
 Peranti teknologi
AI
Adakah versi 3D Sora akan datang? UMass, MIT dan lain-lain mencadangkan model dunia 3D, dan robot pintar yang terkandung mencapai pencapaian baharu
Peranti teknologi
AI
Adakah versi 3D Sora akan datang? UMass, MIT dan lain-lain mencadangkan model dunia 3D, dan robot pintar yang terkandung mencapai pencapaian baharu
Adakah versi 3D Sora akan datang? UMass, MIT dan lain-lain mencadangkan model dunia 3D, dan robot pintar yang terkandung mencapai pencapaian baharu

Dalam penyelidikan baru-baru ini, input model vision-language-action (VLA, vision-language-action) pada asasnya ialah data 2D, tanpa menyepadukan dunia fizikal 3D yang lebih umum.
Selain itu, model sedia ada melakukan ramalan tindakan dengan mempelajari "pemetaan langsung tindakan yang dirasakan", mengabaikan dinamik dunia dan hubungan antara tindakan dan dinamik.
Sebaliknya, apabila manusia berfikir, mereka memperkenalkan model dunia, yang boleh menggambarkan imaginasi mereka tentang senario masa depan dan merancang tindakan seterusnya.
Untuk tujuan ini, penyelidik dari University of Massachusetts Amherst, MIT dan institusi lain telah mencadangkan model 3D-VLA Dengan memperkenalkan kelas model asas yang terkandung, ia boleh berdasarkan model dunia yang dijana dengan lancar. penaakulan dan tindakan. 
Laman utama projek: https://vis-www.cs.umass.edu/3dvla/
Alamat kertas: https://ab.
Secara khusus, 3D-VLA dibina pada model bahasa besar (LLM) berasaskan 3D dan memperkenalkan satu set token interaksi untuk mengambil bahagian dalam persekitaran yang terkandung.
Pasukan Qianchuang melatih satu siri model resapan yang terkandung, menyuntik keupayaan generatif ke dalam model dan menyelaraskannya ke dalam LLM untuk meramalkan imej sasaran dan awan titik.
Untuk melatih model 3D-VLA, kami mengekstrak sejumlah besar maklumat berkaitan 3D daripada set data robot sedia ada dan membina set data arahan terkandung 3D yang besar.
Hasil penyelidikan menunjukkan bahawa 3D-VLA berprestasi baik dalam mengendalikan penaakulan, penjanaan pelbagai mod dan tugas perancangan dalam persekitaran yang terkandung, yang menyerlahkan potensi nilai aplikasinya dalam senario kehidupan sebenar.
Set Data Penalaan Arahan Terwujud 3DDisebabkan set data berbilion-bilion di Internet, VLM telah menunjukkan prestasi cemerlang dalam pelbagai tugas, dan berjuta-juta data tindakan video Set itu juga meletakkan asas bagi VLM konkrit untuk kawalan robot .
Walau bagaimanapun, kebanyakan set data semasa tidak dapat memberikan kedalaman yang mencukupi atau anotasi 3D dan kawalan yang tepat untuk pengendalian robot. Ini memerlukan kandungan penaakulan spatial 3D dan interaksi untuk dimasukkan ke dalam set data. Kekurangan maklumat 3D menyukarkan robot untuk memahami dan melaksanakan arahan yang memerlukan penaakulan spatial 3D, seperti "Letakkan cawan paling jauh di dalam laci tengah."

Untuk merapatkan jurang ini, penyelidik membina set data penalaan arahan 3D berskala besar, yang menyediakan "maklumat berkaitan 3D" dan "arahan teks yang sepadan" yang mencukupi untuk melatih model .
Para penyelidik mereka bentuk saluran paip untuk mengekstrak pasangan tindakan bahasa 3D daripada set data terkandung sedia ada, mendapatkan anotasi awan titik, peta kedalaman, kotak sempadan 3D, tindakan 7D robot dan penerangan teks.
Model asas 3D-VLA3D-VLA ialah model dunia yang digunakan untuk penaakulan tiga dimensi, penjanaan sasaran dan membuat keputusan dalam persekitaran yang terkandung.
