

Melatih model bahasa besar (llm) ialah tugas yang intensif dari segi pengiraan, walaupun yang mempunyai "hanya" 7 bilion parameter. Tahap latihan ini memerlukan sumber di luar kemampuan kebanyakan peminat individu. Untuk merapatkan jurang ini, kaedah cekap parameter seperti penyesuaian peringkat rendah (LoRA) telah muncul, membolehkan penalaan halus sejumlah besar model pada GPU gred pengguna.
GaLore ialah kaedah inovatif yang menggunakan latihan parameter yang dioptimumkan untuk mengurangkan keperluan VRAM dan bukannya hanya mengurangkan bilangan parameter. Ini bermakna GaLore ialah strategi latihan model baharu yang membolehkan model menggunakan sepenuhnya semua parameter untuk pembelajaran dan menjimatkan memori dengan lebih cekap daripada LoRA.
GaLore mengurangkan beban pengiraan dengan berkesan dengan memetakan kecerunan ini ke dalam ruang berdimensi rendah sambil mengekalkan maklumat latihan utama. Tidak seperti pengoptimum tradisional yang mengemas kini semua lapisan sekaligus semasa perambatan belakang, GaLore menggunakan kaedah kemas kini lapisan demi lapisan untuk perambatan balik. Strategi ini dengan ketara mengurangkan jejak memori semasa latihan dan seterusnya mengoptimumkan prestasi.
Sama seperti LoRA, GaLore membenarkan kami memperhalusi model 7B pada GPU gred pengguna yang dilengkapi dengan sehingga 24 GB VRAM. Keputusan menunjukkan bahawa prestasi model adalah setanding dengan penalaan halus parameter penuh malah nampaknya lebih baik daripada LoRA.
lebih baik daripada Memeluk Wajah Buat masa ini tiada kod rasmi. Mari kita gunakan kod kertas secara manual untuk latihan dan bandingkan dengan LoRA
semua. GaLore
pip install galore-torch
Kemudian kami juga perlu menyemak perpustakaan ini, dan sila beri perhatian kepada versi
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrsfrom transformers import get_constant_schedule from functools import partial import torch.nn import bitsandbytes as bnb from galore_torch import GaLoreAdamW8bit def load_galore_optimizer(model, lr, galore_config):# function to hook optimizer and scheduler to a given parameter def optimizer_hook(p, optimizer, scheduler):if p.grad is not None: optimizer.step()optimizer.zero_grad()scheduler.step() # Parameters to optimize with Galoregalore_params = [(module.weight, module_name) for module_name, module in model.named_modules() if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])] id_galore_params = {id(p) for p, _ in galore_params} # Hook Galore optim to all target params, Adam8bit to all othersfor p in model.parameters():if p.requires_grad:if id(p) in id_galore_params:optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)else:optimizer = bnb.optim.Adam8bit([p], lr = lr)scheduler = get_constant_schedule(optimizer) p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler)) # return dummies, stepping is done with hooks return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, set_seed, get_constant_schedule from trl import SFTTrainer, setup_chat_format, DataCollatorForCompletionOnlyLM from datasets import load_dataset import torch, torch.nn as nn, uuid, wandb lr = 1e-5 # GaLore optimizer hyperparameters galore_config = dict(target_modules_list = ["attn", "mlp"], rank = 1024, update_proj_gap = 200, scale = 2, proj_type="std" ) modelpath = "meta-llama/Llama-2-7b" model = AutoModelForCausalLM.from_pretrained(modelpath,torch_dtype=torch.bfloat16,attn_implementation = "flash_attention_2",device_map = "auto",use_cache = False, ) tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False) # Setup for ChatML model, tokenizer = setup_chat_format(model, tokenizer) if tokenizer.pad_token in [None, tokenizer.eos_token]: tokenizer.pad_token = tokenizer.unk_token # subset of the Open Assistant 2 dataset, 4000 of the top ranking conversations dataset = load_dataset("g-ronimo/oasst2_top4k_en") training_arguments = TrainingArguments(output_dir = f"out_{run_id}",evaluation_strategy = "steps",label_names = ["labels"],per_device_train_batch_size = 16,gradient_accumulation_steps = 1,save_steps = 250,eval_steps = 250,logging_steps = 1, learning_rate = lr,num_train_epochs = 3,lr_scheduler_type = "constant",gradient_checkpointing = True,group_by_length = False, ) optimizers = load_galore_optimizer(model, lr, galore_config) trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset["train"],eval_dataset = dataset['test'],data_collator = DataCollatorForCompletionOnlyLM(instruction_template = "user", response_template = "assistant", tokenizer = tokenizer, mlm = False),max_seq_length = 256,dataset_kwargs = dict(add_special_tokens = False),optimizers = optimizers,args = training_arguments, ) trainer.train()Pengoptimum GaLore mempunyai beberapa hiperparameter yang perlu ditetapkan seperti berikut:
target_modules_list: Tentukan lapisan sasaran GaLore
kedudukan: Kedudukan matriks unjuran. Sama seperti LoRA, semakin tinggi kedudukannya, semakin hampir penalaan halus dengan penalaan halus parameter penuh. Pengarang GaLore mengesyorkan 7B untuk menggunakan 1024
update_proj_gap: Bilangan langkah untuk mengemas kini unjuran. Ini adalah langkah yang mahal dan mengambil masa kira-kira 15 minit untuk 7B. Mentakrifkan selang untuk mengemas kini unjuran, julat yang disyorkan adalah antara 50 dan 1000 langkah. Skala
: Faktor penskalaan yang serupa dengan alfa LoRA, digunakan untuk melaraskan keamatan kemas kini. Selepas mencuba beberapa nilai, saya mendapati skala=2 paling hampir dengan penalaan halus parameter penuh klasik.
