
 Peranti teknologi
AI
Satu artikel untuk memahami cabaran teknikal dan strategi pengoptimuman untuk memperhalusi model bahasa besar
Peranti teknologi
AI
Satu artikel untuk memahami cabaran teknikal dan strategi pengoptimuman untuk memperhalusi model bahasa besar
Satu artikel untuk memahami cabaran teknikal dan strategi pengoptimuman untuk memperhalusi model bahasa besar

Hello semua, nama saya Luga. Hari ini kami akan terus meneroka teknologi dalam ekosistem kecerdasan buatan, terutamanya LLM Penalaan Halus. Artikel ini akan terus menganalisis teknologi Penalaan Halus LLM secara mendalam untuk membantu semua orang memahami mekanisme pelaksanaannya dengan lebih baik supaya ia boleh digunakan dengan lebih baik pada pembangunan pasaran dan bidang lain.

LLM (Model Bahasa Besar) menerajui gelombang baharu teknologi kecerdasan buatan. AI lanjutan ini mensimulasikan kebolehan kognitif dan bahasa manusia dengan menganalisis sejumlah besar data menggunakan model statistik untuk mempelajari corak kompleks antara perkataan dan frasa. Fungsi berkuasa LLM telah menimbulkan minat yang kuat daripada banyak syarikat terkemuka dan peminat teknologi, yang tergesa-gesa untuk menerima pakai penyelesaian inovatif ini yang didorong oleh kecerdasan buatan, bertujuan untuk meningkatkan kecekapan operasi, mengurangkan beban kerja, mengurangkan perbelanjaan kos, dan akhirnya memberi inspirasi. idea yang lebih inovatif yang mencipta nilai perniagaan.
Namun, untuk benar-benar merealisasikan potensi LLM, kuncinya terletak pada "penyesuaian". Iaitu, cara perusahaan boleh mengubah model umum pra-latihan kepada model eksklusif yang memenuhi keperluan perniagaan unik mereka sendiri dan menggunakan senario kes melalui strategi pengoptimuman khusus. Memandangkan perbezaan antara perusahaan yang berbeza dan senario aplikasi, adalah amat penting untuk memilih kaedah penyepaduan LLM yang sesuai. Oleh itu, menilai dengan tepat keperluan kes penggunaan khusus dan memahami perbezaan dan pertukaran halus antara pilihan penyepaduan yang berbeza akan membantu perusahaan membuat keputusan termaklum.
Apakah Penalaan Halus?
Dalam era popularisasi pengetahuan hari ini, tidak pernah semudah ini untuk mendapatkan maklumat dan pendapat tentang AI dan LLM. Walau bagaimanapun, mencari jawapan profesional yang praktikal dan khusus konteks tetap menjadi cabaran. Dalam kehidupan seharian kita, kita sering menghadapi salah faham seperti ini: secara umumnya dipercayai bahawa model Penalaan Halus (penalaan halus) adalah satu-satunya (atau mungkin cara terbaik) untuk LLM memperoleh pengetahuan baharu. Malah, sama ada anda menambah pembantu kolaboratif pintar pada produk anda atau menggunakan LLM untuk menganalisis sejumlah besar data tidak berstruktur yang disimpan dalam awan, data sebenar dan persekitaran perniagaan anda merupakan faktor utama dalam memilih pendekatan LLM yang betul.
Dalam banyak kes, selalunya lebih berkesan untuk menggunakan strategi alternatif yang kurang kompleks untuk dikendalikan, lebih mantap kepada set data yang kerap berubah, dan menghasilkan keputusan yang lebih dipercayai dan tepat daripada kaedah penalaan halus tradisional. Walaupun penalaan halus ialah teknik penyesuaian LLM biasa yang melaksanakan latihan tambahan pada model pra-latihan pada set data tertentu untuk menyesuaikannya dengan lebih baik kepada tugas atau domain tertentu, ia juga mempunyai beberapa pertukaran dan pengehadan yang penting.
