
 Peranti teknologi
AI
Anggaran kedalaman SOTA! Gabungan penyesuaian kedalaman monokular dan sekeliling untuk pemanduan autonomi
Peranti teknologi
AI
Anggaran kedalaman SOTA! Gabungan penyesuaian kedalaman monokular dan sekeliling untuk pemanduan autonomi
Anggaran kedalaman SOTA! Gabungan penyesuaian kedalaman monokular dan sekeliling untuk pemanduan autonomi

Ditulis sebelum & pemahaman peribadi
Anggaran kedalaman berbilang paparan telah mencapai prestasi tinggi dalam pelbagai ujian penanda aras. Walau bagaimanapun, hampir semua sistem berbilang paparan semasa bergantung pada pose kamera ideal yang diberikan, yang tidak tersedia dalam banyak senario dunia sebenar, seperti pemanduan autonomi. Kerja ini mencadangkan penanda aras kekukuhan baharu untuk menilai sistem anggaran kedalaman di bawah pelbagai tetapan pose bising. Yang menghairankan, didapati kaedah anggaran kedalaman berbilang paparan semasa atau kaedah gabungan pandangan tunggal dan berbilang pandangan gagal apabila diberikan tetapan pose bising. Untuk menangani cabaran ini, di sini kami mencadangkan AFNet, sistem anggaran kedalaman bercantum satu pandangan dan berbilang paparan yang menyepadukan secara adaptif hasil berbilang pandangan dan pandangan tunggal berkeyakinan tinggi untuk mencapai anggaran kedalaman yang mantap dan tepat. Modul gabungan adaptif melakukan gabungan dengan memilih kawasan berkeyakinan tinggi secara dinamik antara kedua-dua cawangan berdasarkan peta keyakinan bungkusan. Oleh itu, apabila berhadapan dengan pemandangan tanpa tekstur, penentukuran yang tidak tepat, objek dinamik dan keadaan lain yang terdegradasi atau mencabar, sistem cenderung untuk memilih cawangan yang lebih dipercayai. Di bawah ujian kekukuhan, kaedah ini mengatasi kaedah berbilang pandangan dan gabungan terkini. Selain itu, prestasi tercanggih dicapai pada penanda aras yang mencabar (KITTI dan DDAD).
Pautan kertas: https://arxiv.org/pdf/2403.07535.pdf
Nama kertas: Gabungan Suaian Kedalaman Pandangan Tunggal dan Pelbagai Pandangan untuk Pemanduan Autonomi
Latar belakang medan
sentiasa ada estimasi imej telah Satu cabaran dalam bidang penglihatan komputer dengan pelbagai aplikasi. Untuk sistem pemanduan autonomi berasaskan penglihatan, persepsi kedalaman adalah kunci, membantu memahami objek di jalan raya dan membina peta 3D persekitaran. Dengan aplikasi rangkaian neural dalam dalam pelbagai masalah visual, kaedah berdasarkan rangkaian neural konvolusi (CNN) telah menjadi arus utama tugas anggaran kedalaman. Mengikut format input, ia terbahagi terutamanya kepada anggaran kedalaman berbilang pandangan dan anggaran kedalaman pandangan tunggal. Andaian di sebalik kaedah berbilang paparan untuk menganggarkan kedalaman ialah, memandangkan kedalaman yang betul, penentukuran kamera dan pose kamera, piksel merentas paparan sepatutnya serupa. Mereka bergantung pada geometri epipolar untuk menyegitiga ukuran kedalaman berkualiti tinggi. Walau bagaimanapun, ketepatan dan keteguhan kaedah berbilang paparan sangat bergantung pada konfigurasi geometri