
 Peranti teknologi
AI
Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Peranti teknologi
AI
Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu

Pemahaman dokumen pelbagai modKeupayaan SOTA baharu!
Pasukan Alibaba mPLUG mengeluarkan kerja sumber terbuka terkini mPLUG-DocOwl 1.5, yang mencadangkan satu siri penyelesaian untuk empat cabaran utama pengecaman teks imej resolusi tinggi, pemahaman struktur dokumen sejagat, mengikut arahan dan pengenalan pengetahuan luaran .
Tanpa berlengah lagi, mari kita lihat kesannya dahulu.
Pengiktirafan satu klik dan penukaran carta dengan struktur kompleks ke dalam format Markdown:
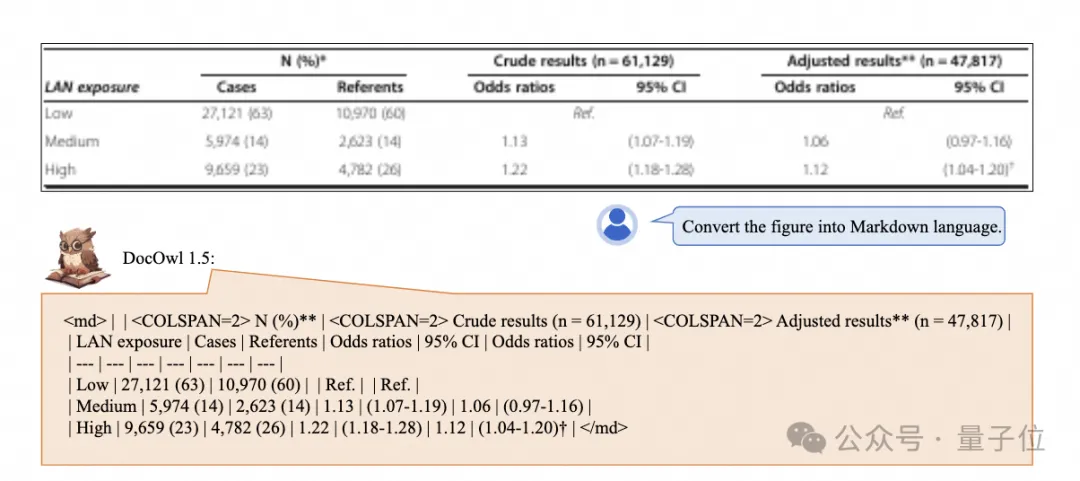
Carta gaya berbeza tersedia:
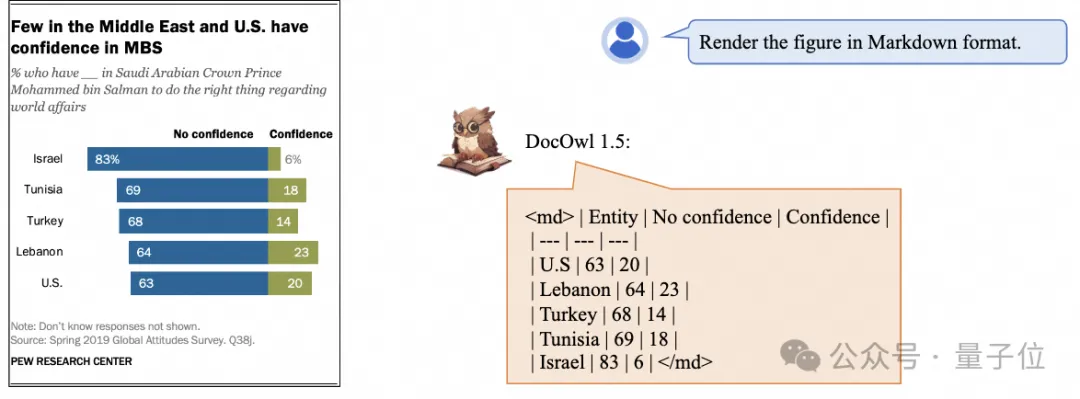
Pengecaman dan kedudukan teks yang lebih terperinci juga boleh dikendalikan:🜎
juga boleh dikendalikan dengan mudahBeri juga penjelasan terperinci tentang pemahaman dokumen: 
Anda mesti tahu bahawa "pemahaman dokumen" pada masa ini merupakan senario penting untuk pelaksanaan model bahasa besar Terdapat banyak produk di pasaran untuk membantu pembacaan dokumen, dan beberapa terutamanya menggunakan sistem OCR untuk membaca teks Pengecaman dan pemahaman teks dengan LLM boleh mencapai keupayaan pemahaman dokumen yang baik. 
