
 Peranti teknologi
AI
Tsinghua Microsoft sumber terbuka alat pemampatan perkataan segera baharu, panjangnya menurun sebanyak 80%! GitHub mendapat 3.1K bintang
Peranti teknologi
AI
Tsinghua Microsoft sumber terbuka alat pemampatan perkataan segera baharu, panjangnya menurun sebanyak 80%! GitHub mendapat 3.1K bintang
Tsinghua Microsoft sumber terbuka alat pemampatan perkataan segera baharu, panjangnya menurun sebanyak 80%! GitHub mendapat 3.1K bintang

Dalam pemprosesan bahasa semula jadi, banyak maklumat sebenarnya diulang.
Jika perkataan gesaan boleh dimampatkan dengan berkesan, ia sama dengan mengembangkan panjang konteks yang disokong oleh model sedikit sebanyak.
Kaedah entropi maklumat sedia ada mengurangkan lebihan ini dengan mengalih keluar perkataan atau frasa tertentu.
Walau bagaimanapun, pengiraan berdasarkan entropi maklumat hanya meliputi konteks sehala teks dan mungkin mengabaikan maklumat penting yang diperlukan untuk pemampatan tambahan pula, kaedah pengiraan entropi maklumat tidak sepenuhnya konsisten dengan tujuan sebenar memampatkan segera perkataan.
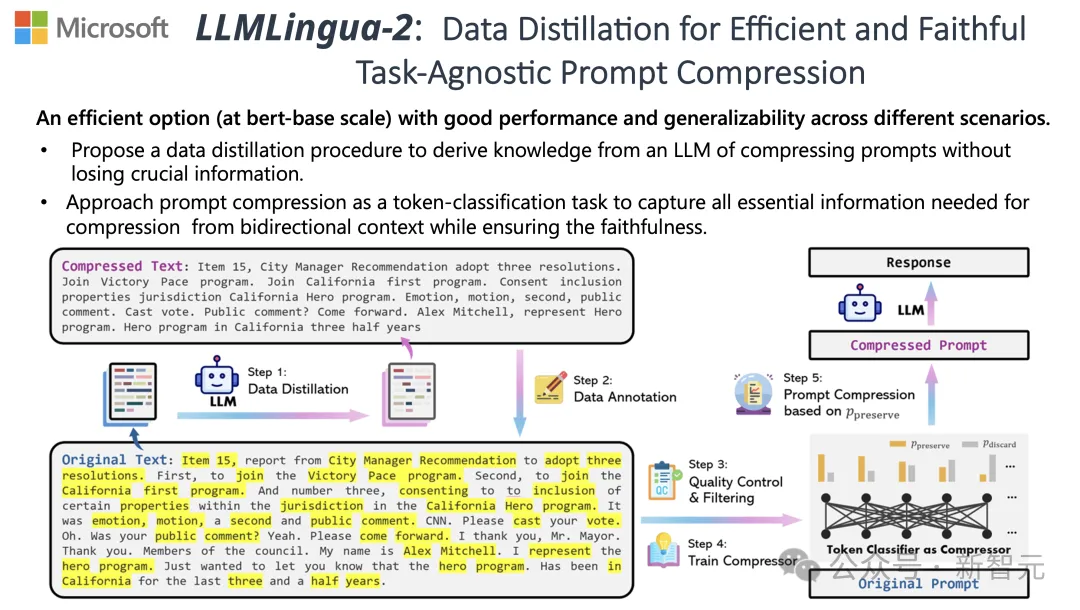
Untuk menghadapi cabaran ini, penyelidik dari Universiti Tsinghua dan Microsoft bersama-sama mencadangkan proses pemprosesan data baharu yang dipanggil LLMLingua-2. Ia bertujuan untuk mengekstrak pengetahuan daripada model bahasa besar (LLM) dan mencapai pemurnian maklumat dengan memampatkan perkataan segera sambil memastikan maklumat penting tidak hilang.
Projek ini telah memperoleh 3.1k bintang di GitHub
Hasilnya menunjukkan bahawa LLMLingua-2 boleh mengurangkan panjang teks dengan ketara kepada 20%, dengan berkesan mengurangkan masa dan kos pemprosesan.
Selain itu, kelajuan pemprosesan LLMLingua 2 meningkat 3 hingga 6 kali ganda berbanding versi LLMLingua sebelumnya dan teknologi lain yang serupa.

Alamat kertas: https://arxiv.org/abs/2403.12968
Dalam proses ini, teks asal dimasukkan pertama ke dalam model.
Model akan menilai kepentingan setiap perkataan dan memutuskan sama ada untuk mengekalkan atau memadamkannya, di samping mengambil kira hubungan antara perkataan.
