
 Peranti teknologi
AI
Berita besar alam semula jadi: AI mengalahkan sistem amaran banjir global yang paling maju dan meramalkan banjir sungai 7 hari lebih awal, menyelamatkan beribu-ribu nyawa setiap tahun
Peranti teknologi
AI
Berita besar alam semula jadi: AI mengalahkan sistem amaran banjir global yang paling maju dan meramalkan banjir sungai 7 hari lebih awal, menyelamatkan beribu-ribu nyawa setiap tahun
Berita besar alam semula jadi: AI mengalahkan sistem amaran banjir global yang paling maju dan meramalkan banjir sungai 7 hari lebih awal, menyelamatkan beribu-ribu nyawa setiap tahun

Banjir adalah salah satu bencana alam yang paling biasa, dengan hampir 1.5 bilion orang di seluruh dunia (19% daripada penduduk dunia) menghadapi risiko banjir. Banjir bukan sahaja menyebabkan kerosakan fizikal yang besar tetapi juga menyebabkan kerugian ekonomi kira-kira AS$50 bilion di seluruh dunia setiap tahun.
Dalam beberapa tahun kebelakangan ini, perubahan iklim yang disebabkan oleh manusia telah meningkatkan lagi kekerapan banjir di beberapa kawasan. Walau bagaimanapun, kaedah peramalan semasa kebanyakannya bergantung pada stesen pemerhatian yang dibina di sepanjang sungai, yang tidak sekata di seluruh dunia Ini menjadikannya lebih sukar untuk meramalkan sungai yang tidak diukur, dan kesan negatifnya dicerminkan terutamanya di negara membangun. Menaik taraf sistem amaran awal supaya kumpulan ini mempunyai akses kepada maklumat yang tepat dan tepat pada masanya boleh menyelamatkan beribu-ribu nyawa setiap tahun.
Jadi, bagaimana untuk mencapai ramalan banjir yang boleh dipercayai pada skala global? Model kecerdasan buatan (AI) mungkin mempunyai janji yang besar.
Gray Nearing dan ahli pasukan daripada pasukan ramalan banjir Google Research telah berjaya membangunkan model kecerdasan buatan yang dilatih menggunakan 5680 tolok sedia ada. Model ini boleh meramalkan air larian harian dengan tepat di kawasan tadahan air yang tidak terurus dalam tempoh tujuh hari akan datang, memberikan sokongan data penting untuk amaran dan pencegahan banjir. Grey Nearing menyatakan bahawa teknologi itu dibangunkan untuk meningkatkan keupayaan meramal risiko banjir supaya langkah-langkah yang perlu boleh diambil tepat pada masanya untuk mengurangkan kesan bencana yang berpotensi. Demonstrasi hasil penyelidikan yang berjaya
Kemudian, mereka menjalankan ujian perbandingan ke atas model kecerdasan buatan ini dengan perisian ramalan banjir jangka pendek dan jangka panjang terkemuka di dunia-Global Flood Alert System (GloFAS). Keputusan menunjukkan bahawa model itu setanding atau lebih baik daripada sistem sedia ada dari segi ketepatan ramalan hari yang sama.
Selain itu, model tersebut menunjukkan tahap ketepatan yang setanding atau lebih tinggi daripada GloFAS dalam meramalkan peristiwa cuaca ekstrem dengan tetingkap pulangan lima tahun, berbanding GloFAS dalam meramalkan peristiwa dengan tetingkap pulangan satu tahun.
Kertas penyelidikan berkaitan bertajuk "Ramalan global banjir melampau di kawasan tadahan air yang tidak terjaga" dan telah diterbitkan dalam jurnal saintifik berwibawa Nature.
Pasukan penyelidik menegaskan bahawa model ini boleh memberikan amaran awal tentang kejadian banjir berskala kecil dan ekstrem yang mungkin berlaku di kawasan tadahan air yang tidak diukur, dan memberikan masa amaran yang lebih lama daripada kaedah sebelumnya. Ini akan membantu meningkatkan akses kepada maklumat amaran banjir yang boleh dipercayai di wilayah negara membangun.
7 hari lebih awal, bagaimana AI melakukannya?
Jadi, bagaimana model kecerdasan buatan ini boleh memberikan ramalan banjir yang boleh dipercayai?
