

Pembelajaran pengukuhan Kuaishou dan cadangan pelbagai tugas

1. Pelakon-Pengkritik Terkekang Dua Peringkat untuk Syor Video Pendek
Karya pertama dibangunkan sendiri oleh Kuaishou, terutamanya menyasarkan senario pelbagai tugas yang terhad.
1. Senario pengesyoran pelbagai tugas video pendek

Kerja ini ditujukan terutamanya kepada senario video pendek yang lebih profesional, terbahagi kepada tempoh tontonan dan interaksi, yang merupakan interaksi yang lebih biasa Termasuk suka, koleksi, ikuti dan komen, setiap maklum balas ini mempunyai ciri tersendiri. Melalui pemerhatian sistem dalam talian, kami mendapati bahawa isyarat tempoh sebenarnya sangat jarang, dan kerana ia adalah nilai berterusan, adalah sukar untuk mengukur tahap minat pengguna dengan tepat. Sebaliknya, isyarat interaktif lebih kaya, termasuk suka, kegemaran, ikutan dan ulasan ini boleh dibahagikan kepada dua kategori: pilihan khalayak dan maklum balas tingkah laku. Semasa proses pengoptimuman, kami menganggap isyarat ini sebagai matlamat utama, dan interaksi sebagai pengoptimuman tambahan Kami cuba memastikan bahawa isyarat interaktif tidak hilang sebagai matlamat keseluruhan pengoptimuman. Sebaliknya, nombor interaksi adalah lebih jarang, dan kerana tiada standard bersatu, adalah sukar untuk mengukur minat pengguna dengan tepat. Untuk meningkatkan kesan, kami perlu menjalankan pengoptimuman tertentu supaya ia boleh dioptimumkan sebagai matlamat utama dalam sistem kami, sambil memastikan integriti data interaktif sebagai tambahan kepada matlamat keseluruhan.

Dengan cara ini, masalah itu boleh digambarkan dengan sangat intuitif sebagai masalah pengoptimuman yang terhad. Terdapat matlamat utama untuk mengoptimumkan utiliti, dan matlamat tambahan adalah untuk memenuhi batas bawah. Berbeza dengan masalah pengoptimuman Pareto biasa, di sini kita perlu memberi keutamaan.
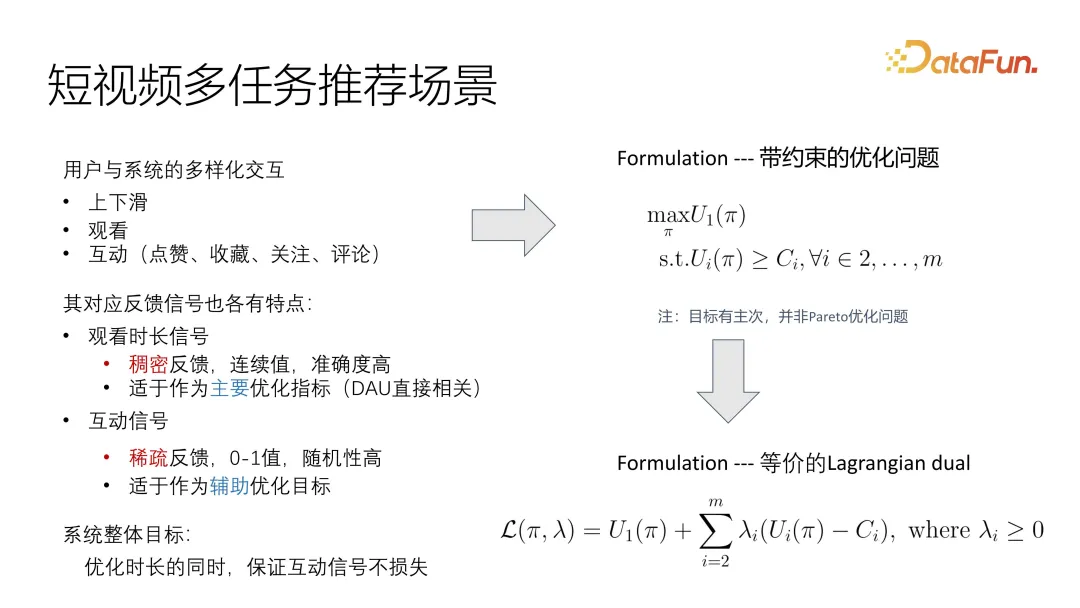
Cara biasa untuk menyelesaikan masalah ini ialah menukarnya kepada masalah dwi Lagrangian, supaya ia boleh disepadukan terus ke dalam fungsi objektif yang dioptimumkan sama ada pengoptimuman keseluruhan atau pengoptimuman berselang-seli, ia boleh Optimumkan matlamat keseluruhan. Sudah tentu, adalah perlu untuk mengawal korelasi dan faktor-faktor yang mempengaruhi matlamat yang berbeza.
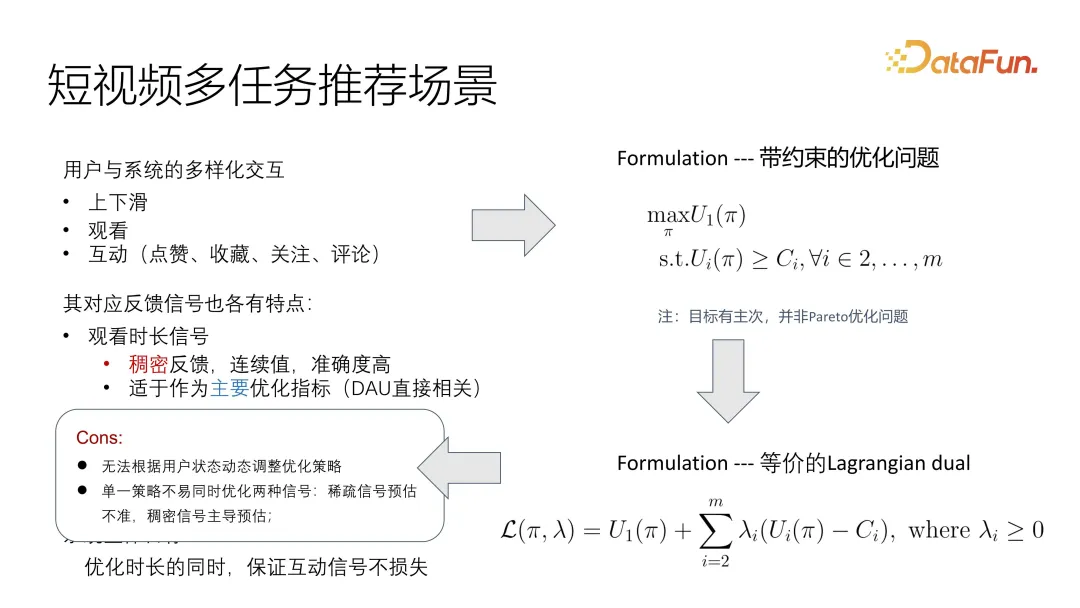
Masih terdapat beberapa masalah dalam rumusan pemerhatian ini, kerana status pengguna berubah secara dinamik, menjadikannya berubah dengan cepat dalam senario video pendek. Di samping itu, kerana isyarat tidak seragam, terutamanya pengoptimuman sasaran utama dan pengoptimuman sasaran tambahan sianosis mempunyai masalah pengedaran yang sangat tidak konsisten, sukar untuk menangani penyelesaian sedia ada. Jika anda menyatukannya menjadi fungsi sasaran, salah satu isyarat mungkin menguasai isyarat lain.
