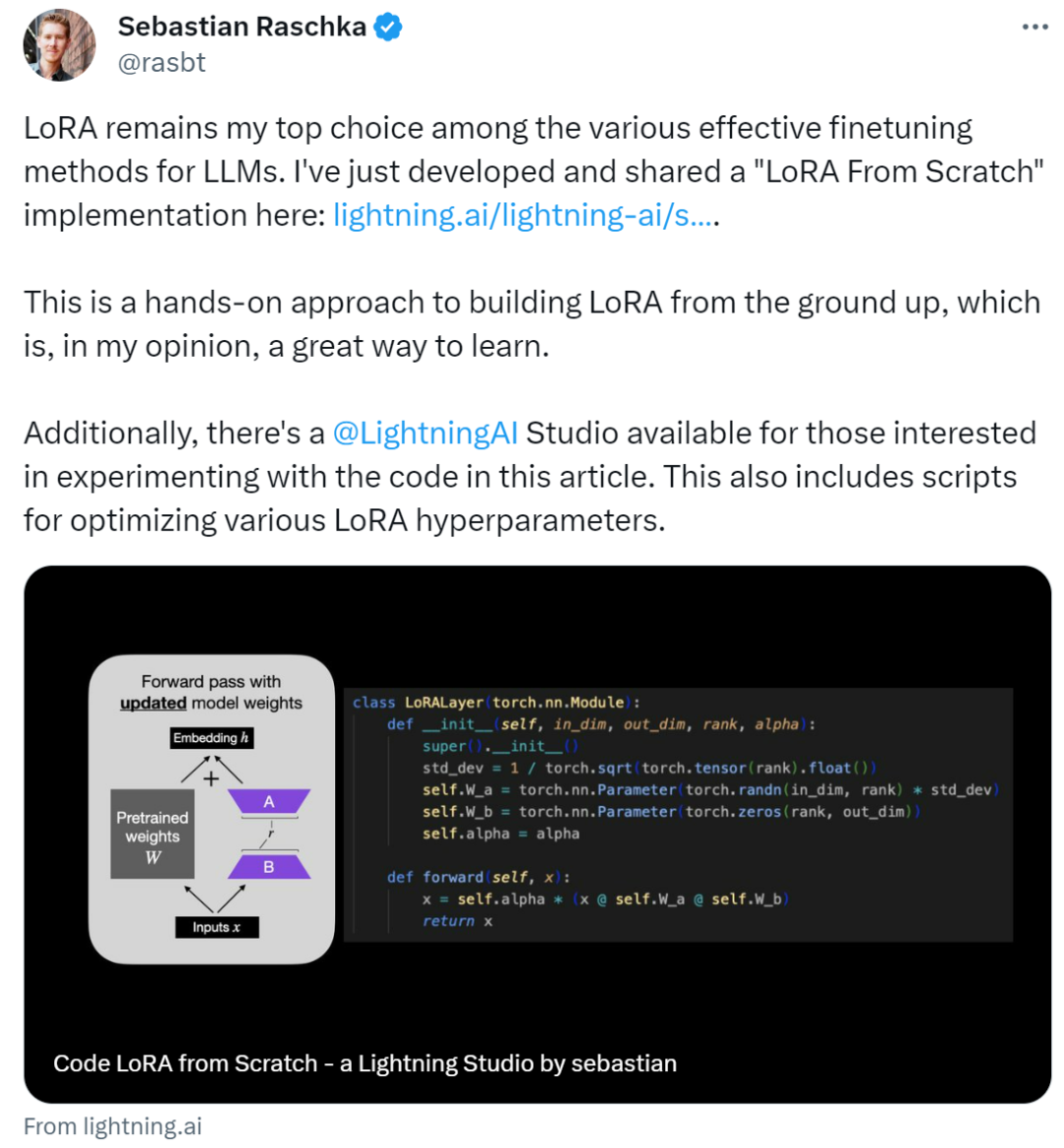
Artikel ini memperkenalkan penyesuaian peringkat rendah (LoRA) dengan menulis kod dari awal Sebastian memperhalusi model DistilBERT dalam percubaan dan menggunakannya pada tugas pengelasan.
