

Tafsiran bersepadu AI data besar

1. Detik "iPhone" AI
Pada tahun lalu, model besar telah berkembang dengan sangat pesat. Orang ramai telah memasuki peringkat kecerdasan buatan yang selalu mereka impikan. Sebagai contoh, apabila berbual dengan model bahasa yang besar, anda akan merasakan bahawa anda bukan berhadapan dengan robot yang tumpul, tetapi seorang yang berdarah daging. Ia membuka lebih banyak ruang untuk imaginasi kita. Interaksi manusia-komputer asal diperlukan menggunakan papan kekunci dan tetikus untuk memberitahu mesin arahan kami melalui beberapa kaedah pemformatan. Kini, orang ramai boleh berinteraksi dengan komputer melalui bahasa, dan mesin boleh memahami maksud kami dan bertindak balas.
Untuk mengikuti trend, banyak syarikat teknologi mula memberi tumpuan kepada penyelidikan model besar. 2023 dianggap sebagai tahun pertama kecerdasan buatan, sama seperti pelancaran iPhone membuka era baharu Internet mudah alih. Kejayaan sebenar kali ini terletak pada penggunaan kuasa pengkomputeran berskala besar dan data besar-besaran.
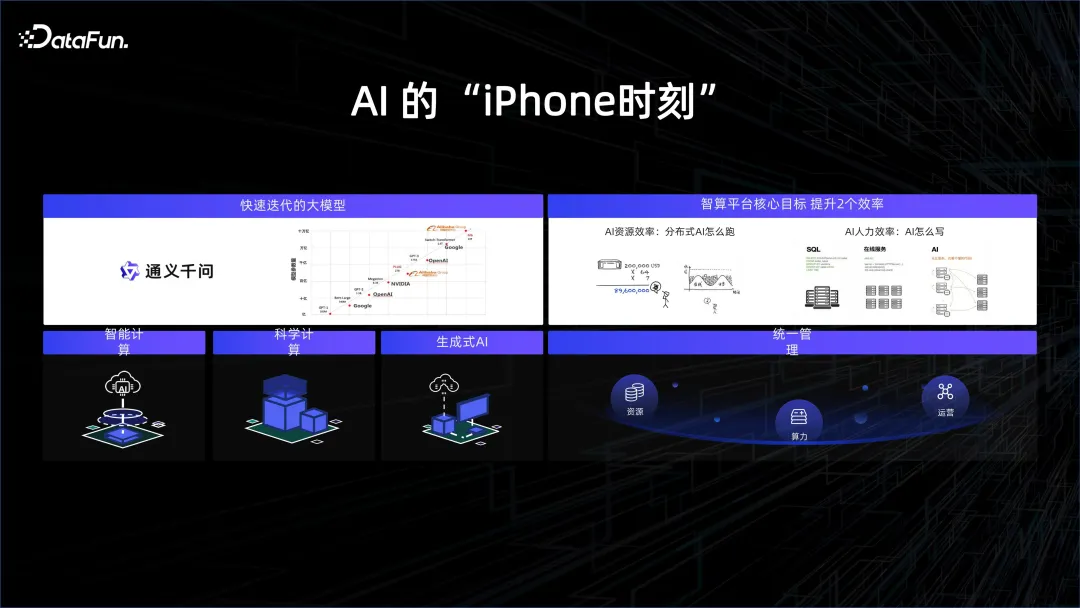
Dari perspektif struktur model, struktur Transformer sebenarnya telah lama dilancarkan. Malah, model GPT telah diterbitkan setahun lebih awal daripada model Bert Walau bagaimanapun, disebabkan oleh keterbatasan kuasa pengkomputeran pada masa itu, GPT adalah jauh kurang berkesan daripada Bert Oleh itu, Bert menjadi popular pertama dan digunakan untuk terjemahan, dengan keputusan yang sangat baik. Tetapi tumpuan tahun ini telah menjadi GPT Sebab di sebaliknya adalah kerana kuasa pengkomputeran yang sangat tinggi Kerana usaha pengeluar perkakasan dan beberapa kemajuan dalam pembungkusan dan zarah penyimpanan, kami mempunyai keupayaan untuk menggunakan kuasa pengkomputeran yang sangat tinggi bersama-sama, mereka mempromosikan pemahaman yang mendalam tentang lebih banyak data dan membawa hasil terobosan dalam AI. Berdasarkan sokongan kuat platform asas, pelajar algoritma boleh membangunkan dan mengulang model dengan lebih mudah dan cekap, menggalakkan evolusi model yang pantas. . Tetapi sebenarnya, sebelum latihan model, terdapat sejumlah besar data yang perlu dikumpul, dibersihkan dan diurus. Dalam proses ini, anda dapat melihat bahawa terdapat banyak langkah yang perlu disahkan, seperti sama ada terdapat data kotor dan sama ada taburan statistik data itu mewakili. Selepas model keluar, ia perlu diuji dan disahkan Ini juga pengesahan data Data digunakan untuk memberi maklum balas tentang keberkesanan model.
Pembelajaran mesin yang lebih baik ialah 80% data ditambah 20% model, dan tumpuan harus diberikan pada data.
Ini juga mencerminkan arah aliran evolusi pembangunan model Pembangunan model asal adalah berpusatkan model, tetapi kini ia telah menjadi berpusatkan data.
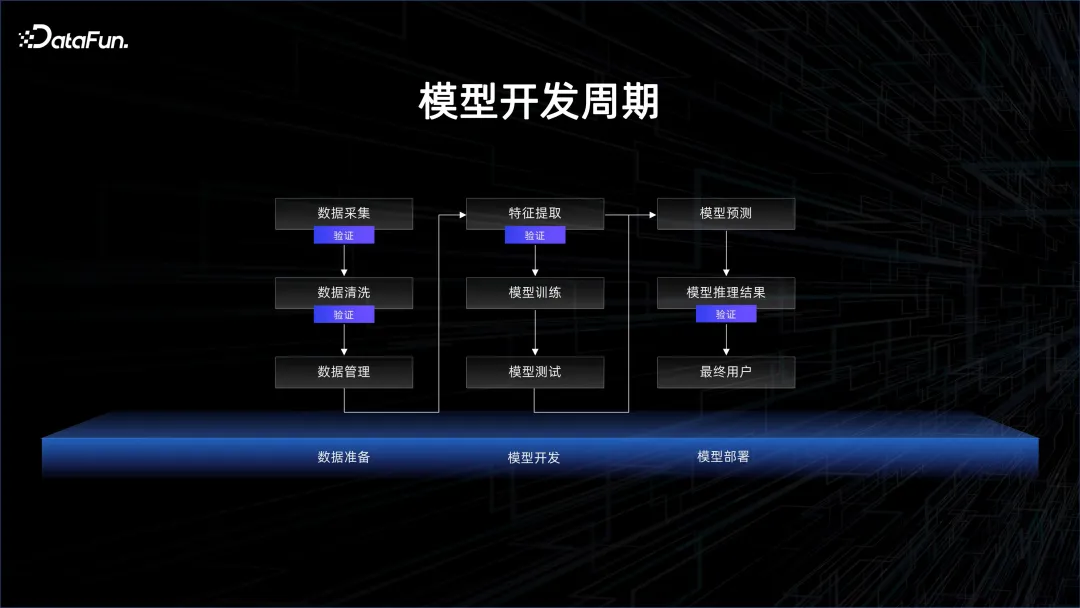 Pada zaman awal pembelajaran mendalam, pembelajaran terselia adalah fokus utama, dan perkara yang paling penting ialah mempunyai data yang dilabelkan. Data berlabel dibahagikan kepada dua kategori, satu adalah data latihan dan satu lagi adalah data pengesahan. Gunakan data latihan untuk melatih model, dan kemudian sahkan sama ada model boleh memberikan hasil yang baik pada data ujian. Kos pelabelan data adalah sangat tinggi kerana orang ramai dikehendaki melabelkannya. Jika anda ingin menambah baik kesan model, anda perlu menghabiskan banyak masa dan tenaga kerja pada struktur model, meningkatkan keupayaan generalisasi model melalui perubahan struktur, dan mengurangkan kelebihan model ini. paradigma pembangunan berpusat.
