
 Peranti teknologi
AI
CVPR 2024 |. Segmentasi semua model mempunyai keupayaan generalisasi yang lemah bagi SAM? Strategi penyesuaian domain diselesaikan
Peranti teknologi
AI
CVPR 2024 |. Segmentasi semua model mempunyai keupayaan generalisasi yang lemah bagi SAM? Strategi penyesuaian domain diselesaikan
CVPR 2024 |. Segmentasi semua model mempunyai keupayaan generalisasi yang lemah bagi SAM? Strategi penyesuaian domain diselesaikan

yang besar antara set data latihan dan set data ujian hiliran. Oleh itu, persoalan yang sangat penting ialah, bagaimana untuk mereka bentuk skema penyesuaian domain untuk menjadikan SAM lebih mantap dalam menghadapi dunia sebenar dan tugas hiliran yang pelbagai? Strategi penyesuaian domain pertama untuk model besar "Segmen Apa-apa" ada di sini! Kertas berkaitan telah diterima oleh CVPR 2024. Kejayaan model bahasa besar (LLM) telah memberi inspirasi kepada bidang penglihatan komputer untuk meneroka model asas untuk pembahagian. Model pembahagian asas ini biasanya digunakan untuk pembahagian imej sifar/sedikit melalui Jurutera Prompt. Antaranya, Model Segmen Anything (SAM) ialah model asas yang paling maju untuk pembahagian imej.个 Tu SAM telah berprestasi buruk pada beberapa tugas hiliran Tetapi penyelidikan terkini menunjukkan bahawa SAM tidak begitu berkuasa dan umum dalam banyak tugasan hiliran , seperti prestasi buruk dalam imej perubatan, objek yang disamarkan, imej semula jadi dengan gangguan tambahan, dsb. Ini mungkin disebabkan oleh Domain Shift
Pertama, paradigma penyesuaian domain tradisional tanpa seliaan memerlukan

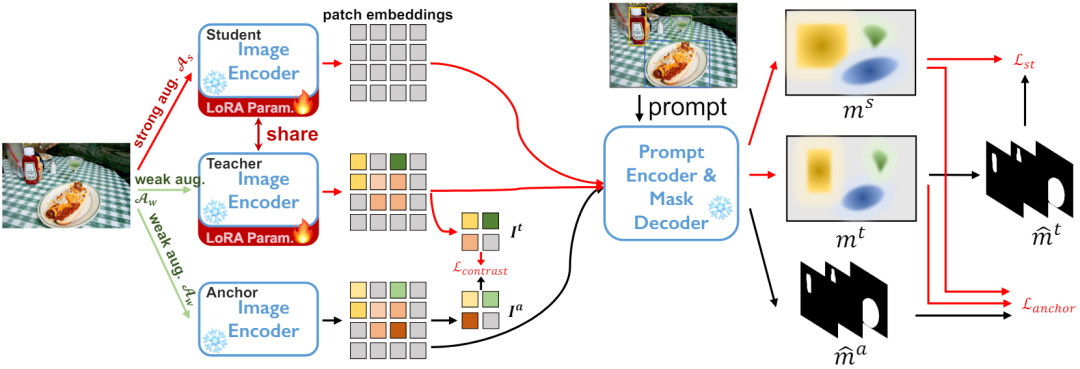
, penyesuaian tanpa pengawasan akan menjadi sangat mencabar.大 Rajah 1 SAM adalah pra-latihan pada set data berskala besar, tetapi terdapat masalah generalisasi. Kami menggunakan penyeliaan yang lemah untuk menyesuaikan SAM pada pelbagai tugas hiliran seni bina latihan kendiri yang diselia
- Untuk mengurangkan lagi kos pengiraan yang tinggi bagi mengemas kini berat model penuh, kami menggunakan
penguraian berat peringkat rendah pada pengekod dan melakukan perambatan balik melalui laluan pintasan peringkat rendah. Akhir sekali, untuk meningkatkan lagi kesan penyesuaian domain pasif, kami memperkenalkan penyeliaan yang lemah, seperti anotasi titik jarang, dalam domain sasaran untuk memberikan maklumat penyesuaian domain yang lebih kukuh Pada masa yang sama, Ini jenis penyeliaan yang lemah secara semula jadi serasi dengan pengekod kiu dalam SAM. Dengan pengawasan yang lemah sebagai Prompt, kami memperoleh lebih banyak label pseudo terlatih sendiri tempatan dan eksplisit. Model yang ditala menunjukkan keupayaan generalisasi yang lebih kukuh pada berbilang tugas hiliran.
