
 Peranti teknologi
AI
Teks panjang tidak boleh membunuh RAG: vektor SQL+ memacu model besar dan paradigma baharu data besar, pangkalan data MyScale AI adalah sumber terbuka secara rasmi
Peranti teknologi
AI
Teks panjang tidak boleh membunuh RAG: vektor SQL+ memacu model besar dan paradigma baharu data besar, pangkalan data MyScale AI adalah sumber terbuka secara rasmi
Teks panjang tidak boleh membunuh RAG: vektor SQL+ memacu model besar dan paradigma baharu data besar, pangkalan data MyScale AI adalah sumber terbuka secara rasmi

Gabungan model besar dan pangkalan data AI telah menjadi senjata ajaib untuk mengurangkan kos dan meningkatkan kecekapan model besar dan menjadikan data besar benar-benar pintar.

Pangkalan data vektor khusus yang diwakili oleh Pinecone/Weaviate/Milvus direka dan dibina untuk mendapatkan semula vektor dari awal Prestasi mendapatkan semula vektor adalah sangat baik, tetapi fungsi pengurusan data umum adalah lemah. Sistem perolehan kata kunci dan vektor yang diwakili oleh Elasticsearch/OpenSearch digunakan secara meluas dalam pengeluaran kerana fungsi pencarian kata kunci yang lengkap Walau bagaimanapun, ia menduduki banyak sumber sistem dan ketepatan pertanyaan bersama serta prestasi kata kunci dan vektor tidak memuaskan. Orang ramai mendapat apa yang mereka mahu. Pangkalan data vektor SQL yang diwakili oleh pgvector (pemalam carian vektor untuk PostgreSQL) dan pangkalan data AI MyScale adalah berdasarkan SQL dan mempunyai fungsi pengurusan data yang berkuasa. Walau bagaimanapun, disebabkan oleh kelemahan storan baris PostgreSQL dan batasan algoritma vektor, pgvector mempunyai ketepatan yang rendah dalam pertanyaan vektor kompleks.