Rangkaian ingatan jangka pendek panjang (LSTM) digunakan sebagai model kecerdasan buatan dalam kajian untuk meramalkan aliran sungai. Model ini berfungsi sama dengan otak manusia dan dapat meramalkan aliran sungai masa hadapan dengan mempelajari urutan data meteorologi. Model ini dibahagikan kepada dua bahagian: pengekod dan penyahkod Pengekod bertanggungjawab untuk memproses data input, dan penyahkod bertanggungjawab untuk menjana hasil ramalan. Dengan cara ini, model itu boleh memberikan ramalan aliran sungai yang tepat dan boleh dipercayai, memberikan sokongan penting untuk pengurusan sumber air dan usaha pencegahan bencana.
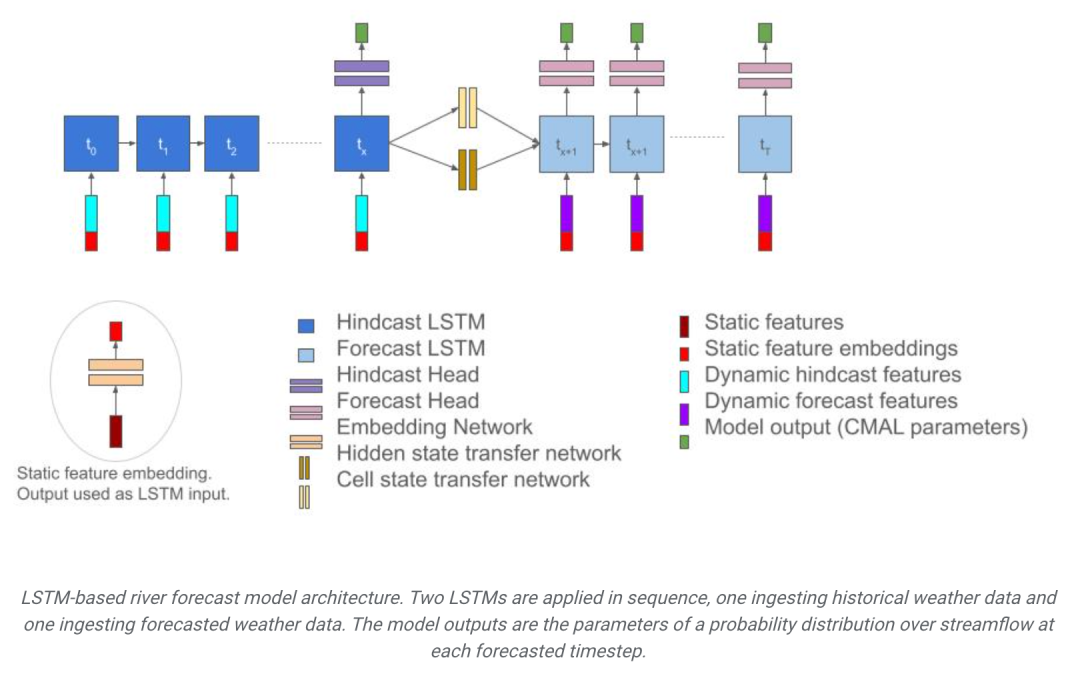
Seni bina model ramalan sungai berdasarkan LSTM. Dua LSTM digunakan secara berurutan, satu menerima data cuaca sejarah dan satu lagi menerima data cuaca yang diramalkan. Output model ialah parameter taburan kebarangkalian aliran pada setiap langkah masa ramalan.
Pertama, pengekod bertanggungjawab mengekstrak maklumat daripada data meteorologi tempoh sebelumnya. Ia memahami perubahan aliran sungai daripada keadaan cuaca lalu. Ia menukar data meteorologi sejarah kepada satu bentuk maklumat yang boleh digunakan oleh penyahkod. Dengan mempelajari ciri dan corak temporal dalam data meteorologi, model membangunkan pemahaman abstrak tentang keadaan meteorologi yang lalu, memberikan input kritikal untuk ramalan aliran seterusnya.
Pengekod menerima satu siri data meteorologi (seperti pemendakan, suhu, sinaran, dll.) sebagai input dan mempelajari cara mengekstrak maklumat ciri utama dalam data ini. Maklumat ciri ini mungkin termasuk perubahan bermusim, peristiwa meteorologi (seperti hujan lebat, suhu tinggi, dll.) dan kesannya terhadap aliran sungai.