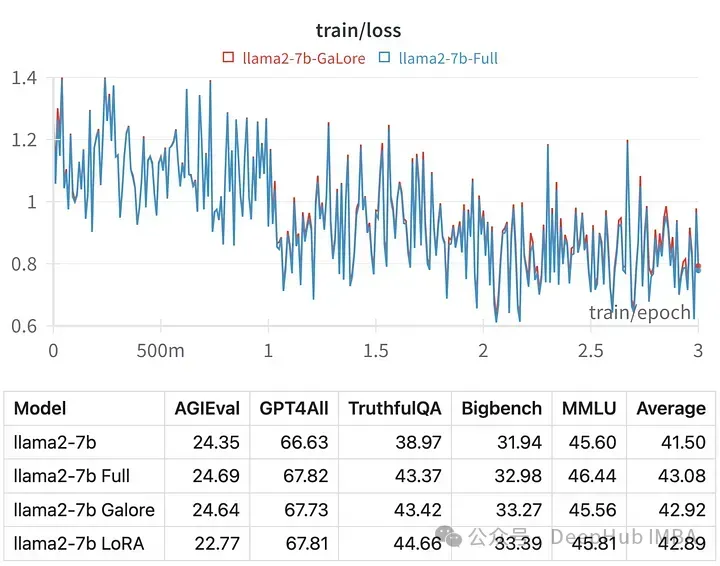
Kehilangan latihan untuk hiperparameter tertentu adalah sangat serupa dengan trajektori penalaan parameter penuh, menunjukkan bahawa kaedah berlapis GaLore sememangnya setara.
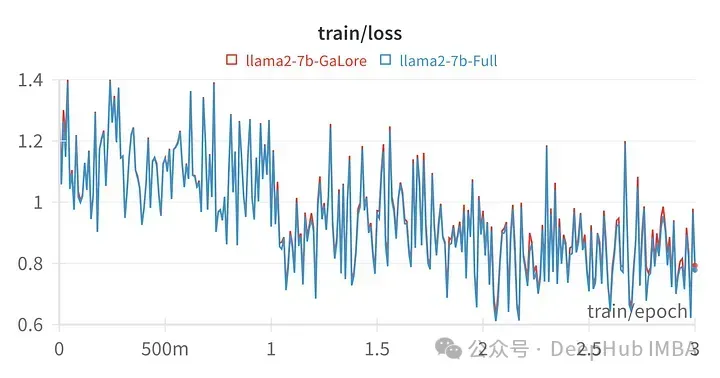
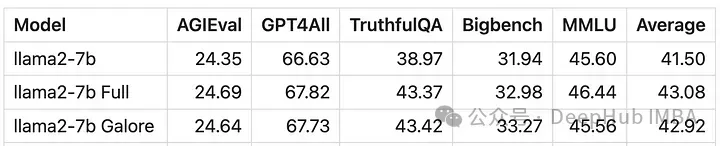
Skor model yang dilatih dengan GaLore sangat serupa dengan penalaan halus parameter penuh.
GaLore boleh menjimatkan kira-kira 15 GB VRAM, tetapi ia mengambil masa yang lebih lama untuk melatih kerana kemas kini unjuran biasa.