Pada zaman awal pembelajaran mendalam, pembelajaran terselia adalah fokus utama, dan perkara yang paling penting ialah mempunyai data yang dilabelkan. Data berlabel dibahagikan kepada dua kategori, satu adalah data latihan dan satu lagi adalah data pengesahan. Gunakan data latihan untuk melatih model, dan kemudian sahkan sama ada model boleh memberikan hasil yang baik pada data ujian. Kos pelabelan data adalah sangat tinggi kerana orang ramai dikehendaki melabelkannya. Jika anda ingin menambah baik kesan model, anda perlu menghabiskan banyak masa dan tenaga kerja pada struktur model, meningkatkan keupayaan generalisasi model melalui perubahan struktur, dan mengurangkan kelebihan model ini. paradigma pembangunan berpusat.
Dengan pengumpulan data dan kuasa pengkomputeran, pembelajaran tanpa seliaan secara beransur-ansur mula digunakan Melalui data besar-besaran, model itu boleh menemui perhubungan yang wujud dalam data pada masa ini. paradigma.

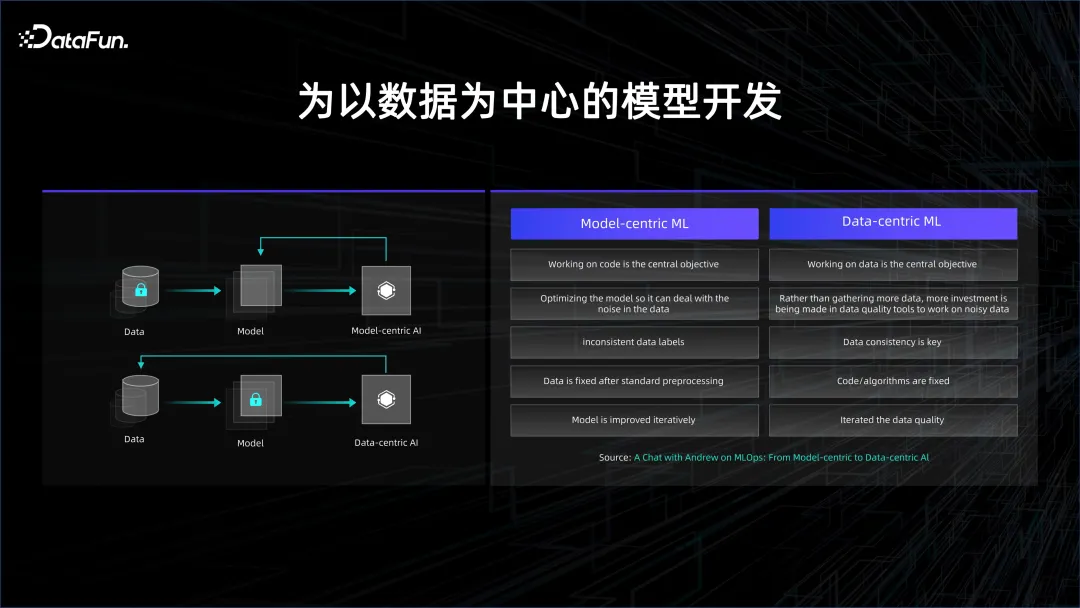
3. Integrasi AI Big Data
1. Oleh itu, kami membina platform dengan infrastruktur yang sangat baik, termasuk kluster GPU lebar jalur tinggi untuk menyediakan kuasa pengkomputeran AI berprestasi tinggi, dan kluster CPU untuk menyediakan storan dan keupayaan pengurusan data yang menjimatkan kos. Selain itu, kami telah membina data besar dan platform PaaS bersepadu AI, yang merangkumi platform data besar, platform AI, platform kuasa pengkomputeran tinggi, platform asli awan, dsb. Bahagian enjin termasuk pengkomputeran penstriman, pengkomputeran luar talian data besar MaxCompute dan PAI.
 Dalam lapisan perkhidmatan, terdapat platform aplikasi model besar Bailian dan komuniti model sumber terbuka ModelScope. Alibaba secara aktif mempromosikan perkongsian komuniti model, dengan harapan untuk menggunakan konsep Model sebagai perkhidmatan untuk memberi inspirasi kepada lebih ramai pengguna dengan AI perlu menggunakan keupayaan asas model ini untuk membina aplikasi AI dengan cepat.
Dalam lapisan perkhidmatan, terdapat platform aplikasi model besar Bailian dan komuniti model sumber terbuka ModelScope. Alibaba secara aktif mempromosikan perkongsian komuniti model, dengan harapan untuk menggunakan konsep Model sebagai perkhidmatan untuk memberi inspirasi kepada lebih ramai pengguna dengan AI perlu menggunakan keupayaan asas model ini untuk membina aplikasi AI dengan cepat.
2. Mengapa perlu menggabungkan data besar dan AI
Dua kes berikut akan digunakan untuk menjelaskan mengapa kaitan antara data besar dan AI diperlukan.