Pada masa yang sama, pengekod dapat menangkap kebergantungan temporal antara data meteorologi. Ini bermakna ia bukan sahaja mempertimbangkan keadaan meteorologi pada masa semasa, tetapi juga mempertimbangkan trend perubahan meteorologi dalam tempoh sebelumnya. Dengan belajar daripada data sejarah, pengekod dapat memahami corak siri masa data meteorologi dan memasukkannya ke dalam model.
Dalam pengekod, rangkaian LSTM digunakan untuk memproses data siri masa. LSTM mempunyai unit memori dalaman yang boleh mengingati maklumat lepas dan mengemas kini keadaan dalaman berdasarkan input semasa. Ini membolehkan pengekod berfungsi dengan baik dalam mengendalikan kebergantungan jangka panjang dan mengekalkan maklumat sejarah penting semasa proses pemodelan.
Akhir sekali, pengekod menukar data meteorologi sejarah kepada perwakilan berpotensi yang mengandungi pemahaman dan ringkasan keadaan meteorologi yang lalu. Perwakilan ini ialah output pengekod dan dihantar kepada penyahkod untuk ramalan trafik masa hadapan.
Bahagian penyahkod kemudian menggunakan maklumat ini untuk meramalkan aliran sungai dalam beberapa hari akan datang. Ia mengambil kira ramalan cuaca semasa, serta kesan cuaca lalu terhadap aliran masa hadapan. Dengan cara ini, anda boleh mendapatkan ramalan trafik untuk minggu hadapan.

Penyahkod bertanggungjawab untuk menggabungkan maklumat meteorologi sejarah dan ramalan masa depan dalam model, menjana ramalan aliran sungai masa hadapan dan mengeluarkan taburan kebarangkalian aliran yang sepadan.
Penyahkod mula-mula menerima perwakilan terpendam daripada pengekod, yang mengandungi pemahaman abstrak tentang data meteorologi sejarah. Penyahkod menggunakan maklumat ini untuk memahami kesan keadaan meteorologi yang lalu terhadap aliran sungai dan untuk mewujudkan hubungan antara data sejarah dan ramalan masa depan.
Penyahkod juga menerima data ramalan cuaca masa hadapan sebagai input. Data ramalan ini biasanya termasuk pemendakan, suhu dan penunjuk meteorologi lain dalam beberapa hari akan datang. Penyahkod menggabungkan maklumat sejarah dan ramalan masa depan untuk meramalkan aliran sungai masa hadapan dengan mempelajari hubungan antara mereka.
Setelah memahami keadaan meteorologi sejarah dan ramalan masa depan, penyahkod menjana ramalan aliran sungai masa hadapan melalui rangkaian LSTM bebas. Rangkaian ini boleh difahami sebagai penjana siri masa yang menjana jujukan trafik berdasarkan maklumat lalu dan ramalan masa depan.
Penyahkod bukan sahaja meramalkan nilai aliran sungai masa hadapan, tetapi juga mengeluarkan taburan kebarangkalian. Secara khusus, model menggunakan taburan Laplace sebelah untuk menerangkan ketidakpastian aliran Apabila meramalkan nilai aliran pada setiap langkah masa, ia mengeluarkan parameter taburan Laplace sebelah dan bukannya nilai yang ditentukan. Ini membolehkan model mengambil kira ketidakpastian dalam ramalan aliran, memberikan lebih banyak maklumat untuk membuat keputusan.
Hasil ramalan trafik terakhir diperoleh dengan menyepadukan output berbilang model penyahkod. Model ini menggunakan tiga rangkaian LSTM penyahkod terlatih secara bebas dan kemudian mengambil median ramalan mereka, dengan itu mengurangkan varians ramalan dan meningkatkan kestabilan ramalan.
Bagaimana kesan sebenar?
Penyelidik mengumpul sejumlah besar data meteorologi dan data aliran sungai untuk melatih model ini. Data datang daripada sumber data yang berbeza, termasuk ramalan cuaca, rekod sejarah dan maklumat geografi. Dengan menormalkan data, model memahaminya dengan betul.
Kemudian, data dibahagikan kepada dua jenis: set latihan dan set ujian. Set latihan digunakan untuk melatih model, manakala set ujian digunakan untuk menilai prestasi model. Para penyelidik menggunakan pendekatan "pengesahan silang" untuk memastikan model berfungsi dengan berkesan merentas masa dan lokasi.
Akhir sekali, pasukan penyelidik menilai prestasi model dan membandingkannya dengan model ramalan trafik sedia ada.