Hasil perbandingan antara kaedah LoRA dan kaedah penalaan halus tradisional menunjukkan bahawa kaedah LoRA mencapai 92.39% dalam ketepatan ujian, yang lebih baik daripada penalaan halus hanya beberapa lapisan terakhir model (86.22% ketepatan ujian ) prestasi. Ini menunjukkan bahawa kaedah LoRA mempunyai kelebihan yang jelas dalam mengoptimumkan prestasi model dan boleh meningkatkan keupayaan generalisasi model dan ketepatan ramalan dengan lebih baik. Keputusan ini menyerlahkan kepentingan mengguna pakai teknik dan kaedah lanjutan semasa latihan dan penalaan model untuk mendapatkan prestasi dan hasil yang lebih baik. Dengan membandingkan bagaimana
Sebastian mencapainya, mari lihat di bawah.
Tulis LoRA dari awal
Menerangkan lapisan LoRA dalam kod adalah seperti ini:
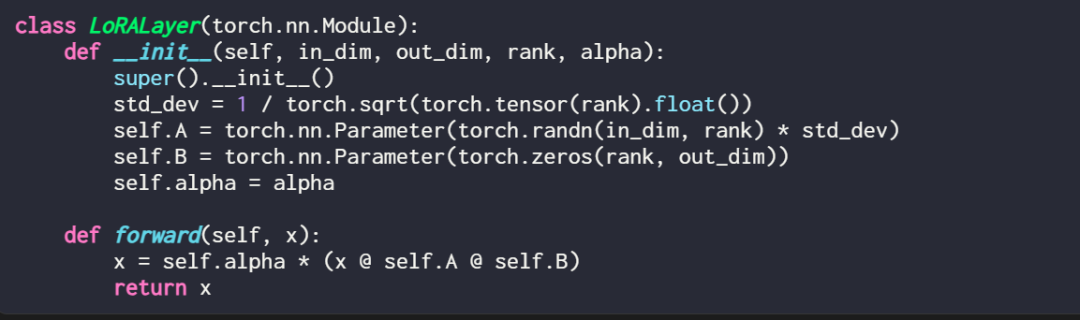
di mana in_dim ialah dimensi input ubah suai menggunakan lapisan yang anda ingin ubah LoRA ini. dimensi keluaran lapisan. Hiperparameter, alfa faktor penskalaan, juga ditambahkan pada kod nilai alfa yang lebih tinggi bermakna pelarasan yang lebih besar kepada tingkah laku model, dan nilai yang lebih rendah bermakna sebaliknya. Selain itu, artikel ini memulakan matriks A dengan nilai yang lebih kecil daripada taburan rawak dan memulakan matriks B dengan sifar.
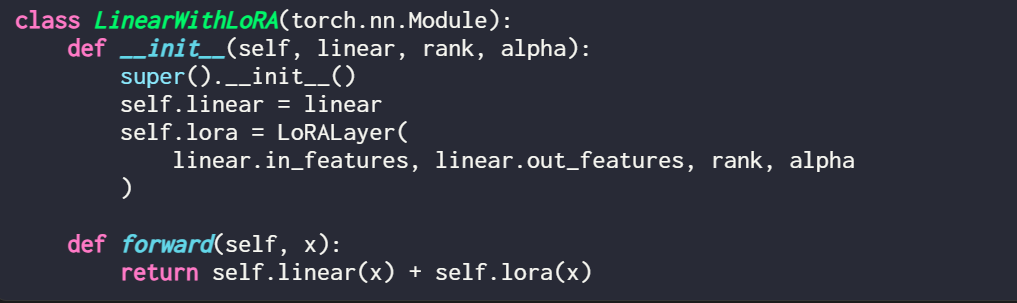
Perlu dinyatakan bahawa tempat LoRA berperanan biasanya adalah lapisan linear (suapan) rangkaian saraf. Contohnya, untuk model atau modul PyTorch mudah dengan dua lapisan linear (contohnya, ini mungkin modul suapan hadapan blok Transformer), kaedah hadapan boleh dinyatakan sebagai:

Apabila menggunakan LoRA, ia adalah perkara biasa untuk menambah kemas kini LoRA pada output lapisan linear ini, dan kod yang terhasil adalah seperti berikut:

Jika anda ingin melaksanakan LoRA dengan mengubah suai model PyTorch sedia ada, cara mudah ialah dengan Setiap lapisan linear digantikan dengan lapisan LinearWithLoRA:
Konsep di atas diringkaskan dalam rajah di bawah:
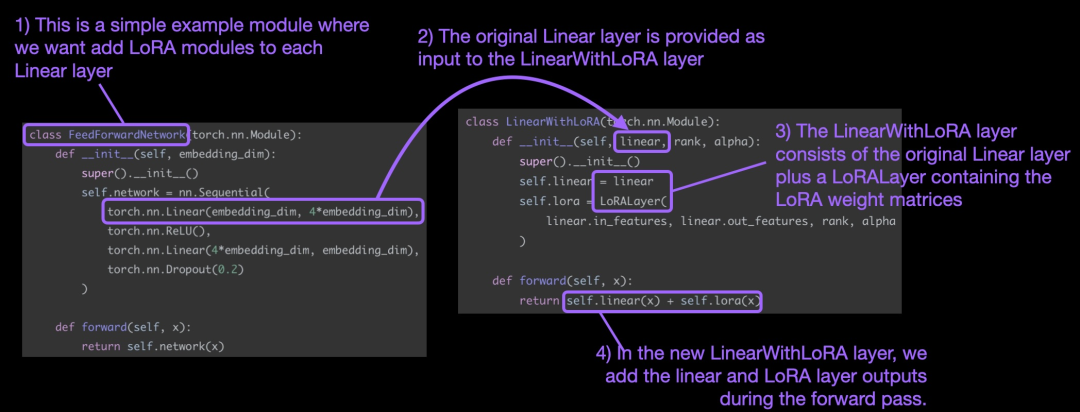
Untuk menggunakan LoRA, artikel ini menggantikan dalam rangkaian linear yang sedia ada. digabungkan Lapisan linear asal dan lapisan LinearWithLoRA LoRALayer.
Cara mula menggunakan LoRA untuk penalaan halus
LoRA boleh digunakan untuk model seperti GPT atau penjanaan imej. Untuk penjelasan ringkas, artikel ini menggunakan model BERT (DistilBERT) kecil untuk pengelasan teks.

Memandangkan artikel ini hanya melatih pemberat LoRA baharu, anda perlu menetapkan require_grad semua parameter boleh dilatih kepada False untuk membekukan semua parameter model:

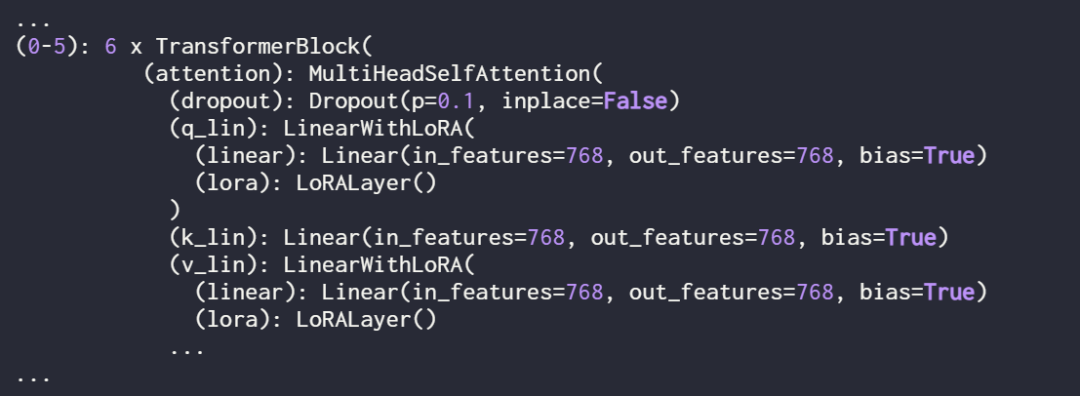
Seterusnya, gunakan cetakan (model) Struktur

 Semak model sekali lagi menggunakan cetakan (model) untuk menyemak strukturnya yang dikemas kini:
Semak model sekali lagi menggunakan cetakan (model) untuk menyemak strukturnya yang dikemas kini:
Seperti yang anda lihat di atas, lapisan Linear telah berjaya digantikan oleh lapisan LinearWithLoRA.