Akhir sekali, model akan memilih perkataan yang mempunyai markah tertinggi untuk membentuk perkataan gesaan yang lebih pendek.
Pasukan menguji model LLMLingua-2 pada berbilang set data termasuk MeetingBank, LongBench, ZeroScrolls, GSM8K dan BBH.
Walaupun model ini bersaiz kecil, ia mencapai peningkatan prestasi yang ketara dalam ujian penanda aras dan membuktikan prestasinya dalam model bahasa besar yang berbeza (dari GPT-3.5 hingga Mistral-7B) dan bahasa (dari bahasa Inggeris kepada bahasa Cina) mempunyai keupayaan generalisasi yang sangat baik. .
Petua Pengguna:
Sila mampatkan teks yang diberikan menjadi ungkapan pendek supaya anda (GPT-4) boleh memulihkan teks asal setepat mungkin. Berbeza daripada pemampatan teks biasa, saya memerlukan anda mengikut lima syarat berikut:
1 Hanya keluarkan perkataan yang tidak penting itu. 2. Pastikan susunan perkataan asal tidak berubah.
3. Pastikan perbendaharaan kata asal tidak berubah.
4. Jangan gunakan sebarang singkatan atau emotikon.
5. Jangan tambah sebarang perkataan atau simbol baharu.
Sila mampatkan teks asal sebanyak mungkin sambil mengekalkan sebanyak mungkin maklumat. Jika anda faham, sila mampatkan teks berikut: {Teks untuk dimampatkan}
Teks yang dimampatkan ialah: [...]
Hasilnya menunjukkan bahawa dalam Soal Jawab, penulisan abstrak dan penaakulan logik Dalam pelbagai tugas bahasa, LLMLlingua-2 dengan ketara mengatasi model LLMLingua asal dan strategi konteks terpilih yang lain.
Perlu dinyatakan bahawa kaedah pemampatan ini sama-sama berkesan untuk model bahasa besar yang berbeza (dari GPT-3.5 hingga Mistral-7B) dan bahasa yang berbeza (dari bahasa Inggeris ke bahasa Cina).
Selain itu, penggunaan LLMLingua-2 boleh dicapai dengan hanya dua baris kod.
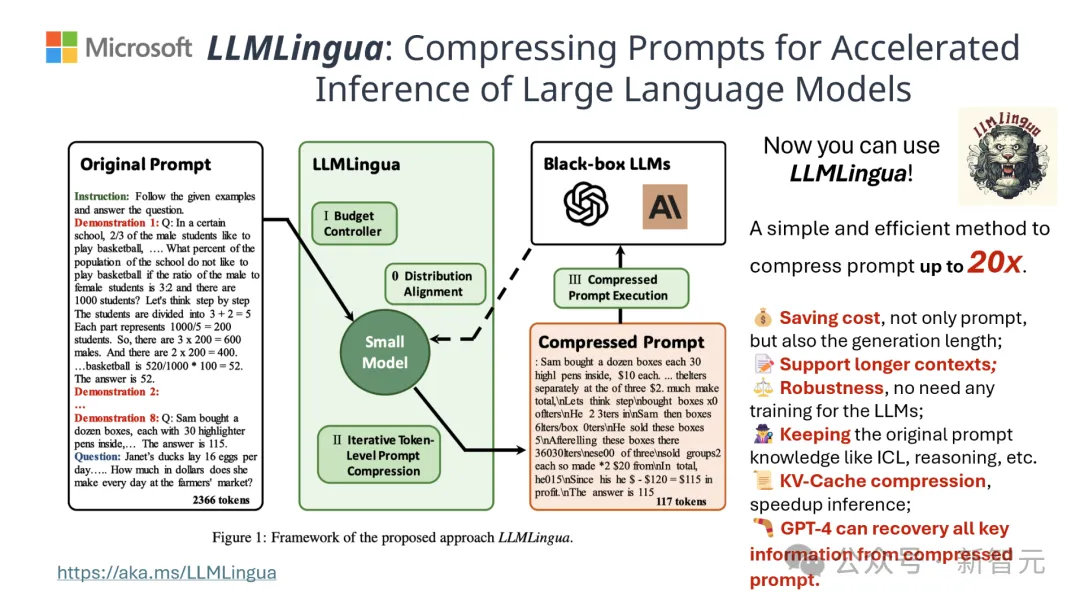
Pada masa ini, model itu telah disepadukan ke dalam rangka kerja RAG LangChain dan LlamaIndex yang digunakan secara meluas.
Kaedah pelaksanaan
Untuk mengatasi masalah yang dihadapi oleh kaedah pemampatan teks berasaskan entropi maklumat sedia ada, LLMLingua-2 mengamalkan strategi pengekstrakan data yang inovatif.