Pasukan penyelidik menggunakan metrik ralat biasa untuk mengukur perbezaan antara ramalan model dan pemerhatian sebenar. Oleh kerana model itu meramalkan bukan sahaja nilai khusus aliran masa depan, tetapi juga memberikan ketidakpastian dalam ramalan aliran, mereka menggunakan plot Transformasi Integral Kebarangkalian (PIT) untuk menilai ketepatan pengedaran yang diramalkan.
Pasukan penyelidik juga menilai prestasi model yang dicadangkan dengan membandingkannya dengan model ramalan trafik yang lain. Ini termasuk model fizikal tradisional dan model pembelajaran mesin lain. Dengan membandingkan penunjuk ralat model yang berbeza, kelebihan model yang dicadangkan dari segi ketepatan dan kebolehpercayaan boleh ditunjukkan secara intuitif.
Selain itu, pasukan penyelidik juga menggunakan tadahan air atau sungai tertentu sebagai kajian kes, menggunakan model dalam situasi sebenar dan menganalisis secara terperinci prestasi ramalan model dalam musim yang berbeza dan keadaan iklim yang berbeza. Ini membantu menilai kebolehlaksanaan dan kestabilan model dalam aplikasi praktikal.
Selain penunjuk kuantitatif, pasukan penyelidik juga menjalankan analisis mendalam tentang ketidakpastian ramalan model. Ini termasuk menilai kesan sumber ketidakpastian yang berbeza (seperti ketidakpastian dalam data input, ketidakpastian dalam struktur model, dsb.) pada hasil ramalan dan sejauh mana model masih boleh memberikan ramalan berguna dalam keadaan ketidakpastian.
Hasilnya menunjukkan bahawa model mempamerkan ketepatan dan ingatan yang tinggi, terutamanya untuk acara dengan tempoh pulangan jangka pendek. Ini bermakna model itu dapat mengenal pasti peristiwa banjir dengan tepat dan terlepas lebih sedikit peristiwa.
Menggabungkan ketepatan dan ingatan semula, model ini mencapai skor F1 yang tinggi pada acara dengan tempoh pulangan yang berbeza, menunjukkan bahawa ia mencapai keseimbangan yang baik antara ketepatan dan kekomprekan.
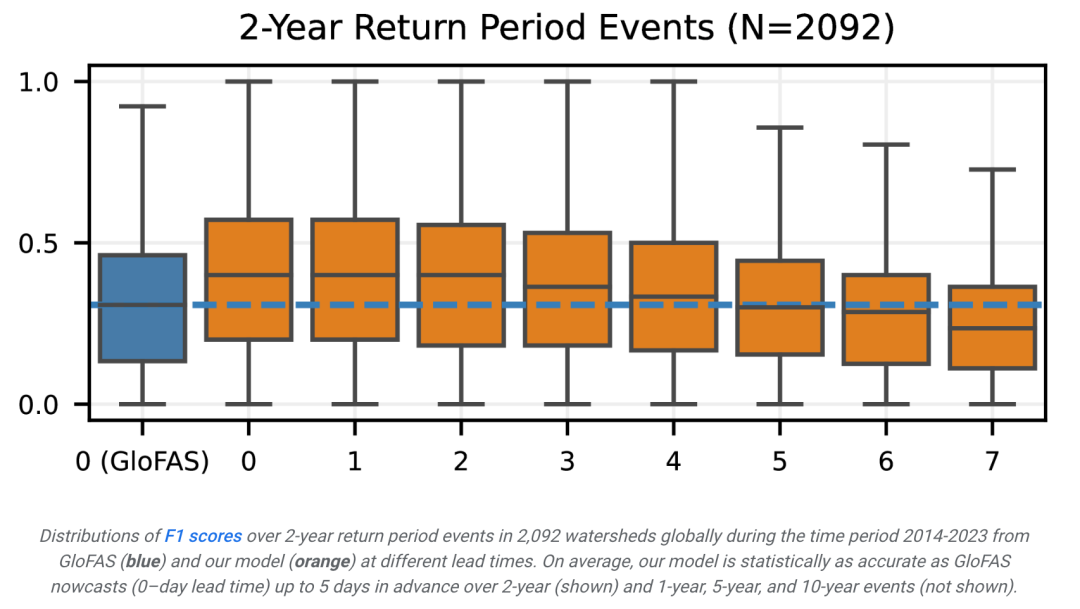
Selain itu, keputusan ramalan model adalah secara statistik lebih baik daripada model garis dasar melalui ujian peringkat bertanda Wilcoxon dua belah. Ini menunjukkan keberkesanan model dalam ramalan banjir.