kamera dan padanan yang sepadan antara pandangan. Pertama, kamera perlu menterjemah cukup untuk membenarkan triangulasi. Dalam senario pandu sendiri, kenderaan sendiri mungkin berhenti di lampu isyarat atau membelok tanpa bergerak ke hadapan, yang boleh menyebabkan triangulasi gagal. Selain itu, kaedah berbilang paparan mengalami masalah sasaran dinamik dan kawasan tanpa tekstur, yang lazim dalam senario pemanduan autonomi. Masalah lain ialah pengoptimuman sikap SLAM pada kenderaan bergerak. Dalam kaedah SLAM sedia ada, bunyi bising tidak dapat dielakkan, apatah lagi situasi yang mencabar dan tidak dapat dielakkan. Sebagai contoh, robot atau kereta pandu sendiri boleh digunakan selama bertahun-tahun tanpa penentukuran semula, menghasilkan pose yang bising. Sebaliknya, memandangkan kaedah pandangan tunggal bergantung pada pemahaman semantik adegan dan isyarat unjuran perspektif, kaedah tersebut lebih teguh kepada kawasan tanpa tekstur, objek dinamik dan tidak bergantung pada pose kamera. Walau bagaimanapun, disebabkan oleh kekaburan skala, prestasinya masih jauh di belakang kaedah berbilang paparan. Di sini, kami cenderung untuk mempertimbangkan sama ada kelebihan kedua-dua kaedah ini boleh digabungkan dengan baik untuk anggaran kedalaman video monokular yang mantap dan tepat dalam senario pemanduan autonomi.Struktur rangkaian AFNet
Struktur AFNet ditunjukkan di bawah Ia terdiri daripada tiga bahagian: cawangan satu pandangan, cawangan berbilang pandangan dan modul gabungan adaptif (AF). Kedua-dua cawangan berkongsi rangkaian pengekstrakan ciri dan mempunyai ramalan dan peta keyakinan mereka sendiri, iaitu, , , dan , dan kemudian digabungkan oleh modul AF untuk mendapatkan ramalan akhir yang tepat dan mantap Latar belakang hijau dalam modul AF mewakili tunggal -lihat cawangan dan Keluaran cawangan berbilang paparan.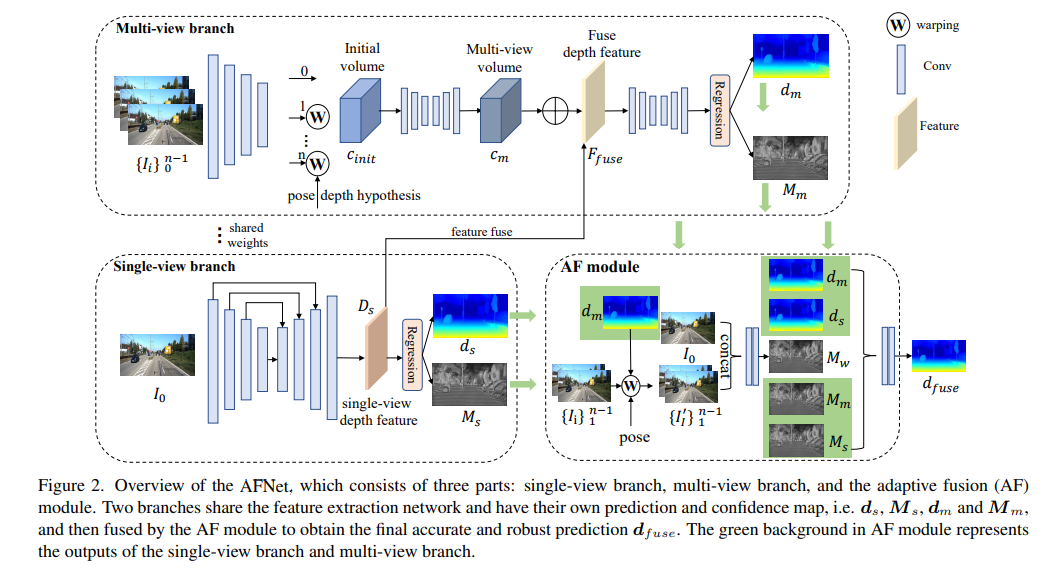

Modul kedalaman paparan tunggal dan berbilang pandangan
Untuk menggabungkan ciri-ciri tulang belakang dan mendapatkan ciri binaan dalam Ds.-AFNet Dalam proses ini, operasi softmax dilakukan pada 256 saluran pertama Ds untuk mendapatkan isipadu kebarangkalian kedalaman Ps. Saluran terakhir dalam ciri kedalaman digunakan sebagai peta keyakinan kedalaman pandangan tunggal Ms. Akhir sekali, kedalaman satu pandangan dikira melalui pemberat lembut.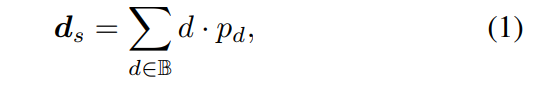
Cawangan berbilang paparan
Cawangan berbilang paparan berkongsi tulang belakang dengan cawangan pandangan tunggal untuk mengekstrak ciri rujukan dan imej sumber. Kami mengguna pakai penyahkonvolusi untuk mengasingkan ciri resolusi rendah kepada resolusi suku dan menggabungkannya dengan ciri suku awal yang digunakan untuk membina volum kos. Isipadu ciri dibentuk dengan membungkus ciri sumber ke dalam satah hipotesis diikuti oleh kamera rujukan. Untuk padanan mantap yang tidak memerlukan terlalu banyak maklumat, dimensi saluran ciri dikekalkan dalam pengiraan dan volum kos 4D dibina, dan kemudian bilangan saluran dikurangkan kepada 1 melalui dua lapisan konvolusi 3D.