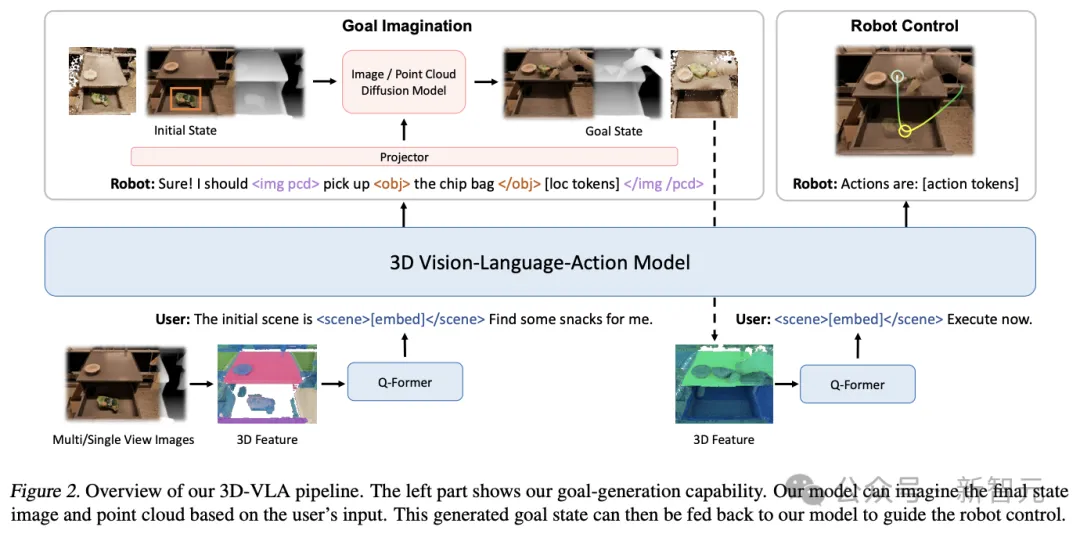
Mula-mula bina rangkaian tulang belakang di atas 3D-LLM, dan meningkatkan lagi keupayaan model untuk berinteraksi dengan dunia 3D dengan menambahkan satu siri token interaksi kemudian pra-latih model penyebaran dan gunakan unjuran untuk menyelaraskan LLM dan model resapan, menyuntik keupayaan penjanaan sasaran ke dalam 3D-VLA
rangkaian tulang belakang
Pada peringkat pertama, penyelidik mengikuti kaedah 3D-LLM untuk membangunkan model asas 3D-VLA set data yang dikumpul tidak mencapai Skala peringkat bilion yang diperlukan untuk melatih LLM berbilang modal dari awal memerlukan penggunaan ciri berbilang paparan untuk menjana ciri pemandangan 3D supaya ciri visual boleh disepadukan dengan lancar ke dalam VLM yang telah dilatih tanpa perlu untuk penyesuaian.
Pada masa yang sama, set data latihan 3D-LLM terutamanya termasuk objek dan pemandangan dalaman, yang tidak konsisten secara langsung dengan tetapan tertentu, jadi penyelidik memilih untuk menggunakan BLIP2-PlanT5XL sebagai model pra-latihan.
Semasa proses latihan, nyahbekukan pemasukan input dan output token, dan pemberat Q-Former.
Token interaksi
Untuk meningkatkan pemahaman model tentang adegan 3D dan interaksi dalam persekitaran, penyelidik memperkenalkan set token interaksi baharu
Pertama, token objek telah ditambahkan pada input, termasuk kata nama objek dalam ayat yang dihuraikan (seperti <). ; obj> sebatang coklat [token kunci] di atas meja) supaya model boleh menangkap objek yang dimanipulasi atau disebut.
Kedua, untuk menyatakan maklumat spatial dalam bahasa dengan lebih baik, para penyelidik mereka bentuk satu set token kedudukan
Ketiga, untuk melaksanakan pengekodan dinamik dengan lebih baik,
Seni bina dipertingkatkan lagi dengan memanjangkan set penanda khusus yang mewakili tindakan robot. Tindakan robot mempunyai 7 darjah kebebasan seperti
Inject goal generation capabilities
Humans can pre-visualize the final state of the scene to improve the accuracy of action prediction or decision-making, which is also a key aspect of building a world model; in pendahuluan Dalam eksperimen, para penyelidik juga mendapati bahawa menyediakan keadaan akhir yang realistik boleh meningkatkan keupayaan penaakulan dan perancangan model.
Tetapi melatih MLLM untuk menjana imej, kedalaman dan awan titik bukanlah mudah:
Pertama sekali, model penyebaran video tidak disesuaikan untuk adegan yang terkandung, seperti Landasan dalam menghasilkan bingkai masa depan "laci terbuka" , isu seperti perubahan paparan, ubah bentuk objek, penggantian tekstur pelik dan herotan reka letak berlaku di tempat kejadian.
Dan, bagaimana untuk mengintegrasikan model resapan pelbagai mod ke dalam satu model asas masih menjadi masalah yang sukar.
