

Sistem pengesyor berdasarkan inferens sebab musabab: semakan dan prospek

Tema perkongsian ini ialah sistem pengesyoran berdasarkan inferens sebab-sebab Kami menyemak kerja-kerja berkaitan yang lalu dan mencadangkan prospek masa depan ke arah ini.
Mengapa kita perlu menggunakan teknologi inferens sebab dalam sistem pengesyoran? Kerja penyelidikan sedia ada menggunakan inferens sebab-musabab untuk menyelesaikan tiga jenis masalah (lihat kertas TOIS 2023 Causal Inference in Recommender Systems: A Survey and Future Directions by Gao et al.):
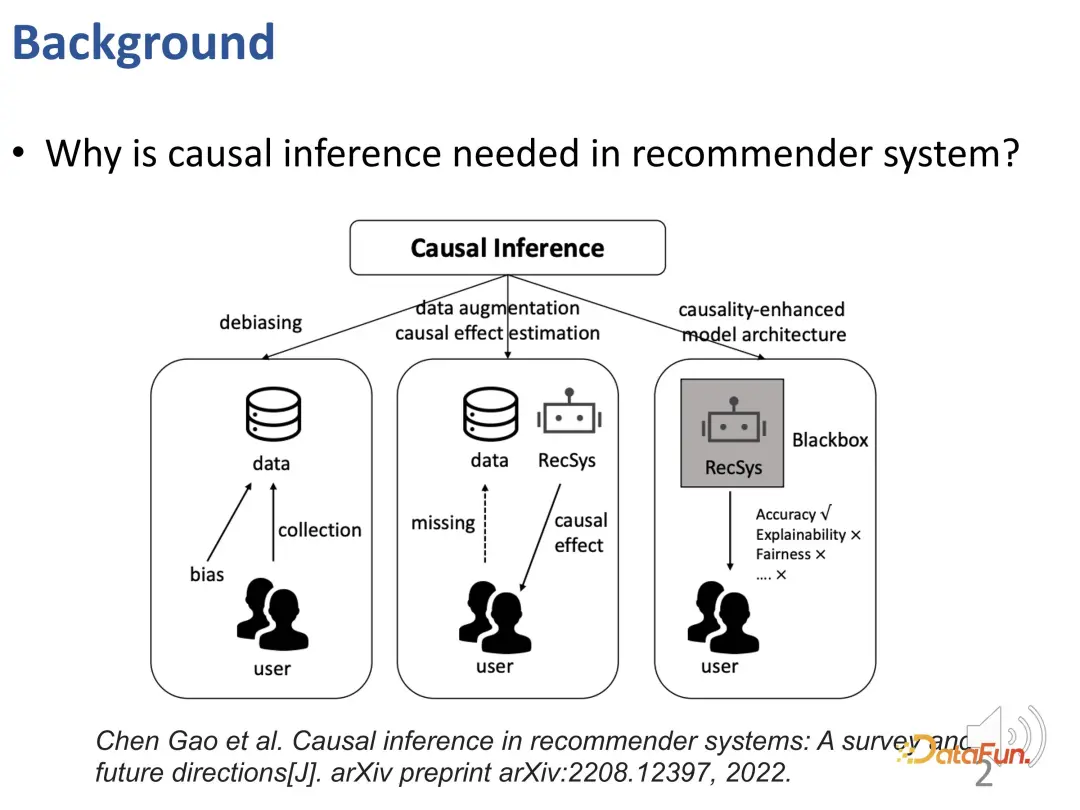
Pertama, dalam sistem pengesyoran, terdapat Pelbagai bias (BIAS), inferens sebab merupakan alat yang berkesan untuk menghapuskan bias ini.
Untuk menangani isu kekurangan data dan ketidakupayaan untuk menganggarkan kesan sebab akibat dengan tepat, sistem pengesyor mungkin menghadapi cabaran. Bagi menyelesaikan masalah ini, kaedah penambahbaikan data atau kaedah anggaran kesan sebab berdasarkan inferens sebab boleh digunakan untuk menyelesaikan masalah kekurangan data dan kesukaran menganggar kesan sebab akibat dengan berkesan.
Akhir sekali, model pengesyoran boleh dibina dengan lebih baik dengan menggunakan pengetahuan kausal atau pengetahuan terdahulu kausal untuk membimbing reka bentuk sistem pengesyoran. Kaedah ini membolehkan model pengesyoran mengatasi model kotak hitam tradisional, bukan sahaja meningkatkan ketepatan, tetapi juga meningkatkan kebolehtafsiran dan keadilan dengan ketara.
Bermula daripada tiga idea ini, perkongsian ini memperkenalkan tiga bahagian kerja berikut:
- Merungkai minat dan pematuhan pengguna untuk pengesyoran (Y. Zheng, Chen Gao, et al. Merungkai minat dan pematuhan pengguna untuk pengesyoran dengan penyematan sebab akibat [C]//Prosiding Persidangan Web 2021. 2021: 2980-2991.)
- Pembelajaran pengasingan kepentingan jangka panjang dan minat jangka pendek (Y. Zheng, Chen Gao*, et al. Merungkai panjang dan pendek- kepentingan terma untuk pengesyoran[C]//Prosiding Persidangan Web ACM 2022. 2022: 2256-2267.)
- Debiasing cadangan video pendek (Y. Zheng, Chen Gao*, et al. DVR: micro- video pengesyoran mengoptimumkan keuntungan masa tontonan di bawah berat sebelah tempoh[C]//Prosiding Persidangan Antarabangsa ACM ke-30 tentang Multimedia 2022: 334-345.)
1. Merungkai minat dan pematuhan pengguna
. Pertama, pelajari perwakilan yang sepadan untuk minat pengguna dan diskriminasi pematuhan melalui kaedah inferens sebab-akibat. Ini tergolong dalam bahagian ketiga rangka kerja pengelasan yang disebutkan di atas, iaitu untuk menjadikan model lebih mudah ditafsir apabila terdapat pengetahuan awal tentang sebab dan akibat.
Kembali kepada latar belakang penyelidikan. Dapat diperhatikan bahawa terdapat sebab yang mendalam dan berbeza di sebalik interaksi antara pengguna dan produk. Di satu pihak, ia adalah kepentingan pengguna sendiri, dan di sisi lain, pengguna mungkin cenderung mengikuti amalan pengguna lain (conformity). Dalam sistem tertentu, ini mungkin nyata sebagai volum jualan atau populariti. Sebagai contoh, sistem pengesyoran sedia ada akan memaparkan produk dengan jualan yang lebih tinggi di kedudukan hadapan, yang menyebabkan populariti di luar kepentingan pengguna sendiri menjejaskan interaksi dan menimbulkan berat sebelah. Oleh itu, untuk membuat cadangan yang lebih tepat, adalah perlu untuk membezakan antara pembelajaran dan menyelesaikan perwakilan kedua-dua bahagian.
Mengapa kita perlu mempelajari representasi terurai? Di sini, mari kita lakukan penjelasan yang lebih mendalam. Perwakilan terurai boleh membantu mengatasi masalah pengedaran tidak konsisten (OOD) data latihan luar talian dan data eksperimen dalam talian. Dalam sistem pengesyoran sebenar, jika model sistem pengesyoran luar talian dilatih di bawah pengedaran data tertentu, ia perlu dipertimbangkan bahawa pengedaran data mungkin berubah apabila digunakan dalam talian. Tingkah laku akhir pengguna dihasilkan oleh tindakan bersama kepatuhan dan kepentingan Kepentingan relatif kedua-dua bahagian ini adalah berbeza antara persekitaran dalam talian dan luar talian, yang boleh menyebabkan pengedaran data berubah dan jika pengedaran berubah, tiada jaminan bahawa minat untuk belajar akan tetap efisyen. Ini adalah masalah taburan silang. Gambar di bawah boleh menggambarkan masalah ini secara visual. Dalam angka ini, terdapat perbezaan pengedaran antara set data latihan dan ujian: bentuk yang sama, tetapi saiz dan warnanya telah berubah. Untuk ramalan bentuk, model tradisional mungkin membuat kesimpulan bentuk berdasarkan saiz dan warna pada set data latihan Contohnya, segi empat tepat berwarna biru dan terbesar, tetapi inferens tidak berlaku untuk set data ujian.
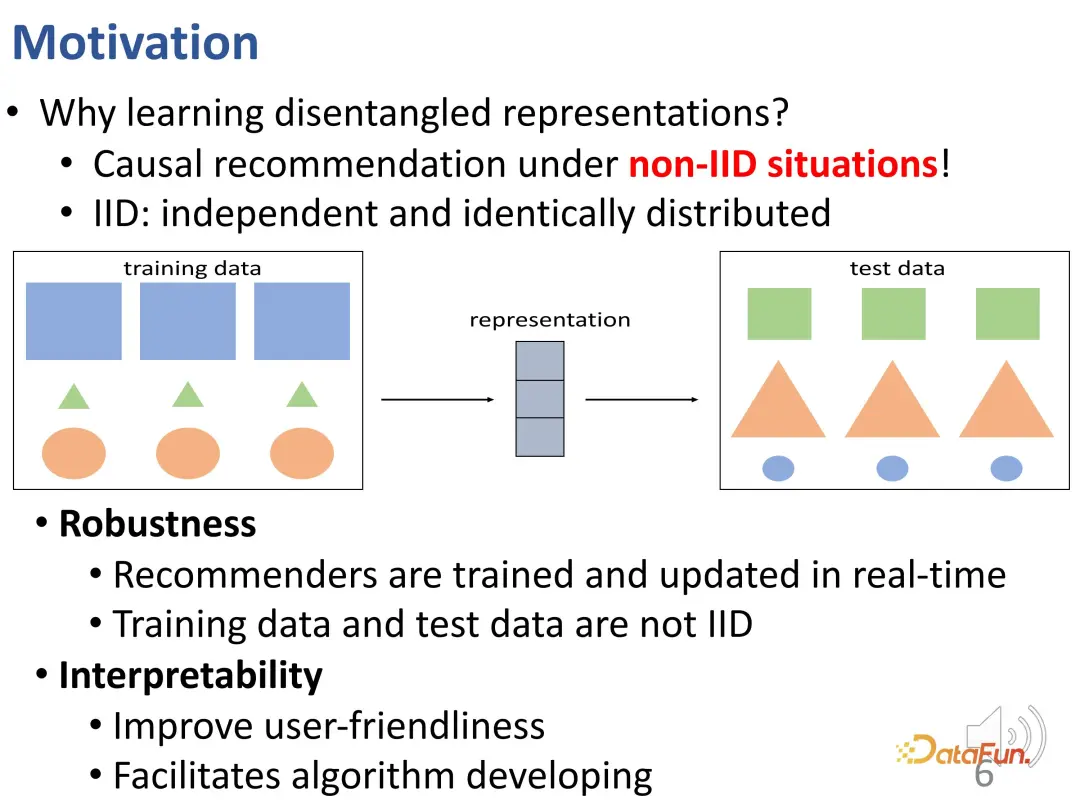
Jika anda ingin mengatasi kesukaran ini dengan lebih baik, anda perlu memastikan dengan berkesan bahawa perwakilan setiap bahagian ditentukan oleh faktor yang sepadan. Ini adalah salah satu motivasi untuk mempelajari representasi terurai. Model yang boleh merungkai faktor terpendam boleh mencapai hasil yang lebih baik dalam situasi taburan silang yang serupa dengan rajah di atas: contohnya, penguraian mempelajari faktor seperti kontur, warna dan saiz serta lebih suka menggunakan kontur untuk meramal bentuk.
Pendekatan tradisional adalah menggunakan kaedah IPS untuk mengimbangi populariti produk. Kaedah ini menghukum item yang terlalu popular (item ini mempunyai berat yang lebih besar dari segi pematuhan) semasa proses pembelajaran model sistem pengesyoran. Tetapi pendekatan ini menggabungkan minat dan kepatuhan bersama-sama tanpa memisahkannya dengan berkesan.

Terdapat beberapa kerja awal untuk mempelajari perwakilan sebab-akibat (Pembenaman sebab-akibat) melalui inferens sebab-akibat. Kelemahan jenis kerja ini ialah ia mesti bergantung pada beberapa set data yang tidak berat sebelah dan mengekang proses pembelajaran set data yang berat sebelah melalui set data yang tidak berat sebelah. Walaupun tidak banyak yang diperlukan, sejumlah kecil data tidak berat sebelah masih diperlukan untuk mempelajari perwakilan terurai. Oleh itu, kebolehgunaannya dalam sistem sebenar agak terhad.

- Keakuran pembolehubah: Keakuran sebenarnya adalah konsep bias yang lebih umum atau lebih umum, yang melibatkan konsep bias yang lebih umum . Pematuhan ditentukan oleh kedua-dua pengguna dan item Pematuhan pengguna pada item yang berbeza mungkin berbeza, dan sebaliknya.
- Kesukaran merungkai: Agak mencabar untuk mempelajari secara langsung representasi yang terurai. Hanya data pemerhatian (tingkah laku yang dipengaruhi oleh kedua-dua minat dan pematuhan) boleh diperoleh, tetapi tidak ada kebenaran asas tentang minat pengguna, iaitu, tiada label yang jelas untuk minat dan pematuhan itu sendiri.
