
 Peranti teknologi
AI
ICLR 2024 |. Model lapisan kritikal untuk serangan pintu belakang pembelajaran bersekutu
Peranti teknologi
AI
ICLR 2024 |. Model lapisan kritikal untuk serangan pintu belakang pembelajaran bersekutu
ICLR 2024 |. Model lapisan kritikal untuk serangan pintu belakang pembelajaran bersekutu

Pembelajaran bersekutu menggunakan pelbagai pihak untuk melatih model sementara privasi data dilindungi. Walau bagaimanapun, kerana pelayan tidak dapat memantau proses latihan yang dilakukan secara tempatan oleh peserta, peserta boleh mengusik model latihan tempatan, sekali gus menimbulkan risiko keselamatan kepada keseluruhan model pembelajaran bersekutu, seperti serangan pintu belakang.
Artikel ini memfokuskan pada cara melancarkan serangan pintu belakang ke atas pembelajaran bersekutu di bawah rangka kerja latihan yang dilindungi secara pertahanan. Makalah ini mendapati bahawa implantasi serangan pintu belakang lebih berkait rapat dengan beberapa lapisan rangkaian saraf, dan memanggil lapisan ini sebagai lapisan utama untuk serangan pintu belakang. Dalam pembelajaran bersekutu, pelanggan yang mengambil bahagian dalam latihan diedarkan pada peranti yang berbeza Mereka masing-masing melatih model mereka sendiri, dan kemudian memuat naik parameter model yang dikemas kini ke pelayan untuk pengagregatan. Memandangkan pelanggan yang mengambil bahagian dalam latihan tidak boleh dipercayai dan terdapat risiko tertentu, pelayan
Berdasarkan penemuan lapisan kunci pintu belakang, artikel ini mencadangkan untuk memintas pengesanan algoritma pertahanan dengan menyerang lapisan kunci pintu belakang , supaya sebilangan kecil peserta dapat dikawal untuk melakukan serangan pintu belakang yang cekap.

Tajuk kertas: Pembelajaran Bersekutu Pintu Belakang Dengan Meracuni Lapisan Kritikal Pintu Belakang
Pautan kertas: https://openreview.net/pdf?id=AJBGSVSTT2
Pautan kod: https://github.com/zhmzm.com/zhmzm.com Poisoning_Backdoor-critical_Layers_Attack
Kaedah
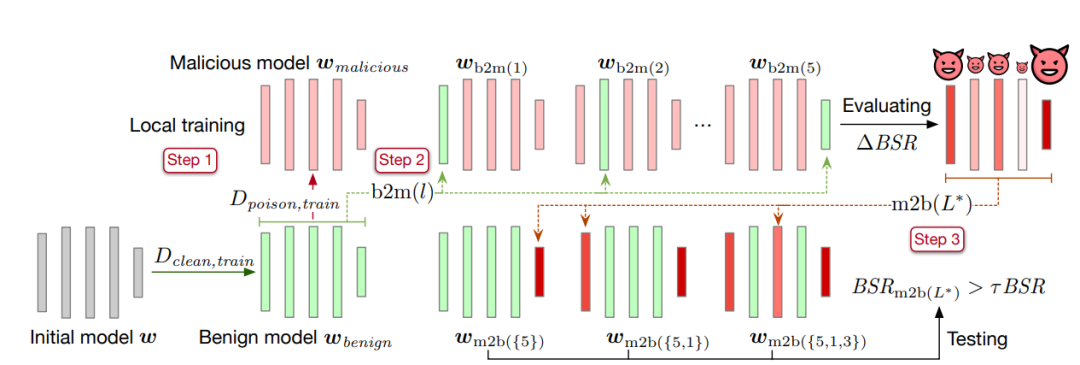
Artikel ini mencadangkan kaedah penggantian lapisan untuk mengenal pasti lapisan kritikal pintu belakang. Kaedah khusus adalah seperti berikut:
Langkah pertama ialah melatih model pada set data yang bersih sehingga penumpuan, dan menyimpan parameter model sebagai model jinak
 . Kemudian salin model jinak dan latihnya pada set data yang mengandungi pintu belakang Selepas penumpuan, simpan parameter model dan rekodkannya sebagai model berniat jahat.
