
 Peranti teknologi
AI
Biarkan Siri tidak lagi terencat akal! Apple mentakrifkan model sisi peranti baharu, yang 'jauh lebih baik daripada GPT-4 Ia menyingkirkan teks dan mensimulasikan maklumat skrin secara visual Model parameter minimum masih 5% lebih baik daripada sistem garis dasar.
Peranti teknologi
AI
Biarkan Siri tidak lagi terencat akal! Apple mentakrifkan model sisi peranti baharu, yang 'jauh lebih baik daripada GPT-4 Ia menyingkirkan teks dan mensimulasikan maklumat skrin secara visual Model parameter minimum masih 5% lebih baik daripada sistem garis dasar.
Biarkan Siri tidak lagi terencat akal! Apple mentakrifkan model sisi peranti baharu, yang 'jauh lebih baik daripada GPT-4 Ia menyingkirkan teks dan mensimulasikan maklumat skrin secara visual Model parameter minimum masih 5% lebih baik daripada sistem garis dasar.

Ditulis oleh Noah
Dihasilkan | 51CTO Technology Stack (WeChat ID: blog51cto)
Siri, yang selalu dikritik pengguna kerana "agak terencat akal", diselamatkan!
Siri merupakan salah seorang wakil dalam bidang pembantu suara pintar sejak dilahirkan, namun sejak sekian lama, prestasinya kurang memuaskan. Bagaimanapun, hasil penyelidikan terkini yang dikeluarkan oleh pasukan kecerdasan buatan Apple dijangka akan mengubah status quo dengan ketara. Keputusan ini menarik dan meningkatkan jangkaan yang besar untuk masa depan bidang ini.
Dalam kertas penyelidikan berkaitan, pakar AI Apple menerangkan sistem di mana Siri bukan sahaja dapat mengenali kandungan dalam imej, tetapi juga melakukan lebih banyak lagi, menjadi lebih pintar dan lebih berguna. Model berfungsi ini dipanggil ReALM, yang berdasarkan standard GPT 4.0 dan mempunyai keupayaan penanda aras yang lebih baik daripada GPT 4.0. Pakar ini percaya bahawa model yang mereka bangunkan digunakan untuk melaksanakan fungsi yang mereka bangunkan, yang boleh menjadikan Siri lebih pintar, lebih praktikal dan lebih sesuai untuk pelbagai senario.
1. Motivasi: Menyelesaikan resolusi rujukan entiti yang berbeza
Menurut pasukan penyelidik Apple: “Adalah sangat penting untuk membolehkan pembantu perbualan memahami konteks, termasuk penunjuk kandungan yang berkaitan skrin berdasarkan perkara yang mereka lihat adalah langkah penting untuk memastikan pengalaman dikendalikan suara.”
Sebagai contoh, semasa interaksi manusia-komputer, pengguna sering menyebut elemen atau kandungan tertentu pada skrin semasa perbualan, seperti mengarahkan pembantu suara Hubungi nombor telefon, navigasi ke tempat tertentu pada peta, buka apl atau halaman web tertentu dan banyak lagi. Jika pembantu perbualan tidak dapat memahami rujukan entiti di sebalik arahan pengguna, ia tidak akan dapat melaksanakan arahan tersebut dengan tepat.
Selain itu, fenomena rujukan kabur adalah perkara biasa dalam perbualan manusia Untuk mencapai interaksi manusia-komputer semula jadi dan memahami konteks dengan tepat apabila pengguna membuat pertanyaan tentang kandungan skrin dengan pembantu suara, keupayaan untuk menyelesaikan rujukan adalah penting.
Kelebihan model yang dipanggil ReALM (Resolusi Rujukan Sebagai Pemodelan Bahasa) yang disebut oleh Apple dalam kertas itu ialah ia boleh mempertimbangkan kandungan pada skrin pengguna dan tugas yang sedang dijalankan pada masa yang sama, dan menggunakan model bahasa yang besar untuk menyelesaikan masalah yang berbeza. Masalah penyelesaian rujukan entiti jenis (termasuk entiti perbualan dan bukan entiti perbualan).
