

Gunakan model siap pakai pada Huggingface untuk "menjimatkan" -
Bolehkah anda menggabungkan model berkuasa baharu secara langsung? !
Sakana.ai, sebuah syarikat model Jepun yang besar, mempunyai imaginasi yang hebat(ia adalah syarikat yang diasaskan oleh salah satu daripada "Transformer Eight"), dan menghasilkan cara yang bijak untuk berkembang dan menggabungkan model.

Kaedah ini bukan sahaja boleh menjana model asas baharu secara automatik, tetapi juga prestasinya sama sekali tidak buruk:
Mereka menggunakan model besar matematik Jepun yang mengandungi 7 bilion parameter dan mencapai keadaan-of- hasil seni dalam penanda aras yang relevan Hasilnya mengatasi model sebelumnya seperti Llama-2 dengan 70 bilion parameter.
Perkara yang paling penting ialah tiba di model sedemikian tidak memerlukan sebarang latihan kecerunan , jadi sumber pengkomputeran yang diperlukan sangat berkurangan.
Saintis NVIDIA Jim Fan memujinya selepas membacanya:
Ini adalah salah satu kertas paling imaginatif yang saya baca baru-baru ini.

Kebanyakan model berprestasi terbaik daripada kedudukan model besar sumber terbuka bukan lagi model "asal" seperti LLaMA atau Mistral, tetapi beberapa model yang diperhalusi atau digabungkan Selepas itu, kita boleh lihat:
Trend baru telah muncul.
