
 Peranti teknologi
AI
Berbilang SOTA! OV-Uni3DETR: Meningkatkan kebolehgeneralisasian pengesanan 3D merentas kategori, adegan dan modaliti (Tsinghua & HKU)
Peranti teknologi
AI
Berbilang SOTA! OV-Uni3DETR: Meningkatkan kebolehgeneralisasian pengesanan 3D merentas kategori, adegan dan modaliti (Tsinghua & HKU)
Berbilang SOTA! OV-Uni3DETR: Meningkatkan kebolehgeneralisasian pengesanan 3D merentas kategori, adegan dan modaliti (Tsinghua & HKU)

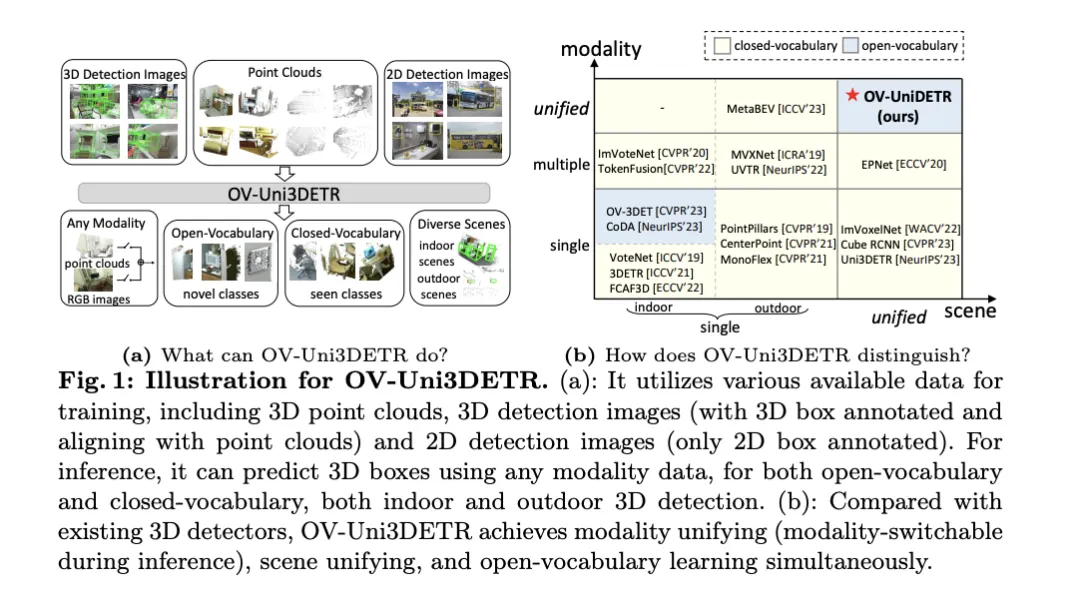
Kertas kerja ini membincangkan bidang pengesanan objek 3D, terutamanya pengesanan objek 3D untuk Perbendaharaan Kata Terbuka. Dalam tugas pengesanan objek 3D tradisional, sistem perlu meramalkan penyetempatan kotak sempadan 3D dan label kategori semantik untuk objek dalam adegan sebenar, yang biasanya bergantung pada awan titik atau imej RGB. Walaupun teknologi pengesanan objek 2D berprestasi baik kerana keluasan dan kelajuannya, penyelidikan berkaitan menunjukkan bahawa pembangunan pengesanan universal 3D ketinggalan berbanding perbandingan. Pada masa ini, kebanyakan kaedah pengesanan objek 3D masih bergantung pada pembelajaran diselia sepenuhnya dan dihadkan oleh data beranotasi sepenuhnya di bawah mod input tertentu dan hanya boleh mengecam kategori yang muncul semasa latihan, sama ada dalam adegan dalaman atau luaran.
Makalah ini menunjukkan bahawa cabaran yang dihadapi oleh pengesanan objek universal 3D terutamanya termasuk: pengesan 3D sedia ada hanya boleh berfungsi dengan pengagregatan perbendaharaan kata tertutup, dan oleh itu hanya boleh mengesan kategori yang telah dilihat. Pengesanan objek 3D Open-Vocabulary sangat diperlukan untuk mengenal pasti dan mencari contoh objek kelas baharu yang tidak diperoleh semasa latihan. Set data pengesanan 3D sedia ada adalah terhad dalam saiz dan kategori berbanding set data 2D, yang mengehadkan keupayaan generalisasi dalam mencari objek baharu. Di samping itu, kekurangan model teks imej pra-latihan dalam domain 3D memburukkan lagi cabaran pengesanan 3D Perbendaharaan Kata Terbuka. Pada masa yang sama, terdapat kekurangan seni bina bersatu untuk pengesanan 3D berbilang modal, dan pengesan 3D sedia ada kebanyakannya direka untuk modaliti input tertentu (awan titik, imej RGB atau kedua-duanya), yang menghalang penggunaan data yang berkesan daripada modaliti dan pemandangan yang berbeza (dalam atau luar), dengan itu mengehadkan keupayaan generalisasi kepada sasaran baharu.
