
 Peranti teknologi
AI
Stable Video 3D membuat penampilan pertama yang mengejutkan: satu imej menghasilkan video 3D tanpa bintik buta dan berat model dibuka
Peranti teknologi
AI
Stable Video 3D membuat penampilan pertama yang mengejutkan: satu imej menghasilkan video 3D tanpa bintik buta dan berat model dibuka
Stable Video 3D membuat penampilan pertama yang mengejutkan: satu imej menghasilkan video 3D tanpa bintik buta dan berat model dibuka

Stability AI mempunyai ahli baharu dalam keluarga model besarnya.
Semalam, selepas melancarkan Stable Diffusion dan Stable Video Diffusion, Stability AI membawakan model penjanaan video 3D yang besar "Stable Video 3D" (pendek kata SV3D) kepada komuniti.
Model ini dibina berdasarkan Stable Video Diffusion, kelebihan utamanya ialah ia meningkatkan dengan ketara kualiti penjanaan 3D dan konsistensi berbilang paparan. Berbanding dengan Stable Zero123 sebelumnya yang dilancarkan oleh Stability AI dan sumber terbuka bersama Zero123-XL, kesan model ini lebih baik.
Pada masa ini, Stable Video 3D menyokong kedua-dua penggunaan komersial, yang memerlukan keahlian Stability AI (Keahlian) dan penggunaan bukan komersial, di mana pengguna boleh memuat turun berat model pada Wajah Memeluk.

Stability AI menyediakan dua varian model iaitu SV3D_u dan SV3D_p. SV3D_u menjana video orbital berdasarkan input imej tunggal tanpa memerlukan pelarasan kamera, manakala SV3D_p memanjangkan lagi keupayaan penjanaan dengan menyesuaikan imej tunggal dan perspektif orbit, membolehkan pengguna mencipta video 3D di sepanjang laluan kamera yang ditentukan.
Pada masa ini, kertas penyelidikan mengenai Stable Video 3D telah dikeluarkan, dengan tiga pengarang teras.

- Alamat kertas: https://stability.ai/s/SV3D_report.pdf
- Alamat blog: https://stability-ing-s/introducvideo 3d
- Huggingface Alamat: https://huggingface.co/stabilityai/sv3d
Tinjauan Teknikal
Stable Video 3D telah mencapai kemajuan yang ketara dalam penjanaan novel 3D terutamanya dalam penjanaan novel synthes , NVS).
Kaedah terdahulu selalunya cenderung untuk menyelesaikan masalah sudut tontonan yang terhad dan input yang tidak konsisten, manakala Video 3D Stabil mampu memberikan pandangan yang koheren dari mana-mana sudut tertentu dan membuat generalisasi dengan baik. Hasilnya, model ini bukan sahaja meningkatkan kebolehkawalan pose tetapi juga memastikan penampilan objek yang konsisten merentas pelbagai paparan, menambah baik lagi isu utama yang mempengaruhi penjanaan 3D yang realistik dan tepat.
Seperti yang ditunjukkan dalam rajah di bawah, berbanding dengan Stable Zero123 dan Zero-XL, Stable Video 3D mampu menjana berbilang paparan novel dengan butiran yang lebih kukuh, lebih setia kepada imej input dan berbilang sudut pandangan yang lebih konsisten.

Selain itu, Stable Video 3D memanfaatkan ketekalan berbilang paparannya untuk mengoptimumkan Medan Sinaran Neural 3D (NeRF) untuk meningkatkan kualiti jejaring 3D yang dijana terus daripada paparan baharu.
Untuk tujuan ini, Stability AI mereka bentuk kehilangan pensampelan penyulingan pecahan topeng yang meningkatkan lagi kualiti 3D kawasan ghaib dalam paparan yang diramalkan. Juga untuk mengurangkan isu pencahayaan bakar, Stable Video 3D menggunakan model pencahayaan terpisah yang dioptimumkan dengan bentuk dan tekstur 3D.
Gambar di bawah menunjukkan contoh penjanaan jejaring 3D yang dipertingkatkan melalui pengoptimuman 3D apabila menggunakan model 3D Video Stabil dan outputnya.

