
 Peranti teknologi
AI
Model AI super resolusi khas dua dimensi APISR: tersedia dalam talian, dipilih oleh CVPR
Peranti teknologi
AI
Model AI super resolusi khas dua dimensi APISR: tersedia dalam talian, dipilih oleh CVPR
Model AI super resolusi khas dua dimensi APISR: tersedia dalam talian, dipilih oleh CVPR

Karya animasi seperti "Dragon Ball", "Pokémon", "Neon Genesis Evangelion" dan animasi lain yang disiarkan pada abad yang lalu adalah sebahagian daripada kenangan zaman kanak-kanak ramai orang. Ia telah membawa kita visi yang penuh semangat, persahabatan dan impian. perjalanan daripada. Pada satu ketika, kami tiba-tiba akan mempunyai keinginan untuk melihat semula kenangan zaman kanak-kanak ini, tetapi kami mungkin menyesal mendapati bahawa kadar pengecaman kenangan zaman kanak-kanak ini adalah sangat rendah, dan adalah mustahil untuk mencipta pengalaman visual yang baik pada TV skrin lebar, supaya ia menghalang kami berkongsi kenangan zaman kanak-kanak ini dengan kanak-kanak yang membesar dalam dunia digital dengan resolusi HD.
Untuk persaingan sengit seperti ini (dan pasaran yang berpotensi), salah satu cara adalah dengan meminta syarikat animasi menghasilkan pembuatan semula. Tugas ini akan menelan kos yang tinggi dari segi manusia dan kewangan, tetapi mungkin lebih bernilai daripada mengabaikan masalah dan kehilangan bahagian pasaran.
Prestasi kecerdasan buatan berbilang mod menjadi semakin berkuasa, dan menggunakan teknologi resolusi super berasaskan AI untuk meningkatkan peleraian animasi telah menjadi arah yang patut diterokai. Teknologi ini boleh membina semula imej resolusi tinggi daripada sebilangan kecil imej resolusi rendah, menjadikan imej animasi lebih jelas dan terperinci. Kaedah ini menggunakan kedalaman dengan melatih sejumlah besar data sampel
Baru-baru ini, pasukan bersama dari Universiti Michigan, Universiti Yale dan Universiti Zhejiang mencipta satu set kaedah baharu yang agak praktikal untuk tugas resolusi super animasi dengan menganalisis proses pengeluaran animasi kaedah. Ini termasuk set data, model dan beberapa penambahbaikan. Penyelidikan ini telah diterima ke dalam persidangan CVPR 2024. Pasukan itu juga membuka sumber kod yang berkaitan dan melancarkan model percubaan pada Huggingface.

Tajuk kertas: APISR: Anime Production Inspired Real-World Anime Super-Resolution
-
Alamat kertas: https://arxiv.org/pdf/2403.01598.