Sakana.ai memperkenalkan bahawa model asas sumber terbuka boleh diperluaskan dengan mudah dan diperhalusi dalam ratusan arah berbeza, dan kemudian menjana model baharu yang berprestasi baik dalam bidang baharu.
Antaranya, Model penggabungan menunjukkan janji yang hebat.

Namun, ia mungkin "ilmu hitam" yang banyak bergantung pada gerak hati dan kepakaran.
Justeru, kita perlukan pendekatan yang lebih sistematik.
Diinspirasikan oleh pemilihan semula jadi dalam alam semula jadi, Sakana.ai memfokuskan pada algoritma evolusi, memperkenalkan konsep "Gabungan Model Evolusi", dan mencadangkan kaedah umum yang boleh menemui gabungan model terbaik.
Kaedah ini menggabungkan dua idea berbeza:
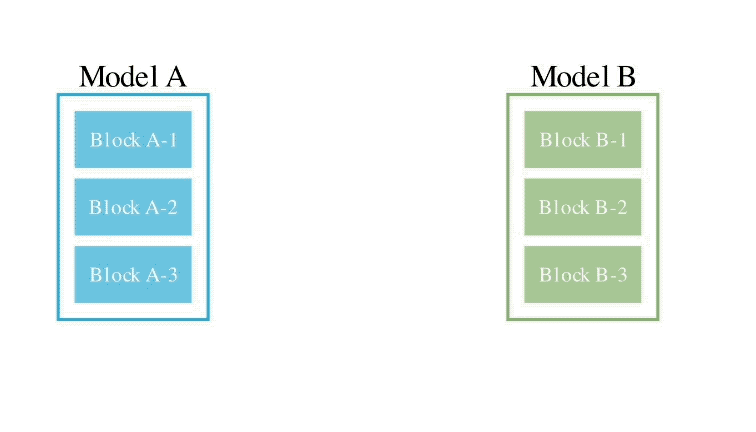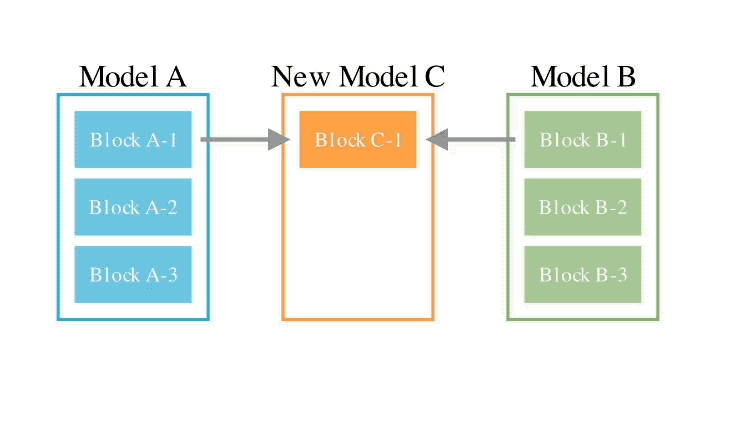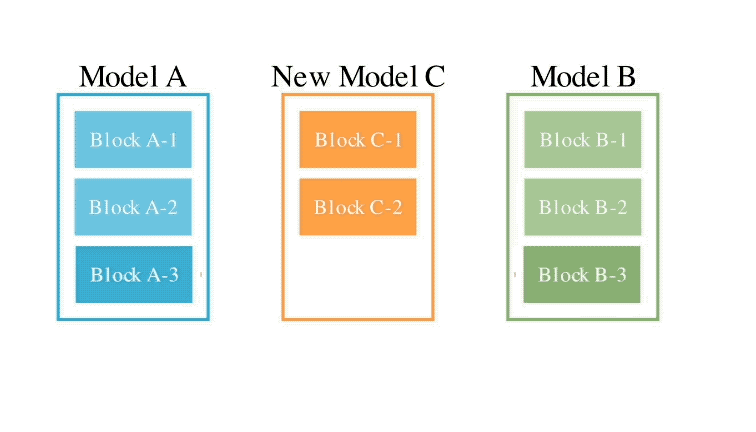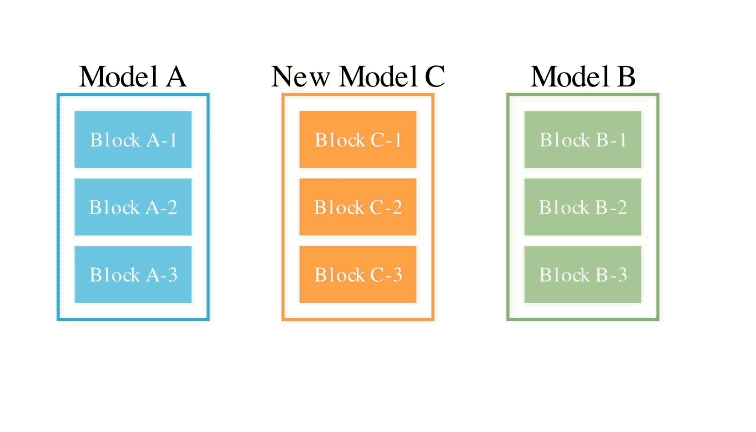
(1) menggabungkan model dalam ruang aliran data (lapisan) , dan (2) menggabungkan model dalam ruang parameter (berat) .
Secara khusus, kaedah ruang aliran data pertama adalah untuk menemui gabungan terbaik lapisan model yang berbeza melalui evolusi untuk membentuk model baharu.
Pada masa lalu, komuniti bergantung pada gerak hati untuk menentukan cara dan lapisan mana model boleh digabungkan dengan lapisan model lain.
Tetapi sebenarnya, Sakana.ai memperkenalkan bahawa masalah ini mempunyai ruang carian dengan sejumlah besar kombinasi, yang paling sesuai untuk carian dengan algoritma pengoptimuman seperti algoritma evolusi.