Kami merumuskan sumbangan kerja ini seperti berikut: 
Alamat kertas: https://arxiv.org/pdf/2312.03502.pdf Alamat projek: https://github.com/Zhang-Haojie/WeSAM Penambahbaikan Tajuk Umum: Penambahbaikan Tajuk Umum: Model Asas Segmentasi di bawah Anjakan Pengedaran melalui Penyesuaian yang Dikawal Lemah
- nything Model
- Berdasarkan latihan kendiri Bagaimana rangka kerja penyesuaian
- penyeliaan yang lemah membantu mencapai latihan kendiri yang berkesan
- kemas kini berat badan peringkat rendah
Model 1.
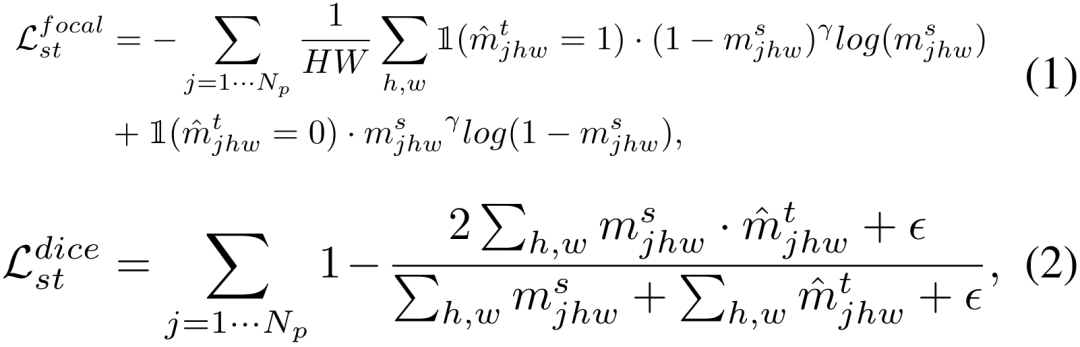
3) Ruang ciri pengekod tetap kehilangan kontras 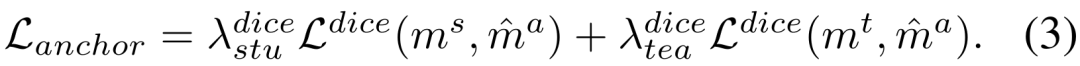
Kedua-dua matlamat latihan di atas dilakukan dalam ruang keluaran penyahkod. Bahagian percubaan mendedahkan bahawa mengemas kini rangkaian pengekod adalah cara paling cekap untuk menyesuaikan SAM, jadi perlu untuk menggunakan penyelarasan terus kepada output ciri daripada rangkaian
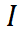
ialah pekali suhu. 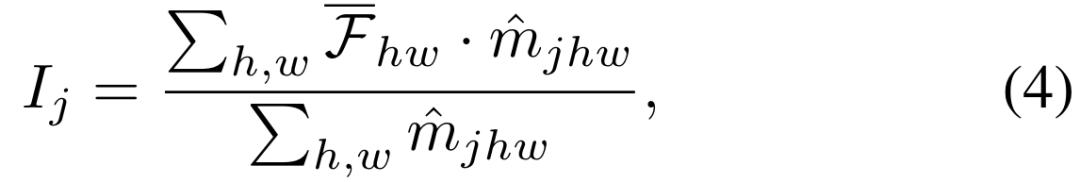