Strategi ini mencapai pemampatan teks yang cekap tanpa kehilangan kandungan utama dan mengelakkan penambahan maklumat yang salah dengan mengekstrak maklumat penting daripada model bahasa besar seperti GPT-4.
Petua Reka Bentuk
Untuk menggunakan sepenuhnya potensi pemampatan teks GPT-4, kuncinya terletak pada cara menetapkan arahan pemampatan yang tepat.
Iaitu, semasa memampatkan teks, arahkan GPT-4 untuk hanya mengalih keluar perkataan yang kurang penting dalam teks asal, sambil mengelakkan pengenalan mana-mana perkataan baharu dalam proses.
Tujuan ini adalah untuk memastikan teks yang dimampatkan mengekalkan keaslian dan integriti teks asal sebanyak mungkin.

Anotasi dan Penapisan
Penyelidik telah membangunkan algoritma anotasi data novel menggunakan pengetahuan yang diekstrak daripada model bahasa besar seperti GPT-4.
Algoritma ini boleh melabelkan setiap perkataan dalam teks asal dan dengan jelas menunjukkan perkataan yang mesti dikekalkan semasa proses pemampatan.
Untuk memastikan kualiti tinggi set data yang dibina, mereka juga mereka bentuk dua mekanisme pemantauan kualiti khusus untuk mengenal pasti dan menghapuskan sampel data yang berkualiti rendah.

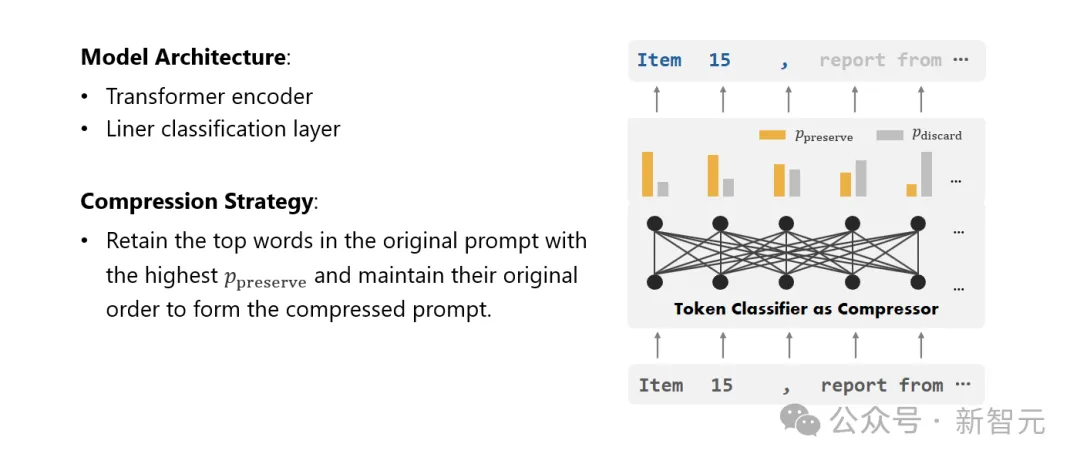
Compressor
Akhir sekali, penyelidik mengubah masalah pemampatan teks menjadi tugas mengklasifikasikan setiap perbendaharaan kata (Token) dan menggunakan Transformer yang berkuasa sebagai ekstrak ciri.
Alat ini memahami konteks teks untuk menangkap maklumat yang penting untuk pemampatan teks dengan tepat.
Dengan melatih set data yang dibina dengan teliti, model penyelidik dapat mengira nilai kebarangkalian berdasarkan kepentingan setiap perkataan untuk memutuskan sama ada perkataan itu harus dikekalkan dalam teks mampat terakhir atau harus ditinggalkan.
Penilaian Prestasi
Para penyelidik menguji prestasi LLMLingua-2 pada pelbagai tugas, termasuk pembelajaran konteks, ringkasan teks, penjanaan dialog, soal jawab penjanaan berbilang dan dokumen tunggal, dan soal jawab. Tugas sintesis termasuk kedua-dua set data dalam domain dan set data luar domain.
Keputusan ujian menunjukkan bahawa kaedah penyelidik mengurangkan kehilangan prestasi minimum sambil mengekalkan prestasi tinggi, dan berprestasi cemerlang dalam kalangan kaedah pemampatan teks tidak khusus tugasan.