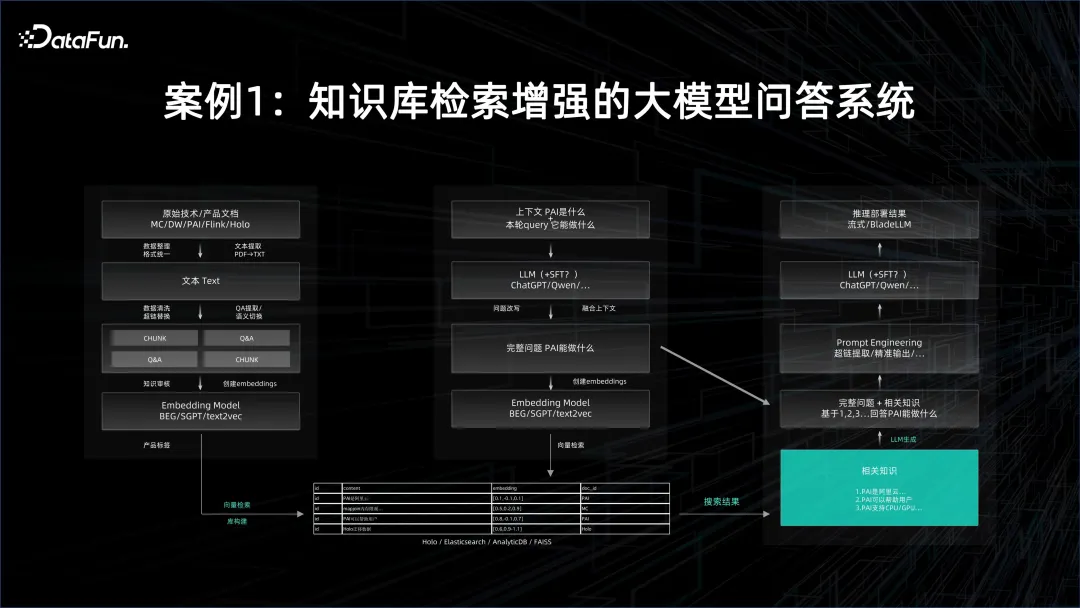
Kes 1: Sistem menjawab soalan model besar dengan pengambilan semula asas pengetahuan yang dipertingkatkan Hasilnya disimpan dalam pangkalan data vektor. Bilangan dokumen boleh menjadi sangat besar, jadi pembenaman memerlukan keupayaan pemprosesan kelompok. Perkhidmatan inferens model asas itu sendiri juga sangat memakan sumber Sudah tentu, ini juga bergantung pada seberapa besar model asas dan cara menyelaraskannya. Semua embeddings yang dihasilkan dituangkan ke dalam pangkalan data vektor Apabila membuat pertanyaan, pertanyaan juga mesti divektorkan, dan kemudian melalui pengambilan vektor, pengetahuan yang mungkin berkaitan dengan soalan dan jawapan diekstrak daripada pangkalan data vektor. Ini memerlukan prestasi perkhidmatan inferens yang sangat baik.
Selepas mengekstrak vektor, anda perlu menggunakan dokumen yang diwakili oleh vektor sebagai konteks, kemudian mengekang model besar ini, dan membuat soalan dan jawapan berdasarkan ini Kesan jawapan akan jauh lebih baik daripada keputusan yang diperoleh dengan kaedah carian anda sendiri, dan jawapannya adalah dalam bahasa semula jadi manusia.
Dalam proses di atas, kedua-dua platform data besar teragih luar talian diperlukan untuk menjana pembenaman dengan cepat, dan platform AI untuk latihan dan perkhidmatan model besar diperlukan untuk menyambung keseluruhan proses untuk membentuk sistem soal jawab model besar. .
Contoh lain ialah pengesyoran yang diperibadikan Model ini selalunya memerlukan ketepatan masa yang tinggi kerana minat dan personaliti semua orang akan berubah, dan perubahan ini mesti diambil untuk digunakan. penstriman sistem pengkomputeran untuk menganalisis data yang diperolehi dalam APP, dan kemudian terus membiarkan model belajar dalam talian melalui ciri yang diekstrak Setiap kali data baharu masuk, model akan dikemas kini, dan kemudian melalui model baharu untuk melayani pelanggan. Oleh itu, dalam senario ini, keupayaan pengkomputeran penstriman diperlukan, serta keupayaan penyajian model dan latihan.
3. Bagaimana untuk menggabungkan data besar dengan AI
Melalui kes di atas, kita dapat melihat bahawa gabungan AI dan data besar telah menjadi trend pembangunan yang tidak dapat dielakkan. Berdasarkan konsep ini, kita perlu mempunyai ruang kerja yang boleh mengurus platform data besar dan platform AI bersama-sama Inilah sebabnya ruang kerja AI dilahirkan.
Dalam ruang kerja AI ini, ia menyokong kelompok Flink, kelompok pengkomputeran luar talian MaxCompute, platform AI, platform pengkomputeran perkhidmatan kontena, dsb.
Menyatukan data besar dan pengurusan AI hanyalah langkah pertama. Apa yang lebih penting ialah menghubungkannya dalam aliran kerja. Aliran kerja boleh diwujudkan dalam pelbagai cara, seperti SDK, grafik, GUI, penulisan SPEC, dsb. Nod dalam aliran kerja boleh menjadi nod pemprosesan data besar atau nod pemprosesan AI, supaya proses yang kompleks boleh disambungkan dengan baik.
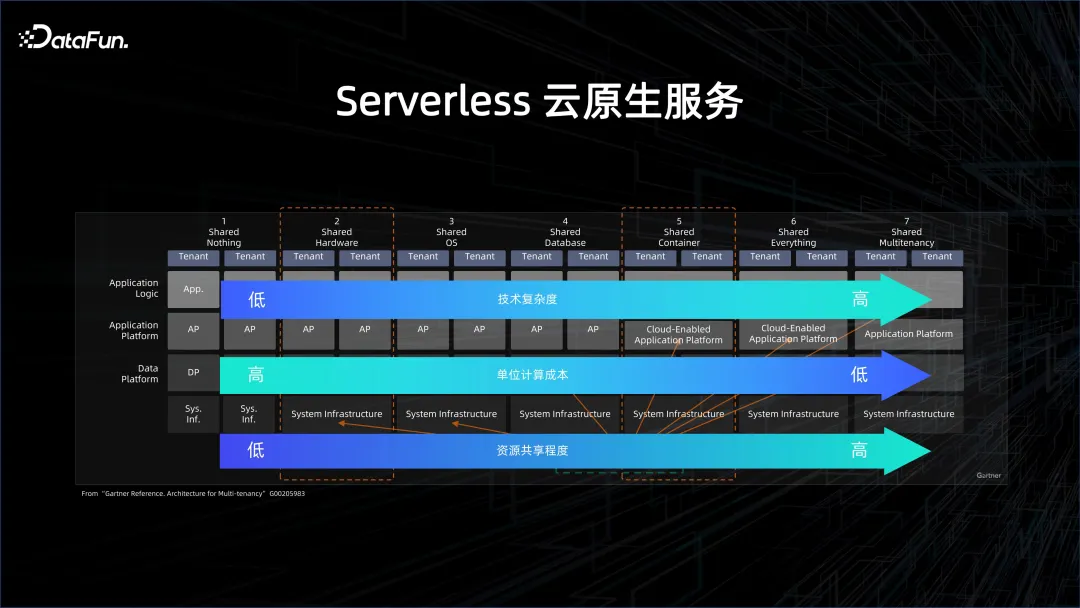
Untuk meningkatkan lagi kecekapan dan mengurangkan kos, perkhidmatan asal awan Severless diperlukan. Apa itu Severless diterangkan secara terperinci dalam imej di atas. Cloud native mempunyai banyak tahap yang berbeza, daripada berkongsi apa-apa (pendekatan bukan awan) hingga berkongsi segala-galanya (pendekatan sangat awan). Semakin tinggi tahap, semakin tinggi tahap perkongsian sumber, semakin rendah kos pengkomputeran unit, tetapi semakin besar tekanan pada sistem.