Walaupun modaliti teks tradisional menyusahkan untuk mengendalikan entiti yang dipaparkan pada skrin, sistem ReALM menukar penghuraian rujukan kepada masalah pemodelan bahasa dan berjaya menggunakan LLM untuk mengendalikan rujukan entiti bukan perbualan pada skrin, iaitu sangat cekap. Bumi memudahkan matlamat ini. Dengan cara ini, ia dijangka mencapai pengalaman pengguna yang sangat pintar dan lebih mendalam.
2. Pembinaan semula: Menembusi batasan modaliti teks tradisional
Modaliti teks tradisional tidak sesuai untuk memproses entiti yang dipaparkan pada skrin kerana entiti pada skrin biasanya mengandungi maklumat visual yang kaya dan struktur susun atur, seperti imej , ikon , butang dan hubungan kedudukan relatifnya, dsb. Maklumat ini sukar untuk dinyatakan sepenuhnya dalam perihalan teks tulen.
Untuk menangani cabaran ini, sistem ReALM secara kreatif mencadangkan untuk membina semula skrin dengan menghuraikan entiti pada skrin dan maklumat kedudukannya, dan menjana perwakilan teks tulen yang boleh mencerminkan kandungan skrin secara visual.
Bahagian entiti akan ditanda khas supaya model bahasa memahami tempat entiti muncul dan teks di sekelilingnya, supaya ia boleh mensimulasikan "melihat" maklumat pada skrin dan memahami serta menghuraikan arahan pada skrin Menyediakan maklumat kontekstual yang diperlukan. Pendekatan ini merupakan percubaan pertama untuk menggunakan model bahasa yang besar untuk mengekod konteks daripada kandungan skrin, mengatasi masalah entiti skrin yang sukar dikendalikan dengan modaliti teks tradisional.
Secara khusus, agar model bahasa besar "memahami" dan memproses entiti yang dipaparkan pada skrin, sistem ReALM menggunakan langkah berikut:
Pertama, entiti dalam teks skrin diekstrak dengan bantuan pengesan data lapisan atas, Entiti ini akan mempunyai jenis, kotak sempadan dan senarai elemen teks bukan entiti yang mengelilingi entiti. Ini bermakna bahawa untuk setiap entiti visual pada skrin, sistem menangkap maklumat asasnya dan konteks di mana ia wujud.
Kemudian, ReALM secara inovatif mencadangkan algoritma untuk mengisih titik tengah kotak sempadan entiti dan objek sekeliling dalam susunan menegak (atas ke bawah) dan mendatar (kiri ke kanan), dan menyusunnya secara stabil . Jika jarak antara entiti adalah dekat, mereka dianggap berada pada baris yang sama dan dipisahkan oleh tab jika jarak melebihi jidar yang ditetapkan, mereka diletakkan pada baris seterusnya. Dengan cara ini, dengan menggunakan kaedah di atas secara berterusan, kandungan skrin boleh dikodkan ke dalam format teks biasa dari kiri ke kanan dan atas ke bawah, dengan berkesan mengekalkan hubungan spatial relatif antara entiti.
Dengan cara ini, maklumat visual skrin yang sukar diproses secara langsung oleh LLM ditukar kepada bentuk teks yang sesuai untuk input model bahasa, membolehkan LLM mengambil kira sepenuhnya kedudukan dan lokasi spesifik entiti skrin semasa memproses tugasan urutan ke urutan untuk mencapai pengenalpastian yang betul dan resolusi rujukan entiti skrin.
Ini menjadikan sistem ReALM bukan sahaja berprestasi baik dalam menyelesaikan masalah rujukan entiti dialog, tetapi juga menunjukkan peningkatan prestasi yang ketara apabila berurusan dengan entiti bukan dialog - iaitu entiti pada skrin.
