
 Peranti teknologi
AI
Model besar juga sangat berkuasa dalam ramalan siri masa! Pasukan China mengaktifkan keupayaan baharu LLM dan mencapai SOTA melebihi model tradisional
Peranti teknologi
AI
Model besar juga sangat berkuasa dalam ramalan siri masa! Pasukan China mengaktifkan keupayaan baharu LLM dan mencapai SOTA melebihi model tradisional
Model besar juga sangat berkuasa dalam ramalan siri masa! Pasukan China mengaktifkan keupayaan baharu LLM dan mencapai SOTA melebihi model tradisional

Potensi model bahasa besar dirangsang -
Ramalan siri masa berketepatan tinggi boleh dicapai tanpa melatih model bahasa besar, mengatasi semua model siri masa tradisional.
Monash University, Ant dan IBM Research bersama-sama membangunkan rangka kerja umum yang berjaya mempromosikan keupayaan model bahasa besar untuk memproses data jujukan merentas modaliti. Rangka kerja telah menjadi inovasi teknologi yang penting.

Ramalan siri masa bermanfaat untuk membuat keputusan dalam sistem kompleks biasa seperti bandar, tenaga, pengangkutan, penderiaan jauh, dsb.
Sejak itu, model besar dijangka merevolusikan kaedah perlombongan data siri masa/spatiotemporal.
Rangka kerja pengaturcaraan semula model bahasa besar universal
Pasukan penyelidik mencadangkan rangka kerja umum untuk menggunakan model bahasa besar dengan mudah untuk ramalan siri masa umum tanpa sebarang latihan.
Terutamanya mencadangkan dua teknologi utama: pengaturcaraan semula input masa;
Time-LLM mula-mula menggunakan prototaip teks (Prototaip Teks) untuk memprogram semula data masa input, dan menggunakan perwakilan bahasa semula jadi untuk mewakili maklumat semantik data masa, dengan itu menjajarkan dua modaliti data yang berbeza, supaya model bahasa yang besar tidak memerlukan Sebarang pengubahsuaian untuk memahami maklumat di sebalik modaliti data lain. Pada masa yang sama, model bahasa besar tidak memerlukan sebarang set data latihan khusus untuk memahami maklumat di sebalik modaliti data yang berbeza. Kaedah ini bukan sahaja meningkatkan ketepatan model, tetapi juga memudahkan proses prapemprosesan data.
Untuk mengendalikan data siri masa input dan analisis tugasan yang sepadan dengan lebih baik, penulis mencadangkan paradigma Prompt-as-Prefix (PaP). Paradigma ini mengaktifkan sepenuhnya keupayaan pemprosesan LLM pada tugas temporal dengan menambahkan maklumat kontekstual tambahan dan arahan tugas sebelum perwakilan data temporal. Kaedah ini boleh mencapai analisis yang lebih halus tentang tugasan pemasaan, dan mengaktifkan sepenuhnya keupayaan pemprosesan LLM pada tugasan pemasaan dengan menambahkan maklumat kontekstual tambahan dan arahan tugasan di hadapan jadual data pemasaan.
Sumbangan utama termasuk:
- Mencadangkan konsep baharu pengaturcaraan semula model bahasa besar untuk analisis masa tanpa sebarang pengubahsuaian kepada model bahasa tulang belakang.
- Cadangkan Time-LLM, rangka kerja pengaturcaraan semula model bahasa umum, yang terdiri daripada pengaturcaraan semula data temporal input ke dalam perwakilan prototaip teks yang lebih semula jadi dan mempertingkatkan konteks input dengan isyarat deklaratif seperti pengetahuan pakar domain dan huraian tugas , untuk membimbing LLM untuk penaakulan merentas domain yang berkesan.

- Prestasi dalam tugas ramalan arus perdana secara konsisten melebihi prestasi model sedia ada terbaik, terutamanya dalam senario beberapa sampel dan sifar sampel. Tambahan pula, Time-LLM mampu mencapai prestasi yang lebih tinggi sambil mengekalkan kecekapan pengaturcaraan semula model yang cemerlang. Membuka kunci potensi LLM yang belum diterokai untuk siri masa dan data berjujukan lain.