Bidang data besar dan pangkalan data perlahan-lahan mula bergerak ke arah tanpa pelayan sejak dua tahun lalu, juga berdasarkan pertimbangan kos. Pada asalnya, malah pelayan yang digunakan pada awan, seperti pangkalan data di awan, wujud dalam bentuk instantiasi. Di sebalik kejadian ini terdapat bayang-bayang sumber, seperti bilangan CPU dan Teras yang ada pada tika ini. Perlahan-lahan dan beransur-ansur berubah menjadi Tanpa Pelayan, tahap pertama ialah pengkomputeran penyewa tunggal, yang merujuk kepada menyediakan kluster pada awan dan kemudian menggunakan data besar atau platform pangkalan data di dalamnya. Tetapi kluster ini adalah penyewa tunggal, iaitu, ia berkongsi mesin fizikal dengan orang lain Mesin fizikal dimayakan menjadi mesin maya, yang digunakan untuk membina platform data besar Ini dipanggil pengkomputeran penyewa tunggal. simpanan penyewa, dan pengurusan dan kawalan penyewa tunggal. Apa yang pengguna perolehi ialah mesin ECS anjal pada awan, tetapi pengurusan data besar dan penyelesaian operasi dan penyelenggaraan perlu dilakukan sendiri. EMR adalah penyelesaian klasik dalam hal ini.
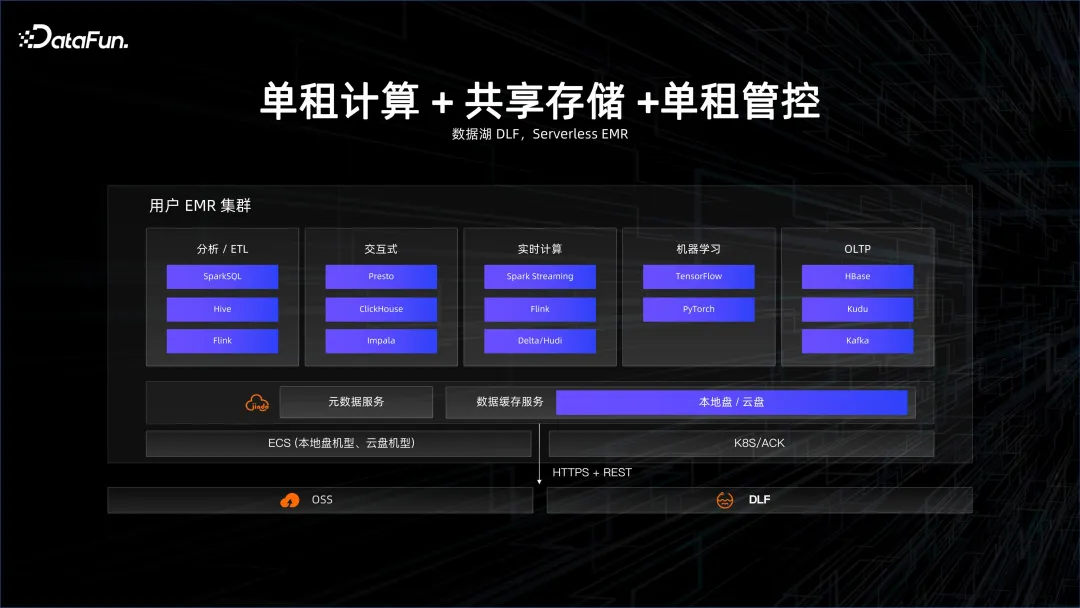
perlahan-lahan akan beralih dari storan penyewa tunggal ke storan kongsi, iaitu penyelesaian tasik data. Data berada dalam sistem data besar yang lebih dikongsi Pengiraan adalah untuk menarik kluster secara dinamik Selepas pengiraan selesai, kluster akan mati, tetapi data tidak akan mati kerana data berada di hujung storan alat kawalan jauh yang boleh dipercayai. . Ini adalah storan bersama. Yang biasa ialah DLF tasik data dan penyelesaian EMR tanpa pelayan. . Pemeteran pengebilan.

Ini boleh mendatangkan banyak manfaat. Contohnya, terdapat banyak nod dalam pengiraan data besar dan tidak memerlukan kod pengguna, kerana nod ini sebenarnya adalah beberapa operator binaan, seperti gabungan dan agregator ini tidak memerlukan Kotak Pasir yang agak berat pengendali yang telah diuji dengan teliti dan tidak mengandungi sebarang kod hasad atau kod UDF sewenang-wenangnya, mereka boleh menghapuskan overhed virtualisasi.
 Faedah UDF ialah fleksibiliti, yang membolehkan kami memproses data yang kaya dan mempunyai kebolehskalaan yang baik apabila jumlah data adalah besar. Tetapi salah satu cabaran yang akan dibawa oleh UDF ialah keperluan untuk keselamatan dan pengasingan.
Faedah UDF ialah fleksibiliti, yang membolehkan kami memproses data yang kaya dan mempunyai kebolehskalaan yang baik apabila jumlah data adalah besar. Tetapi salah satu cabaran yang akan dibawa oleh UDF ialah keperluan untuk keselamatan dan pengasingan.
Kedua-dua BigQuery dan MaxComputer Google adalah berdasarkan perkongsian segala-galanya syarikat mampu menggunakan data ini, mempromosikan penggunaan data dalam latihan model.
Semestinya kerana berkongsi segala-galanya, kita bukan sahaja boleh mengurus data besar dan AI dengan cara bersatu melalui ruang kerja, menyambungkannya melalui aliran PAI, tetapi juga melaksanakan penjadualan bersatu melalui berkongsi segala-galanya. Dengan cara ini, kos penyelidikan dan pembangunan data besar AI + perusahaan akan dikurangkan lagi.
Pada ketika ini, terdapat banyak kerja yang perlu dilakukan. Penjadualan K8S itu sendiri berorientasikan perkhidmatan mikro, yang akan menghadapi cabaran besar untuk data besar Oleh kerana butiran penjadualan perkhidmatan data besar adalah sangat kecil, banyak tugas hanya akan bertahan selama beberapa saat hingga berpuluh-puluh saat pada skala penjadualan dan kesan ke atas penjadualan Tekanan keseluruhan akan meningkat dengan beberapa susunan magnitud. Kami terutamanya perlu menyelesaikan cara untuk mengurangkan keupayaan penjadualan ini pada K8S Projek sumber terbuka Koordinator yang kami lancarkan adalah untuk meningkatkan keupayaan penjadualan dan menyepadukan data besar dan AI dalam ekosistem K8S.

Satu lagi tugas penting ialah pengasingan selamat berbilang penyewa. Cara melaksanakan berbilang penyewaan dalam lapisan perkhidmatan dan lapisan kawalan K8S, dan cara melaksanakan berbilang penyewaan di atas rangkaian, supaya berbilang pengguna boleh disampaikan pada satu K8S dan data serta sumber setiap pengguna boleh digunakan dengan berkesan terpencil.