Terima kasih kepada penggilap pangkalan data SQL jangka panjang dalam senario data berstruktur besar-besaran, MyScaleDB
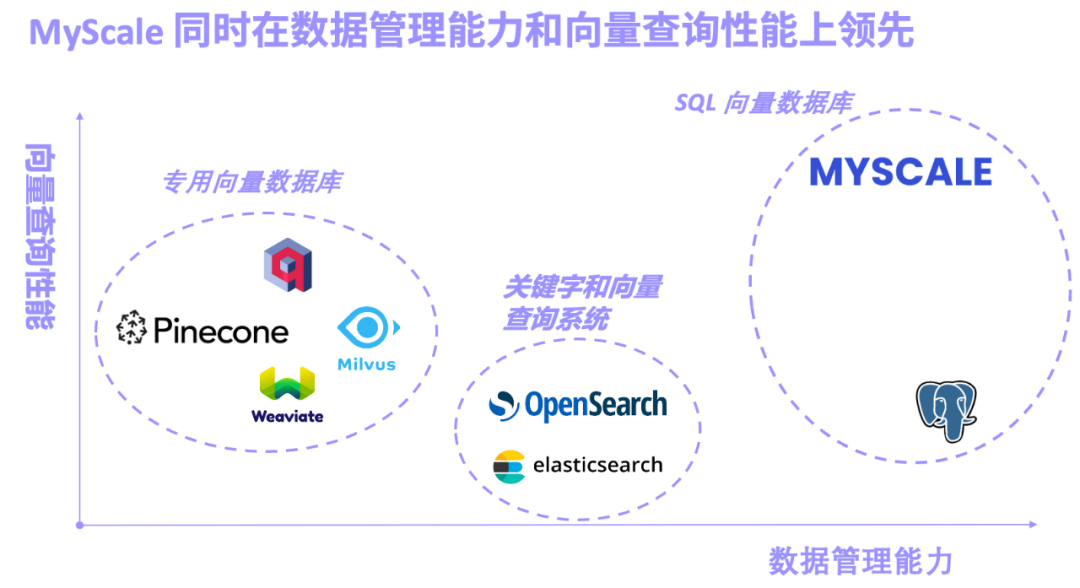
AI pertama yang benar-benar berorientasikan model besar dan data besar
Keserasian asli SQL dan vektor
Dalam senario aplikasi AI kompleks sebenar, gabungan SQL dan vektor boleh meningkatkan fleksibiliti pemodelan data dan memudahkan proses pembangunan. Contohnya, dalam projek Science Navigator yang bekerjasama antara pasukan MyScale dan Institut Kecerdasan Saintifik Beijing, MyScaleDB digunakan untuk mendapatkan semula data kesusasteraan saintifik yang besar dan melaksanakan jawapan soalan pintar Terdapat lebih daripada 10 struktur jadual SQL utama, yang kebanyakannya ditubuhkan vektor. Dan indeks jadual terbalik, dan gunakan kunci utama dan kunci asing untuk membuat perkaitan. Dalam pertanyaan sebenar, sistem juga akan melibatkan pertanyaan bersama data berstruktur, vektor dan kata kunci, serta pertanyaan berkaitan beberapa jadual. Pemodelan dan korelasi ini sukar dicapai dalam pangkalan data vektor khusus, yang juga akan membawa kepada lelaran sistem akhir yang perlahan, pertanyaan yang tidak cekap dan penyelenggaraan yang sukar. 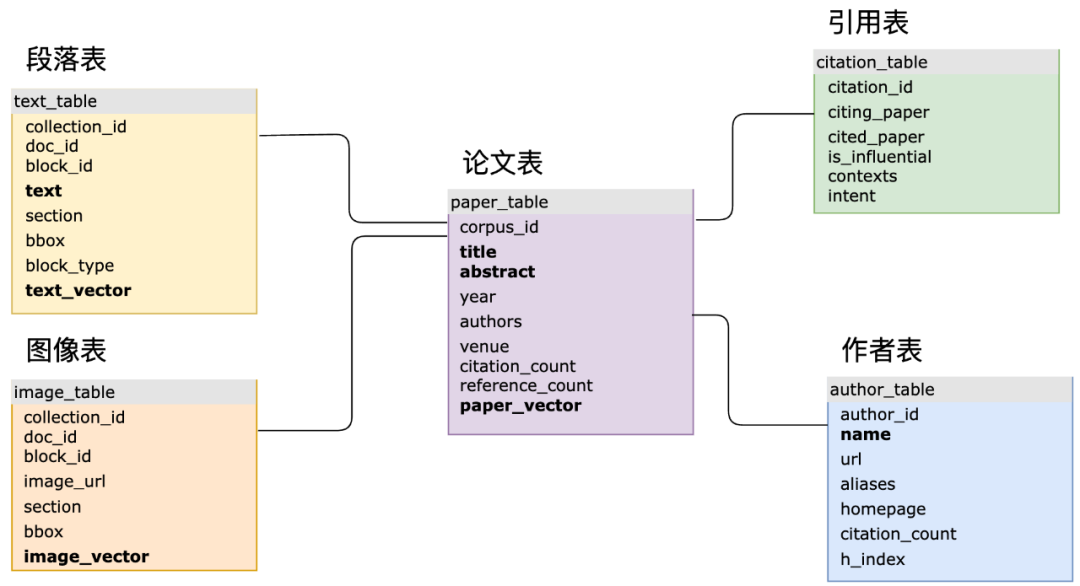
60%
Keseimbangan prestasi dan kos dalam adegan sebenar Disebabkan kepentingan dan perhatian yang tinggi dalam aplikasi model besar. semakin banyak pasukan telah melabur dalam trek pangkalan data vektor. Tumpuan awal semua orang adalah untuk meningkatkan QPS dalam senario carian vektor tulen, tetapi
Dalam senario RAG, prestasi pertanyaan vektor tulen mempunyai lebihan 10x, vektor menduduki sumber yang besar, kekurangan fungsi pertanyaan bersama, prestasi dan ketepatan yang lemah sering menjadi norma dalam pangkalan data vektor proprietari semasa.