:Co. ://github.com/Kiteretsu77/APISR - Model percubaan: https://huggingface.co/spaces/HikariDawn/APISR
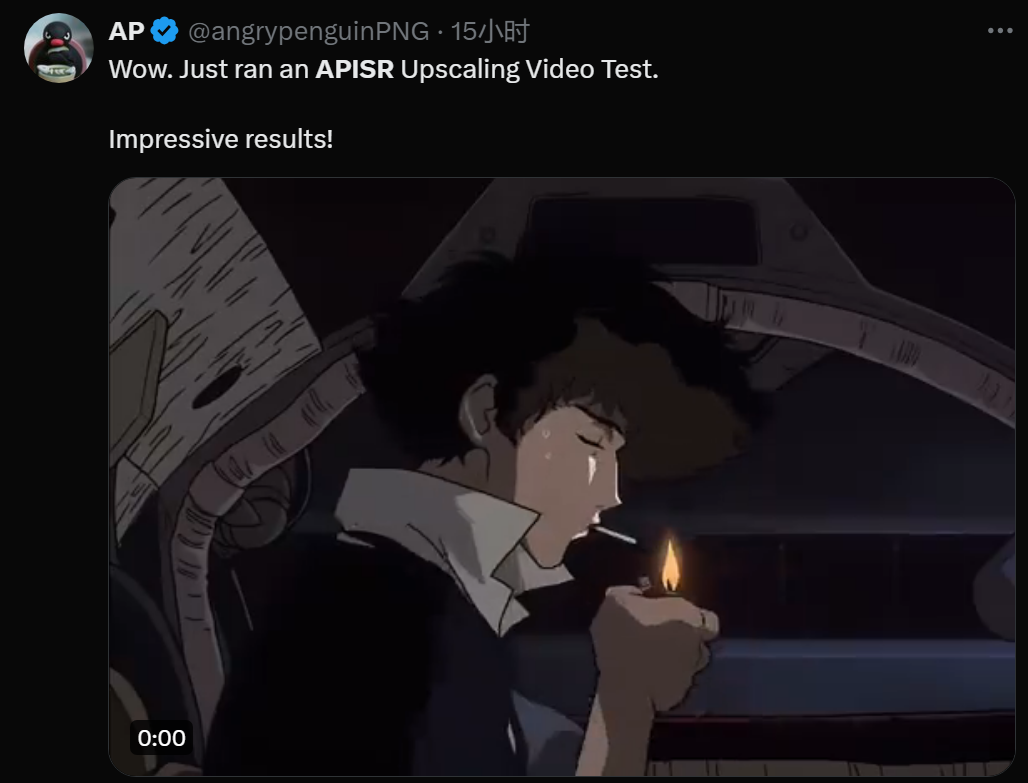
- Gambar di bawah adalah apa yang laman web ini cuba menggunakan tangkapan skrin episod pertama "Dragon Ball" Akibatnya, kesannya dapat dilihat dengan mata kasar.
Selain itu, sesetengah orang telah mencuba menggunakan teknologi ini untuk meningkatkan resolusi video, dan hasilnya sangat bagus: 
 Proses pengeluaran animasi
Proses pengeluaran animasi
Untuk memahami kaedah baru ini, inovasi mari kita lihat dahulu Bagaimana anime secara umumnya dibuat.
Pertama, lakaran manusia di atas kertas, yang kemudiannya diwarnakan dan dipertingkatkan melalui pemprosesan imej janaan komputer (CGI). Lakaran yang diproses ini kemudiannya disambungkan untuk mencipta video. Walau bagaimanapun, memandangkan proses lukisan sangat memerlukan tenaga kerja dan mata manusia tidak sensitif terhadap gerakan, apabila mengarang video, amalan standard industri adalah menggunakan semula satu imej untuk berbilang bingkai berturut-turut. Dengan menganalisis proses ini, pasukan bersama tidak dapat mengelak daripada tertanya-tanya sama ada perlu menggunakan model video dan set data video untuk melatih model resolusi super animasi: adalah mungkin untuk melaksanakan resolusi super pada imej dan kemudian menyambung imej-imej ini! Jadi mereka memutuskan untuk menggunakan kaedah dan set data berasaskan imej untuk mencipta rangka kerja resolusi super dan pemulihan bersatu yang sesuai untuk imej dan video.Kaedah baharu yang dicadangkan
Set data resolusi super imej (API SR) untuk pengeluaran animasi
Pasukan mencadangkan set data API SR Berikut ialah pengenalan ringkas kepada kaedah pengumpulan dan organisasinya. Kaedah ini mengambil kesempatan daripada ciri-ciri video animasi (lihat Rajah 2) dan boleh memilih bingkai yang paling kurang mampat dan paling bermaklumat daripada video.
Pengumpulan imej berasaskan bingkai-I: Pemampatan video melibatkan pertukaran antara kualiti video dan saiz data. Terdapat banyak piawaian pemampatan video sekarang, masing-masing dengan sistem kejuruteraan kompleksnya sendiri, tetapi semuanya mempunyai reka bentuk tulang belakang yang serupa. 
Pemilihan berdasarkan kerumitan imej: Pasukan ini menapis kumpulan I-frame awal berdasarkan Penilaian Kerumitan Imej (ICA), yang merupakan metrik yang lebih sesuai untuk animasi, lihat Rajah 4.