. Kemudian salin model jinak dan latihnya pada set data yang mengandungi pintu belakang Selepas penumpuan, simpan parameter model dan rekodkannya sebagai model berniat jahat. Langkah kedua ialah menggantikan lapisan parameter dalam model jinak ke dalam model berniat jahat yang mengandungi pintu belakang, dan mengira kadar kejayaan serangan pintu belakang model yang dihasilkan
. Perbezaan antara kadar kejayaan serangan pintu belakang yang diperoleh dan kadar kejayaan serangan pintu belakang model berniat jahat BSR ialah ΔBSR, yang boleh digunakan untuk mendapatkan kesan lapisan ini pada serangan pintu belakang. Menggunakan kaedah yang sama untuk setiap lapisan dalam rangkaian saraf, anda boleh mendapatkan senarai kesan semua lapisan pada serangan pintu belakang. Langkah ketiga ialah menyusun semua lapisan mengikut kesannya terhadap serangan pintu belakang. Ambil lapisan dengan impak paling hebat daripada senarai dan tambahkannya pada set lapisan kritikal serangan pintu belakang
, dan benamkan parameter lapisan kritikal serangan pintu belakang (lapisan dalam set ) daripada model berniat jahat ke dalam model jinak. Kira kadar kejayaan serangan pintu belakang model yang diperoleh. Jika kadar kejayaan serangan pintu belakang lebih besar daripada ambang ditetapkan τ didarab dengan kadar kejayaan serangan pintu belakang model berniat jahat , algoritma dihentikan. Jika tidak berpuas hati, teruskan menambah lapisan terbesar antara lapisan yang tinggal dalam senarai ke lapisan kunci untuk serangan pintu belakang sehingga syarat dipenuhi.
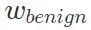 . Kemudian salin model jinak dan latihnya pada set data yang mengandungi pintu belakang Selepas penumpuan, simpan parameter model dan rekodkannya sebagai model berniat jahat
. Kemudian salin model jinak dan latihnya pada set data yang mengandungi pintu belakang Selepas penumpuan, simpan parameter model dan rekodkannya sebagai model berniat jahat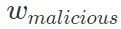 .
. 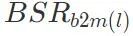 . Perbezaan antara kadar kejayaan serangan pintu belakang yang diperoleh dan kadar kejayaan serangan pintu belakang model berniat jahat BSR ialah ΔBSR, yang boleh digunakan untuk mendapatkan kesan lapisan ini pada serangan pintu belakang. Menggunakan kaedah yang sama untuk setiap lapisan dalam rangkaian saraf, anda boleh mendapatkan senarai kesan semua lapisan pada serangan pintu belakang.
. Perbezaan antara kadar kejayaan serangan pintu belakang yang diperoleh dan kadar kejayaan serangan pintu belakang model berniat jahat BSR ialah ΔBSR, yang boleh digunakan untuk mendapatkan kesan lapisan ini pada serangan pintu belakang. Menggunakan kaedah yang sama untuk setiap lapisan dalam rangkaian saraf, anda boleh mendapatkan senarai kesan semua lapisan pada serangan pintu belakang. 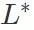 , dan benamkan parameter lapisan kritikal serangan pintu belakang (lapisan dalam set
, dan benamkan parameter lapisan kritikal serangan pintu belakang (lapisan dalam set  ) daripada model berniat jahat ke dalam model jinak. Kira kadar kejayaan serangan pintu belakang model yang diperoleh
) daripada model berniat jahat ke dalam model jinak. Kira kadar kejayaan serangan pintu belakang model yang diperoleh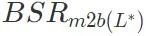 . Jika kadar kejayaan serangan pintu belakang lebih besar daripada ambang ditetapkan τ didarab dengan kadar kejayaan serangan pintu belakang model berniat jahat
. Jika kadar kejayaan serangan pintu belakang lebih besar daripada ambang ditetapkan τ didarab dengan kadar kejayaan serangan pintu belakang model berniat jahat 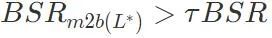 , algoritma dihentikan. Jika tidak berpuas hati, teruskan menambah lapisan terbesar antara lapisan yang tinggal dalam senarai ke lapisan kunci untuk serangan pintu belakang
, algoritma dihentikan. Jika tidak berpuas hati, teruskan menambah lapisan terbesar antara lapisan yang tinggal dalam senarai ke lapisan kunci untuk serangan pintu belakangSetelah mendapatkan koleksi lapisan utama serangan pintu belakang, artikel ini mencadangkan kaedah untuk memintas kaedah pengesanan pertahanan dengan menyerang lapisan utama pintu belakang. Selain itu, kertas kerja ini memperkenalkan pengagregatan simulasi dan pusat model jinak untuk mengurangkan lagi jarak dari model jinak yang lain.