2. Pembelajaran Pengukuhan Pelbagai Tugas
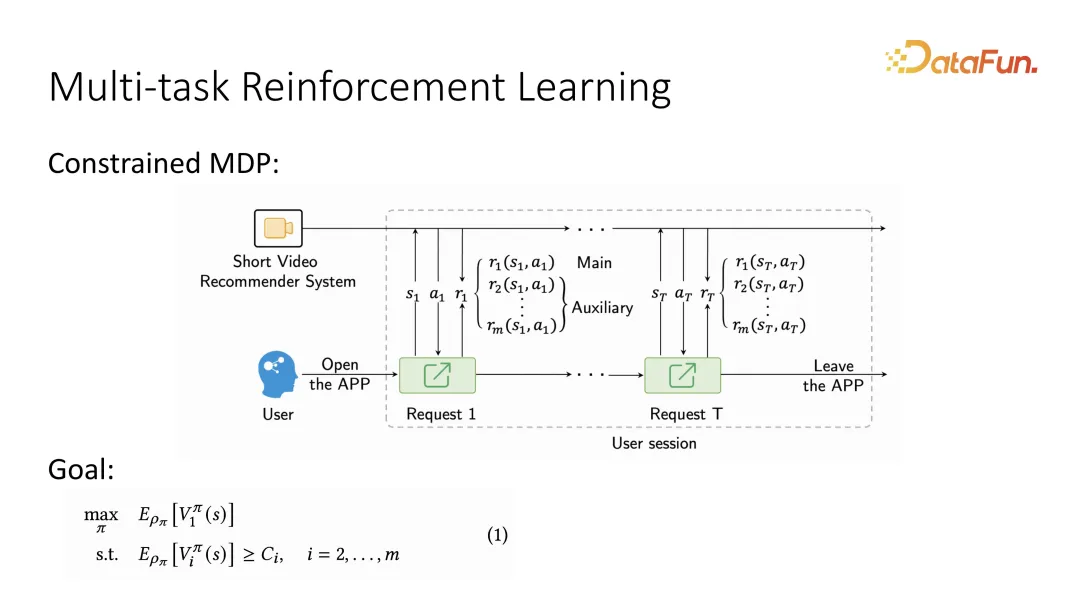
Berdasarkan perkara pertama, memandangkan perubahan dinamik pengguna, masalah itu sering digambarkan sebagai MDP, iaitu urutan interaksi bergantian antara pengguna dan sistem, dan turutan ini Selepas menggambarkannya sebagai Proses Keputusan Markov, ia boleh diselesaikan menggunakan kaedah pembelajaran pengukuhan. Secara khusus, selepas menerangkan Proses Keputusan Markov, kerana ia juga perlu untuk membezakan matlamat utama dan matlamat tambahan, adalah perlu untuk membuat kenyataan tambahan bahawa apabila maklum balas pengguna diberikan, dua matlamat yang berbeza mesti dibezakan mungkin berbilang matlamat tambahan. Apabila pembelajaran peneguhan mentakrifkan matlamat pengoptimuman jangka panjang, ia mentakrifkan matlamat utama untuk dioptimumkan sebagai fungsi nilai jangka panjang, dipanggil fungsi nilai. Begitu juga, untuk sasaran tambahan, terdapat juga fungsi nilai yang sepadan. Setara dengan maklum balas setiap pengguna, akan ada penilaian nilai jangka panjang Berbanding dengan fungsi utiliti sebelumnya, ia kini telah menjadi fungsi nilai jangka panjang.
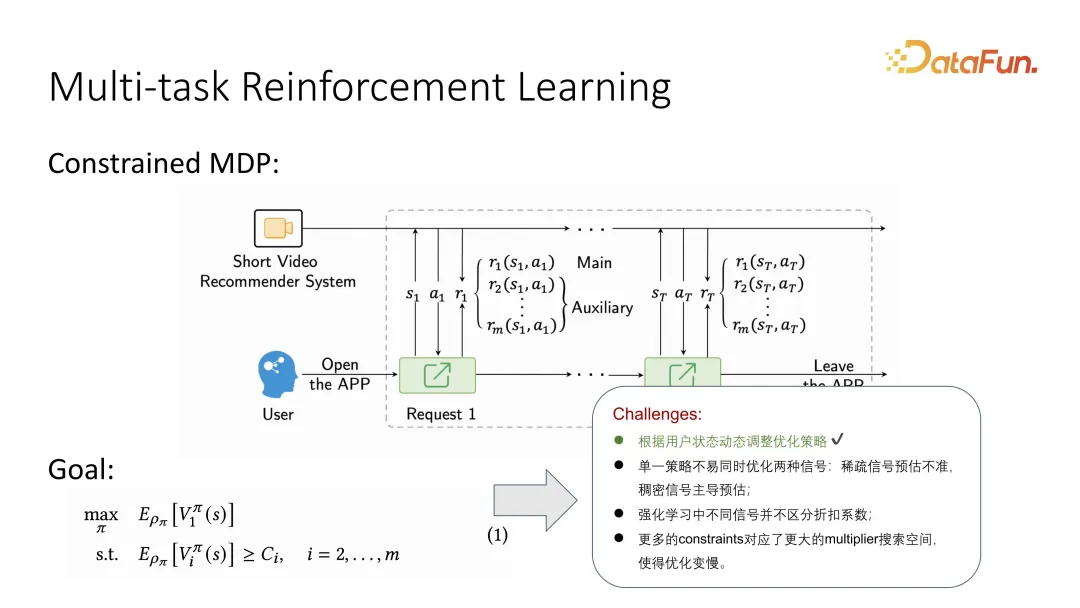
Begitu juga, beberapa masalah baharu akan timbul apabila digabungkan dengan pembelajaran peneguhan, seperti bagaimana pembelajaran peneguhan membezakan pekali diskaun yang berbeza. Di samping itu, apabila lebih banyak kekangan diperkenalkan, ruang carian untuk parameter menjadi lebih besar, menjadikan pembelajaran pengukuhan lebih sukar.
3. Penyelesaian: Pengoptimuman Pelbagai Kritik Dua Peringkat

Penyelesaian untuk kerja ini adalah untuk membahagikan keseluruhan pengoptimuman kepada dua peringkat Peringkat pertama mengoptimumkan objektif tambahan, dan peringkat kedua mengoptimumkan objektif utama.
Dalam peringkat pertama pengoptimuman sasaran tambahan, kaedah pengoptimuman pengkritik pelakon biasa digunakan Untuk pengoptimuman sasaran tambahan seperti suka dan ikuti, seorang pengkritik dioptimumkan untuk menganggarkan kualiti keadaan semasa. Selepas anggaran nilai jangka panjang adalah tepat, anda boleh menggunakan fungsi nilai untuk membimbing pembelajarannya apabila mengoptimumkan pelakon. Formula (2) ialah pengoptimuman pengkritik, dan formula (3) ialah pengoptimuman pelakon Untuk pengoptimuman pengkritik, keadaan semasa, keadaan seterusnya dan pensampelan tindakan semasa akan digunakan semasa latihan. . Menurut persamaan Bellman, tindakan itu boleh diperolehi, dan ditambah dengan anggaran nilai keadaan masa hadapan, ia harus hampir dengan anggaran keadaan semasa Dengan cara ini, pengoptimuman boleh mendekati anggaran nilai jangka panjang yang tepat . Apabila membimbing pembelajaran aktor, iaitu mengesyorkan pembelajaran dasar, fungsi kelebihan digunakan. Fungsi kelebihan merujuk kepada sama ada kesan tindakan tertentu lebih kuat daripada anggaran purata ini dipanggil garis dasar. Lebih besar Kelebihan, lebih baik tindakan, dan lebih besar kebarangkalian untuk menggunakan strategi yang disyorkan ini. Ini adalah peringkat pertama, pengoptimuman matlamat tambahan.

Peringkat kedua adalah untuk mengoptimumkan matlamat utama, kami menggunakan tempoh. Sasaran tambahan menggunakan strategi anggaran apabila mengekang sasaran utama Kami berharap bahawa output pengedaran tindakan oleh sasaran utama adalah sedekat mungkin dengan sasaran tambahan yang berbeza Selagi kami terus mendekati sasaran tambahan, hasil daripada bantuan sasaran tidak boleh terlalu buruk. Selepas mendapat rumusan anggaran, penyelesaian bentuk tertutup boleh diperolehi melalui penyiapan segi empat sama, iaitu dengan cara berwajaran. Sebenarnya tidak banyak perbezaan antara kaedah pengoptimuman pengkritik pelakon keseluruhan matlamat utama pada peringkat pengkritik dan peringkat anggaran fungsi nilai. Tetapi dalam kes pelakon, kami memperkenalkan pemberat yang diperoleh daripada penyelesaian bentuk tertutup. Maksud berat ini ialah lebih besar faktor impak yang sepadan dengan strategi tambahan I tertentu, lebih besar impaknya terhadap berat keseluruhan. Kami berharap pengagihan keluaran dasar adalah sehampir mungkin dengan purata semua dasar sasaran tambahan Fenomena ini berlaku apabila tingkah laku penyelesaian bentuk tertutup diperolehi.