Jadi, apakah itu Fine-Tuning?
LLM (Large Language Model) fine-tuning merupakan salah satu teknologi yang telah menarik perhatian ramai dalam bidang NLP (Natural Language Processing) sejak beberapa tahun kebelakangan ini. Ia membolehkan model menyesuaikan diri dengan lebih baik pada domain atau tugas tertentu dengan melakukan latihan tambahan pada model yang sudah terlatih. Kaedah ini membolehkan model mempelajari lebih banyak pengetahuan yang berkaitan dengan domain tertentu, dengan itu mencapai prestasi yang lebih baik dalam domain atau tugasan ini. Kelebihan penalaan halus LLM ialah ia mengambil kesempatan daripada pengetahuan am yang telah dipelajari oleh model pra-latihan, dan kemudian memperhalusinya lagi pada domain tertentu untuk mencapai ketepatan dan prestasi yang lebih tinggi pada tugasan tertentu. Kaedah ini telah digunakan secara meluas dalam pelbagai tugasan NLP dan telah mencapai hasil yang ketara Konsep utama penalaan halus LLM adalah menggunakan parameter model pra-latihan sebagai asas untuk tugasan baharu, dan menjadikan model diperhalusi. sejumlah kecil domain atau data tugasan tertentu Keupayaan untuk menyesuaikan diri dengan cepat kepada tugasan atau set data baharu. Kaedah ini boleh menjimatkan banyak masa dan sumber latihan sambil meningkatkan prestasi model pada tugasan baharu. Fleksibiliti dan kecekapan penalaan halus LLM menjadikannya salah satu kaedah pilihan dalam banyak tugas pemprosesan bahasa semula jadi. Dengan memperhalusi di atas model yang telah dilatih, model itu boleh mempelajari ciri dan corak untuk tugasan baharu dengan lebih pantas, sekali gus meningkatkan prestasi keseluruhan. Ini
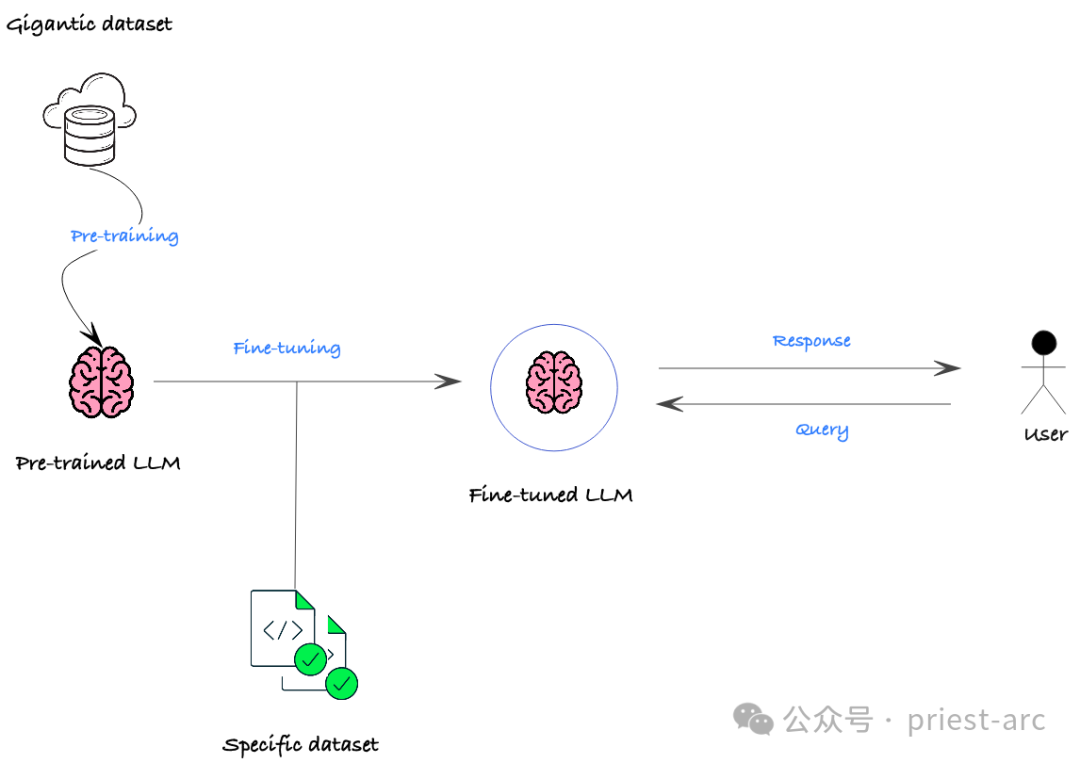 Dalam senario perniagaan sebenar, tujuan utama penalaan halus biasanya termasuk perkara berikut:
Dalam senario perniagaan sebenar, tujuan utama penalaan halus biasanya termasuk perkara berikut:
(1) Penyesuaian domain
LLM biasanya dilatih pada data umum merentas domain, tetapi apabila digunakan pada bidang Dalam tertentu seperti kewangan, perubatan, undang-undang dan senario lain, prestasi mungkin terjejas dengan teruk. Melalui penalaan halus, model pra-latihan boleh dilaraskan dan disesuaikan dengan domain sasaran supaya ia dapat menangkap dengan lebih baik ciri-ciri bahasa dan hubungan semantik domain tertentu, seterusnya meningkatkan prestasi dalam domain ini.