Jika anda melatih model menggunakan hiperparameter lalai yang ditunjukkan di atas, ia menghasilkan prestasi berikut pada set data klasifikasi semakan filem IMDb:
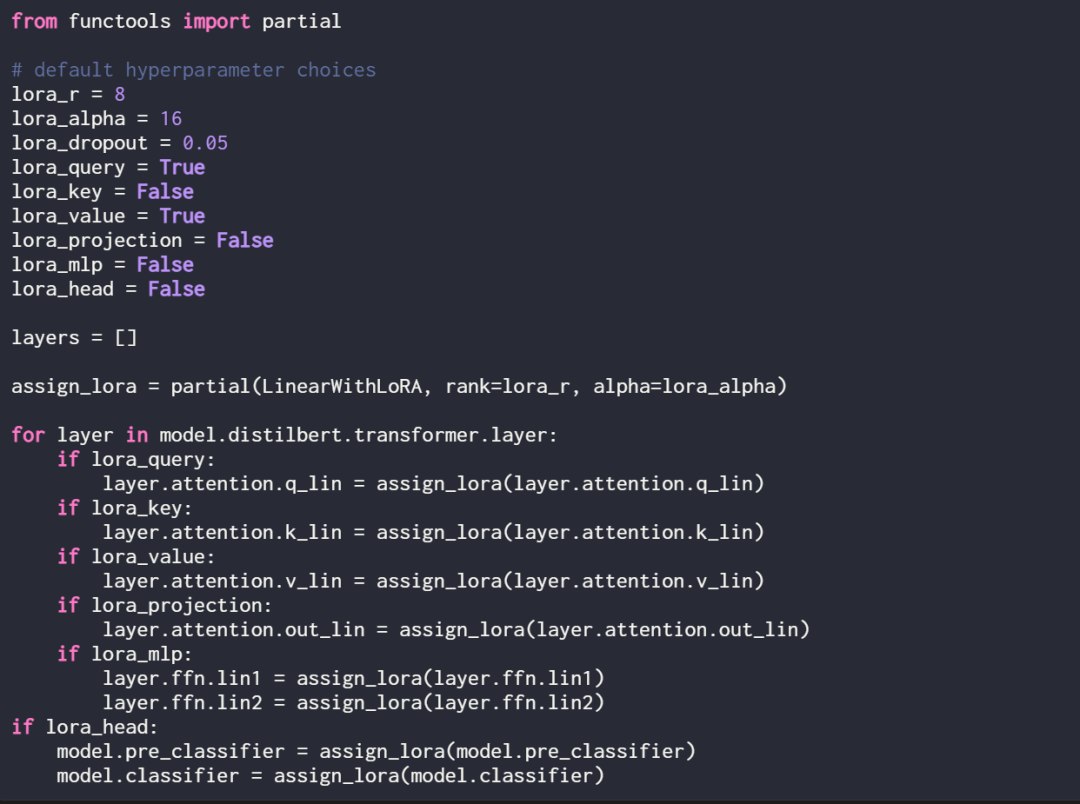 Ketepatan latihan: 92.15%
Ketepatan latihan: 92.15%
9 % ketepatan klasifikasi
 8
8
Ketepatan ujian: 89.44%
Dalam bahagian seterusnya, kertas kerja ini membandingkan keputusan penalaan halus LoRA ini dengan hasil penalaan halus tradisional.
- Perbandingan dengan kaedah penalaan halus tradisional
- Dalam bahagian sebelumnya, LoRA mencapai ketepatan ujian 89.44% di bawah tetapan lalai. Bagaimanakah ini dibandingkan dengan kaedah penalaan halus tradisional?