Untuk menyelesaikan masalah di atas, kertas kerja mencadangkan pengesan 3D berbilang modal bersatu yang dipanggil OV-Uni3DETR. Pengesan dapat memanfaatkan data berbilang modal dan berbilang sumber semasa latihan, termasuk awan titik, awan titik dengan anotasi kotak 3D yang tepat dan imej pengesanan 3D sejajar awan titik dan imej pengesanan 2D yang mengandungi hanya anotasi kotak 2D. Melalui kaedah pembelajaran pelbagai mod ini, OV-Uni3DETR dapat memproses data sebarang modaliti semasa inferens, mencapai penukaran modaliti semasa ujian, dan berprestasi baik dalam mengesan kategori asas dan kategori baharu. Struktur bersatu seterusnya membolehkan OV-Uni3DETR mengesan dalam pemandangan dalam dan luar, dengan keupayaan Perbendaharaan Kata Terbuka, dengan itu meningkatkan dengan ketara kesejagatan pengesan 3D merentas kategori, adegan dan modaliti.
Selain itu, menyasarkan kepada masalah bagaimana membuat generalisasi pengesan untuk mengenal pasti kategori baharu, dan cara belajar daripada sejumlah besar imej pengesanan 2D tanpa anotasi kotak 3D, kertas itu mencadangkan kaedah yang dipanggil perambatan mod berkala—— Melalui ini pendekatan, pengetahuan disebarkan antara modaliti 2D dan 3D untuk menangani kedua-dua cabaran. Melalui pendekatan ini, pengetahuan semantik yang kaya tentang pengesan 2D boleh disebarkan ke domain 3D untuk membantu dalam menemui kotak baharu, dan pengetahuan geometri pengesan 3D boleh digunakan untuk menyetempatkan objek dalam imej pengesanan 2D dan memadankan label pengelasan. melalui padanan.
Sumbangan utama kertas kerja termasuk mencadangkan pengesan 3D Perbendaharaan Kata Terbuka bersatu OV-Uni3DETR yang boleh mengesan mana-mana kategori sasaran dalam modaliti yang berbeza dan adegan yang pelbagai mencadangkan pengesan pelbagai mod bersatu untuk seni bina pemandangan dalaman dan luaran; konsep gelung penyebaran pengetahuan antara modaliti 2D dan 3D dicadangkan. Dengan inovasi ini, OV-Uni3DETR mencapai prestasi terkini pada berbilang tugas pengesanan 3D dan dengan ketara mengatasi kaedah sebelumnya dalam tetapan Perbendaharaan Kata Terbuka. Keputusan ini menunjukkan bahawa OV-Uni3DETR telah mengambil langkah penting untuk pembangunan masa depan model asas 3D.
Penjelasan terperinci tentang kaedah OV-Uni3DETR
Pembelajaran Berbilang Modal
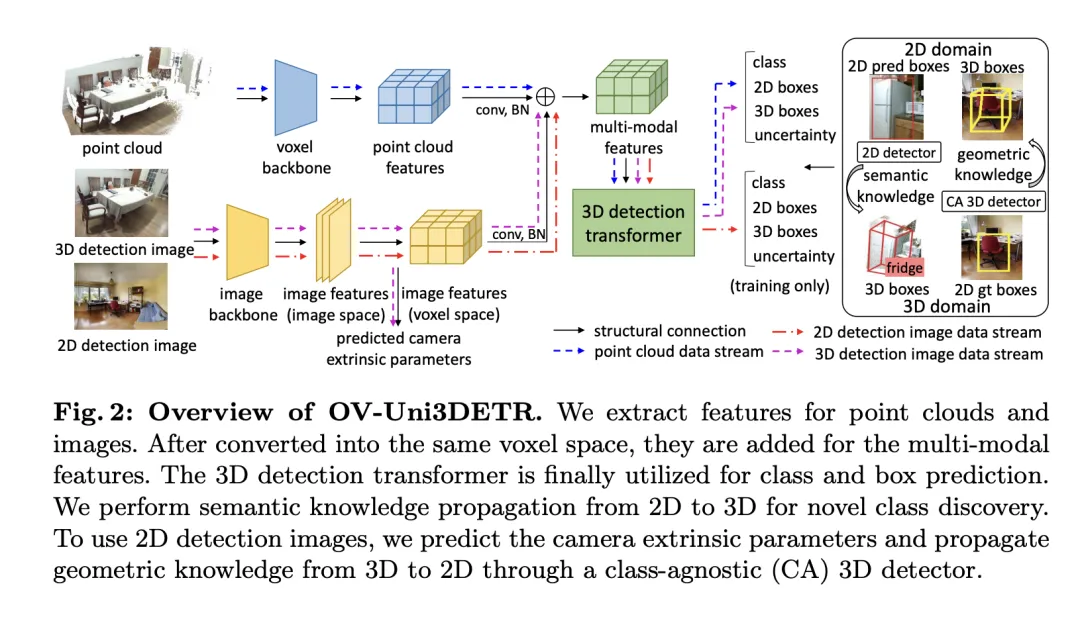
Artikel ini memperkenalkan data pengesanan data 3D yang menyepadukan berbilang mod secara khusus Tingkatkan prestasi pengesanan. Rangka kerja ini boleh mengendalikan modaliti sensor tertentu yang mungkin hilang semasa inferens, iaitu, ia juga mempunyai keupayaan untuk menukar mod semasa ujian. Ciri daripada dua modaliti berbeza, termasuk ciri awan titik 3D dan ciri imej 2D, diekstrak dan disepadukan melalui struktur rangkaian tertentu Selepas pemprosesan unsur dan pemetaan parameter kamera, ciri ini digabungkan untuk tugas pengesanan sasaran seterusnya.
