

Sebuah foto + video boleh menjadikan foto itu hidup!
Baru-baru ini, Champ, karya penjanaan penglihatan manusia yang boleh dikawal yang dikeluarkan bersama oleh Alibaba, Universiti Fudan dan Universiti Nanjing, telah menjadi popular di seluruh Internet. Model ini hanya bersumberkan terbuka selama 5 hari dan telah menerima 1k bintang di GitHub Ia telah menjadi sangat popular di Twitter, menarik sejumlah besar penulis blog untuk mencipta projek baharu, dan jumlah tontonan telah mencecah 300K.
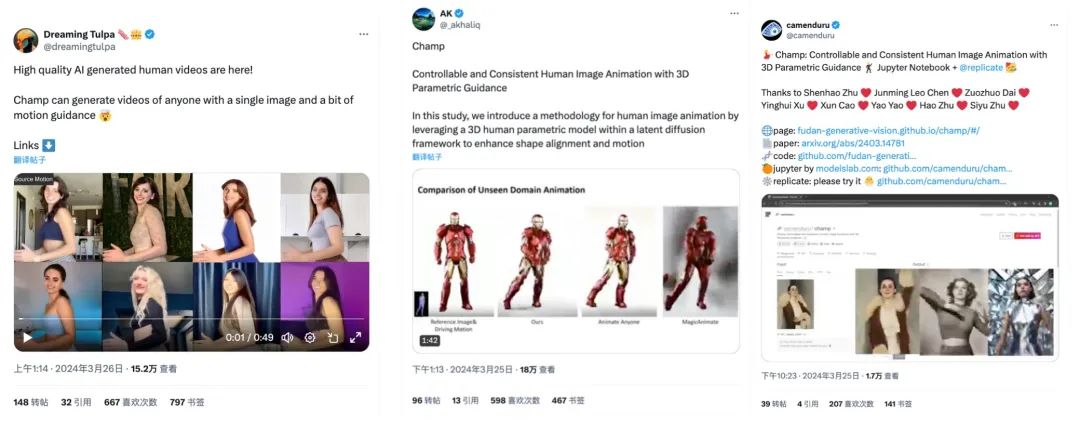
Pada masa ini, Champ telah membuka sumber kod inferens dan pemberat, dan pengguna boleh memuat turun dan menggunakannya terus daripada Github. Demo rasmi Memeluk Wajah telah dilancarkan, dan Champ-ComfyUI yang terkandung juga dipromosikan secara serentak. Halaman utama GitHub menunjukkan bahawa pasukan akan membuka sumber kod latihan dan set data dalam masa terdekat Rakan kongsi yang berminat boleh terus memberi perhatian kepada dinamik projek. 
Laman utama projek: https://fudan-generative-vision.github.io/champ/
Pautan kertas: https://arxiv.org/abs/2403.14781