- Sebagai perbandingan, artikel ini menjalankan satu lagi eksperimen, mengambil latihan model DistilBERT sebagai contoh, tetapi hanya mengemas kini 2 lapisan terakhir semasa latihan. Penyelidik mencapai ini dengan membekukan semua berat model dan kemudian menyahbekukan dua lapisan keluaran linear:
Prestasi klasifikasi yang diperolehi dengan melatih hanya dua lapisan terakhir adalah seperti berikut:
:Pengumpulan 8% Latihan. . . Penalaan halus semua lapisan memerlukan pengemaskinian 450 kali lebih banyak parameter daripada persediaan LoRA, tetapi hanya meningkatkan ketepatan ujian sebanyak 2%. . gunakan Perintah berikut:
Walau bagaimanapun, konfigurasi hiperparameter optimum adalah seperti berikut:
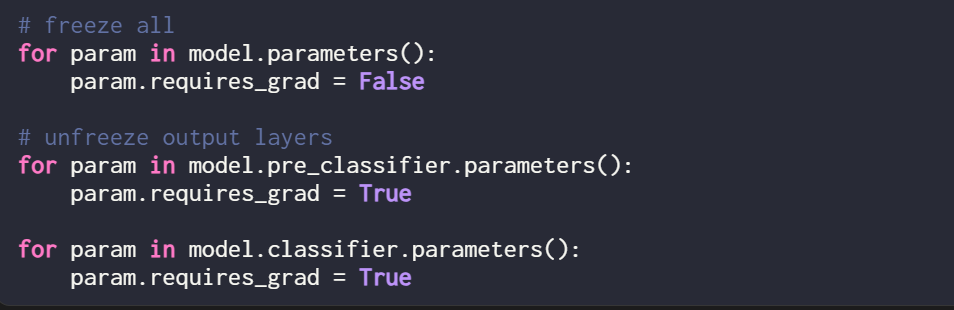
Di bawah konfigurasi ini, hasilnya ialah:
-
- Ketepatan pengesahan: 92.96%
- Ketepatan ujian: 92.39%
Perlu diperhatikan bahawa walaupun hanya terdapat sekumpulan kecil parameter ketepatan Lo (ra 600) dalam tetapan boleh dilatih Lo (ra 600) masih lebih tinggi sedikit daripada ketepatan yang diperoleh dengan penalaan halus sepenuhnya.
Pautan asal: https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?cnotallow=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
Atas ialah kandungan terperinci Bagaimana untuk menulis kod LoRA dari awal, berikut adalah tutorial. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Sony mengesahkan kemungkinan menggunakan GPU khas di PS5 Pro untuk membangunkan AI dengan AMD
Apr 13, 2025 pm 11:45 PM
Sony mengesahkan kemungkinan menggunakan GPU khas di PS5 Pro untuk membangunkan AI dengan AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, Ketua Arkitek SonyinterActiveEntainment (SIE, Sony Interactive Entertainment), telah mengeluarkan lebih banyak butiran perkakasan dari PlayStation5Pro hos generasi akan datang (PS5Pro), termasuk GPU seni bina AMDRDNA2.x yang dinamakan, dan Kod Arsitektur AMDRDNA2.x yang dinamakan. Tumpuan peningkatan prestasi PS5Pro masih pada tiga tiang, termasuk GPU yang lebih kuat, jejak sinar maju dan fungsi resolusi super PSSR yang berkuasa AI. GPU mengamalkan seni bina AmdrDNA2 yang disesuaikan, yang Sony menamakan RDNA2.x, dan ia mempunyai beberapa seni bina RDNA3.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Penalaan prestasi zookeeper pada centOs boleh bermula dari pelbagai aspek, termasuk konfigurasi perkakasan, pengoptimuman sistem operasi, pelarasan parameter konfigurasi, pemantauan dan penyelenggaraan, dan lain -lain. Memori yang cukup: memperuntukkan sumber memori yang cukup untuk zookeeper untuk mengelakkan cakera kerap membaca dan menulis. CPU multi-teras: Gunakan CPU multi-teras untuk memastikan bahawa zookeeper dapat memprosesnya selari.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