Perkara teknikal utama termasuk menggunakan lilitan 3D dan penormalan kelompok untuk menormalkan dan menyepadukan ciri mod yang berbeza untuk mengelakkan ketidakkonsistenan pada tahap ciri daripada menyebabkan mod tertentu diabaikan. Selain itu, strategi latihan menukar mod secara rawak memastikan model boleh memproses data secara fleksibel daripada hanya satu mod, dengan itu meningkatkan keteguhan dan kebolehsuaian model.
Akhirnya, seni bina menggunakan fungsi kehilangan komposit yang menggabungkan kerugian daripada ramalan kelas, regresi kotak sempadan 2D dan 3D, dan ramalan ketidakpastian untuk kehilangan regresi wajaran untuk mengoptimumkan keseluruhan proses pengesanan. Kaedah pembelajaran pelbagai mod ini bukan sahaja meningkatkan prestasi pengesanan kategori sedia ada, tetapi juga meningkatkan keupayaan generalisasi kepada kategori baharu dengan menggabungkan pelbagai jenis data. Seni bina berbilang modal akhirnya meramalkan label kelas, kotak 4D 2D dan kotak 7D 3D untuk pengesanan objek 2D dan 3D. Untuk regresi kotak 3D, kehilangan L1 dan kehilangan IoU yang dipisahkan digunakan; untuk regresi kotak 2D, kehilangan L1 dan kehilangan GIoU digunakan. Dalam tetapan Open-Vocabulary, terdapat sampel kategori baharu, yang meningkatkan kesukaran sampel latihan. Oleh itu, ramalan ketidakpastian 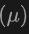 diperkenalkan dan digunakan untuk menimbang kehilangan regresi L1. Kehilangan pembelajaran pengesanan objek ialah:
diperkenalkan dan digunakan untuk menimbang kehilangan regresi L1. Kehilangan pembelajaran pengesanan objek ialah:
Untuk sesetengah adegan 3D, mungkin terdapat imej berbilang paparan dan bukannya imej monokular tunggal. Bagi setiap daripadanya, ciri imej diekstrak dan ditayangkan ke dalam ruang voxel menggunakan matriks unjuran masing-masing. Ciri imej berbilang dalam ruang voxel dijumlahkan untuk mendapatkan ciri multimodal. Pendekatan ini meningkatkan keupayaan generalisasi model kepada kategori baharu dan meningkatkan kebolehsuaian di bawah keadaan input yang pelbagai dengan menggabungkan maklumat daripada modaliti yang berbeza.
Penyebaran Pengetahuan: 2D—3D
Berdasarkan pembelajaran pelbagai mod yang diperkenalkan, kaedah yang dipanggil "Penyebaran Pengetahuan:  " dilaksanakan untuk pengesanan 3D Perbendaharaan Kata Terbuka. Masalah teras pembelajaran Open-Vocabulary adalah untuk mengenal pasti kategori baharu yang belum dilabel secara manual semasa proses latihan. Disebabkan kesukaran untuk mendapatkan data awan titik, model bahasa visual yang telah dilatih belum lagi dibangunkan dalam medan awan titik. Perbezaan modal antara data awan titik dan imej RGB mengehadkan prestasi model ini dalam pengesanan 3D.
" dilaksanakan untuk pengesanan 3D Perbendaharaan Kata Terbuka. Masalah teras pembelajaran Open-Vocabulary adalah untuk mengenal pasti kategori baharu yang belum dilabel secara manual semasa proses latihan. Disebabkan kesukaran untuk mendapatkan data awan titik, model bahasa visual yang telah dilatih belum lagi dibangunkan dalam medan awan titik. Perbezaan modal antara data awan titik dan imej RGB mengehadkan prestasi model ini dalam pengesanan 3D.

Untuk menyelesaikan masalah ini, adalah dicadangkan untuk menggunakan pengetahuan semantik pengesan Perbendaharaan Kata Terbuka 2D yang telah terlatih dan menjana kotak sempadan 3D yang sepadan untuk kategori baharu. Kotak 3D yang dijana ini akan melengkapkan label kebenaran tanah 3D terhad yang tersedia semasa latihan.
