
 Peranti teknologi
AI
Sumber terbuka pasukan Cambridge: memperkasakan aplikasi RAG model besar berbilang modal, retriever pengetahuan pasca interaktif berbilang modal sejagat pra-terlatih yang pertama
Peranti teknologi
AI
Sumber terbuka pasukan Cambridge: memperkasakan aplikasi RAG model besar berbilang modal, retriever pengetahuan pasca interaktif berbilang modal sejagat pra-terlatih yang pertama
Sumber terbuka pasukan Cambridge: memperkasakan aplikasi RAG model besar berbilang modal, retriever pengetahuan pasca interaktif berbilang modal sejagat pra-terlatih yang pertama


- Pautan kertas: https://arxiv.org/abs/2402.08327
- 544-b8d4-53eaa55d. westx .seetacloud.com:8443/
- Pautan laman utama projek: https://preflmr.github.io/
- Tajuk kertas: PreFLMR-Inctioned Multi-Grained Layer Retriever
Latar Belakang
Walaupun model berbilang modal yang besar (seperti GPT4-Vision, Gemini, dll.) telah menunjukkan imej umum dan keupayaan pemahaman teks yang hebat apabila prestasi pemahaman teks tidak memuaskan, masalah yang memerlukan pengetahuan profesional. Malah GPT4-Vision tidak dapat menjawab soalan berintensif pengetahuan dengan berkesan (seperti yang ditunjukkan dalam Rajah 1), yang menimbulkan cabaran kepada banyak aplikasi peringkat perusahaan.
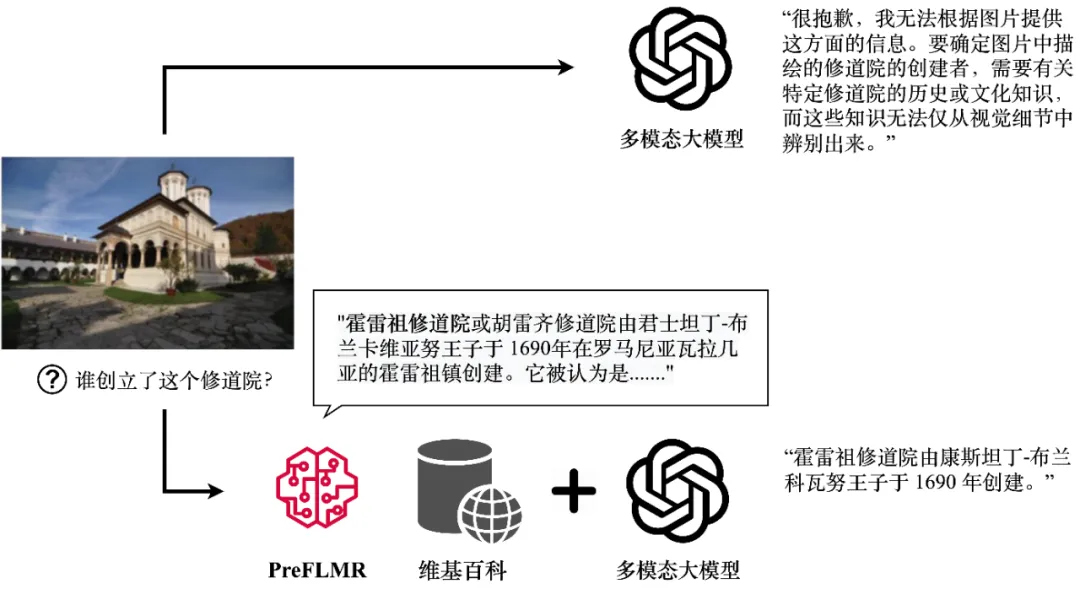
GPT4-Vision boleh memperolehi pengetahuan yang berkaitan melalui retriever pengetahuan pelbagai mod PreFLMR dan menjana jawapan yang tepat. Rajah menunjukkan output sebenar model.