Contoh operasi adalah seperti berikut:
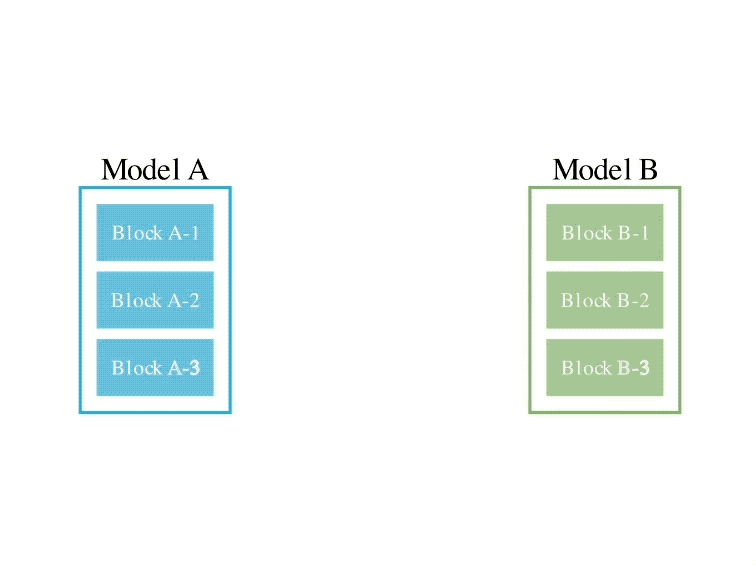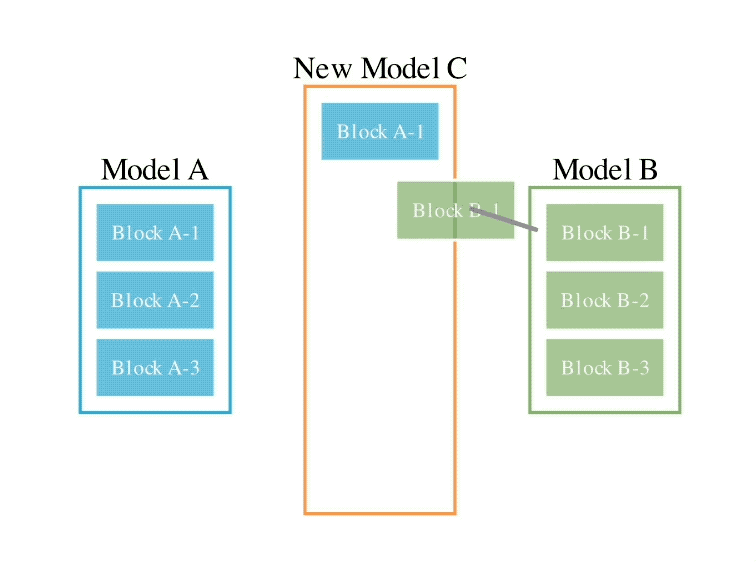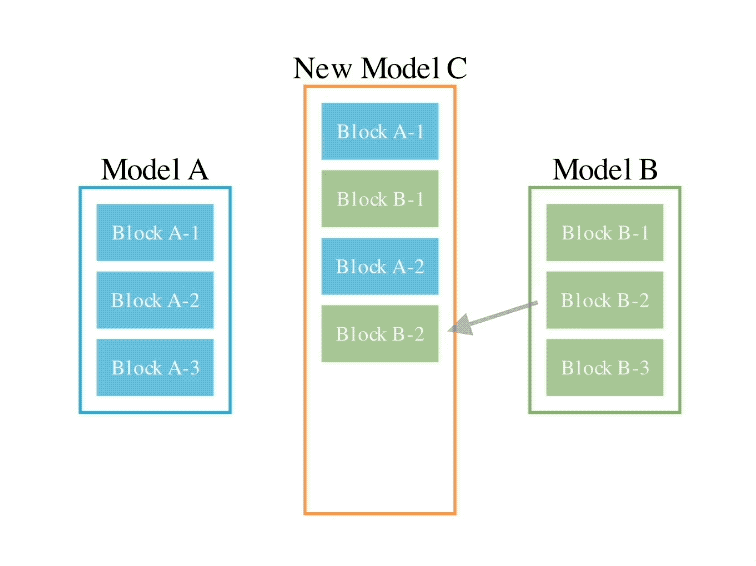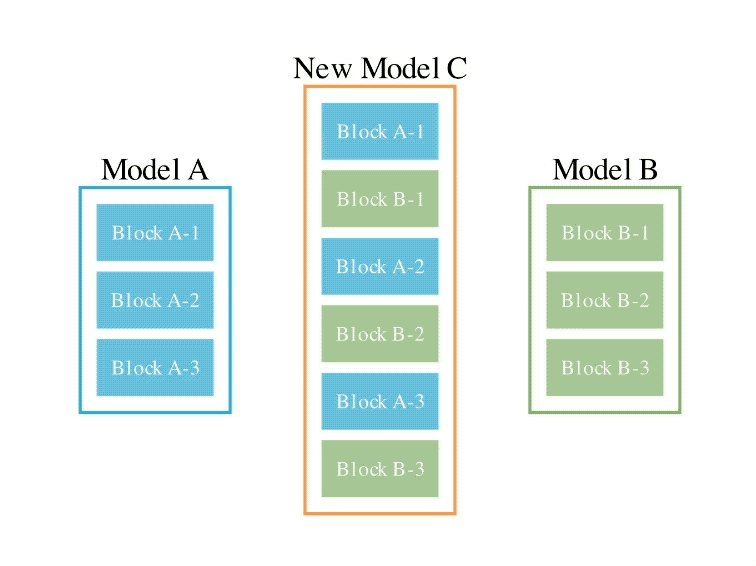
Bagi kaedah ruang parameter kedua, berat model berbilang dicampur untuk membentuk model baharu.