4 Eksperimen
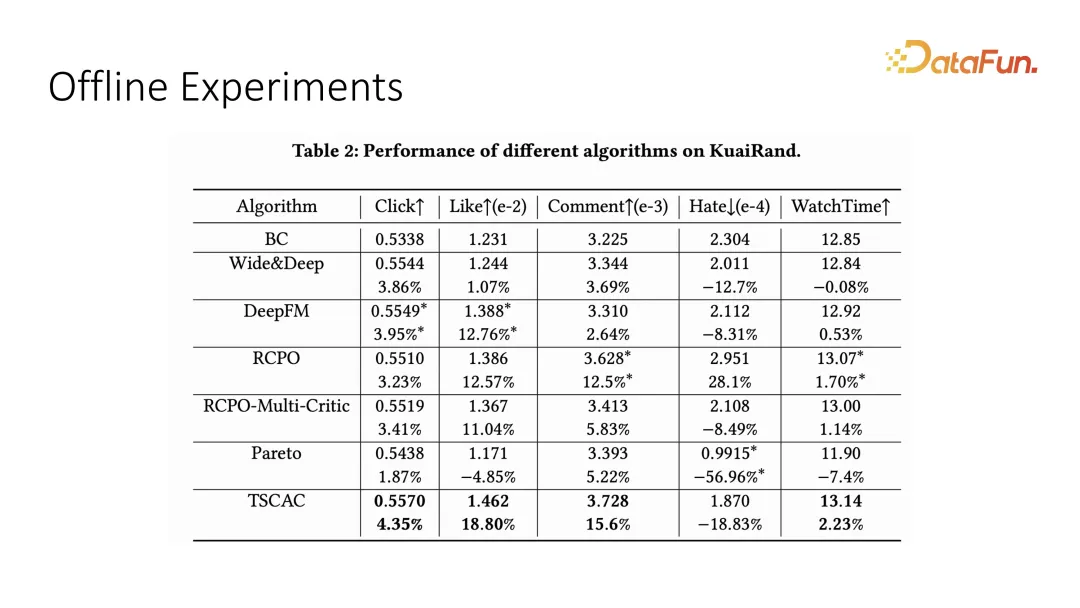
Kami menguji kesan pengoptimuman berbilang objektif pada set data luar talian. suka, komen dan benci dan penunjuk interaktif lain. Dapat dilihat bahawa pelakon-pengkritik dua peringkat yang kami cadangkan boleh mencapai hasil yang optimum.
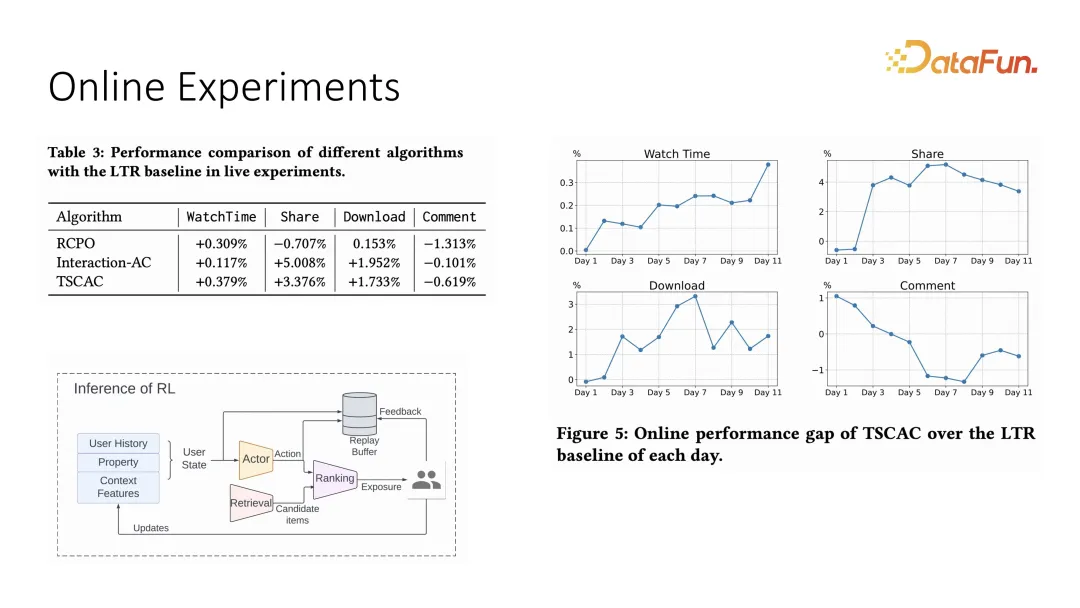
Begitu juga, kami juga telah melakukan eksperimen perbandingan yang sepadan dalam sistem dalam talian Penetapan sistem dalam talian menggunakan model pengesyoran pelakon tambah kedudukan, dan kedudukan akhir ditentukan oleh setiap item dan Hasil darab dalam bagi pemberat. Ia juga boleh dilihat daripada percubaan dalam talian bahawa masa menonton boleh mengekang interaksi lain sambil bertambah baik Berbanding dengan strategi pengoptimuman sebelumnya, ia boleh mengekang penunjuk interaksi dengan lebih baik.
Di atas adalah pengenalan kepada karya pertama.
2. Cadangan Pelbagai Tugas dengan Pembelajaran Pengukuhan
Kerja kedua juga adalah penerapan pembelajaran pengukuhan dalam pengoptimuman pelbagai tugas, tetapi ini adalah pengoptimuman yang lebih tradisional. Kerja ini adalah projek bersama antara Kuaishou dan City University of Hong Kong Pengarang pertama ialah Liu Ziru.
1. Latar Belakang dan Motivasi
Masalah utama yang dibincangkan dalam kerja ini ialah latihan bersama berbilang tugasan biasa kaedah akan dipertimbangkan, dan dimensi sesi, iaitu perubahan dinamik jangka panjang, akan diabaikan. RMTL yang dicadangkan dalam kerja ini mengubah kaedah pemberat melalui ramalan jangka panjang.
2. Rumusan Masalah
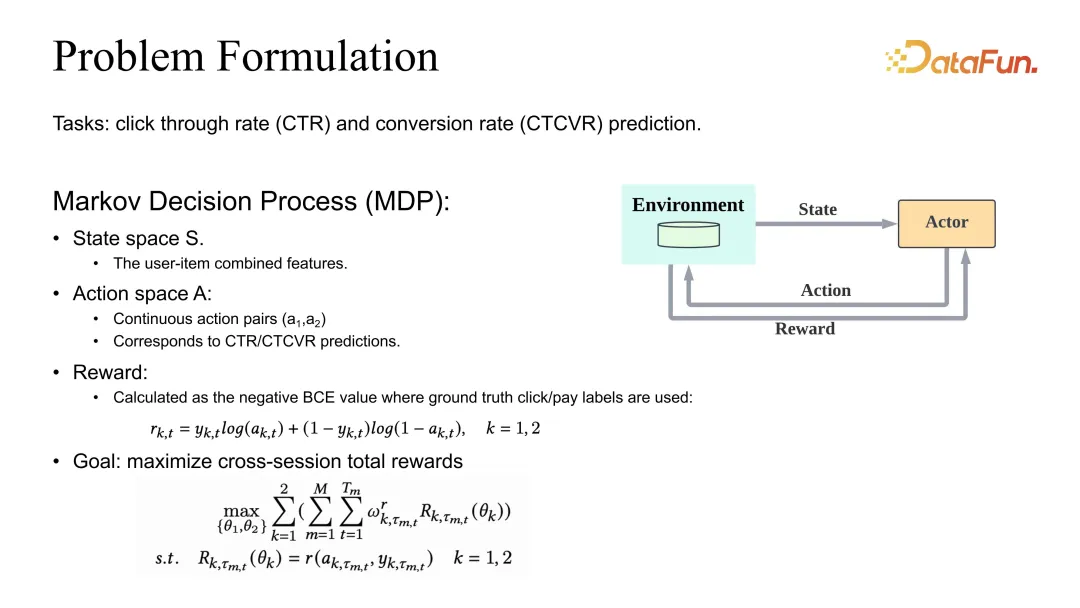
Tetapan masalah adalah untuk menentukan pengoptimuman bersama anggaran CTR dan CVR. Kami juga mempunyai takrifan MDP (Proses Keputusan Markov), tetapi di sini tindakan itu bukan lagi senarai cadangan, tetapi anggaran CTR dan CVR yang sepadan. Jika anggaran adalah tepat, ganjaran hendaklah ditakrifkan sebagai BCE atau sebarang kerugian munasabah yang sepadan. Dari segi definisi matlamat keseluruhan, ia secara amnya ditakrifkan sebagai pemberat tugasan yang berbeza dan kemudian keseluruhan sesi dan semua sampel data dijumlahkan.