Retrieval-Augmented Generation (RAG) menyediakan cara yang mudah dan berkesan untuk menyelesaikan masalah ini, membolehkan model berbilang modal yang besar menjadi seperti "pakar domain" dalam bidang tertentu. Prinsip kerjanya adalah seperti berikut: pertama, gunakan retriever pengetahuan ringan (Knowledge Retriever) untuk mendapatkan semula pengetahuan profesional yang berkaitan daripada pangkalan data profesional (seperti Wikipedia atau pangkalan pengetahuan perusahaan kemudian, model berskala besar mengambil pengetahuan dan soalan ini sebagai input). dan output Jawapan tepat. Pengetahuan "keupayaan mengingat semula" pengekstrak pengetahuan pelbagai mod secara langsung mempengaruhi sama ada model berskala besar boleh memperoleh pengetahuan profesional yang tepat semasa menjawab soalan penaakulan.
Baru-baru ini, Makmal Kecerdasan Buatan Jabatan Kejuruteraan Maklumat Universiti Cambridge telah membuka sepenuhnya perolehan semula pengetahuan interaksi lewat berbilang mod sejagat pra-terlatih, PraFLMR (Pra-trained Fine-grained Retriever Multi-modal interaksi lewat) . Berbanding dengan model biasa pada masa lalu, PreFLMR mempunyai ciri-ciri berikut:
PreFLMR ialah model pra-latihan umum yang boleh menyelesaikan berbilang sub-tugas dengan berkesan seperti mendapatkan semula teks, mendapatkan semula imej dan mendapatkan pengetahuan. Pra-dilatih pada berjuta-juta tahap data berbilang modal, model ini berfungsi dengan baik dalam berbilang tugas mendapatkan semula hiliran. Di samping itu, sebagai model asas yang sangat baik, PreFLMR boleh berkembang dengan cepat menjadi model khusus domain yang sangat baik selepas penalaan halus untuk data peribadi.
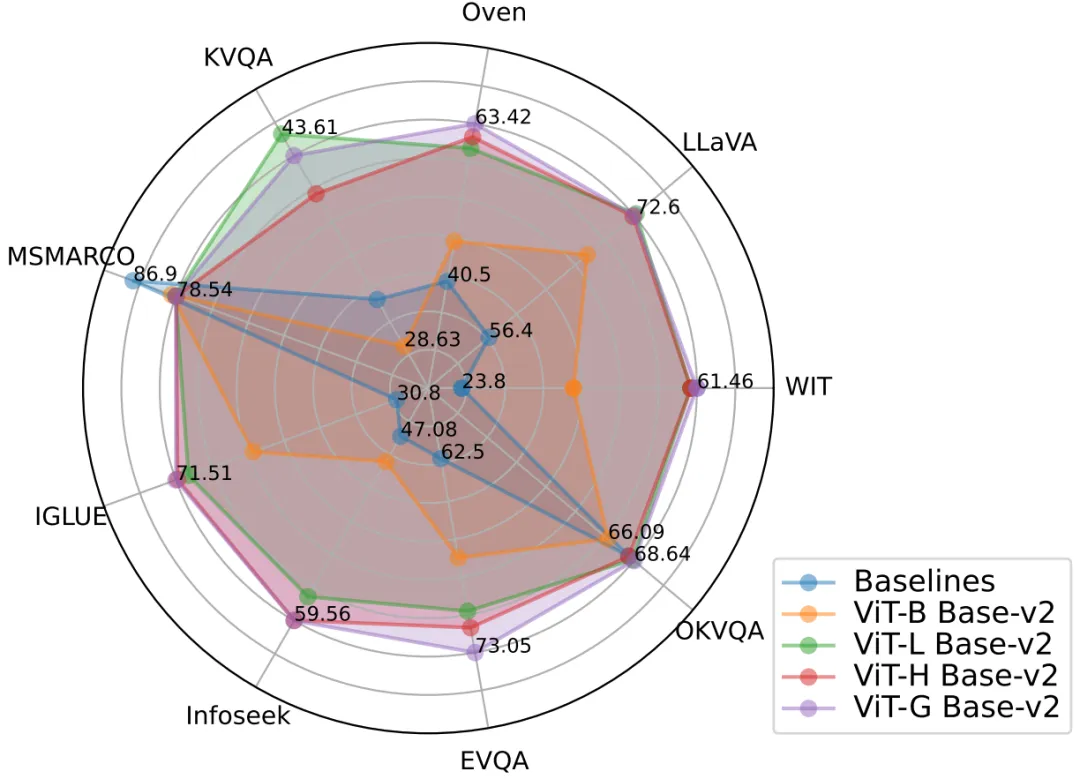
Rajah 2: Model PreFLMR mencapai prestasi perolehan semula pelbagai mod yang sangat baik pada pelbagai tugas pada masa yang sama, dan merupakan model asas pra-latihan yang sangat kuat.