- Sifat berbilang sebab tingkah laku pengguna: Interaksi pengguna tertentu mungkin datang daripada tindakan satu faktor atau gabungan dua faktor Sistem pengesyoran memerlukan reka bentuk yang teliti untuk menyepadukan kedua-dua faktor secara berkesan.
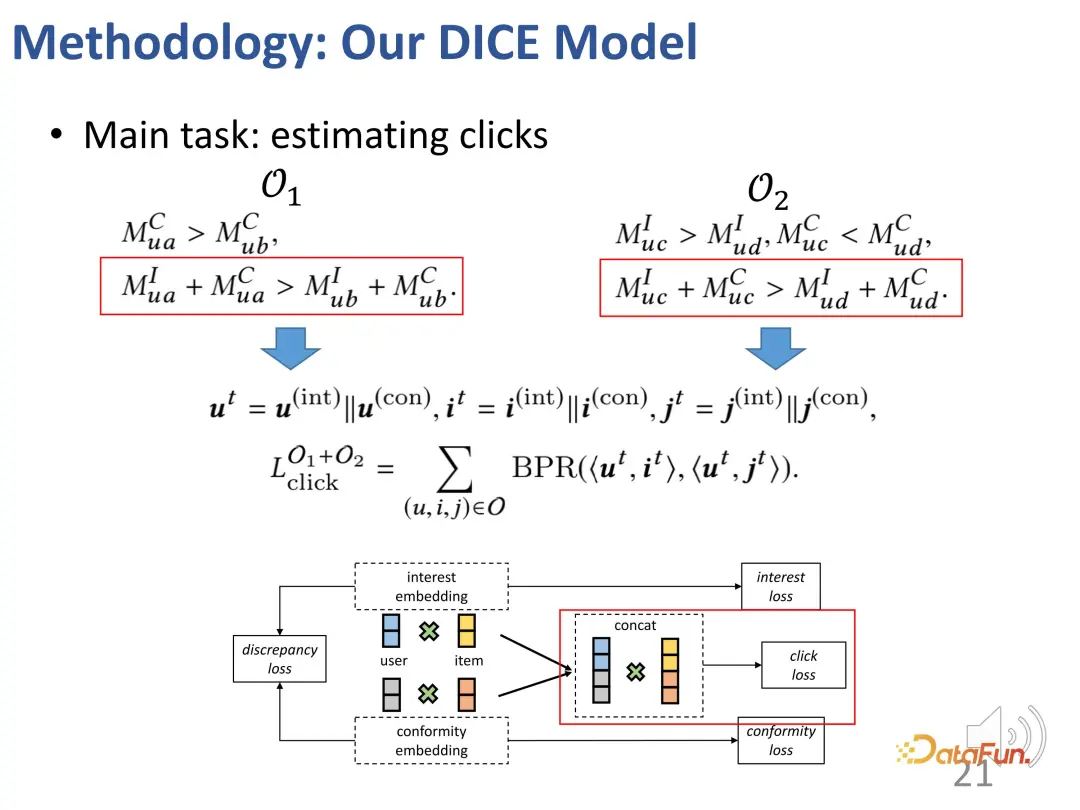
- Untuk menyelesaikan cabaran pertama, perwakilan yang sepadan ditetapkan untuk pengguna dan produk dari segi minat dan pematuhan. Pertama, interaksi pembenaman antara pengguna dan produk dalam ruang dimensi tinggi secara berkesan dapat menyatakan pematuhan yang pelbagai. Kedua, kaedah ini secara langsung boleh merungkai minat dan kepatuhan dalam ruang dimensi tinggi, dan bukannya bergantung pada perwakilan yang sama, mencapai kebebasan kedua-duanya.
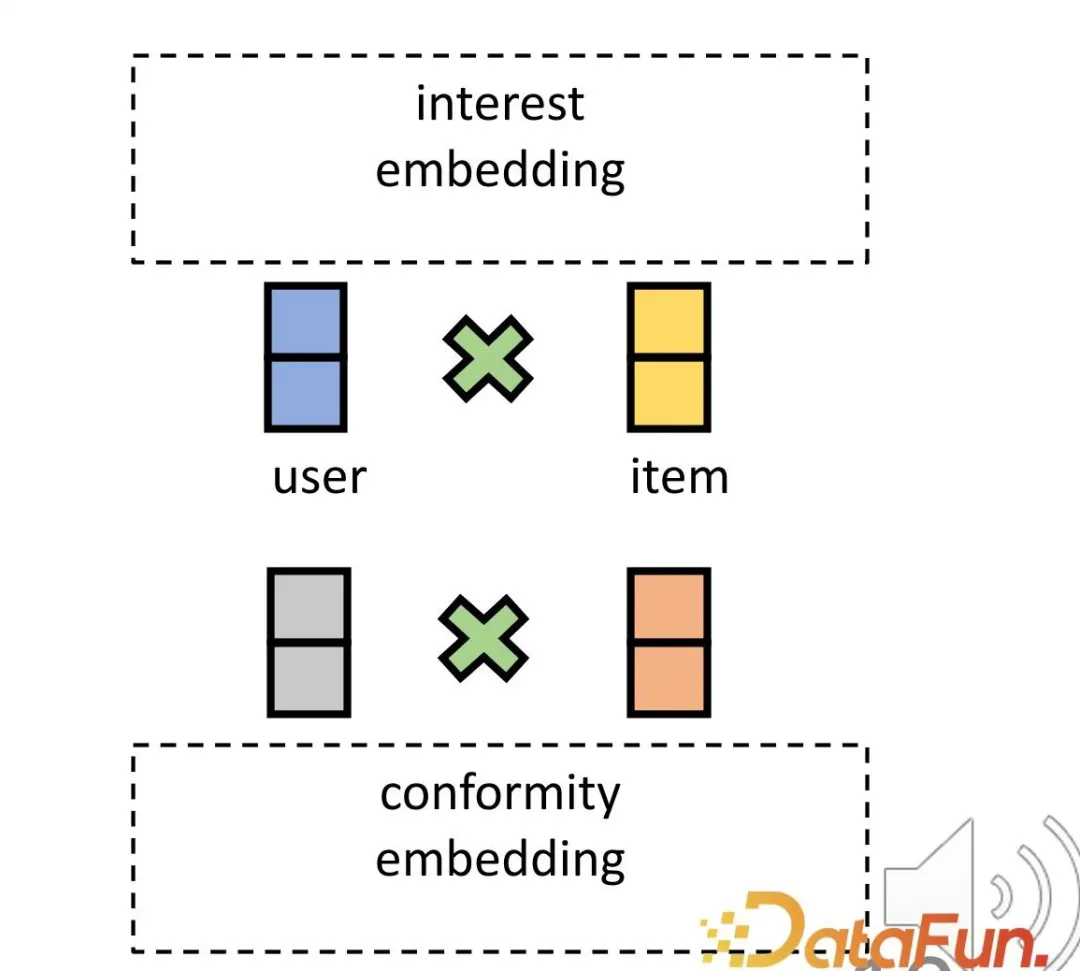
- Untuk menyelesaikan cabaran kedua, hubungan perlanggaran dalam inferens sebab-akibat digunakan. Minat dan pematuhan bersama-sama membawa kepada tingkah laku, dan terdapat hubungan perlanggaran ini digunakan untuk mendapatkan data sebab-sebab tertentu untuk mempelajari perwakilan yang sepadan untuk kedua-dua bahagian.
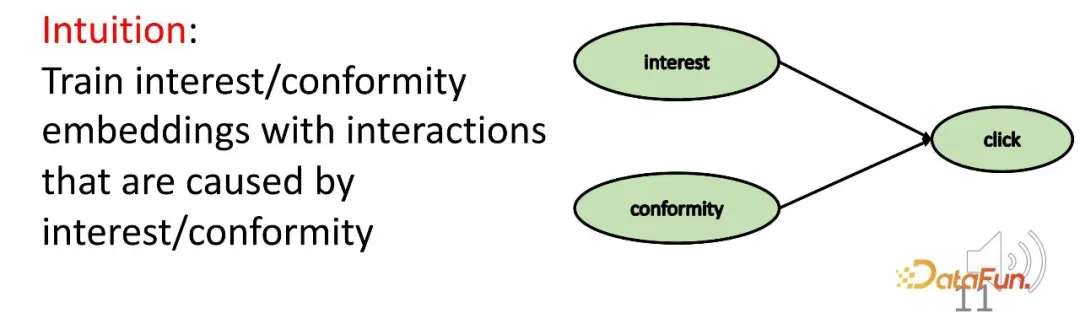
- Untuk menyelesaikan cabaran pelbagai faktor tingkah laku pengguna, kaedah pembelajaran progresif (CL) pelbagai tugas digunakan untuk menggabungkan kedua-dua faktor ini dengan berkesan untuk mencapai cadangan akhir.
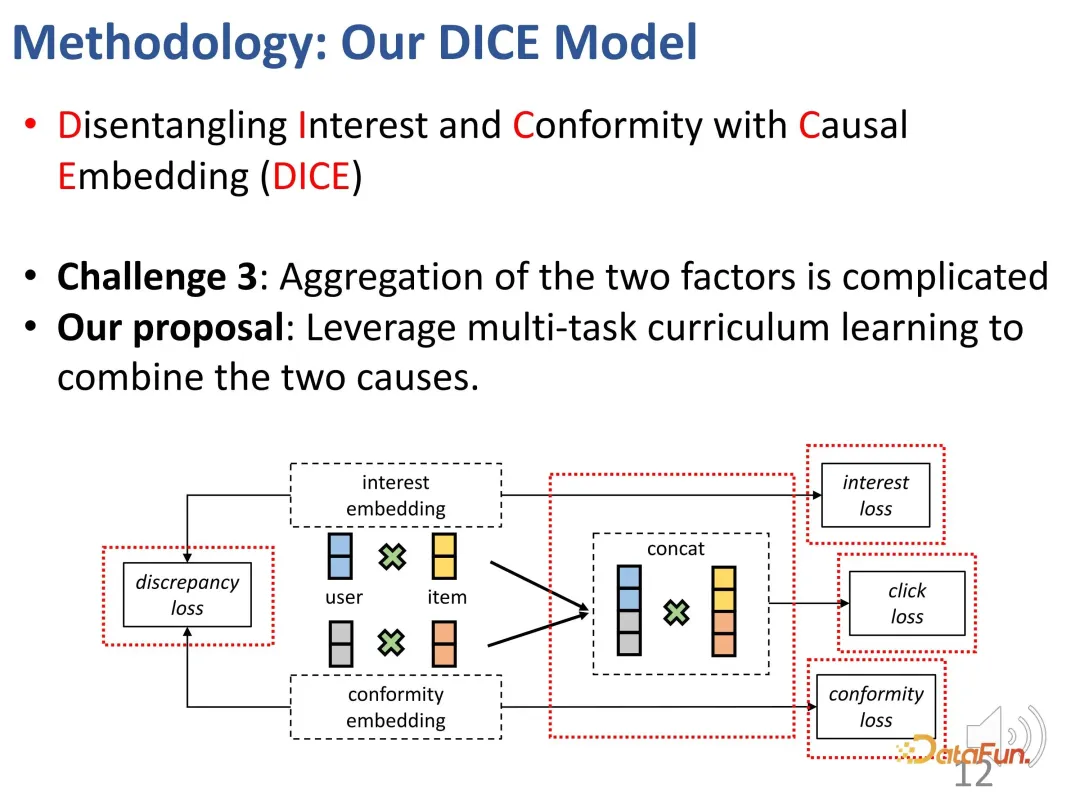
1. Penyematan kausal
Pertama, bina model kausal struktur, termasuk minat dan tingkah laku penggembalaan.