Penunjuk d Cohen menunjukkan bahawa kesan peningkatan prestasi model adalah ketara, yang mengesahkan lagi kelebihan model berbanding kaedah tradisional.
Mengenai penunjuk hidrologi seperti kecekapan Nash–Sutcliffe dan kecekapan Kling-Gupta, model ini juga menunjukkan ketepatan ramalan yang baik dan kepekaan terhadap perubahan dalam proses hidrologi.
Kekurangan dan prospek
Walau bagaimanapun, kajian ini juga mempunyai beberapa batasan.
Sebagai contoh, sampel yang digunakan dalam eksperimen mungkin kecil, mengehadkan kebolehgunaan umum dan kuasa statistik hasil penyelidikan. Terdapat kekurangan kepelbagaian dalam set data yang digunakan dalam kajian, yang mungkin menjejaskan keupayaan generalisasi model. Kerumitan model yang diguna pakai mungkin meningkatkan kos pengiraan dan mengehadkan kebolehtafsiran dan kemudahannya.
Selain itu, penyelidikan memfokuskan kepada tugas atau bidang tertentu, yang mungkin mengehadkan penggunaan kaedah yang meluas kaedah ini tidak mempunyai penilaian kesan jangka panjang, mengakibatkan kekurangan pemahaman tentang prestasi model masa, dan kriteria penilaian mungkin tidak mencerminkan sepenuhnya prestasi model Dan tahap peningkatan ke atas teknologi sedia ada mungkin agak terhad.
Sehubungan itu, pasukan penyelidik menyatakan bahawa kerja masa depan diperlukan untuk meluaskan lagi liputan ramalan banjir ke lebih banyak lokasi di seluruh dunia, serta jenis lain kejadian dan bencana berkaitan banjir, termasuk banjir kilat dan bandar. banjir. Teknologi kecerdasan buatan juga akan terus memainkan peranan penting dalam membantu memajukan penyelidikan saintifik dan menggalakkan tindakan iklim.
Atas ialah kandungan terperinci Berita besar alam semula jadi: AI mengalahkan sistem amaran banjir global yang paling maju dan meramalkan banjir sungai 7 hari lebih awal, menyelamatkan beribu-ribu nyawa setiap tahun. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1653
1653
 14
1413
52
1305
25
1251
29
1224
24
14
1413
52
1305
25
1251
29
1224
24

 Apakah sepuluh aplikasi perdagangan mata wang maya teratas? Kedudukan pertukaran mata wang digital terkini
Apr 28, 2025 pm 08:03 PM
Apakah sepuluh aplikasi perdagangan mata wang maya teratas? Kedudukan pertukaran mata wang digital terkini
Apr 28, 2025 pm 08:03 PM
Sepuluh pertukaran mata wang digital teratas seperti Binance, OKX, Gate.io telah meningkatkan sistem mereka, urus niaga yang pelbagai dan langkah -langkah keselamatan yang ketat.
 Platform perdagangan mata wang teratas yang manakah di dunia adalah versi terbaru dari Platform Perdagangan Top Top Top
Apr 28, 2025 pm 08:09 PM
Platform perdagangan mata wang teratas yang manakah di dunia adalah versi terbaru dari Platform Perdagangan Top Top Top
Apr 28, 2025 pm 08:09 PM
Sepuluh platform perdagangan cryptocurrency teratas di dunia termasuk Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, Kucoin dan Poloniex, yang semuanya menyediakan pelbagai kaedah perdagangan dan langkah -langkah keselamatan yang kuat.
 Platform perdagangan mata wang digital yang boleh dipercayai. 10 mata wang mata wang digital teratas di dunia. 2025
Apr 28, 2025 pm 04:30 PM
Platform perdagangan mata wang digital yang boleh dipercayai. 10 mata wang mata wang digital teratas di dunia. 2025
Apr 28, 2025 pm 04:30 PM
Platform perdagangan mata wang digital yang boleh dipercayai: 1. Okx, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. Kucoin, 7.