Secara khusus, jana kotak sempadan 2D atau topeng contoh menggunakan pengesan 2DOpen-Vocabulary. Memandangkan data dan anotasi yang tersedia dalam domain 2D adalah lebih kaya, kotak 2D yang dijana ini boleh mencapai ketepatan kedudukan yang lebih tinggi dan merangkumi julat kategori yang lebih luas. Kemudian, kotak 2D ini ditayangkan ke ruang 3D melalui 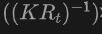 untuk mendapatkan kotak 3D yang sepadan. Operasi khusus adalah menggunakan
untuk mendapatkan kotak 3D yang sepadan. Operasi khusus adalah menggunakan 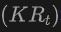
untuk menayangkan titik 3D ke dalam ruang 2D, mencari titik dalam kotak 2D, dan kemudian kumpulkan titik ini dalam kotak 2D untuk menghapuskan outlier untuk mendapatkan kotak 3D yang sepadan. Disebabkan kehadiran pengesan 2D yang telah terlatih, objek tidak berlabel baharu boleh ditemui dalam set kotak 3D yang dijana. Dengan cara ini, pengesanan 3DOpen-Vocabulary sangat dipermudahkan oleh pengetahuan semantik yang kaya yang disebarkan daripada domain 2D ke kotak 3D yang dijana. Untuk imej berbilang paparan, kotak 3D dijana secara berasingan dan disepadukan bersama untuk kegunaan akhir.
Semasa inferens, apabila kedua-dua awan titik dan imej tersedia, kotak 3D boleh diekstrak dengan cara yang sama. Kotak 3D yang dijana ini juga boleh dianggap sebagai satu bentuk hasil pengesanan 3DOpen-Vocabulary. Kotak 3D ini ditambahkan pada ramalan pengubah 3D multimodal untuk menambah kemungkinan objek hilang dan menapis kotak sempadan yang bertindih melalui penindasan bukan maksimum (NMS) 3D. Skor keyakinan yang diberikan oleh pengesan 2D pra-latihan dibahagikan secara sistematik dengan pemalar yang telah ditetapkan dan kemudian ditafsir semula ke dalam skor keyakinan kotak 3D yang sepadan.
Eksperimen
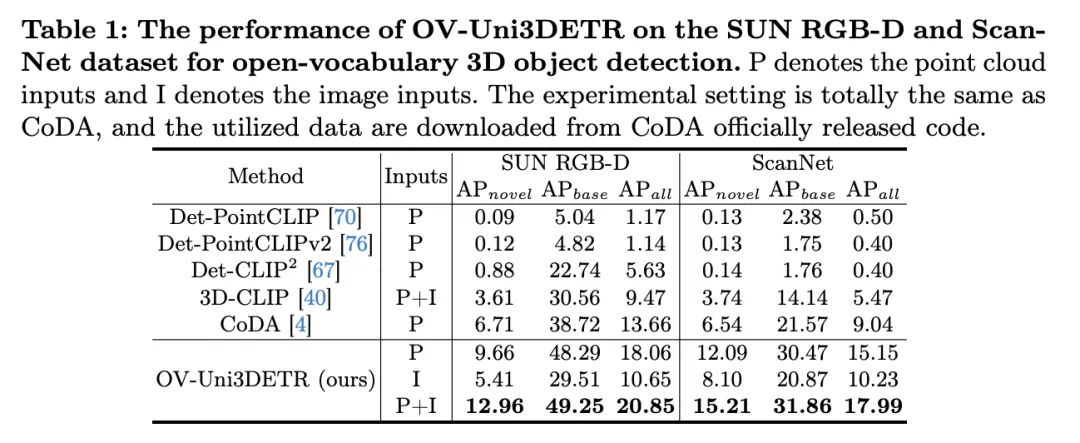
Jadual menunjukkan prestasi OV-Uni3DETR untuk pengesanan objek Open-Vocabulary3D pada set data SUN RGB-D dan ScanNet. Tetapan percubaan adalah betul-betul sama seperti CoDA, dan data yang digunakan datang daripada kod CoDA yang dikeluarkan secara rasmi. Metrik prestasi termasuk ketepatan purata kelas baharu 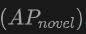 , ketepatan purata kelas asas
, ketepatan purata kelas asas 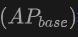 dan semua ketepatan purata kelas
dan semua ketepatan purata kelas 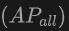 . Jenis input termasuk awan titik (P), imej (I), dan gabungannya (P+I).
. Jenis input termasuk awan titik (P), imej (I), dan gabungannya (P+I).