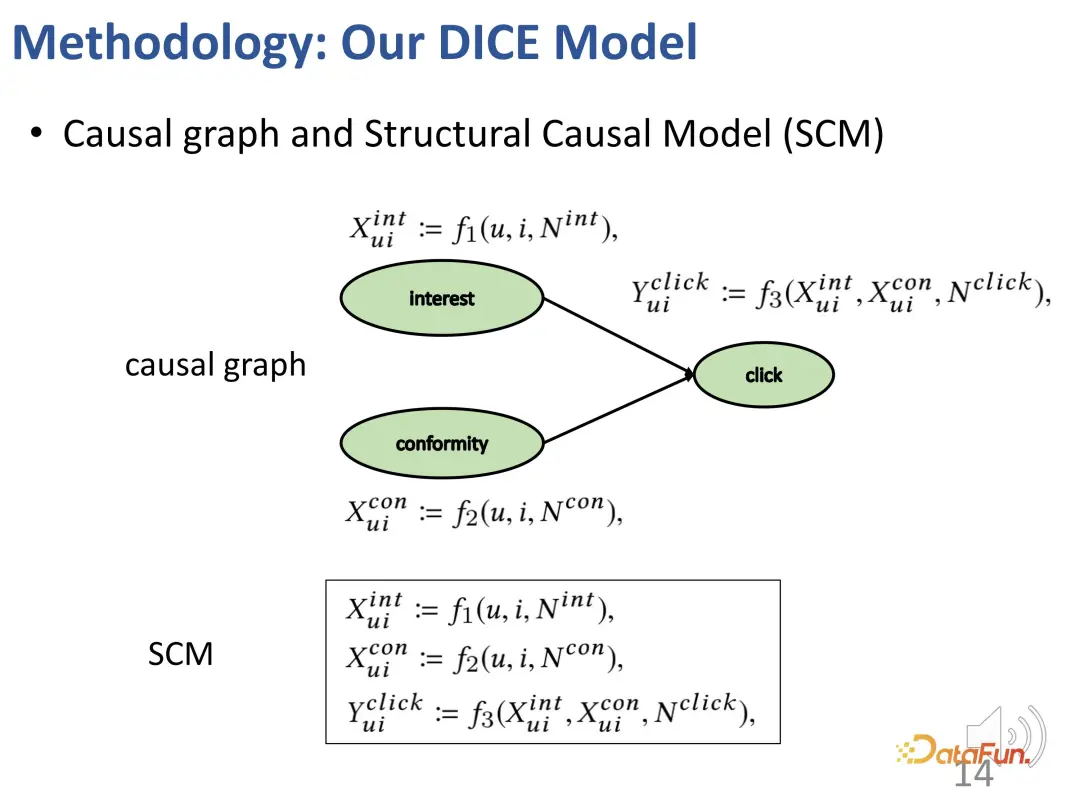
2. Pembelajaran perwakilan terurai
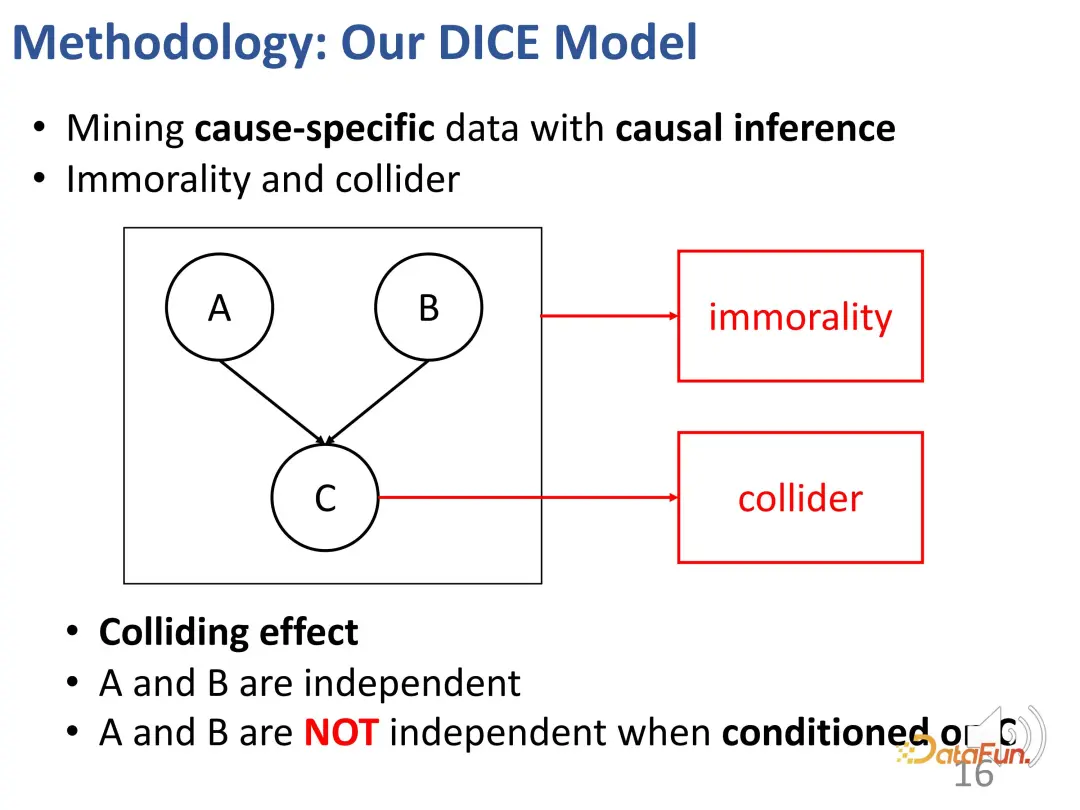
Memandangkan struktur perlanggaran seperti di atas, apabila keadaan c ditetapkan, a dan b sebenarnya tidak bebas. Berikan satu contoh untuk menerangkan kesan ini: Contohnya, a mewakili bakat pelajar, b mewakili ketekunan pelajar, dan c mewakili sama ada pelajar itu boleh lulus peperiksaan. Jika pelajar ini lulus peperiksaan dan dia tidak mempunyai bakat yang sangat kuat, maka dia pasti telah bekerja keras. Seorang lagi pelajar, dia gagal dalam peperiksaan, tetapi dia sangat berbakat, maka rakan sekelas ini mungkin tidak cukup bekerja.
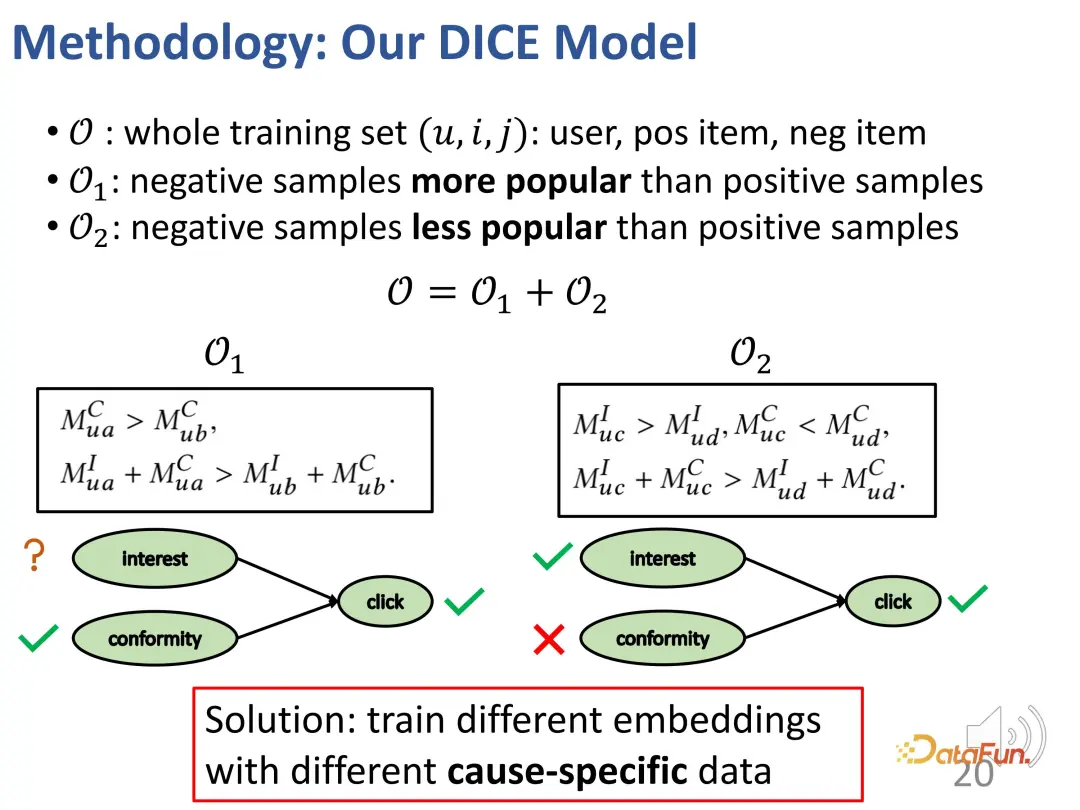
Berdasarkan idea ini, kaedah ini direka untuk membahagikan padanan minat dan pemadanan pematuhan, dan menggunakan populariti produk sebagai proksi untuk pematuhan.
Kes pertama: Jika pengguna mengklik pada item yang lebih popular a, tetapi tidak mengklik pada item lain yang kurang popular b, sama seperti contoh tadi, akan ada hubungan minat seperti yang ditunjukkan di bawah: a ke pengguna Keakuran a adalah lebih besar daripada b (kerana a lebih popular daripada b), dan daya tarikan keseluruhan a kepada pengguna (minat + keakuran) lebih besar daripada b (kerana pengguna mengklik a tetapi tidak mengklik b).
Kes kedua: Seorang pengguna mengklik pada item yang tidak popular c, tetapi tidak mengklik pada item popular d, menghasilkan perhubungan berikut: keakuran c kepada pengguna adalah kurang daripada d (kerana d lebih popular daripada c ), tetapi daya tarikan keseluruhan c kepada pengguna (minat + pematuhan) adalah lebih besar daripada d (kerana pengguna mengklik c tetapi bukan d), jadi minat pengguna terhadap c adalah lebih besar daripada d (kerana hubungan perlanggaran, seperti yang dinyatakan di atas) .
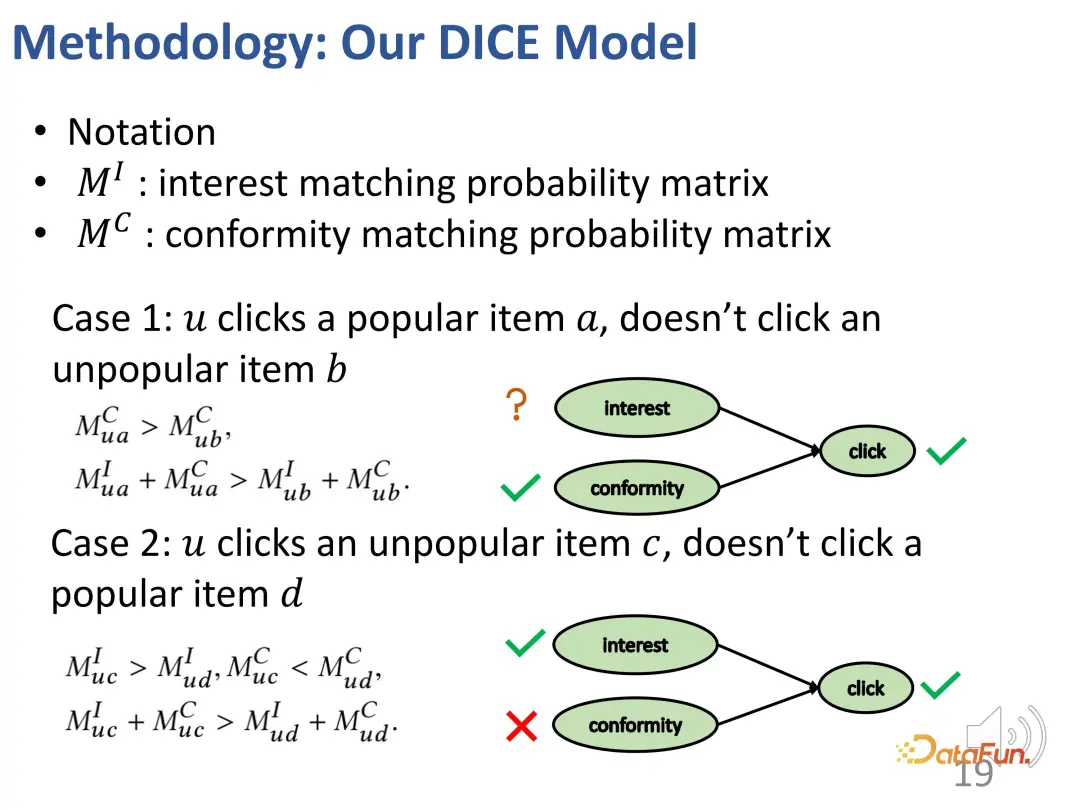
Secara amnya, dua set dibina melalui kaedah di atas: satu ialah sampel negatif yang kurang popular daripada sampel positif (kontras antara minat pengguna terhadap sampel positif dan negatif tidak diketahui), dan satu lagi adalah yang kurang popular daripada sampel positif Sampel negatif di mana sampel lebih popular (pengguna lebih berminat dengan sampel positif daripada sampel negatif). Pada kedua-dua bahagian ini, perhubungan pembelajaran kontrastif boleh dibina untuk melatih vektor perwakilan bagi kedua-dua bahagian tersebut dengan cara yang disasarkan.
Sudah tentu, dalam proses latihan sebenar, matlamat utama masih untuk menyesuaikan tingkah laku interaksi yang diperhatikan. Seperti kebanyakan sistem pengesyoran, kehilangan BPR digunakan untuk meramalkan gelagat klik. (u: pengguna, i: produk sampel positif, j: produk sampel negatif).