Alamat projek Penanda Aras Pangkalan Data Vektor MyScale:
pangkalan data SQL + vektor berprestasi tinggi
Atas ialah kandungan terperinci Teks panjang tidak boleh membunuh RAG: vektor SQL+ memacu model besar dan paradigma baharu data besar, pangkalan data MyScale AI adalah sumber terbuka secara rasmi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan yang digunakan untuk operasi nombor terapung dalam bahasa Go memperkenalkan cara memastikan ketepatannya ...
 GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
Giteepages Statik Laman Web Penggunaan Gagal: 404 Penyelesaian Masalah dan Resolusi Ralat Semasa Menggunakan Gitee ...
 Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Menjalankan projek H5 memerlukan langkah -langkah berikut: memasang alat yang diperlukan seperti pelayan web, node.js, alat pembangunan, dan lain -lain. Membina persekitaran pembangunan, membuat folder projek, memulakan projek, dan menulis kod. Mulakan pelayan pembangunan dan jalankan arahan menggunakan baris arahan. Pratonton projek dalam penyemak imbas anda dan masukkan URL Server Pembangunan. Menerbitkan projek, mengoptimumkan kod, menggunakan projek, dan menyediakan konfigurasi pelayan web.
 Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau projek sumber terbuka yang terkenal? Semasa pengaturcaraan di GO, pemaju sering menghadapi beberapa keperluan biasa, ...
 Bagaimana cara menentukan pangkalan data yang berkaitan dengan model dalam beego orm?
Apr 02, 2025 pm 03:54 PM
Bagaimana cara menentukan pangkalan data yang berkaitan dengan model dalam beego orm?
Apr 02, 2025 pm 03:54 PM
Di bawah rangka kerja beegoorm, bagaimana untuk menentukan pangkalan data yang berkaitan dengan model? Banyak projek beego memerlukan pelbagai pangkalan data untuk dikendalikan secara serentak. Semasa menggunakan beego ...
 Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Halaman H5 perlu dikekalkan secara berterusan, kerana faktor -faktor seperti kelemahan kod, keserasian pelayar, pengoptimuman prestasi, kemas kini keselamatan dan peningkatan pengalaman pengguna. Kaedah penyelenggaraan yang berkesan termasuk mewujudkan sistem ujian lengkap, menggunakan alat kawalan versi, kerap memantau prestasi halaman, mengumpul maklum balas pengguna dan merumuskan pelan penyelenggaraan.
 Bagaimana menyelesaikan masalah penukaran jenis user_id semasa menggunakan aliran redis untuk melaksanakan beratur mesej dalam bahasa Go?
Apr 02, 2025 pm 04:54 PM
Bagaimana menyelesaikan masalah penukaran jenis user_id semasa menggunakan aliran redis untuk melaksanakan beratur mesej dalam bahasa Go?
Apr 02, 2025 pm 04:54 PM
Masalah menggunakan redisstream untuk melaksanakan beratur mesej dalam bahasa Go menggunakan bahasa Go dan redis ...
 Typecho Route Conflict Conflict: Kenapa saya/TEST/TAG/HIS/10086 Pencocokan TestTagIndex dan bukannya TestTagPage?
Apr 01, 2025 am 09:03 AM
Typecho Route Conflict Conflict: Kenapa saya/TEST/TAG/HIS/10086 Pencocokan TestTagIndex dan bukannya TestTagPage?
Apr 01, 2025 am 09:03 AM
TypeCho Routing Pencocokan Peraturan Analisis dan Penyiasatan Masalah Artikel ini akan menganalisis dan menjawab soalan mengenai hasil yang tidak konsisten dari pendaftaran routing plug-in typecho dan hasil padanan sebenar ...
