
 Peranti teknologi
AI
DeepMind menamatkan ilusi model besar? Pelabelan fakta lebih dipercayai daripada manusia, 20 kali lebih murah, dan sumber terbuka sepenuhnya
Peranti teknologi
AI
DeepMind menamatkan ilusi model besar? Pelabelan fakta lebih dipercayai daripada manusia, 20 kali lebih murah, dan sumber terbuka sepenuhnya
DeepMind menamatkan ilusi model besar? Pelabelan fakta lebih dipercayai daripada manusia, 20 kali lebih murah, dan sumber terbuka sepenuhnya

Ilusi model besar akhirnya akan berakhir?
Hari ini, satu catatan di platform media sosial Reddit membangkitkan perbincangan hangat di kalangan netizen. Siaran itu membincangkan kertas kerja "Faktualiti bentuk panjang dalam model bahasa besar" yang diserahkan oleh Google DeepMind semalam. Kaedah dan hasil yang dicadangkan dalam artikel membuat orang membuat kesimpulan bahawa ilusi model bahasa besar tidak lagi menjadi masalah.

Kami tahu bahawa model bahasa yang besar sering menghasilkan kandungan yang mengandungi ralat fakta apabila menjawab soalan mencari fakta mengenai topik terbuka. DeepMind telah menjalankan beberapa penyelidikan penerokaan terhadap fenomena ini.
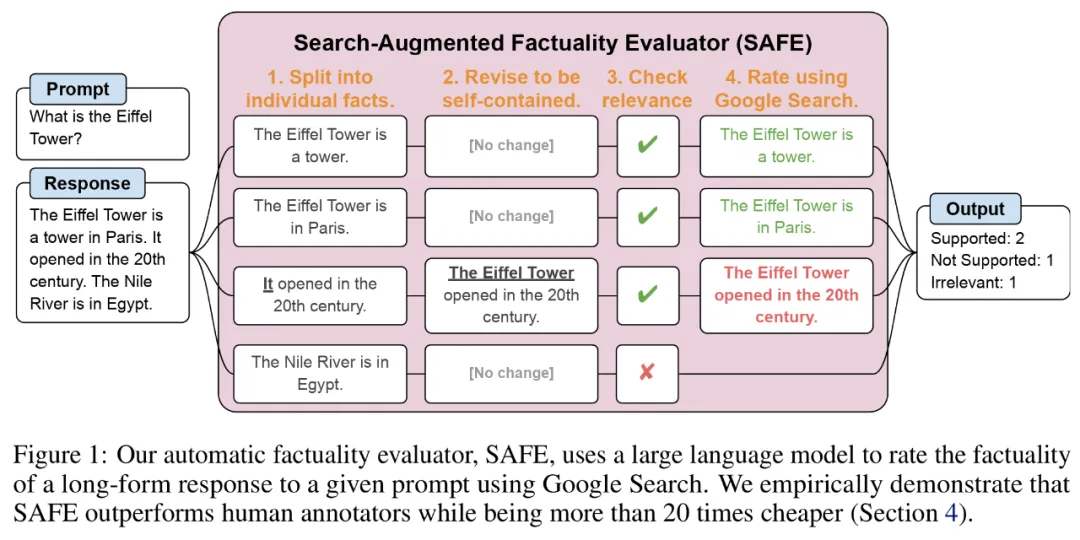
Untuk menanda aras fakta panjang model dalam domain terbuka, penyelidik menggunakan GPT-4 untuk menjana LongFact, set segera yang mengandungi 38 topik dan beribu-ribu soalan. Mereka kemudiannya mencadangkan menggunakan Penilai Fakta Ditambah Carian (SAFE) untuk menggunakan ejen LLM sebagai penilai automatik bagi fakta bentuk panjang. Tujuan SAFE adalah untuk meningkatkan ketepatan penilai kredibiliti fakta.