(2) Penyesuaian tugas
Walaupun dalam bidang yang sama, tugasan khusus yang berbeza mungkin mempunyai keperluan yang berbeza. Tugas NLP seperti klasifikasi teks, menjawab soalan, pengecaman entiti bernama, dsb. semuanya akan mengemukakan keperluan yang berbeza untuk pemahaman bahasa dan keupayaan penjanaan. Melalui penalaan halus, penunjuk prestasi model pada tugas tertentu, seperti ketepatan, Ingat, nilai F1, dsb., boleh dioptimumkan mengikut keperluan khusus tugas hiliran.
(3) Peningkatan prestasi
Walaupun pada tugas tertentu, model pra-latihan mungkin mempunyai kesesakan dalam ketepatan, kelajuan, dsb. Melalui penalaan halus, kami boleh meningkatkan lagi prestasi model pada tugasan ini. Contohnya, untuk senario aplikasi masa nyata yang memerlukan kelajuan inferens yang tinggi, model boleh dimampatkan dan dioptimumkan untuk tugas utama yang memerlukan ketepatan yang lebih tinggi, keupayaan pertimbangan model juga boleh dipertingkatkan lagi melalui penalaan halus.
Apakah faedah dan kesukaran yang dihadapi oleh Penalaan Halus (penalaan halus)?
Secara amnya, faedah utama Penalaan Halus (penalaan halus) ialah ia dapat meningkatkan prestasi model pra-latihan sedia ada dengan berkesan dalam senario aplikasi tertentu. Melalui latihan berterusan dan pelarasan parameter model asas dalam bidang sasaran atau tugas, ia boleh menangkap ciri dan corak semantik dengan lebih baik dalam senario tertentu, dengan itu meningkatkan dengan ketara penunjuk utama model dalam bidang atau tugasan ini. Contohnya, dengan memperhalusi model Llama 2, prestasi pada beberapa ciri boleh menjadi lebih baik daripada pelaksanaan model bahasa asal Meta.
Walaupun Penalaan Halus membawa faedah yang ketara kepada LLM, terdapat juga beberapa kelemahan yang perlu dipertimbangkan. Jadi, apakah dilema yang dihadapi oleh Penalaan Halus (fine-tuning)? semasa pra-latihan. Ini boleh berlaku jika data nudge terlalu khusus atau tertumpu terutamanya pada kawasan yang sempit.
Keperluan Data: Walaupun penalaan halus memerlukan kurang data berbanding latihan dari awal, data berkualiti tinggi dan berkaitan masih diperlukan untuk tugasan tertentu. Data yang tidak mencukupi atau tidak dilabelkan dengan betul boleh menyebabkan prestasi yang lemah.
