
 Peranti teknologi
AI
Penjelasan terperinci tentang GQA, mekanisme perhatian yang biasa digunakan dalam model besar, dan pelaksanaan kod Pytorch
Peranti teknologi
AI
Penjelasan terperinci tentang GQA, mekanisme perhatian yang biasa digunakan dalam model besar, dan pelaksanaan kod Pytorch
Penjelasan terperinci tentang GQA, mekanisme perhatian yang biasa digunakan dalam model besar, dan pelaksanaan kod Pytorch

Perhatian Pertanyaan Berkumpulan ialah kaedah perhatian berbilang pertanyaan dalam model bahasa besar Matlamatnya adalah untuk mencapai kualiti MHA sambil mengekalkan kelajuan MQA. Pertanyaan Berkumpulan Pertanyaan kumpulan perhatian supaya pertanyaan dalam setiap kumpulan berkongsi berat perhatian yang sama, yang membantu mengurangkan kerumitan pengiraan dan meningkatkan kelajuan inferens.
Dalam artikel ini, kami akan menerangkan idea GQA dan cara menterjemahkannya ke dalam kod.
GQA telah dicadangkan dalam kertas GQA: Latihan Model Transformer Berbilang Pertanyaan Umum daripada kertas Pusat Pemeriksaan Berbilang Kepala Ia adalah idea yang agak mudah dan bersih, dan dibina berdasarkan perhatian berbilang kepala.
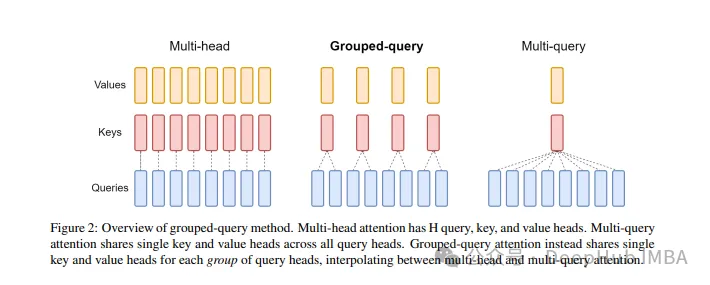
GQA
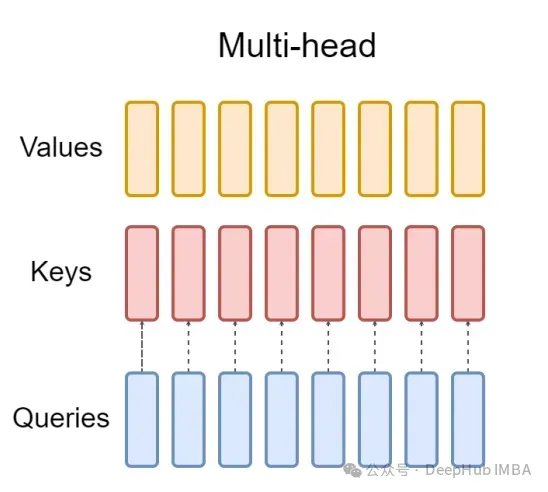
Lapisan perhatian berbilang kepala standard (MHA) terdiri daripada pengepala pertanyaan H, pengepala utama dan pengepala nilai. Setiap kepala mempunyai dimensi D. Kod Pytorch adalah seperti berikut:
from torch.nn.functional import scaled_dot_product_attention # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 8, 64) value = torch.randn(1, 256, 8, 64) output = scaled_dot_product_attention(query, key, value) print(output.shape) # torch.Size([1, 256, 8, 64])
Untuk setiap pengepala pertanyaan, terdapat kunci yang sepadan. Proses ini ditunjukkan dalam rajah di bawah:
Dan GQA membahagikan pengepala pertanyaan kepada kumpulan G, setiap kumpulan berkongsi kunci dan nilai. Ia boleh dinyatakan sebagai:
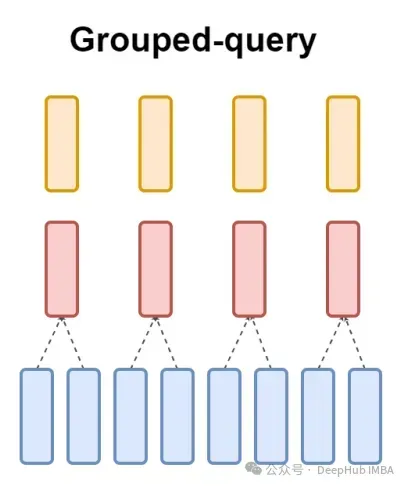
Menggunakan ekspresi visual, anda boleh memahami dengan jelas prinsip kerja GQA, seperti yang kami katakan di atas. GQA ialah idea yang agak mudah dan bersih.
