

Mamba Masa sudah tiba?
Seni bina transformer telah mendominasi bidang kecerdasan buatan generatif sejak penerbitan kertas penyelidikan terobosan "Attention is All You Need" pada 2017.
Walau bagaimanapun, seni bina transformer sebenarnya mempunyai dua kelemahan yang ketara:
Jejak memori Transformer berbeza mengikut panjang konteks. Ini menjadikan ia mencabar untuk menjalankan tetingkap konteks panjang atau pemprosesan selari besar-besaran tanpa sumber perkakasan yang ketara, sekali gus mengehadkan percubaan dan penggunaan yang meluas. Jejak memori model Transformer menskalakan dengan panjang konteks, menjadikannya sukar untuk menjalankan tetingkap konteks yang panjang atau pemprosesan yang sangat selari tanpa sumber perkakasan yang ketara, sekali gus mengehadkan percubaan dan penggunaan yang meluas.
Mekanisme perhatian dalam model Transformer akan melaraskan kelajuan mengikut pertambahan panjang konteks Mekanisme ini akan mengembangkan panjang jujukan secara rawak dan mengurangkan kos pengiraan, kerana setiap token bergantung pada keseluruhan jujukan sebelum itu, dengan itu. mengurangkan konteks Digunakan di luar skop pengeluaran yang cekap.
Transformer bukan satu-satunya jalan ke hadapan untuk pengeluaran kecerdasan buatan. Baru-baru ini, AI21 Labs melancarkan dan membuka sumber kaedah baharu yang dipanggil "Jamba" yang mengatasi pengubah pada berbilang penanda aras.

Alamat Muka Berpeluk: https://huggingface.co/ai21labs/Jamba-v0.1
Seni bina SSM Mamba boleh menyelesaikan masalah sumber memori dan konteks pengubah dengan baik. Walau bagaimanapun, pendekatan Mamba bergelut untuk menyediakan tahap output yang sama seperti model pengubah.
Jamba menggabungkan model Mamba berdasarkan Model Ruang Negeri Berstruktur (SSM) dengan seni bina transformer, bertujuan untuk menggabungkan sifat terbaik SSM dan transformer.