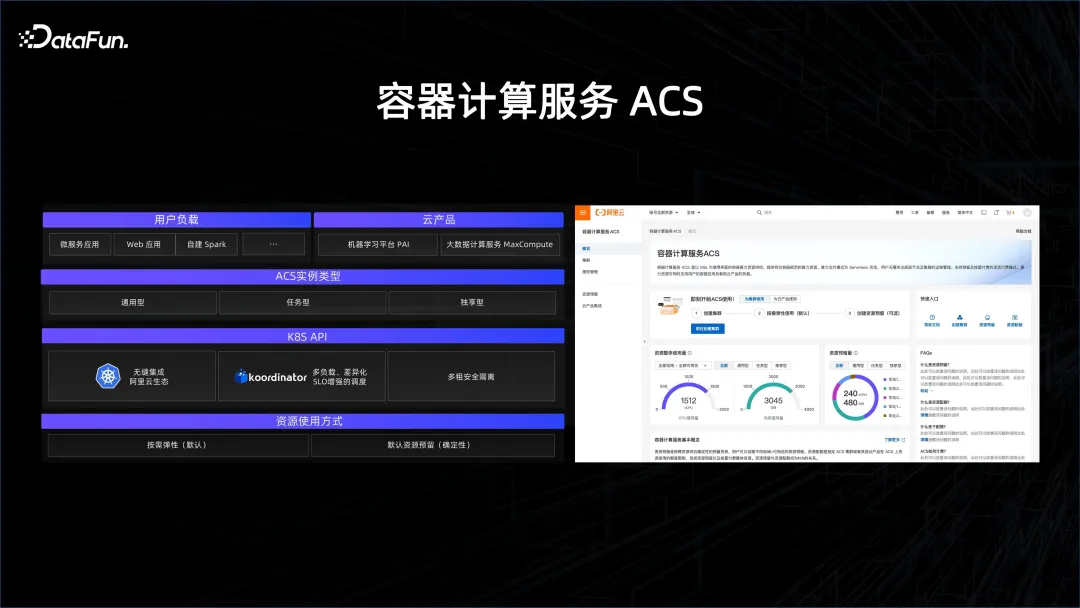
Alibaba telah melancarkan perkhidmatan kontena yang dipanggil ACS, yang menggunakan dua teknologi yang diperkenalkan sebelum ini untuk mendedahkan semua sumber melalui kontena, membolehkan pengguna menggunakan platform data besar dan platform AI dengan lancar. Ia adalah kaedah berbilang penyewa dan boleh menyokong keperluan data besar. Keperluan penjadualan data besar adalah beberapa urutan magnitud yang lebih tinggi daripada perkhidmatan mikro dan AI, dan mesti dilakukan dengan baik. Atas dasar ini, produk ACS boleh membantu pelanggan mengurus sumber mereka dengan baik.
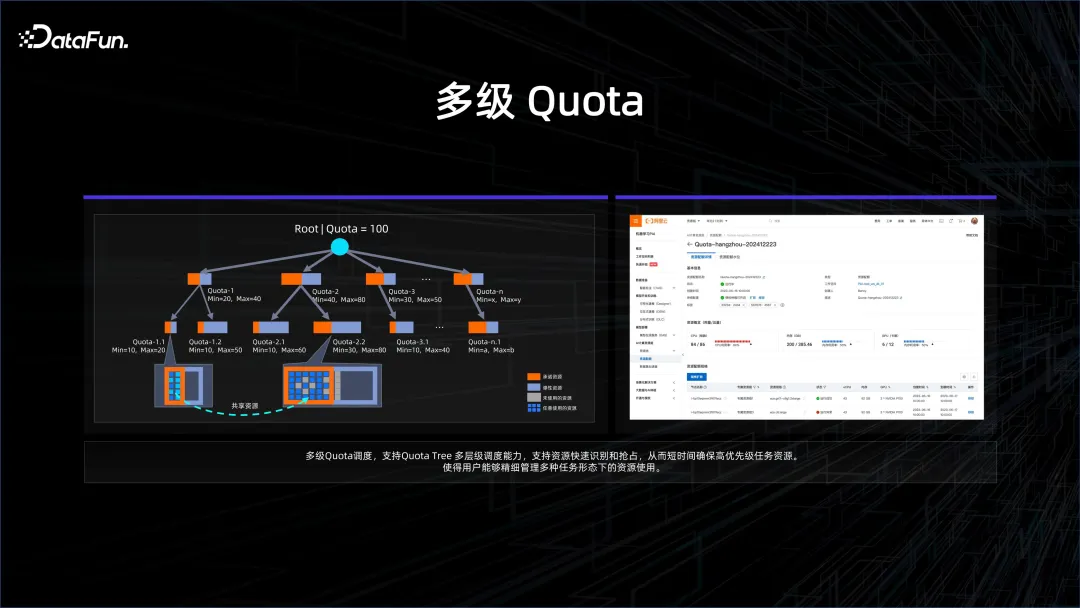
Syarikat menghadapi banyak permintaan dan perlu mengurus sumber dengan lebih berhati-hati. Sebagai contoh, perusahaan dibahagikan kepada pelbagai jabatan dan sub-pasukan Apabila membina model yang besar, sumber akan dibahagikan kepada banyak arah Setiap pasukan akan melakukan inovasi yang berbeza untuk melihat dalam senario apa model asas ini boleh digunakan dengan baik. Tetapi pada masa tertentu, saya berharap untuk menumpukan pada melakukan perkara-perkara besar dan mengumpulkan semua kuasa dan sumber pengkomputeran untuk melatih lelaran seterusnya model asas. Untuk menyelesaikan masalah ini, kami telah memperkenalkan pengurusan kuota berbilang peringkat, yang bermaksud bahawa apabila tugasan dengan keperluan yang lebih tinggi tiba, mungkin terdapat tahap yang lebih tinggi untuk menggabungkan dan menyatukan semua sub-kuota di bawah.