Jadi rangka kerja baharu yang dicadangkan oleh penyelidik terlebih dahulu melatih model resapan khusus berdasarkan bentuk berbeza seperti imej, kedalaman dan awan titik, dan kemudian menjajarkan penyahkod model resapan ke ruang benam 3D-VLA dalam peringkat penjajaran.

Hasil eksperimen
3D-VLA ialah model dunia generatif berasaskan 3D serba boleh yang boleh melakukan penaakulan dan penyetempatan dalam dunia 3D, bayangkan kandungan sasaran berbilang mod dan menjana untuk operasi robot Tindakan, penyelidik terutamanya menilai 3D-VLA daripada tiga aspek: penaakulan dan penyetempatan 3D, penjanaan sasaran berbilang modal dan perancangan tindakan yang terkandung. Inferens dan Penyetempatan 3D
Di samping itu, memandangkan set data mengandungi satu set anotasi kedudukan 3D, 3D-VLA belajar untuk mencari objek yang berkaitan, membantu model memfokuskan lebih pada objek utama untuk penaakulan.
Para penyelidik mendapati bahawa 3D-LLM berprestasi lemah pada tugas inferens robotik ini, menunjukkan keperluan untuk mengumpul dan melatih set data 3D berkaitan robotik.
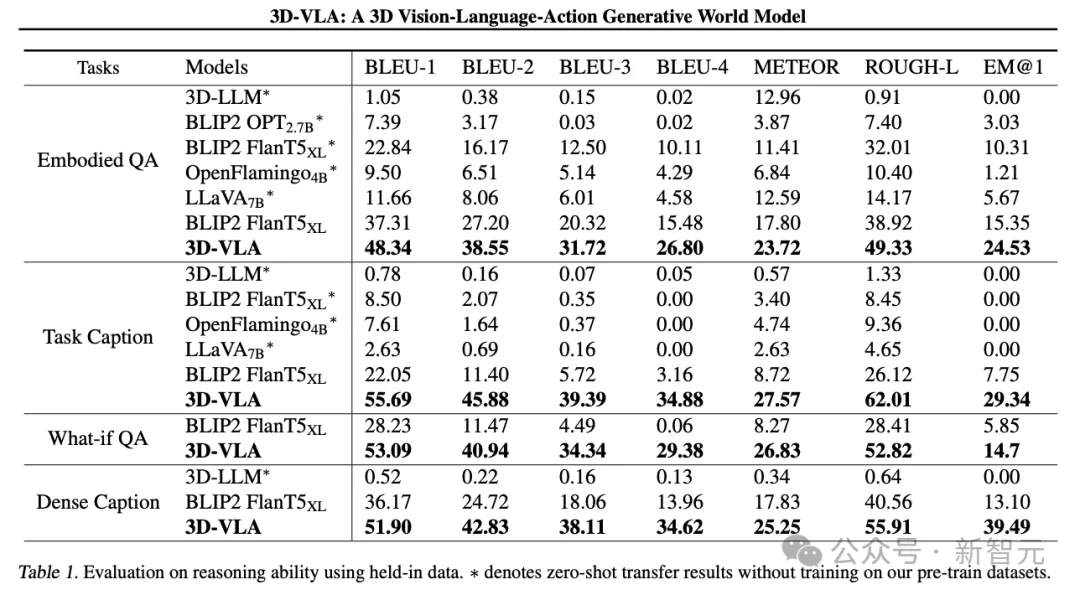
Dan 3D-VLA menunjukkan prestasi yang lebih baik daripada kaedah garis dasar 2D dalam prestasi penyetempatan ini juga memberikan bukti yang meyakinkan untuk keberkesanan proses anotasi, membantu model memperoleh keupayaan Kedudukan 3D yang berkuasa.