Berkenaan SELAMAT, menggunakan LLM boleh menerangkan ketepatan setiap kejadian dengan lebih tepat. Proses penaakulan berbilang langkah ini melibatkan penghantaran pertanyaan carian ke Carian Google dan menentukan sama ada hasil carian menyokong contoh tertentu.

Alamat kertas: https://arxiv.org/pdf/2403.18802.pdf
Alamat GitHub: https://github.com/google-deepmind/long-form-factuality Selain itu, penyelidik mencadangkan untuk memanjangkan skor F1 (F1@K) kepada penunjuk agregat praktikal bentuk panjang. Mereka mengimbangi peratusan fakta yang disokong dalam respons (ketepatan) dengan peratusan fakta yang diberikan berbanding hiperparameter yang mewakili panjang respons pilihan pengguna (ingat semula).
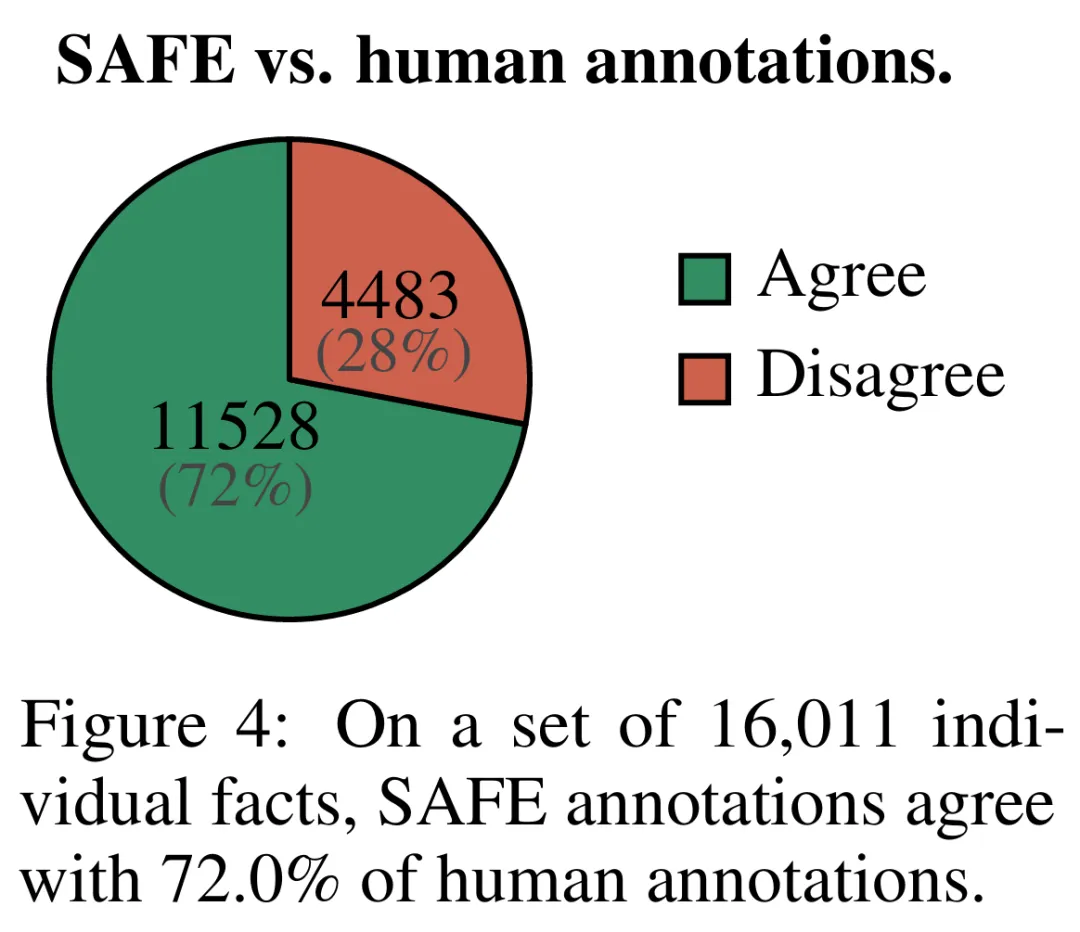
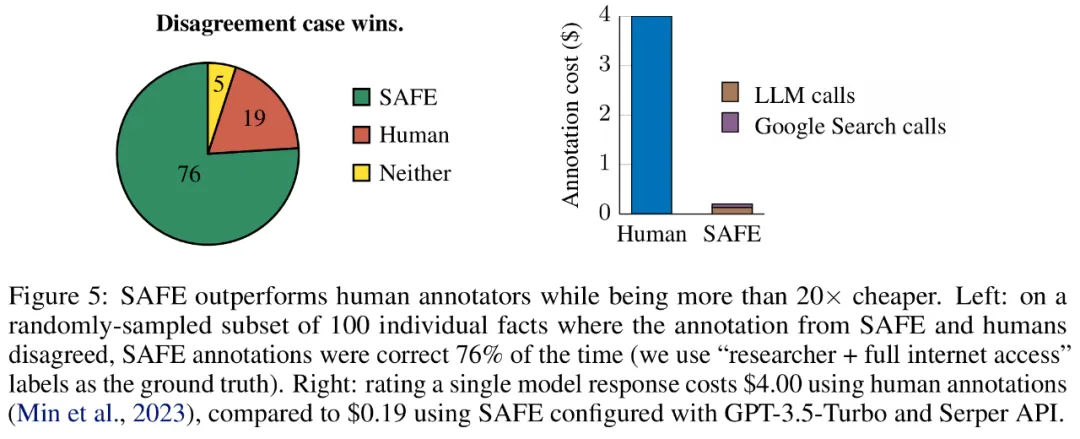
Hasil empirikal menunjukkan ejen LLM boleh mencapai prestasi penarafan yang melebihi manusia. Pada set ~16k fakta individu, SAFE bersetuju dengan anotasi manusia sebanyak 72% dan pada subset rawak 