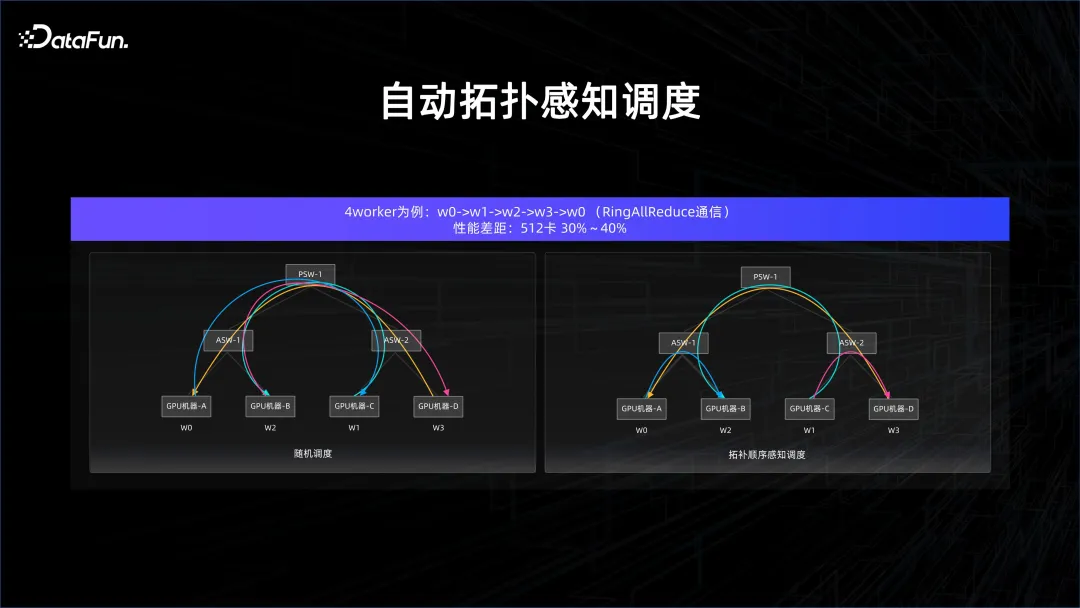
Sebenarnya, terdapat banyak kekhususan dalam senario AI Dalam banyak kes, pengiraan segerak diperlukan, dan pengiraan segerak sangat sensitif terhadap kelewatan, dan ketumpatan pengiraan AI adalah tinggi, yang memerlukan rangkaian. sangat tinggi. Jika anda ingin memastikan kuasa pengkomputeran, anda perlu membekalkan data dan bertukar maklumat kecerunan, dan apabila model selari, lebih banyak perkara akan ditukar. Dalam kes ini, untuk memastikan tiada kekurangan dalam komunikasi, penjadualan yang sedar topologi diperlukan.
Sebagai contoh, dalam pautan All Reduce latihan model, jika penjadualan rawak dilakukan, akan terdapat banyak sambungan suis port silang, tetapi jika pesanan dikawal dengan teliti, maka sambungan suis silang akan menjadi sangat bersih , jadi kelewatan akan menjadi Ia boleh dijamin dengan baik kerana tiada konflik akan berlaku dalam suis lapisan atas.
Selepas pengoptimuman ini, prestasi boleh dipertingkatkan dengan ketara. Cara memindahkan jadual sedar topologi ini kepada pengurus seluruh platform juga merupakan isu yang perlu dipertimbangkan apabila AI meningkatkan pengurusan platform data.
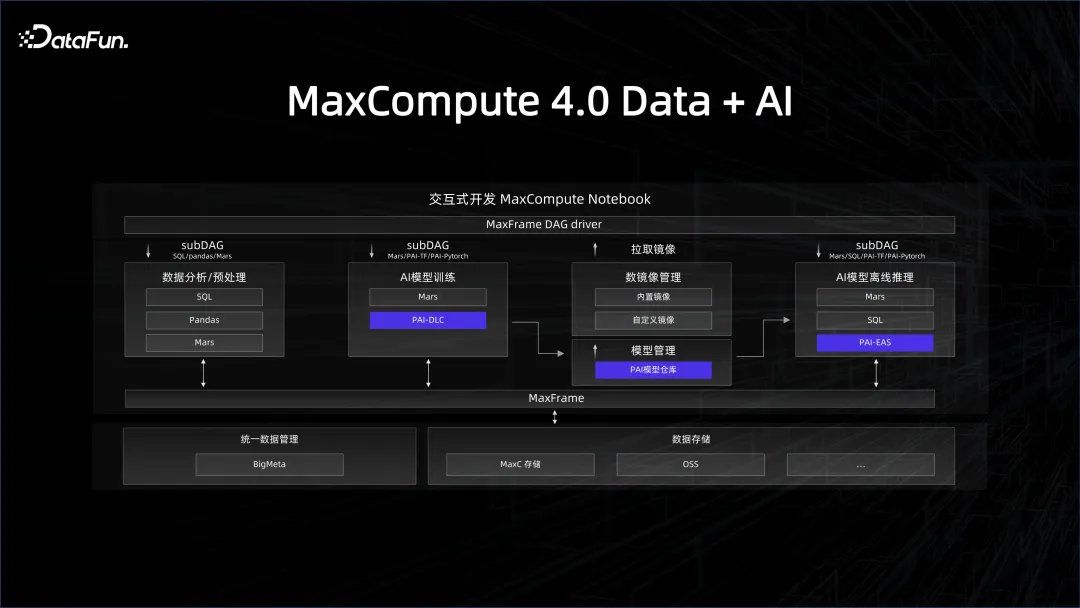
Apa yang kami perkenalkan sebelum ini ialah pengurusan sumber dan platform juga penting. Untuk mengaitkan sistem data dengan sistem AI, gudang data perlu menyediakan pautan data mesra AI. Sebagai contoh, dalam proses pembangunan AI, ekosistem Python digunakan Bagaimana bahagian data boleh menggunakan platform ini melalui SDK Python. Pustaka paling popular dalam Python ialah struktur data bingkai data yang serupa dengan panda Kami boleh membungkus bahagian pelanggan enjin data besar ke dalam antara muka panda, supaya semua pekerja pembangunan AI yang biasa dengan Python boleh menggunakannya dengan baik . Ini juga merupakan falsafah di sebalik rangka kerja MaxFrame yang kami lancarkan pada MaxCompute tahun ini.
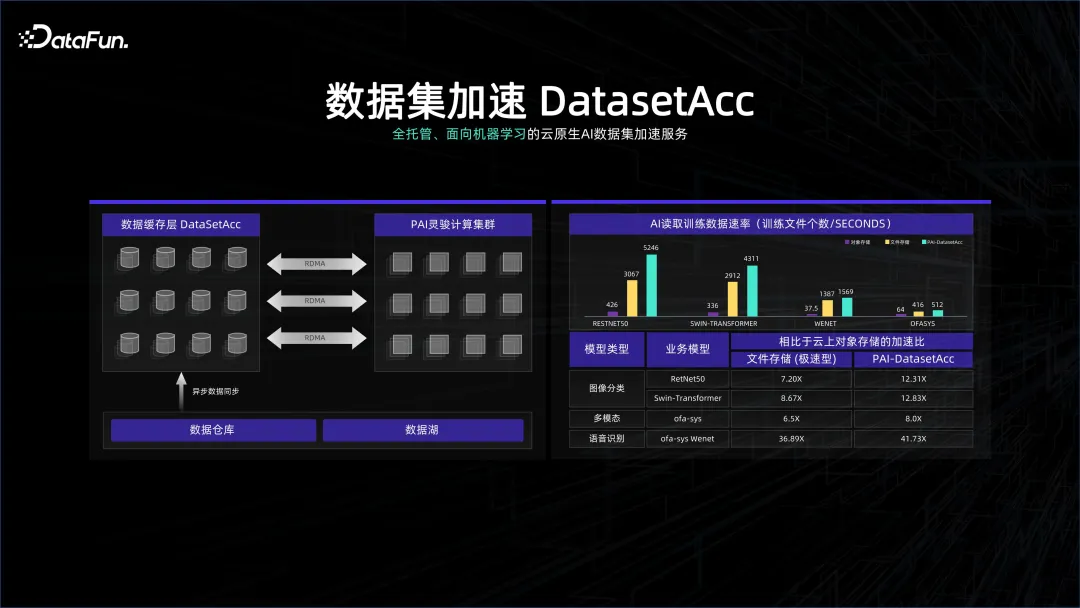
Dalam kebanyakan kes, sistem pemprosesan data sangat sensitif terhadap kos Kadangkala sistem storan berketumpatan tinggi digunakan untuk menyimpan sistem gudang data, namun, untuk tidak membazirkan sistem ini, banyak GPU digunakan padanya sistem storan Kelompok ini sangat menuntut pada rangkaian dan GPU, dan kedua-dua sistem mungkin akan dipisahkan daripada storan dan pengiraan. Sistem data kami mungkin berat sebelah terhadap tadbir urus dan pengurusan, manakala sistem pengkomputeran mungkin berat sebelah terhadap pengiraan Ia mungkin kaedah sambungan jauh Walaupun kedua-duanya berada di bawah pengurusan K8S, untuk mengelakkan menunggu data semasa pengiraan, kami telah mencipta data Tetapkan pecutan DataSetAcc sebenarnya ialah cache data yang bersambung dengan lancar ke data nod storan jauh, membantu jurutera algoritma menarik data ke memori tempatan atau SSD di belakang tabir untuk pengiraan.