2. Traditional Dense Passage Retrieval (DPR) hanya menggunakan satu vektor untuk mewakili pertanyaan (Query) atau dokumen (Document). Model FLMR yang diterbitkan oleh pasukan Cambridge di NeurIPS 2023 membuktikan bahawa reka bentuk perwakilan vektor tunggal DPR boleh membawa kepada kehilangan maklumat yang terperinci, menyebabkan DPR berprestasi rendah dalam tugas mendapatkan semula yang memerlukan pemadanan maklumat yang baik. Terutama dalam tugas berbilang modal, pertanyaan pengguna mengandungi maklumat pemandangan yang kompleks, dan memampatkannya menjadi vektor satu dimensi sangat menghalang keupayaan ekspresif ciri. PreFLMR mewarisi dan menambah baik struktur FLMR, memberikannya kelebihan unik dalam pencarian pengetahuan pelbagai mod.
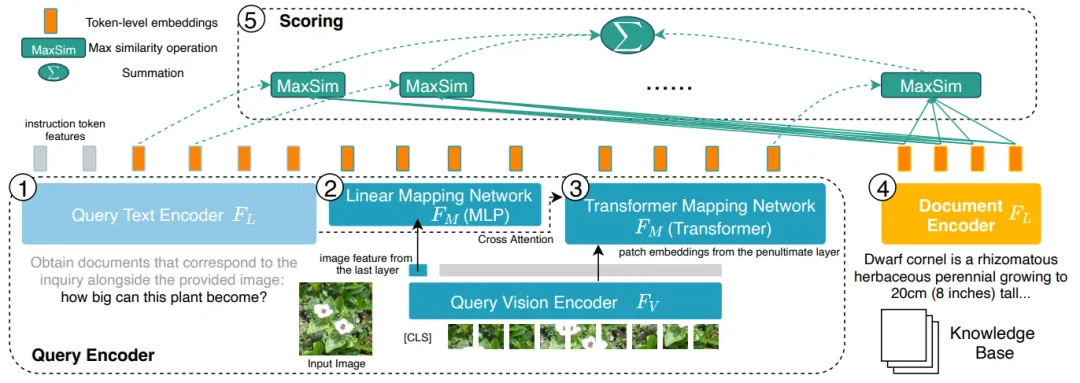
Rajah 3: PreFLMR mengekod pertanyaan (Pertanyaan, 1, 2, 3 di sebelah kiri) dan dokumen (Dokumen, 4 di sebelah kanan) pada tahap aksara (peringkat Token), berbanding dengan pengekodan semua sistem DPR yang memampatkan maklumat ke dalam vektor satu dimensi mempunyai kelebihan maklumat terperinci.
3. PreFLMR boleh mengekstrak dokumen yang berkaitan daripada pangkalan pengetahuan yang besar berdasarkan arahan yang dimasukkan oleh pengguna (seperti "Ekstrak dokumen yang boleh digunakan untuk menjawab soalan berikut" atau "Ekstrak dokumen yang berkaitan dengan item dalam gambar. "), Membantu model besar berbilang modal untuk meningkatkan prestasi tugasan soal jawab pengetahuan profesional dengan ketara.