3. Butiran: Takrifan tugas dan set data
Ringkasnya, tugas yang dihadapi oleh sistem ReALM adalah untuk mencari entiti yang berkaitan dengan pertanyaan pengguna semasa dalam koleksi entiti yang diberikan berdasarkan tugasan yang pengguna mahu lakukan melaksanakan.
Tugas ini distrukturkan sebagai soalan aneka pilihan untuk model bahasa yang besar, dan ia dijangka memilih satu atau lebih pilihan sebagai jawapan daripada entiti yang dipaparkan pada skrin pengguna. Sudah tentu, dalam beberapa kes jawapannya mungkin "tidak".
Malah, kertas penyelidikan membahagikan entiti yang terlibat dalam tugasan kepada tiga kategori:
1 Entiti skrin: merujuk kepada entiti yang kelihatan pada antara muka pengguna.
2 Entiti dialog: entiti yang berkaitan dengan kandungan perbualan, yang mungkin datang daripada ucapan pengguna sebelumnya (contohnya, jika pengguna menyebut "panggil ibu", kemasukan "ibu" dalam senarai kenalan ialah entiti yang berkaitan) , atau mungkin dijana oleh Pembantu maya disediakan dalam perbualan (seperti senarai tempat untuk dipilih oleh pengguna).
3 Entiti latar belakang: entiti berkaitan yang berasal daripada proses latar belakang dan tidak semestinya ditunjukkan secara langsung dalam paparan skrin pengguna atau interaksi dengan pembantu maya, seperti jam penggera yang akan berbunyi secara lalai atau muzik dimainkan di latar belakang.
Bagi set data yang digunakan untuk melatih dan menguji ReALM, ia terdiri daripada data sintetik dan data beranotasi manual, yang juga boleh dibahagikan kepada tiga kategori:
Pertama, set data dialog: mengandungi interaksi antara pengguna dan ejen Titik data untuk entiti berkaitan. Data ini dikumpul dengan meminta penilai melihat tangkapan skrin yang mengandungi senarai entiti sintetik dan meminta mereka memberikan pertanyaan yang menunjuk secara eksplisit kepada mana-mana entiti yang dipilih dalam senarai.
Set data sintetik kedua: Gunakan kaedah penjanaan templat untuk mendapatkan data Kaedah ini amat berguna apabila pertanyaan pengguna dan jenis entiti mencukupi untuk menentukan rujukan tanpa bergantung pada penerangan terperinci. Set data sintetik juga boleh mengandungi berbilang entiti yang sepadan dengan pertanyaan yang sama.
Ketiga, set data skrin: Ia merangkumi terutamanya data entiti yang dipaparkan pada skrin pengguna pada masa ini Setiap bahagian data mengandungi pertanyaan pengguna, senarai entiti dan entiti yang betul (atau koleksi entiti) yang sepadan dengan pertanyaan. Maklumat tentang setiap entiti termasuk jenis entiti dan sifat lain seperti nama dan butiran teks lain yang dikaitkan dengan entiti (cth., label dan masa jam penggera).
Untuk titik data yang mengandungi konteks berkaitan skrin, maklumat konteks disediakan dalam bentuk kotak sempadan entiti dan senarai objek lain yang mengelilingi entiti, bersama-sama dengan maklumat atribut seperti jenis, kandungan teks dan lokasi objek sekeliling ini. Saiz keseluruhan set data dibahagikan kepada set latihan dan set ujian mengikut kategori, dan setiap satu mempunyai saiz tertentu.