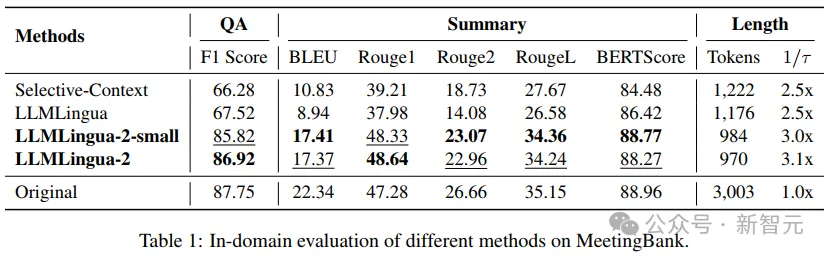
- Ujian dalam domain (MeetingBank)
Para penyelidik membandingkan prestasi LLMLingua-2 pada ujian MeetingBank yang ditetapkan dengan kaedah asas lain yang berkuasa.
Walaupun saiz model mereka jauh lebih kecil daripada LLaMa-2-7B yang digunakan dalam garis dasar, pada tugas menjawab soalan dan ringkasan teks, kaedah penyelidik bukan sahaja meningkatkan prestasi dengan ketara, tetapi juga dilakukan hampir seperti serta gesaan teks asal.
- Ujian di luar domain (LongBench, GSM8K dan BBH)
Memandangkan para penyelidik menggunakan data yang direkodkan hanya dilatih dalam mesyuarat Mesej. dalam keupayaan Generalisasi dalam senario yang berbeza seperti teks panjang, penaakulan logik dan pembelajaran kontekstual.
Perlu dinyatakan bahawa walaupun LLMLlingua-2 hanya dilatih pada satu set data, dalam ujian di luar domain, prestasinya bukan sahaja setanding dengan kaedah pemampatan tidak spesifik tugas terkini, malah dalam beberapa kes Lebih teruk lagi.
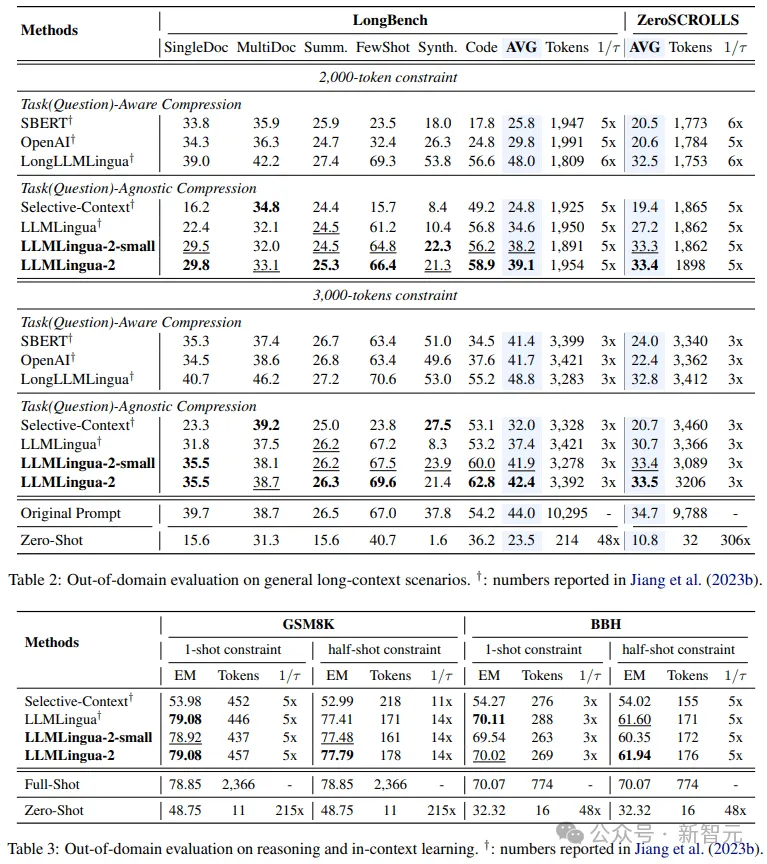
Malah model penyelidik yang lebih kecil (saiz asas BERT) mampu mencapai prestasi yang setanding dengan, dan dalam beberapa kes malah lebih baik sedikit daripada petunjuk asal.
Walaupun pendekatan penyelidik mencapai hasil yang memberangsangkan, ia masih mempunyai kelemahan jika dibandingkan dengan kaedah pemampatan sedar tugas lain seperti LongLLMlingua di Longbench.
Para penyelidik mengaitkan jurang prestasi ini kepada maklumat tambahan yang mereka peroleh daripada masalah tersebut. Walau bagaimanapun, model penyelidik adalah agnostik tugas, menjadikannya pilihan yang cekap dengan kebolehgeneralisasian yang baik apabila digunakan dalam senario yang berbeza.