Set Data API: Pasukan ini mengumpul 562 video anime berkualiti tinggi secara manual. 10 bingkai pemarkahan tertinggi daripada setiap video kemudiannya dikumpulkan berdasarkan dua langkah di atas. Kemudian beberapa penapisan dijalankan untuk mengalih keluar imej yang tidak sesuai, dan akhirnya satu set data yang mengandungi 3740 imej berkualiti tinggi diperolehi. Rajah 5 menunjukkan beberapa contoh imej. Selain itu, kita juga boleh melihat kelebihan set data API dari segi kerumitan imej daripada Rajah 3b.

Kembali kepada resolusi 720P asal: Dengan mengkaji proses pengeluaran animasi, anda dapat melihat bahawa kebanyakan pengeluaran animasi menggunakan format 720P (iaitu, imej adalah 720 piksel tinggi). Walau bagaimanapun, dalam senario dunia sebenar, anime sering tersilap ditingkatkan kepada 1080P atau format lain dalam usaha untuk menyeragamkan format multimedia. Pasukan secara eksperimen mendapati bahawa mengubah saiz semua imej anime kepada 720P asli memberikan ketumpatan ciri yang dibayangkan oleh pencipta, bersama dengan garis lukisan tangan anime yang lebih ketat dan maklumat CGI.
Model degradasi praktikal untuk animasi
Dalam tugas resolusi super dunia sebenar, reka bentuk model degradasi adalah sangat penting. Berdasarkan model degradasi tertib tinggi dan model pemulihan mampatan video berasaskan imej terkini, pasukan mencadangkan dua penambahbaikan yang boleh memulihkan garisan lukisan tangan yang herot dan pelbagai artifak mampatan, dan juga meningkatkan perwakilan model degradasi. Rajah 6a menggambarkan model degradasi ini.
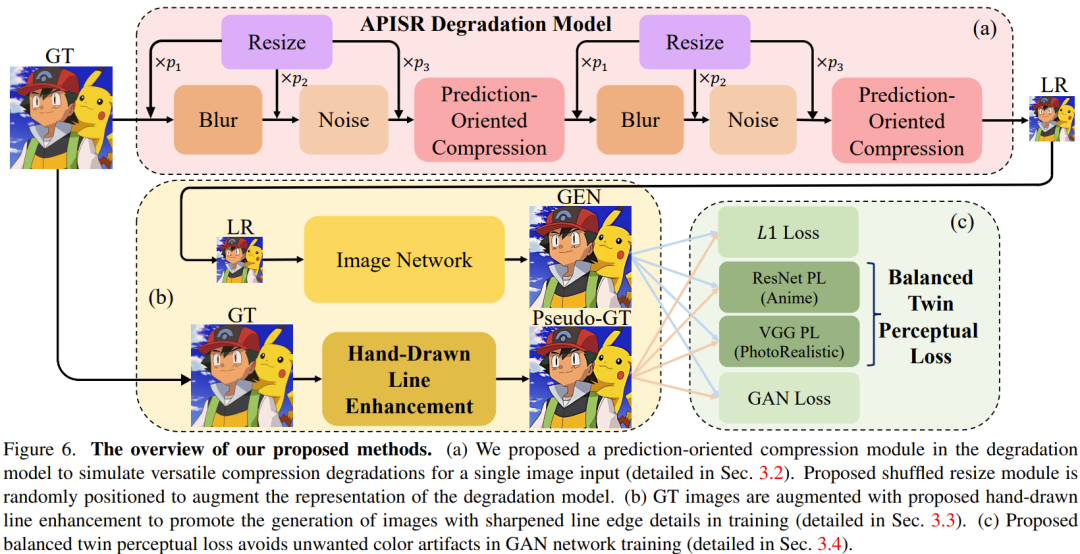
Mampatan berorientasikan ramalan: Untuk tugas pemulihan animasi artifak mampatan video, menggunakan model degradasi imej menimbulkan masalah yang sukar. Ini kerana kaedah pemampatan format imej JPEG dan prinsip pemampatan video adalah berbeza.