Hasil percubaan
Artikel ini mengesahkan keberkesanan serangan lapisan kunci pintu belakang pada pelbagai kaedah pertahanan pada set data CIFAR-10 dan MNIST. Percubaan akan menggunakan kadar kejayaan serangan pintu belakang BSR dan kadar penerimaan model berniat jahat MAR (kadar penerimaan model jinak BAR) sebagai penunjuk untuk mengukur keberkesanan serangan.
Pertama sekali, serangan berasaskan lapisan LP Attack boleh membenarkan pelanggan berniat jahat mendapatkan kadar pemilihan yang tinggi. Seperti yang ditunjukkan dalam jadual di bawah, LP Attack mencapai kadar penerimaan sebanyak 90% pada set data CIFAR-10, yang jauh lebih tinggi daripada 34% pengguna jinak.
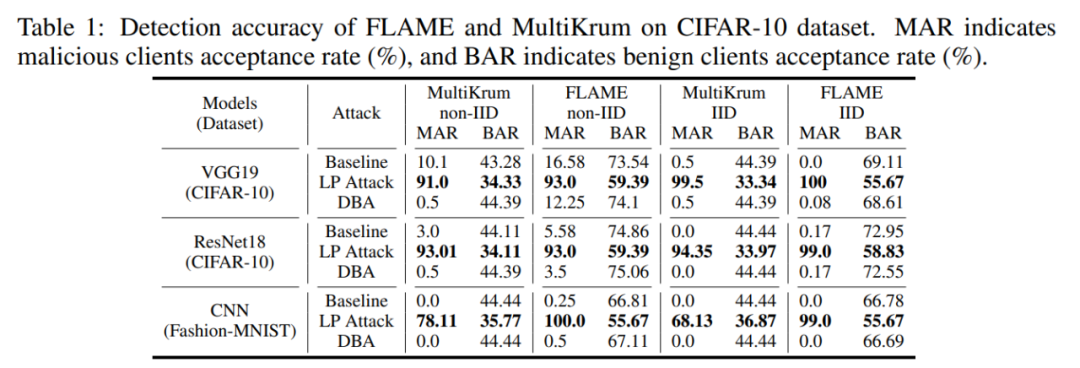
Kemudian, LP Attack boleh mencapai kadar kejayaan serangan pintu belakang yang tinggi, walaupun dalam tetapan dengan hanya 10% pelanggan berniat jahat. Seperti yang ditunjukkan dalam jadual di bawah, LP Attack boleh mencapai kadar kejayaan serangan pintu belakang yang tinggi BSR di bawah perlindungan set data yang berbeza dan kaedah pertahanan yang berbeza.