- Sumber pengiraan: Proses penalaan halus kekal mahal dari segi pengiraan, terutamanya untuk model kompleks dan set data yang besar. Bagi organisasi yang lebih kecil atau mereka yang mempunyai sumber terhad, ini boleh menjadi penghalang.
- Kepakaran diperlukan: Penalaan halus selalunya memerlukan kepakaran dalam bidang seperti pembelajaran mesin, NLP dan tugas khusus yang ada. Memilih model pralatihan yang betul, mengkonfigurasi hiperparameter dan menilai keputusan boleh menjadi rumit bagi mereka yang tidak mempunyai pengetahuan yang diperlukan.
- Isu berpotensi:
- Penguatan bias: Model pra-latihan boleh mewarisi berat sebelah daripada data latihan mereka. Jika data yang didorong mencerminkan bias yang serupa, dorongan tersebut mungkin secara tidak sengaja menguatkan bias ini. Ini boleh membawa kepada hasil yang tidak adil atau diskriminasi.
Cabaran Kebolehtafsiran: Model yang diperhalusi adalah lebih sukar untuk ditafsirkan daripada model yang telah dilatih. Memahami cara model mencapai keputusannya boleh menjadi sukar, yang boleh menghalang nyahpepijat dan mempercayai output model.
- Risiko Keselamatan: Model yang diperhalusi mungkin terdedah kepada serangan musuh, di mana pelaku berniat jahat memanipulasi data input, menyebabkan model menghasilkan output yang salah.
- Bagaimana Penalaan Halus berbanding kaedah penyesuaian lain?
- Secara umumnya, Penalaan Halus bukanlah satu-satunya cara untuk menyesuaikan output model atau menyepadukan data tersuai. Malah, ia mungkin tidak sesuai untuk keperluan khusus dan kes penggunaan kami, terdapat beberapa alternatif lain yang patut diterokai dan dipertimbangkan, seperti berikut:
Strategi ini agak mudah, tetapi pendekatan dipacu data masih harus digunakan untuk menilai secara kuantitatif ketepatan pelbagai petua untuk memastikan prestasi yang diingini. Dengan cara ini, kita boleh memperhalusi isyarat secara sistematik untuk mencari cara paling berkesan untuk membimbing model menghasilkan output yang diingini.
Namun, Prompt Engineering bukan tanpa kekurangannya. Pertama, ia tidak boleh secara langsung menyepadukan set data yang besar kerana gesaan biasanya diubah suai dan digunakan secara manual. Ini bermakna Prompt Engineering mungkin kelihatan kurang cekap apabila memproses data berskala besar. 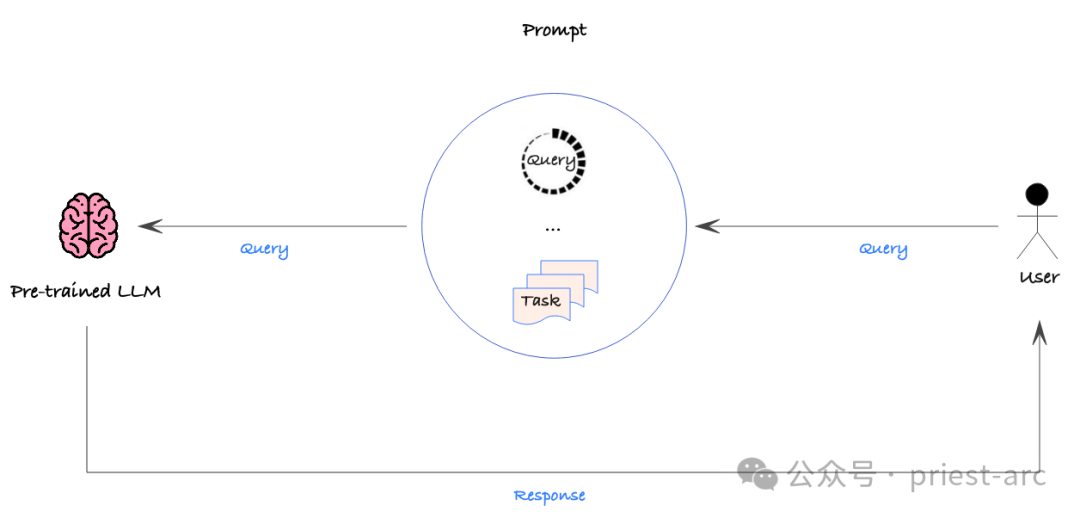
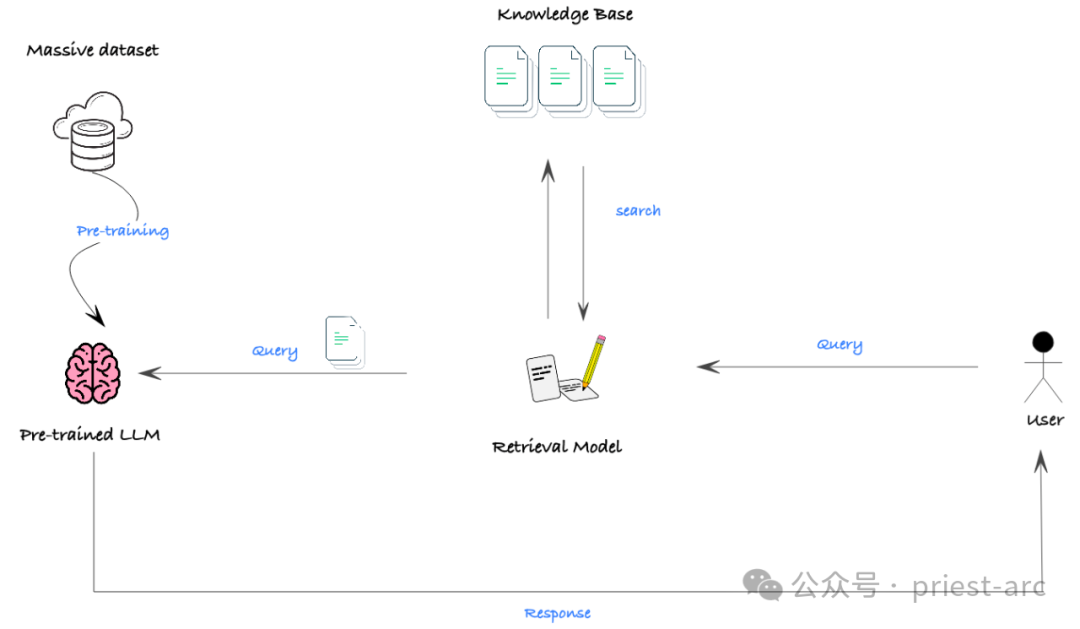
Dalam senario sebenar, halangan terbesar kepada keberkesanan RAG ialah banyak model mempunyai tetingkap konteks terhad, iaitu panjang maksimum teks yang boleh diproses oleh model pada satu masa adalah terhad. Dalam sesetengah situasi di mana pengetahuan latar belakang yang luas diperlukan, ia mungkin menghalang model daripada mendapatkan maklumat yang mencukupi untuk mencapai prestasi yang baik.
Namun, dengan perkembangan pesat teknologi, tetingkap konteks model berkembang pesat. Malah beberapa model sumber terbuka telah dapat mengendalikan input teks panjang sehingga 32,000 token. Ini bermakna RAG akan mempunyai prospek aplikasi yang lebih luas pada masa hadapan dan boleh memberikan sokongan yang kuat untuk tugas yang lebih kompleks.