 Decryption Gate.IO Strategy Upgrade: Bagaimana untuk mentakrifkan semula Pengurusan Aset Crypto di Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.IO Strategy Upgrade: Bagaimana untuk mentakrifkan semula Pengurusan Aset Crypto di Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0 mentakrifkan semula pengurusan aset crypto melalui seni bina yang inovatif dan kejayaan prestasi. 1) Ia menyelesaikan tiga titik kesakitan utama: silo aset, kerosakan pendapatan dan paradoks keselamatan dan kemudahan. 2) Melalui hab aset pintar, pengurusan risiko dinamik dan enjin peningkatan pulangan, kelajuan pemindahan rantaian, kadar hasil purata dan kelajuan tindak balas insiden keselamatan diperbaiki. 3) Menyediakan pengguna dengan visualisasi aset, automasi dasar dan integrasi tadbir urus, merealisasikan pembinaan semula nilai pengguna. 4) Melalui kerjasama ekologi dan inovasi pematuhan, keberkesanan keseluruhan platform telah dipertingkatkan. 5) Pada masa akan datang, kolam insurans kontrak pintar, ramalan integrasi pasaran dan peruntukan aset yang didorong AI akan dilancarkan untuk terus memimpin pembangunan industri.
 Platform perdagangan mata wang teratas yang manakah di dunia adalah antara sepuluh platform perdagangan mata wang teratas pada tahun 2025
Apr 28, 2025 pm 08:12 PM
Platform perdagangan mata wang teratas yang manakah di dunia adalah antara sepuluh platform perdagangan mata wang teratas pada tahun 2025
Apr 28, 2025 pm 08:12 PM
Sepuluh pertukaran cryptocurrency teratas di dunia pada tahun 2025 termasuk Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, Kucoin, Bittrex dan Poloniex, yang semuanya dikenali dengan jumlah dan keselamatan perdagangan mereka yang tinggi.
 Berapa bernilai bitcoin
Apr 28, 2025 pm 07:42 PM
Berapa bernilai bitcoin
Apr 28, 2025 pm 07:42 PM
Harga Bitcoin berkisar antara $ 20,000 hingga $ 30,000. 1. Harga Bitcoin telah berubah secara dramatik sejak tahun 2009, mencapai hampir $ 20,000 pada tahun 2017 dan hampir $ 60,000 pada tahun 2021. Harga dipengaruhi oleh faktor -faktor seperti permintaan pasaran, bekalan, dan persekitaran makroekonomi. 3. Dapatkan harga masa nyata melalui pertukaran, aplikasi mudah alih dan laman web. 4. Harga Bitcoin sangat tidak menentu, didorong oleh sentimen pasaran dan faktor luaran. 5. Ia mempunyai hubungan tertentu dengan pasaran kewangan tradisional dan dipengaruhi oleh pasaran saham global, kekuatan dolar AS, dan sebagainya. 6. Trend jangka panjang adalah yakin, tetapi risiko perlu dinilai dengan berhati-hati.
 Apakah platform perdagangan mata wang teratas? 10 pertukaran mata wang maya terkini
Apr 28, 2025 pm 08:06 PM
Apakah platform perdagangan mata wang teratas? 10 pertukaran mata wang maya terkini
Apr 28, 2025 pm 08:06 PM
Saat ini disenaraikan di antara sepuluh mata wang mata wang maya yang teratas: 1. Binance, 2 Okx, 3. Gate.io, 4. Perpustakaan duit syiling, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9.
 Bagaimana untuk mengukur prestasi benang di C?
Apr 28, 2025 pm 10:21 PM
Bagaimana untuk mengukur prestasi benang di C?
Apr 28, 2025 pm 10:21 PM
Mengukur prestasi thread di C boleh menggunakan alat masa, alat analisis prestasi, dan pemasa tersuai di perpustakaan standard. 1. Gunakan perpustakaan untuk mengukur masa pelaksanaan. 2. Gunakan GPROF untuk analisis prestasi. Langkah -langkah termasuk menambah pilihan -pg semasa penyusunan, menjalankan program untuk menghasilkan fail gmon.out, dan menghasilkan laporan prestasi. 3. Gunakan modul Callgrind Valgrind untuk melakukan analisis yang lebih terperinci. Langkah -langkah termasuk menjalankan program untuk menghasilkan fail callgrind.out dan melihat hasil menggunakan kcachegrind. 4. Pemasa tersuai secara fleksibel dapat mengukur masa pelaksanaan segmen kod tertentu. Kaedah ini membantu memahami sepenuhnya prestasi benang dan mengoptimumkan kod.