Penjanaan sasaran berbilang modal
Berbanding dengan kaedah penjanaan sedia ada untuk pemindahan pukulan sifar ke domain robotik, 3D-VLA mencapai prestasi yang lebih baik dalam kebanyakan metrik, mengesahkan penggunaan "reka bentuk khusus untuk aplikasi robotik" Kepentingan mereka bentuk set data untuk melatih model dunia. 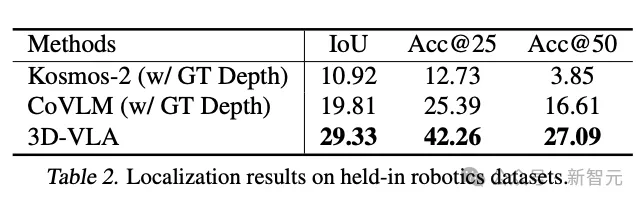
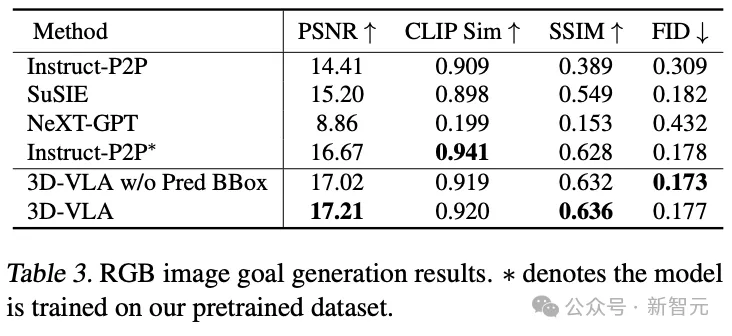
Walaupun dalam perbandingan langsung dengan Instruct-P2P*, 3D-VLA secara konsisten menunjukkan prestasi yang lebih baik, dan keputusan menunjukkan bahawa penyepaduan model bahasa besar ke dalam 3D-VLA membolehkan pemahaman yang lebih komprehensif dan mendalam tentang arahan pengendalian robot, dengan itu meningkatkan prestasi penjanaan imej sasaran.
Selain itu, apabila mengecualikan kotak sempadan yang diramalkan daripada gesaan input, sedikit penurunan prestasi boleh diperhatikan, mengesahkan keberkesanan penggunaan kotak sempadan ramalan pertengahan, yang boleh membantu model memahami keseluruhan adegan, membenarkan model untuk menggabungkan lebih banyak perhatian diperuntukkan kepada objek khusus yang disebut dalam arahan yang diberikan, akhirnya meningkatkan keupayaannya untuk membayangkan imej sasaran akhir.
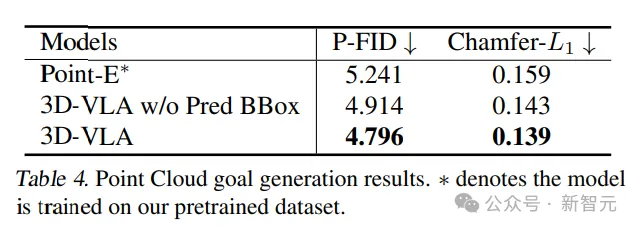
Dalam perbandingan hasil yang dijana daripada awan titik, 3D-VLA dengan kotak sempadan ramalan pertengahan menunjukkan prestasi terbaik, mengesahkan kepentingan menggabungkan model bahasa besar dan penyetempatan objek yang tepat dalam konteks memahami arahan dan adegan.
Perancangan Tindakan Terwujud
3D-VLA melebihi prestasi model garis dasar dalam kebanyakan tugas dalam ramalan tindakan RLBench, menunjukkan keupayaan perancangannya.
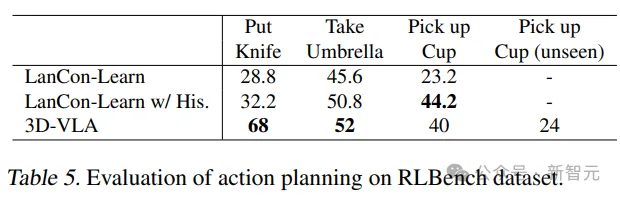
Perlu diperhatikan bahawa model garis dasar memerlukan penggunaan pemerhatian sejarah, status objek dan maklumat status semasa, manakala model 3D-VLA hanya dilaksanakan melalui kawalan gelung terbuka.
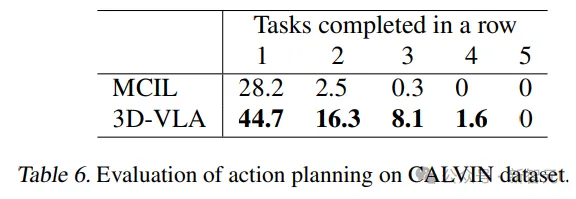
Selain itu, keupayaan generalisasi model telah terbukti dalam tugasan 3D-VLA juga mencapai keputusan yang baik dalam CALVIN minat dan bayangkan keadaan matlamat, menyediakan maklumat yang kaya untuk membuat kesimpulan tindakan.
Atas ialah kandungan terperinci Adakah versi 3D Sora akan datang? UMass, MIT dan lain-lain mencadangkan model dunia 3D, dan robot pintar yang terkandung mencapai pencapaian baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