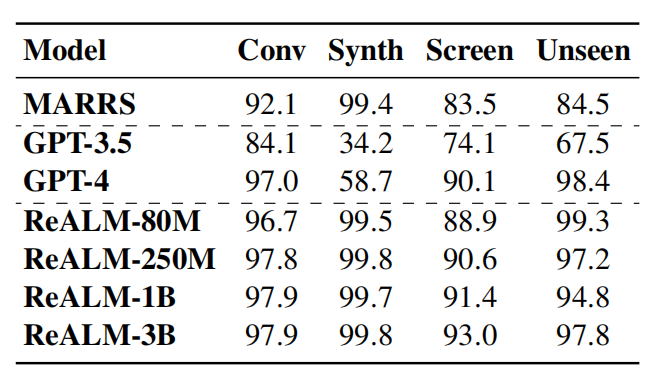
4. Keputusan: Model terkecil juga mencapai peningkatan prestasi 5%
Dalam ujian penanda aras, Apple membandingkan sistemnya sendiri dengan GPT 3.5 dan GPT 4.0. Model ReALM menunjukkan daya saing yang sangat baik dalam menyelesaikan pelbagai jenis tugasan penghuraian rujukan.
 Gambar
Gambar
Menurut kertas kerja, walaupun versi dengan parameter paling sedikit dalam ReALM telah mencapai peningkatan prestasi lebih daripada 5% berbanding sistem garis dasar. Pada versi model yang lebih besar, ReALM jelas mengatasi GPT-4. Terutamanya apabila memproses entiti yang dipaparkan pada skrin, apabila saiz model meningkat, peningkatan prestasi ReALM pada set data skrin menjadi lebih ketara.
Selain itu, prestasi model ReALM agak hampir dengan GPT-4 dalam senario pembelajaran sifar pukulan dalam bidang baharu. Apabila memproses pertanyaan dalam medan tertentu, model ReALM berprestasi lebih tepat daripada GPT-4 kerana penalaan halus berdasarkan permintaan pengguna.
Sebagai contoh, untuk permintaan pengguna untuk melaraskan kecerahan, GPT-4 hanya mengaitkan permintaan dengan tetapan, mengabaikan bahawa peranti rumah pintar yang sedia ada di latar belakang juga merupakan entiti yang berkaitan, dan ReALM dilatih dengan khusus domain. data , boleh lebih memahami dan menyelesaikan masalah rujukan dengan lebih baik dalam bidang khusus tersebut.
“Kami menunjukkan bahawa RealLM mengatasi kaedah sebelumnya dan mencapai hasil yang setanding walaupun ketika berurusan dengan rujukan dalam skrin semata-mata berdasarkan medan teks, walaupun mempunyai parameter yang jauh lebih sedikit daripada LLM terkini, GPT-4 . Tahap prestasi yang agak tinggi Selain itu, RealLM berprestasi lebih baik daripada GPT-4 untuk sebutan pengguna dalam bidang tertentu Oleh itu, RealLM boleh dikatakan sesuai untuk membangunkan persekitaran aplikasi praktikal dan boleh dilaksanakan secara tempatan pada peranti sambil memastikan prestasi itu. tidak terjejas. Penyelesaian pilihan untuk pengendalian sistem resolusi rujukan yang cekap Selain itu, para penyelidik juga menyatakan bahawa dalam senario aplikasi praktikal dengan sumber terhad, tindak balas kependaman rendah, atau melibatkan integrasi berbilang peringkat seperti panggilan API, satu besar-. Model hujung ke hujung skala selalunya tidak berkenaan.
Dalam konteks ini, sistem ReALM yang direka bentuk secara modular mempunyai lebih banyak kelebihan, membolehkan modul resolusi rujukan asal diganti dan dinaik taraf dengan mudah tanpa menjejaskan seni bina keseluruhan, sambil memberikan potensi pengoptimuman dan Kebolehtafsiran yang lebih baik.
Menghadapi masa hadapan, hala tuju penyelidikan menunjukkan kaedah yang lebih kompleks, seperti membahagikan kawasan skrin kepada grid dan mengekodkan kedudukan ruang relatif dalam bentuk teks Walaupun ia agak mencabar, ini adalah jalan yang menjanjikan untuk diterokai.
