

Jika anda ingin mengetahui lebih lanjut tentang AIGC,
sila layari: 51CTO AI , latih model besar di peringkat Llama-2.
Model
MoElebih kecil tetapi mempunyai prestasi yang sama:
Ia dipanggil JetMoE, dan ia datang daripada institusi penyelidikan seperti MIT dan Princeton. Prestasi jauh melebihi Llama-2 dengan saiz yang sama.
△Ditweet semula oleh Jia Yangqing
Anda mesti tahu bahawa yang terakhir ini mempunyai kos pelaburan sebanyakberbilion dolar
peringkat.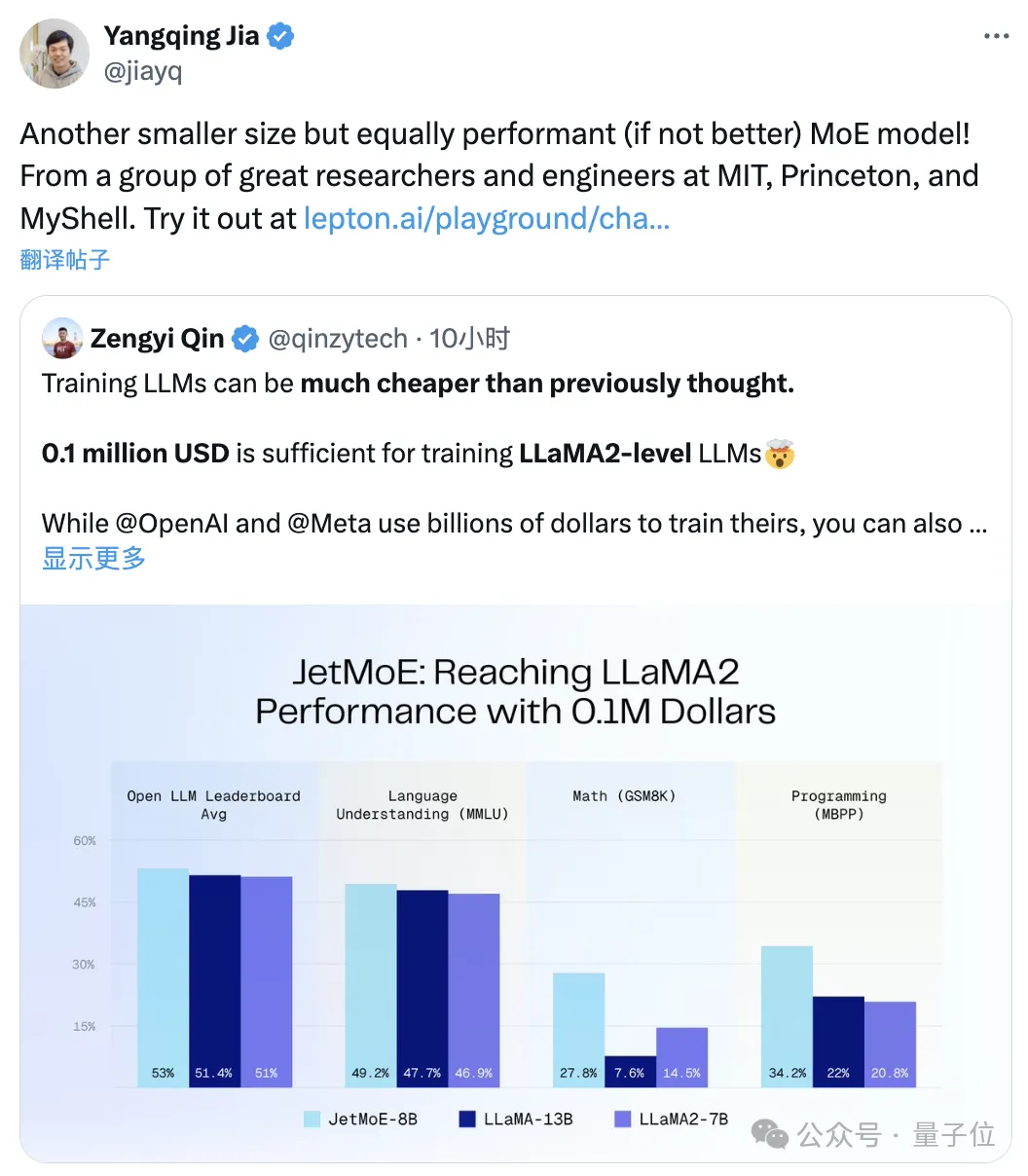
sumber terbuka apabila dikeluarkan, dan mesra akademik: ia hanya menggunakan set data awam dan kod sumber terbuka, dan boleh diperhalusi dengan GPU gred pengguna
. Mesti dikatakan kos membina model besar memang jauh lebih murah daripada yang orang sangka.
