

Keupayaan teks panjang CLIP dibuka dan prestasi tugasan mendapatkan imej dipertingkatkan dengan ketara!
Beberapa butiran penting juga boleh ditangkap. Shanghai Jiao Tong University dan Shanghai AI Laboratory mencadangkan rangka kerja baharu Long-CLIP.
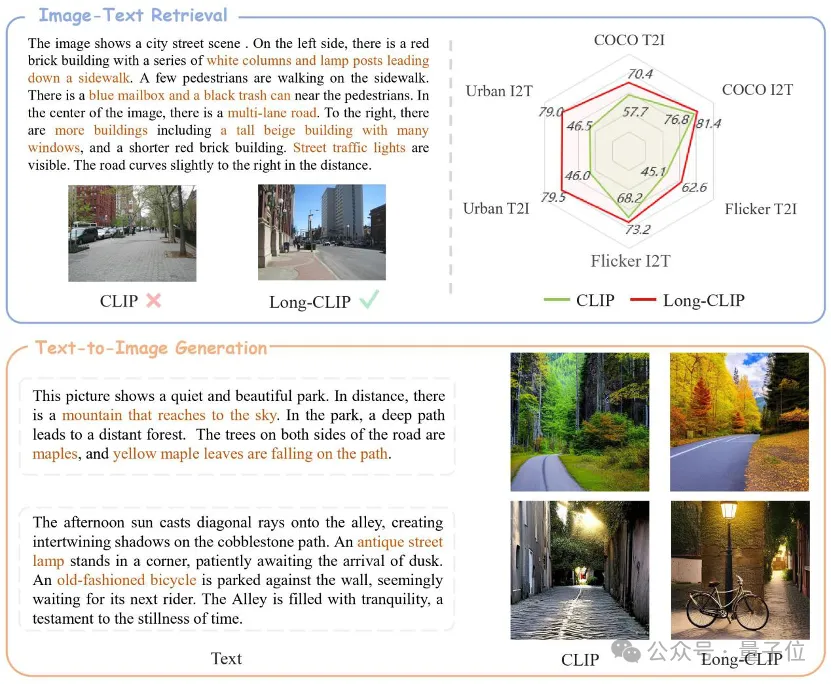
Long-CLIP adalah berdasarkan pada mengekalkan ruang ciri asal CLIP dan adalah plug-and-play dalam tugas hiliran seperti penjanaan imej untuk mencapai prestasi yang baik. -penjanaan imej berbutir bagi teks panjang .
Pendapatan imej teks panjang meningkat sebanyak 20%, perolehan imej teks pendek meningkat sebanyak 6%.
CLIP menjajarkan modaliti visual dan teks serta mempunyai keupayaan generalisasi tangkapan sifar yang berkuasa. Oleh itu, CLIP digunakan secara meluas dalam pelbagai tugas multi-modal, seperti klasifikasi imej, pengambilan imej teks, penjanaan imej, dll.
Tetapi kelemahan utama CLIP ialah kekurangan keupayaan teks panjang.
Pertama sekali, disebabkan penggunaan pengekodan kedudukan mutlak, panjang input teks CLIP dihadkan kepada 677 token. Bukan itu sahaja, percubaan telah membuktikan bahawa panjang berkesan sebenar CLIP adalah kurang daripada 20 token, yang jauh daripada cukup untuk mewakili maklumat terperinci. Walau bagaimanapun, untuk mengatasi batasan ini, penyelidik telah mencadangkan penyelesaian. Dengan memperkenalkan teg tertentu dalam input teks, model boleh memfokuskan pada bahagian penting. Kedudukan dan bilangan token ini dalam input ditentukan terlebih dahulu dan tidak akan melebihi 20 token. Dengan cara ini, CLIP dapat mengendalikan input teks Ketiadaan teks panjang pada bahagian teks juga mengehadkan keupayaan bahagian visual. Memandangkan ia hanya mengandungi teks pendek, pengekod visual CLIP hanya akan mengekstrak komponen terpenting imej, sambil mengabaikan pelbagai butiran. Ini sangat memudaratkan tugasan yang terperinci seperti
pendapatan silang modal. Pada masa yang sama, kekurangan teks yang panjang juga menjadikan CLIP menggunakan kaedah pemodelan mudah serupa dengan beg-of-feature (BOF), yang tidak mempunyai keupayaan kompleks seperti penaakulan sebab-akibat.