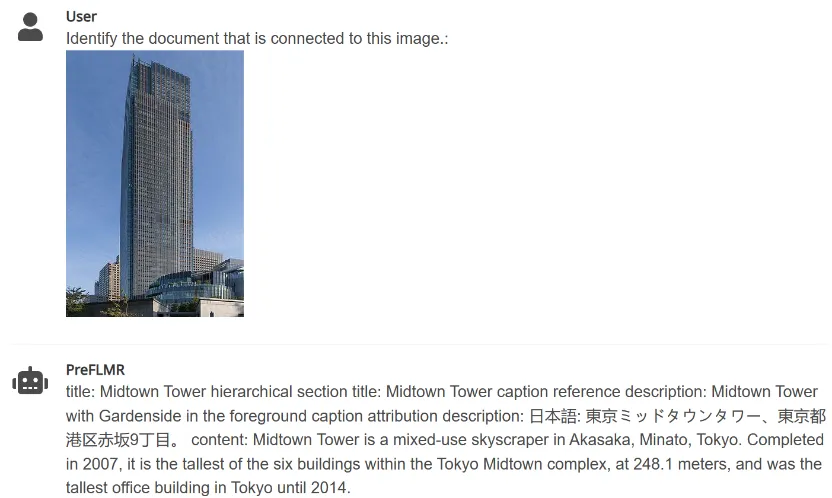
Rajah 4: PreFLMR pada masa yang sama boleh mengendalikan tugasan pertanyaan berbilang mod untuk mengekstrak dokumen berdasarkan dokumen, mengekstrak dokumen berdasarkan imej bersama-sama, mengekstrak imej berdasarkan dokumen, dan mengekstrak dokumen berdasarkan imej. .
Pasukan Universiti Cambridge mempunyai tiga model bersumber terbuka dengan saiz yang berbeza Parameter model dari kecil hingga besar ialah: PreFLMR_ViT-B (207M), PreFLMR_ViT-L (422M), PreFLMR_ViT-G (2B). , Untuk pengguna memilih mengikut keadaan sebenar.
Selain model sumber terbuka PreFLMR sendiri, projek ini juga telah memberikan dua sumbangan penting dalam hala tuju penyelidikan ini:
- Projek ini juga sumber terbuka dataset berskala besar untuk latihan dan menilai perolehan pengetahuan am, Penanda Aras Pengambilan Pengetahuan Pelbagai Modal (M2KR), yang mengandungi 10 subtugas pencarian yang telah dikaji secara meluas dalam komuniti akademik dan sejumlah lebih daripada satu juta pasangan perolehan.
- Dalam kertas kerja, pasukan Universiti Cambridge membandingkan pengekod imej dan pengekod teks dengan saiz dan prestasi yang berbeza, dan meringkaskan amalan terbaik untuk mengembangkan parameter dan pralatihan sistem perolehan pengetahuan pasca interaksi berbilang mod untuk pengambilan Umum masa hadapan model menyediakan panduan empirikal.
Berikut akan memperkenalkan secara ringkas set data M2KR, model PreFLMR dan analisis keputusan eksperimen.
M2KR Dataset
Untuk melatih dan menilai model perolehan semula berbilang mod am secara berskala, pengarang menyusun sepuluh set data yang tersedia secara terbuka dan menukarnya kepada format perolehan dokumen masalah yang bersatu. Tugas asal set data ini termasuk kapsyen imej, dialog berbilang modal, dsb. Rajah di bawah menunjukkan soalan (baris pertama) dan dokumen yang sepadan (baris kedua) untuk lima tugasan. . Pertanyaan dikodkan sebagai ciri peringkat Token. Untuk setiap vektor dalam matriks pertanyaan, PreFLMR mencari vektor terdekat dalam matriks dokumen dan mengira produk titik, dan kemudian menjumlahkan produk titik maksimum ini untuk mendapatkan perkaitan akhir.