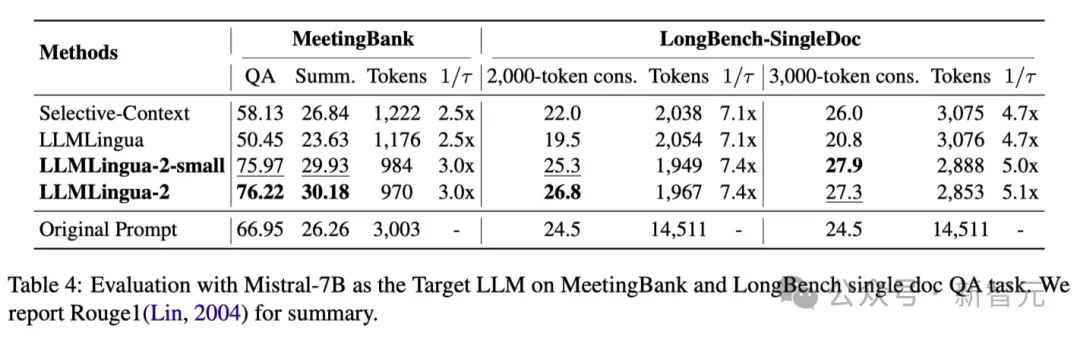
Jadual 4 di atas menyenaraikan keputusan kaedah berbeza menggunakan Mistral-7Bv0.1 4 sebagai LLM sasaran.
Berbanding dengan kaedah asas yang lain, kaedah penyelidik mempunyai peningkatan yang ketara dalam prestasi, menunjukkan keupayaan generalisasi yang baik pada LLM sasaran.
Perlu diperhatikan bahawa LLMLingua-2 berprestasi lebih baik daripada gesaan asal.
Penyelidik membuat spekulasi bahawa Mistral-7B mungkin tidak pandai mengurus konteks panjang seperti GPT-3.5-Turbo.
Pendekatan penyelidik secara berkesan meningkatkan prestasi inferens akhir Mistral7B dengan memberikan petunjuk ringkas dengan kepadatan maklumat yang lebih tinggi.
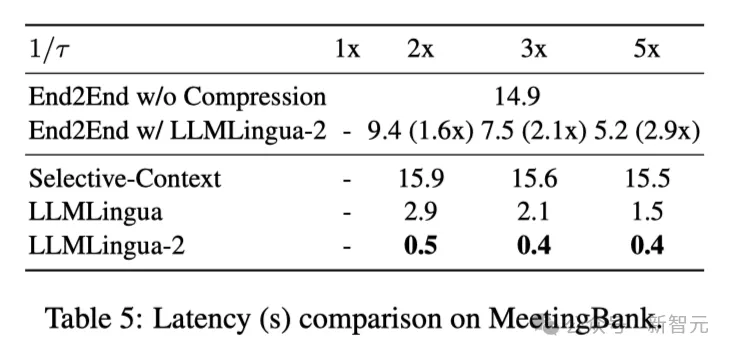
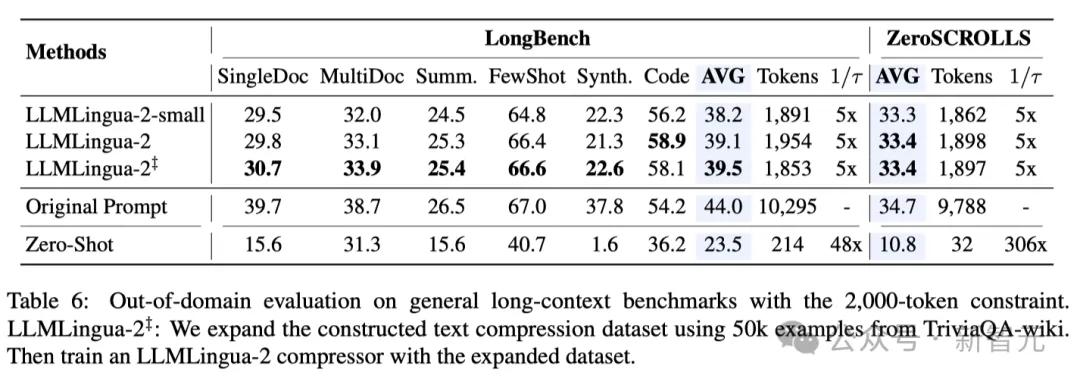
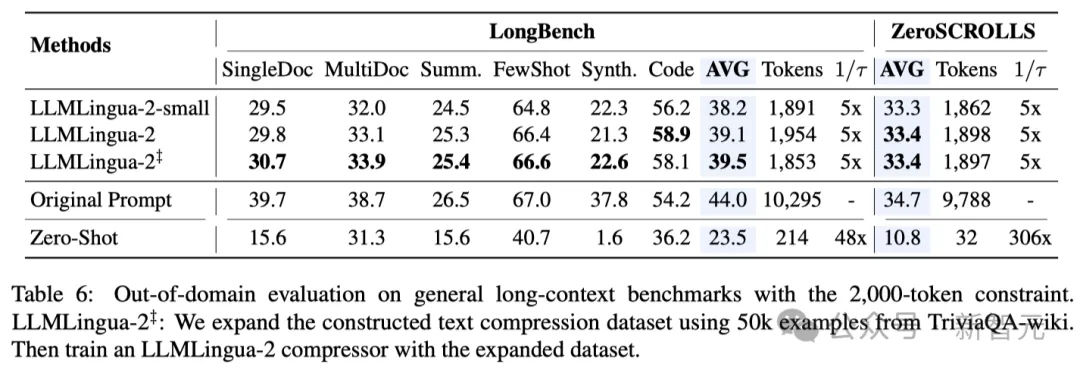
Jadual 5 di atas menunjukkan kependaman sistem berbeza pada GPU V100-32G dengan nisbah mampatan berbeza.