Kaedah pensampelan hipotesis kedalaman adalah konsisten dengan cawangan pandangan tunggal, tetapi bilangan sampel hanya 128, dan kemudian diselaraskan menggunakan rangkaian jam pasir 2D bertindan untuk mendapatkan volum kos berbilang paparan akhir. Untuk menambah maklumat semantik yang kaya bagi ciri paparan tunggal dan butiran yang hilang akibat penyelarasan kos, struktur sisa digunakan untuk menggabungkan ciri kedalaman satu paparan Ds dan volum kos untuk mendapatkan ciri kedalaman bersatu seperti berikut:
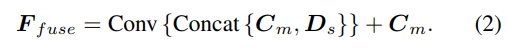
Modul Gabungan Adaptif
Untuk mendapatkan ramalan akhir yang tepat dan mantap, modul AF direka bentuk untuk menyesuaikan secara adaptif kedalaman paling tepat antara kedua-dua cawangan sebagai output akhir, seperti yang ditunjukkan dalam Rajah 2. Pemetaan gabungan dilakukan melalui tiga keyakinan, dua daripadanya ialah peta keyakinan Ms dan Mm masing-masing yang dijana oleh kedua-dua cabang Yang paling kritikal ialah peta keyakinan Mw yang dijana oleh pembalut hadapan untuk menentukan sama ada ramalan cawangan berbilang pandangan itu. boleh dipercayai.
Hasil Eksperimen
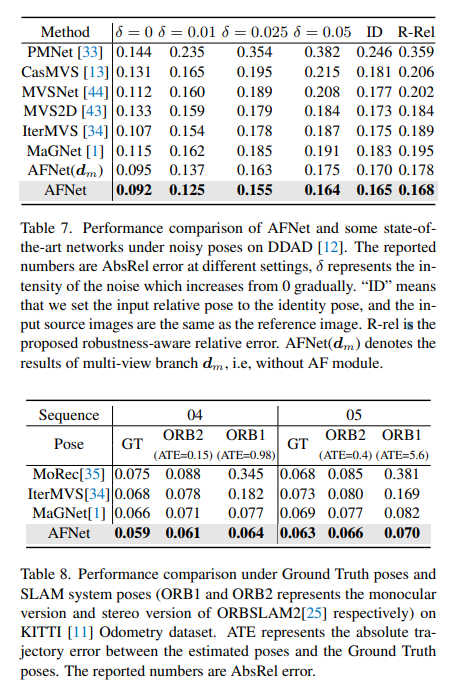
DDAD (Dense Depth for Autonomous Driving) ialah penanda aras pemanduan autonomi baharu untuk anggaran kedalaman padat dalam keadaan bandar yang mencabar dan pelbagai. Ia ditangkap oleh 6 kamera yang disegerakkan dan mengandungi kedalaman tanah yang tepat (keseluruhan medan pandangan 360 darjah) yang dijana oleh lidar berketumpatan tinggi. Ia mempunyai 12650 sampel latihan dan 3950 sampel pengesahan dalam paparan kamera tunggal dengan resolusi 1936×1216. Semua data daripada 6 kamera digunakan untuk latihan dan ujian. Set data KITTI menyediakan imej stereoskopik pemandangan luar yang dirakam pada kenderaan bergerak dan imbasan laser 3D yang sepadan, dengan resolusi lebih kurang 1241×376.