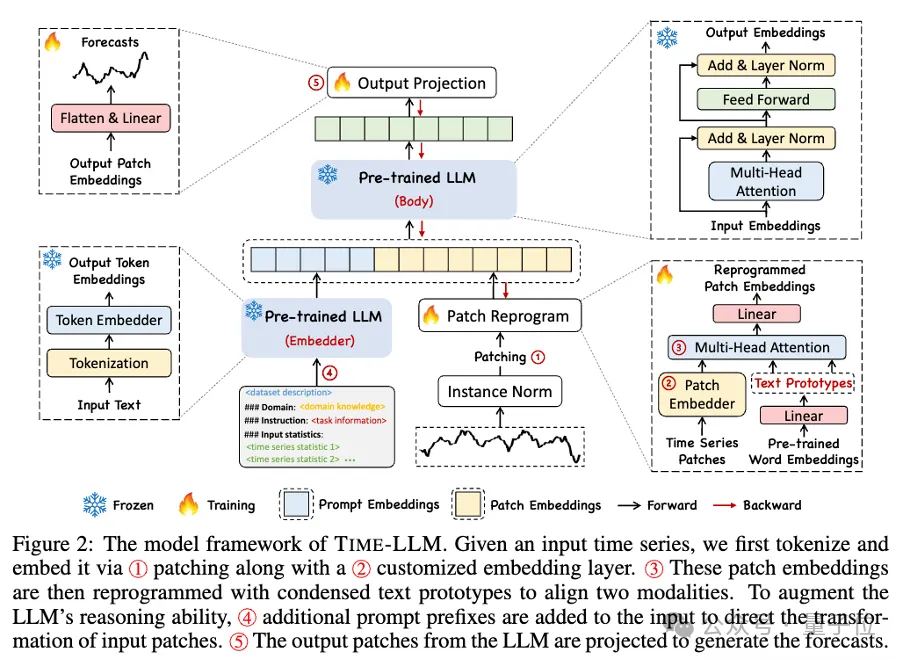
Melihat rangka kerja ini secara khusus, pertama, data siri masa input dinormalkan oleh RevIN, dan kemudian dibahagikan kepada patch berbeza dan dipetakan ke ruang terpendam.
Terdapat perbezaan ketara dalam kaedah ungkapan antara data siri masa dan data teks, dan ia tergolong dalam modaliti yang berbeza.
Siri masa tidak boleh diedit secara langsung atau digambarkan tanpa kehilangan dalam bahasa semula jadi. Oleh itu, kita perlu menyelaraskan ciri input temporal kepada domain teks bahasa semula jadi.

Cara biasa untuk menjajarkan modaliti yang berbeza ialah merentas perhatian, tetapi perbendaharaan kata yang wujud bagi LLM adalah sangat besar, jadi adalah mustahil untuk menjajarkan ciri temporal secara langsung dengan semua perkataan dan bukan semua perkataan berkaitan dengan masa. Urutan telah menyelaraskan hubungan semantik.
Untuk menyelesaikan masalah ini, kerja ini melakukan gabungan linear perbendaharaan kata untuk mendapatkan prototaip teks Bilangan prototaip teks adalah jauh lebih kecil daripada perbendaharaan kata asal, dan gabungan itu boleh digunakan untuk mewakili ciri-ciri perubahan data siri masa. .
Untuk mengaktifkan sepenuhnya keupayaan LLM pada tugas pemasaan tertentu, kerja ini mencadangkan paradigma awalan segera.
Ringkasnya, beberapa maklumat terdahulu set data siri masa disalurkan kepada LLM dalam bentuk bahasa semula jadi sebagai gesaan awalan, dan ciri siri masa yang diselaraskan disambungkan bersama. Bolehkah kesan ramalan dipertingkatkan?
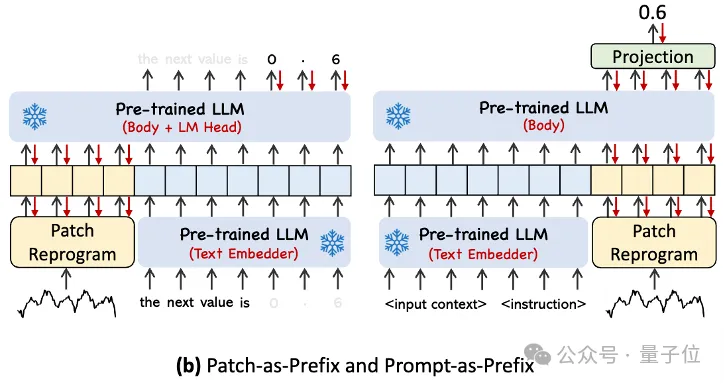
Dalam amalan, pengarang mengenal pasti tiga komponen utama untuk membina gesaan yang berkesan:
konteks set data; (2) arahan tugas, membolehkan LLM menyesuaikan diri dengan tugasan hiliran yang berbeza, seperti arah aliran , kelewatan , dsb., membolehkan LLM memahami dengan lebih baik ciri-ciri data siri masa.