100 kes perselisihan faham, SAFE memenangi 76% pada setiap masa. Pada masa yang sama, SAFE adalah lebih daripada 20 kali lebih murah daripada anotasi manusia.
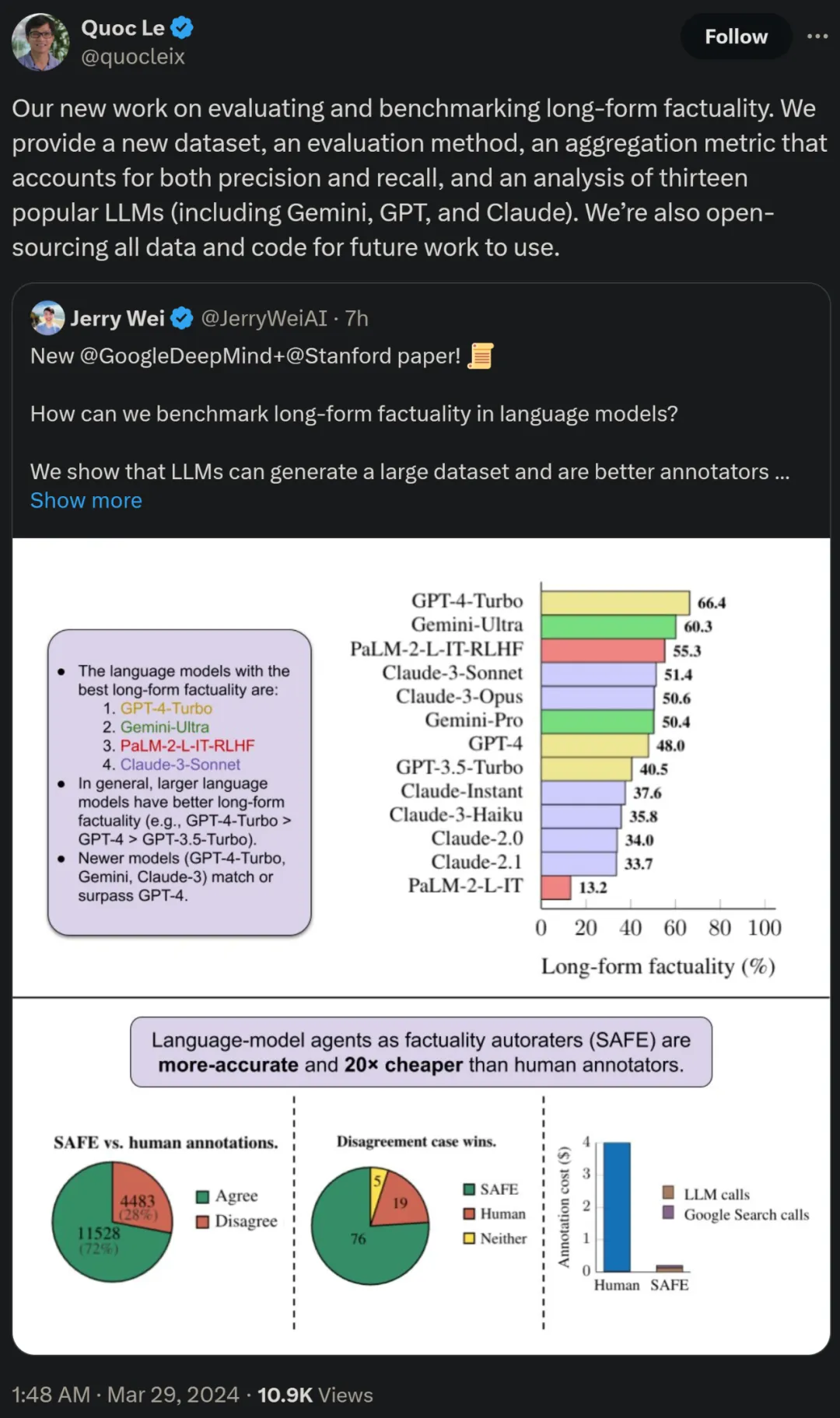
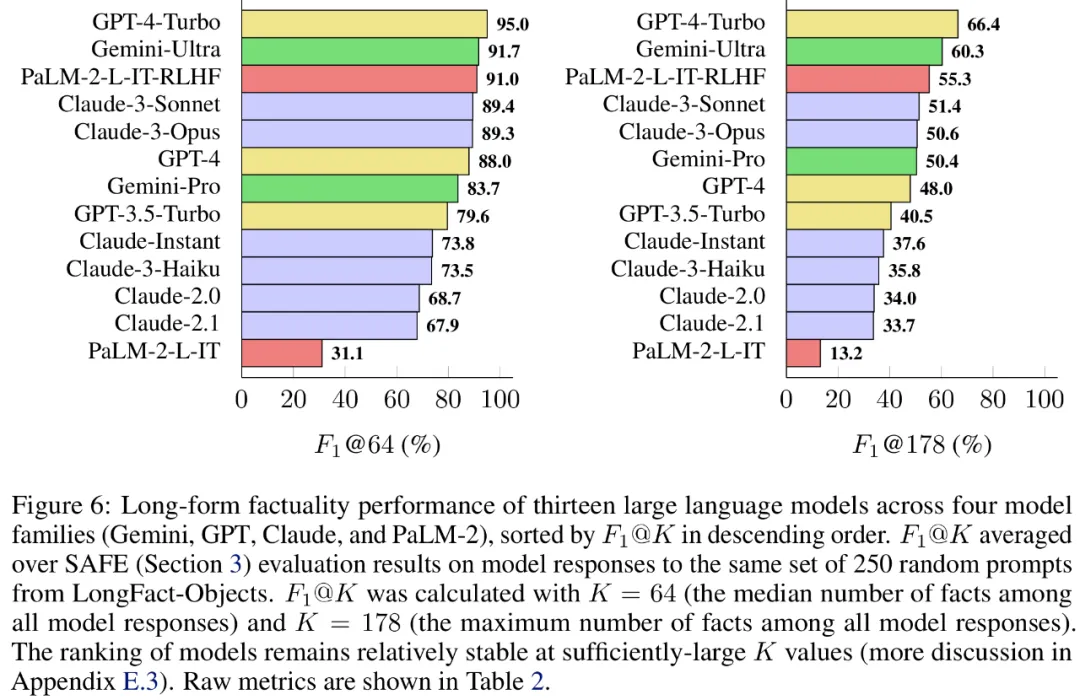
Para penyelidik juga menggunakan LongFact untuk menanda aras 13 model bahasa popular dalam empat siri model besar (Gemini, GPT, Claude dan PaLM-2), dan mendapati bahawa model bahasa yang lebih besar secara amnya boleh mencapai hasil yang lebih baik.