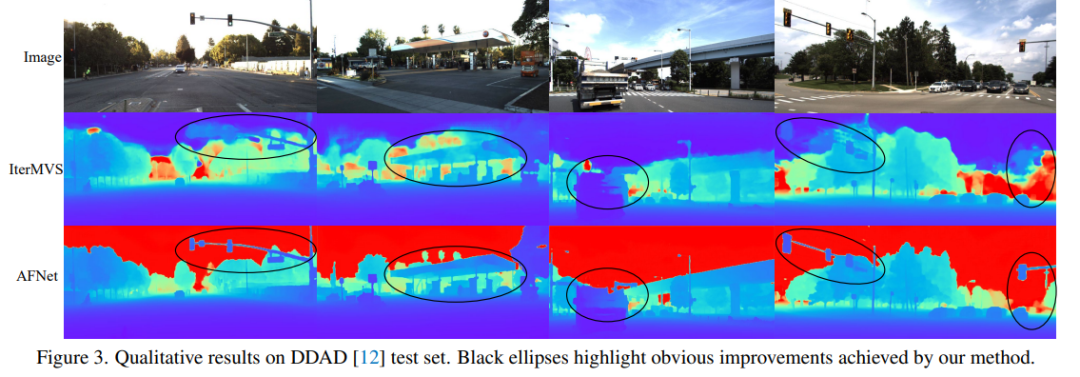
Perbandingan keputusan penilaian pada DDAD dan KITTI. Ambil perhatian bahawa * menandakan keputusan direplikasi menggunakan kod sumber terbuka mereka, nombor lain yang dilaporkan adalah daripada kertas asal yang sepadan.
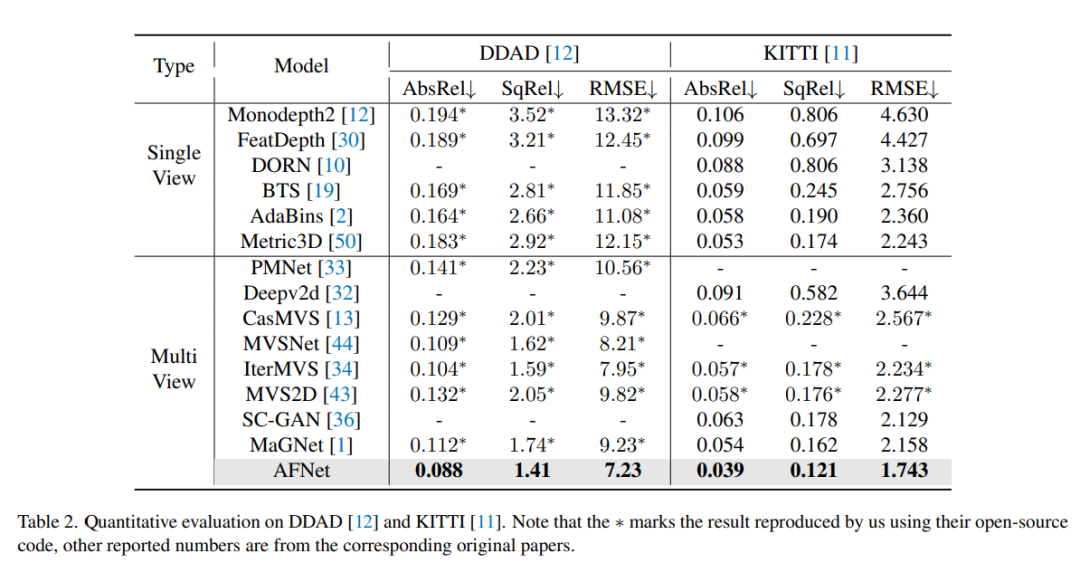
Keputusan percubaan ablasi untuk setiap strategi dalam kaedah pada DDAD. Tunggal mewakili hasil ramalan cawangan pandangan tunggal, Berbilang mewakili hasil ramalan cawangan berbilang paparan, dan Fius mewakili hasil gabungan dfuse.