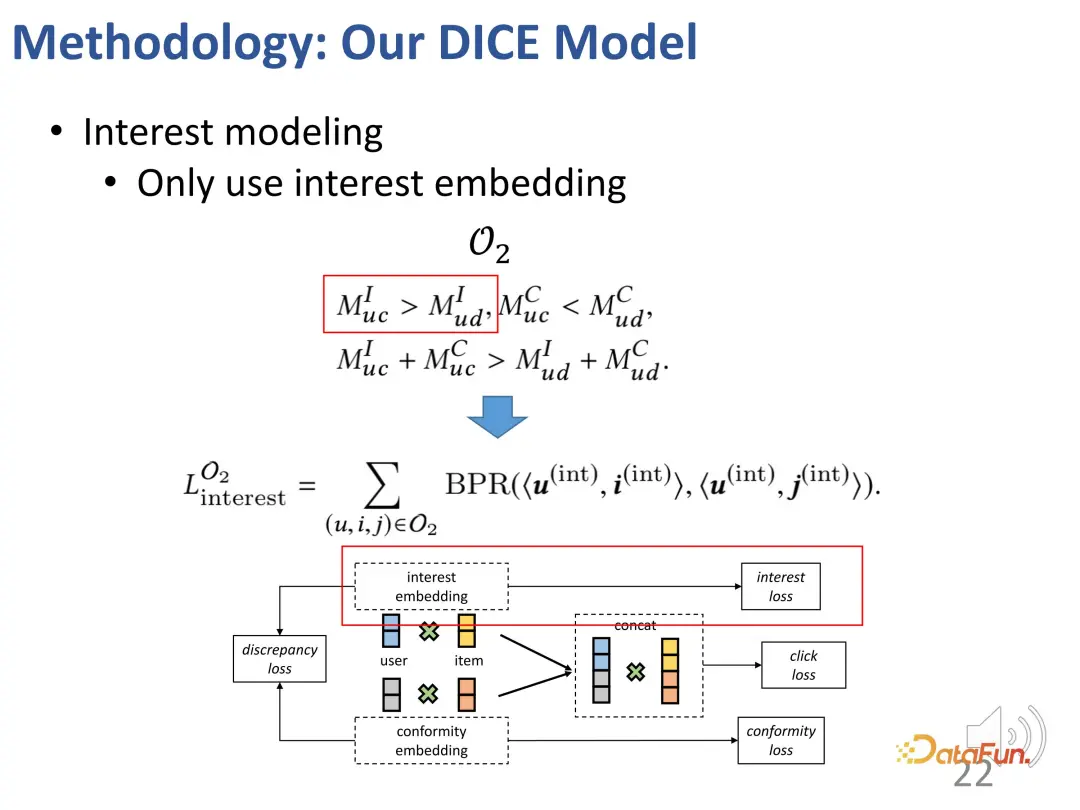
Selain itu, berdasarkan idea di atas, kami juga mereka bentuk dua bahagian kaedah pembelajaran kontrastif, memperkenalkan fungsi kehilangan pembelajaran kontrastif, dan tambahan memperkenalkan kekangan dua bahagian vektor perwakilan untuk mengoptimumkan kedua-duanya. bahagian vektor perwakilan
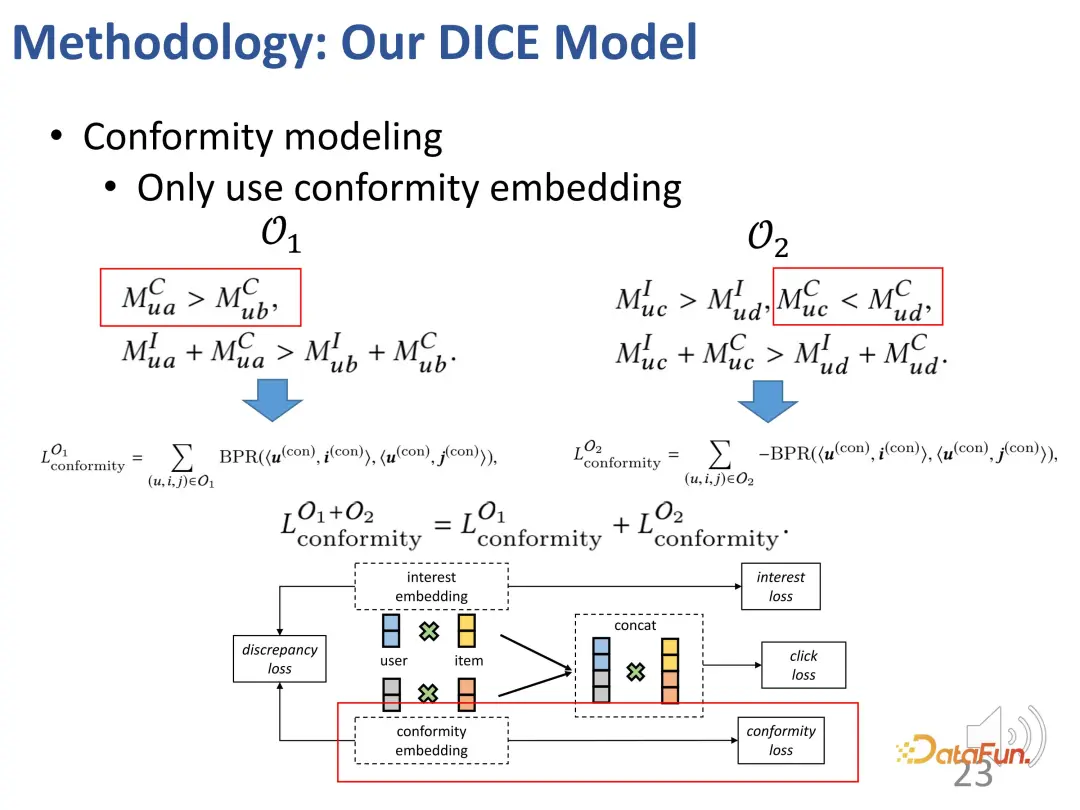
Selain itu, vektor perwakilan kedua-dua bahagian ini mesti dikekang untuk berada sejauh mungkin antara satu sama lain. Ini kerana mereka boleh kehilangan perbezaan jika mereka terlalu rapat. Oleh itu, fungsi kehilangan tambahan diperkenalkan untuk mengekang jarak antara dua vektor perwakilan separa.
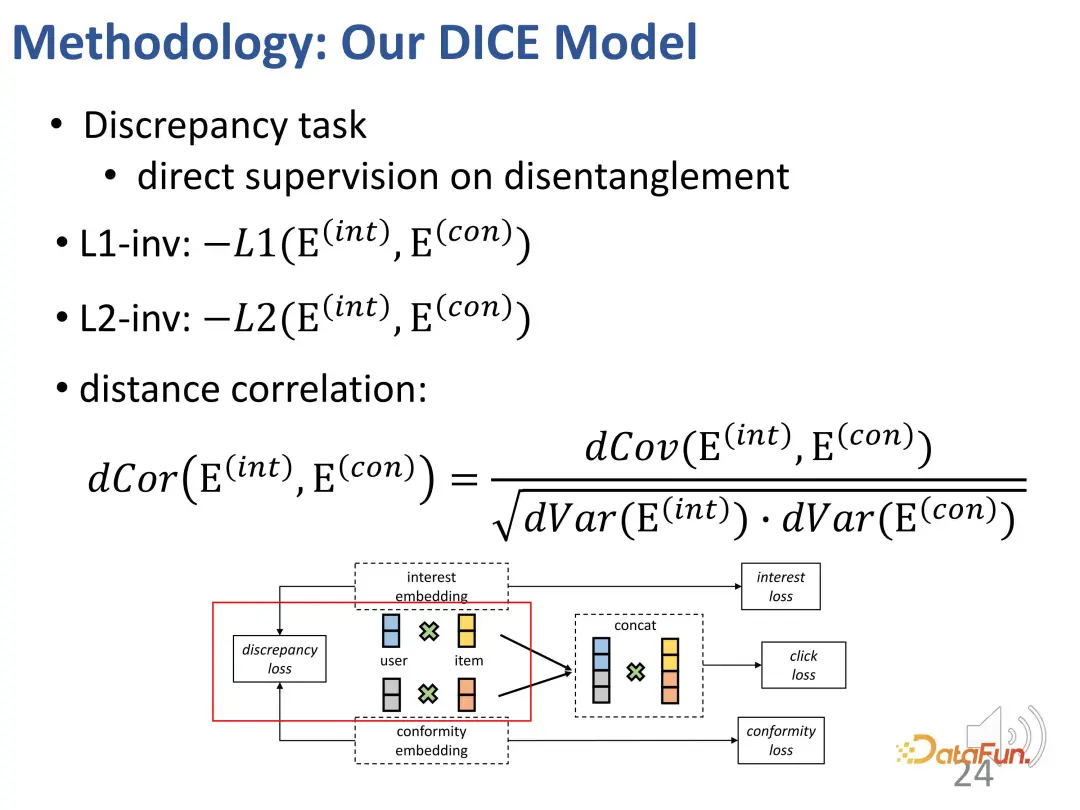
3. Pembelajaran kursus pelbagai tugas
Akhirnya, pembelajaran pelbagai tugas akan mengintegrasikan pelbagai matlamat bersama. Semasa proses ini, strategi telah direka untuk memastikan peralihan beransur-ansur daripada mudah kepada sukar dari segi kesukaran pembelajaran. Pada permulaan latihan, sampel dengan kurang diskriminasi digunakan untuk membimbing parameter model untuk dioptimumkan ke arah umum yang betul, dan kemudian secara beransur-ansur mencari sampel yang sukar untuk belajar untuk memperhalusi parameter model dengan lebih lanjut. (Sampel negatif dengan perbezaan populariti yang besar daripada sampel positif dianggap sebagai sampel mudah, dan sampel yang mempunyai perbezaan kecil dianggap sebagai sampel sukar).

4. Kesan kaedah
telah diuji pada set data biasa untuk mengkaji prestasi kaedah pada penunjuk kedudukan utama. Memandangkan DICE ialah rangka kerja umum yang tidak bergantung pada model pengesyoran tertentu, model yang berbeza boleh dianggap sebagai tulang belakang dan DICE boleh digunakan sebagai rangka kerja pasang dan main.

Pertama sekali, DICE protagonis. Ia boleh dilihat bahawa peningkatan DICE adalah agak stabil pada tulang belakang yang berbeza, jadi ia boleh dianggap sebagai rangka kerja umum yang boleh membawa peningkatan prestasi.
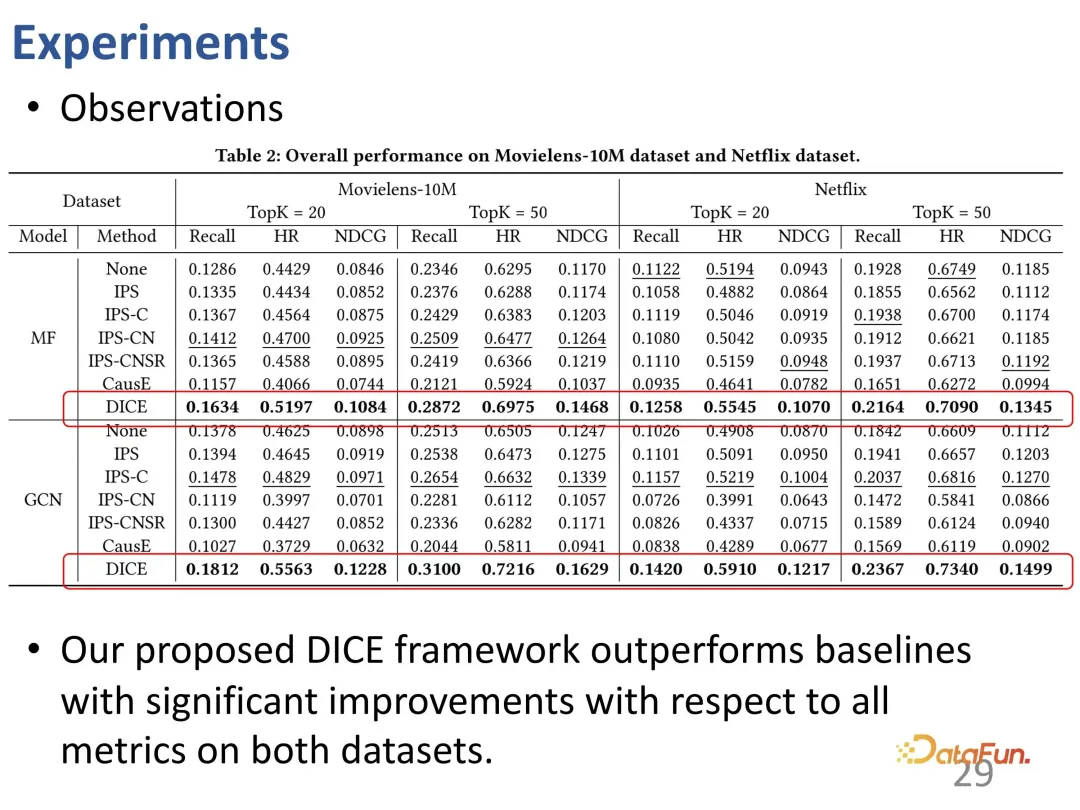
Perwakilan yang dipelajari oleh DICE boleh ditafsirkan Selepas mempelajari perwakilan untuk minat dan pematuhan secara berasingan, vektor bahagian pematuhan mengandungi populariti produk. Melalui visualisasi, didapati ia sememangnya berkaitan dengan populariti (perwakilan populariti yang berbeza menunjukkan stratifikasi yang jelas: titik hijau, oren dan kuning).