Gambar di bawah menunjukkan perbandingan hasil jejaring 3D yang dijana menggunakan Stable Video 3D dengan yang dijana oleh EscherNet dan Stable Zero123. Butir -butir Architecture

Proses khusus adalah seperti berikut:
(i) Padamkan syarat vektor "id fps" dan "id baldi gerakan" kerana ia tiada kaitan dengan Stable Video 3D; imej bersyarat melepasi pengekod VAE Stable Video Diffusion dibenamkan ke dalam ruang pendam dan kemudian disambungkan kepada input keadaan pendam hingar zt pada langkah masa hingar t menuju ke UNet
(iii) Matriks CLIPembedding imej bersyarat disediakan; kepada setiap blok pengubah Lapisan perhatian silang bertindak sebagai kunci dan nilai, dan pertanyaan menjadi ciri lapisan yang sepadan
(iv) Trajektori kamera dimasukkan ke dalam blok sisa sepanjang langkah masa hingar resapan. Sudut pose kamera ei dan ai dan langkah masa hingar t mula-mula dibenamkan ke dalam benam kedudukan sinusoidal, kemudian benam pose kamera digabungkan bersama untuk transformasi linear dan ditambah kepada benam langkah masa hingar, dan akhirnya dimasukkan ke dalam setiap blok baki dan ditambah pada ciri input blok.
Selain itu, Stability AI mereka bentuk orbit statik dan orbit dinamik untuk mengkaji kesan pelarasan pose kamera, seperti ditunjukkan dalam Rajah 3 di bawah.
Pada orbit statik, kamera berputar mengelilingi objek dalam azimut sama jarak menggunakan sudut ketinggian yang sama seperti imej keadaan. Kelemahan ini ialah berdasarkan sudut ketinggian yang dilaraskan, anda mungkin tidak mendapat sebarang maklumat tentang bahagian atas atau bawah objek. Dalam orbit dinamik, sudut azimut boleh menjadi tidak sama, dan sudut ketinggian setiap pandangan juga boleh berbeza. 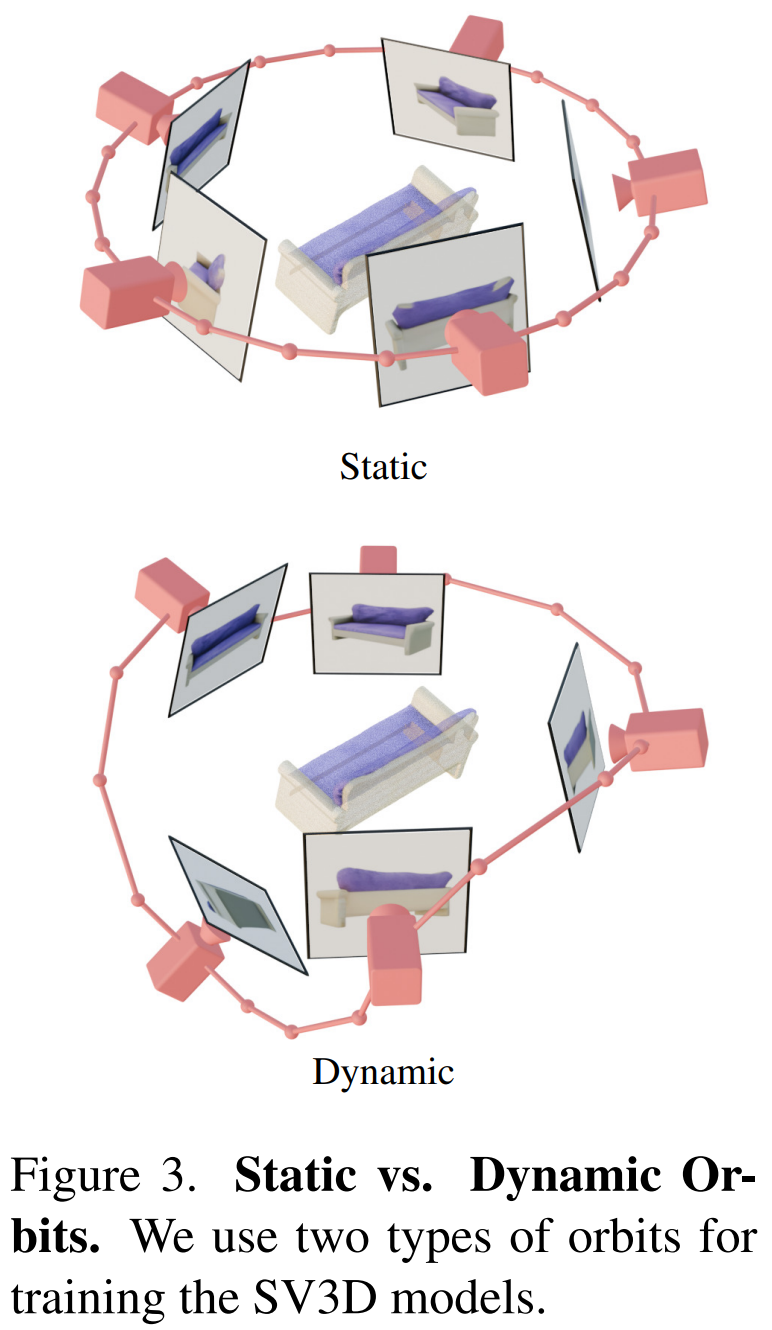
Untuk membina orbit dinamik, Stability AI mencontohi orbit statik, menambah hingar rawak kecil pada azimutnya dan gabungan berwajaran rawak sinusoid dengan frekuensi berbeza pada ketinggiannya. Melakukannya memberikan kelancaran sementara dan memastikan trajektori kamera berakhir di sepanjang azimut dan gelung ketinggian yang sama seperti imej keadaan.