Selain keupayaan untuk memberikan jawapan mudah pada penanda aras, melalui sejumlah kecil "penjelasan terperinci" 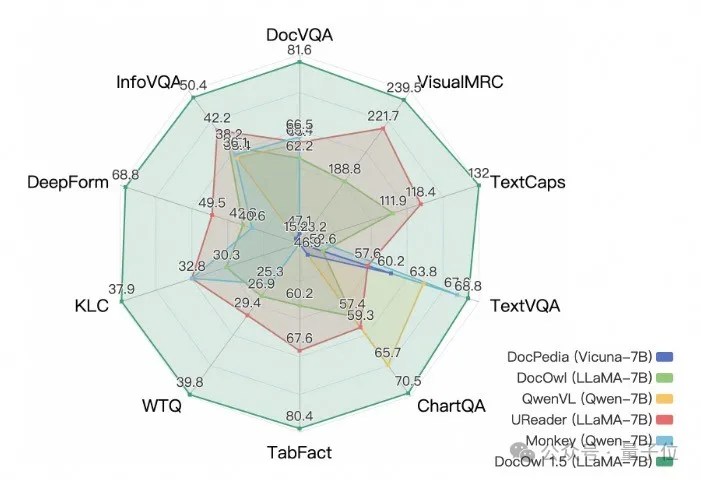 (penaakulan)
(penaakulan)
Pasukan Alibaba mPLUG telah melabur dalam penyelidikan pemahaman dokumen berbilang modal sejak Julai 2023, dan telah mengeluarkan secara berturut-turut mPLUG-DocOwl, UReader, mPLUG-PaperOwl, mPLUG-DocOwl 1.5 dan sumber terbuka siri model pemahaman dokumen besar dan data latihan.
Artikel ini bermula daripada karya terkini mPLUG-DocOwl 1.5, menganalisis cabaran utama dan penyelesaian berkesan dalam bidang "pemahaman dokumen pelbagai mod". Cabaran 1: Pengecaman teks imej resolusi tinggiBerbeza daripada imej biasa, imej dokumen dicirikan oleh pelbagai bentuk dan saiz, yang boleh termasuk imej dokumen bersaiz A4, imej jadual pendek dan lebar serta halaman web mudah alih yang panjang dan sempit Tangkapan skrin, imej adegan rawak, dsb. diedarkan dalam pelbagai resolusi. Apabila model besar berbilang modal arus perdana mengekod imej, ia selalunya menskalakan secara langsung saiz imej Contohnya, skala mPLUG-Owl2 dan QwenVL kepada 448x448, dan skala LLaVA 1.5 kepada 336x336. Hanya menskalakan imej dokumen akan menyebabkan teks dalam imej menjadi kabur dan cacat, menjadikannya tidak dapat dikenali. Untuk memproses imej dokumen, mPLUG-DocOwl 1.5 meneruskan pendekatancutting
pendahulunya URReader Struktur model ditunjukkan dalam Rajah 1:
△struktur UReader 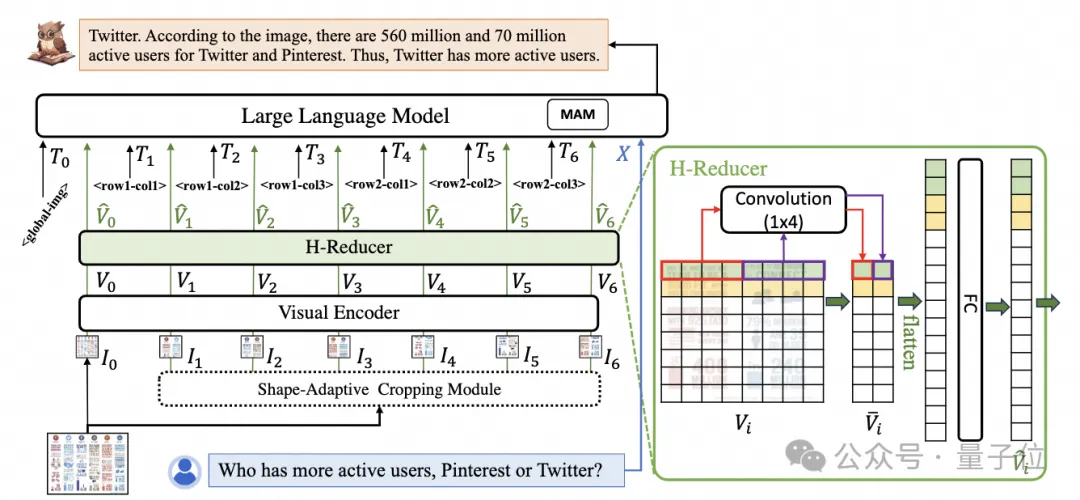
. Ia pertama kali dicadangkan untuk mendapatkan satu siri sub-imej melalui Modul Pemotongan penyesuaian bentuk bebas parameter
berdasarkan model besar berbilang mod sedia ada Setiap sub-imej dikodkan oleh pengekod resolusi rendah untuk mengarahkan semantik melalui model bahasa.Strategi pemotongan graf ini boleh menggunakan maksimum keupayaan pengekod visual tujuan umum sedia ada (seperti CLIP ViT-14/L)
untuk pemahaman dokumen,sangat mengurangkan kos latihan semula pengekod visual resolusi tinggi . Modul pemotongan yang disesuaikan dengan bentuk ditunjukkan dalam Rajah 2:
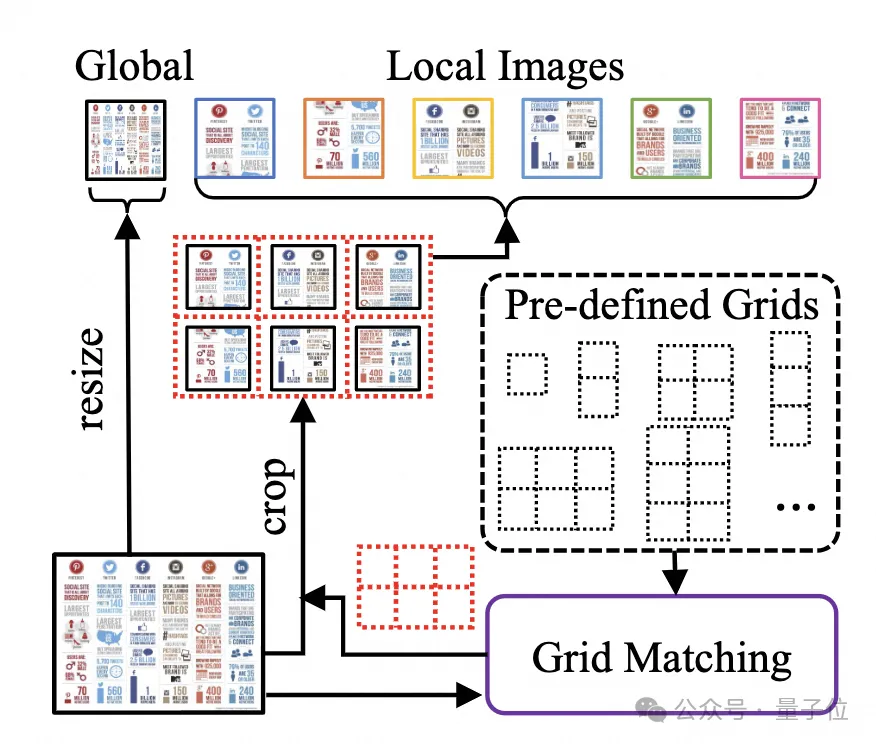
△Rajah 2: Modul pemotongan penyesuaian bentuk.
Cabaran 2: Pemahaman struktur dokumen umum
Untuk pemahaman dokumen yang tidak bergantung pada sistem OCR, mengenali teks ialah keupayaan asas untuk mencapai pemahaman semantik dan pemahaman struktur kandungan dokumen memerlukan pemahaman tajuk jadual dan Surat-menyurat antara baris dan lajur Memahami carta memerlukan pemahaman struktur yang pelbagai seperti graf garis, graf bar dan carta pai Memahami kontrak memerlukan pemahaman pasangan nilai kunci yang pelbagai seperti tandatangan tarikh.
mPLUG-DocOwl 1.5 memfokuskan pada menyelesaikan keupayaan pemahaman struktur seperti dokumen umum Melalui pengoptimuman struktur model dan peningkatan tugas latihan, ia telah mencapai keupayaan pemahaman dokumen umum yang lebih kukuh.
Dari segi struktur, seperti yang ditunjukkan dalam Rajah 1, mPLUG-DocOwl 1.5 meninggalkan modul sambungan bahasa visual Abstractor dalam mPLUG-Owl/mPLUG-Owl2, menggunakan H-Reducer berdasarkan "konvolusi + lapisan bersambung sepenuhnya" untuk ciri pengagregatan Dan penjajaran ciri .
Berbanding dengan Abstractor berdasarkan pertanyaan yang boleh dipelajari, H-Reducer mengekalkan hubungan kedudukan relatif antara ciri visual dan memindahkan maklumat struktur dokumen yang lebih baik kepada model bahasa.
Berbanding dengan MLP yang mengekalkan panjang jujukan visual, H-Reducer sangat mengurangkan bilangan ciri visual melalui konvolusi, membolehkan LLM memahami imej dokumen resolusi tinggi dengan lebih cekap.
Memandangkan teks dalam kebanyakan imej dokumen disusun secara mendatar dahulu, dan semantik teks dalam arah mendatar adalah koheren, H-Reducer menggunakan bentuk lilitan 1x4 dan saiz langkah. Dalam kertas itu, penulis membuktikan melalui eksperimen perbandingan yang mencukupi keunggulan H-Reducer dalam pemahaman struktur dan bahawa 1x4 adalah bentuk agregat yang lebih umum.
Dari segi tugas latihan, mPLUG-DocOwl 1.5 mereka bentuk pembelajaran struktur bersatu (Pembelajaran Struktur Bersepadu) tugasan untuk semua jenis gambar, seperti yang ditunjukkan dalam Rajah 3.