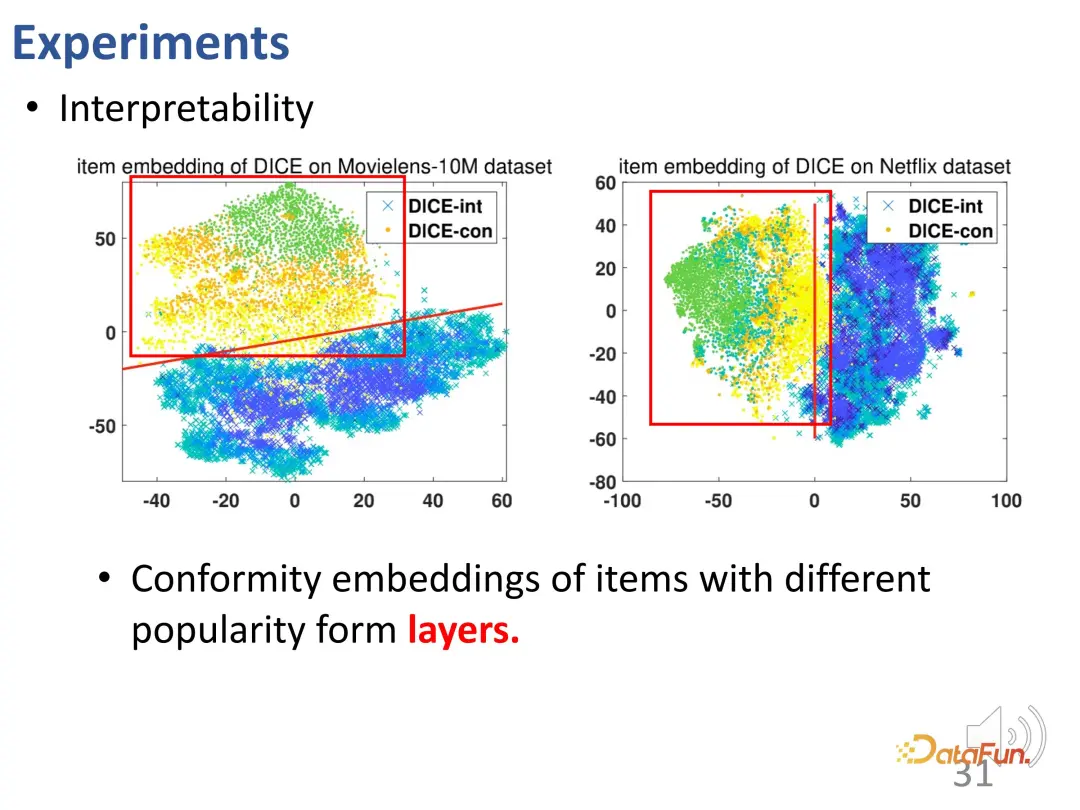
Lebih-lebih lagi, perwakilan vektor minat item dengan populariti berbeza diagihkan sama rata dalam ruang (cyanine cross). Perwakilan vektor pematuhan dan perwakilan vektor minat juga menduduki ruang yang berbeza dan dipisahkan oleh pemisahan. Visualisasi ini mengesahkan bahawa perwakilan yang dipelajari oleh DICE sebenarnya bermakna.
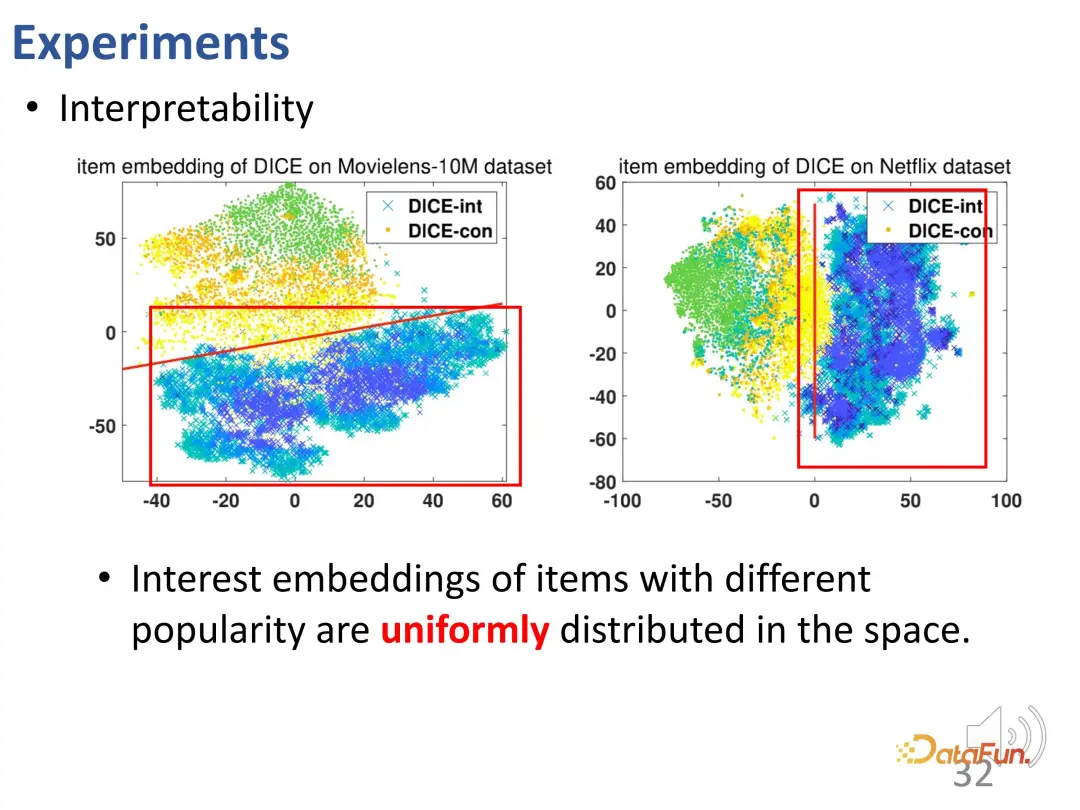
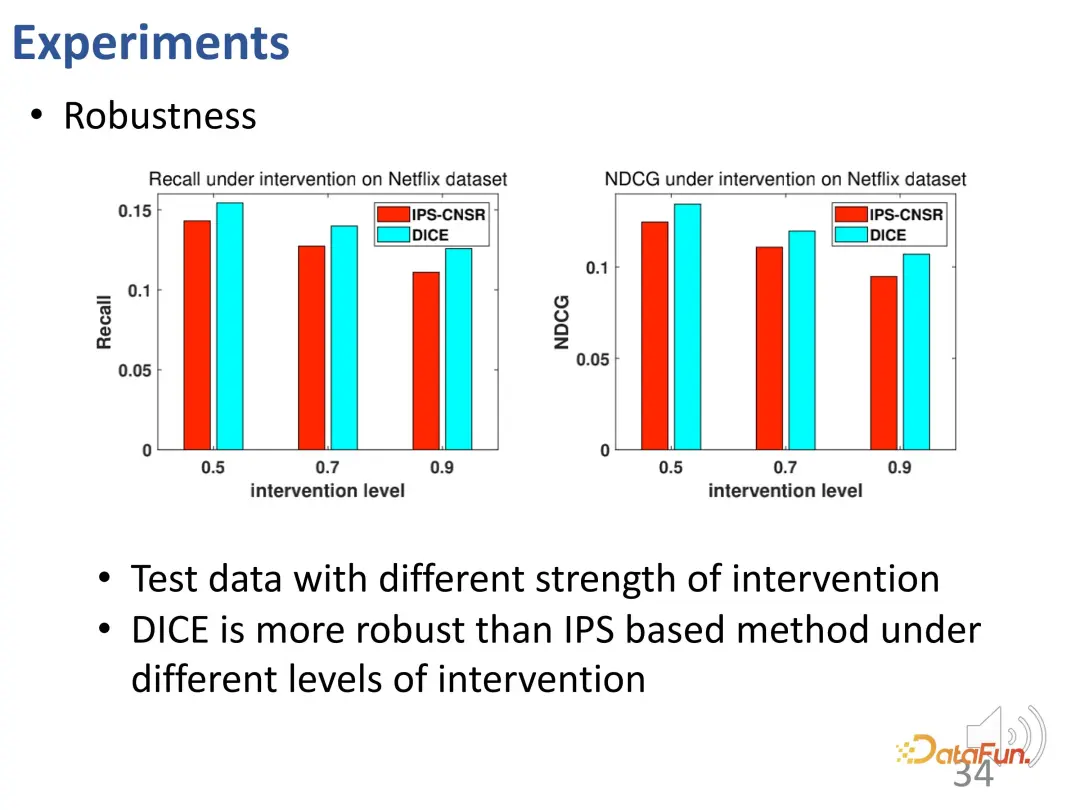
DICE mencapai kesan reka bentuk yang dimaksudkan. Ujian lanjut telah dijalankan ke atas data dengan intensiti intervensi yang berbeza, dan keputusan menunjukkan bahawa prestasi DICE adalah lebih baik daripada kaedah IPS dalam kumpulan eksperimen yang berbeza.
Untuk meringkaskan, DICE menggunakan alat inferens sebab untuk mempelajari vektor perwakilan yang sepadan untuk kepentingan dan pematuhan masing-masing, memberikan keteguhan dan kebolehtafsiran yang baik dalam situasi bukan IID. . pengesyoran urutan, khususnya, Minat pengguna adalah kompleks Sesetengah minat mungkin secara relatif, stabil dan dipanggil kepentingan jangka panjang, manakala minat lain mungkin tiba-tiba dan dipanggil minat jangka pendek. Dalam contoh di bawah, pengguna berminat dengan produk elektronik dalam jangka masa panjang, tetapi ingin membeli beberapa pakaian dalam jangka pendek. Jika minat ini dapat dikenal pasti dengan baik, sebab bagi setiap tingkah laku boleh dijelaskan dengan lebih baik dan prestasi keseluruhan sistem pengesyoran boleh dipertingkatkan.

Masalah sebegini boleh dipanggil pemodelan kepentingan jangka panjang dan jangka pendek, iaitu, ia boleh menyesuaikan secara adaptif kepentingan jangka panjang dan kepentingan jangka pendek masing-masing, dan seterusnya membuat kesimpulan bahagian mana tingkah laku semasa pengguna didorong terutamanya. Jika anda boleh mengenal pasti minat yang mendorong gelagat pada masa ini, anda boleh membuat pengesyoran berdasarkan minat semasa dengan lebih baik. Sebagai contoh, jika pengguna menyemak imbas kategori yang sama dalam tempoh yang singkat, ia mungkin minat jangka pendek jika pengguna meneroka secara meluas dalam tempoh masa yang singkat, mungkin perlu merujuk lebih kepada yang diperhatikan lama- kepentingan jangka, tidak terhad kepada kepentingan semasa. Secara umum, kepentingan jangka panjang dan kepentingan jangka pendek adalah berbeza sifatnya, dan keperluan jangka panjang dan keperluan jangka pendek perlu dirungkai dengan baik.
Secara umumnya, boleh dianggap bahawa penapisan kolaboratif sebenarnya adalah kaedah untuk menangkap minat jangka panjang, kerana ia mengabaikan perubahan minat yang dinamik manakala cadangan jujukan sedia ada lebih menumpukan pada pemodelan minat jangka pendek, yang Ini membawa kepada melupakan kepentingan jangka panjang, dan walaupun kepentingan jangka panjang diambil kira, ia masih bergantung terutamanya pada minat jangka pendek apabila membuat model. Oleh itu, kaedah sedia ada masih gagal dalam menggabungkan kedua-dua minat untuk pembelajaran ini.
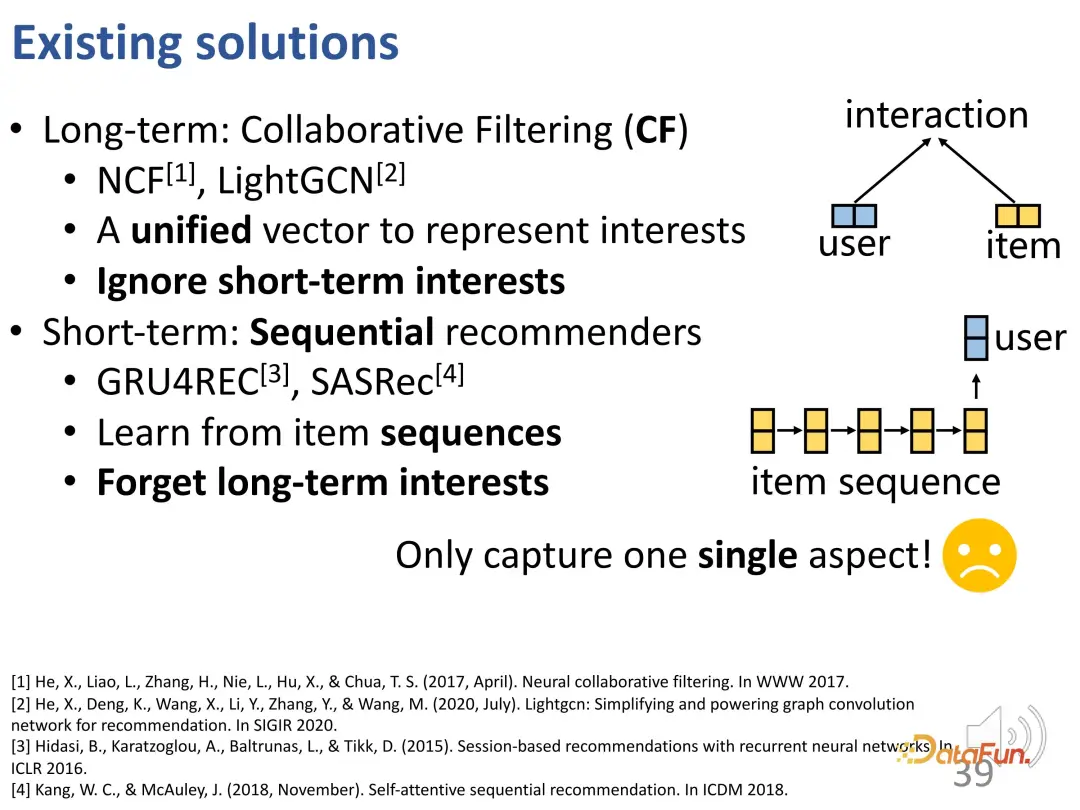
Beberapa karya baru-baru ini telah mula mempertimbangkan pemodelan minat jangka panjang dan jangka pendek, mereka bentuk modul jangka pendek dan modul jangka panjang secara berasingan, dan kemudian menggabungkannya secara langsung. Walau bagaimanapun, antara kaedah ini, terdapat hanya satu vektor pengguna yang akhirnya dipelajari, yang mengandungi kedua-dua isyarat jangka pendek dan isyarat jangka panjang Kedua-duanya masih terikat dan memerlukan penambahbaikan lagi.
