Model AniPortrait adalah sumber terbuka dan boleh dimainkan secara bebas.
"Alat produktiviti baharu untuk Zon Hantu Xiaopozhan Baru-baru ini, projek baharu yang dikeluarkan oleh Tencent Open Source telah menerima penilaian sebegitu. Projek ini ialah AniPortrait, yang menjana potret animasi berkualiti tinggi berdasarkan audio dan imej rujukan. Tanpa berlengah lagi, mari kita lihat demo yang mungkin diberi amaran oleh surat peguam:  Imej anime juga boleh bercakap dengan mudah:
Imej anime juga boleh bercakap dengan mudah:  baru sahaja dibuat dalam talian
baru sahaja dibuat dalam talian beberapa hari, dan ia telah pun Ia telah menerima pujian yang meluas: bilangan Bintang GitHub telah melebihi 2,800. 
Mari kita lihat inovasi AniPortrait. 
Tajuk kertas: AniPortrait: Sintesis Dipacu Audio bagi Animasi Potret FotorealistikAlamat kertas: https://arxiv.org/pdf/2403.17- .pdf:Co. /arxiv.org/pdf/2403.17694.pdf /github.com/Zejun-Yang/AniPortrait
modul Audio yang dipromosikan
Audio2Lmk digunakan untuk mengekstrak jujukan Mercu Tanda, yang boleh menangkap ekspresi muka dan pergerakan bibir yang kompleks daripada input audio. Lmk2Video menggunakan jujukan Mercu Tanda ini untuk menjana video potret berkualiti tinggi yang stabil sementara dan konsisten.
Rajah 1 memberikan gambaran keseluruhan rangka kerja AniPortrait. 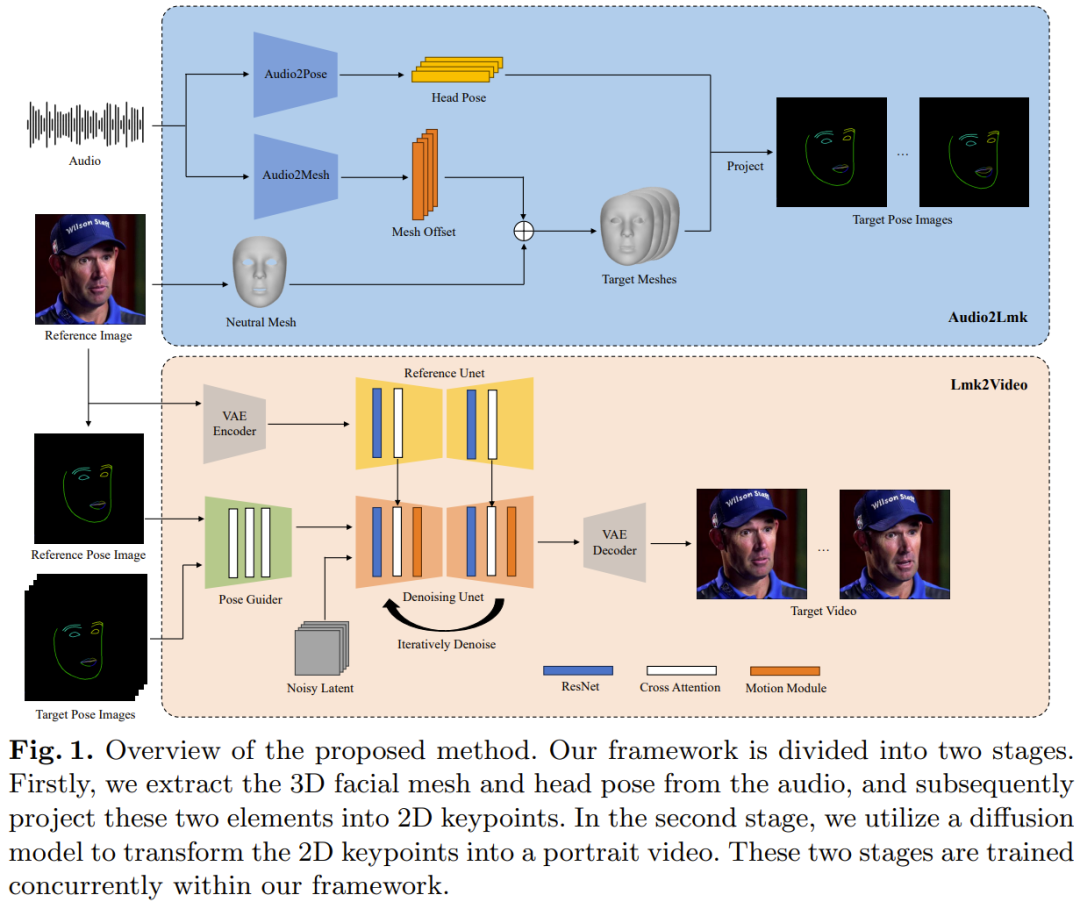
🎜🎜
Untuk urutan klip pertuturan, matlamat di sini ialah untuk meramalkan urutan mata 3D yang sepadan dan turutan gerak isyarat. Pasukan menggunakan wav2vec terlatih untuk mengekstrak ciri audio. Model ini membuat generalisasi dengan baik dan boleh mengecam sebutan dan intonasi dengan tepat dalam audio - penting untuk menghasilkan animasi muka yang realistik. Dengan mengeksploitasi ciri pertuturan teguh yang diperolehi, ia boleh ditukar dengan cekap menjadi jerat muka 3D menggunakan seni bina ringkas yang terdiri daripada dua lapisan fc. Pasukan memerhatikan bahawa reka bentuk yang ringkas dan mudah ini bukan sahaja memastikan ketepatan tetapi juga meningkatkan kecekapan proses inferens. Dalam tugas menukar audio kepada gerak isyarat, rangkaian tulang belakang yang digunakan oleh pasukan masih wav2vec yang