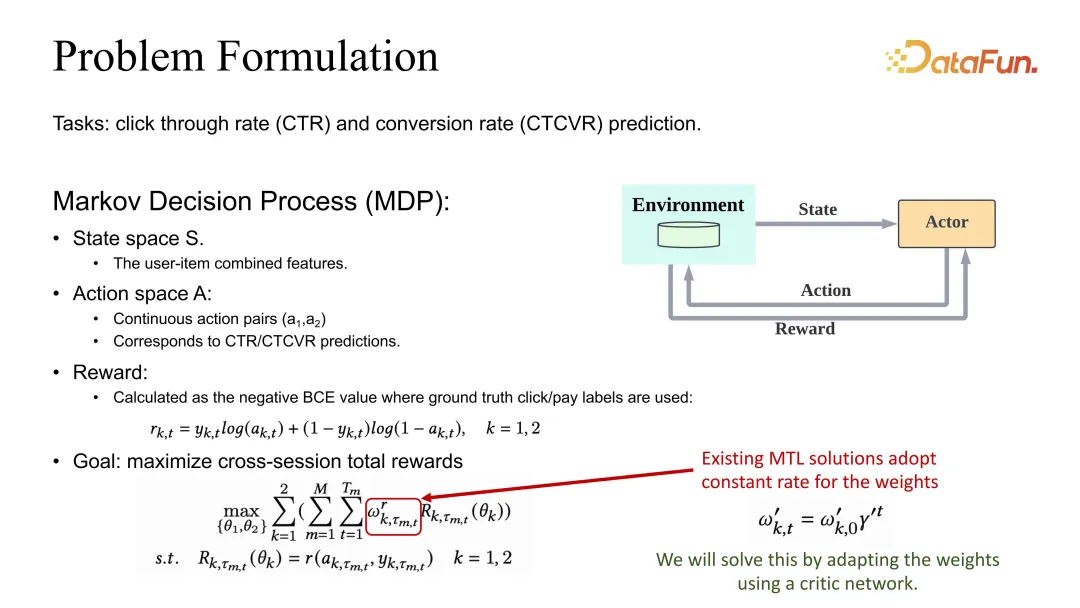
Anda boleh lihat selain diskaun Gamma, pekali beratnya juga akan dipengaruhi oleh pekali yang perlu dilaraskan.
3. Rangka Kerja Penyelesaian
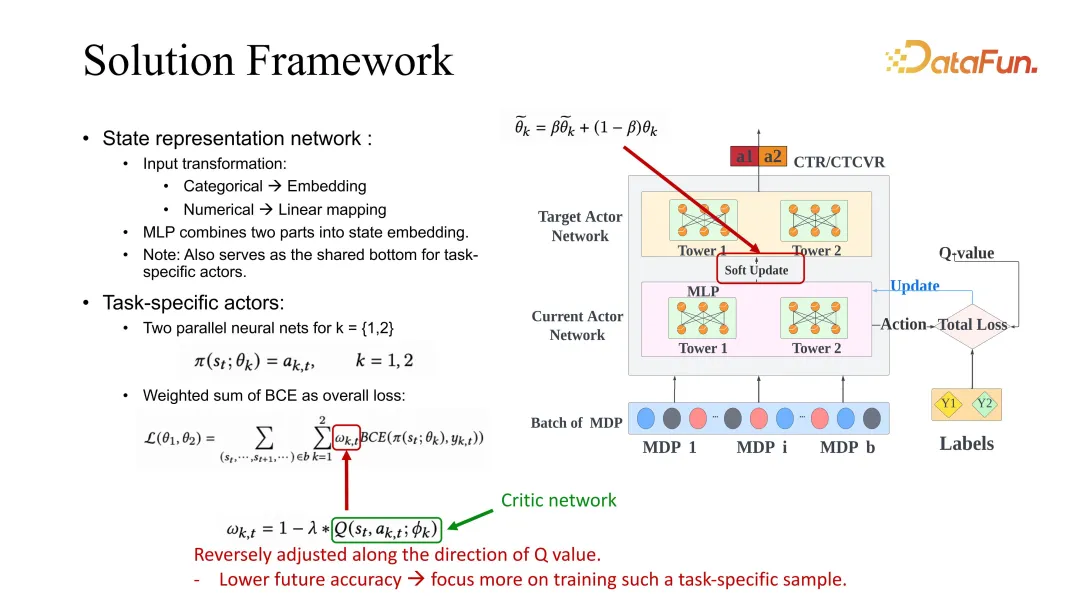
Penyelesaian kami adalah untuk membuat pelarasan pekali ini berkaitan dengan anggaran dimensi sesi. Tulang belakang ESMM diberikan di sini Sudah tentu, penggunaan garis dasar lain juga biasa dan boleh diperbaiki menggunakan kaedah kami.
Mari perkenalkan ESMM secara terperinci Pertama, terdapat pelakon khusus tugasan Setiap tugas akan mempunyai sasaran dan pengoptimuman pelakon semasa, rangka kerja yang serupa dengan pengkritik pelakon yang disebutkan sebelum ini. Semasa proses pengoptimuman, kehilangan BCE perlu melaraskan berat khusus tugas apabila membimbing pembelajaran pelakon. Dalam penyelesaian kami, berat ini perlu diubah sewajarnya berdasarkan penilaian nilai masa hadapan. Maksud tetapan ini ialah jika nilai penilaian masa depan lebih tinggi, ini bermakna keadaan semasa dan tindakan semasa adalah lebih tepat, dan pembelajarannya boleh diperlahankan. Sebaliknya, jika ramalan masa depan adalah buruk, ini bermakna model itu tidak optimistik tentang masa depan keadaan dan tindakan, dan pembelajarannya harus ditingkatkan dengan cara ini. Penilaian masa depan di sini juga menggunakan rangkaian pengkritik yang disebutkan di atas untuk pembelajaran.
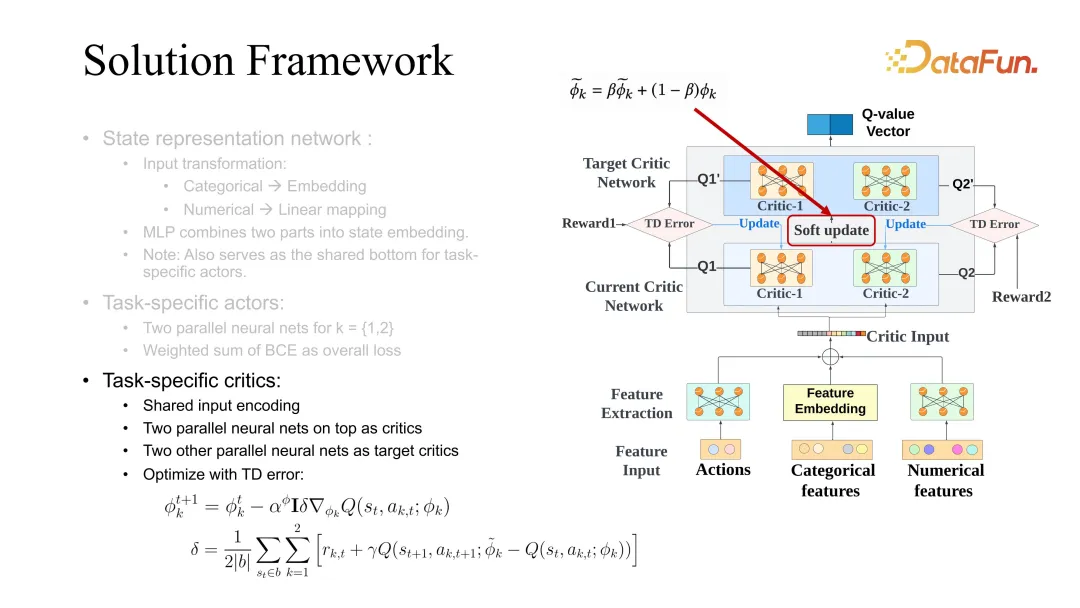
pengkritik juga menggunakan perbezaan antara keadaan masa depan dan keadaan semasa, tetapi ia berbeza daripada fungsi nilai Pembelajaran perbezaan di sini menggunakan fungsi Q, yang memerlukan penilaian bersama keadaan dan tindakan . Apabila mengemas kini pelakon, ia juga perlu menggunakan pembelajaran pelakon yang sepadan dengan tugas yang berbeza pada masa yang sama. Kemas kini lembut adalah helah umum, yang lebih berguna apabila meningkatkan kestabilan pembelajaran RL Ia biasanya mengoptimumkan sasaran dan pengkritik semasa pada masa yang sama.