Walau bagaimanapun, menyahganding kepentingan jangka panjang dan pendek masih mencabar:
- Pertama, minat jangka panjang dan jangka pendek sebenarnya mencerminkan perbezaan dalam pilihan yang agak berbeza di kalangan pengguna yang mungkin agak berbeza. ciri mereka juga berbeza . Faedah jangka panjang ialah minat umum yang agak stabil, manakala minat jangka pendek adalah dinamik dan boleh berkembang dengan pantas.
- Kedua, tiada label yang jelas untuk kepentingan panjang dan pendek. Kebanyakan data akhir yang dikumpul sebenarnya adalah tingkah laku terakhir, dan tidak ada kebenaran asas tentang jenis minat yang dimilikinya.
- Akhirnya, adalah juga tidak pasti bahagian mana kepentingan jangka panjang dan jangka pendek yang mendorong tingkah laku semasa, dan bahagian mana yang lebih penting.
Sebagai tindak balas kepada masalah ini, kaedah pembelajaran perbandingan dicadangkan untuk memodelkan minat jangka panjang dan jangka pendek pada masa yang sama. (Rangka kerja pembelajaran kontrastif kepentingan Jangka Panjang dan Pendek untuk Cadangan (CLSR))
1. Pengasingan kepentingan jangka panjang dan pendek
Untuk cabaran pertama - pemisahan minat jangka panjang dan jangka pendek. kepentingan jangka, kami memisahkan kepentingan jangka panjang dan jangka pendek Berminat untuk mewujudkan mekanisme evolusi yang sepadan masing-masing. Dalam model kausal struktur, kepentingan jangka panjang ditetapkan bebas daripada masa, dan kepentingan jangka pendek ditentukan oleh kepentingan jangka pendek pada saat sebelumnya dan kepentingan jangka panjang umum. Iaitu, semasa proses pemodelan, minat jangka panjang adalah agak stabil, manakala minat jangka pendek berubah dalam masa nyata.
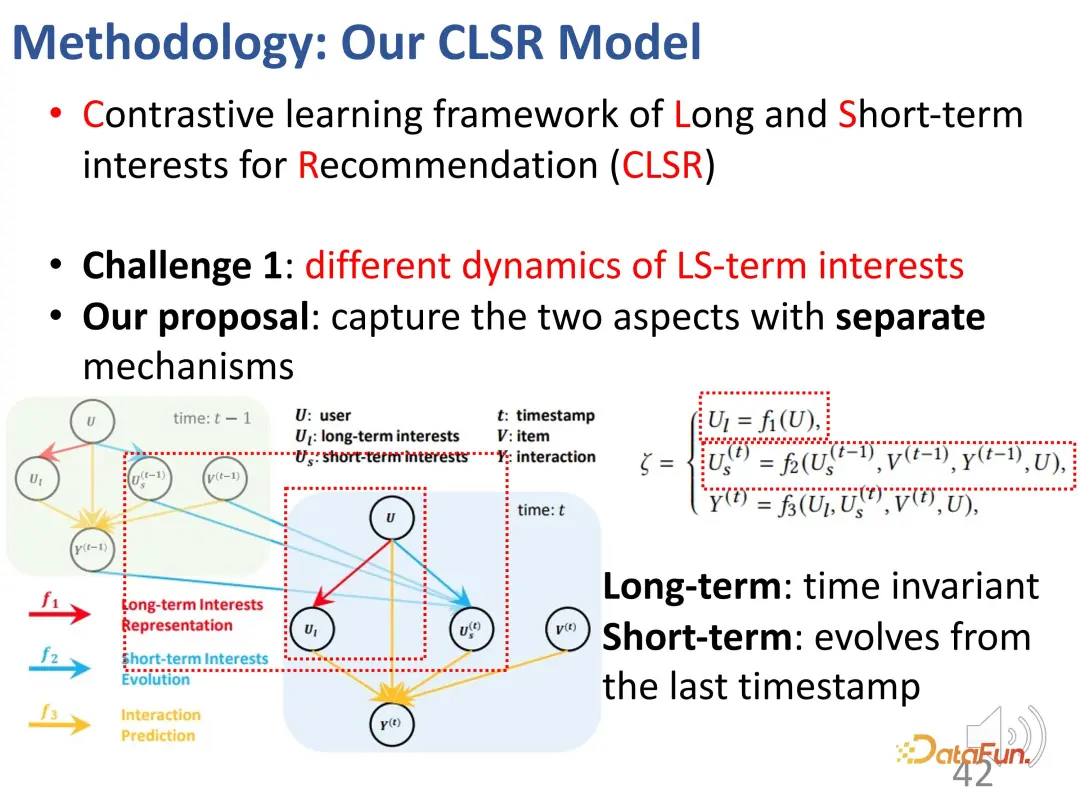
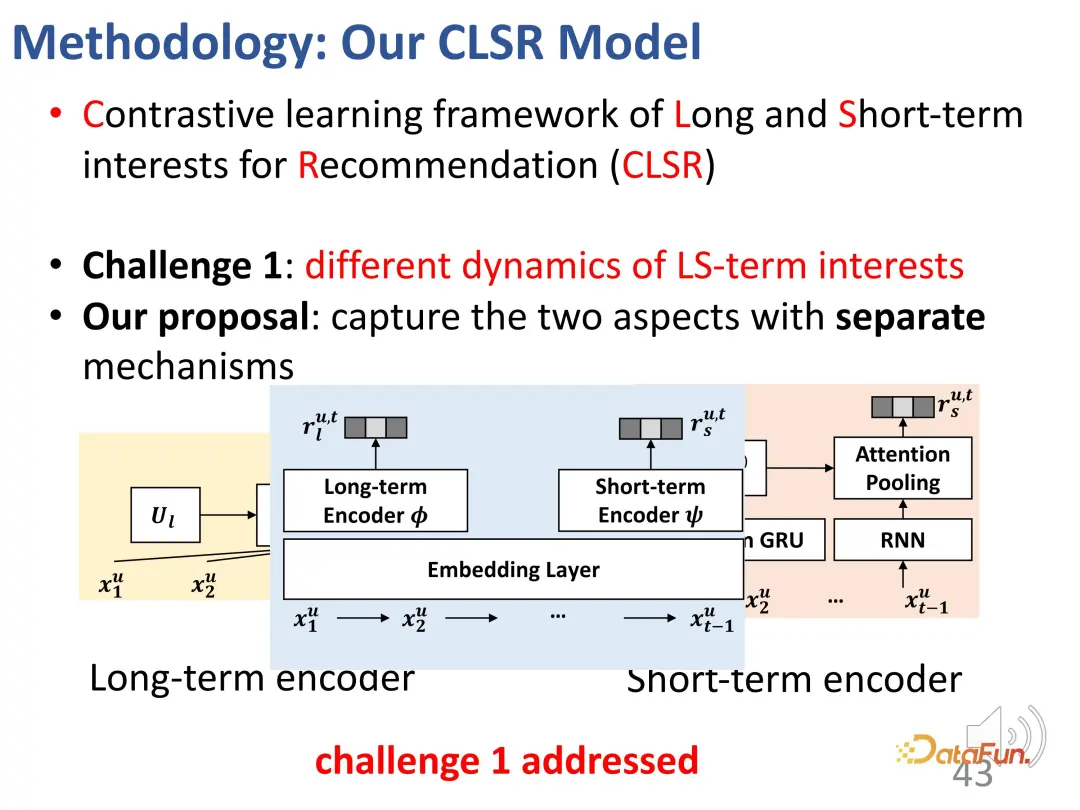
2. Pembelajaran kontrastif menyelesaikan kekurangan isyarat penyeliaan yang jelas
Cabaran kedua ialah kekurangan isyarat penyeliaan yang jelas untuk dua bahagian kepentingan. Untuk menyelesaikan masalah ini, kaedah pembelajaran kontrastif diperkenalkan untuk penyeliaan, dan label proksi dibina untuk menggantikan label eksplisit.
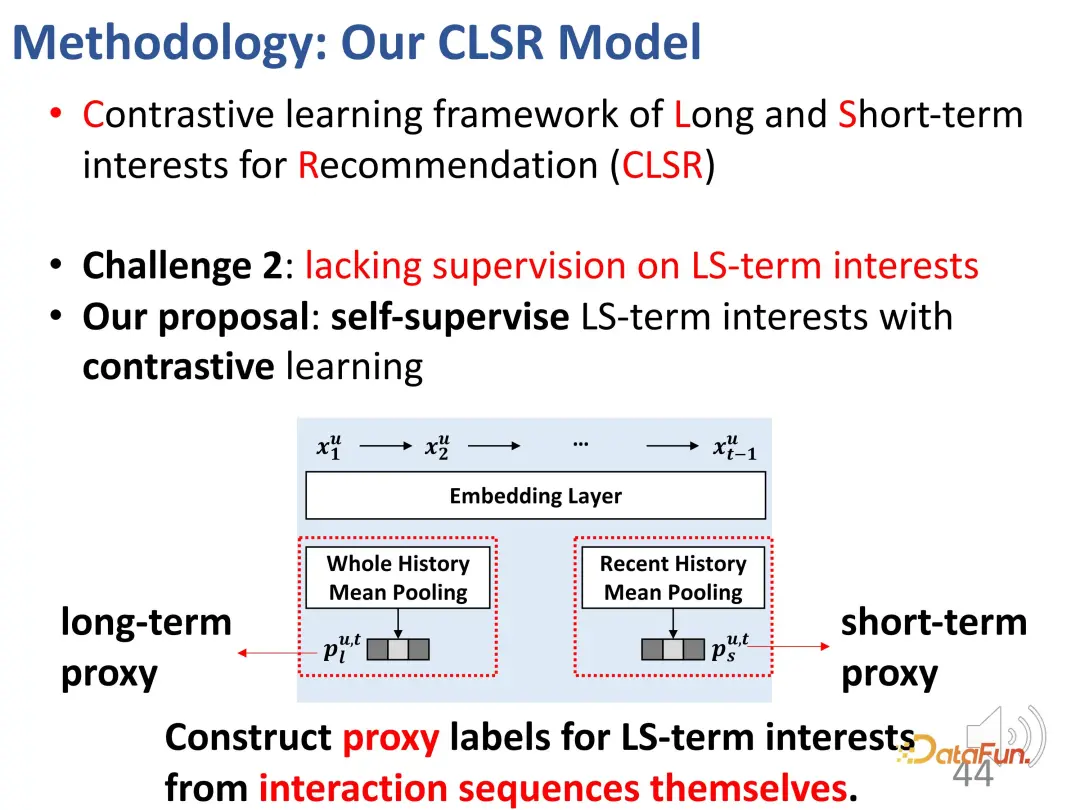
Label ejen terbahagi kepada dua bahagian, satu untuk ejen yang mempunyai kepentingan jangka panjang, dan satu lagi untuk ejen yang mempunyai kepentingan jangka pendek.
Gunakan keseluruhan sejarah pengumpulan sebagai label proksi minat jangka panjang, supaya perwakilan yang dipelajari oleh pengekod lebih dioptimumkan ke arah ini dalam pembelajaran minat jangka panjang.
Ia juga serupa untuk kepentingan jangka pendek Purata pengumpulan beberapa gelagat pengguna baru-baru ini digunakan sebagai proksi jangka pendek, walaupun ia tidak secara langsung mewakili kepentingan pengguna, ia digunakan sebanyak mungkin dalam proses pembelajaran minat jangka pendek pengguna ke arah ini. Walaupun perwakilan ejen seperti
tidak mewakili kepentingan sepenuhnya, ia mewakili arah pengoptimuman. Untuk perwakilan minat jangka panjang dan perwakilan minat jangka pendek, mereka akan berada sedekat mungkin dengan perwakilan yang sepadan dan menjauhkan diri daripada perwakilan ke arah lain, dengan itu membina fungsi kekangan untuk pembelajaran kontrastif. Dengan cara yang sama, kerana perwakilan proksi harus sedekat mungkin dengan output pengekod sebenar, ia adalah fungsi kehilangan dua bahagian simetri Reka bentuk ini dengan berkesan mengimbangi kekurangan isyarat penyeliaan yang baru disebut.