Menganalisis keputusan ini, kita boleh melihat perkara berikut:
-
Kelebihan input berbilang modal: Apabila menggunakan gabungan awan titik dan imej sebagai input, OV-Uni3DETR berprestasi baik pada semua metrik penilaian kedua-dua set data Ia mencapai markah tertinggi dalam semua kategori, terutamanya peningkatan paling ketara dalam ketepatan purata kategori baharu
 . Ini menunjukkan bahawa menggabungkan awan titik dan imej boleh meningkatkan dengan ketara keupayaan model untuk mengesan kelas yang tidak kelihatan, serta prestasi pengesanan keseluruhan.
. Ini menunjukkan bahawa menggabungkan awan titik dan imej boleh meningkatkan dengan ketara keupayaan model untuk mengesan kelas yang tidak kelihatan, serta prestasi pengesanan keseluruhan. - Perbandingan dengan kaedah lain: Berbanding dengan kaedah berasaskan awan titik lain (seperti Det-PointCLIP, Det-PointCLIPv2, Det-CLIP, 3D-CLIP dan CoDA), OV-Uni3DETR mempamerkan prestasi unggul pada semua penilaian metrik Prestasi cemerlang. Ini menunjukkan keberkesanan OV-Uni3DETR dalam mengendalikan tugas pengesanan objek Open-Vocabulary3D, terutamanya dalam memanfaatkan pembelajaran pelbagai mod dan strategi penyebaran pengetahuan.
- Perbandingan imej dan input awan titik: Walaupun prestasi OV-Uni3DETR hanya menggunakan imej (I) sebagai input adalah lebih rendah daripada menggunakan awan titik (P) sebagai input, ia masih menunjukkan keupayaan pengesanan yang baik. Ini membuktikan fleksibiliti dan kebolehsuaian seni bina OV-Uni3DETR kepada data modal tunggal, dan juga menekankan kepentingan menggabungkan berbilang data modal untuk meningkatkan prestasi pengesanan.
-
Prestasi pada kategori baharu: Prestasi OV-Uni3DETR pada ketepatan purata kategori baharu amat perlu diberi perhatian, yang amat penting untuk pengesanan Perbendaharaan Kata Terbuka. Pada set data SUN RGB-D, mencapai 12.96% apabila menggunakan titik awan dan input imej, dan mencapai 15.21% pada set data ScanNet, yang jauh lebih tinggi daripada kaedah lain, menunjukkan bahawa ia tidak mempunyai kesan pada proses latihan pengecaman keupayaan dalam kategori yang saya lihat.
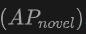 . Ini menunjukkan bahawa menggabungkan awan titik dan imej boleh meningkatkan dengan ketara keupayaan model untuk mengesan kelas yang tidak kelihatan, serta prestasi pengesanan keseluruhan.
. Ini menunjukkan bahawa menggabungkan awan titik dan imej boleh meningkatkan dengan ketara keupayaan model untuk mengesan kelas yang tidak kelihatan, serta prestasi pengesanan keseluruhan. 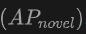 amat perlu diberi perhatian, yang amat penting untuk pengesanan Perbendaharaan Kata Terbuka. Pada set data SUN RGB-D,
amat perlu diberi perhatian, yang amat penting untuk pengesanan Perbendaharaan Kata Terbuka. Pada set data SUN RGB-D, 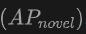 mencapai 12.96% apabila menggunakan titik awan dan input imej, dan mencapai 15.21% pada set data ScanNet, yang jauh lebih tinggi daripada kaedah lain, menunjukkan bahawa ia tidak mempunyai kesan pada proses latihan pengecaman keupayaan dalam kategori yang saya lihat.
mencapai 12.96% apabila menggunakan titik awan dan input imej, dan mencapai 15.21% pada set data ScanNet, yang jauh lebih tinggi daripada kaedah lain, menunjukkan bahawa ia tidak mempunyai kesan pada proses latihan pengecaman keupayaan dalam kategori yang saya lihat. Secara amnya, OV-Uni3DETR menunjukkan prestasi cemerlang pada tugas pengesanan objek Open-Vocabulary3D melalui seni bina pembelajaran pelbagai mod yang bersatu, terutamanya apabila menggabungkan awan titik dan data imej, ia boleh meningkatkan ketepatan pengesanan yang baharu dengan berkesan kategori membuktikan keberkesanan dan kepentingan input pelbagai modal dan strategi penyebaran pengetahuan.