4. Eksperimen
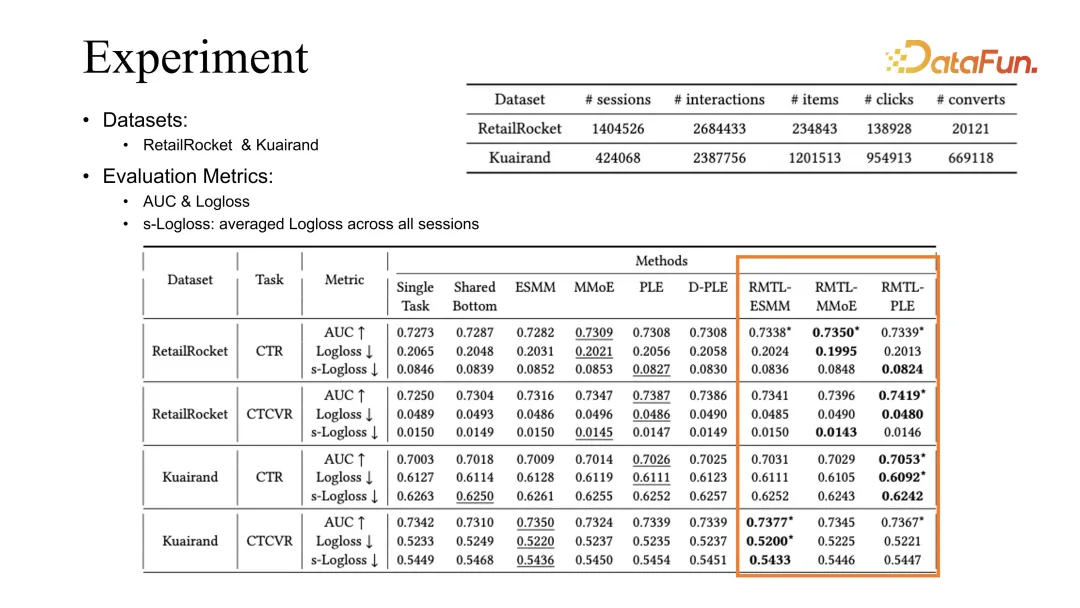
Melalui eksperimen perbandingan pada dua set data awam, dapat dilihat bahawa kaedah kami boleh digabungkan dengan kaedah pengoptimuman sedia ada termasuk ESMM, MMoE dan PLE, dan keputusan yang diperolehi boleh Garis asas sebelumnya telah diperbaiki.
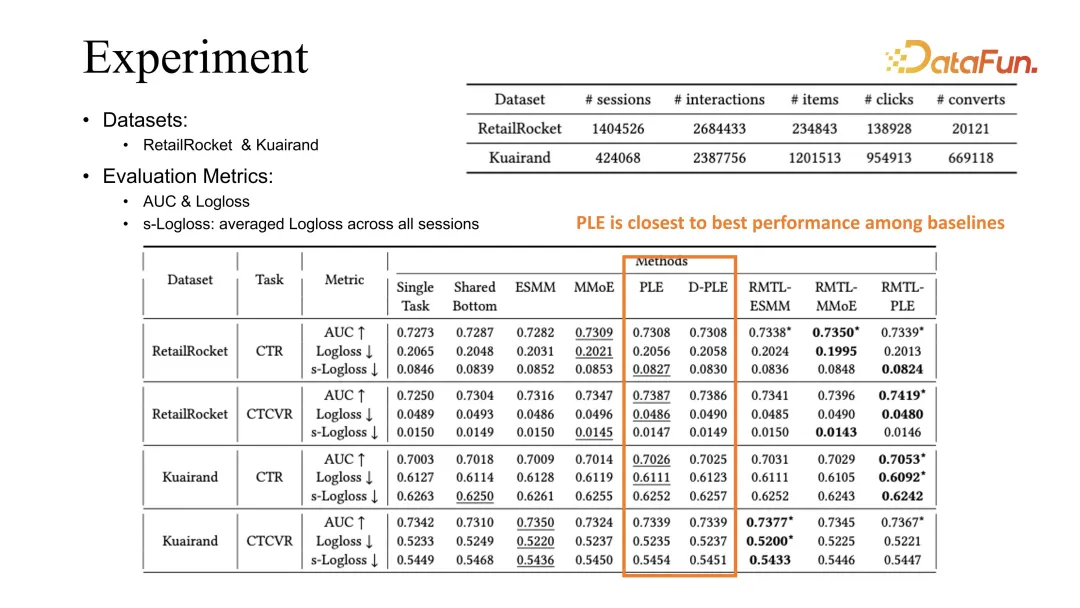
PLE ialah garis dasar terbaik dalam pemerhatian kami. Atribusi kami berdasarkan fenomena yang diperhatikan ialah PLE boleh mempelajari pembenaman dikongsi dengan lebih baik apabila mempelajari tugasan yang berbeza.
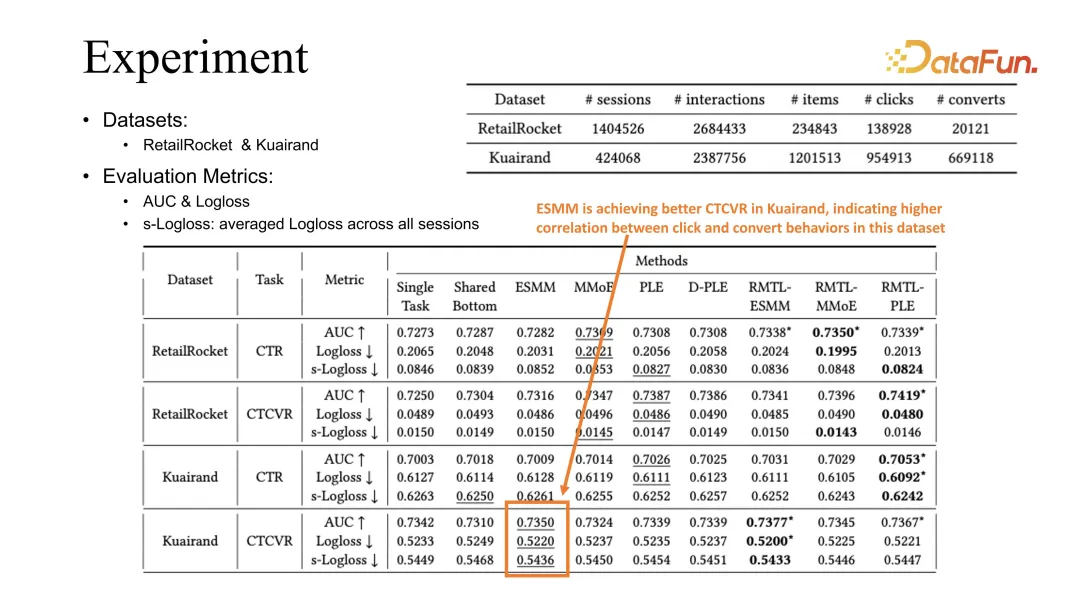
Sebaliknya, ESMM boleh mencapai penilaian CVR yang lebih baik pada tugas Kuairand. Kami membuat spekulasi bahawa ini berkaitan dengan korelasi yang lebih kukuh antara klik dan penukaran dalam set data ini.
5. Kajian Kebolehpindahan
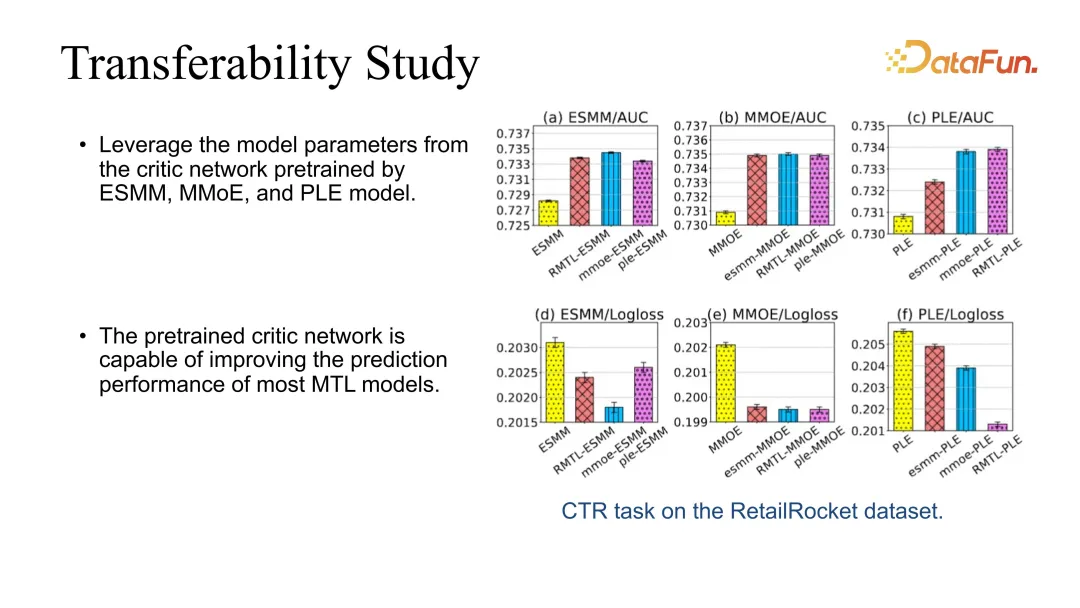
Selain itu, kami juga melakukan ujian kebolehpindahan, kerana pengkritik kami boleh dicantumkan terus ke model lain. Sebagai contoh, anda boleh mempelajari pengkritik pelakon melalui RMTL yang paling asas, dan kemudian menggunakan pengkritik untuk meningkatkan prestasi model lain secara langsung. Kami mendapati bahawa kesannya boleh diperbaiki secara stabil semasa cantuman.