5. Ditulis pada penghujungnya
Dalam bidang kecerdasan buatan, walaupun Apple sentiasa lebih berhati-hati, ia juga melabur secara senyap. Sama ada model besar multi-modal MM1, atau alat penjanaan animasi dipacu AI Keyframer, atau ReALM hari ini, pasukan penyelidik Apple terus mencapai kejayaan teknologi.
Penonton seperti Google, Microsoft, Amazon dan pesaing lain menambahkan AI pada carian, perkhidmatan awan dan perisian pejabat, melenturkan otot mereka satu demi satu. Apple jelas cuba untuk tidak ketinggalan. Memandangkan hasil pelaksanaan AI generatif terus muncul, Apple telah mempercepatkan langkah mengejarnya. Orang yang biasa dengan perkara itu telah lama mendedahkan bahawa Apple akan menumpukan pada bidang kecerdasan buatan pada Persidangan Pembangun Global pada bulan Jun, dan strategi kecerdasan buatan baharu mungkin akan menjadi kandungan teras peningkatan iOS 18. Pada masa itu, ia mungkin membawa anda kejutan.
Pautan rujukan:
https://apple.slashdot.org/story/24/04/01/1959205/apple-ai-researchers-boast-useful-on-device-model-that-substantially-outperforms -gpt-4
https://arxiv.org/pdf/2403.20329.pdf
Atas ialah kandungan terperinci Biarkan Siri tidak lagi terencat akal! Apple mentakrifkan model sisi peranti baharu, yang 'jauh lebih baik daripada GPT-4 Ia menyingkirkan teks dan mensimulasikan maklumat skrin secara visual Model parameter minimum masih 5% lebih baik daripada sistem garis dasar.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara menyesuaikan pertukaran terbuka bijan ke dalam bahasa Cina
Mar 04, 2025 pm 11:51 PM
Cara menyesuaikan pertukaran terbuka bijan ke dalam bahasa Cina
Mar 04, 2025 pm 11:51 PM
Bagaimana cara menyesuaikan pertukaran terbuka bijan ke bahasa Cina? Tutorial ini merangkumi langkah -langkah terperinci mengenai komputer dan telefon bimbit Android, dari penyediaan awal hingga proses operasi, dan kemudian menyelesaikan masalah biasa, membantu anda dengan mudah menukar antara muka pertukaran terbuka ke Cina dan cepat memulakan dengan platform perdagangan.
 Adakah saya perlu menggunakan Flexbox di tengah gambar bootstrap?
Apr 07, 2025 am 09:06 AM
Adakah saya perlu menggunakan Flexbox di tengah gambar bootstrap?
Apr 07, 2025 am 09:06 AM
Terdapat banyak cara untuk memusatkan gambar bootstrap, dan anda tidak perlu menggunakan Flexbox. Jika anda hanya perlu berpusat secara mendatar, kelas pusat teks sudah cukup; Jika anda perlu memusatkan elemen secara menegak atau berganda, Flexbox atau Grid lebih sesuai. Flexbox kurang serasi dan boleh meningkatkan kerumitan, manakala grid lebih berkuasa dan mempunyai kos pengajian yang lebih tinggi. Apabila memilih kaedah, anda harus menimbang kebaikan dan keburukan dan memilih kaedah yang paling sesuai mengikut keperluan dan keutamaan anda.
 Cara Mengira C-SubScript 3 Subscript 5 C-SubScript 3 Subscript 5 Algoritma Tutorial
Apr 03, 2025 pm 10:33 PM
Cara Mengira C-SubScript 3 Subscript 5 C-SubScript 3 Subscript 5 Algoritma Tutorial
Apr 03, 2025 pm 10:33 PM
Pengiraan C35 pada dasarnya adalah matematik gabungan, yang mewakili bilangan kombinasi yang dipilih dari 3 dari 5 elemen. Formula pengiraan ialah C53 = 5! / (3! * 2!), Yang boleh dikira secara langsung oleh gelung untuk meningkatkan kecekapan dan mengelakkan limpahan. Di samping itu, memahami sifat kombinasi dan menguasai kaedah pengiraan yang cekap adalah penting untuk menyelesaikan banyak masalah dalam bidang statistik kebarangkalian, kriptografi, reka bentuk algoritma, dll.