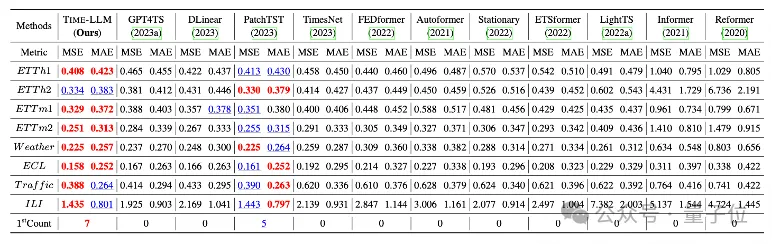
Pasukan menjalankan ujian komprehensif ke atas 8 set data awam klasik untuk ramalan jarak jauh.
Hasilnya ialah Time-LLM dengan ketara melebihi keputusan terbaik sebelumnya dalam bidang dalam perbandingan penanda aras Contohnya, berbanding dengan GPT4TS yang secara langsung menggunakan GPT-2, Time-LLM mempunyai peningkatan yang ketara, menunjukkan keberkesanan kaedah ini. .
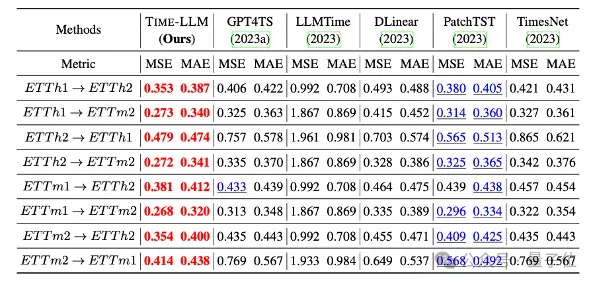
Selain itu, ia juga menunjukkan keupayaan ramalan yang kuat dalam senario sifar pukulan.
Projek ini disokong oleh NextEvo, jabatan R&D inovasi AI bagi Bahagian Enjin Pintar Kumpulan Ant.
Rakan-rakan yang berminat boleh klik pada pautan di bawah untuk mengetahui lebih lanjut tentang kertas kerja~
Pautan kertashttps://arxiv.org/abs/2310.01728.
Atas ialah kandungan terperinci Model besar juga sangat berkuasa dalam ramalan siri masa! Pasukan China mengaktifkan keupayaan baharu LLM dan mencapai SOTA melebihi model tradisional. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara menambah lajur baru dalam SQL
Apr 09, 2025 pm 02:09 PM
Cara menambah lajur baru dalam SQL
Apr 09, 2025 pm 02:09 PM
Tambah lajur baru ke jadual yang sedia ada dalam SQL dengan menggunakan pernyataan Alter Table. Langkah -langkah khusus termasuk: Menentukan nama jadual dan maklumat lajur, menulis pernyataan Alter Jadual, dan melaksanakan pernyataan. Sebagai contoh, tambahkan lajur e -mel ke Jadual Pelanggan (Varchar (50)): Alter Jadual Pelanggan Tambah Varchar E -mel (50);
 Apakah sintaks untuk menambah lajur dalam SQL
Apr 09, 2025 pm 02:51 PM
Apakah sintaks untuk menambah lajur dalam SQL
Apr 09, 2025 pm 02:51 PM
Sintaks untuk menambah lajur dalam sql adalah alter table table_name tambah column_name data_type [not null] [default default_value]; Di mana table_name adalah nama jadual, column_name adalah nama lajur baru, data_type adalah jenis data, tidak null menentukan sama ada nilai null dibenarkan, dan lalai default_value menentukan nilai lalai.