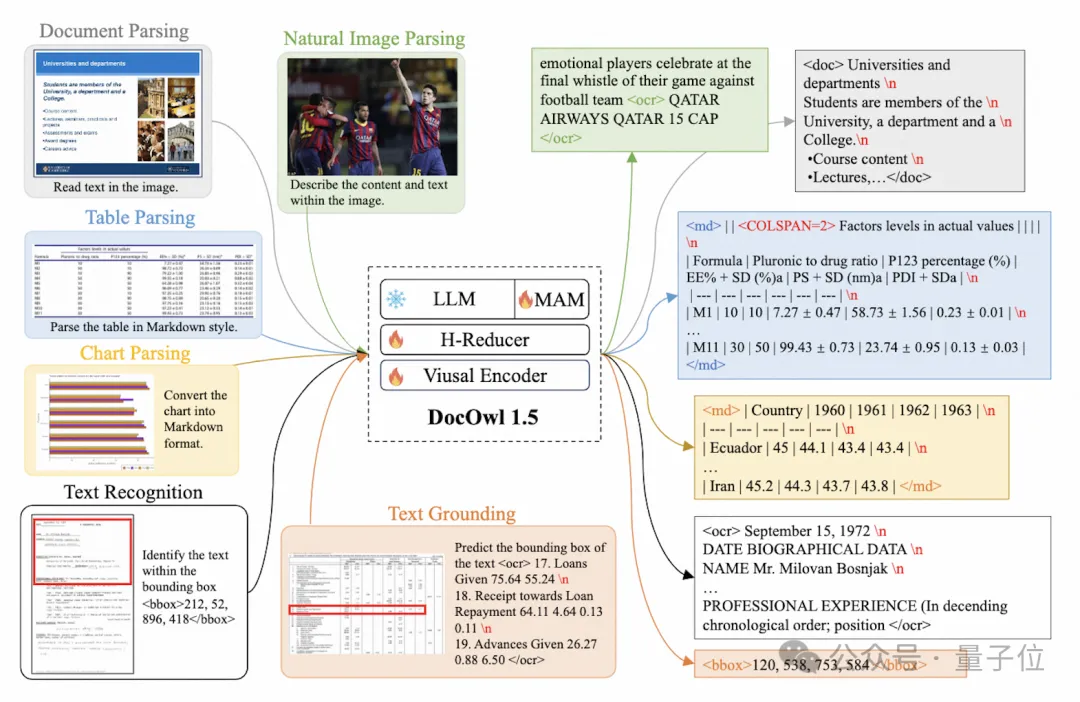
△Rajah 3: Pembelajaran Struktur Bersatu
Pembelajaran Struktur Bersatu bukan sahaja merangkumi analisis teks imej global, tetapi juga pengecaman dan kedudukan teks berbutir-butir.
Dalam tugas menghurai teks imej global, untuk imej dokumen dan imej halaman web, ruang dan pemisah baris boleh digunakan untuk paling biasa mewakili struktur teks untuk jadual, pengarang memperkenalkan aksara khas untuk mewakili berbilang baris dan lajur berdasarkan; Sintaks penurunan nilai penerangan dan teks adegan adalah sama penting, jadi bentuk penerangan gambar yang disambung dengan teks adegan digunakan sebagai sasaran penghuraian.
Dalam tugasan "Pengecaman dan Kedudukan Teks", untuk lebih sesuai dengan pemahaman imej dokumen, pengarang mereka bentuk pengecaman dan kedudukan teks pada empat butiran perkataan, frasa, baris dan blok Kotak sempadan diwakili oleh a nombor integer diskret, dan julat 0-999.
Untuk menyokong pembelajaran struktur bersatu, penulis membina set latihan komprehensif DocStruct4M, meliputi pelbagai jenis imej seperti dokumen/halaman web, jadual, carta, imej semula jadi, dsb.
Selepas pembelajaran struktur bersatu, DocOwl 1.5 mempunyai keupayaan analisis berstruktur dan kedudukan teks imej dokumen dalam pelbagai medan.

