
 Peranti teknologi
AI
Google mengeluarkan model 'Vlogger': satu gambar menghasilkan video 10 saat
Peranti teknologi
AI
Google mengeluarkan model 'Vlogger': satu gambar menghasilkan video 10 saat
Google mengeluarkan model 'Vlogger': satu gambar menghasilkan video 10 saat

Google telah mengeluarkan rangka kerja video baharu:
Anda hanya memerlukan gambar anda dan rakaman ucapan anda, dan anda boleh mendapatkan video seperti hidup ucapan anda.
Tempoh video berubah-ubah, dan contoh semasa yang dilihat adalah sehingga 10s.
Anda boleh lihat sama ada bentuk mulut atau mimik muka, ia adalah sangat semula jadi.
Jika imej input meliputi seluruh bahagian atas badan, ia juga boleh digunakan dengan kaya isyarat:

Selepas membacanya, netizen berkata:
Dengannya, kita tidak perlu lagi menahannya. persidangan video dalam talian pada masa hadapan Selesaikan rambut anda dan berpakaian sebelum pergi.
Nah, ambil potret dan rakam audio pertuturan (kepala anjing manual)
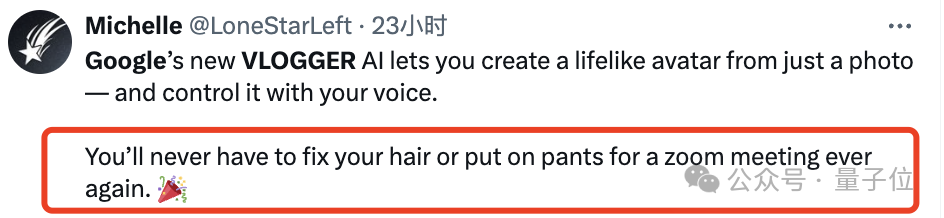
Gunakan suara anda untuk mengawal potret untuk menjana video
Rangka kerja ini dipanggil VLOGGER
Ia terutamanya berdasarkan model resapan dan mengandungi dua bahagian: Satu ialah model resapan manusia-ke-3d(manusia-ke-3d-gerakan).
Yang lain ialah seni bina resapan baharu untuk mempertingkatkan model teks-ke-imej.
(bernama MENTOR) .
Berapa besarnya?Ia berdurasi 2200 jam dan mengandungi 800,000 video aksara.
Antaranya, tempoh video set ujian juga adalah 120 jam, dengan jumlah 4,000 aksara. Google memperkenalkan bahawa prestasi VLOGGER yang paling cemerlang ialah kepelbagaiannya: Seperti yang ditunjukkan dalam gambar di bawah, semakin gelap(merah) bahagian imej piksel akhir, semakin kaya tindakan.

(termasuk muka dan bibir, termasuk pergerakan badan) dan sebagainya.



Adakah ini tahap Google?

Saya agak kesal dengan nama "VLOGGER".