6. Kajian Ablasi
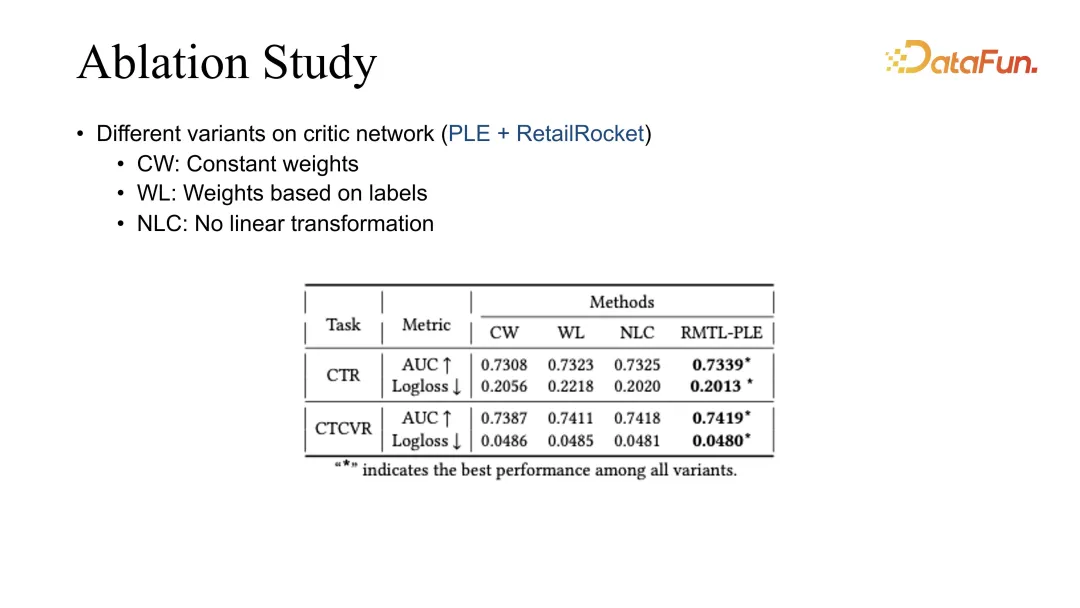
Akhir sekali, kami melakukan kajian ablasi untuk membandingkan kaedah pemberat yang berbeza Pada masa ini, hasil terbaik diperolehi oleh RMTL kami.
3. Kesimpulan
Akhir sekali, mari kita ringkaskan beberapa pengalaman RL dan MTL.

Kami mendapati bahawa pengoptimuman jangka panjang sistem pengesyoran, terutamanya pengoptimuman jangka panjang penunjuk kompleks, adalah senario yang sangat tipikal bagi pembelajaran pengukuhan dan pengoptimuman pelbagai tugas. Jika ia adalah pengoptimuman bersama matlamat utama dan sekunder, regularisasi lembut boleh digunakan untuk mengekang pembelajaran matlamat utama. Semasa pengoptimuman bersama berbilang objektif, jika perubahan dinamik objektif berbeza diambil kira, kesan pengoptimuman juga boleh dipertingkatkan.
Selain itu, terdapat juga beberapa cabaran Sebagai contoh, apabila menggabungkan modul pembelajaran pengukuhan yang berbeza, ia akan membawa banyak cabaran kepada kestabilan sistem. Pengalaman kami ialah mengawal kualiti data, mengawal ketepatan label dan menyelia ketepatan ramalan model adalah cara yang sangat penting. Selain itu, memandangkan sistem pengesyoran dan pengguna berinteraksi secara langsung, matlamat yang berbeza hanya boleh mencerminkan sebahagian pengalaman pengguna, jadi strategi pengesyoran yang terhasil akan menjadi sangat berbeza. Cara untuk bersama-sama mengoptimumkan dan meningkatkan pengalaman pengguna secara menyeluruh di bawah status pengguna yang sentiasa berubah akan menjadi topik yang sangat penting pada masa hadapan.
IV. Soal Jawab
S1: Apakah kerugian yang biasanya digunakan untuk isyarat tempoh dan isyarat interaksi di Kuaishou Adakah ia klasifikasi atau regresi Apakah penunjuk yang biasanya digunakan untuk penilaian luar talian sasaran dan sasaran tontonan?
A1: Penunjuk tempoh ialah tugas regresi biasa. Tetapi kami juga mendapati bahawa anggaran tempoh sangat berkaitan dengan panjang video itu sendiri Contohnya, pengedaran video pendek dan video panjang akan sangat berbeza, jadi apabila menganggarkan, ia akan diklasifikasikan dahulu, dan kemudian regresi akan menjadi. selesai. Baru-baru ini, kami juga mempunyai artikel dalam KDD, yang bercakap tentang kaedah pembahagian anggaran isyarat tempoh menggunakan kaedah pokok Jika anda berminat, anda boleh memberi perhatian kepadanya. Maksud umum ialah, sebagai contoh, jika tempoh dibahagikan kepada video panjang dan video pendek, video panjang akan mempunyai julat anggaran, dan video pendek akan mempunyai julat anggaran untuk video pendek. Anda juga boleh menggunakan kaedah pokok untuk klasifikasi yang lebih terperinci Video panjang boleh dibahagikan kepada video sederhana dan video panjang, dan video pendek juga boleh dibahagikan kepada video ultra pendek dan video pendek. Sudah tentu, terdapat juga kaedah yang menggunakan kaedah pengelasan semata-mata untuk menyelesaikan anggaran tempoh, dan kami juga telah menjalankan ujian. Dari segi kesan keseluruhan, ia masih dalam kerangka klasifikasi Jika kita melakukan regresi semula, kesannya akan menjadi lebih baik sedikit. Anggaran penunjuk interaktif lain secara amnya serupa dengan kaedah anggaran sedia ada. Semasa penilaian luar talian, AUC dan GAUC secara amnya adalah isyarat yang agak kuat, dan pada masa ini kedua-dua isyarat ini agak tepat.
S2: Apakah penunjuk yang boleh dilihat di luar talian seperti penunjuk regresi seperti penunjuk tempoh?
A2: Sistem kami terutamanya melihat penunjuk dalam talian, dan luar talian biasanya menggunakan MAE dan RMSE. Tetapi kami juga melihat bahawa terdapat perbezaan antara penilaian luar talian dan dalam talian Jika tiada peningkatan yang jelas dalam penilaian luar talian, maka kesan penambahbaikan yang sepadan mungkin tidak dapat dilihat secara dalam talian. perbezaannya tidak akan banyak.
S3: Untuk sasaran yang jarang seperti pemajuan, adakah terdapat kaedah pemodelan yang boleh menjadikannya lebih tepat?
A3: Menganalisis sebab pengguna menyiarkan semula dan melakukan beberapa pemerhatian mungkin mendapat hasil yang lebih baik. Pada masa ini, apabila kami melakukan anggaran pemajuan, perbezaan antara kaedah anggaran di bawah pautan kami dan sasaran interaktif lain tidak terlalu besar. Terdapat idea yang lebih umum bahawa definisi label, terutamanya definisi isyarat maklum balas negatif, akan sangat mempengaruhi ketepatan latihan model. Di samping itu, terdapat pengoptimuman sumber data Sama ada data dan pengedaran dalam talian adalah berat sebelah juga akan menjejaskan ketepatan ramalan, jadi banyak kerja kami juga pada debiasing. Kerana dalam senario pengesyoran, banyak penunjuk anggaran sebenarnya adalah isyarat tidak langsung, yang akan menjejaskan kesan pengesyoran dalam langkah seterusnya. Oleh itu, mengoptimumkan penunjuk berdasarkan kesan pengesyoran ialah senario aplikasi kami.
S4: Bagaimanakah Kuaishou melakukan gabungan pelbagai sasaran ini? Adakah pelarasan parameter pembelajaran pengukuhan?
A4: Dalam gabungan pelbagai objektif, terdapat beberapa kaedah heuristik dan beberapa kaedah pengimbangan parameter manual pada permulaannya. Kemudian, saya secara beransur-ansur mula menggunakan kaedah pelarasan parameter, dan juga cuba melaraskan parameter untuk pembelajaran pengukuhan. Pengalaman semasa ialah pelarasan rujukan automatik adalah lebih baik daripada pelarasan manual, dan had atasnya lebih tinggi sedikit.