Sebenarnya terdapat banyak cara untuk melaksanakan kaedah ini, dan pada dasarnya, setiap lapisan adunan boleh menggunakan nisbah bancuhan yang berbeza, malah lebih banyak lagi.
Dan di sini, menggunakan kaedah evolusi, kami boleh mencari lebih banyak strategi hibrid baru dengan berkesan.
Berikut adalah contoh mencampurkan berat dua model yang berbeza untuk mendapatkan model baharu:
Menggabungkan dua kaedah di atas, inilah rupanya:
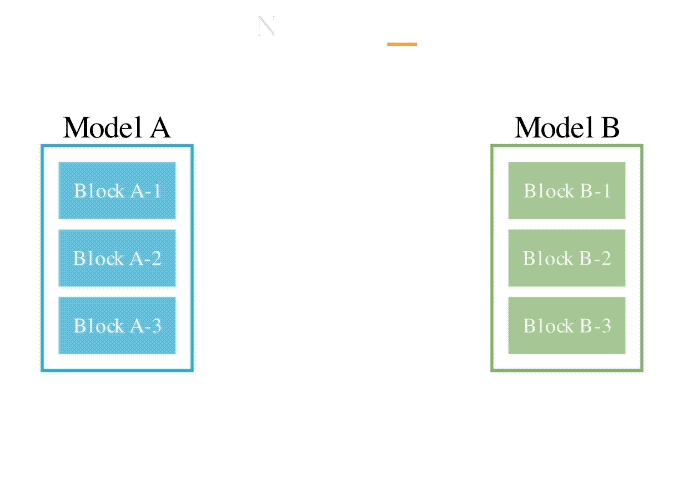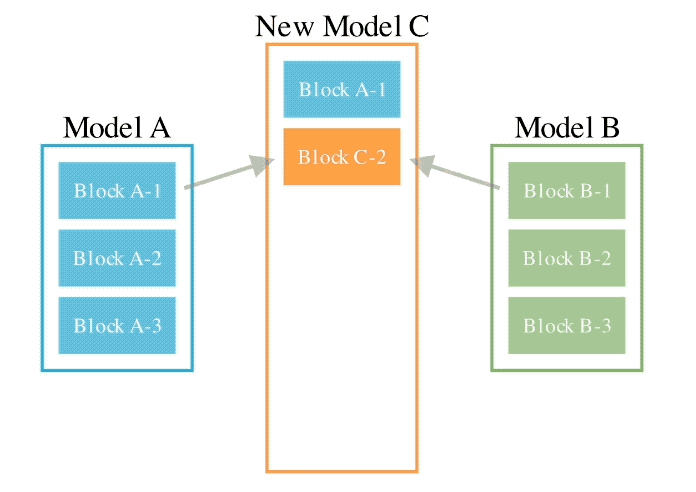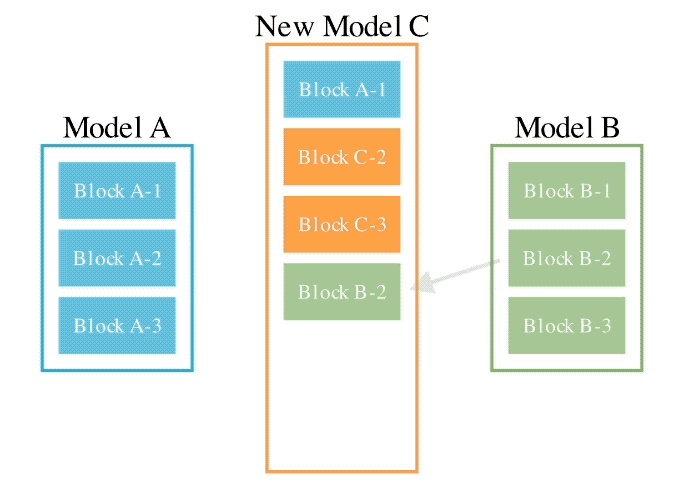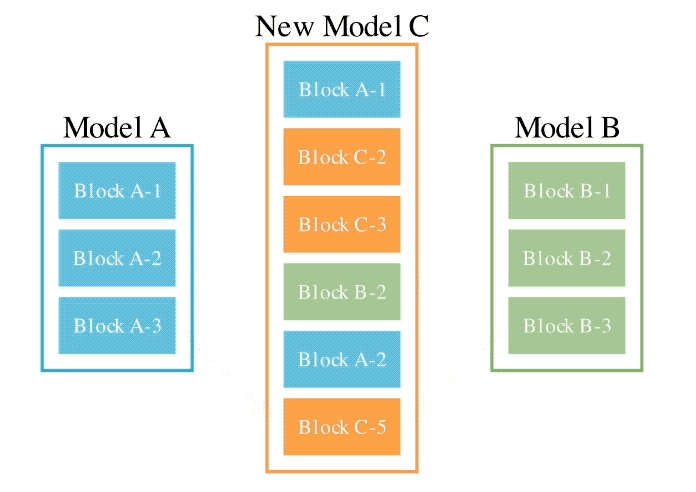
Pengarang memperkenalkan bahawa mereka berharap untuk mencapai matlamat untuk menggabungkan berat dua model yang berbeza, seperti matematik dan bahasa bukan Inggeris, visi dan bahasa bukan Inggeris, untuk membentuk gabungan baru yang belum diterokai sebelum ini.
Hasilnya memang memeranjatkan.
Menggunakan kaedah penggabungan evolusi di atas, pasukan memperoleh 3 model asas:
Model besar Jepun Shisa Gamma 7B v1+LLaVa-1.6-Mistral-7B, ialah VLM dengan keupayaan bahasa Jepun.
Menyokong model penyebaran SDXL Jepun.
Dua yang pertama telah dikeluarkan pada Hugging Face dan GitHub, dan yang terakhir akan dilancarkan tidak lama lagi.
Lihat secara khusus. EvoLLM-JP menyelesaikan matematik dalam bahasa Jepun Prestasi masalah melebihi model asalnya, serta model berprestasi tinggi seperti Llama-2 dan GPT-3.5.
Antaranya, model 4 dioptimumkan hanya dalam ruang parameter, dan model 6 adalah hasil pengoptimuman selanjutnya dalam ruang aliran data menggunakan model 4. Pada penanda aras lm-evaluation-harness Jepun, yang menilai kedua-dua keupayaan data dan kebolehan umum bahasa Jepun, EvoLLM-JP mencapai skor purata tertinggi 70.5 pada 9 tugasan - menggunakan hanya 7 bilion parameter, ia mengalahkan 70 bilion Llama-2 dan model lain.