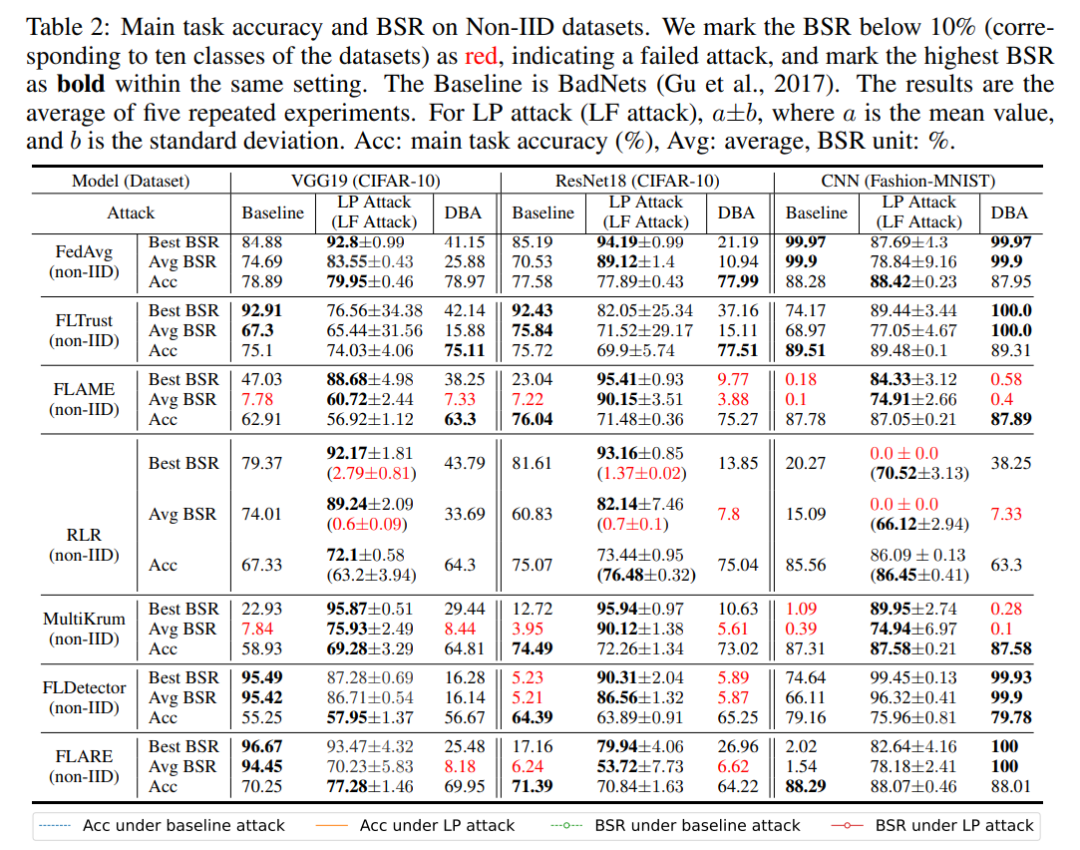
Dalam eksperimen ablasi, artikel ini masing-masing meracuni lapisan kunci pintu belakang dan lapisan kunci bukan pintu belakang dan mengukur kadar kejayaan serangan pintu belakang bagi kedua-dua eksperimen. Seperti yang ditunjukkan dalam rajah di bawah, apabila menyerang bilangan lapisan yang sama, kadar kejayaan meracuni lapisan kunci bukan pintu belakang adalah jauh lebih rendah daripada meracuni lapisan kunci pintu belakang Ini menunjukkan bahawa algoritma dalam artikel ini boleh memilih kunci serangan pintu belakang yang berkesan lapisan.
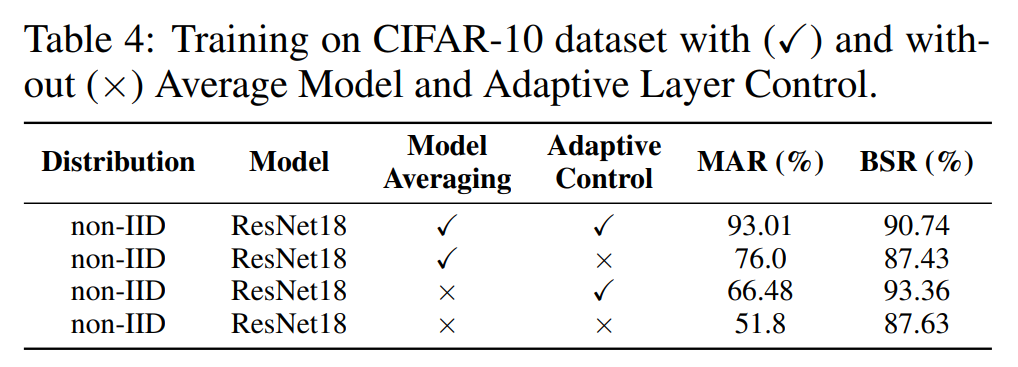
Selain itu, kami menjalankan eksperimen ablasi pada modul pengagregatan model Model Averaging dan modul kawalan adaptif Kawalan Adaptif. Seperti yang ditunjukkan dalam jadual di bawah, kedua-dua modul meningkatkan kadar pemilihan dan kadar kejayaan serangan pintu belakang, membuktikan keberkesanan kedua-dua modul ini.