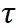
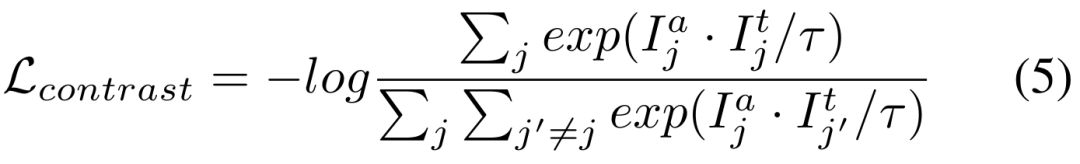

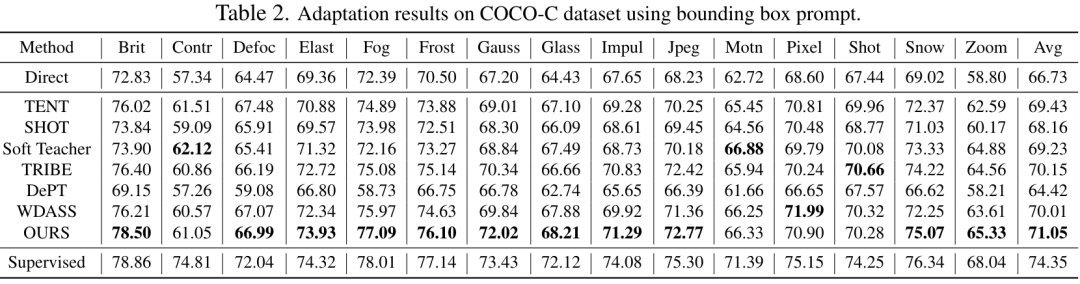
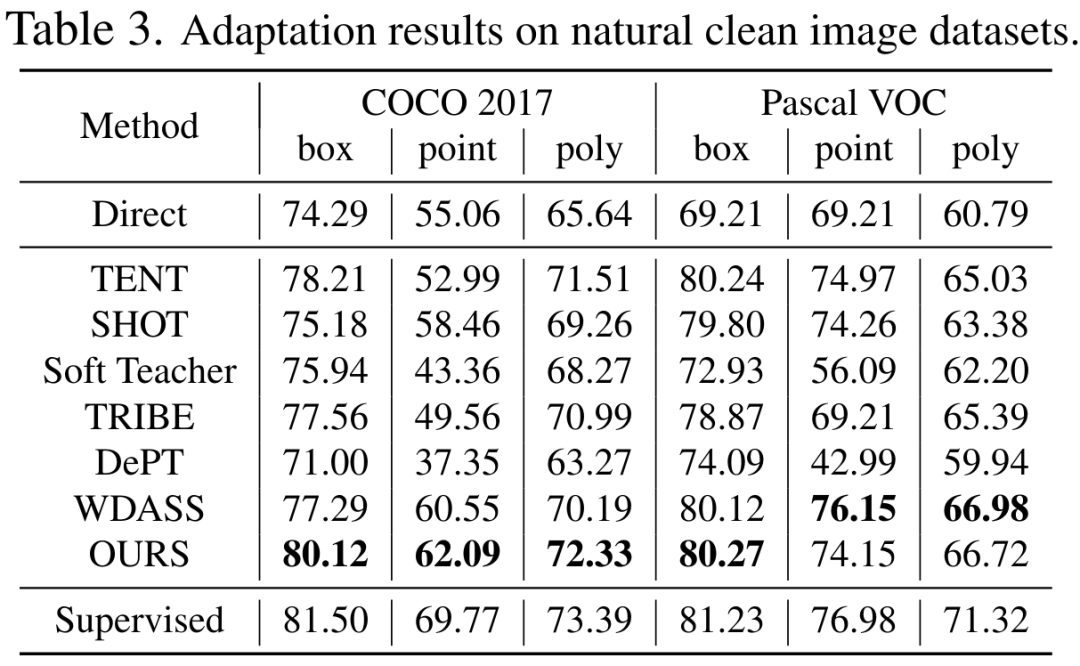
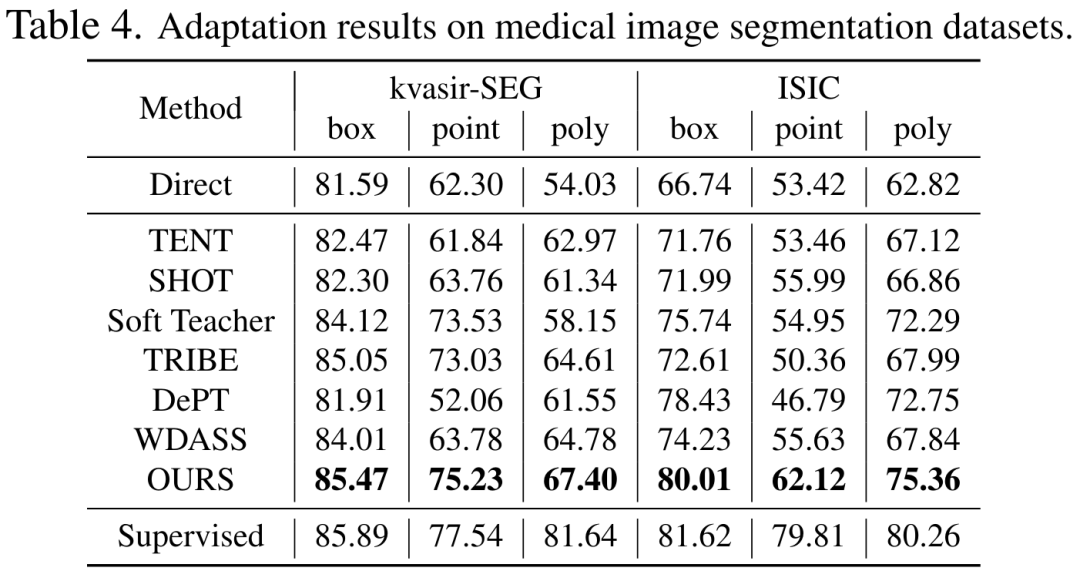
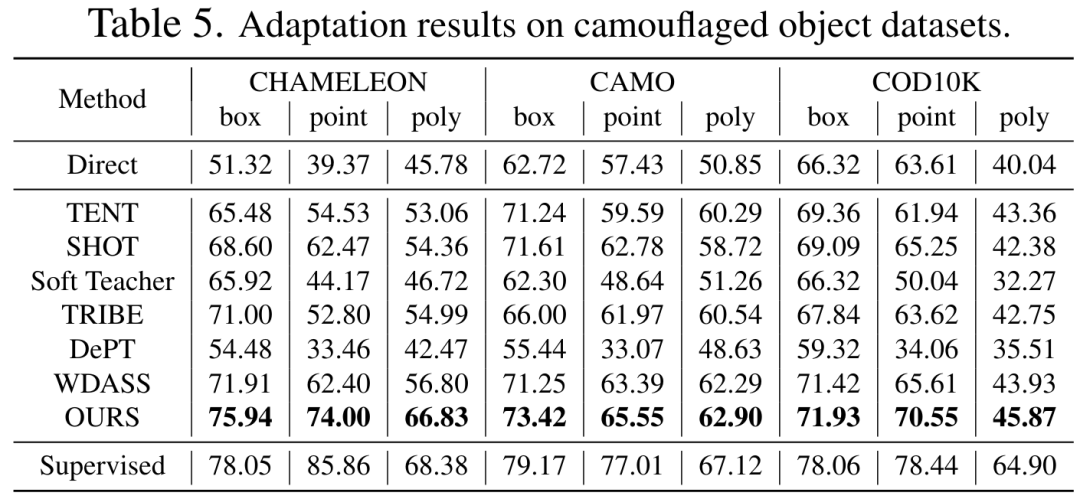


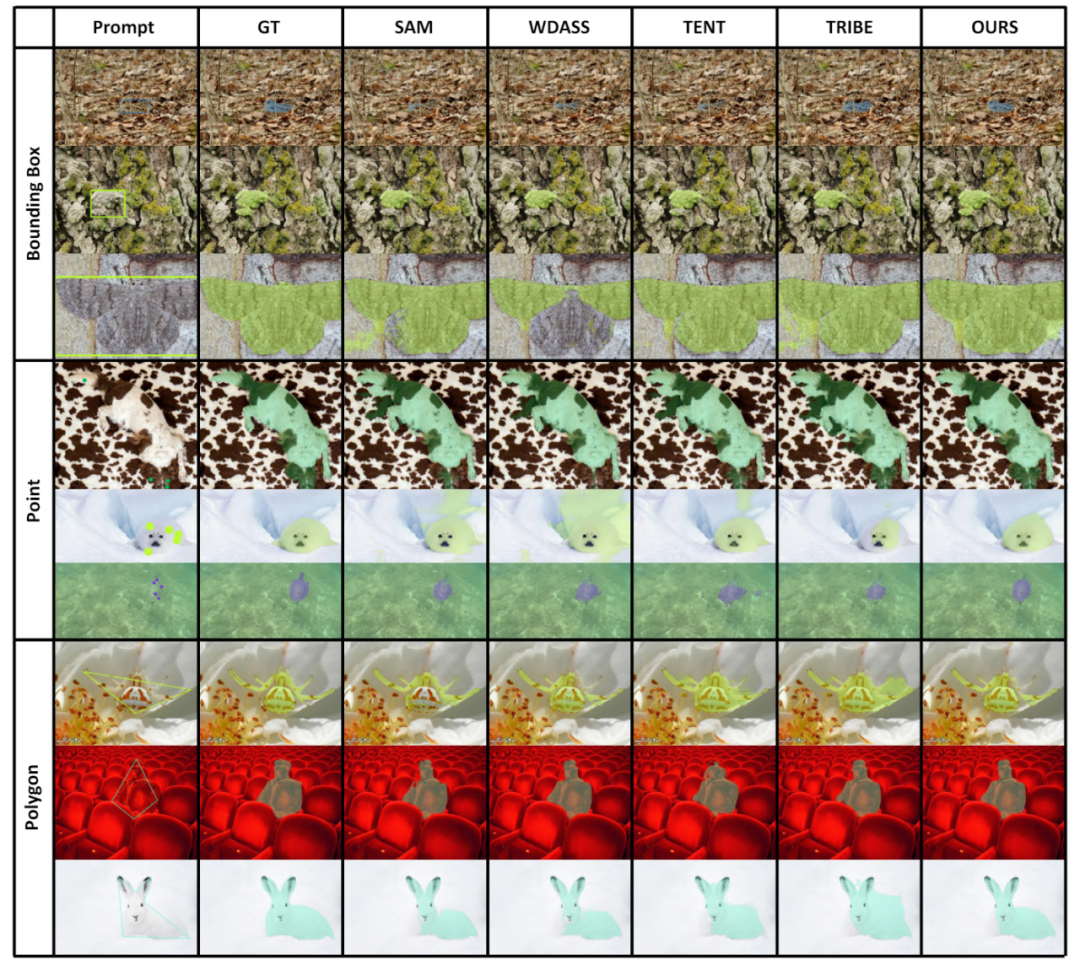
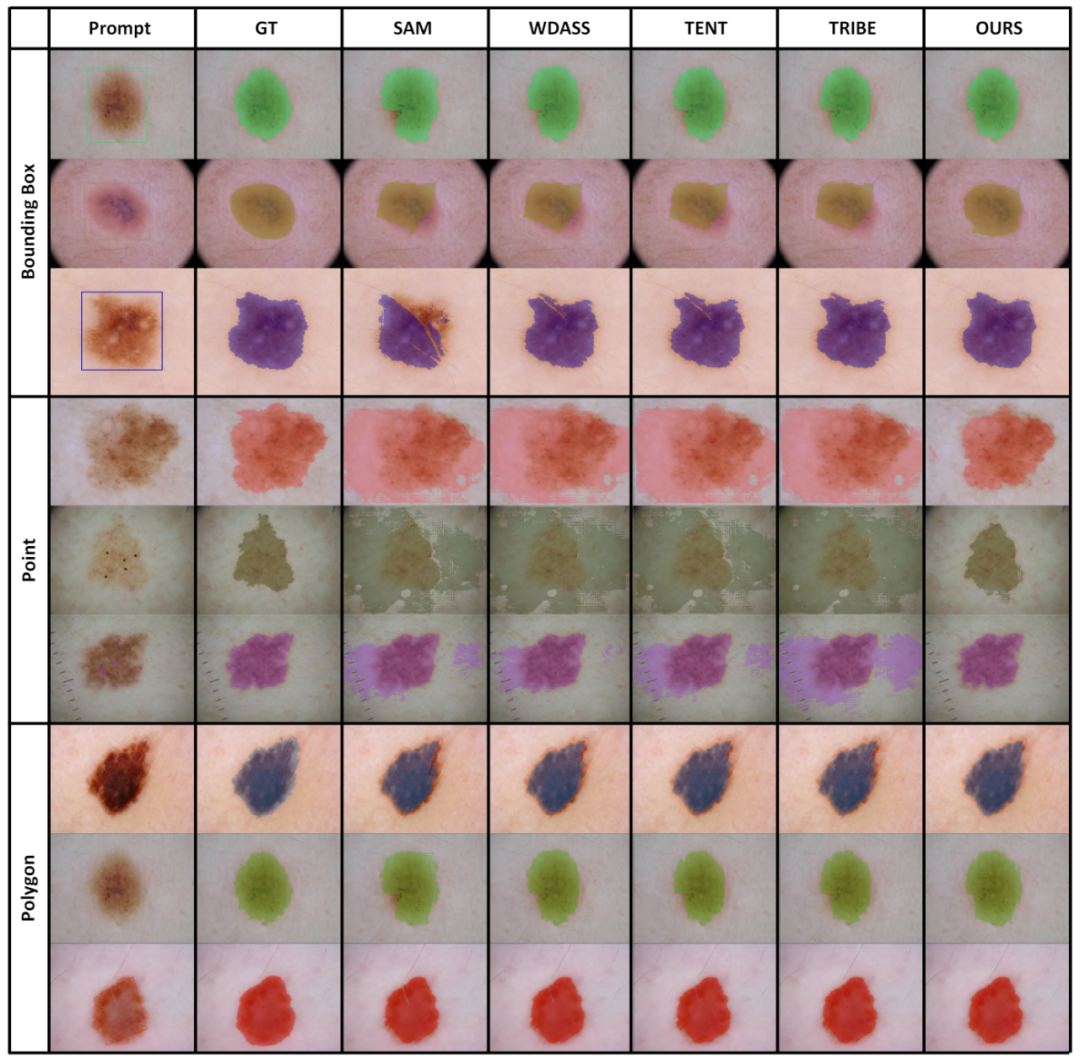
Walaupun model visi asas boleh berfungsi dengan baik pada tugasan segmentasi, ia masih mengalami prestasi yang lemah dalam tugasan hiliran. Kami