Pasukan menyatakan bahawa EvoLLM-JP cukup baik untuk digunakan sebagai model berskala besar Jepun umum dan menyelesaikan beberapa contoh menarik: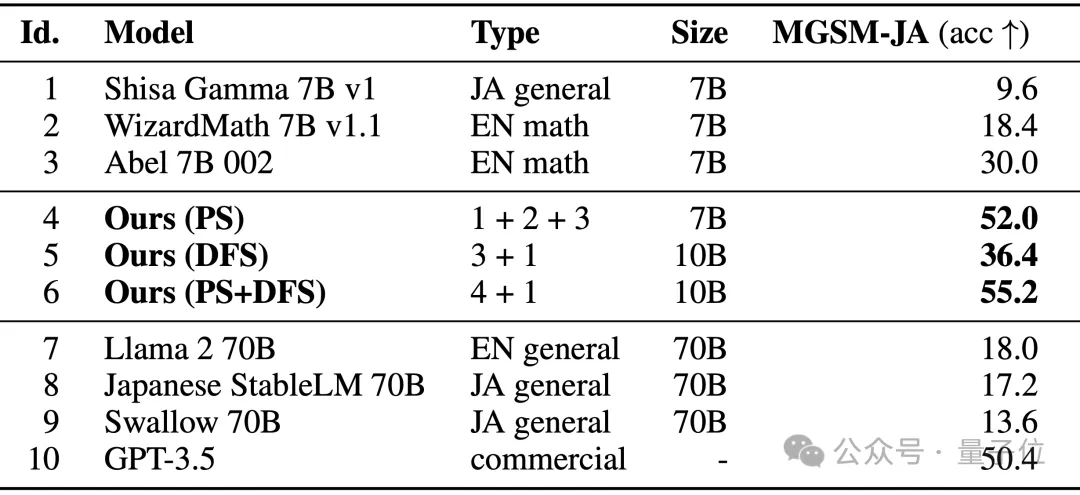 seperti masalah matematik yang memerlukan pengetahuan khusus tentang budaya Jepun, atau menceritakan jenaka Jepun dalam dialek Kansai.
seperti masalah matematik yang memerlukan pengetahuan khusus tentang budaya Jepun, atau menceritakan jenaka Jepun dalam dialek Kansai.
2, EvoVLM-JP
Pada dua set data penanda aras berikut bagi soalan dan jawapan imej, semakin tinggi skor, semakin tepat huraian jawapan model dalam bahasa Jepun. 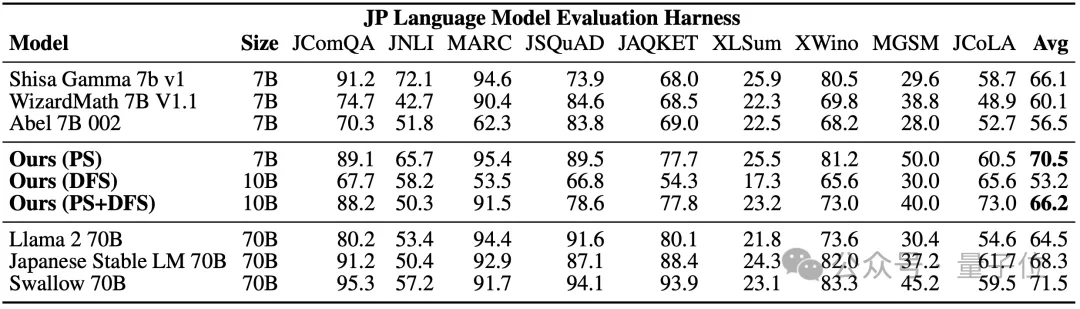
Seperti gambar di bawah, apabila ditanya apa warna lampu isyarat dalam gambar, hanya EvoVLM-JP sahaja yang menjawab dengan betul: biru.
3, EvoSDXL-JP Model SDXL yang disokong Jepun ini hanya memerlukan 4 model resapan untuk melakukan inferens, dan kelajuan penjanaan agak pantas.
Model SDXL yang disokong Jepun ini hanya memerlukan 4 model resapan untuk melakukan inferens, dan kelajuan penjanaan agak pantas.
Skor larian khusus belum dikeluarkan lagi, tetapi pasukan mendedahkan bahawa ia "agak menjanjikan".