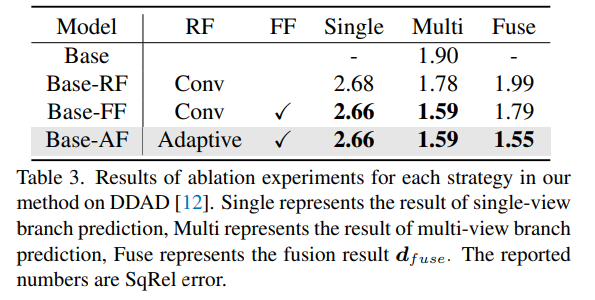
Satu kaedah untuk berkongsi parameter rangkaian dan mengekstrak maklumat padanan untuk pengekstrakan ciri hasil ablasi.
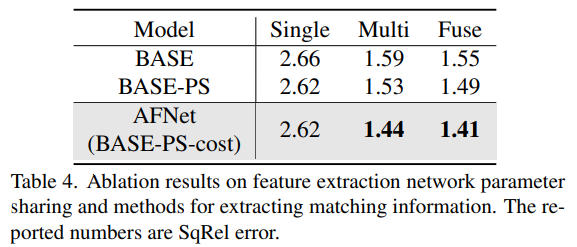
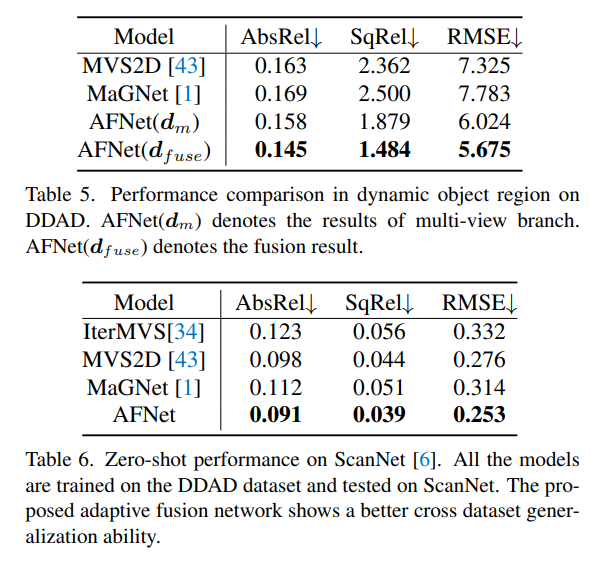

Atas ialah kandungan terperinci Anggaran kedalaman SOTA! Gabungan penyesuaian kedalaman monokular dan sekeliling untuk pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Pendaraban matriks universal CUDA: dari kemasukan kepada kemahiran!
Mar 25, 2024 pm 12:30 PM
Pendaraban matriks universal CUDA: dari kemasukan kepada kemahiran!