Mesti dikatakan kos membina model besar memang jauh lebih murah daripada yang orang sangka.
Ps. Emad, bekas bos Stable Diffusion, juga menyukainya:
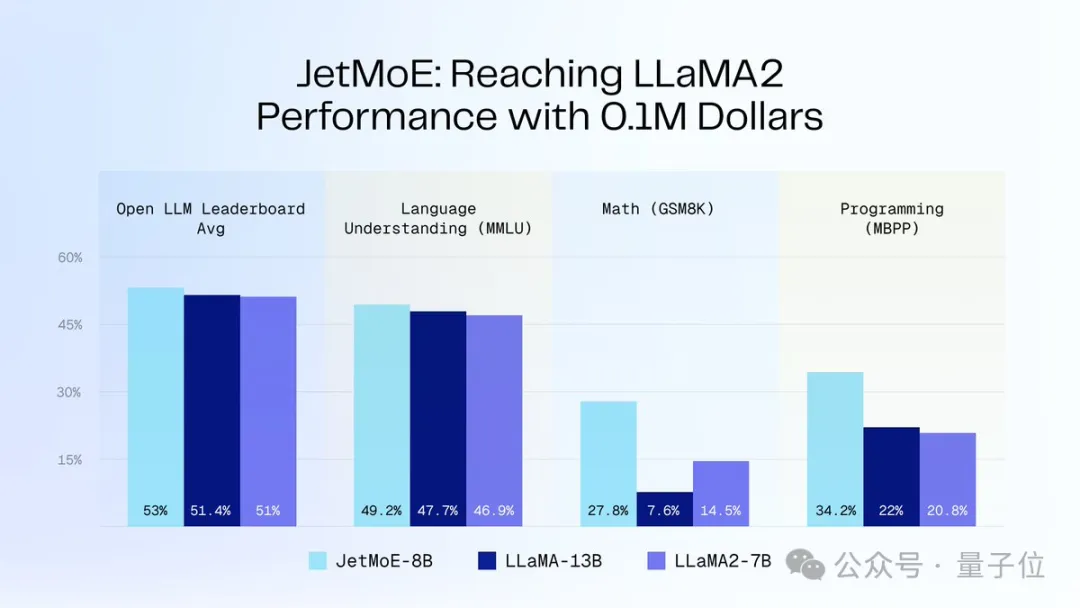
$100,000 untuk mencapai prestasi Llama-2JetMoE diilhamkan oleh seni bina yang jarang digunakan.
(ModuleFormer, seni bina modular berdasarkan Campuran Jarang Pakar (SMoE) untuk meningkatkan kecekapan dan fleksibiliti model besar, dicadangkan pada Jun tahun lepas) 
JetMoE dengan 8 bilion parameter mempunyai sejumlah 24 blok, setiap blok mengandungi 2 lapisan MoE iaitu attention head mixing
(MoA)dan MLP expert mixing (MoE) .
Setiap lapisan MoA dan MoE mempunyai 8 pakar, 2 diaktifkan setiap kali token dimasukkan.