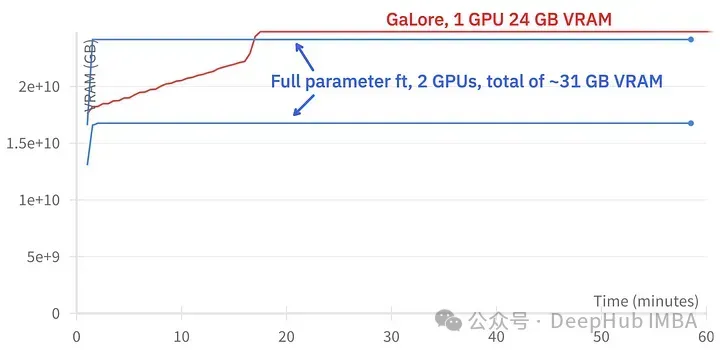
Gambar di atas menunjukkan perbandingan penggunaan memori dua 3090s
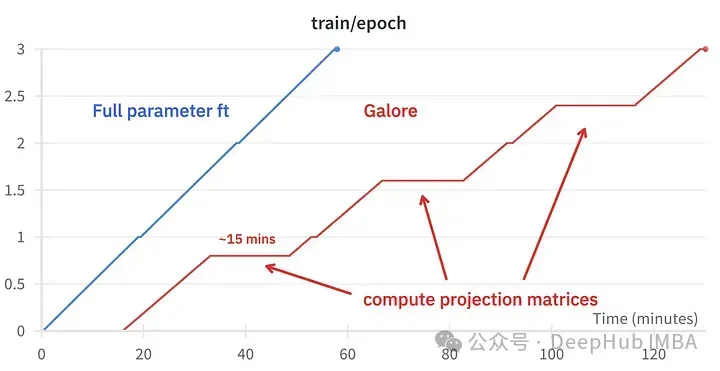
Perbandingan acara latihan, penalaan halus: ~58 minit. GaLore: Kira-kira 130 minit
Akhir sekali mari kita lihat perbandingan antara GaLore dan LoRA
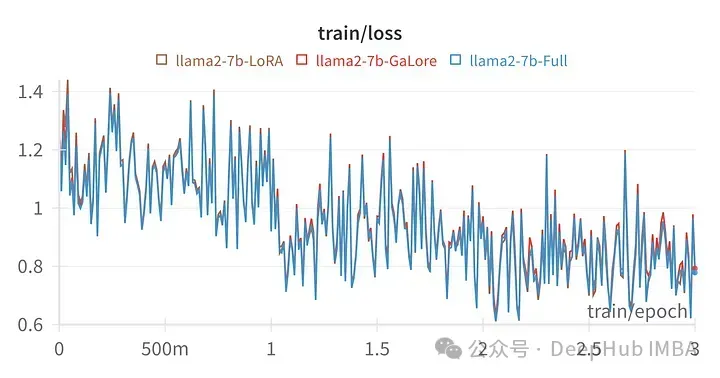
Gambar di atas ialah carta kehilangan LoRA penalaan halus semua lapisan linear, alpha 164 peringkat
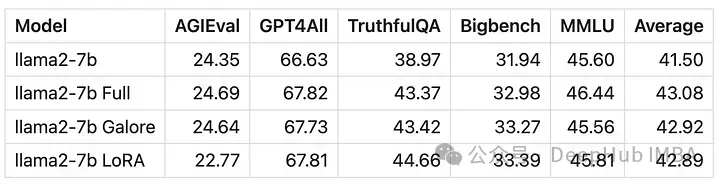
Daripada Numerik, dapat dilihat bahawa GaLore ialah kaedah baharu yang menghampiri latihan parameter penuh, dan prestasinya setanding dengan penalaan halus dan jauh lebih baik daripada LoRA.
GaLore menjimatkan VRAM dan membenarkan latihan model 7B pada GPU pengguna, tetapi lebih perlahan dan mengambil masa hampir dua kali lebih lama daripada penalaan halus dan LoRA.
Atas ialah kandungan terperinci Penalaan LLM yang cekap pada GPU tempatan menggunakan GaLore. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah tulisan brc20
Apakah tulisan brc20
 Tutorial Laravel
Tutorial Laravel
 Cara menggunakan localstorage
Cara menggunakan localstorage
 fungsi direct3d tidak tersedia
fungsi direct3d tidak tersedia
 Pengenalan kepada pembekal perkhidmatan dengan harga pelayan awan kos efektif
Pengenalan kepada pembekal perkhidmatan dengan harga pelayan awan kos efektif
 Senarai lengkap kekunci pintasan idea
Senarai lengkap kekunci pintasan idea
 Tiada penyesuai rangkaian dalam pengurus peranti
Tiada penyesuai rangkaian dalam pengurus peranti
 Penggunaan arahan sumber dalam linux
Penggunaan arahan sumber dalam linux
 Bagaimana pula dengan Ouyi Exchange?
Bagaimana pula dengan Ouyi Exchange?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