mengkaji keupayaan generalisasi model Segmen-Apa-apa sahaja dalam berbilang tugas pembahagian imej hiliran dan mencadangkan kaedah latihan kendiri berdasarkan regularisasi utama dan penalaan halus peringkat rendah. Kaedah ini tidak memerlukan akses kepada set data sumber, mempunyai kos memori yang rendah, secara semula jadi serasi dengan penyeliaan yang lemah, dan boleh meningkatkan kesan penyesuaian dengan ketara. Selepas pengesahan percubaan yang meluas, keputusan menunjukkan bahawa kaedah penyesuaian domain kami yang dicadangkan boleh meningkatkan keupayaan generalisasi SAM di bawah pelbagai anjakan pengedaran. 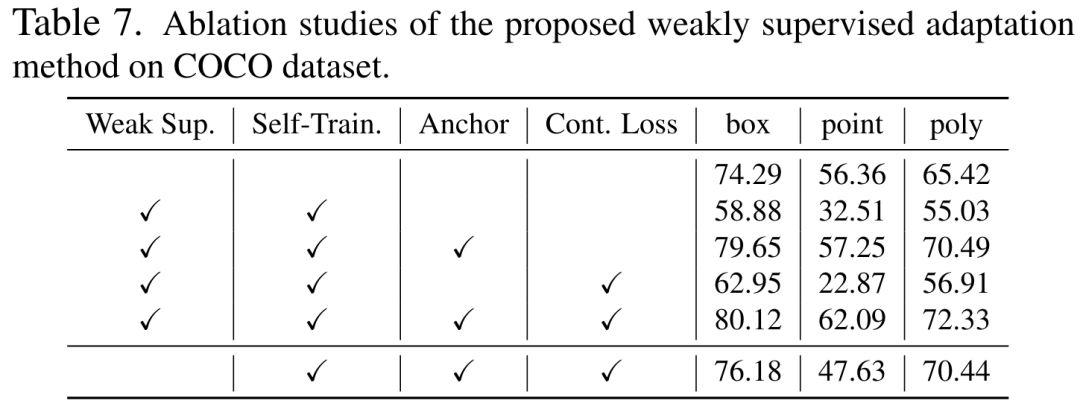
Atas ialah kandungan terperinci CVPR 2024 |. Segmentasi semua model mempunyai keupayaan generalisasi yang lemah bagi SAM? Strategi penyesuaian domain diselesaikan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan yang digunakan untuk operasi nombor terapung dalam bahasa Go memperkenalkan cara memastikan ketepatannya ...
 Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Menjalankan projek H5 memerlukan langkah -langkah berikut: memasang alat yang diperlukan seperti pelayan web, node.js, alat pembangunan, dan lain -lain. Membina persekitaran pembangunan, membuat folder projek, memulakan projek, dan menulis kod. Mulakan pelayan pembangunan dan jalankan arahan menggunakan baris arahan. Pratonton projek dalam penyemak imbas anda dan masukkan URL Server Pembangunan. Menerbitkan projek, mengoptimumkan kod, menggunakan projek, dan menyediakan konfigurasi pelayan web.
 GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
Giteepages Statik Laman Web Penggunaan Gagal: 404 Penyelesaian Masalah dan Resolusi Ralat Semasa Menggunakan Gitee ...
 Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau projek sumber terbuka yang terkenal? Semasa pengaturcaraan di GO, pemaju sering menghadapi beberapa keperluan biasa, ...
 Bagaimana cara menentukan pangkalan data yang berkaitan dengan model dalam beego orm?
Apr 02, 2025 pm 03:54 PM
Bagaimana cara menentukan pangkalan data yang berkaitan dengan model dalam beego orm?
Apr 02, 2025 pm 03:54 PM
Di bawah rangka kerja beegoorm, bagaimana untuk menentukan pangkalan data yang berkaitan dengan model? Banyak projek beego memerlukan pelbagai pangkalan data untuk dikendalikan secara serentak. Semasa menggunakan beego ...
 Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Halaman H5 perlu dikekalkan secara berterusan, kerana faktor -faktor seperti kelemahan kod, keserasian pelayar, pengoptimuman prestasi, kemas kini keselamatan dan peningkatan pengalaman pengguna. Kaedah penyelenggaraan yang berkesan termasuk mewujudkan sistem ujian lengkap, menggunakan alat kawalan versi, kerap memantau prestasi halaman, mengumpul maklum balas pengguna dan merumuskan pelan penyelenggaraan.
 Bagaimana menyelesaikan masalah penukaran jenis user_id semasa menggunakan aliran redis untuk melaksanakan beratur mesej dalam bahasa Go?
Apr 02, 2025 pm 04:54 PM
Bagaimana menyelesaikan masalah penukaran jenis user_id semasa menggunakan aliran redis untuk melaksanakan beratur mesej dalam bahasa Go?
Apr 02, 2025 pm 04:54 PM
Masalah menggunakan redisstream untuk melaksanakan beratur mesej dalam bahasa Go menggunakan bahasa Go dan redis ...
 CS-Week 3
Apr 04, 2025 am 06:06 AM
CS-Week 3
Apr 04, 2025 am 06:06 AM
Algorithms are the set of instructions to solve problems, and their execution speed and memory usage vary. In programming, many algorithms are based on data search and sorting. Artikel ini akan memperkenalkan beberapa algoritma pengambilan data dan penyortiran. Carian linear mengandaikan bahawa terdapat array [20,500,10,5,100,1,50] dan perlu mencari nombor 50. Algoritma carian linear memeriksa setiap elemen dalam array satu demi satu sehingga nilai sasaran dijumpai atau array lengkap dilalui. Carta aliran algoritma adalah seperti berikut: kod pseudo untuk carian linear adalah seperti berikut: periksa setiap elemen: jika nilai sasaran dijumpai: pulih semula benar-benar pelaksanaan bahasa palsu c: #termasuk #termasukintmain (tidak sah) {i