Hasilnya menunjukkan bahawa berbanding dengan kaedah pemampatan lain, LLMLingua2 mempunyai lebih sedikit overhed pengiraan dan boleh mencapai peningkatan kelajuan hujung ke hujung sebanyak 1.6x hingga 2.9x.
Di samping itu, kaedah penyelidik boleh mengurangkan kos memori GPU sebanyak 8 kali ganda, sekali gus mengurangkan permintaan untuk sumber perkakasan.
Pemerhatian Sedar Konteks Para penyelidik memerhatikan bahawa apabila nisbah mampatan meningkat, LLMLingua-2 boleh mengekalkan perkataan yang paling bermaklumat dengan konteks yang lengkap dengan berkesan.
Ini adalah terima kasih kepada penggunaan pengekstrak ciri peka konteks dua arah dan strategi yang mengoptimumkan secara eksplisit ke arah matlamat pemampatan tepat pada masanya.
Para penyelidik memerhatikan bahawa apabila nisbah mampatan meningkat, LLMLingua-2 boleh mengekalkan perkataan paling bermaklumat yang berkaitan dengan konteks lengkap dengan berkesan.
Ini adalah terima kasih kepada penggunaan pengekstrak ciri peka konteks dua hala dan strategi yang secara eksplisit mengoptimumkan ke arah matlamat pemampatan tepat pada masanya.
Akhirnya, penyelidik meminta GPT-4 untuk membina semula nada asal daripada pembayang mampatan LLMLlingua-2.
Hasilnya menunjukkan bahawa GPT-4 boleh membina semula petua asal dengan berkesan, menunjukkan bahawa tiada maklumat penting hilang semasa proses pemampatan LLMLingua-2.
Atas ialah kandungan terperinci Tsinghua Microsoft sumber terbuka alat pemampatan perkataan segera baharu, panjangnya menurun sebanyak 80%! GitHub mendapat 3.1K bintang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Alamat masuk versi antarabangsa Microsoft bing (pintu masuk enjin carian bing)
Mar 14, 2024 pm 01:37 PM
Alamat masuk versi antarabangsa Microsoft bing (pintu masuk enjin carian bing)
Mar 14, 2024 pm 01:37 PM
Bing ialah enjin carian dalam talian yang dilancarkan oleh Microsoft Fungsi carian sangat berkuasa dan mempunyai dua pintu masuk: versi domestik dan versi antarabangsa. Di manakah pintu masuk ke dua versi ini? Bagaimana untuk mengakses versi antarabangsa? Mari kita lihat butiran di bawah. Pintu masuk laman web versi Cina Bing: https://cn.bing.com/ Pintu masuk laman web versi antarabangsa Bing: https://global.bing.com/ Bagaimana untuk mengakses versi antarabangsa Bing? 1. Mula-mula masukkan URL untuk membuka Bing: https://www.bing.com/ 2. Anda boleh melihat bahawa terdapat pilihan untuk versi domestik dan antarabangsa Kami hanya perlu memilih versi antarabangsa dan masukkan kata kunci.
