

Teknologi Lanzhou diumumkan secara rasmi: Model besar Mencius 3-13B adalah sumber terbuka secara rasmi!
Model ringan yang besar dan menjimatkan kos ini terbuka sepenuhnya kepada penyelidikan akademik dan menyokong penggunaan komersial percuma.
Dalam pelbagai penilaian penanda aras seperti MMLU, GSM8K, dan HUMAN-EVAL, Mencius 3-13B telah menunjukkan prestasi yang baik.
Terutama dalam bidang model besar ringan dengan parameter dalam lingkungan 20B, kemahiran bahasa Cina dan Inggeris amat cemerlang. Kemahiran matematik dan pengaturcaraan juga berada di barisan hadapan.
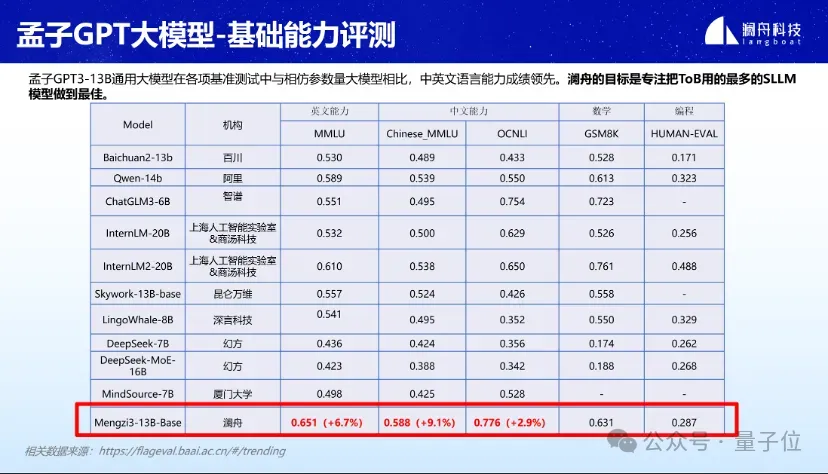
Menurut laporan, model besar Mencius 3-13B adalah berdasarkan seni bina Llama, dan saiz set data setinggi 3T Token.
Korpus dipilih daripada halaman web, ensiklopedia, media sosial, media, berita dan set data sumber terbuka berkualiti tinggi. Dengan terus melatih korpus berbilang bahasa mengenai trilion token, model ini mempunyai keupayaan bahasa Cina yang luar biasa dan mengambil kira keupayaan berbilang bahasa.
Anda boleh menggunakan model besar Mencius 3-13B dalam dua langkah sahaja.
Mula-mula konfigurasikan persekitaran.
pip install -r requirements.txt
Kemudian mulakan dengan cepat.
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizertokenizer = AutoTokenizer.from_pretrained("Langboat/Mengzi3-13B-Base", use_fast=False, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained("Langboat/Mengzi3-13B-Base", device_map="auto", trust_remote_code=True)inputs = tokenizer('指令:回答以下问题。输入:介绍一下孟子。输出:', return_tensors='pt')if torch.cuda.is_available():inputs = inputs.to('cuda')pred = model.generate(**inputs, max_new_tokens=512, repetition_penalty=1.01, eos_token_id=tokenizer.eos_token_id)print(tokenizer.decode(pred[0], skip_special_tokens=True))Selain itu, mereka menyediakan kod sampel yang boleh digunakan untuk inferens interaktif pusingan tunggal dengan model asas.
cd examplespython examples/base_streaming_gen.py --model model_path --tokenizer tokenizer_path
Jika anda ingin memperhalusi model, mereka juga menyediakan fail dan kod yang berkaitan.

Malah, banyak butiran model besar Mencius 3-13B telah didedahkan seawal 18 Mac di persidangan pelancaran produk dan teknologi model besar Lanzhou.
Ketika itu, mereka menyatakan latihan model besar Mencius 3-13B telah selesai.
Mengenai sebab memilih versi 13B, Zhou Ming menjelaskan:
Pertama sekali, Lanzhou jelas memfokuskan pada penyediaan senario ToB, ditambah dengan ToC.
Amalan mendapati bahawa parameter model besar yang paling kerap digunakan dalam senario ToB adalah kebanyakannya 7B, 13B, 40B, 100B dan kepekatan keseluruhan adalah antara 10B-100B.
Kedua, dalam julat ini, dari perspektif ROI (pulangan pelaburan), ia bukan sahaja memenuhi keperluan tempat kejadian, tetapi juga paling kos efektif.
Oleh itu, untuk sekian lama, matlamat Lanzhou adalah untuk mencipta model besar industri berkualiti tinggi dalam skala parameter 10B-100B.
Sebagai salah satu pasukan keusahawanan model besar yang terawal di China, Lanzhou mengeluarkan Mencius GPT V1 (MChat) pada Mac tahun lepas.
Pada bulan Januari tahun ini, Mencius Big Model GPT V2 (termasuk Mencius Big Model-Standard, Mencius Big Model-Lightweight, Mencius Big Model-Finance, Mencius Big Model-Encoding) telah dibuka kepada orang ramai.
Okay kawan-kawan yang berminat boleh klik link di bawah untuk merasainya.
Pautan GitHub: https://github.com/Langboat/Mengzi3
HuggingFace: https://huggingface.co/Langboat/Mengzi3-13B-BaseModel
//www.modelscope.cn/models/langboat/Mengzi3-13B-BaseWisemodel:
Atas ialah kandungan terperinci 0 ambang untuk kegunaan komersial percuma! Model besar Mencius 3-13B adalah sumber terbuka secara rasmi dan dilatih dengan trilion data token. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah Spring MVC
Apakah Spring MVC
 kad bebas mysql
kad bebas mysql
 Lihat maklumat sistem dalam linux
Lihat maklumat sistem dalam linux
 locallapstore
locallapstore
 Bagaimana untuk mengeluarkan yuran di WeChat
Bagaimana untuk mengeluarkan yuran di WeChat
 Tutorial penggunaan pelayan awan
Tutorial penggunaan pelayan awan
 Pengenalan kepada arahan pendaftaran Windows yang biasa digunakan
Pengenalan kepada arahan pendaftaran Windows yang biasa digunakan
 Apakah enjin carian direktori yang ada?
Apakah enjin carian direktori yang ada?
 Bagaimana untuk menyemak pautan mati di tapak web anda
Bagaimana untuk menyemak pautan mati di tapak web anda








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