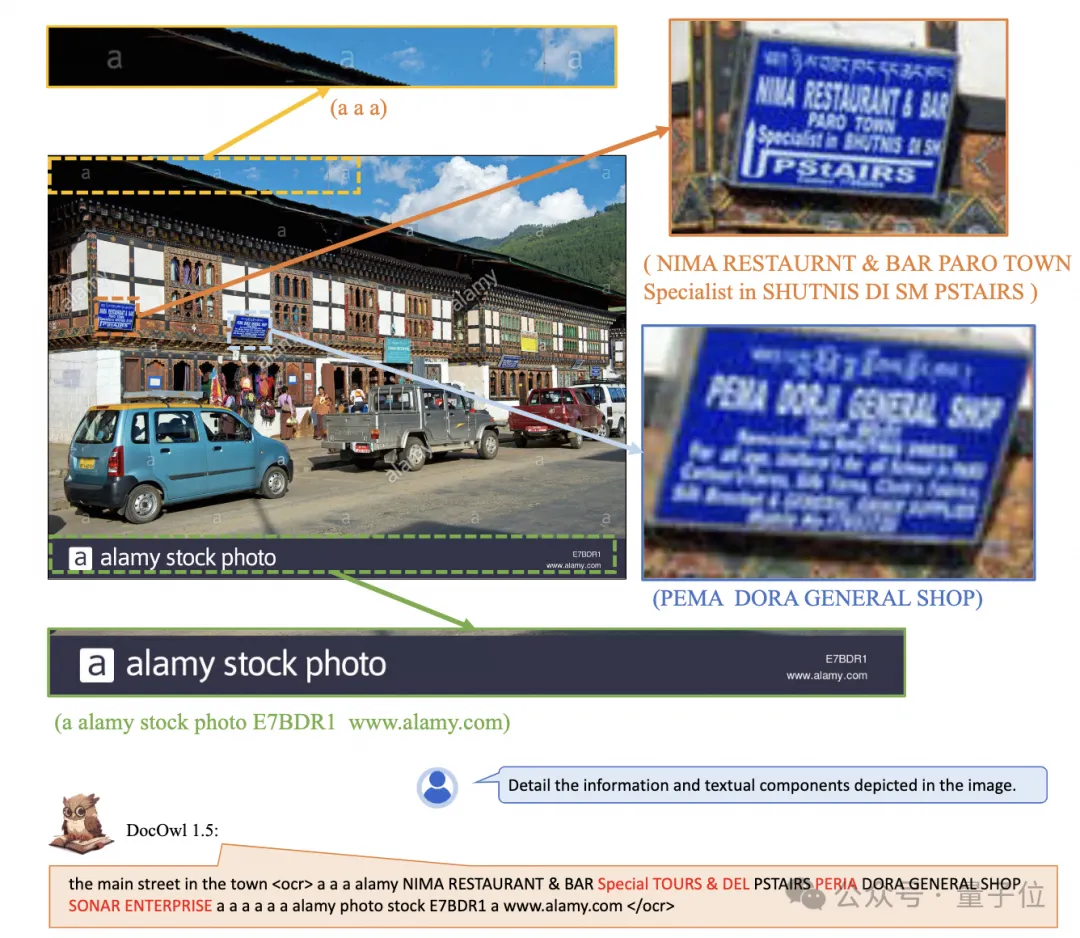
△ Rajah 4: Parsing teks berstruktur
As ditunjukkan dalam Rajah 4 dan Rajah 5:
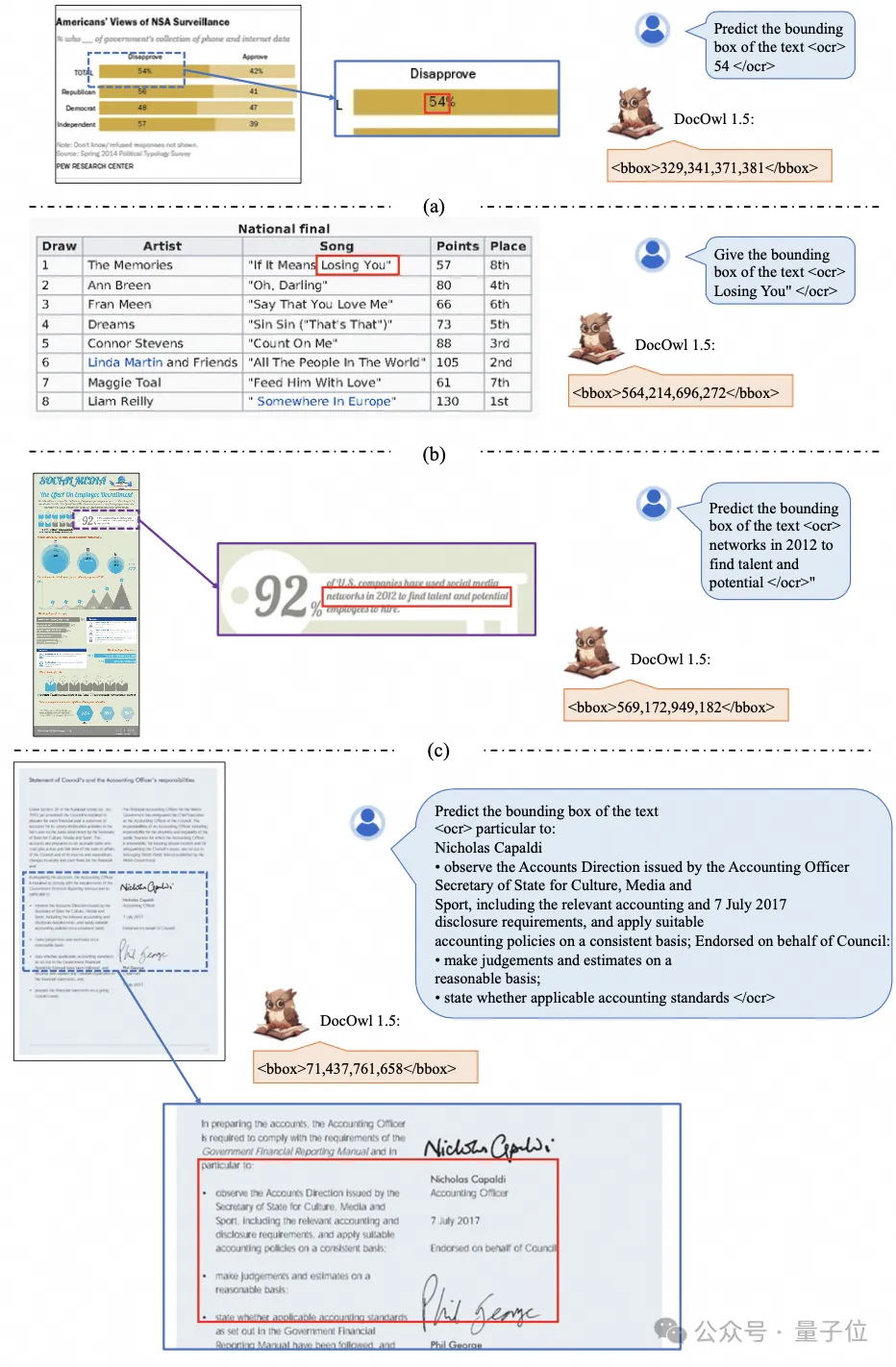
△ Rajah 5: Pengiktirafan teks dan kedudukan multi-granulariti
Challenge 3: Arahan berikut
"Mengikuti Arahan"(Mengikuti Arahan) memerlukan model berdasarkan keupayaan pemahaman dokumen asas dan melaksanakan tugas yang berbeza mengikut arahan pengguna, seperti pengekstrakan maklumat, soal jawab, penerangan gambar, dsb.
Meneruskan amalan mPLUG-DocOwl, DocOwl 1.5 menyatukan pelbagai tugas hiliran ke dalam bentuk soal jawab arahan Selepas pembelajaran struktur bersatu, model umum dalam bidang dokumen diperoleh melalui latihan bersama pelbagai tugas(generalis). .
Selain itu, untuk membolehkan model mempunyai keupayaan untuk menerangkan secara terperinci, mPLUG-DocOwl telah cuba memperkenalkan arahan teks biasa untuk memperhalusi data untuk latihan bersama, yang mempunyai kesan tertentu tetapi tidak