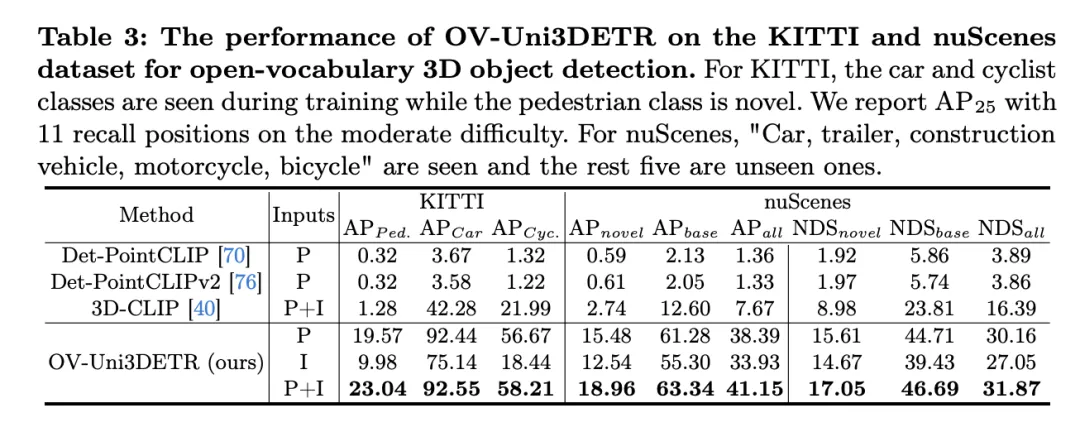
Jadual ini menunjukkan prestasi OV-Uni3DETR untuk pengesanan objek Open-Vocabulary3D pada set data KITTI dan nuScenes, meliputi kategori yang telah dilihat (asas) dan tidak kelihatan (novel) semasa proses latihan. Untuk set data KITTI, kategori "kereta" dan "penunggang basikal" dilihat semasa latihan, manakala kategori "pejalan kaki" adalah novel. Prestasi diukur menggunakan metrik 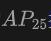
pada kesukaran sederhana dan menggunakan 11 kedudukan panggil semula. Untuk set data nuScenes, "kereta, treler, kenderaan pembinaan, motosikal, basikal" ialah kategori yang dilihat, dan lima lagi adalah kategori yang tidak kelihatan. Selain penunjuk AP, NDS (NuScenes Detection Score) juga dilaporkan untuk menilai secara menyeluruh prestasi pengesanan.
Menganalisis keputusan ini membawa kepada kesimpulan berikut:
- Kelebihan ketara input berbilang modal: Berbanding dengan kes menggunakan awan titik (P) atau imej (I) sahaja sebagai input, apabila menggunakan kedua-dua awan titik dan imej (P+I) sebagai input, OV - Uni3DETR menerima markah tertinggi pada semua metrik penilaian. Keputusan ini menyerlahkan kelebihan ketara pembelajaran pelbagai mod dalam meningkatkan keupayaan pengesanan untuk kategori yang tidak kelihatan dan prestasi pengesanan keseluruhan.
- Keberkesanan pengesanan Perbendaharaan Kata Terbuka: OV-Uni3DETR menunjukkan prestasi cemerlang dalam mengendalikan kategori ghaib, terutamanya pada kategori "pejalan kaki" bagi set data KITTI dan kategori "novel" set data nuScenes. Ini menunjukkan bahawa model tersebut mempunyai keupayaan generalisasi yang kuat kepada kategori novel dan merupakan penyelesaian pengesanan Perbendaharaan Kata Terbuka yang berkesan.
- Perbandingan dengan kaedah lain: Berbanding dengan kaedah berasaskan awan titik lain (seperti Det-PointCLIP, Det-PointCLIPv2 dan 3D-CLIP), OV-Uni3DETR menunjukkan peningkatan prestasi yang ketara, kedua-duanya dalam Pada pengesanan yang dilihat atau tidak kelihatan kategori. Ini menunjukkan kemajuannya dalam mengendalikan tugas pengesanan objek Open-Vocabulary3D.
- Perbandingan input imej dan input awan titik: Walaupun prestasi penggunaan input imej adalah lebih rendah sedikit daripada menggunakan input awan titik, input imej masih mampu memberikan ketepatan pengesanan yang agak tinggi, yang menunjukkan kebolehsuaian OV-Uni3DETR seni bina dan fleksibiliti.
- Indeks penilaian komprehensif: Ia dapat dilihat daripada keputusan indeks penilaian NDS bahawa OV-Uni3DETR bukan sahaja berprestasi baik dalam ketepatan pengecaman, tetapi juga mencapai skor tinggi dalam kualiti pengesanan keseluruhan, terutamanya apabila digabungkan dengan awan titik dan imej data.
OV-Uni3DETR menunjukkan prestasi cemerlang pada pengesanan objek Open-Vocabulary3D, terutamanya dalam mengendalikan kategori ghaib dan data berbilang modal. Keputusan ini mengesahkan keberkesanan input pelbagai mod dan strategi penyebaran pengetahuan, serta potensi OV-Uni3DETR dalam meningkatkan keupayaan generalisasi tugas pengesanan objek 3D.