JetMoE-8B menggunakan
1.25T token dalam set data awam untuk latihan, dengan kadar pembelajaran 5.0 x 10-4 dan saiz kelompok global 4M token. . peringkat menggunakan prapemanasan linear Kadar pembelajaran berterusan, dilatih dengan 1 trilion token daripada set data pra-latihan sumber terbuka berskala besar, termasuk RefinedWeb, Pile, data Github, dsb.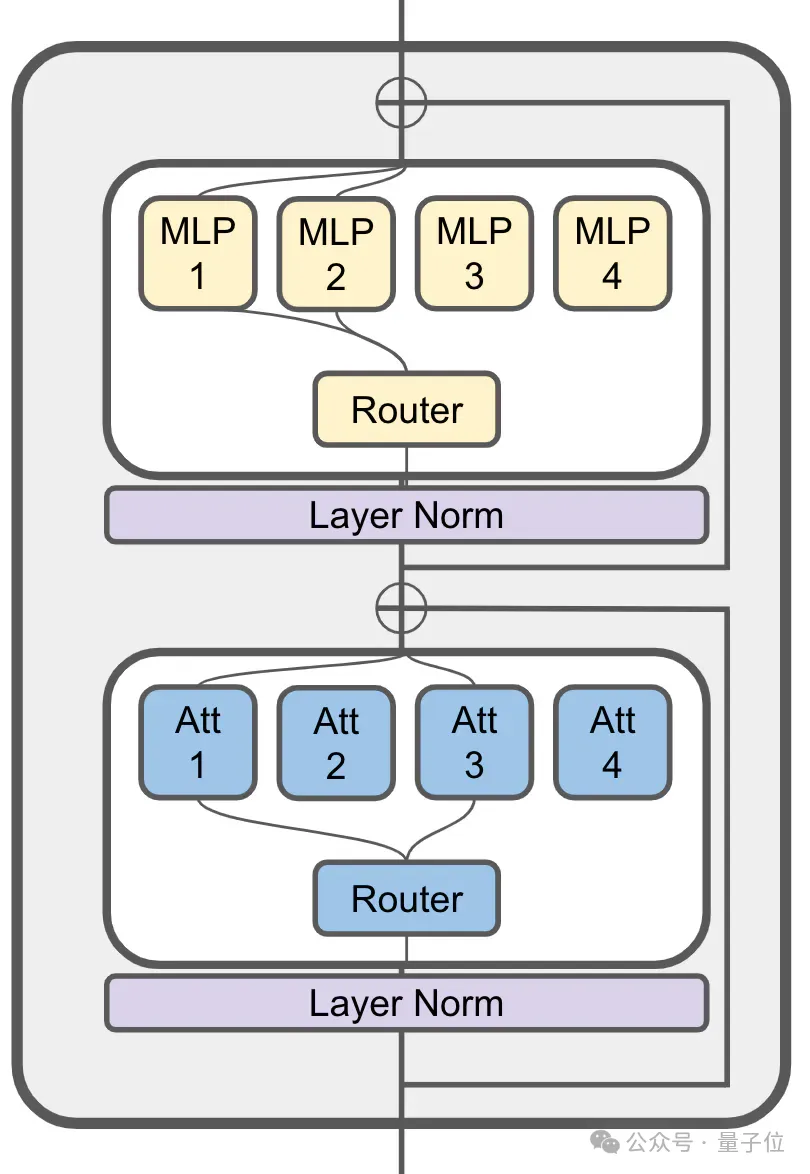
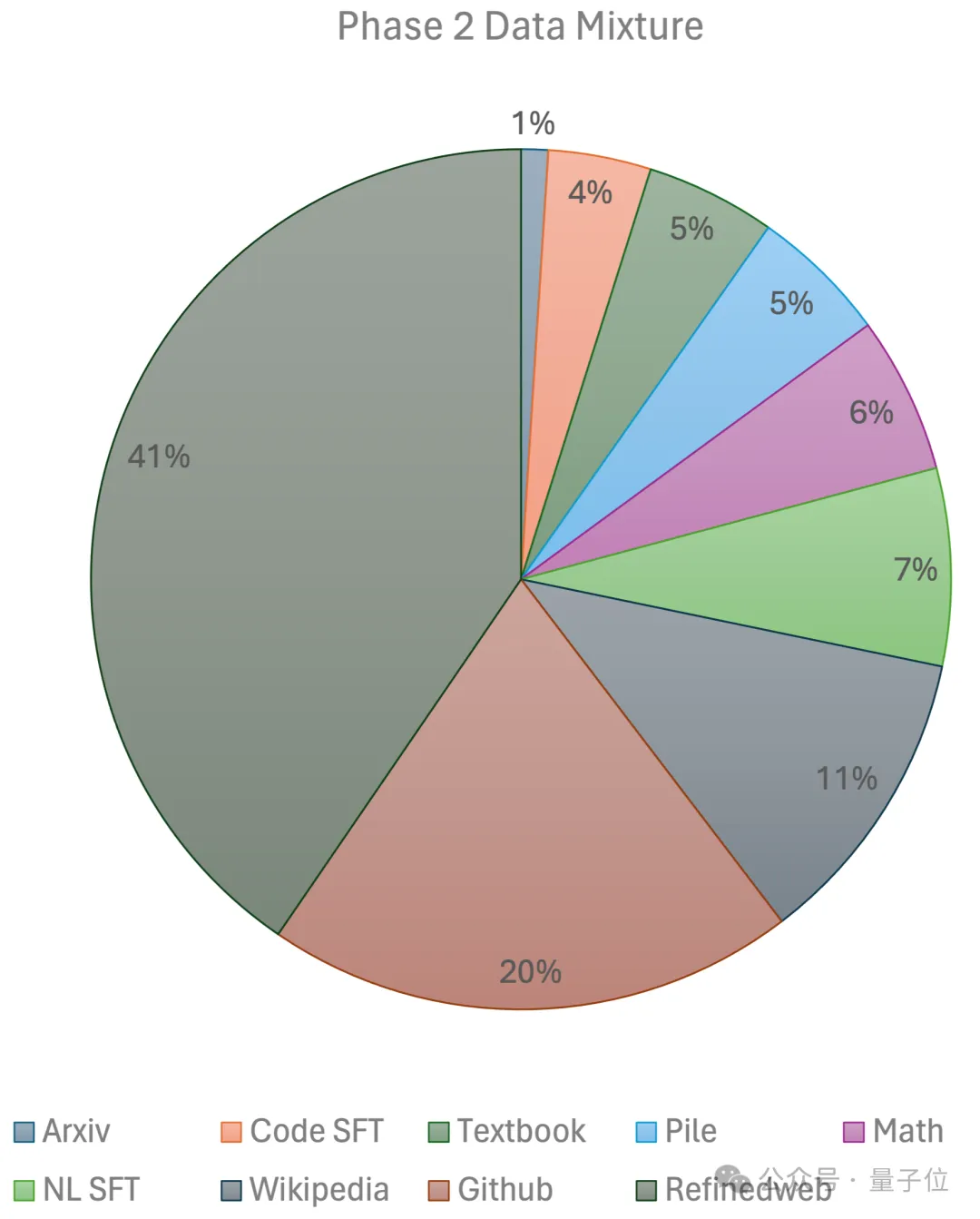
Peringkat kedua menggunakan pereputan kadar pembelajaran eksponen dan menggunakan 250 bilion token untuk melatih token daripada set data peringkat pertama dan set data sumber terbuka berkualiti ultra tinggi.
Akhirnya, pasukan menggunakan 96×H100 kluster GPU, menghabiskan masa 2 minggu dan kira-kira 80,000 dolar AS untuk melengkapkan JetMoE-8B. Lebih banyak butiran teknikal akan didedahkan dalam laporan teknikal yang dikeluarkan tidak lama lagi.
Semasa proses inferens, memandangkan JetMoE-8B hanya mempunyai
2.2 bilion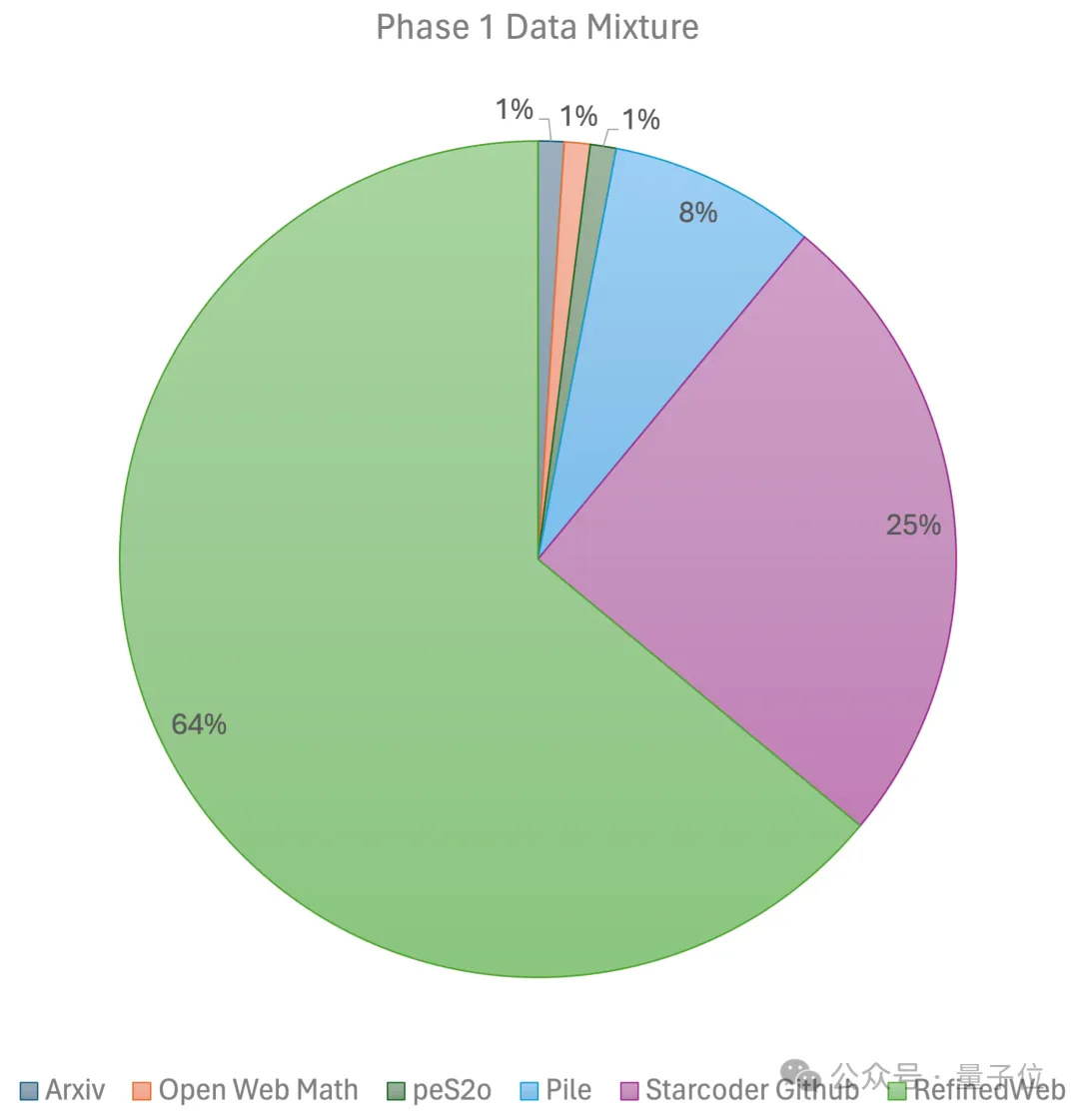
 Seperti yang ditunjukkan dalam rajah di bawah:
Seperti yang ditunjukkan dalam rajah di bawah:
JetMoE-8B mencapai 5 sota pada 8 penanda aras penilaian (termasuk arena model besar Open LLM Leaderboard) , mengatasi LLaMA-13B, LLaMA2-7B dan DeepseekMoE-16B. Mendapat 6.681 pada penanda aras MT-Bench, juga mengatasi model seperti LLaMA2 dan Vicuna dengan 13 bilion parameter.
Pengenalan pengarangJetMoE mempunyai 4 pengarang kesemuanya, mereka ialah: Penyelidik di MIT-IBM Watson Lab, NLP hala tuju penyelidikan. Berlulus dari Universiti Beihang dengan ijazah sarjana muda dan sarjana, dan pengalaman PhD dalam Institut Penyelidikan Mila yang diasaskan oleh Yoshua Bengio. ialah calon PhD di MIT, hala tuju penyelidikannya ialah pembelajaran mesin yang cekap data untuk pengimejan 3D. Lulus dari UC Berkeley dengan ijazah sarjana muda pada musim panas lalu, beliau menyertai MIT-IBM Watson Lab sebagai seorang penyelidik pelajarnya ialah Yikang Shen dan lain-lain. sedang belajar untuk PhD di MIT dan memulakan perniagaan, pengarah R&D AI MyShell Portal: https://github.com/myshell-ai/JetMoE sila layari: 51CTO AI.