Pelaksanaan kod pytorch
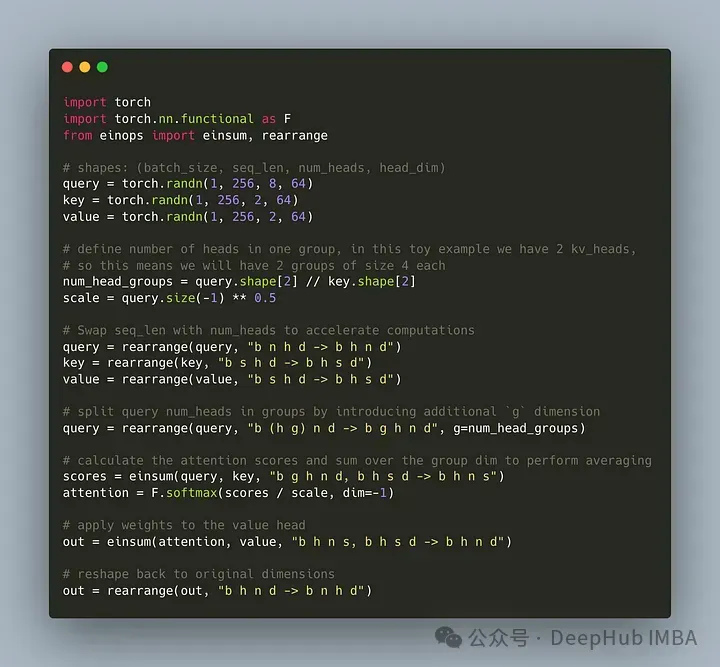
Mari tulis kod untuk membahagikan pengepala pertanyaan kepada kumpulan G, setiap kumpulan berkongsi kunci dan nilai. Kita boleh menggunakan perpustakaan einops untuk melaksanakan operasi kompleks pada tensor dengan cekap.
Pertama, tentukan pertanyaan, kunci dan nilai. Kemudian tetapkan bilangan kepala perhatian Nombor itu adalah sewenang-wenangnya, tetapi ia mesti dipastikan bahawa num_heads_for_query % num_heads_for_key = 0, yang bermaksud ia mesti boleh dibahagikan. Definisi kami adalah seperti berikut:
import torch # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 2, 64) value = torch.randn(1, 256, 2, 64) num_head_groups = query.shape[2] // key.shape[2] print(num_head_groups) # each group is of size 4 since there are 2 kv_heads
Untuk meningkatkan kecekapan, tukar dimensi seq_len dan num_heads, einops boleh dilengkapkan dengan mudah seperti berikut:
from einops import rearrange query = rearrange(query, "b n h d -> b h n d") key = rearrange(key, "b s h d -> b h s d") value = rearrange(value, "b s h d -> b h s d")
kita perlu memperkenalkan "kumpulan itu" konsep matriks pertanyaan.
from einops import rearrange query = rearrange(query, "b (h g) n d -> b g h n d", g=num_head_groups) print(query.shape) # torch.Size([1, 4, 2, 256, 64])
Dengan kod di atas kita membentuk semula 2D menjadi 2D: Untuk tensor yang kami takrifkan, dimensi asal 8 (bilangan kepala dalam pertanyaan) kini dibahagikan kepada dua kumpulan (untuk memadankan kepala dalam kekunci dan nombor nilai), setiap saiz kumpulan ialah 4.
Bahagian terakhir dan paling sukar ialah mengira markah perhatian. Tetapi sebenarnya, ia boleh dilakukan dalam satu baris melalui operasi insum. Mari lihat cara ia berfungsi
einsum melakukan dua perkara untuk kita:1. Pertanyaan dan pendaraban matriks kunci. Dalam kes kita, bentuk tensor ini ialah (1,4,2,256,64) dan (1,2,256,64), jadi pendaraban matriks sepanjang dua dimensi terakhir memberi kita (1,4,2,256,256).