Perbincangan

Kertas kerja ini membawa kemajuan yang ketara kepada bidang pengesanan objek 3D Perbendaharaan Kata Terbuka dengan mencadangkan OV-Uni3DETR, pengesan 3D pelbagai mod bersatu. Kaedah ini menggunakan data berbilang mod (awan titik dan imej) untuk meningkatkan prestasi pengesanan, dan secara berkesan mengembangkan keupayaan pengecaman model untuk kategori yang tidak kelihatan melalui strategi penyebaran pengetahuan 2D hingga 3D. Keputusan percubaan pada berbilang set data awam menunjukkan prestasi cemerlang OV-Uni3DETR pada kategori baharu dan kategori asas, terutamanya apabila menggabungkan awan titik dan input imej, yang boleh meningkatkan keupayaan pengesanan kategori baharu dengan ketara pada masa yang sama Prestasi pengesanan keseluruhan juga telah mencapai ketinggian baru.
Dari segi kelebihan, OV-Uni3DETR pertama kali menunjukkan potensi pembelajaran pelbagai mod dalam meningkatkan prestasi pengesanan sasaran 3D. Dengan menyepadukan awan titik dan data imej, model ini dapat mempelajari ciri pelengkap daripada setiap modaliti, membolehkan pengesanan yang lebih tepat pada adegan kaya dan kategori sasaran yang pelbagai. Kedua, dengan memperkenalkan mekanisme pemindahan pengetahuan 2D kepada 3D, OV-Uni3DETR dapat menggunakan data imej 2D yang kaya dan model pengesanan 2D yang telah terlatih untuk mengenal pasti dan mencari kategori baharu yang belum dilihat semasa proses latihan, yang sangat meningkatkan generalisasi keupayaan model. Di samping itu, kaedah ini menunjukkan keupayaan berkuasa dalam memproses pengesanan Perbendaharaan Kata Terbuka, membawa arah penyelidikan baharu dan aplikasi yang berpotensi ke dalam bidang pengesanan 3D.
Dari segi keburukan, walaupun OV-Uni3DETR telah menunjukkan kelebihannya dalam banyak aspek, terdapat juga beberapa batasan yang berpotensi. Pertama, walaupun pembelajaran pelbagai mod boleh meningkatkan prestasi, ia juga meningkatkan kerumitan pemerolehan dan pemprosesan data Terutamanya dalam aplikasi praktikal, penyegerakan dan pendaftaran data modal yang berbeza mungkin menimbulkan cabaran. Kedua, walaupun strategi penyebaran pengetahuan boleh menggunakan data 2D secara berkesan untuk membantu pengesanan 3D, kaedah ini mungkin bergantung pada model pengesanan 2D berkualiti tinggi dan teknologi penjajaran 3D-2D yang tepat, yang mungkin sukar untuk dijamin dalam beberapa persekitaran yang kompleks. Selain itu, untuk beberapa kategori yang sangat jarang berlaku, pengesanan Perbendaharaan Kata Terbuka mungkin menghadapi cabaran ketepatan pengecaman, yang memerlukan penyelidikan lanjut untuk diselesaikan.
OV-Uni3DETR telah mencapai kemajuan yang ketara dalam pengesanan objek Open-Vocabulary3D melalui pembelajaran pelbagai mod yang inovatif dan strategi penyebaran pengetahuan. Walaupun terdapat beberapa batasan yang berpotensi, kelebihannya menunjukkan potensi besar kaedah ini dalam menggalakkan pembangunan dan pengembangan aplikasi teknologi pemeriksaan 3D. Penyelidikan masa depan boleh meneroka lebih lanjut cara untuk mengatasi batasan ini dan cara menggunakan strategi ini untuk pelbagai tugas persepsi 3D yang lebih luas.
Kesimpulan
Dalam kertas kerja ini, kami terutamanya mencadangkan OV-Uni3DETR, pengesan 3D perbendaharaan kata terbuka pelbagai mod bersatu. Dengan bantuan pembelajaran pelbagai mod dan penyebaran pengetahuan mod kitaran, OV-Uni3DETR kami boleh mengenal pasti dan mencari kelas baharu dengan baik, mencapai penyatuan ragam dan penyatuan adegan. Percubaan menunjukkan keupayaan kukuhnya dalam kedua-dua persekitaran perbendaharaan kata terbuka dan tertutup, kedua-dua adegan dalaman dan luaran, dan dalam sebarang input data modal. Dengan mensasarkan pengesanan 3D perbendaharaan kata terbuka bersatu dalam persekitaran multimodal, kami percaya kajian kami akan memacu penyelidikan seterusnya sepanjang arah visi komputer 3D umum yang menjanjikan tetapi mencabar.