Quoc V. Le, salah seorang pengarang kertas kerja dan saintis penyelidikan di Google, berkata bahawa kerja baharu ini untuk menilai dan menanda aras kefaktaan bentuk panjang mencadangkan set data baharu, kaedah penilaian baharu dan kaedah yang mengimbangi ketepatan dan Metrik agregat ingat kembali. Pada masa yang sama, semua data dan kod akan menjadi sumber terbuka untuk kerja masa hadapan.
 method overview
method overview
longfact: Menggunakan llm untuk menghasilkan tanda aras multi-topik faktual yang panjang, terlebih dahulu melihat set longfact prompt yang dihasilkan menggunakan GPT-4, yang mengandungi 2280 fakta mencari yang memerlukan respons bentuk panjang merentas 38 topik yang dipilih secara manual. Para penyelidik mengatakan LongFact ialah set segera pertama untuk menilai faktual bentuk panjang dalam pelbagai bidang.
LongFact mengandungi dua tugas: LongFact-Concepts dan LongFact-Objects, dibezakan dengan sama ada soalan bertanya tentang konsep atau objek. Para penyelidik menjana 30 isyarat unik untuk setiap subjek, menghasilkan 1140 isyarat untuk setiap tugas.
SELAMAT: Ejen LLM sebagai penilai automatik fakta

Para penyelidik mencadangkan Penilai Fakta Ditambah Carian (SELAMAT), dan prinsip operasinya menyala jawapan panjang ke dalam fakta bebas yang berasingan;
b) Tentukan sama ada setiap fakta individu adalah relevan untuk menjawab gesaan dalam konteksc) Untuk setiap fakta yang berkaitan, keluarkan pertanyaan carian Google secara berulang dalam proses berbilang langkah dan sebabkan sama ada hasil carian menyokong fakta tersebut. Mereka percaya bahawa inovasi utama SAFE ialah menggunakan model bahasa sebagai ejen untuk menjana pertanyaan carian Google berbilang langkah dan membuat alasan dengan teliti sama ada hasil carian menyokong fakta. Rajah 3 di bawah menunjukkan contoh rantaian penaakulan. Untuk membahagikan respons yang panjang kepada fakta bebas yang berasingan, para penyelidik mula-mula menggesa model bahasa untuk membahagikan setiap ayat dalam respons yang panjang kepada fakta yang berasingan, dan kemudian mengarahkan model itu untuk memisahkan rujukan yang tidak jelas seperti kata ganti nama ) dengan entiti yang betul yang mereka rujuk dalam konteks tindak balas, mengubah suai setiap fakta individu menjadi bebas. Untuk menjaringkan setiap fakta bebas, mereka menggunakan model bahasa untuk membuat alasan sama ada fakta itu berkaitan dengan gesaan yang dijawab dalam konteks respons, dan kemudian menggunakan kaedah berbilang langkah untuk menilai setiap fakta relevan yang masih ada sebagai "disokong" atau "tidak disokong". Butirannya ditunjukkan dalam Rajah 1 di bawah. Pada setiap langkah, model menjana pertanyaan carian