Hasil eksperimen
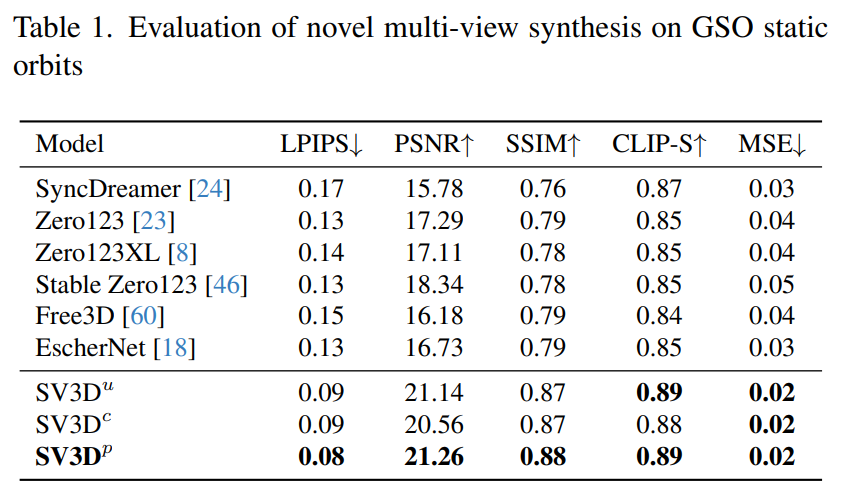
Stability AI menilai kesan berbilang paparan komposit Video 3D Stabil pada orbit statik dan dinamik pada set data GSO dan OmniObject3D yang tidak kelihatan. Keputusan, ditunjukkan dalam Jadual 1 hingga 4 di bawah, menunjukkan bahawa Video 3D Stabil mencapai prestasi terkini dalam sintesis berbilang paparan novel.
Jadual 1 dan Jadual 3 menunjukkan keputusan Video 3D Stabil berbanding model lain pada orbit statik, menunjukkan walaupun model SV3D_u tanpa pelarasan pose berprestasi lebih baik daripada semua kaedah sebelumnya.
Hasil analisis ablasi menunjukkan bahawa SV3D_c dan SV3D_p mengatasi SV3D_u dalam penjanaan trajektori statik, walaupun trajektori statik dilatih secara eksklusif pada trajektori statik.