sesuai. Dalam DocOwl 1.5, penulis membina sejumlah kecil data penjelasan terperinci(DocReason25K) melalui GPT3.5 dan GPT4V berdasarkan masalah tugasan hiliran.
Dengan menggabungkan tugas hiliran dokumen dan DocReason25K untuk latihan, DocOwl 1.5-Chat boleh mencapai hasil yang lebih baik pada penanda aras:
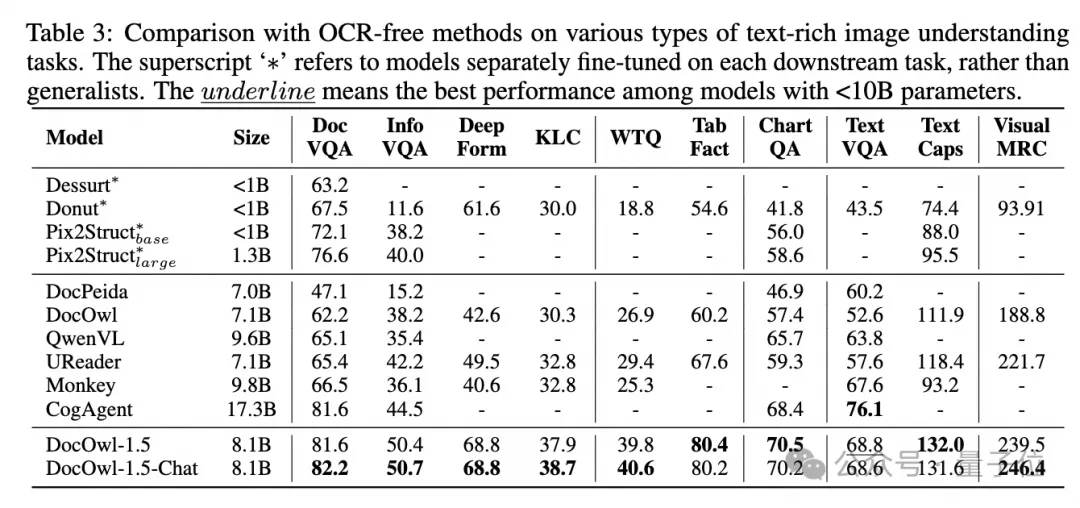
△ Rajah 6: Pemahaman Dokumen Penilaian Penanda Aras
: dan
: dan 
: dan : dan : 
△Rajah 7: Penjelasan terperinci tentang pemahaman dokumen
Cabaran 4: Pengenalan pengetahuan luaran
Gambar dokumen Disebabkan kekayaan maklumat, pemahaman sering memerlukan pengenalan pengetahuan tambahan, seperti istilah profesional dan maknanya dalam bidang khas dll. Untuk mengkaji cara memperkenalkan pengetahuan luaran untuk pemahaman dokumen yang lebih baik, pasukan mPLUG bermula dalam bidang kertas dan mencadangkan mPLUG-PaperOwl, membina set data analisis carta kertas berkualiti tinggi M-Paper, melibatkan 447k kertas definisi tinggi carta.