 Model PreFLMR adalah berdasarkan Pengambilan Berbilang Modal Interaksi Lewat Berbutir Halus (FLMR) yang diterbitkan dalam NeurIPS 2023 dan menjalani penambahbaikan model dan pra-latihan berskala besar pada M2KR. Berbanding dengan DPR, FLMR dan PreFLMR menggunakan matriks yang terdiri daripada semua vektor token untuk mencirikan dokumen dan pertanyaan. Token termasuk token teks dan token imej yang ditayangkan ke dalam ruang teks. Interaksi lewat ialah algoritma untuk mengira korelasi antara dua matriks perwakilan dengan cekap. Kaedah khusus ialah: untuk setiap vektor dalam matriks pertanyaan, cari vektor terdekat dalam matriks dokumen dan hitung hasil darab titik. Produk titik maksimum ini kemudiannya dijumlahkan untuk mendapatkan korelasi akhir. Dengan cara ini, setiap perwakilan token boleh menjejaskan korelasi akhir secara eksplisit, dengan itu mengekalkan maklumat terperinci peringkat token. Terima kasih kepada enjin perolehan semula pasca interaksi yang berdedikasi, PreFLMR hanya mengambil masa 0.2 saat untuk mengekstrak 100 dokumen yang berkaitan daripada 400,000 dokumen, yang meningkatkan kebolehgunaan dalam senario RAG.
Model PreFLMR adalah berdasarkan Pengambilan Berbilang Modal Interaksi Lewat Berbutir Halus (FLMR) yang diterbitkan dalam NeurIPS 2023 dan menjalani penambahbaikan model dan pra-latihan berskala besar pada M2KR. Berbanding dengan DPR, FLMR dan PreFLMR menggunakan matriks yang terdiri daripada semua vektor token untuk mencirikan dokumen dan pertanyaan. Token termasuk token teks dan token imej yang ditayangkan ke dalam ruang teks. Interaksi lewat ialah algoritma untuk mengira korelasi antara dua matriks perwakilan dengan cekap. Kaedah khusus ialah: untuk setiap vektor dalam matriks pertanyaan, cari vektor terdekat dalam matriks dokumen dan hitung hasil darab titik. Produk titik maksimum ini kemudiannya dijumlahkan untuk mendapatkan korelasi akhir. Dengan cara ini, setiap perwakilan token boleh menjejaskan korelasi akhir secara eksplisit, dengan itu mengekalkan maklumat terperinci peringkat token. Terima kasih kepada enjin perolehan semula pasca interaksi yang berdedikasi, PreFLMR hanya mengambil masa 0.2 saat untuk mengekstrak 100 dokumen yang berkaitan daripada 400,000 dokumen, yang meningkatkan kebolehgunaan dalam senario RAG.
Pra-latihan untuk PreFLMR terdiri daripada empat peringkat berikut:
- Pralatihan pengekod teks: Pertama, model perolehan teks pasca interaksi dipralatih pada MSMARCO (set data perolehan pengetahuan teks tulen) sebagai pengekod teks PreFLMR.
-
Lapisan unjuran teks imej pra-latihan: Kedua, latih lapisan unjuran teks imej pada M2KR dan bekukan bahagian lain. Peringkat ini hanya menggunakan vektor imej unjuran untuk mendapatkan semula, bertujuan untuk mengelakkan model daripada terlalu bergantung pada maklumat teks.
-
Pralatihan berterusan: Pengekod teks dan lapisan unjuran imej-ke-teks kemudiannya dilatih secara berterusan pada tugas menjawab soalan visual berintensif pengetahuan berkualiti tinggi dalam E-VQA, M2KR. Peringkat ini bertujuan untuk meningkatkan keupayaan perolehan pengetahuan halus PreFLMR.
-
Latihan Pencapaian Sejagat: Akhir sekali, latih semua pemberat pada keseluruhan set data M2KR, bekukan pengekod imej sahaja. Pada masa yang sama, parameter pengekod teks pertanyaan dan pengekod teks dokumen dibuka kunci dan dilatih secara berasingan. Peringkat ini bertujuan untuk meningkatkan keupayaan mendapatkan semula umum PreFLMR.
Pada masa yang sama, pengarang menunjukkan bahawa PreFLMR boleh diperhalusi lebih lanjut pada sub-set data (seperti OK-VQA, Infoseek) untuk mendapatkan prestasi perolehan semula yang lebih baik pada tugas tertentu.
Hasil eksperimen dan pengembangan menegak
Hasil perolehan semula terbaik: Model PreFLMR berprestasi terbaik menggunakan ViT-G sebagai pengekod imej dan ColBERT-base-v2 sebagai pengekod teks, dengan jumlah dua bilion parameter. Ia mencapai prestasi melebihi model garis dasar pada 7 subtugas pengambilan M2KR (WIT, OVEN, Infoseek, E-VQA, OKVQA, dll.).