 10 platform perdagangan mata wang maya teratas 2025 Aplikasi Perdagangan Cryptocurrency Kedudukan Sepuluh Teratas
Mar 17, 2025 pm 05:54 PM
10 platform perdagangan mata wang maya teratas 2025 Aplikasi Perdagangan Cryptocurrency Kedudukan Sepuluh Teratas
Mar 17, 2025 pm 05:54 PM
Sepuluh Platform Perdagangan Mata Wang Maya 2025: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6 Coinbase, 7. Kucoin, 8. Crypto.com, 9. Keselamatan, kecairan, yuran pengendalian, pemilihan mata wang, antara muka pengguna dan sokongan pelanggan harus dipertimbangkan ketika memilih platform.
 10 platform perdagangan cryptocurrency teratas, sepuluh aplikasi platform perdagangan mata wang yang disyorkan
Mar 17, 2025 pm 06:03 PM
10 platform perdagangan cryptocurrency teratas, sepuluh aplikasi platform perdagangan mata wang yang disyorkan
Mar 17, 2025 pm 06:03 PM
Sepuluh platform perdagangan cryptocurrency teratas termasuk: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8 crypto.com, 9. Keselamatan, kecairan, yuran pengendalian, pemilihan mata wang, antara muka pengguna dan sokongan pelanggan harus dipertimbangkan ketika memilih platform.
 Apakah platform mata wang digital yang selamat dan boleh dipercayai?
Mar 17, 2025 pm 05:42 PM
Apakah platform mata wang digital yang selamat dan boleh dipercayai?
Mar 17, 2025 pm 05:42 PM
Platform mata wang digital yang selamat dan boleh dipercayai: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6 Coinbase, 7. Kucoin, 8 crypto.com, 9. Bitfinex, 10. Keselamatan, kecairan, yuran pengendalian, pemilihan mata wang, antara muka pengguna dan sokongan pelanggan harus dipertimbangkan ketika memilih platform.
 Fungsi Penggunaan Fungsi Jarak Jarak Jarak Penggunaan C Tutorial Penggunaan
Apr 03, 2025 pm 10:27 PM
Fungsi Penggunaan Fungsi Jarak Jarak Jarak Penggunaan C Tutorial Penggunaan
Apr 03, 2025 pm 10:27 PM
STD :: Unik menghilangkan elemen pendua bersebelahan di dalam bekas dan menggerakkannya ke akhir, mengembalikan iterator yang menunjuk ke elemen pendua pertama. STD :: Jarak mengira jarak antara dua iterators, iaitu bilangan elemen yang mereka maksudkan. Kedua -dua fungsi ini berguna untuk mengoptimumkan kod dan meningkatkan kecekapan, tetapi terdapat juga beberapa perangkap yang perlu diberi perhatian, seperti: STD :: Unik hanya berkaitan dengan unsur -unsur pendua yang bersebelahan. STD :: Jarak kurang cekap apabila berurusan dengan Iterator Akses Bukan Rawak. Dengan menguasai ciri -ciri dan amalan terbaik ini, anda boleh menggunakan sepenuhnya kuasa kedua -dua fungsi ini.
 Bagaimana untuk melaksanakan susun atur penyesuaian kedudukan paksi y dalam anotasi web?
Apr 04, 2025 pm 11:30 PM
Bagaimana untuk melaksanakan susun atur penyesuaian kedudukan paksi y dalam anotasi web?
Apr 04, 2025 pm 11:30 PM
Algoritma Adaptif Kedudukan Y-Axis untuk Fungsi Anotasi Web Artikel ini akan meneroka cara melaksanakan fungsi anotasi yang serupa dengan dokumen perkataan, terutama bagaimana menangani selang antara anotasi ...