berdasarkan fakta yang akan dijaringkan dan hasil carian yang diperoleh sebelum ini. Selepas beberapa langkah tertentu, model melakukan inferens untuk menentukan sama ada hasil carian menyokong fakta tersebut, seperti yang ditunjukkan dalam Rajah 3 di atas. Selepas semua fakta dinilai, metrik keluaran SAFE untuk pasangan tindak balas segera adalah bilangan fakta "sokongan", bilangan fakta "tidak berkaitan" dan bilangan fakta "tidak disokong". Ejen LLM menjadi pencatat fakta yang lebih baik daripada manusia Untuk menilai secara kuantitatif kualiti anotasi yang diperoleh menggunakan SELAMAT, para penyelidik menggunakan anotasi manusia. Data tersebut mengandungi 496 pasangan tindak balas segera, yang mana respons dibahagikan secara manual kepada fakta individu (jumlah 16,011 fakta individu), dan setiap fakta individu dilabelkan secara manual sebagai disokong, tidak relevan atau tidak disokong. Mereka membandingkan secara langsung anotasi SELAMAT dan anotasi manusia untuk setiap fakta dan mendapati bahawa SELAMAT bersetuju dengan manusia pada 72.0% fakta individu, seperti ditunjukkan dalam Rajah 4 di bawah. Ini menunjukkan bahawa SAFE mencapai prestasi peringkat manusia pada kebanyakan fakta individu. Subset 100 fakta individu daripada temu bual rawak kemudiannya diperiksa yang mana anotasi SAFE tidak konsisten dengan penilai manusia. Penyelidik menganotasi semula setiap fakta secara manual (membenarkan akses kepada Carian Google, bukan sahaja Wikipedia, untuk penjelasan yang lebih komprehensif) dan menggunakan label ini sebagai kebenaran asas. Mereka mendapati bahawa dalam kes percanggahan pendapat ini, anotasi SAFE adalah betul 76% sepanjang masa, manakala anotasi manusia adalah betul hanya 19% pada masa itu, mewakili kadar kemenangan 4 berbanding 1 untuk SAFE. Butirannya ditunjukkan dalam Rajah 5 di bawah. Di sini, harga dua pelan anotasi patut diberi perhatian. Kos untuk menilai respons model tunggal menggunakan anotasi manusia ialah $4, manakala SAFE menggunakan GPT-3.5-Turbo dan Serper API hanya $0.19. Tanda aras siri Gemini, GPT, Claude dan PaLM-2 Akhirnya, penyelidik menguji empat siri model (Gemini, GPT-12 di bawah Long) dan PaFLM dalam Jadual 2) Menjalankan ujian penanda aras yang meluas pada 13 model bahasa yang besar. Secara khusus, mereka menilai setiap model menggunakan subset rawak yang sama iaitu 250 petunjuk dalam LongFact-Objects, kemudian menggunakan SAFE untuk mendapatkan metrik penilaian mentah bagi setiap tindak balas model, dan menggunakan metrik F1@K. Didapati bahawa, secara amnya, model bahasa yang lebih besar mencapai faktual bentuk panjang yang lebih baik. Seperti yang ditunjukkan dalam Rajah 6 dan Jadual 2 di bawah, GPT-4-Turbo lebih baik daripada GPT-4, GPT-4 lebih baik daripada GPT-3.5-Turbo, Gemini-Ultra lebih baik daripada Gemini-Pro dan PaLM-2-L -IT-RLHF Lebih baik daripada PaLM-2-L-IT. Sila rujuk kertas asal untuk butiran lanjut teknikal dan keputusan percubaan. 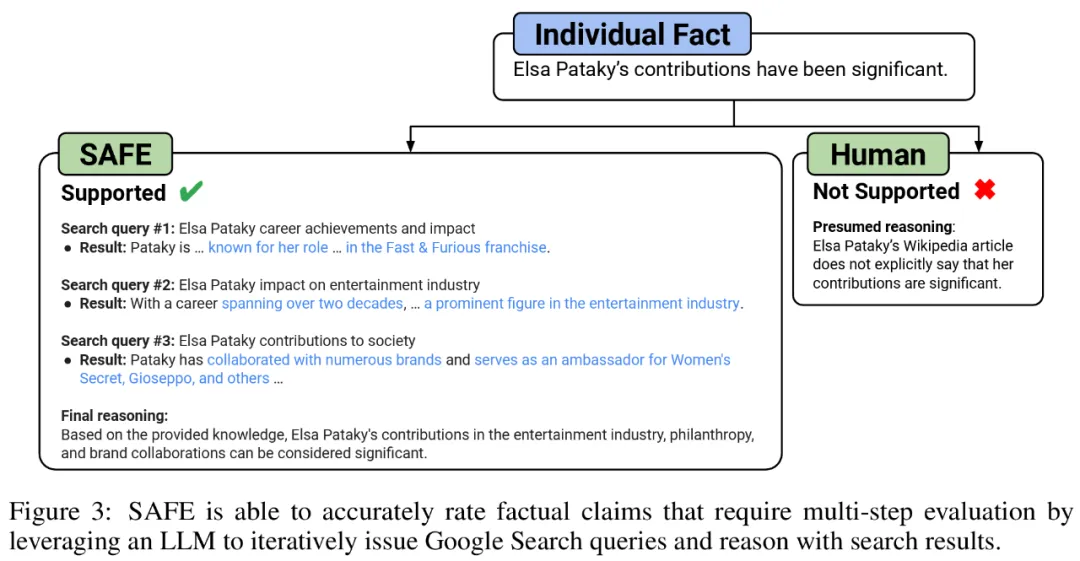