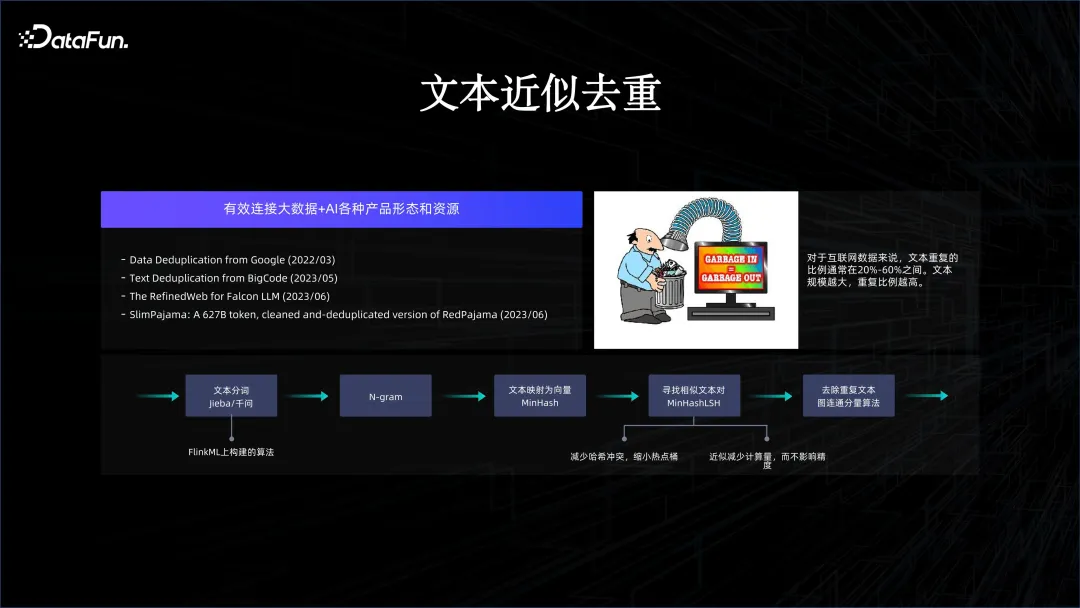
Melalui kaedah di atas, AI dan platform data besar boleh digabungkan secara organik, supaya kami boleh melakukan beberapa inovasi. Sebagai contoh, apabila menyokong latihan model untuk banyak siri umum, terdapat banyak data yang perlu dibersihkan, kerana terdapat banyak pertindihan dalam data Internet, jadi cara menyahduplikasi data melalui sistem data besar adalah kritikal. Ia adalah tepat kerana kami telah menggabungkan kedua-dua sistem secara organik bahawa ia adalah mudah untuk membersihkan data pada platform data besar, dan hasilnya boleh dimasukkan ke dalam latihan model dengan segera.

Artikel sebelumnya terutamanya memperkenalkan cara data besar menyediakan sokongan untuk latihan model AI. Sebaliknya, teknologi AI juga boleh digunakan untuk membantu cerapan data dan bergerak ke arah model pemprosesan data BI + AI.
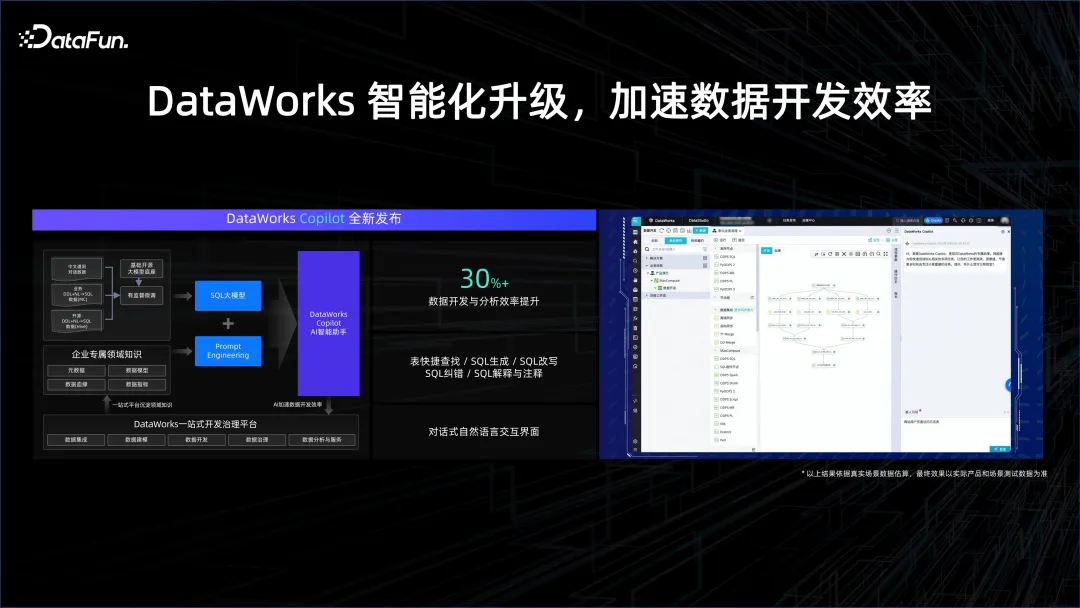
Dalam proses pemprosesan data, ia boleh membantu penganalisis data membina analisis dengan lebih mudah Pada asalnya, mereka mungkin perlu menulis SQL dan belajar cara menggunakan alatan untuk berinteraksi dengan sistem data. Walau bagaimanapun, era AI telah mengubah cara interaksi manusia-komputer berlaku, dan boleh berinteraksi dengan sistem data melalui bahasa semula jadi. Sebagai contoh, pembantu pengaturcaraan Copilot boleh membantu dalam menjana SQL dan membantu menyelesaikan pelbagai langkah dalam proses pembangunan data, sekali gus meningkatkan kecekapan pembangunan.