S5: Jika data dalam talian atau sasaran tertentu yang akan dilaraskan adalah sangat jarang, dan jika pelarasan parameter berdasarkan data dalam talian, kitaran maklum balas atau keyakinan pemerhatian akan mengambil masa yang lama, jadi kecekapan pelarasan parameter akan menjadi agak rendah. Dalam kes ini Apakah penyelesaiannya?
A5: Kami baru-baru ini mendapat beberapa isyarat di mana perbincangan kerja sangat jarang, dan maklum balas hanya mengambil masa beberapa hari. Salah satu isyarat yang paling tipikal ialah pengekalan pengguna, kerana pengguna mungkin pergi selama beberapa hari sebelum kembali, jadi apabila kami mendapat isyarat, model telah dikemas kini selama beberapa hari. Terdapat beberapa kompromi untuk menyelesaikan masalah ini Satu penyelesaian adalah untuk menganalisis isyarat maklum balas masa nyata yang mempunyai korelasi tertentu dengan isyarat yang sangat jarang ini. Dengan mengoptimumkan isyarat masa nyata ini, gabungan kaedah digunakan untuk mengoptimumkan isyarat jangka panjang secara tidak langsung. Mengambil pengekalan sebentar tadi sebagai contoh, dalam sistem kami, kami mendapati bahawa terdapat korelasi positif yang sangat kuat antara pengekalan pengguna dan masa tontonan masa nyata pengguna mewakili kelikatan pengguna kepada sistem, yang pada asasnya boleh menjamin sempadan bawah pengekalan pengguna. Apabila kami mengoptimumkan pengekalan, kami biasanya menggunakan tempoh pengoptimuman digabungkan dengan beberapa penunjuk lain yang berkaitan untuk mengoptimumkan pengekalan. Selagi analisis kami mendapati bahawa terdapat korelasi tertentu dengan pengekalan, kami boleh memperkenalkannya.
S6: Sudahkah anda mencuba kaedah pembelajaran pengukuhan yang lain Apakah kelebihan pengkritik pelakon Mengapa menggunakan kaedah ini?
A6: Pengkritik pelakon adalah hasilnya selepas kami mengulangi beberapa kali Kami juga telah mencuba kaedah yang lebih intuitif seperti DQN dan Reinforce sebelum ini, sesetengah daripadanya memang berkesan dalam beberapa senario, tetapi pada masa ini pengkritik pelakon agak stabil satu. Dan cara yang baik untuk nyahpepijat. Sebagai contoh, menggunakan Reinforce memerlukan penggunaan isyarat jangka panjang, dan isyarat trajektori jangka panjang agak tidak menentu, jadi ia akan menjadi lebih sukar untuk meningkatkan kestabilannya. Tetapi satu kelebihan pengkritik pelakon ialah ia boleh mengoptimumkan berdasarkan isyarat satu langkah, yang merupakan ciri yang sangat konsisten dengan sistem pengesyoran. Kami berharap maklum balas setiap pengguna boleh digunakan sebagai sampel latihan untuk dipelajari, dan pengkritik pelakon yang sepadan serta kaedah DDPG akan sangat konsisten dengan tetapan sistem kami.
S7: Apabila gabungan pelbagai objektif Kuaishou menggunakan kaedah pembelajaran pengukuhan, ciri pengguna yang manakah digunakan secara amnya. Adakah terdapat beberapa ciri yang sangat baik seperti id pengguna yang menyebabkan kesukaran dalam penumpuan model?
A7: Id pengguna sebenarnya tidak buruk, kerana ciri sisi pengguna kami masih menggunakan pelbagai ciri. Selain ciri id, pengguna juga mempunyai beberapa ciri statistik. Selain itu, pada pautan cadangan, kerana RL berada di peringkat yang agak lewat dalam modul yang kami gunakan, seperti penarafan dan penyusunan semula yang baik, anggaran dan isyarat kedudukan model juga akan diberikan pada peringkat sebelumnya di dalamnya. Oleh itu, pembelajaran pengukuhan masih memperoleh banyak isyarat sisi pengguna dalam senario yang disyorkan, dan pada asasnya tidak akan ada situasi di mana hanya satu ID pengguna digunakan.
S8: Jadi user id pun guna, tapi belum ada masalah convergence kan?
A8: Ya, dan kami mendapati bahawa jika id pengguna tidak digunakan, kesan pada pemperibadian adalah agak besar. Jika anda hanya menggunakan beberapa ciri statistik pengguna, kadangkala kesan peningkatan tidak sehebat ID pengguna. Memang kesan id pengguna agak besar, tetapi jika kesannya terlalu besar, akan berlaku masalah turun naik.
S9: Dalam sesetengah perniagaan di sesetengah syarikat, data tingkah laku pengguna mungkin agak kecil. Adakah mereka juga akan menghadapi masalah yang sukar untuk menumpu jika id pengguna digunakan Jika anda menghadapi masalah yang sama, apakah penyelesaiannya?
A9: Masalah ini berat sebelah terhadap permulaan sejuk pengguna Dalam senario permulaan sejuk, pautan yang disyorkan biasanya diisi dengan ciri pelengkap atau automatik, dengan anggapan ia adalah pengguna lalai, masalah ini boleh diselesaikan pada tahap tertentu. Kemudian, apabila pengguna terus berinteraksi dengan sistem dan sesi terus diperkaya, kami sebenarnya boleh mendapatkan sejumlah maklum balas pengguna dan latihan secara beransur-ansur akan menjadi lebih tepat. Dari segi memastikan kestabilan, pada asasnya selagi anda mengawal dengan baik dan menghalang satu id pengguna daripada mendominasi latihan, anda masih boleh meningkatkan kesan sistem dengan baik.
S10: Seperti yang dinyatakan sebelum ini, pemodelan sasaran tempoh mula-mula dikelaskan dan kemudian regresi dilakukan Secara khusus, adakah tempoh dibahagikan kepada baldi dahulu, dan kemudian regresi selepas baldi? Adakah kaedah ini anggaran yang tidak berat sebelah?
A10: Kerja itu adalah untuk melakukan secara langsung baldi, dan kemudian menggunakan kebarangkalian ketibaan setiap baldi untuk bersama-sama menilai tempoh, bukannya melakukan regresi selepas baldi. Ia hanya menggunakan kebarangkalian timba, ditambah dengan nilai timba untuk membuat penilaian kebarangkalian keseluruhan. Regresi selepas baldi seharusnya tidak lagi tidak berat sebelah Lagipun, setiap baldi masih mempunyai corak pengedarannya sendiri.
S11: Cikgu baru sebut satu soalan Untuk dua matlamat a dan b, matlamat utama kita ialah a, dan syarat untuk b ialah ia tidak jatuh. Dalam senario sebenar kami, mungkin terdapat senario di mana a adalah matlamat utama dan tiada kekangan pada b. Sebagai contoh, sasaran CTR dioptimumkan bersama-sama dengan sasaran CVR, tetapi model itu sendiri adalah model CVR Kami hanya menumpukan pada kesan CVR dan tidak peduli sama ada kesan CTR akan menjadi lebih teruk Sebanyak yang boleh. Dalam senario seperti ini, jika anda ingin menggabungkan mereka untuk latihan bersama, adakah ada penyelesaian?
A11: Ini sebenarnya bukan lagi pengoptimuman multi-objektif malah penunjuk CTR boleh digunakan secara langsung sebagai input untuk mengoptimumkan CPR, kerana CTR bukan lagi matlamat pengoptimuman. Tetapi ini mungkin tidak baik untuk pengguna, kerana CTR pengguna mewakili keutamaan dan kelekatan sistem pada tahap yang lebih besar. Walau bagaimanapun, sistem yang berbeza mungkin berbeza, bergantung pada sama ada sistem pengesyoran tertumpu terutamanya pada penjualan produk atau trafik. Memandangkan video pendek Kuaishou terutamanya berdasarkan trafik, CTR pengguna ialah penunjuk yang lebih intuitif dan penting, dan CVR hanyalah kesan selepas lencongan trafik.