Untuk menangani kesukaran sedemikian, pasukan mereka bentuk model mampatan berorientasikan ramalan yang digunakan dalam model degradasi imej. Modul ini memerlukan algoritma pemampatan video untuk memampatkan satu bingkai input.
Dengan pendekatan ini, model degradasi imej dapat mensintesis artifak mampatan yang serupa dengan yang diperhatikan dalam pemampatan video berbilang bingkai biasa, seperti yang ditunjukkan dalam Rajah 7. Kemudian, dengan memasukkan imej tersintesis ini ke dalam rangkaian peleraian super imej, sistem boleh mempelajari corak pelbagai artifak mampatan dengan berkesan dan memulihkannya.

Kocok tertib mengubah saiz modul: Model yang merosot dalam bidang peleraian super dunia sebenar perlu mempertimbangkan modul kabur, saiz semula, hingar dan mampatan. Kabur, hingar dan mampatan ialah artifak dunia sebenar yang boleh disintesis melalui model atau algoritma matematik yang jelas. Walau bagaimanapun, logik modul mengubah saiz adalah berbeza sama sekali. Saiz semula bukan sebahagian daripada penjanaan imej semula jadi tetapi diperkenalkan khusus untuk resolusi super set data berpasangan. Oleh itu, modul ubah saiz tetap sebelum ini tidak begitu sesuai. Pasukan itu mencadangkan penyelesaian yang lebih mantap dan cekap yang melibatkan penempatan semula operasi saiz semula secara rawak dalam susunan berbeza dalam model yang merosot.
Tingkatkan garisan lukisan tangan untuk animasi
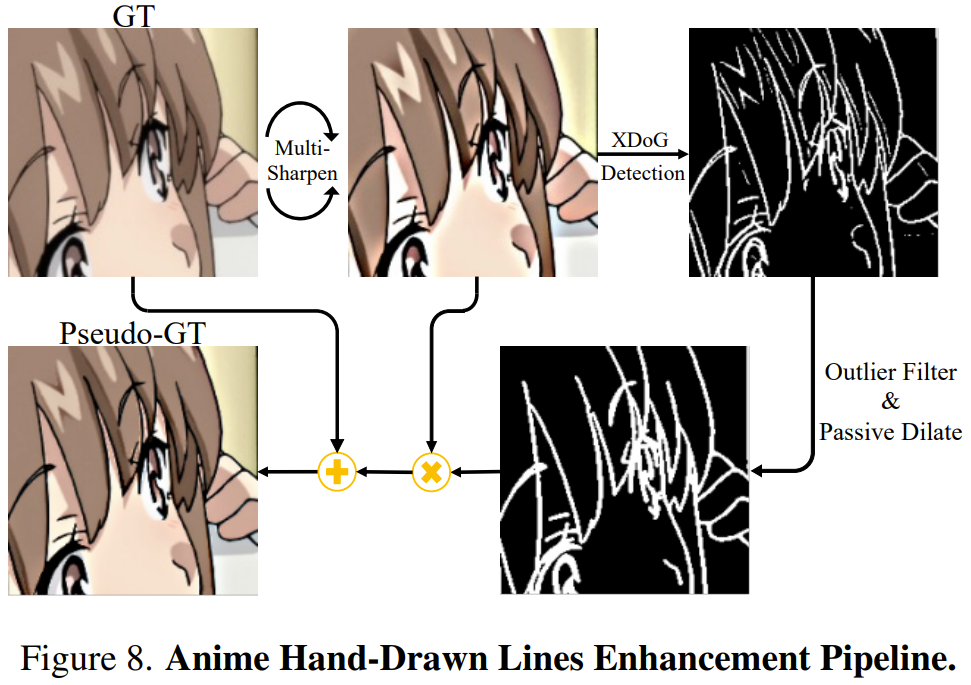
Pilihan pasukan adalah untuk mengekstrak terus maklumat garisan lukisan tangan yang diasah dan menggabungkannya dengan ground truth (GT/ground-truth) untuk membentuk pseudo-GT. Dengan memperkenalkan pseudo-GT yang disasarkan khusus ini ke dalam proses latihan resolusi super, rangkaian boleh menjana garisan lukisan tangan yang tajam tanpa memperkenalkan modul rangkaian saraf tambahan atau rangkaian pasca pemprosesan yang berasingan.