 Pop timbul skrin penuh Microsoft menggesa pengguna Windows 10 untuk menyegerakan dan menaik taraf kepada Windows 11
Jun 06, 2024 am 11:35 AM
Pop timbul skrin penuh Microsoft menggesa pengguna Windows 10 untuk menyegerakan dan menaik taraf kepada Windows 11
Jun 06, 2024 am 11:35 AM
Menurut berita pada 3 Jun, Microsoft sedang aktif menghantar pemberitahuan skrin penuh kepada semua pengguna Windows 10 untuk menggalakkan mereka menaik taraf kepada sistem pengendalian Windows 11. Langkah ini melibatkan peranti yang konfigurasi perkakasannya tidak menyokong sistem baharu. Sejak 2015, Windows 10 telah menduduki hampir 70% bahagian pasaran, dengan kukuh mengukuhkan penguasaannya sebagai sistem pengendalian Windows. Walau bagaimanapun, bahagian pasaran jauh melebihi bahagian pasaran 82%, dan bahagian pasaran jauh melebihi Windows 11, yang akan dikeluarkan pada 2021. Walaupun Windows 11 telah dilancarkan selama hampir tiga tahun, penembusan pasarannya masih perlahan. Microsoft telah mengumumkan bahawa ia akan menamatkan sokongan teknikal untuk Windows 10 selepas 14 Oktober 2025 untuk memberi tumpuan lebih kepada
 Microsoft mengeluarkan kemas kini kumulatif Win11 Ogos: meningkatkan keselamatan, mengoptimumkan skrin kunci, dsb.
Aug 14, 2024 am 10:39 AM
Microsoft mengeluarkan kemas kini kumulatif Win11 Ogos: meningkatkan keselamatan, mengoptimumkan skrin kunci, dsb.
Aug 14, 2024 am 10:39 AM
Menurut berita dari tapak ini pada 14 Ogos, semasa hari acara August Patch Tuesday hari ini, Microsoft mengeluarkan kemas kini kumulatif untuk sistem Windows 11, termasuk kemas kini KB5041585 untuk 22H2 dan 23H2, dan kemas kini KB5041592 untuk 21H2. Selepas peralatan yang disebutkan di atas dipasang dengan kemas kini kumulatif Ogos, perubahan nombor versi yang dilampirkan pada tapak ini adalah seperti berikut: Selepas pemasangan peralatan 21H2, nombor versi meningkat kepada Build22000.314722H2 Selepas pemasangan peralatan, nombor versi meningkat kepada Build22621.403723H2 Selepas pemasangan peralatan, nombor versi meningkat kepada Build22631.4037 Kandungan utama kemas kini KB5041585 untuk Windows 1121H2 adalah seperti berikut: Penambahbaikan.
 Peningkatan Microsoft Edge: Fungsi penjimatan kata laluan automatik diharamkan? ! Pengguna terkejut!
Apr 19, 2024 am 08:13 AM
Peningkatan Microsoft Edge: Fungsi penjimatan kata laluan automatik diharamkan? ! Pengguna terkejut!
Apr 19, 2024 am 08:13 AM
Berita pada 18 April: Baru-baru ini, beberapa pengguna pelayar Microsoft Edge menggunakan saluran Canary melaporkan bahawa selepas menaik taraf kepada versi terkini, mereka mendapati bahawa pilihan untuk menyimpan kata laluan secara automatik telah dilumpuhkan. Selepas penyiasatan, didapati bahawa ini adalah pelarasan kecil selepas naik taraf penyemak imbas, bukannya pembatalan fungsi. Sebelum menggunakan penyemak imbas Edge untuk mengakses laman web, pengguna melaporkan bahawa penyemak imbas akan muncul tetingkap bertanya sama ada mereka mahu menyimpan kata laluan log masuk untuk tapak web tersebut. Selepas memilih untuk menyimpan, Edge secara automatik akan mengisi akaun dan kata laluan yang disimpan apabila anda log masuk seterusnya, memberikan pengguna kemudahan yang hebat. Tetapi kemas kini terkini menyerupai tweak, menukar tetapan lalai. Pengguna perlu memilih untuk menyimpan kata laluan dan kemudian menghidupkan pengisian automatik akaun yang disimpan dan kata laluan dalam tetapan.