 Jadual Jelas SQL: Petua Pengoptimuman Prestasi
Apr 09, 2025 pm 02:54 PM
Jadual Jelas SQL: Petua Pengoptimuman Prestasi
Apr 09, 2025 pm 02:54 PM
Petua untuk Meningkatkan Prestasi Pembersihan Jadual SQL: Gunakan jadual Truncate dan bukannya memadam, membebaskan ruang dan menetapkan semula lajur Identiti. Lumpuhkan kekangan utama asing untuk mengelakkan penghapusan cascading. Gunakan operasi enkapsulasi transaksi untuk memastikan konsistensi data. Batch memadam data besar dan hadkan bilangan baris melalui had. Membina semula indeks selepas membersihkan untuk meningkatkan kecekapan pertanyaan.
 Cara menetapkan nilai lalai semasa menambahkan lajur dalam sql
Apr 09, 2025 pm 02:45 PM
Cara menetapkan nilai lalai semasa menambahkan lajur dalam sql
Apr 09, 2025 pm 02:45 PM
Tetapkan nilai lalai untuk lajur yang baru ditambahkan, gunakan pernyataan ALTER Jadual: Tentukan Menambah Lajur dan Tetapkan Nilai Lalai: Alter Table Table_Name Tambah Column_Name Data_Type Default Default_Value; Gunakan klausa kekangan untuk menentukan nilai lalai: alter table Table_name Tambah lajur Column_name data_type kekangan default_constraint default_value;
 Gunakan penyataan padam untuk membersihkan jadual SQL
Apr 09, 2025 pm 03:00 PM
Gunakan penyataan padam untuk membersihkan jadual SQL
Apr 09, 2025 pm 03:00 PM
Ya, pernyataan padam boleh digunakan untuk membersihkan jadual SQL, langkah -langkahnya adalah seperti berikut: Gunakan pernyataan padam: padam dari meja_name; Ganti Table_name dengan nama jadual untuk dibersihkan.
 Bagaimana untuk menangani pemecahan memori Redis?
Apr 10, 2025 pm 02:24 PM
Bagaimana untuk menangani pemecahan memori Redis?
Apr 10, 2025 pm 02:24 PM
Pemecahan ingatan redis merujuk kepada kewujudan kawasan bebas kecil dalam ingatan yang diperuntukkan yang tidak dapat ditugaskan semula. Strategi mengatasi termasuk: Mulakan semula Redis: Kosongkan memori sepenuhnya, tetapi perkhidmatan mengganggu. Mengoptimumkan struktur data: Gunakan struktur yang lebih sesuai untuk Redis untuk mengurangkan bilangan peruntukan dan siaran memori. Laraskan parameter konfigurasi: Gunakan dasar untuk menghapuskan pasangan nilai kunci yang paling kurang baru-baru ini. Gunakan mekanisme kegigihan: sandarkan data secara teratur dan mulakan semula redis untuk membersihkan serpihan. Pantau penggunaan memori: Cari masalah tepat pada masanya dan ambil langkah.
 phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
Untuk membuat jadual data menggunakan phpmyadmin, langkah -langkah berikut adalah penting: Sambungkan ke pangkalan data dan klik tab baru. Namakan jadual dan pilih enjin penyimpanan (disyorkan innoDB). Tambah butiran lajur dengan mengklik butang Tambah Lajur, termasuk nama lajur, jenis data, sama ada untuk membenarkan nilai null, dan sifat lain. Pilih satu atau lebih lajur sebagai kunci utama. Klik butang Simpan untuk membuat jadual dan lajur.
 Pantau titisan redis dengan perkhidmatan pengeksport redis
Apr 10, 2025 pm 01:36 PM
Pantau titisan redis dengan perkhidmatan pengeksport redis
Apr 10, 2025 pm 01:36 PM
Pemantauan yang berkesan terhadap pangkalan data REDIS adalah penting untuk mengekalkan prestasi yang optimum, mengenal pasti kemungkinan kesesakan, dan memastikan kebolehpercayaan sistem keseluruhan. Perkhidmatan Pengeksport Redis adalah utiliti yang kuat yang direka untuk memantau pangkalan data REDIS menggunakan Prometheus. Tutorial ini akan membimbing anda melalui persediaan lengkap dan konfigurasi perkhidmatan pengeksport REDIS, memastikan anda membina penyelesaian pemantauan dengan lancar. Dengan mengkaji tutorial ini, anda akan mencapai tetapan pemantauan operasi sepenuhnya