Anda boleh menikmati beberapa contoh: 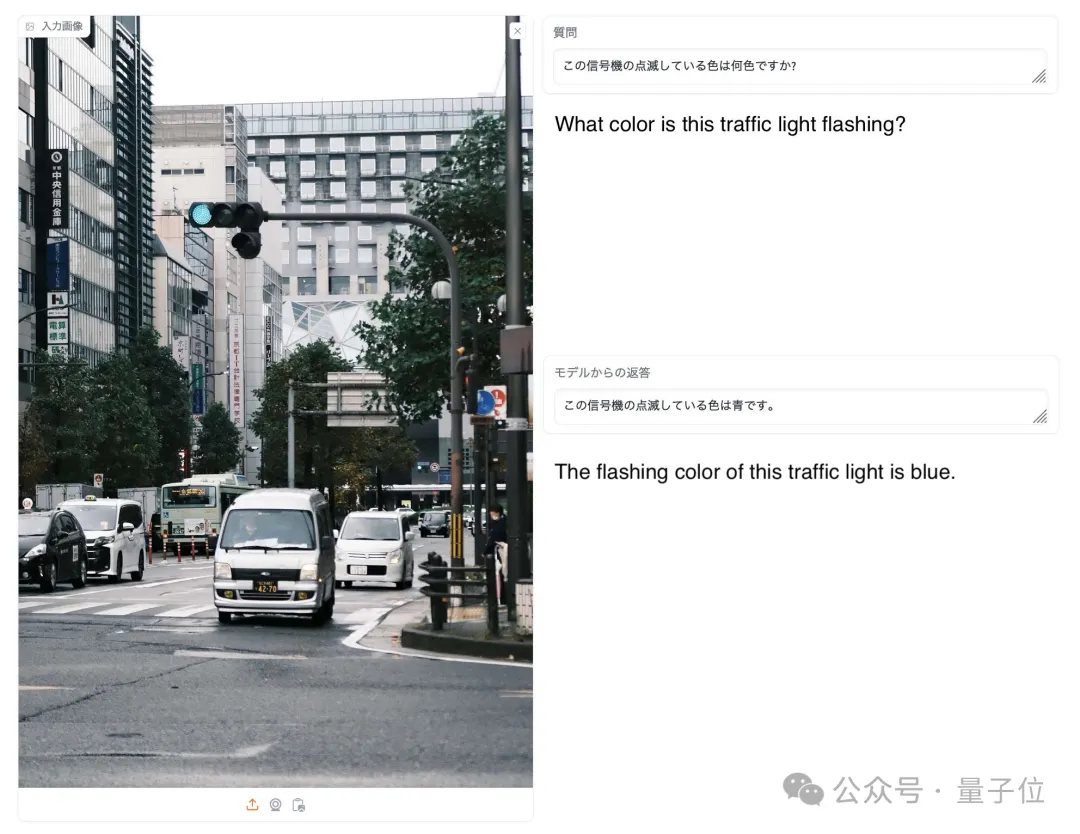
Kata-kata gesaan termasuk: Miso ラーメン, Ukiyoe Kualiti Tertinggi, Katsushika Hokusai, Zaman Edo.
Untuk 3 model baharu di atas, pasukan menyatakan:
Secara prinsipnya, kami boleh menggunakan perambatan belakang berasaskan kecerunan untuk meningkatkan lagi prestasi model ini.
Tetapi kami tidak menggunakan , kerana tujuannya sekarang adalah untuk menunjukkan bahawa walaupun tanpa backpropagation, kami masih boleh mendapatkan model asas yang cukup maju untuk mencabar "paradigma mahal" semasa.
Netizen menyukai ini satu demi satu. 
, tetapi yang terakhir adalah latihan (itu ialah, algoritma evolusi yang dicadangkan dalam artikel ini) dan peringkat penaakulan sebenarnya mempunyai potensi yang besar.
△Disukai oleh MuskJadi, bak kata netizen: Adakah kita kini berada di era Ledakan Cambrian model?
Atas ialah kandungan terperinci Model ini akan berkembang selepas bergabung, dan secara langsung memenangi SOTA! Pencapaian keusahawanan baru pengarang Transformer adalah popular. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Apakah nama suara tt yang ditukar?
Apakah nama suara tt yang ditukar?
 Bagaimana untuk memasukkan pemacu d dengan cmd
Bagaimana untuk memasukkan pemacu d dengan cmd
 Proses khusus untuk menyambung ke wifi dalam sistem win7
Proses khusus untuk menyambung ke wifi dalam sistem win7
 Alat penilaian nama domain tapak web
Alat penilaian nama domain tapak web
 kata putus baris paksa
kata putus baris paksa
 Bagaimana untuk menyelesaikan ralat kipas cpu
Bagaimana untuk menyelesaikan ralat kipas cpu
 Bagaimana untuk membaca carriage return di java
Bagaimana untuk membaca carriage return di java








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