Mar 25, 2024 pm 12:30 PM
Pendaraban Matriks Umum (GEMM) ialah bahagian penting dalam banyak aplikasi dan algoritma, dan juga merupakan salah satu petunjuk penting untuk menilai prestasi perkakasan komputer. Penyelidikan mendalam dan pengoptimuman pelaksanaan GEMM boleh membantu kami lebih memahami pengkomputeran berprestasi tinggi dan hubungan antara perisian dan sistem perkakasan. Dalam sains komputer, pengoptimuman GEMM yang berkesan boleh meningkatkan kelajuan pengkomputeran dan menjimatkan sumber, yang penting untuk meningkatkan prestasi keseluruhan sistem komputer. Pemahaman yang mendalam tentang prinsip kerja dan kaedah pengoptimuman GEMM akan membantu kami menggunakan potensi perkakasan pengkomputeran moden dengan lebih baik dan menyediakan penyelesaian yang lebih cekap untuk pelbagai tugas pengkomputeran yang kompleks. Dengan mengoptimumkan prestasi GEMM
 Sistem pemanduan pintar Qiankun ADS3.0 Huawei akan dilancarkan pada bulan Ogos dan akan dilancarkan pada Xiangjie S9 buat kali pertama
Jul 30, 2024 pm 02:17 PM
Sistem pemanduan pintar Qiankun ADS3.0 Huawei akan dilancarkan pada bulan Ogos dan akan dilancarkan pada Xiangjie S9 buat kali pertama
Jul 30, 2024 pm 02:17 PM
Pada 29 Julai, pada majlis pelepasan kereta baharu AITO Wenjie yang ke-400,000, Yu Chengdong, Pengarah Urusan Huawei, Pengerusi Terminal BG, dan Pengerusi Smart Car Solutions BU, menghadiri dan menyampaikan ucapan dan mengumumkan bahawa model siri Wenjie akan akan dilancarkan tahun ini Pada bulan Ogos, Huawei Qiankun ADS 3.0 versi telah dilancarkan, dan ia dirancang untuk terus naik taraf dari Ogos hingga September. Xiangjie S9, yang akan dikeluarkan pada 6 Ogos, akan memperkenalkan sistem pemanduan pintar ADS3.0 Huawei. Dengan bantuan lidar, versi Huawei Qiankun ADS3.0 akan meningkatkan keupayaan pemanduan pintarnya, mempunyai keupayaan bersepadu hujung-ke-hujung, dan mengguna pakai seni bina hujung ke hujung baharu GOD (pengenalpastian halangan am)/PDP (ramalan). membuat keputusan dan kawalan), menyediakan fungsi NCA pemanduan pintar dari ruang letak kereta ke ruang letak kereta, dan menaik taraf CAS3.0
 Versi sistem Apple 16 manakah yang terbaik?
Mar 08, 2024 pm 05:16 PM
Versi sistem Apple 16 manakah yang terbaik?
Mar 08, 2024 pm 05:16 PM
Versi terbaik sistem Apple 16 ialah iOS16.1.4 Versi terbaik sistem iOS16 mungkin berbeza dari orang ke orang Penambahan dan peningkatan dalam pengalaman penggunaan harian juga telah dipuji oleh ramai pengguna. Versi sistem Apple 16 yang manakah adalah yang terbaik Jawapan: iOS16.1.4 Versi terbaik sistem iOS 16 mungkin berbeza dari orang ke orang. Menurut maklumat awam, iOS16, yang dilancarkan pada 2022, dianggap sebagai versi yang sangat stabil dan berprestasi, dan pengguna cukup berpuas hati dengan pengalaman keseluruhannya. Selain itu, penambahan ciri baharu dan penambahbaikan dalam pengalaman penggunaan harian dalam iOS16 juga telah diterima baik oleh ramai pengguna. Terutamanya dari segi hayat bateri yang dikemas kini, prestasi isyarat dan kawalan pemanasan, maklum balas pengguna agak positif. Walau bagaimanapun, memandangkan iPhone14
 Sentiasa baru! Siri Huawei Mate60 dinaik taraf kepada HarmonyOS 4.2: Peningkatan awan AI, Dialek Xiaoyi sangat mudah digunakan
Jun 02, 2024 pm 02:58 PM
Sentiasa baru! Siri Huawei Mate60 dinaik taraf kepada HarmonyOS 4.2: Peningkatan awan AI, Dialek Xiaoyi sangat mudah digunakan
Jun 02, 2024 pm 02:58 PM
Pada 11 April, Huawei secara rasmi mengumumkan pelan peningkatan 100 mesin HarmonyOS 4.2 kali ini, lebih daripada 180 peranti akan mengambil bahagian dalam peningkatan, meliputi telefon bimbit, tablet, jam tangan, fon kepala, skrin pintar dan peranti lain. Pada bulan lalu, dengan kemajuan mantap pelan peningkatan 100 mesin HarmonyOS4.2, banyak model popular termasuk Huawei Pocket2, siri Huawei MateX5, siri nova12, siri Huawei Pura, dll. juga telah mula menaik taraf dan menyesuaikan diri, yang bermaksud bahawa akan ada Lebih ramai pengguna model Huawei boleh menikmati pengalaman biasa dan selalunya baharu yang dibawa oleh HarmonyOS. Berdasarkan maklum balas pengguna, pengalaman model siri Huawei Mate60 telah bertambah baik dalam semua aspek selepas menaik taraf HarmonyOS4.2. Terutamanya Huawei M
 Apakah sistem pengendalian komputer?