Selain itu, cerapan data juga boleh dilakukan melalui AI. Contohnya, sekeping data, berapa banyak kunci unik yang ada, dan kaedah yang sesuai untuk visualisasi semuanya boleh diperoleh dengan menggunakan AI. AI boleh memerhati dan memahami data dari semua sudut, merealisasikan penerokaan data automatik, pertanyaan data pintar, penjanaan carta, dan penjanaan satu klik laporan analisis, dsb. Ini ialah perkhidmatan analisis pintar.
IV Ringkasan
Didorong oleh data besar dan AI, terdapat beberapa tahun perkembangan teknologi yang sangat menggembirakan. Untuk kekal tidak dapat dikalahkan dalam aliran ini, adalah perlu untuk menghubungkan data besar dan AI Hanya apabila kedua-duanya saling melengkapi, kita boleh mencapai pecutan lelaran AI dan pemahaman data yang lebih baik.
Atas ialah kandungan terperinci Tafsiran bersepadu AI data besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1383
1383
 52
52

 iPhone 16 Pro dan iPhone 16 Pro Max rasmi dengan kamera baharu, A18 Pro SoC dan skrin yang lebih besar
Sep 10, 2024 am 06:50 AM
iPhone 16 Pro dan iPhone 16 Pro Max rasmi dengan kamera baharu, A18 Pro SoC dan skrin yang lebih besar
Sep 10, 2024 am 06:50 AM
Apple akhirnya telah menanggalkan penutup model iPhone mewah baharunya. iPhone 16 Pro dan iPhone 16 Pro Max kini hadir dengan skrin yang lebih besar berbanding dengan model generasi terakhir mereka (6.3-in pada Pro, 6.9-in pada Pro Max). Mereka mendapat Apple A1 yang dipertingkatkan
 Kunci Pengaktifan bahagian iPhone dikesan dalam iOS 18 RC — mungkin merupakan pukulan terbaharu Apple ke kanan untuk dibaiki dijual di bawah nama perlindungan pengguna
Sep 14, 2024 am 06:29 AM
Kunci Pengaktifan bahagian iPhone dikesan dalam iOS 18 RC — mungkin merupakan pukulan terbaharu Apple ke kanan untuk dibaiki dijual di bawah nama perlindungan pengguna
Sep 14, 2024 am 06:29 AM
Awal tahun ini, Apple mengumumkan bahawa ia akan mengembangkan ciri Kunci Pengaktifannya kepada komponen iPhone. Ini memautkan komponen iPhone individu secara berkesan, seperti bateri, paparan, pemasangan FaceID dan perkakasan kamera ke akaun iCloud,
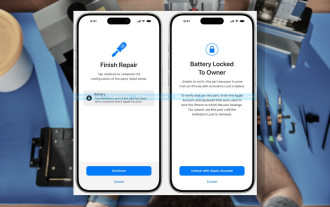 Kunci Pengaktifan bahagian iPhone mungkin merupakan pukulan terbaharu Apple ke kanan untuk dibaiki dijual dengan berselindung di bawah perlindungan pengguna
Sep 13, 2024 pm 06:17 PM
Kunci Pengaktifan bahagian iPhone mungkin merupakan pukulan terbaharu Apple ke kanan untuk dibaiki dijual dengan berselindung di bawah perlindungan pengguna
Sep 13, 2024 pm 06:17 PM
Awal tahun ini, Apple mengumumkan bahawa ia akan mengembangkan ciri Kunci Pengaktifannya kepada komponen iPhone. Ini memautkan komponen iPhone individu secara berkesan, seperti bateri, paparan, pemasangan FaceID dan perkakasan kamera ke akaun iCloud,
 Platform Perdagangan Platform Perdagangan Rasmi dan Alamat Pemasangan Rasmi
Feb 13, 2025 pm 07:33 PM
Platform Perdagangan Platform Perdagangan Rasmi dan Alamat Pemasangan Rasmi
Feb 13, 2025 pm 07:33 PM
Artikel ini memperincikan langkah -langkah untuk mendaftar dan memuat turun aplikasi terkini di laman web rasmi Gate.io. Pertama, proses pendaftaran diperkenalkan, termasuk mengisi maklumat pendaftaran, mengesahkan nombor e -mel/telefon bimbit, dan menyelesaikan pendaftaran. Kedua, ia menerangkan cara memuat turun aplikasi Gate.io pada peranti iOS dan peranti Android. Akhirnya, petua keselamatan ditekankan, seperti mengesahkan kesahihan laman web rasmi, membolehkan pengesahan dua langkah, dan berjaga-jaga terhadap risiko phishing untuk memastikan keselamatan akaun pengguna dan aset.
 Berbilang pengguna iPhone 16 Pro melaporkan isu pembekuan skrin sentuh, mungkin dikaitkan dengan sensitiviti penolakan tapak tangan
Sep 23, 2024 pm 06:18 PM
Berbilang pengguna iPhone 16 Pro melaporkan isu pembekuan skrin sentuh, mungkin dikaitkan dengan sensitiviti penolakan tapak tangan
Sep 23, 2024 pm 06:18 PM
Jika anda sudah mendapatkan peranti daripada barisan iPhone 16 Apple — lebih khusus lagi, 16 Pro/Pro Max — kemungkinan besar anda baru-baru ini menghadapi beberapa jenis isu dengan skrin sentuh. Perkara utama ialah anda tidak bersendirian—laporan
 Anbi App Rasmi Muat turun v2.96.2 Pemasangan versi terkini ANBI Versi Android Rasmi
Mar 04, 2025 pm 01:06 PM
Anbi App Rasmi Muat turun v2.96.2 Pemasangan versi terkini ANBI Versi Android Rasmi
Mar 04, 2025 pm 01:06 PM
Langkah Pemasangan Rasmi Binance: Android perlu melawat laman web rasmi untuk mencari pautan muat turun, pilih versi Android untuk memuat turun dan memasang; Semua harus memberi perhatian kepada perjanjian melalui saluran rasmi.
 Bagaimana untuk menyelesaikan masalah 'Kunci Array Undefined' Sign ''ralat ketika memanggil Alipay Easysdk menggunakan PHP?
Mar 31, 2025 pm 11:51 PM
Bagaimana untuk menyelesaikan masalah 'Kunci Array Undefined' Sign ''ralat ketika memanggil Alipay Easysdk menggunakan PHP?
Mar 31, 2025 pm 11:51 PM
Penerangan Masalah Apabila memanggil Alipay Easysdk menggunakan PHP, selepas mengisi parameter mengikut kod rasmi, mesej ralat dilaporkan semasa operasi: "Undefined ...
 Beats menambah sarung telefon pada barisannya: memperkenalkan sarung MagSafe untuk siri iPhone 16
Sep 11, 2024 pm 03:33 PM
Beats menambah sarung telefon pada barisannya: memperkenalkan sarung MagSafe untuk siri iPhone 16
Sep 11, 2024 pm 03:33 PM
Beats terkenal dengan pelancaran produk audio seperti pembesar suara Bluetooth dan fon kepala, tetapi dalam apa yang paling boleh digambarkan sebagai kejutan, syarikat milik Apple itu telah bercabang untuk membuat sarung telefon, bermula dengan siri iPhone 16. The Beats iPhone