Untuk menangani masalah ini, penyelidik mencadangkan model Long-CLIP.
Secara khusus mencadangkan dua strategi: Pemeliharaan Pengetahuan Regangan Pembenaman Kedudukan dan strategi penalaan halus untuk menambah penjajaran komponen teras (Pemadanan Komponen Utama). 
Peluasan pengekodan kedudukan yang memelihara pengetahuan
, dan kemudian memperhalusinya melalui panjang teks. Penyelidik mendapati bahawa tahap latihan pengekodan kedudukan berbeza CLIP adalah berbeza. Memandangkan teks latihan mungkin kebanyakannya teks pendek, pengekodan kedudukan yang lebih rendah lebih terlatih sepenuhnya dan boleh mewakili kedudukan mutlak dengan tepat, manakala pengekodan kedudukan yang lebih tinggi hanya boleh mewakili anggaran kedudukan relatifnya. Oleh itu, kos interpolasi kod pada kedudukan berbeza adalah berbeza.
Berdasarkan pemerhatian di atas, penyelidik mengekalkan 20 kod kedudukan pertama, dan untuk baki 57 kod kedudukan, diinterpolasi dengan nisbah yang lebih besar λ
2 Formula pengiraan boleh dinyatakan sebagai:
Percubaan Ia menunjukkan bahawa. berbanding dengan interpolasi langsung, strategi ini boleh meningkatkan prestasi dengan ketara pada pelbagai tugas sambil menyokong jumlah panjang yang lebih panjang. 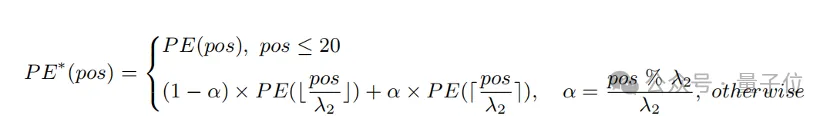
Tambahkan penalaan halus penjajaran atribut teras
Secara khusus, penyelidik menggunakan algoritma analisis komponen utama (PCA) untuk mengekstrak atribut teras daripada ciri imej berbutir halus, menapis atribut yang tinggal untuk membina semula ciri imej berbutir kasar dan membandingkannya dengan teks ringkas ringkasan. Strategi ini memerlukan model bukan sahaja mengandungi lebih banyak butiran (penjajaran berbutir halus), tetapi juga mengenal pasti dan memodelkan atribut yang paling teras (pengekstrakan komponen teras dan penjajaran berbutir kasar).
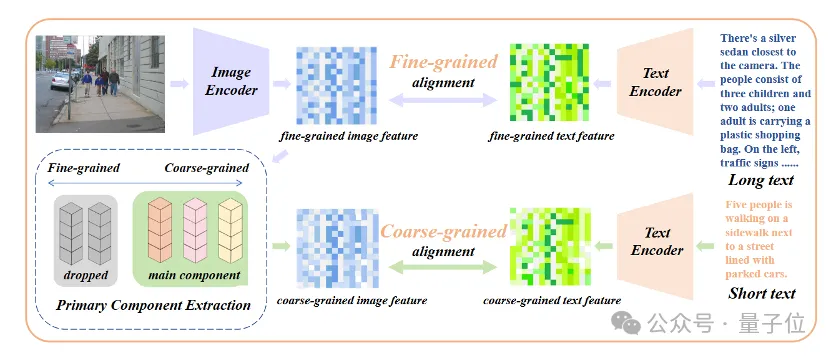 △Tambahkan proses penalaan halus penjajaran atribut teras
△Tambahkan proses penalaan halus penjajaran atribut teras
Palamkan dan mainkan dalam pelbagai tugas berbilang modal
Sebagai contoh, dalam pengambilan imej dan teks, Long-CLIP boleh menangkap maklumat yang lebih terperinci dalam mod imej dan teks, dengan itu meningkatkan keupayaan untuk membezakan imej dan teks yang serupa, dan meningkatkan prestasi perolehan semula imej dan teks.