Jan 12, 2024 pm 03:12 PM
Apakah sistem pengendalian komputer?
Jan 12, 2024 pm 03:12 PM
Sistem pengendalian komputer ialah sistem yang digunakan untuk mengurus perkakasan komputer dan program perisian Ia juga merupakan program sistem pengendalian yang dibangunkan berdasarkan semua sistem perisian yang berbeza mempunyai pengguna yang berbeza. Di bawah, editor akan berkongsi dengan anda apa itu sistem pengendalian komputer. Apa yang dipanggil sistem pengendalian adalah untuk mengurus perkakasan komputer dan program perisian Semua perisian dibangunkan berdasarkan program sistem pengendalian. Sebenarnya, terdapat banyak jenis sistem pengendalian, termasuk yang untuk kegunaan industri, kegunaan komersial dan kegunaan peribadi, meliputi pelbagai aplikasi. Di bawah, editor akan menerangkan kepada anda apa itu sistem pengendalian komputer. Apakah sistem pengendalian komputer sistem Windows Sistem Windows ialah sistem pengendalian yang dibangunkan oleh Microsoft Corporation dari Amerika Syarikat. daripada kebanyakannya
 Perbezaan dan persamaan arahan cmd dalam sistem Linux dan Windows
Mar 15, 2024 am 08:12 AM
Perbezaan dan persamaan arahan cmd dalam sistem Linux dan Windows
Mar 15, 2024 am 08:12 AM
Linux dan Windows ialah dua sistem pengendalian biasa, masing-masing mewakili sistem Linux sumber terbuka dan sistem Windows komersial. Dalam kedua-dua sistem pengendalian, terdapat antara muka baris arahan untuk pengguna berinteraksi dengan sistem pengendalian. Dalam sistem Linux, pengguna menggunakan baris arahan Shell, manakala dalam sistem Windows, pengguna menggunakan baris arahan cmd. Baris arahan Shell dalam sistem Linux ialah alat yang sangat berkuasa yang boleh menyelesaikan hampir semua tugas pengurusan sistem.
 Penjelasan terperinci tentang cara mengubah suai tarikh sistem dalam pangkalan data Oracle
Mar 09, 2024 am 10:21 AM
Penjelasan terperinci tentang cara mengubah suai tarikh sistem dalam pangkalan data Oracle
Mar 09, 2024 am 10:21 AM
Penjelasan terperinci tentang kaedah mengubah suai tarikh sistem dalam pangkalan data Oracle Dalam pangkalan data Oracle, kaedah mengubah suai tarikh sistem terutamanya melibatkan pengubahsuaian parameter NLS_DATE_FORMAT dan menggunakan fungsi SYSDATE. Artikel ini akan memperkenalkan kedua-dua kaedah ini dan contoh kod khusus mereka secara terperinci untuk membantu pembaca lebih memahami dan menguasai operasi mengubah suai tarikh sistem dalam pangkalan data Oracle. 1. Ubah suai kaedah parameter NLS_DATE_FORMAT NLS_DATE_FORMAT ialah data Oracle
 Di manakah laluan storan fon sistem?
Feb 19, 2024 pm 09:11 PM
Di manakah laluan storan fon sistem?
Feb 19, 2024 pm 09:11 PM
Dalam folder manakah fon sistem terletak dalam sistem komputer moden, fon memainkan peranan penting, mempengaruhi pengalaman membaca kami dan keindahan ekspresi teks. Bagi sesetengah pengguna yang berminat dengan pemperibadian dan penyesuaian, amat penting untuk memahami tempat fon sistem disimpan. Jadi, dalam folder manakah fon sistem disimpan? Artikel ini akan mendedahkannya satu demi satu untuk semua orang. Dalam sistem pengendalian Windows, fon sistem disimpan dalam folder yang dipanggil "Fon". Folder ini terletak dalam pemacu Win C secara lalai.