Seterusnya, mari kita fahami dan bandingkan prestasi khusus ketiga-tiga teknologi ini dari segi privasi data, sila rujuk perkara berikut:
(1) Penalaan Halus (penalaan halus)
Penalaan Halus (. penalaan halus) ) ialah maklumat yang digunakan semasa melatih model dikodkan ke dalam parameter model. Ini bermakna walaupun output model adalah peribadi kepada pengguna, data latihan asas mungkin masih bocor. Penyelidikan menunjukkan bahawa penyerang berniat jahat juga boleh mengekstrak data latihan mentah daripada model melalui serangan suntikan. Oleh itu, kita mesti menganggap bahawa sebarang data yang digunakan untuk melatih model mungkin boleh diakses oleh pengguna masa hadapan.
(2) Prompt Engineering
Sebagai perbandingan, jejak keselamatan data Prompt Engineering jauh lebih kecil. Oleh kerana gesaan boleh diasingkan dan disesuaikan untuk setiap pengguna, data yang terkandung dalam gesaan yang dilihat oleh pengguna yang berbeza mungkin berbeza. Tetapi kami masih perlu memastikan bahawa sebarang data yang terkandung dalam gesaan itu tidak sensitif atau dibenarkan kepada mana-mana pengguna yang mempunyai akses kepada gesaan itu.
(3) RAG (Retrieval Enhancement Generation)
Keselamatan RAG bergantung pada kawalan capaian data dalam sistem perolehan asasnya. Kami perlu memastikan bahawa pangkalan data vektor asas dan templat segera dikonfigurasikan dengan privasi dan kawalan data yang sesuai untuk menghalang capaian yang tidak dibenarkan. Hanya dengan cara ini RAG boleh benar-benar memastikan privasi data.
Secara keseluruhannya, Prompt Engineering dan RAG mempunyai kelebihan yang jelas berbanding penalaan halus dalam hal privasi data. Tetapi tidak kira kaedah yang digunakan, kami mesti mengurus akses data dan perlindungan privasi dengan berhati-hati untuk memastikan maklumat sensitif pengguna dilindungi sepenuhnya.
Jadi, dalam erti kata lain, sama ada kita akhirnya memilih Fine-Tuning, Prompt Engineering atau RAG, pendekatan yang diguna pakai harus konsisten dengan matlamat strategik organisasi, sumber yang ada, kemahiran profesional dan jangkaan pulangan pelaburan Sangat konsisten. Ini bukan sahaja tentang keupayaan teknikal tulen, tetapi juga tentang cara pendekatan ini sesuai dengan strategi perniagaan, garis masa, aliran kerja semasa dan keperluan pasaran kami.
Memahami selok-belok pilihan Penalaan Halus adalah kunci untuk membuat keputusan termaklum. Butiran teknikal dan penyediaan data yang terlibat dalam Penalaan Halus adalah agak kompleks dan memerlukan pemahaman yang mendalam tentang model dan data. Oleh itu, adalah penting untuk bekerjasama rapat dengan rakan kongsi yang mempunyai pengalaman penalaan halus yang meluas. Rakan kongsi ini bukan sahaja mesti mempunyai keupayaan teknikal yang boleh dipercayai, tetapi juga dapat memahami sepenuhnya proses dan matlamat perniagaan kami serta memilih penyelesaian teknologi tersuai yang paling sesuai untuk kami.
Begitu juga, jika kami memilih untuk menggunakan Prompt Engineering atau RAG, kami juga perlu menilai dengan teliti sama ada kaedah ini boleh sepadan dengan keperluan perniagaan kami, keadaan sumber dan kesan yang dijangkakan. Akhirnya kejayaan hanya boleh dicapai dengan memastikan bahawa teknologi tersuai yang dipilih benar-benar boleh mencipta nilai untuk organisasi kita.