2 Jumlahkan elemen dalam dimensi kedua (dimensi g) - jika dimensi ditinggalkan dalam bentuk keluaran yang ditentukan, einsum akan melengkapkan kerja ini secara automatik dan penjumlahan tersebut digunakan untuk memadankan kekunci dan bilangan kepala dalam. nilai.
Akhir sekali, perhatikan pendaraban piawai pecahan dan nilai:
from einops import einsum, rearrange # g stands for the number of groups # h stands for the hidden dim # n and s are equal and stands for sequence length scores = einsum(query, key, "b g h n d, b h s d -> b h n s") print(scores.shape) # torch.Size([1, 2, 256, 256])
Pelaksanaan GQA yang paling mudah kini selesai, memerlukan kurang daripada 16 baris kod python:
Akhir sekali, sebutan ringkas tentang MQA: Perhatian Berbilang Pertanyaan (MQA) ialah satu lagi kaedah popular untuk memudahkan MHA. Semua pertanyaan akan berkongsi kunci dan nilai yang sama. Gambarajah skematik adalah seperti berikut:
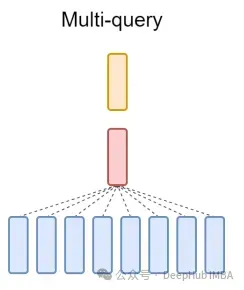
Seperti yang anda lihat, kedua-dua MQA dan MHA boleh diperolehi daripada GQA. GQA dengan satu kunci dan nilai adalah bersamaan dengan MQA, manakala GQA dengan kumpulan yang sama dengan bilangan pengepala adalah bersamaan dengan MHA.
Apakah faedah GQA
GQA ialah pertukaran yang baik antara prestasi terbaik (MQA) dan kualiti model terbaik (MHA).
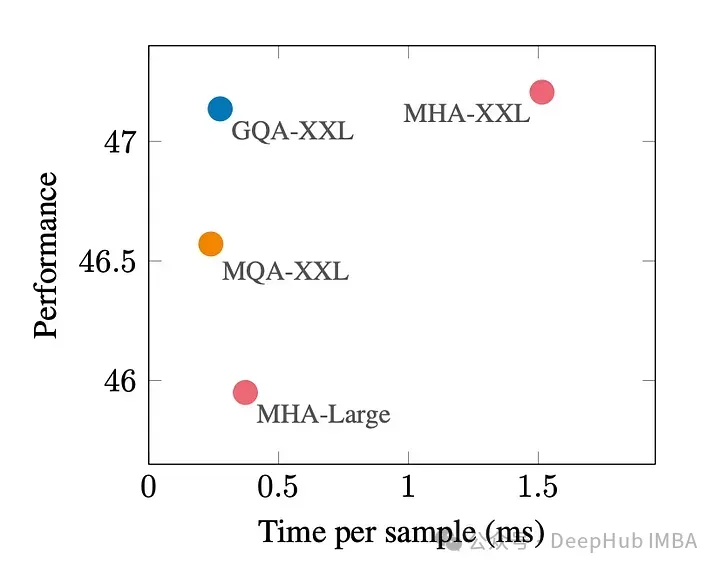
Rajah di bawah menunjukkan bahawa menggunakan GQA, anda boleh mendapatkan kualiti model yang hampir sama dengan MHA, sambil meningkatkan masa pemprosesan sebanyak 3 kali ganda, mencapai prestasi MQA. Ini mungkin penting untuk sistem beban tinggi.
Tiada pelaksanaan rasmi GQA dalam pytorch. Jadi saya temui pelaksanaan tidak rasmi yang lebih baik. Jika anda berminat, anda boleh mencubanya:
https://www.php.cn/link/5b52e27a9d5bf294f5b593c4c071500e
kertas: https ://www.php.cn/link/e4ba31fba036a999321d5460f7f2d1d1
Atas ialah kandungan terperinci Penjelasan terperinci tentang GQA, mekanisme perhatian yang biasa digunakan dalam model besar, dan pelaksanaan kod Pytorch. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