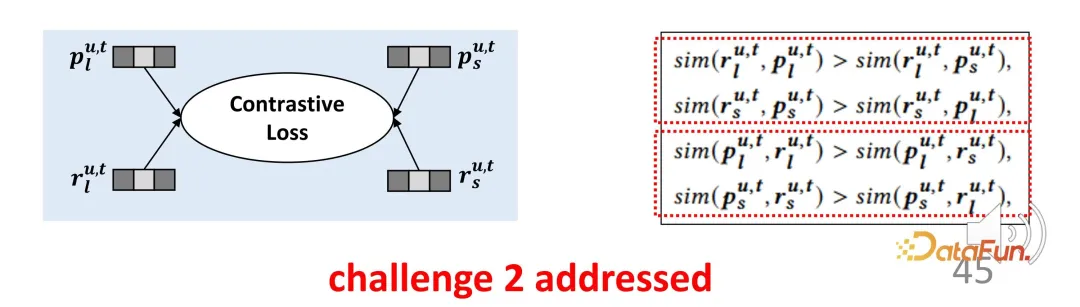
3. Diskriminasi wajaran faedah jangka panjang dan jangka pendek
Cabaran ketiga ialah menilai kepentingan dua bahagian minat untuk tingkah laku yang diberikan secara adaptif. Reka bentuk bahagian ini agak mudah dan mudah, kerana sudah ada dua bahagian vektor perwakilan sebelum ini, dan tidak sukar untuk mencampurkannya bersama. Secara khusus, berat α perlu dikira untuk mengimbangi kepentingan kedua-dua bahagian Apabila α adalah agak besar, faedah semasa terutamanya dikuasai oleh faedah jangka panjang. Akhirnya, anggaran tingkah laku interaksi diperolehi.
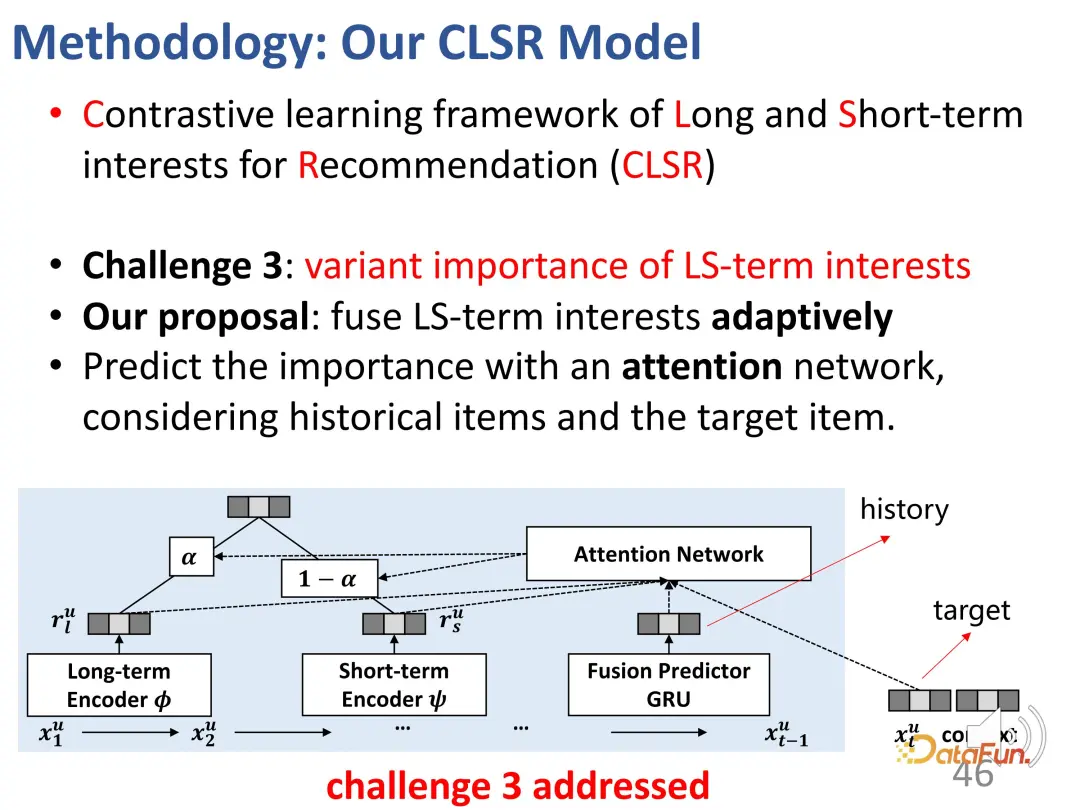
Untuk ramalan, dalam satu pihak, ia adalah kehilangan sistem pengesyoran umum yang disebutkan di atas, dan sebaliknya, kehilangan fungsi pembelajaran kontras ditambah kepadanya dalam bentuk wajaran.

Berikut ialah keseluruhan gambarajah blok:
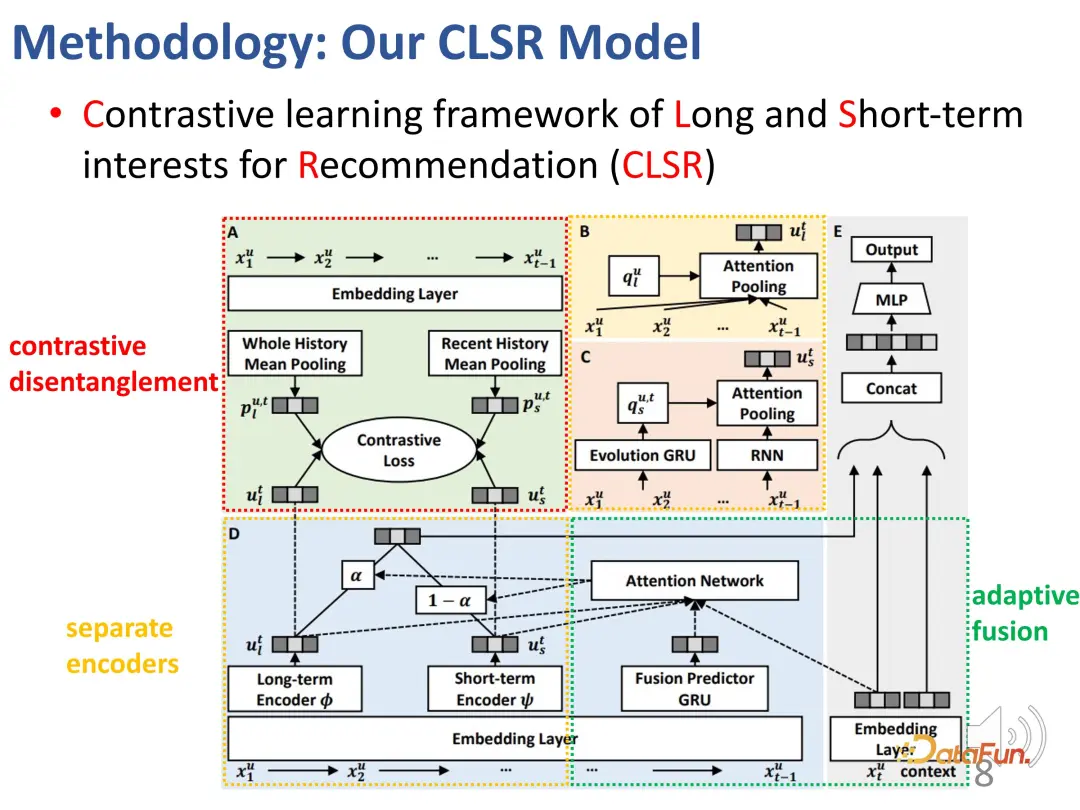
Terdapat dua pengekod berasingan (BCD) dan ejen yang sepadan dengan kontras automatik Mengadun secara adaptif kepentingan kedua-dua bahagian.
Dalam kerja ini, set data pengesyoran jujukan telah digunakan, termasuk set data e-dagang Taobao dan set data video pendek Kuaishou. Kaedah terbahagi kepada tiga jenis: jangka panjang, jangka pendek dan gabungan jangka panjang dan jangka pendek.
4. Hasil eksperimen

Memerhatikan hasil percubaan keseluruhan, kita dapat melihat bahawa model yang hanya menganggap minat jangka pendek berprestasi lebih baik daripada model yang hanya mempertimbangkan kepentingan jangka panjang. model pengesyoran jujukan biasanya lebih baik daripada model penapisan kolaboratif statik adalah lebih baik. Ini adalah munasabah kerana pemodelan minat jangka pendek boleh mengenal pasti dengan lebih baik beberapa minat terbaharu yang mempunyai kesan paling besar pada tingkah laku semasa.
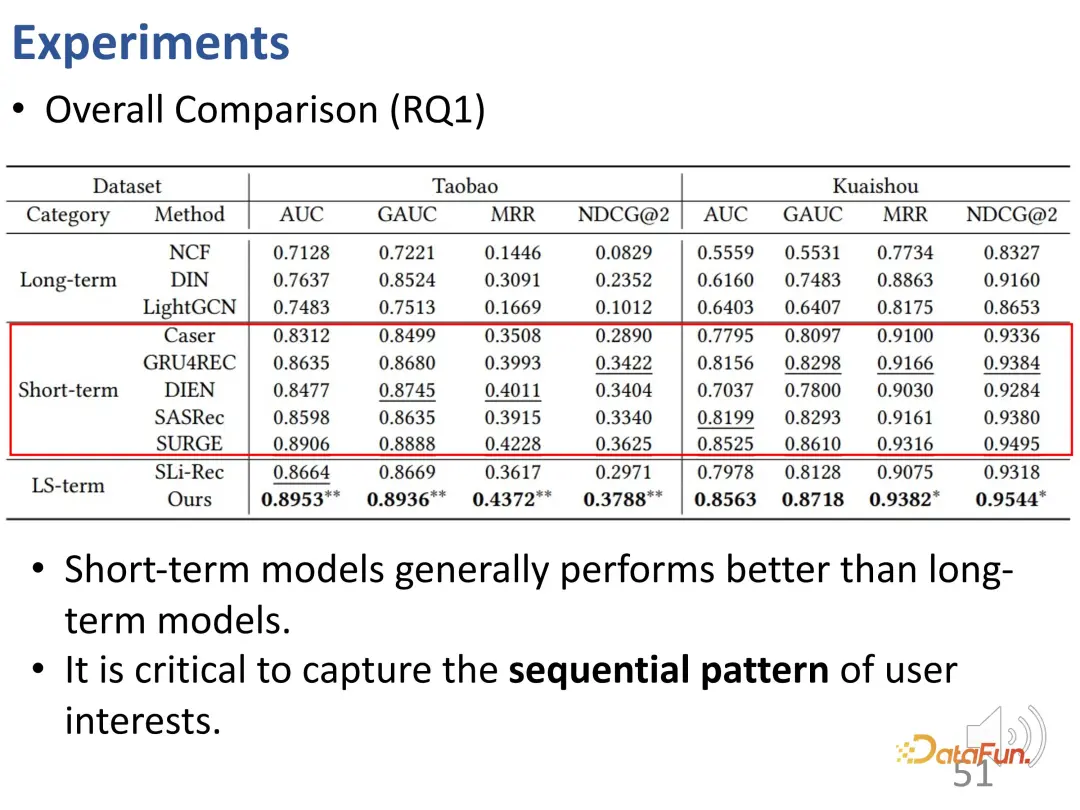
Kesimpulan kedua ialah model SLi-Rec yang memodelkan kedua-dua kepentingan jangka panjang dan jangka pendek tidak semestinya lebih baik daripada model pengesyoran jujukan tradisional. Ini menyerlahkan kelemahan kerja sedia ada. Sebabnya ialah dengan mencampurkan kedua-dua model itu mungkin menimbulkan bias atau hingar seperti yang dapat dilihat di sini, garis dasar yang terbaik sebenarnya ialah model minat jangka pendek yang berurutan.
Kaedah penyahgandingan minat jangka panjang dan jangka pendek yang kami cadangkan menyelesaikan masalah pemodelan pemisahan antara kepentingan jangka panjang dan jangka pendek, dan boleh mencapai keputusan terbaik yang stabil pada dua set data dan empat penunjuk.