Sama ada pada pengambilan teks pendek tradisional (COCO, Flickr30k) atau tugasan mendapatkan teks panjang, Long-CLIP telah meningkatkan kadar ingatan dengan ketara.
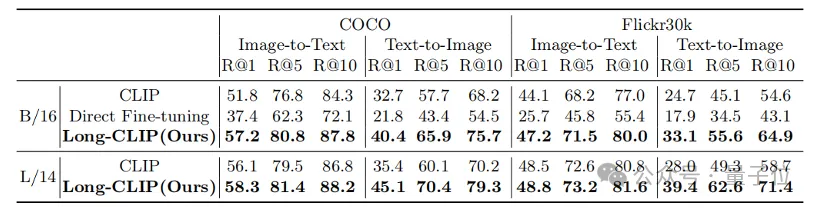
△Keputusan percubaan mendapatkan semula imej teks pendek
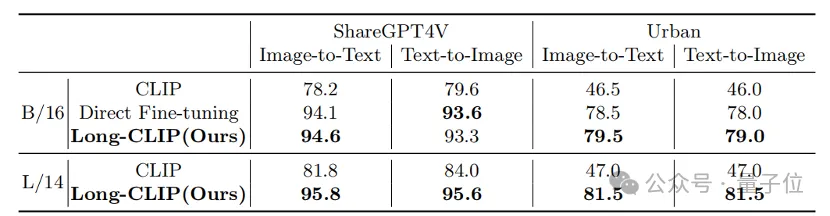
△hasil percubaan mendapatkan semula imej teks yang panjang

△perincian teks-imej semula jadi yang menyengat, perincian teks-imej yang panjang adalah visual yang menyengat. pictures
Selain itu, pengekod teks CLIP sering digunakan dalam model penjanaan teks ke imej, seperti siri resapan stabil, dsb. Walau bagaimanapun, disebabkan kekurangan keupayaan teks panjang, penerangan teks yang digunakan untuk menjana imej biasanya sangat pendek dan tidak boleh disesuaikan dengan pelbagai butiran.
Long-CLIP boleh menembusi had 77 token dan mencapai penjanaan imej peringkat bab (kanan bawah).
Anda juga boleh memodelkan lebih banyak butiran dalam 77 token untuk mencapai penjanaan imej yang halus (kanan atas).

Pautan kertas:https://arxiv.org/abs/2403.15378
Pautan kod:https://github.com/beichenzbc
Atas ialah kandungan terperinci Rangka kerja baharu Universiti Jiao Tong Shanghai membuka kunci keupayaan teks panjang CLIP, memahami perincian penjanaan pelbagai mod dan meningkatkan keupayaan mendapatkan imej dengan ketara. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pengenalan kepada rangka kerja yang digunakan oleh vscode
Pengenalan kepada rangka kerja yang digunakan oleh vscode
 Cara menggunakan append dalam python
Cara menggunakan append dalam python
 Aplikasi rasmi Euro-Italian Exchange
Aplikasi rasmi Euro-Italian Exchange
 Apakah prinsip kerja dan proses mybatis
Apakah prinsip kerja dan proses mybatis
 Apakah maksud sisi b dan sisi c?
Apakah maksud sisi b dan sisi c?
 html editor dalam talian
html editor dalam talian
 Perisian rakaman masa
Perisian rakaman masa
 Penggunaan fungsi fopen dalam Matlab
Penggunaan fungsi fopen dalam Matlab
 bagaimana untuk menyembunyikan alamat ip
bagaimana untuk menyembunyikan alamat ip







![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