Hasil eksperimen

Atas ialah kandungan terperinci DeepMind menamatkan ilusi model besar? Pelabelan fakta lebih dipercayai daripada manusia, 20 kali lebih murah, dan sumber terbuka sepenuhnya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Apabila menukar rentetan ke objek dalam vue.js, json.parse () lebih disukai untuk rentetan json standard. Untuk rentetan JSON yang tidak standard, rentetan boleh diproses dengan menggunakan ungkapan biasa dan mengurangkan kaedah mengikut format atau url yang dikodkan. Pilih kaedah yang sesuai mengikut format rentetan dan perhatikan isu keselamatan dan pengekodan untuk mengelakkan pepijat.
 Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Ringkasan: Terdapat kaedah berikut untuk menukar array rentetan vue.js ke dalam tatasusunan objek: Kaedah asas: Gunakan fungsi peta yang sesuai dengan data yang diformat biasa. Permainan lanjutan: Menggunakan ungkapan biasa boleh mengendalikan format yang kompleks, tetapi mereka perlu ditulis dengan teliti dan dipertimbangkan. Pengoptimuman Prestasi: Memandangkan banyak data, operasi tak segerak atau perpustakaan pemprosesan data yang cekap boleh digunakan. Amalan Terbaik: Gaya Kod Jelas, Gunakan nama dan komen pembolehubah yang bermakna untuk memastikan kod ringkas.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Vue dan Element-UI Cascade Drop-Down Box V-Model Binding
Apr 07, 2025 pm 08:06 PM
Vue dan Element-UI Cascade Drop-Down Box V-Model Binding
Apr 07, 2025 pm 08:06 PM
Vue dan Element-UI cascaded drop-down boxes v-model mengikat titik pit biasa: V-model mengikat array yang mewakili nilai yang dipilih pada setiap peringkat kotak pemilihan cascaded, bukan rentetan; Nilai awal pilihan terpilih mestilah array kosong, tidak batal atau tidak jelas; Pemuatan data dinamik memerlukan penggunaan kemahiran pengaturcaraan tak segerak untuk mengendalikan kemas kini data secara tidak segerak; Untuk set data yang besar, teknik pengoptimuman prestasi seperti menatal maya dan pemuatan malas harus dipertimbangkan.
 Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Untuk menetapkan masa untuk Vue Axios, kita boleh membuat contoh Axios dan menentukan pilihan masa tamat: dalam tetapan global: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dalam satu permintaan: ini. $ axios.get ('/api/pengguna', {timeout: 10000}).
 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