Ringkasan
Artikel ini mendapati bahawa serangan pintu belakang berkait rapat dengan beberapa lapisan, dan mencadangkan algoritma untuk mencari lapisan utama serangan pintu belakang. Kertas kerja ini mencadangkan serangan dari segi lapisan pada algoritma perlindungan dalam pembelajaran bersekutu dengan menggunakan pintu belakang untuk menyerang lapisan utama. Serangan yang dicadangkan mendedahkan kelemahan tiga jenis kaedah pertahanan semasa, menunjukkan bahawa algoritma pertahanan yang lebih canggih akan diperlukan untuk melindungi keselamatan pembelajaran bersekutu pada masa hadapan.
Pengenalan kepada pengarang
Zhuang Haomin, berkelulusan dari Universiti Teknologi China Selatan dengan ijazah sarjana muda Beliau bekerja sebagai pembantu penyelidik di Makmal IntelliSys Universiti Negeri Louisiana dan sedang belajar untuk PhD di Universiti of. Notre Dame. Arah penyelidikan utama ialah serangan pintu belakang dan serangan sampel musuh.
Atas ialah kandungan terperinci ICLR 2024 |. Model lapisan kritikal untuk serangan pintu belakang pembelajaran bersekutu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Ia juga merupakan video Tusheng, tetapi PaintsUndo telah mengambil laluan yang berbeza. Pengarang ControlNet LvminZhang mula hidup semula! Kali ini saya menyasarkan bidang lukisan. Projek baharu PaintsUndo telah menerima 1.4kstar (masih meningkat secara menggila) tidak lama selepas ia dilancarkan. Alamat projek: https://github.com/lllyasviel/Paints-UNDO Melalui projek ini, pengguna memasukkan imej statik, dan PaintsUndo secara automatik boleh membantu anda menjana video keseluruhan proses mengecat, daripada draf baris hingga produk siap . Semasa proses lukisan, perubahan garisan adalah menakjubkan Hasil akhir video sangat serupa dengan imej asal: Mari kita lihat lukisan lengkap.
 Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Jun 24, 2024 pm 03:04 PM
Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Jun 24, 2024 pm 03:04 PM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Dalam proses pembangunan kecerdasan buatan, kawalan dan bimbingan model bahasa besar (LLM) sentiasa menjadi salah satu cabaran utama, bertujuan untuk memastikan model ini adalah kedua-duanya. berkuasa dan selamat untuk masyarakat manusia. Usaha awal tertumpu kepada kaedah pembelajaran pengukuhan melalui maklum balas manusia (RL
 Kumpulan pertama dron di negara ini yang menyampaikan notis kemasukan peperiksaan masuk kolej, pelajar baru 2024 Universiti Teknologi China Selatan 'gembira dari langit'
Jul 17, 2024 am 03:15 AM
Kumpulan pertama dron di negara ini yang menyampaikan notis kemasukan peperiksaan masuk kolej, pelajar baru 2024 Universiti Teknologi China Selatan 'gembira dari langit'
Jul 17, 2024 am 03:15 AM
Laman web ini melaporkan pada 16 Julai bahawa menurut berita rasmi dari South China University of Technology, Guangzhou Post dan South China University of Technology bersama-sama meneroka penggunaan dron untuk menyampaikan notis kemasukan peperiksaan kemasukan ke kolej kepada calon empat yang menunggu datang dari Universiti Teknologi China Selatan tiba melalui penerbangan terus. Pada pagi 15 Julai, Tu Sulan, calon yang diterima masuk ke jurusan kimia Universiti Teknologi China Selatan (Kelas Pelan Asas Kuat), dan pelajar Zhong Mingcheng, Wang Yunyi, dan Li Jinquan, yang diterima masuk ke sukan itu. jurusan latihan, "melihat ke atas" di Vanke Mountain View City, Daerah Huangpu, Guangzhou Menanti-nantikannya" kerana notis kemasukan mereka akan "datang dari syurga dengan kegembiraan". Menurut laporan, keseluruhan proses penghantaran tidak memerlukan kawalan manual oleh juruterbang profesional Sebaliknya, laluan sistem ditetapkan melalui pusat kawalan penerbangan di latar belakang dron. Pada pukul 11 pagi, kakitangan kemasukan menyerahkan notis yang dimeterai kepada perkhidmatan pos
 Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Semua pengarang kertas kerja ini adalah daripada pasukan guru Zhang Lingming di Universiti Illinois di Urbana-Champaign (UIUC), termasuk: Steven Code repair; pelajar kedoktoran tahun empat, penyelidik
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Tunjukkan rantai sebab kepada LLM dan ia mempelajari aksiom. AI sudah pun membantu ahli matematik dan saintis menjalankan penyelidikan Contohnya, ahli matematik terkenal Terence Tao telah berulang kali berkongsi pengalaman penyelidikan dan penerokaannya dengan bantuan alatan AI seperti GPT. Untuk AI bersaing dalam bidang ini, keupayaan penaakulan sebab yang kukuh dan boleh dipercayai adalah penting. Penyelidikan yang akan diperkenalkan dalam artikel ini mendapati bahawa model Transformer yang dilatih mengenai demonstrasi aksiom transitiviti sebab pada graf kecil boleh digeneralisasikan kepada aksiom transitiviti pada graf besar. Dalam erti kata lain, jika Transformer belajar untuk melakukan penaakulan sebab yang mudah, ia boleh digunakan untuk penaakulan sebab yang lebih kompleks. Rangka kerja latihan aksiomatik yang dicadangkan oleh pasukan adalah paradigma baharu untuk pembelajaran penaakulan sebab berdasarkan data pasif, dengan hanya demonstrasi
 Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
sorakan! Bagaimana rasanya apabila perbincangan kertas adalah perkataan? Baru-baru ini, pelajar di Universiti Stanford mencipta alphaXiv, forum perbincangan terbuka untuk kertas arXiv yang membenarkan soalan dan ulasan disiarkan terus pada mana-mana kertas arXiv. Pautan laman web: https://alphaxiv.org/ Malah, tidak perlu melawati tapak web ini secara khusus. Hanya tukar arXiv dalam mana-mana URL kepada alphaXiv untuk terus membuka kertas yang sepadan di forum alphaXiv: anda boleh mencari perenggan dengan tepat dalam. kertas itu, Ayat: Dalam ruang perbincangan di sebelah kanan, pengguna boleh menyiarkan soalan untuk bertanya kepada pengarang tentang idea dan butiran kertas tersebut Sebagai contoh, mereka juga boleh mengulas kandungan kertas tersebut, seperti: "Diberikan kepada
 Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Baru-baru ini, Hipotesis Riemann, yang dikenali sebagai salah satu daripada tujuh masalah utama milenium, telah mencapai kejayaan baharu. Hipotesis Riemann ialah masalah yang tidak dapat diselesaikan yang sangat penting dalam matematik, berkaitan dengan sifat tepat taburan nombor perdana (nombor perdana ialah nombor yang hanya boleh dibahagikan dengan 1 dan dirinya sendiri, dan ia memainkan peranan asas dalam teori nombor). Dalam kesusasteraan matematik hari ini, terdapat lebih daripada seribu proposisi matematik berdasarkan penubuhan Hipotesis Riemann (atau bentuk umumnya). Dalam erti kata lain, sebaik sahaja Hipotesis Riemann dan bentuk umumnya dibuktikan, lebih daripada seribu proposisi ini akan ditetapkan sebagai teorem, yang akan memberi kesan yang mendalam terhadap bidang matematik dan jika Hipotesis Riemann terbukti salah, maka antara cadangan ini sebahagian daripadanya juga akan kehilangan keberkesanannya. Kejayaan baharu datang daripada profesor matematik MIT Larry Guth dan Universiti Oxford