Tinjauan Teknikal
Champ menggunakan model pemulihan jaringan manusia termaju untuk mengekstrak badan manusia tiga dimensi berparameter yang sepadan daripada input video badan manusia Urutan SMPL model mesh (Model Linear Berbilang Orang Berkulit) seterusnya menjadikan peta kedalaman yang sepadan, peta normal, postur manusia dan peta semantik manusia, yang digunakan sebagai keadaan kawalan gerakan yang sepadan untuk membimbing penjanaan video dan memindahkan tindakan kepada input Pada potret rujukan, ia boleh meningkatkan kualiti video pergerakan manusia dengan ketara, serta ketekalan geometri dan rupa.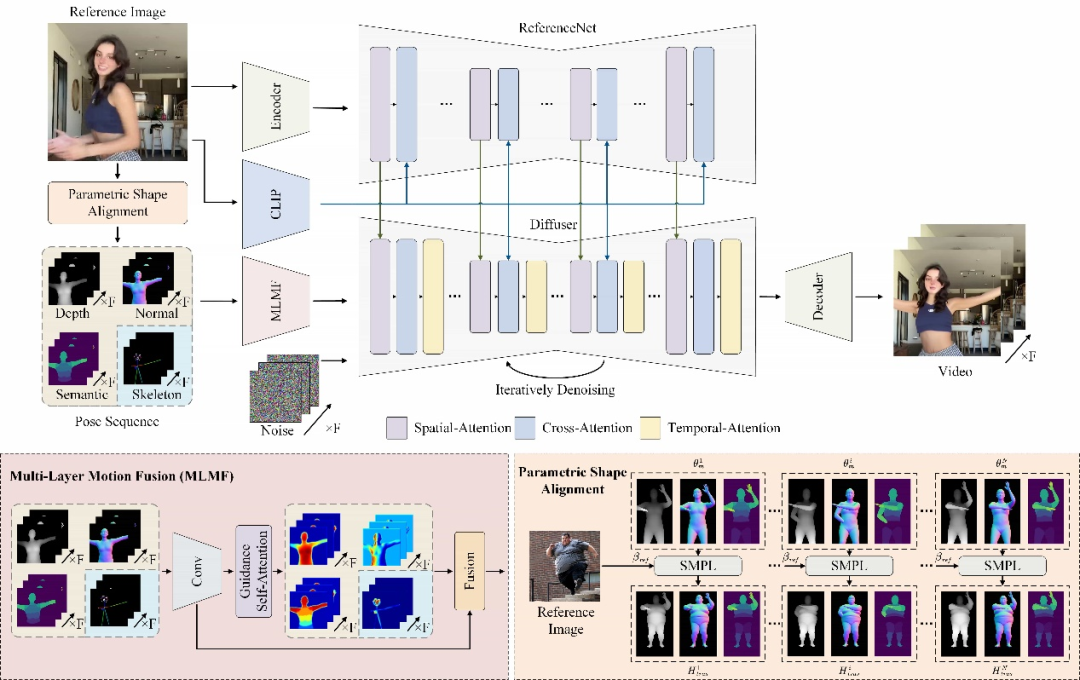
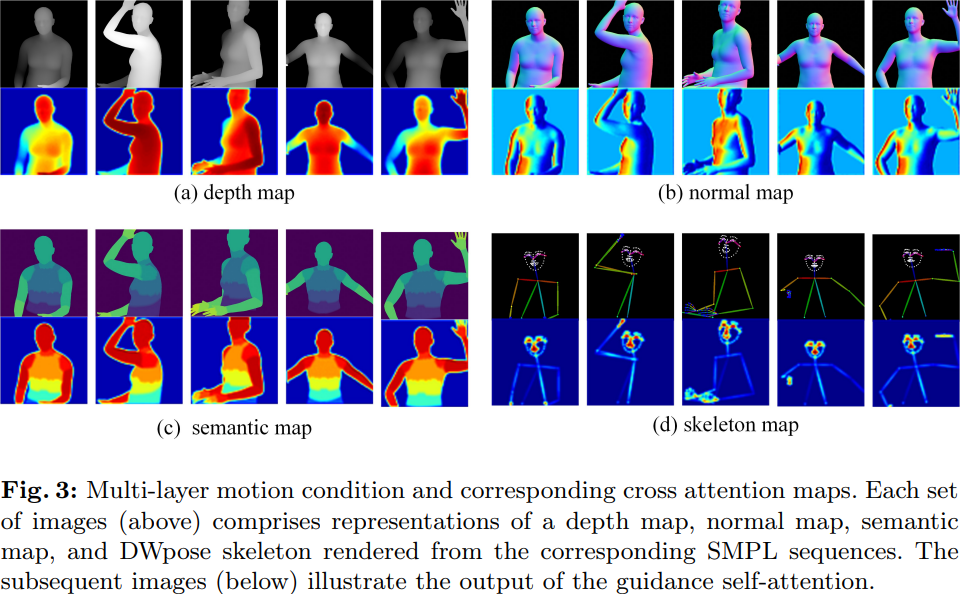

Hasil eksperimen
Seperti yang ditunjukkan dalam Jadual 4 di bawah, berbanding dengan kerja SOTA yang lain, Champ mempunyai kawalan pergerakan yang lebih baik dan lebih sedikit artifak:
Pada masa yang sama, Champ juga menunjukkan prestasi generalisasi yang unggul dan kestabilan dalam padanan penampilan:


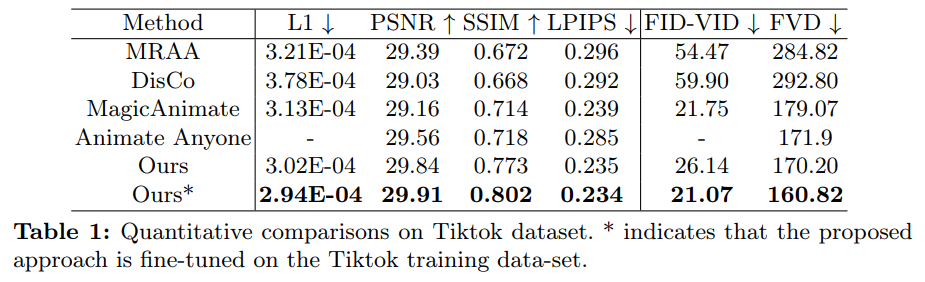
Untuk butiran lanjut teknikal dan hasil percubaan, sila rujuk kertas dan kod asal Champ Anda juga boleh pergi ke HuggingFace atau memuat turun kod sumber rasmi untuk pengalaman langsung.
Atas ialah kandungan terperinci Champ ialah sumber terbuka pertama: video badan manusia menjana SOTA baharu, memperoleh 1k bintang dalam masa 5 hari dan demo boleh dimainkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Tutorial membuat syiling bertulis
Tutorial membuat syiling bertulis
 Telefon tidak boleh bersambung ke set kepala Bluetooth
Telefon tidak boleh bersambung ke set kepala Bluetooth
 Penggunaan kompaun
Penggunaan kompaun
 vue arahan biasa
vue arahan biasa
 Apakah yang perlu saya lakukan jika msconfig tidak boleh dibuka?
Apakah yang perlu saya lakukan jika msconfig tidak boleh dibuka?
 Apakah perbezaan antara Douyin dan Douyin Express Edition?
Apakah perbezaan antara Douyin dan Douyin Express Edition?
 Perisian sistem pengurusan harta
Perisian sistem pengurusan harta
 Mengapa swole boleh bermastautin dalam ingatan?
Mengapa swole boleh bermastautin dalam ingatan?
 Ensiklopedia ChatGPT percuma domestik
Ensiklopedia ChatGPT percuma domestik








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