Jamba juga boleh diakses daripada katalog NVIDIA API sebagai perkhidmatan mikro inferens NVIDIA NIM, yang boleh digunakan oleh pembangun aplikasi perusahaan menggunakan platform perisian NVIDIA AI Enterprise.
Secara amnya, model Jamba mempunyai ciri-ciri berikut:
Model peringkat pengeluaran pertama berdasarkan Mamba, menggunakan seni bina hibrid SSM-Transformer
Berbanding dengan Mixtral 8x7B, konteks panjang. meningkat sebanyak 3 kali ganda;
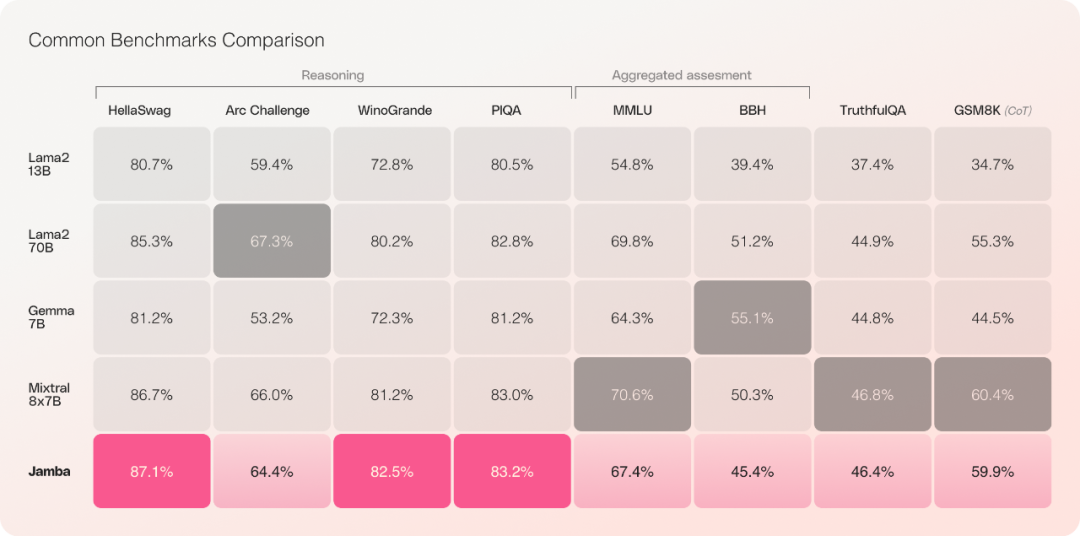
Seperti yang ditunjukkan dalam rajah di bawah, seni bina Jamba menggunakan pendekatan blok dan lapisan, membolehkan Jamba menyepadukan kedua-dua seni bina. Setiap blok Jamba terdiri daripada lapisan perhatian atau lapisan Mamba, diikuti oleh perceptron berbilang lapisan (MLP), membentuk lapisan pengubah.
Tiada siapa yang memanjangkan Mamba melebihi parameter 3B sebelum ini. Jamba ialah seni bina hibrid pertama seumpamanya yang mencapai skala pengeluaran.
Kelancaran dan Kecekapan
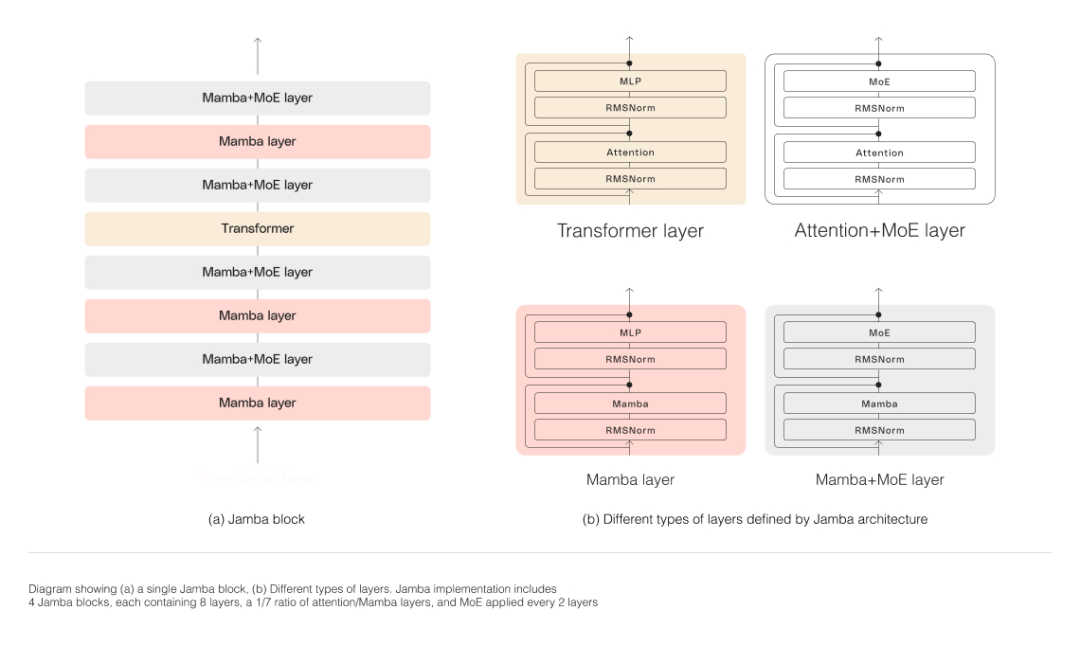 Eksperimen penilaian awal menunjukkan bahawa Jamba berprestasi baik pada metrik utama seperti pemprosesan dan kecekapan.
Eksperimen penilaian awal menunjukkan bahawa Jamba berprestasi baik pada metrik utama seperti pemprosesan dan kecekapan. Dari segi kecekapan, Jamba mencapai 3x daya pemprosesan Mixtral 8x7B pada konteks yang panjang. Jamba lebih cekap daripada model berasaskan Transformer bersaiz serupa seperti Mixtral 8x7B.
Dari segi kos, Jamba boleh menampung 140K konteks pada satu GPU. Jamba menawarkan lebih banyak peluang penggunaan dan percubaan daripada model sumber terbuka semasa yang lain dengan saiz yang sama.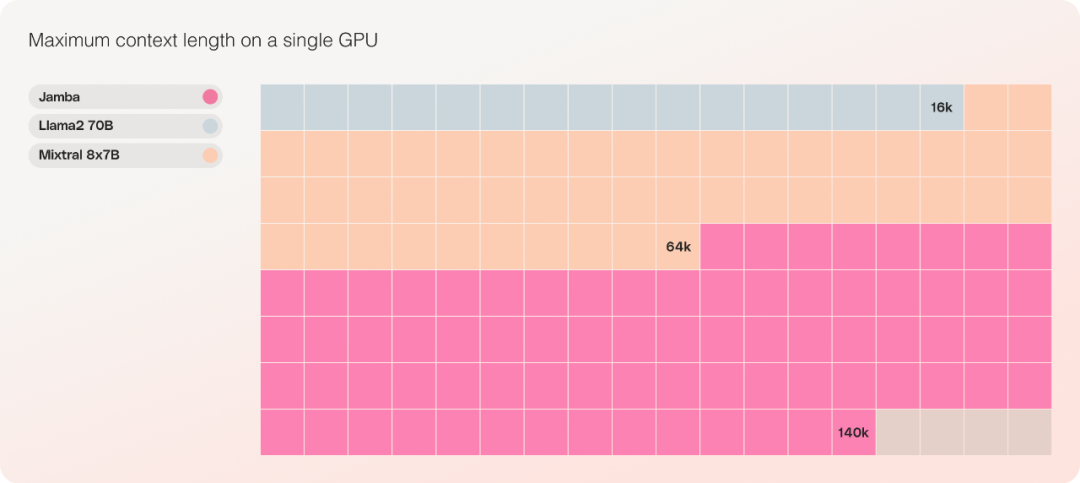
Perlu diingatkan bahawa Jamba pada masa ini tidak mungkin menggantikan model bahasa besar (LLM) berasaskan Transformer semasa, tetapi ia mungkin menjadi pelengkap dalam beberapa kawasan.
Pautan rujukan:
https://www.ai21.com/blog/announcing-jamba
-https://venturebeat.com/sup-jui21- gen-ai-transformers-with-jamba/
Atas ialah kandungan terperinci Perhatian bukan semua yang anda perlukan! Sumber terbuka model besar hibrid Mamba: daya pemprosesan tiga kali ganda Transformer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengubah suai nama fail secara kelompok
Bagaimana untuk mengubah suai nama fail secara kelompok
 apakah maksud unsur
apakah maksud unsur
 Cara menggunakan fungsi nilai
Cara menggunakan fungsi nilai
 Apakah sebab mengapa rangkaian tidak dapat disambungkan?
Apakah sebab mengapa rangkaian tidak dapat disambungkan?
 Ungkapan yang biasa digunakan dalam php
Ungkapan yang biasa digunakan dalam php
 Adakah python bahagian hadapan atau belakang?
Adakah python bahagian hadapan atau belakang?
 photoshare.db
photoshare.db
 Platform dagangan Dogecoin
Platform dagangan Dogecoin
 Ringkasan pengetahuan asas java
Ringkasan pengetahuan asas java








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