 Fungsi Microsoft Win11 untuk memampatkan fail 7z dan TAR telah diturunkan daripada versi 24H2 kepada 23H2/22H2
Apr 28, 2024 am 09:19 AM
Fungsi Microsoft Win11 untuk memampatkan fail 7z dan TAR telah diturunkan daripada versi 24H2 kepada 23H2/22H2
Apr 28, 2024 am 09:19 AM
Menurut berita dari laman web ini pada 27 April, Microsoft mengeluarkan kemas kini versi pratonton Windows 11 Build 26100 ke saluran Canary dan Dev awal bulan ini, yang dijangka menjadi calon versi RTM bagi kemas kini Windows 1124H2. Perubahan utama dalam versi baharu ialah peneroka fail, penyepaduan Copilot, penyuntingan metadata fail PNG, penciptaan fail termampat TAR dan 7z, dsb. @PhantomOfEarth mendapati bahawa Microsoft telah menurunkan beberapa fungsi versi 24H2 (Germanium) kepada versi 23H2/22H2 (Nikel), seperti mencipta fail mampat TAR dan 7z. Seperti yang ditunjukkan dalam rajah, Windows 11 akan menyokong penciptaan asli TAR
 Kemas kini pelayar Microsoft Edge: Menambah fungsi 'zum dalam imej' untuk meningkatkan pengalaman pengguna
Mar 21, 2024 pm 01:40 PM
Kemas kini pelayar Microsoft Edge: Menambah fungsi 'zum dalam imej' untuk meningkatkan pengalaman pengguna
Mar 21, 2024 pm 01:40 PM
Menurut berita pada 21 Mac, Microsoft baru-baru ini mengemas kini pelayar Microsoft Edge dan menambah fungsi "besarkan imej" praktikal. Kini, apabila menggunakan pelayar Edge, pengguna boleh mencari ciri baharu ini dengan mudah dalam menu pop timbul dengan hanya mengklik kanan pada imej. Apa yang lebih mudah ialah pengguna juga boleh menuding kursor pada imej dan kemudian klik dua kali kekunci Ctrl untuk menggunakan fungsi mengezum masuk dengan cepat pada imej. Mengikut pemahaman editor, pelayar Microsoft Edge yang baru dikeluarkan telah diuji untuk ciri-ciri baru dalam saluran Canary. Versi pelayar yang stabil juga secara rasminya telah melancarkan fungsi "besarkan imej" praktikal, memberikan pengguna pengalaman menyemak imbas imej yang lebih mudah. Media sains dan teknologi asing turut memberi perhatian kepada perkara ini
 Microsoft merancang untuk menghapuskan NTLM secara berperingkat dalam Windows 11 pada separuh kedua 2024 dan beralih sepenuhnya kepada pengesahan Kerberos
Jun 09, 2024 pm 04:17 PM
Microsoft merancang untuk menghapuskan NTLM secara berperingkat dalam Windows 11 pada separuh kedua 2024 dan beralih sepenuhnya kepada pengesahan Kerberos
Jun 09, 2024 pm 04:17 PM
Pada separuh kedua 2024, Blog Keselamatan Microsoft rasmi menerbitkan mesej sebagai respons kepada panggilan daripada komuniti keselamatan. Syarikat itu merancang untuk menghapuskan protokol pengesahan Pengurus NTLAN (NTLM) dalam Windows 11, dikeluarkan pada separuh kedua 2024, untuk meningkatkan keselamatan. Menurut penjelasan sebelum ini, Microsoft telah pun membuat langkah serupa sebelum ini. Pada 12 Oktober tahun lepas, Microsoft mencadangkan pelan peralihan dalam siaran akhbar rasmi yang bertujuan untuk menghapuskan kaedah pengesahan NTLM secara berperingkat dan mendorong lebih banyak perusahaan dan pengguna beralih kepada Kerberos. Untuk membantu perusahaan yang mungkin mengalami masalah dengan aplikasi dan perkhidmatan berwayar tegar selepas mematikan pengesahan NTLM, Microsoft menyediakan IAKerb dan
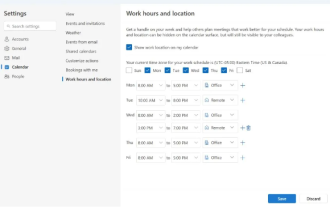 Microsoft melancarkan versi baharu Outlook untuk Windows: peningkatan komprehensif fungsi kalendar
Apr 27, 2024 pm 03:44 PM
Microsoft melancarkan versi baharu Outlook untuk Windows: peningkatan komprehensif fungsi kalendar
Apr 27, 2024 pm 03:44 PM
Dalam berita pada 27 April, Microsoft mengumumkan bahawa ia tidak lama lagi akan mengeluarkan ujian versi baharu klien Outlook untuk Windows. Kemas kini ini tertumpu terutamanya pada mengoptimumkan fungsi kalendar, bertujuan untuk meningkatkan kecekapan kerja pengguna dan memudahkan lagi aliran kerja harian. Penambahbaikan versi baharu klien Outlook untuk Windows terletak pada fungsi pengurusan kalendarnya yang lebih berkuasa. Kini, pengguna boleh berkongsi maklumat masa kerja dan lokasi peribadi dengan lebih mudah, menjadikan perancangan mesyuarat lebih cekap. Selain itu, Outlook juga telah menambah tetapan mesra pengguna, membolehkan pengguna menetapkan mesyuarat untuk tamat awal secara automatik atau bermula kemudian, memberikan pengguna lebih fleksibiliti, sama ada mereka ingin menukar bilik mesyuarat, berehat atau menikmati secawan kopi . mengikut