Untuk mengekstrak garisan lukisan tangan dengan lebih baik, pasukan menggunakan XDoG, algoritma pengekstrakan lakaran berdasarkan kernel Gaussian piksel demi piksel, yang boleh mengekstrak peta tepi tajam GT.
Walau bagaimanapun, peta tepi XDoG mengalami hingar yang berlebihan, mengandungi piksel terpencil dan perwakilan garis putus-putus. Untuk menyelesaikan masalah ini, pasukan mencadangkan teknik penapisan luar yang dipasangkan dengan kaedah pelebaran pasif yang direka khas. Dengan cara ini, perwakilan yang lebih koheren dan tidak terganggu bagi garisan yang dilukis dengan tangan diperolehi.
Pasukan secara eksperimen mendapati GT pra-proses yang terlalu mengasah boleh menjadikan tepi garisan yang dilukis dengan tangan lebih ketara daripada butiran tepi bayang-bayang lain yang tidak berkaitan, menjadikannya lebih mudah bagi penapis terpencil untuk membezakan perbezaannya. Untuk melakukan ini, pasukan mencadangkan untuk melakukan tiga pusingan operasi penyamaran pada GT terlebih dahulu. Rajah 8 memberikan gambaran ringkas tentang proses ini.
Kehilangan Dwi Persepsi Seimbang untuk Animasi
Terdapat juga isu artifak warna yang tidak diingini, terutamanya disebabkan oleh ketidakkonsistenan domain data dalam latihan antara penjana dan kehilangan persepsi.
Untuk menyelesaikan masalah ini dan mengimbangi kelemahan kaedah sebelumnya, pendekatan pasukan adalah menggunakan ResNet terlatih, yang dilatih mengenai tugas pengelasan sasaran animasi pada set data Danbooru. Dataset Danbooru ialah pangkalan data ilustrasi anime yang mengandungi anotasi besar dan kaya. Memandangkan rangkaian pralatihan ini ialah ResNet50 dan bukannya VGG, pasukan itu juga mencadangkan perbandingan lapisan pertengahan yang serupa.
Walau bagaimanapun, jika anda hanya menggunakan kerugian berasaskan ResNet, anda mungkin mengalami hasil visual yang lemah Ini disebabkan oleh kecenderungan yang wujud dalam set data Danbooru - kebanyakan imej dalam set data ini adalah wajah manusia atau ilustrasi yang agak ringkas. Oleh itu, pasukan mengambil kira dan memutuskan untuk menggunakan ciri dunia sebenar sebagai bantuan untuk membimbing kehilangan persepsi berasaskan ResNet semasa latihan. Kaedah ini menghasilkan imej yang menarik secara visual di samping menyelesaikan masalah warna yang tidak diingini.
Eksperimen
Butiran pelaksanaan
Dalam percubaan, pasukan menggunakan set data API yang baru dicadangkan sebagai set data latihan untuk rangkaian imej. Bagi rangkaian imej, versi kecil GRL digunakan dengan modul pensampelan konvolusi yang terdekat.
Sila rujuk kertas asal untuk butiran dan parameter lanjut.
Perbandingan dengan kaedah terbaik semasa
Pasukan secara kuantitatif dan kualitatif membandingkan APISR yang baru dicadangkan dengan beberapa kaedah lanjutan lain, termasuk Real-ESRGAN, BSRGAN, RealBasicVSR, AnimeSR dan VQD-SR.
Perbandingan kuantitatif
Seperti yang ditunjukkan dalam Jadual 1, model baharu mempunyai saiz rangkaian terkecil, dengan hanya 1.03M parameter, tetapi prestasinya pada semua penunjuk melebihi semua kaedah lain.