Pengekodan visual lanjutan adalah lebih berkesan: Pengarang mendapati bahawa menaik taraf pengekod imej ViT daripada ViT-B (86M) kepada ViT-L (307M) membawa peningkatan prestasi yang ketara, tetapi menaik taraf pengekod teks ColBERT daripada pangkalan (110M) ) berkembang kepada besar (345M) menyebabkan kemerosotan prestasi dan menyebabkan masalah ketidakstabilan latihan. Keputusan eksperimen menunjukkan bahawa untuk sistem perolehan semula pelbagai mod interaktif kemudiannya, meningkatkan parameter pengekod visual membawa pulangan yang lebih besar. Pada masa yang sama, menggunakan berbilang lapisan Perhatian silang untuk unjuran teks imej mempunyai kesan yang sama seperti menggunakan satu lapisan, jadi reka bentuk rangkaian unjuran teks imej tidak perlu terlalu rumit.
PreFLMR menjadikan RAG lebih berkesan: Pada tugasan menjawab soalan visual berintensif pengetahuan, menggunakan PreFLMR untuk peningkatan perolehan sangat meningkatkan prestasi sistem akhir: 94% dan 275% peningkatan prestasi masing-masing dicapai pada Infoseek dan EVQA penalaan halus yang mudah, model berasaskan BLIP-2 boleh mengalahkan model PALI-X dengan ratusan bilion parameter dan sistem PaLM-Bison+Lens dipertingkatkan dengan Google API.
Kesimpulan
Model PreFLMR yang dicadangkan oleh Makmal Kecerdasan Buatan Cambridge ialah model perolehan semula pelbagai mod interaktif am sumber terbuka yang pertama. Selepas pra-latihan pada berjuta-juta data pada M2KR, PreFLMR menunjukkan prestasi yang kukuh dalam berbilang subtugas mendapatkan semula. Set data M2KR, berat model dan kod PreFLMR tersedia di halaman utama projek https://preflmr.github.io/. . 2cf 9872-Abstract-Conference.html
Pangkalan kod: https://github.com/LinWeizheDragon/Retrieval-Augmented-Visual-Question-AnsweringBlog versi bahasa Inggeris: https://www.jinghong-chen.net/preflmr-sota-open- bersumberkan -multi/
- FLMR Pengenalan: https://www.jinghong-chen.net/fined-grained-late-interaction-multimodal-retrieval-flmr/
Atas ialah kandungan terperinci Sumber terbuka pasukan Cambridge: memperkasakan aplikasi RAG model besar berbilang modal, retriever pengetahuan pasca interaktif berbilang modal sejagat pra-terlatih yang pertama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Apabila menukar rentetan ke objek dalam vue.js, json.parse () lebih disukai untuk rentetan json standard. Untuk rentetan JSON yang tidak standard, rentetan boleh diproses dengan menggunakan ungkapan biasa dan mengurangkan kaedah mengikut format atau url yang dikodkan. Pilih kaedah yang sesuai mengikut format rentetan dan perhatikan isu keselamatan dan pengekodan untuk mengelakkan pepijat.
 Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Untuk menetapkan masa untuk Vue Axios, kita boleh membuat contoh Axios dan menentukan pilihan masa tamat: dalam tetapan global: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dalam satu permintaan: ini. $ axios.get ('/api/pengguna', {timeout: 10000}).
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Ringkasan: Terdapat kaedah berikut untuk menukar array rentetan vue.js ke dalam tatasusunan objek: Kaedah asas: Gunakan fungsi peta yang sesuai dengan data yang diformat biasa. Permainan lanjutan: Menggunakan ungkapan biasa boleh mengendalikan format yang kompleks, tetapi mereka perlu ditulis dengan teliti dan dipertimbangkan. Pengoptimuman Prestasi: Memandangkan banyak data, operasi tak segerak atau perpustakaan pemprosesan data yang cekap boleh digunakan. Amalan Terbaik: Gaya Kod Jelas, Gunakan nama dan komen pembolehubah yang bermakna untuk memastikan kod ringkas.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