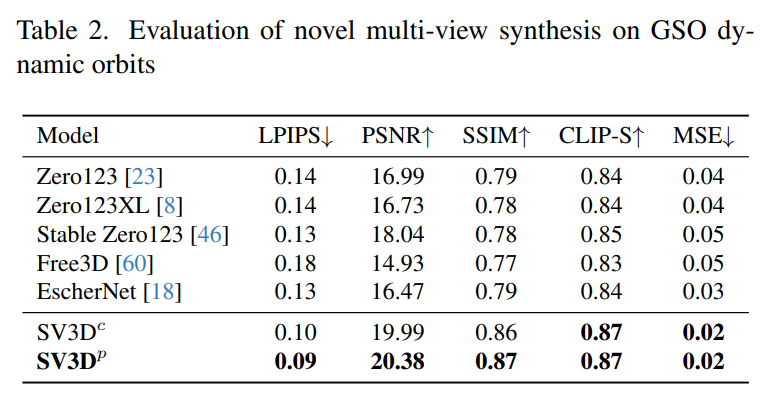
Jadual 2 dan Jadual 4 di bawah menunjukkan hasil penjanaan orbit dinamik, termasuk model pelarasan pose SV3D_c dan SV3D_p, yang kedua mencapai SOTA pada semua metrik. 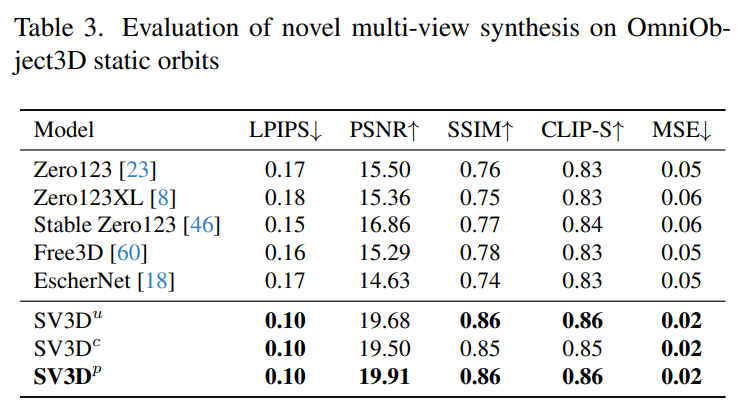
Hasil perbandingan visual dalam Rajah 6 di bawah menunjukkan lagi bahawa berbanding dengan kerja sebelumnya, imej yang dihasilkan oleh Stable Video 3D adalah lebih terperinci, lebih setia kepada imej bersyarat dan lebih konsisten merentas pelbagai perspektif . 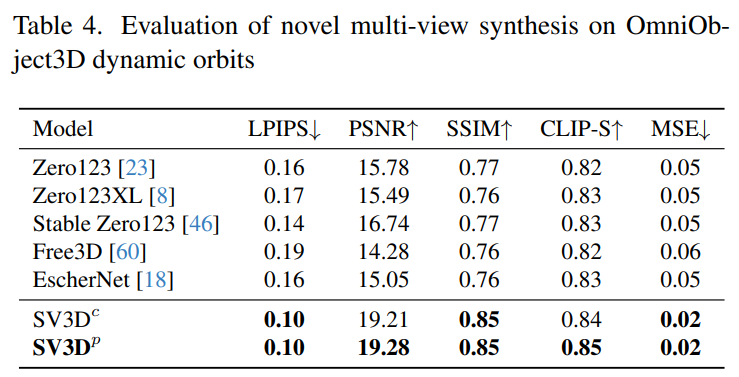
Sila rujuk kertas asal untuk butiran lanjut teknikal dan keputusan percubaan. 
Atas ialah kandungan terperinci Stable Video 3D membuat penampilan pertama yang mengejutkan: satu imej menghasilkan video 3D tanpa bintik buta dan berat model dibuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Untuk membuat pangkalan data Oracle, kaedah biasa adalah menggunakan alat grafik DBCA. Langkah -langkah adalah seperti berikut: 1. Gunakan alat DBCA untuk menetapkan DBName untuk menentukan nama pangkalan data; 2. Tetapkan SYSPASSWORD dan SYSTEMPASSWORD kepada kata laluan yang kuat; 3. Tetapkan aksara dan NationalCharacterset ke Al32utf8; 4. Tetapkan MemorySize dan Tablespacesize untuk menyesuaikan mengikut keperluan sebenar; 5. Tentukan laluan logfile. Kaedah lanjutan dibuat secara manual menggunakan arahan SQL, tetapi lebih kompleks dan terdedah kepada kesilapan. Perhatikan kekuatan kata laluan, pemilihan set aksara, saiz dan memori meja makan
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Mewujudkan pangkalan data Oracle tidak mudah, anda perlu memahami mekanisme asas. 1. Anda perlu memahami konsep pangkalan data dan Oracle DBMS; 2. Menguasai konsep teras seperti SID, CDB (pangkalan data kontena), PDB (pangkalan data pluggable); 3. Gunakan SQL*Plus untuk membuat CDB, dan kemudian buat PDB, anda perlu menentukan parameter seperti saiz, bilangan fail data, dan laluan; 4. Aplikasi lanjutan perlu menyesuaikan set aksara, memori dan parameter lain, dan melakukan penalaan prestasi; 5. Beri perhatian kepada ruang cakera, keizinan dan parameter, dan terus memantau dan mengoptimumkan prestasi pangkalan data. Hanya dengan menguasai ia dengan mahir memerlukan amalan yang berterusan, anda boleh benar -benar memahami penciptaan dan pengurusan pangkalan data Oracle.
 Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Inti dari pernyataan Oracle SQL adalah pilih, masukkan, mengemas kini dan memadam, serta aplikasi fleksibel dari pelbagai klausa. Adalah penting untuk memahami mekanisme pelaksanaan di sebalik pernyataan, seperti pengoptimuman indeks. Penggunaan lanjutan termasuk subqueries, pertanyaan sambungan, fungsi analisis, dan PL/SQL. Kesilapan umum termasuk kesilapan sintaks, isu prestasi, dan isu konsistensi data. Amalan terbaik pengoptimuman prestasi melibatkan menggunakan indeks yang sesuai, mengelakkan pilih *, mengoptimumkan di mana klausa, dan menggunakan pembolehubah terikat. Menguasai Oracle SQL memerlukan amalan, termasuk penulisan kod, debugging, berfikir dan memahami mekanisme asas.
 Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Panduan Operasi Lapangan di MySQL: Tambah, mengubah suai, dan memadam medan. Tambahkan medan: alter table table_name tambah column_name data_type [not null] [default default_value] [primary kekunci] [AUTO_INCREMENT] Modify Field: Alter Table Table_Name Ubah suai column_name data_type [not null] [default default_value] [Kunci Utama]
 Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Kekangan integriti pangkalan data Oracle dapat memastikan ketepatan data, termasuk: tidak null: nilai null dilarang; Unik: Keunikan menjamin, membolehkan nilai null tunggal; Kunci utama: kekangan utama utama, menguatkan unik, dan melarang nilai null; Kunci asing: Mengekalkan hubungan antara jadual, kunci asing merujuk kepada kunci utama jadual utama; Semak: Hadkan nilai lajur mengikut syarat.
 Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Pertanyaan bersarang adalah cara untuk memasukkan pertanyaan lain dalam satu pertanyaan. Mereka digunakan terutamanya untuk mendapatkan data yang memenuhi syarat kompleks, mengaitkan pelbagai jadual, dan mengira nilai ringkasan atau maklumat statistik. Contohnya termasuk mencari pekerja di atas gaji purata, mencari pesanan untuk kategori tertentu, dan mengira jumlah jumlah pesanan bagi setiap produk. Apabila menulis pertanyaan bersarang, anda perlu mengikuti: Tulis subqueries, tulis hasilnya kepada pertanyaan luar (dirujuk dengan alias atau sebagai klausa), dan mengoptimumkan prestasi pertanyaan (menggunakan indeks).
 Apa yang dilakukan Oracle
Apr 11, 2025 pm 06:06 PM
Apa yang dilakukan Oracle
Apr 11, 2025 pm 06:06 PM
Oracle adalah syarikat perisian Sistem Pengurusan Pangkalan Data (DBMS) terbesar di dunia. Produk utamanya termasuk fungsi berikut: Sistem Pengurusan Pengurusan Pangkalan Data Relasi (Oracle Database) Alat Pembangunan (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle SOA Suite) Analisis Awan (Oracle Cloud Infrastructure)
 Cara Mengkonfigurasi Format Log Debian Apache
Apr 12, 2025 pm 11:30 PM
Cara Mengkonfigurasi Format Log Debian Apache
Apr 12, 2025 pm 11:30 PM
Artikel ini menerangkan cara menyesuaikan format log Apache pada sistem Debian. Langkah -langkah berikut akan membimbing anda melalui proses konfigurasi: Langkah 1: Akses fail konfigurasi Apache Fail konfigurasi Apache utama sistem Debian biasanya terletak di /etc/apache2/apache2.conf atau /etc/apache2/httpd.conf. Buka fail konfigurasi dengan kebenaran root menggunakan arahan berikut: Sudonano/etc/Apache2/Apache2.conf atau Sudonano/etc/Apache2/httpd.conf Langkah 2: Tentukan format log tersuai untuk mencari atau