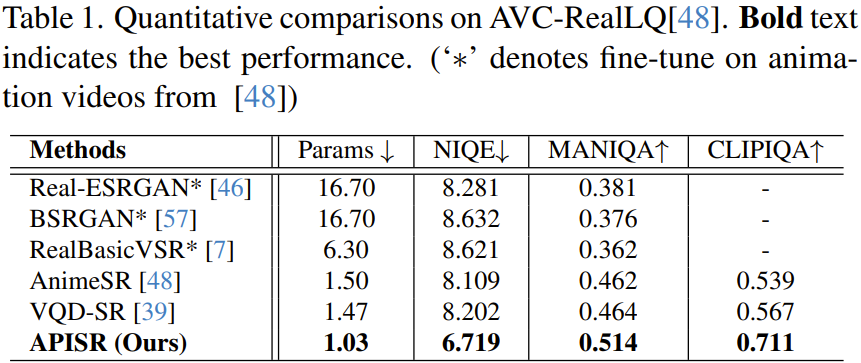
Pasukan terutamanya menekankan peranan model mampatan berorientasikan ramalan.
Selain itu, perlu diingatkan bahawa kaedah baharu itu mencapai keputusan sedemikian hanya dengan kerumitan sampel latihan masing-masing 13.3% dan 25% untuk AnimeSR dan VQDSR. Ini disebabkan terutamanya oleh pengenalan penilaian kerumitan imej dalam proses pengisihan set data, yang boleh meningkatkan kesan pembelajaran perwakilan imej animasi dengan memilih imej yang kaya dengan maklumat. Tambahan pula, terima kasih kepada model degradasi eksplisit yang baru direka, tiada latihan diperlukan pada bahagian model degradasi.
Perbandingan kualitatif
Seperti yang ditunjukkan dalam Rajah 10, kualiti visual yang diperolehi oleh APISR adalah jauh lebih baik daripada kaedah lain.

Pasukan juga menjalankan kajian ablasi untuk mengesahkan keberkesanan set data baharu, model degradasi dan reka bentuk kehilangan Sila lihat kertas asal untuk butiran.
Atas ialah kandungan terperinci Model AI super resolusi khas dua dimensi APISR: tersedia dalam talian, dipilih oleh CVPR. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Ia juga merupakan video Tusheng, tetapi PaintsUndo telah mengambil laluan yang berbeza. Pengarang ControlNet LvminZhang mula hidup semula! Kali ini saya menyasarkan bidang lukisan. Projek baharu PaintsUndo telah menerima 1.4kstar (masih meningkat secara menggila) tidak lama selepas ia dilancarkan. Alamat projek: https://github.com/lllyasviel/Paints-UNDO Melalui projek ini, pengguna memasukkan imej statik, dan PaintsUndo secara automatik boleh membantu anda menjana video keseluruhan proses mengecat, daripada draf baris hingga produk siap . Semasa proses lukisan, perubahan garisan adalah menakjubkan Hasil akhir video sangat serupa dengan imej asal: Mari kita lihat lukisan lengkap.
 Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Jun 24, 2024 pm 03:04 PM
Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Jun 24, 2024 pm 03:04 PM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Dalam proses pembangunan kecerdasan buatan, kawalan dan bimbingan model bahasa besar (LLM) sentiasa menjadi salah satu cabaran utama, bertujuan untuk memastikan model ini adalah kedua-duanya. berkuasa dan selamat untuk masyarakat manusia. Usaha awal tertumpu kepada kaedah pembelajaran pengukuhan melalui maklum balas manusia (RL
 Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Semua pengarang kertas kerja ini adalah daripada pasukan guru Zhang Lingming di Universiti Illinois di Urbana-Champaign (UIUC), termasuk: Steven Code repair; pelajar kedoktoran tahun empat, penyelidik
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Tunjukkan rantai sebab kepada LLM dan ia mempelajari aksiom. AI sudah pun membantu ahli matematik dan saintis menjalankan penyelidikan Contohnya, ahli matematik terkenal Terence Tao telah berulang kali berkongsi pengalaman penyelidikan dan penerokaannya dengan bantuan alatan AI seperti GPT. Untuk AI bersaing dalam bidang ini, keupayaan penaakulan sebab yang kukuh dan boleh dipercayai adalah penting. Penyelidikan yang akan diperkenalkan dalam artikel ini mendapati bahawa model Transformer yang dilatih mengenai demonstrasi aksiom transitiviti sebab pada graf kecil boleh digeneralisasikan kepada aksiom transitiviti pada graf besar. Dalam erti kata lain, jika Transformer belajar untuk melakukan penaakulan sebab yang mudah, ia boleh digunakan untuk penaakulan sebab yang lebih kompleks. Rangka kerja latihan aksiomatik yang dicadangkan oleh pasukan adalah paradigma baharu untuk pembelajaran penaakulan sebab berdasarkan data pasif, dengan hanya demonstrasi
 Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Baru-baru ini, Hipotesis Riemann, yang dikenali sebagai salah satu daripada tujuh masalah utama milenium, telah mencapai kejayaan baharu. Hipotesis Riemann ialah masalah yang tidak dapat diselesaikan yang sangat penting dalam matematik, berkaitan dengan sifat tepat taburan nombor perdana (nombor perdana ialah nombor yang hanya boleh dibahagikan dengan 1 dan dirinya sendiri, dan ia memainkan peranan asas dalam teori nombor). Dalam kesusasteraan matematik hari ini, terdapat lebih daripada seribu proposisi matematik berdasarkan penubuhan Hipotesis Riemann (atau bentuk umumnya). Dalam erti kata lain, sebaik sahaja Hipotesis Riemann dan bentuk umumnya dibuktikan, lebih daripada seribu proposisi ini akan ditetapkan sebagai teorem, yang akan memberi kesan yang mendalam terhadap bidang matematik dan jika Hipotesis Riemann terbukti salah, maka antara cadangan ini sebahagian daripadanya juga akan kehilangan keberkesanannya. Kejayaan baharu datang daripada profesor matematik MIT Larry Guth dan Universiti Oxford
 Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
sorakan! Bagaimana rasanya apabila perbincangan kertas adalah perkataan? Baru-baru ini, pelajar di Universiti Stanford mencipta alphaXiv, forum perbincangan terbuka untuk kertas arXiv yang membenarkan soalan dan ulasan disiarkan terus pada mana-mana kertas arXiv. Pautan laman web: https://alphaxiv.org/ Malah, tidak perlu melawati tapak web ini secara khusus. Hanya tukar arXiv dalam mana-mana URL kepada alphaXiv untuk terus membuka kertas yang sepadan di forum alphaXiv: anda boleh mencari perenggan dengan tepat dalam. kertas itu, Ayat: Dalam ruang perbincangan di sebelah kanan, pengguna boleh menyiarkan soalan untuk bertanya kepada pengarang tentang idea dan butiran kertas tersebut Sebagai contoh, mereka juga boleh mengulas kandungan kertas tersebut, seperti: "Diberikan kepada
 Penjanaan video tanpa had, perancangan dan membuat keputusan, penyebaran paksa penyepaduan ramalan token seterusnya dan penyebaran jujukan penuh
Jul 23, 2024 pm 02:05 PM
Penjanaan video tanpa had, perancangan dan membuat keputusan, penyebaran paksa penyepaduan ramalan token seterusnya dan penyebaran jujukan penuh
Jul 23, 2024 pm 02:05 PM
Pada masa ini, model bahasa berskala besar autoregresif menggunakan paradigma ramalan token seterusnya telah menjadi popular di seluruh dunia Pada masa yang sama, sejumlah besar imej dan video sintetik di Internet telah menunjukkan kepada kami kuasa model penyebaran. Baru-baru ini, pasukan penyelidik di MITCSAIL (salah seorang daripadanya ialah Chen Boyuan, pelajar PhD di MIT) berjaya menyepadukan keupayaan berkuasa model resapan jujukan penuh dan model token seterusnya, dan mencadangkan paradigma latihan dan pensampelan: Diffusion Forcing (DF). ). Tajuk kertas: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Alamat kertas: https:/