Atas ialah kandungan terperinci Pembelajaran pengukuhan Kuaishou dan cadangan pelbagai tugas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Cara melaksanakan sistem pengesyoran menggunakan bahasa Go dan Redis
Oct 27, 2023 pm 12:54 PM
Cara melaksanakan sistem pengesyoran menggunakan bahasa Go dan Redis
Oct 27, 2023 pm 12:54 PM
Cara menggunakan bahasa Go dan Redis untuk melaksanakan sistem pengesyoran Sistem pengesyoran merupakan bahagian penting platform Internet moden. Ia membantu pengguna menemui dan mendapatkan maklumat yang diminati. Bahasa Go dan Redis ialah dua alatan yang sangat popular yang boleh memainkan peranan penting dalam proses melaksanakan sistem pengesyoran. Artikel ini akan memperkenalkan cara menggunakan bahasa Go dan Redis untuk melaksanakan sistem pengesyoran mudah dan memberikan contoh kod khusus. Redis ialah pangkalan data dalam memori sumber terbuka yang menyediakan antara muka simpanan pasangan nilai kunci dan menyokong pelbagai data
 Algoritma dan aplikasi sistem pengesyoran dilaksanakan dalam Java
Jun 19, 2023 am 09:06 AM
Algoritma dan aplikasi sistem pengesyoran dilaksanakan dalam Java
Jun 19, 2023 am 09:06 AM
Dengan pembangunan berterusan dan mempopularkan teknologi Internet, sistem pengesyoran, sebagai teknologi penapisan maklumat yang penting, semakin digunakan dan diberi perhatian secara meluas. Dari segi pelaksanaan algoritma sistem pengesyoran, Java, sebagai bahasa pengaturcaraan yang pantas dan boleh dipercayai, telah digunakan secara meluas. Artikel ini akan memperkenalkan algoritma sistem pengesyoran dan aplikasi yang dilaksanakan dalam Java, dan menumpukan pada tiga algoritma sistem pengesyoran biasa: algoritma penapisan kolaboratif berasaskan pengguna, algoritma penapisan kolaboratif berasaskan item dan algoritma pengesyoran berasaskan kandungan. Algoritma penapisan kolaboratif berasaskan pengguna adalah berdasarkan penapisan kolaboratif berasaskan pengguna
 Contoh aplikasi: Gunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro
Jun 18, 2023 pm 12:43 PM
Contoh aplikasi: Gunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro
Jun 18, 2023 pm 12:43 PM
Dengan populariti aplikasi Internet, seni bina perkhidmatan mikro telah menjadi kaedah seni bina yang popular. Antaranya, kunci kepada seni bina perkhidmatan mikro adalah untuk memisahkan aplikasi kepada perkhidmatan yang berbeza dan berkomunikasi melalui RPC untuk mencapai seni bina perkhidmatan yang digandingkan secara longgar. Dalam artikel ini, kami akan memperkenalkan cara menggunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro berdasarkan kes sebenar. 1. Apakah sistem pengesyoran perkhidmatan mikro? Sistem pengesyoran perkhidmatan mikro ialah sistem pengesyoran berdasarkan seni bina perkhidmatan mikro Ia menyepadukan modul yang berbeza dalam sistem pengesyoran (seperti kejuruteraan ciri, pengelasan
 Rahsia Pengesyoran Tepat: Penjelasan Terperinci mengenai Model Pengingatan Tanpa Pinggir Adaptasi Domain Dipisahkan Alibaba
Jun 05, 2023 am 08:55 AM
Rahsia Pengesyoran Tepat: Penjelasan Terperinci mengenai Model Pengingatan Tanpa Pinggir Adaptasi Domain Dipisahkan Alibaba
Jun 05, 2023 am 08:55 AM
1. Pengenalan senario Mula-mula, mari kita perkenalkan senario yang terlibat dalam artikel ini—senario "barangan bagus tersedia". Lokasinya adalah dalam grid empat persegi pada laman utama Taobao, yang dibahagikan kepada halaman pemilihan satu lompatan dan halaman penerimaan dua lompatan. Terdapat dua bentuk utama halaman penerimaan, satu ialah halaman penerimaan imej dan teks, dan satu lagi ialah halaman penerimaan video pendek. Matlamat senario ini adalah terutamanya untuk menyediakan pengguna dengan barangan yang memuaskan dan memacu pertumbuhan GMV, seterusnya memanfaatkan bekalan pakar. 2. Apakah bias populariti, dan mengapa seterusnya kita masukkan fokus artikel ini, bias populariti. Apakah bias populariti? Mengapa bias populariti berlaku? 1. Apakah bias populariti? Bias populariti mempunyai banyak alias, seperti kesan Matthew dan ruang kepompong maklumat, ia adalah karnival produk letupan tinggi, lebih mudah ia didedahkan. Ini akan mengakibatkan
 Bagaimanakah bahasa Go melaksanakan sistem carian dan pengesyoran awan?
May 16, 2023 pm 11:21 PM
Bagaimanakah bahasa Go melaksanakan sistem carian dan pengesyoran awan?
May 16, 2023 pm 11:21 PM
Dengan pembangunan berterusan dan mempopularkan teknologi pengkomputeran awan, carian awan dan sistem pengesyoran menjadi semakin popular. Sebagai tindak balas kepada permintaan ini, bahasa Go juga menyediakan penyelesaian yang baik. Dalam bahasa Go, kami boleh menggunakan keupayaan pemprosesan serentak berkelajuan tinggi dan perpustakaan standard yang kaya untuk melaksanakan sistem carian dan pengesyoran awan yang cekap. Berikut akan memperkenalkan cara bahasa Go melaksanakan sistem sedemikian. 1. Cari di awan Pertama, kita perlu memahami postur dan prinsip carian. Postur carian merujuk kepada halaman padanan enjin carian berdasarkan kata kunci yang dimasukkan oleh pengguna.
 Sistem pengesyoran untuk teknologi permulaan sejuk NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
Sistem pengesyoran untuk teknologi permulaan sejuk NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
1. Latar belakang masalah: Keperluan dan kepentingan pemodelan permulaan sejuk Sebagai platform kandungan, Cloud Music mempunyai sejumlah besar kandungan baharu dalam talian setiap hari. Walaupun jumlah kandungan baharu pada platform muzik awan agak kecil berbanding dengan platform lain seperti video pendek, jumlah sebenar mungkin jauh melebihi imaginasi semua orang. Pada masa yang sama, kandungan muzik jauh berbeza daripada video pendek, berita dan cadangan produk. Kitaran hayat muzik menjangkau tempoh masa yang sangat lama, selalunya diukur dalam tahun. Sesetengah lagu mungkin meletup selepas tidak aktif selama berbulan-bulan atau bertahun-tahun, dan lagu-lagu klasik mungkin masih mempunyai daya hidup yang kuat walaupun selepas lebih daripada sepuluh tahun. Oleh itu, untuk sistem pengesyoran platform muzik, adalah lebih penting untuk menemui kandungan berkualiti tinggi yang tidak popular dan berekor panjang dan mengesyorkannya kepada pengguna yang betul daripada mengesyorkan kategori lain.
 Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Jan 13, 2024 pm 12:15 PM
Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Jan 13, 2024 pm 12:15 PM
1. Latar belakang pembetulan sebab dan akibat 1. Penyelewengan berlaku dalam sistem pengesyoran Model pengesyoran dilatih dengan mengumpul data untuk mengesyorkan item yang sesuai kepada pengguna. Apabila pengguna berinteraksi dengan item yang disyorkan, data yang dikumpul digunakan untuk terus melatih model, membentuk gelung tertutup. Walau bagaimanapun, mungkin terdapat pelbagai faktor yang mempengaruhi dalam gelung tertutup ini, mengakibatkan ralat. Sebab utama ralat ialah kebanyakan data yang digunakan untuk melatih model adalah data pemerhatian dan bukannya data latihan yang ideal, yang dipengaruhi oleh faktor seperti strategi pendedahan dan pemilihan pengguna. Intipati berat sebelah ini terletak pada perbezaan antara jangkaan anggaran risiko empirikal dan jangkaan anggaran risiko ideal sebenar. 2. Kecondongan biasa Terdapat tiga jenis utama bias biasa dalam sistem pemasaran pengesyoran: Kecondongan selektif: Ini disebabkan oleh akar pengguna
 Sistem pengesyoran dan teknologi penapisan kolaboratif dalam PHP
May 11, 2023 pm 12:21 PM
Sistem pengesyoran dan teknologi penapisan kolaboratif dalam PHP
May 11, 2023 pm 12:21 PM
Dengan perkembangan pesat Internet, sistem pengesyoran telah menjadi semakin penting. Sistem pengesyoran ialah algoritma yang digunakan untuk meramal item yang menarik minat pengguna. Dalam aplikasi Internet, sistem pengesyoran boleh memberikan cadangan dan pengesyoran yang diperibadikan, dengan itu meningkatkan kepuasan pengguna dan kadar penukaran. PHP ialah bahasa pengaturcaraan yang digunakan secara meluas dalam pembangunan web. Artikel ini akan meneroka sistem pengesyoran dan teknologi penapisan kolaboratif dalam PHP. Prinsip sistem pengesyoran Sistem pengesyoran bergantung pada algoritma pembelajaran mesin dan analisis data Ia menganalisis dan meramalkan kelakuan sejarah pengguna.