——Berbanding dengan Sora OpenAI, kenyataan netizen itu sememangnya tidak munasabah. .
Apa pendapat anda?
Lagi kesan:https://enriccorona.github.io/vlogger/
Kertas penuh: https://enriccorona.github.io/vlogger/paper.pdf
Atas ialah kandungan terperinci Google mengeluarkan model 'Vlogger': satu gambar menghasilkan video 10 saat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara merakam video skrin dengan telefon OPPO (operasi mudah)
May 07, 2024 pm 06:22 PM
Cara merakam video skrin dengan telefon OPPO (operasi mudah)
May 07, 2024 pm 06:22 PM
Kemahiran permainan atau tunjuk cara mengajar, dalam kehidupan seharian, kita selalunya perlu menggunakan telefon bimbit untuk merakam video skrin untuk menunjukkan beberapa langkah operasi. Fungsinya merakam video skrin juga sangat baik, dan telefon mudah alih OPPO ialah telefon pintar yang berkuasa. Membolehkan anda menyelesaikan tugasan rakaman dengan mudah dan cepat, artikel ini akan memperkenalkan secara terperinci cara menggunakan telefon mudah alih OPPO untuk merakam video skrin. Persediaan - Tentukan matlamat rakaman Anda perlu menjelaskan matlamat rakaman anda sebelum anda memulakan. Adakah anda ingin merakam video demonstrasi langkah demi langkah? Atau mahu merakam detik indah permainan? Atau ingin merakam video pengajaran? Hanya dengan mengatur proses rakaman yang lebih baik dan matlamat yang jelas. Buka fungsi rakaman skrin telefon mudah alih OPPO dan cari dalam panel pintasan Fungsi rakaman skrin terletak di panel pintasan.
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Cara menukar bahasa dalam Adobe After Effects cs6 (Ae cs6) Langkah terperinci untuk menukar antara bahasa Cina dan Inggeris dalam Ae cs6 - muat turun ZOL
May 09, 2024 pm 02:00 PM
Cara menukar bahasa dalam Adobe After Effects cs6 (Ae cs6) Langkah terperinci untuk menukar antara bahasa Cina dan Inggeris dalam Ae cs6 - muat turun ZOL
May 09, 2024 pm 02:00 PM
1. Mula-mula cari folder AMTLanguages. Kami menemui beberapa dokumentasi dalam folder AMTLanguages. Jika anda memasang Bahasa Cina Ringkas, akan ada dokumen teks zh_CN.txt (kandungan teks ialah: zh_CN). Jika anda memasangnya dalam bahasa Inggeris, akan ada dokumen teks en_US.txt (kandungan teks ialah: en_US). 3. Oleh itu, jika kita ingin bertukar kepada bahasa Cina, kita perlu mencipta dokumen teks baharu zh_CN.txt (kandungan teks ialah: zh_CN) di bawah laluan AdobeAfterEffectsCCSupportFilesAMTLanguages . 4. Sebaliknya, jika kita ingin bertukar kepada bahasa Inggeris,
 Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Apa? Adakah Zootopia dibawa menjadi realiti oleh AI domestik? Didedahkan bersama-sama dengan video itu ialah model penjanaan video domestik berskala besar baharu yang dipanggil "Keling". Sora menggunakan laluan teknikal yang serupa dan menggabungkan beberapa inovasi teknologi yang dibangunkan sendiri untuk menghasilkan video yang bukan sahaja mempunyai pergerakan yang besar dan munasabah, tetapi juga mensimulasikan ciri-ciri dunia fizikal dan mempunyai keupayaan gabungan konsep dan imaginasi yang kuat. Mengikut data, Keling menyokong penjanaan video ultra panjang sehingga 2 minit pada 30fps, dengan resolusi sehingga 1080p dan menyokong berbilang nisbah aspek. Satu lagi perkara penting ialah Keling bukanlah demo atau demonstrasi hasil video yang dikeluarkan oleh makmal, tetapi aplikasi peringkat produk yang dilancarkan oleh Kuaishou, pemain terkemuka dalam bidang video pendek. Selain itu, tumpuan utama adalah untuk menjadi pragmatik, bukan untuk menulis cek kosong, dan pergi ke dalam talian sebaik sahaja ia dikeluarkan Model besar Ke Ling telah pun dikeluarkan di Kuaiying.
 Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Baru-baru ini, bulatan tentera telah terharu dengan berita: jet pejuang tentera AS kini boleh melengkapkan pertempuran udara automatik sepenuhnya menggunakan AI. Ya, baru-baru ini, jet pejuang AI tentera AS telah didedahkan buat pertama kali, mendedahkan misterinya. Nama penuh pesawat pejuang ini ialah Variable Stability Simulator Test Aircraft (VISTA). Ia diterbangkan sendiri oleh Setiausaha Tentera Udara AS untuk mensimulasikan pertempuran udara satu lawan satu. Pada 2 Mei, Setiausaha Tentera Udara A.S. Frank Kendall berlepas menggunakan X-62AVISTA di Pangkalan Tentera Udara Edwards Ambil perhatian bahawa semasa penerbangan selama satu jam, semua tindakan penerbangan telah diselesaikan secara autonomi oleh AI! Kendall berkata - "Sejak beberapa dekad yang lalu, kami telah memikirkan tentang potensi tanpa had pertempuran udara-ke-udara autonomi, tetapi ia sentiasa kelihatan di luar jangkauan." Namun kini,
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Bagaimana untuk merakam video di Douyin? Bagaimana untuk menghidupkan mikrofon untuk rakaman video?
May 09, 2024 pm 02:40 PM
Bagaimana untuk merakam video di Douyin? Bagaimana untuk menghidupkan mikrofon untuk rakaman video?
May 09, 2024 pm 02:40 PM
Sebagai salah satu platform video pendek yang paling popular hari ini, kualiti dan kesan video Douyin secara langsung mempengaruhi pengalaman menonton pengguna. Jadi, bagaimana untuk menangkap video berkualiti tinggi di TikTok? 1. Bagaimana untuk merakam video di Douyin? 1. Buka APP Douyin dan klik butang "+" di bahagian tengah di bahagian bawah untuk memasuki halaman rakaman video. 2. Douyin menyediakan pelbagai mod penangkapan, termasuk penangkapan biasa, gerakan perlahan, video pendek, dsb. Pilih mod penangkapan yang sesuai mengikut keperluan anda. 3. Pada halaman penangkapan, klik butang "Penapis" di bahagian bawah skrin untuk memilih kesan penapis yang berbeza untuk menjadikan video lebih diperibadikan. 4. Jika anda perlu melaraskan parameter seperti pendedahan dan kontras, anda boleh mengklik butang "Parameter" di sudut kiri bawah skrin untuk menetapkannya. 5. Semasa penangkapan, anda boleh klik pada sebelah kiri skrin
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