Rujukan:
- [1] https://medium.com/@younesh.kc/rag-vs-fine-tuning-in-large-language-models-a-comparison-c765b9e21328
- [2] https ://kili-technology.com/large-language-models-llms/the-ultimate-guide-to-fine-tuning-llms-2023
Atas ialah kandungan terperinci Satu artikel untuk memahami cabaran teknikal dan strategi pengoptimuman untuk memperhalusi model bahasa besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara Mengkonfigurasi Format Log Debian Apache
Apr 12, 2025 pm 11:30 PM
Cara Mengkonfigurasi Format Log Debian Apache
Apr 12, 2025 pm 11:30 PM
Artikel ini menerangkan cara menyesuaikan format log Apache pada sistem Debian. Langkah -langkah berikut akan membimbing anda melalui proses konfigurasi: Langkah 1: Akses fail konfigurasi Apache Fail konfigurasi Apache utama sistem Debian biasanya terletak di /etc/apache2/apache2.conf atau /etc/apache2/httpd.conf. Buka fail konfigurasi dengan kebenaran root menggunakan arahan berikut: Sudonano/etc/Apache2/Apache2.conf atau Sudonano/etc/Apache2/httpd.conf Langkah 2: Tentukan format log tersuai untuk mencari atau
 Bagaimana log tomcat membantu menyelesaikan masalah kebocoran memori
Apr 12, 2025 pm 11:42 PM
Bagaimana log tomcat membantu menyelesaikan masalah kebocoran memori
Apr 12, 2025 pm 11:42 PM
Log Tomcat adalah kunci untuk mendiagnosis masalah kebocoran memori. Dengan menganalisis log tomcat, anda boleh mendapatkan wawasan mengenai kelakuan memori dan pengumpulan sampah (GC), dengan berkesan mencari dan menyelesaikan kebocoran memori. Berikut adalah cara menyelesaikan masalah kebocoran memori menggunakan log Tomcat: 1. GC Log Analysis terlebih dahulu, membolehkan pembalakan GC terperinci. Tambah pilihan JVM berikut kepada parameter permulaan TOMCAT: -XX: PrintGCDetails-XX: PrintGCDATestamps-XLogGC: GC.LOG Parameter ini akan menghasilkan log GC terperinci (GC.LOG), termasuk maklumat seperti jenis GC, saiz dan masa yang dikitar semula. Analisis GC.Log
 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
 Cara Mengkonfigurasi Peraturan Firewall Untuk Debian Syslog
Apr 13, 2025 am 06:51 AM
Cara Mengkonfigurasi Peraturan Firewall Untuk Debian Syslog
Apr 13, 2025 am 06:51 AM
Artikel ini menerangkan cara mengkonfigurasi peraturan firewall menggunakan iptables atau UFW dalam sistem debian dan menggunakan syslog untuk merakam aktiviti firewall. Kaedah 1: Gunakan IPTableSiptable adalah alat firewall baris perintah yang kuat dalam sistem Debian. Lihat peraturan yang ada: Gunakan arahan berikut untuk melihat peraturan iptables semasa: sudoiptables-l-n-v membolehkan akses IP tertentu: sebagai contoh, membenarkan alamat IP 192.168.1.100 untuk mengakses port 80: sudoiptables-ainput-pTCP-Dport80-S192.16
 Cara Belajar Debian Syslog
Apr 13, 2025 am 11:51 AM
Cara Belajar Debian Syslog
Apr 13, 2025 am 11:51 AM
Panduan ini akan membimbing anda untuk belajar cara menggunakan syslog dalam sistem Debian. SYSLOG adalah perkhidmatan utama dalam sistem Linux untuk sistem pembalakan dan mesej log aplikasi. Ia membantu pentadbir memantau dan menganalisis aktiviti sistem untuk mengenal pasti dan menyelesaikan masalah dengan cepat. 1. Pengetahuan asas syslog Fungsi teras syslog termasuk: mengumpul dan menguruskan mesej log secara terpusat; menyokong pelbagai format output log dan lokasi sasaran (seperti fail atau rangkaian); Menyediakan fungsi tontonan log dan penapisan masa nyata. 2. Pasang dan konfigurasikan syslog (menggunakan rsyslog) Sistem Debian menggunakan rsyslog secara lalai. Anda boleh memasangnya dengan arahan berikut: sudoaptupdatesud
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