sama. Walau bagaimanapun, berat rangkaian ini berbeza daripada rangkaian modul audio-ke-mesh. Ini kerana gerak isyarat lebih berkait rapat dengan irama dan pic dalam audio, manakala tugas audio-ke-grid memfokuskan pada fokus yang berbeza (sebutan dan intonasi). Untuk mengambil kira kesan keadaan sebelumnya, pasukan menggunakan penyahkod transformer untuk menyahkod urutan pose. Dalam proses ini, modul menggunakan mekanisme perhatian silang untuk menyepadukan ciri audio ke dalam penyahkod. Untuk dua modul di atas, fungsi kehilangan yang digunakan untuk latihan ialah kehilangan L1 yang mudah. Selepas mendapatkan jujukan mesh dan pose, gunakan unjuran perspektif untuk menukarnya menjadi jujukan tanda tanda muka 2D. Mercu Tanda ini ialah isyarat input untuk peringkat seterusnya. . Proses animasi ini menjajarkan gerakan dengan jujukan Mercu Tanda sambil mengekalkan rupa yang konsisten dengan imej rujukan. Idea yang diterima pakai oleh pasukan adalah untuk mewakili animasi potret sebagai urutan bingkai potret. Reka bentuk struktur rangkaian Lmk2Video ini diilhamkan oleh AnimateAnyone. Rangkaian tulang belakang ialah SD1.5, yang menyepadukan modul gerakan temporal yang secara berkesan menukar input hingar berbilang bingkai ke dalam urutan bingkai video.
Selain itu, mereka juga menggunakan ReferenceNet, yang juga menggunakan struktur SD1.5 Fungsinya adalah untuk mengekstrak maklumat penampilan imej rujukan dan mengintegrasikannya ke dalam rangkaian tulang belakang. Reka bentuk strategik ini memastikan Face ID kekal konsisten sepanjang video keluaran.
Tidak seperti AnimateAnyone, ini meningkatkan kerumitan reka bentuk PoseGuider. Versi asal baru sahaja menyepadukan beberapa lapisan konvolusi, dan kemudian ciri Mercu Tanda digabungkan dengan ciri terpendam lapisan input rangkaian tulang belakang. Pasukan Tencent mendapati bahawa reka bentuk asas ini tidak dapat menangkap pergerakan bibir yang kompleks. Oleh itu, mereka menggunakan strategi berbilang skala ControlNet: menyepadukan ciri Mercu Tanda skala yang sepadan ke dalam modul rangkaian tulang belakang yang berbeza. Walaupun terdapat peningkatan ini, bilangan parameter dalam model akhir masih agak rendah.