Data ini menyediakan konteks untuk carta dalam kertas sebagai sumber luar pengetahuan, dan mereka bentuk "titik penting"
(garis besar) sebagai isyarat kawalan untuk analisis carta untuk membantu model memahami niat pengguna dengan lebih baik.
Berdasarkan UReader, pengarang memperhalusi mPLUG-PaperOwl pada M-Paper, yang menunjukkan keupayaan analisis carta kertas awal, seperti yang ditunjukkan dalam Rajah 8. . Secara umum, artikel ini bermula daripada model besar pemahaman dokumen berbilang modal 7B yang dikeluarkan baru-baru ini mPLUG-DocOwl 1.5 dan meringkaskan empat cabaran utama pemahaman dokumen berbilang modal tanpa bergantung pada OCR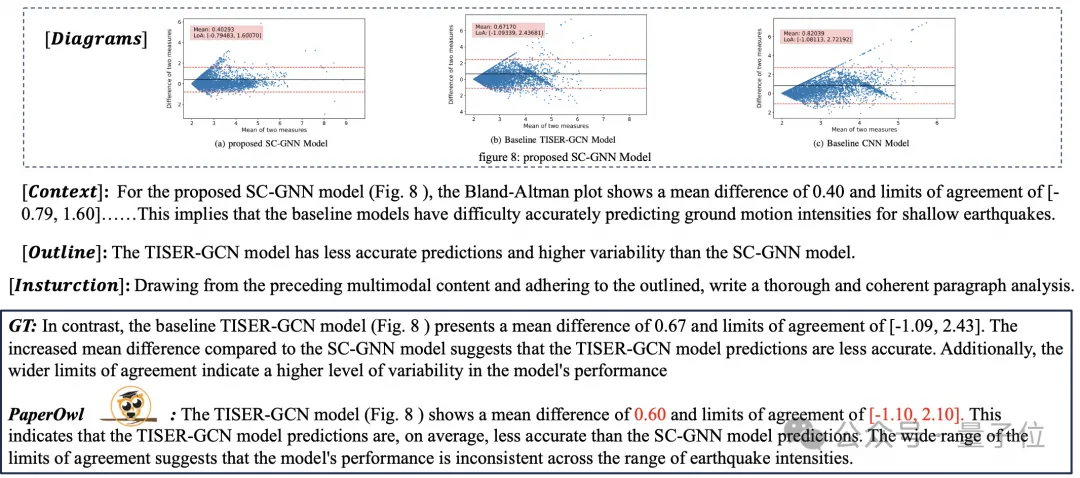
("Teks imej resolusi tinggi pengiktirafan", "Pemahaman struktur dokumen sejagat", "Pengikut arahan", "Pengenalan pengetahuan luaran")
dan penyelesaian yang diberikan oleh pasukan Alibaba mPLUG.Walaupun mPLUG-DocOwl 1.5 telah meningkatkan prestasi pemahaman dokumen model sumber terbuka, ia masih jauh di belakang model besar sumber tertutup dan keperluan kehidupan sebenar Masih terdapat ruang untuk penambahbaikan dalam pengecaman teks, pengiraan matematik, umum tujuan, dsb. dalam pemandangan semula jadi.
Pasukan mPLUG akan mengoptimumkan lagi prestasi DocOwl dan sumber terbuka Semua orang dialu-alukan untuk terus memberi perhatian dan mengadakan perbincangan mesra.Pautan GitHub: https://github.com/X-PLUG/mPLUG-DocOwl
Pautan kertas: https://arxiv.org/abs/2403.12895
Atas ialah kandungan terperinci Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara Melaksanakan Kaunter Redis
Apr 10, 2025 pm 10:21 PM
Cara Melaksanakan Kaunter Redis
Apr 10, 2025 pm 10:21 PM
Kaunter Redis adalah satu mekanisme yang menggunakan penyimpanan pasangan nilai utama REDIS untuk melaksanakan operasi pengiraan, termasuk langkah-langkah berikut: mewujudkan kekunci kaunter, meningkatkan tuduhan, mengurangkan tuduhan, menetapkan semula, dan mendapatkan tuduhan. Kelebihan kaunter Redis termasuk kelajuan cepat, konkurensi tinggi, ketahanan dan kesederhanaan dan kemudahan penggunaan. Ia boleh digunakan dalam senario seperti pengiraan akses pengguna, penjejakan metrik masa nyata, skor permainan dan kedudukan, dan pengiraan pemprosesan pesanan.
 phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
Untuk membuat jadual data menggunakan phpmyadmin, langkah -langkah berikut adalah penting: Sambungkan ke pangkalan data dan klik tab baru. Namakan jadual dan pilih enjin penyimpanan (disyorkan innoDB). Tambah butiran lajur dengan mengklik butang Tambah Lajur, termasuk nama lajur, jenis data, sama ada untuk membenarkan nilai null, dan sifat lain. Pilih satu atau lebih lajur sebagai kunci utama. Klik butang Simpan untuk membuat jadual dan lajur.