Calon PhD di Princeton, dengan ijazah sarjana muda dalam bidang matematik gunaan dan sains komputer dari Universiti Peking Beliau kini juga merupakan penyelidik sambilan di Together.ai, bekerja dengan Tri Dao . 
Pautan rujukan: https://twitter.com/jiayq/status/1775935845205463292🜎
Atas ialah kandungan terperinci AS$100,000 untuk melatih model besar Llama-2! Semua orang Cina membina MoE baharu, Jia Yangqing, bekas CEO SD, melihat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 ppt ke perkataan
ppt ke perkataan
 Pengenalan kepada jenis antara muka
Pengenalan kepada jenis antara muka
 Perintah biasa OGG
Perintah biasa OGG
 Peranan alat formatfactory
Peranan alat formatfactory
 Perbezaan antara kursus python dan kursus c+
Perbezaan antara kursus python dan kursus c+
 perisian antivirus
perisian antivirus
 Penyelesaian kepada sifat folder Win7 tidak berkongsi halaman tab
Penyelesaian kepada sifat folder Win7 tidak berkongsi halaman tab
 Penggunaan treenode
Penggunaan treenode
 Bagaimana untuk menetapkan nombor halaman dalam perkataan
Bagaimana untuk menetapkan nombor halaman dalam perkataan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