Pasukan juga memperkenalkan satu lagi peningkatan: menggunakan Tanda Tanda imej rujukan sebagai input tambahan. Modul silang perhatian PoseGuider memudahkan interaksi antara tanda tempat rujukan dan tanda tempat sasaran dalam setiap bingkai. Proses ini menyediakan rangkaian dengan petunjuk tambahan yang membolehkannya memahami hubungan antara tanda tempat muka dan penampilan, yang boleh membantu animasi potret menjana pergerakan yang lebih tepat. Rangkaian tulang belakang yang digunakan dalam peringkat Audio2Lmk adalah wa Alat yang digunakan untuk mengekstrak jerat 3D dan pose 6D ialah MediaPipe. Data latihan Audio2Mesh datang daripada set data dalaman Tencent, yang mengandungi hampir sejam data pertuturan berkualiti tinggi daripada satu pembesar suara. Untuk memastikan kestabilan jaringan 3D yang diekstrak oleh MediaPipe, kedudukan kepala pelaku adalah stabil dan menghadap kamera semasa rakaman. Latihan Audio2Pose menggunakan HDTF. Semua operasi latihan dilakukan pada A100 tunggal, menggunakan pengoptimum Adam, dan kadar pembelajaran ditetapkan kepada 1e-5.
Proses Lmk2Video menggunakan kaedah latihan dua langkah.
Fasa langkah awal memfokuskan pada latihan rangkaian tulang belakang ReferenceNet dan komponen 2D PoseGuider, tanpa mengira modul gerakan. Dalam langkah seterusnya, semua komponen lain akan dibekukan untuk memberi tumpuan kepada latihan modul gerakan. Untuk melatih model, dua set data video muka berkualiti tinggi berskala besar digunakan di sini: VFHQ dan CelebV-HQ. Semua data dihantar melalui MediaPipe untuk mengekstrak tanda tempat muka 2D. Untuk meningkatkan kepekaan rangkaian terhadap pergerakan bibir, pendekatan pasukan adalah untuk menganotasi bibir atas dan bawah dengan warna yang berbeza apabila memaparkan imej pose berdasarkan Mercu Tanda 2D.
Semua imej telah diubah saiznya kepada 512x512.Model ini dilatih menggunakan 4 GPU A100, dengan setiap langkah mengambil masa 2 hari. Pengoptimum ialah AdamW dan kadar pembelajaran ditetapkan pada 1e-5. Seperti yang ditunjukkan dalam Rajah 2, animasi yang diperolehi melalui kaedah baharu adalah cemerlang dalam kualiti dan realisme. 
Selain itu, pengguna boleh mengedit perwakilan 3D di tengah untuk mengubah suai output akhir. Sebagai contoh, pengguna boleh mengekstrak Mercu Tanda daripada sumber dan mengubah suai maklumat ID mereka untuk mencapai pembiakan muka, seperti yang ditunjukkan dalam video berikut:  Sila rujuk kertas asal untuk mendapatkan butiran lanjut.
Sila rujuk kertas asal untuk mendapatkan butiran lanjut. Atas ialah kandungan terperinci Pemilik atas telah mula bermain-main dengan sumber terbuka Tencent 'AniPortrait' untuk membenarkan foto menyanyi dan bercakap.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


 Cara membetulkan get laluan lalai komputer tidak tersedia
Cara membetulkan get laluan lalai komputer tidak tersedia
 Bagaimana untuk mendayakan fungsi bandar yang sama pada Douyin
Bagaimana untuk mendayakan fungsi bandar yang sama pada Douyin
 Semak ruang cakera dalam linux
Semak ruang cakera dalam linux
 Bagaimana untuk mengecas semula Ouyiokx
Bagaimana untuk mengecas semula Ouyiokx
 permainan ipad tiada bunyi
permainan ipad tiada bunyi
 titik simbol khas
titik simbol khas
 kekunci pintasan komen python
kekunci pintasan komen python
 Penjelasan popular tentang maksud Metaverse XR
Penjelasan popular tentang maksud Metaverse XR








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