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Mewujudkan pangkalan data Oracle tidak mudah, anda perlu memahami mekanisme asas. 1. Anda perlu memahami konsep pangkalan data dan Oracle DBMS; 2. Menguasai konsep teras seperti SID, CDB (pangkalan data kontena), PDB (pangkalan data pluggable); 3. Gunakan SQL*Plus untuk membuat CDB, dan kemudian buat PDB, anda perlu menentukan parameter seperti saiz, bilangan fail data, dan laluan; 4. Aplikasi lanjutan perlu menyesuaikan set aksara, memori dan parameter lain, dan melakukan penalaan prestasi; 5. Beri perhatian kepada ruang cakera, keizinan dan parameter, dan terus memantau dan mengoptimumkan prestasi pangkalan data. Hanya dengan menguasai ia dengan mahir memerlukan amalan yang berterusan, anda boleh benar -benar memahami penciptaan dan pengurusan pangkalan data Oracle.
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Untuk membuat pangkalan data Oracle, kaedah biasa adalah menggunakan alat grafik DBCA. Langkah -langkah adalah seperti berikut: 1. Gunakan alat DBCA untuk menetapkan DBName untuk menentukan nama pangkalan data; 2. Tetapkan SYSPASSWORD dan SYSTEMPASSWORD kepada kata laluan yang kuat; 3. Tetapkan aksara dan NationalCharacterset ke Al32utf8; 4. Tetapkan MemorySize dan Tablespacesize untuk menyesuaikan mengikut keperluan sebenar; 5. Tentukan laluan logfile. Kaedah lanjutan dibuat secara manual menggunakan arahan SQL, tetapi lebih kompleks dan terdedah kepada kesilapan. Perhatikan kekuatan kata laluan, pemilihan set aksara, saiz dan memori meja makan
 Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Inti dari pernyataan Oracle SQL adalah pilih, masukkan, mengemas kini dan memadam, serta aplikasi fleksibel dari pelbagai klausa. Adalah penting untuk memahami mekanisme pelaksanaan di sebalik pernyataan, seperti pengoptimuman indeks. Penggunaan lanjutan termasuk subqueries, pertanyaan sambungan, fungsi analisis, dan PL/SQL. Kesilapan umum termasuk kesilapan sintaks, isu prestasi, dan isu konsistensi data. Amalan terbaik pengoptimuman prestasi melibatkan menggunakan indeks yang sesuai, mengelakkan pilih *, mengoptimumkan di mana klausa, dan menggunakan pembolehubah terikat. Menguasai Oracle SQL memerlukan amalan, termasuk penulisan kod, debugging, berfikir dan memahami mekanisme asas.
 Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Panduan Operasi Lapangan di MySQL: Tambah, mengubah suai, dan memadam medan. Tambahkan medan: alter table table_name tambah column_name data_type [not null] [default default_value] [primary kekunci] [AUTO_INCREMENT] Modify Field: Alter Table Table_Name Ubah suai column_name data_type [not null] [default default_value] [Kunci Utama]
 Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Pertanyaan bersarang adalah cara untuk memasukkan pertanyaan lain dalam satu pertanyaan. Mereka digunakan terutamanya untuk mendapatkan data yang memenuhi syarat kompleks, mengaitkan pelbagai jadual, dan mengira nilai ringkasan atau maklumat statistik. Contohnya termasuk mencari pekerja di atas gaji purata, mencari pesanan untuk kategori tertentu, dan mengira jumlah jumlah pesanan bagi setiap produk. Apabila menulis pertanyaan bersarang, anda perlu mengikuti: Tulis subqueries, tulis hasilnya kepada pertanyaan luar (dirujuk dengan alias atau sebagai klausa), dan mengoptimumkan prestasi pertanyaan (menggunakan indeks).
 Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Kekangan integriti pangkalan data Oracle dapat memastikan ketepatan data, termasuk: tidak null: nilai null dilarang; Unik: Keunikan menjamin, membolehkan nilai null tunggal; Kunci utama: kekangan utama utama, menguatkan unik, dan melarang nilai null; Kunci asing: Mengekalkan hubungan antara jadual, kunci asing merujuk kepada kunci utama jadual utama; Semak: Hadkan nilai lajur mengikut syarat.