Atas ialah kandungan terperinci Berbilang SOTA! OV-Uni3DETR: Meningkatkan kebolehgeneralisasian pengesanan 3D merentas kategori, adegan dan modaliti (Tsinghua & HKU). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Ditulis di atas & pemahaman peribadi pengarang Gaussiansplatting tiga dimensi (3DGS) ialah teknologi transformatif yang telah muncul dalam bidang medan sinaran eksplisit dan grafik komputer dalam beberapa tahun kebelakangan ini. Kaedah inovatif ini dicirikan oleh penggunaan berjuta-juta Gaussians 3D, yang sangat berbeza daripada kaedah medan sinaran saraf (NeRF), yang terutamanya menggunakan model berasaskan koordinat tersirat untuk memetakan koordinat spatial kepada nilai piksel. Dengan perwakilan adegan yang eksplisit dan algoritma pemaparan yang boleh dibezakan, 3DGS bukan sahaja menjamin keupayaan pemaparan masa nyata, tetapi juga memperkenalkan tahap kawalan dan pengeditan adegan yang tidak pernah berlaku sebelum ini. Ini meletakkan 3DGS sebagai penukar permainan yang berpotensi untuk pembinaan semula dan perwakilan 3D generasi akan datang. Untuk tujuan ini, kami menyediakan gambaran keseluruhan sistematik tentang perkembangan dan kebimbangan terkini dalam bidang 3DGS buat kali pertama.
 Ketahui tentang emoji Fasih 3D dalam Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Ketahui tentang emoji Fasih 3D dalam Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Anda mesti ingat, terutamanya jika anda adalah pengguna Teams, bahawa Microsoft telah menambah kumpulan baharu emoji 3DFluent pada apl persidangan video tertumpu kerjanya. Selepas Microsoft mengumumkan emoji 3D untuk Pasukan dan Windows tahun lepas, proses itu sebenarnya telah melihat lebih daripada 1,800 emoji sedia ada dikemas kini untuk platform. Idea besar ini dan pelancaran kemas kini emoji 3DFluent untuk Pasukan pertama kali dipromosikan melalui catatan blog rasmi. Kemas kini Pasukan Terkini membawa FluentEmojis ke aplikasi Microsoft mengatakan 1,800 emoji yang dikemas kini akan tersedia kepada kami setiap hari
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
1. Pengenalan Pada masa ini, pengesan objek utama ialah rangkaian dua peringkat atau satu peringkat berdasarkan rangkaian pengelas tulang belakang yang digunakan semula CNN dalam. YOLOv3 ialah salah satu pengesan satu peringkat tercanggih yang menerima imej input dan membahagikannya kepada matriks grid bersaiz sama. Sel grid dengan pusat sasaran bertanggungjawab untuk mengesan sasaran tertentu. Apa yang saya kongsikan hari ini ialah kaedah matematik baharu yang memperuntukkan berbilang grid kepada setiap sasaran untuk mencapai ramalan kotak sempadan ketat muat yang tepat. Para penyelidik juga mencadangkan peningkatan data salin-tampal luar talian yang berkesan untuk pengesanan sasaran. Kaedah yang baru dicadangkan dengan ketara mengatasi beberapa pengesan objek terkini dan menjanjikan prestasi yang lebih baik. 2. Rangkaian pengesanan sasaran latar belakang direka bentuk untuk digunakan
 SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
Dalam bidang pengesanan sasaran, YOLOv9 terus membuat kemajuan dalam proses pelaksanaan Dengan mengguna pakai seni bina dan kaedah baharu, ia secara berkesan meningkatkan penggunaan parameter konvolusi tradisional, yang menjadikan prestasinya jauh lebih unggul daripada produk generasi sebelumnya. Lebih setahun selepas YOLOv8 dikeluarkan secara rasmi pada Januari 2023, YOLOv9 akhirnya hadir! Sejak Joseph Redmon, Ali Farhadi dan yang lain mencadangkan model YOLO generasi pertama pada 2015, penyelidik dalam bidang pengesanan sasaran telah mengemas kini dan mengulanginya berkali-kali. YOLO ialah sistem ramalan berdasarkan maklumat global imej, dan prestasi modelnya terus dipertingkatkan. Dengan menambah baik algoritma dan teknologi secara berterusan, penyelidik telah mencapai hasil yang luar biasa, menjadikan YOLO semakin berkuasa dalam tugas pengesanan sasaran.
 Cat 3D dalam Windows 11: Muat Turun, Pemasangan dan Panduan Penggunaan
Apr 26, 2023 am 11:28 AM
Cat 3D dalam Windows 11: Muat Turun, Pemasangan dan Panduan Penggunaan
Apr 26, 2023 am 11:28 AM
Apabila gosip mula tersebar bahawa Windows 11 baharu sedang dibangunkan, setiap pengguna Microsoft ingin tahu bagaimana rupa sistem pengendalian baharu itu dan apa yang akan dibawanya. Selepas spekulasi, Windows 11 ada di sini. Sistem pengendalian datang dengan reka bentuk baharu dan perubahan fungsi. Selain beberapa tambahan, ia disertakan dengan penamatan dan pengalihan keluar ciri. Salah satu ciri yang tidak wujud dalam Windows 11 ialah Paint3D. Walaupun ia masih menawarkan Paint klasik, yang bagus untuk laci, doodle dan doodle, ia meninggalkan Paint3D, yang menawarkan ciri tambahan yang sesuai untuk pencipta 3D. Jika anda mencari beberapa ciri tambahan, kami mengesyorkan Autodesk Maya sebagai perisian reka bentuk 3D terbaik. suka
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