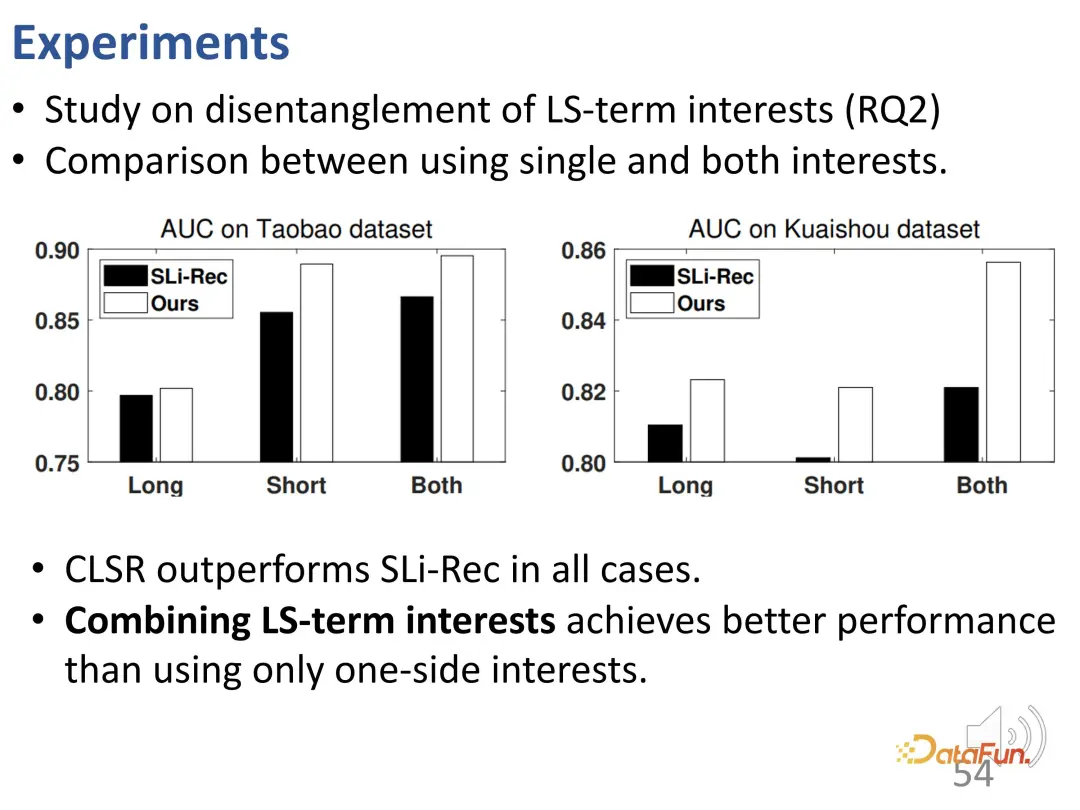
Untuk mengkaji lebih lanjut kesan keterpisahan ini, eksperimen telah dijalankan untuk perwakilan dua bahagian yang sepadan dengan kepentingan jangka panjang dan jangka pendek. Bandingkan minat jangka panjang, minat jangka pendek pembelajaran CLSR dan dua minat pembelajaran Sli-Rec. Keputusan eksperimen menunjukkan bahawa kerja kami (CLSR) mampu mencapai hasil yang lebih baik secara konsisten pada setiap bahagian, dan juga membuktikan keperluan untuk menggabungkan pemodelan minat jangka panjang dan pemodelan minat jangka pendek, kerana menggunakan kedua-duanya Hasil terbaik ialah penyepaduan minat .
Selanjutnya, gunakan gelagat pembelian dan gelagat suka untuk kajian perbandingan, kerana kos gelagat ini lebih tinggi daripada klik: pembelian memerlukan wang dan suka memerlukan kos operasi tertentu, jadi minat ini sebenarnya mencerminkan keutamaan yang lebih kukuh untuk kepentingan jangka panjang yang stabil. Pertama, dari segi perbandingan prestasi, CLSR mencapai hasil yang lebih baik. Tambahan pula, pemberatan kedua-dua aspek pemodelan adalah lebih munasabah. CLSR mampu memberikan pemberat yang lebih besar daripada model SLi-Rec kepada tingkah laku yang lebih berat sebelah terhadap minat jangka panjang, yang konsisten dengan motivasi sebelumnya.

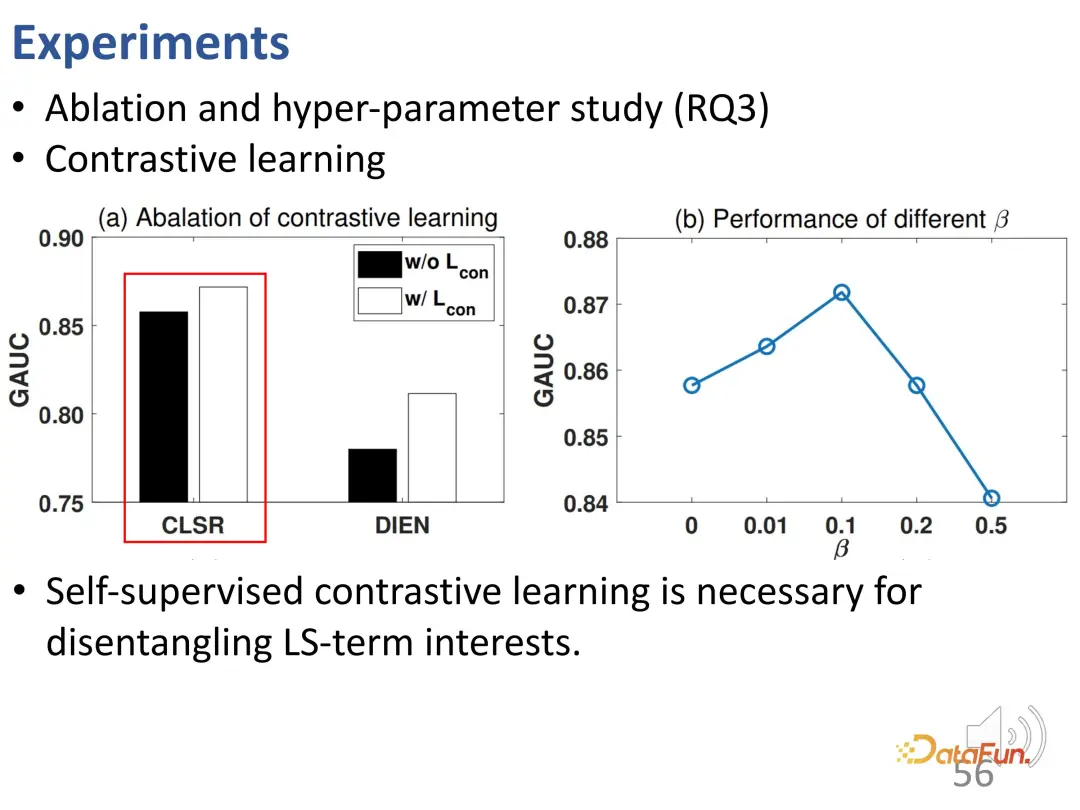
Eksperimen ablasi lanjut dan eksperimen hiperparameter telah dijalankan. Pertama, kehilangan fungsi pembelajaran kontrastif telah dialih keluar dan prestasi didapati menurun, menunjukkan bahawa pembelajaran kontrastif sangat diperlukan untuk merungkai minat jangka panjang dan minat jangka pendek. Percubaan ini seterusnya membuktikan bahawa CLSR ialah rangka kerja umum yang lebih baik kerana ia juga berfungsi di atas kaedah sedia ada (pembelajaran kontrastif penyeliaan kendiri boleh meningkatkan prestasi DIEN) dan merupakan kaedah pasang dan main. Penyelidikan ke atas β mendapati nilai yang munasabah ialah 0.1.
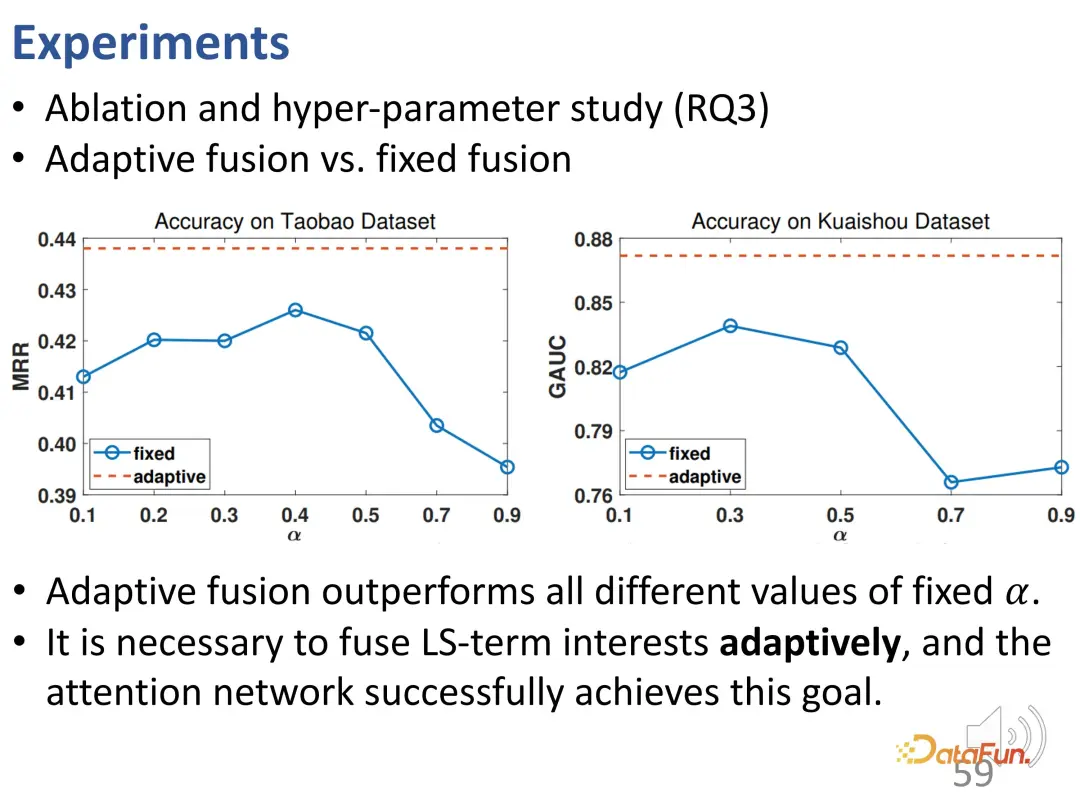
Seterusnya, kita akan mengkaji lebih lanjut hubungan antara pelakuran suaian dan pelakuran mudah. Pelaburan berat suai berprestasi stabil dan lebih baik daripada pelakuran berat tetap pada semua nilai α yang berbeza, yang mengesahkan bahawa setiap tingkah laku interaksi boleh ditentukan oleh pemberat saiz yang berbeza, dan mengesahkan bahawa pelakuran minat dicapai melalui pelakuran penyesuaian dan Keperluan untuk ramalan tingkah laku akhir.
Kerja ini mencadangkan kaedah pembelajaran kontrastif untuk memodelkan minat jangka panjang dan minat jangka pendek dalam minat jujukan, mempelajari vektor perwakilan yang sepadan masing-masing dan mencapai keterpisahan. Keputusan eksperimen menunjukkan keberkesanan kaedah ini. . Kerja ketiga memberi tumpuan kepada pembetulan tingkah laku pembelajaran minat.
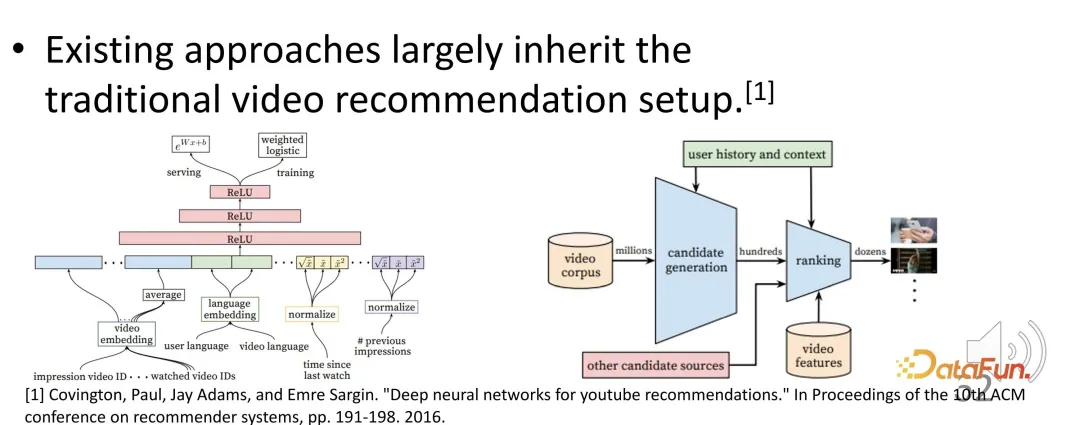
 Cadangan video pendek telah menjadi bahagian yang sangat penting dalam sistem pengesyoran. Walau bagaimanapun, sistem pengesyoran video pendek sedia ada masih mengikut paradigma pengesyoran video panjang sebelum ini, dan mungkin terdapat beberapa masalah.
Cadangan video pendek telah menjadi bahagian yang sangat penting dalam sistem pengesyoran. Walau bagaimanapun, sistem pengesyoran video pendek sedia ada masih mengikut paradigma pengesyoran video panjang sebelum ini, dan mungkin terdapat beberapa masalah.
Sebagai contoh, bagaimana untuk menilai kepuasan dan aktiviti pengguna dalam cadangan video pendek? Apakah matlamat pengoptimuman? Matlamat pengoptimuman biasa ialah masa menonton atau menonton kemajuan. Video pendek yang dianggarkan mempunyai kadar penyiapan yang lebih tinggi dan masa tontonan mungkin diberi kedudukan lebih tinggi oleh sistem pengesyoran. Ia mungkin dioptimumkan berdasarkan masa tontonan semasa latihan, dan diisih berdasarkan anggaran masa tontonan semasa perkhidmatan, dan video dengan masa tontonan yang lebih tinggi adalah disyorkan.
Walau bagaimanapun, masalah dalam cadangan video pendek ialah masa tontonan yang lebih lama tidak semestinya bermakna pengguna sangat berminat dengan video pendek tersebut, iaitu panjang video pendek itu sendiri adalah penyelewengan yang sangat penting. Dalam sistem pengesyoran yang menggunakan matlamat pengoptimuman di atas (masa tontonan atau kemajuan tontonan), video yang lebih panjang mempunyai kelebihan semula jadi. Mengesyorkan terlalu banyak video panjang seperti ini mungkin tidak sepadan dengan minat pengguna Walau bagaimanapun, disebabkan kos operasi pengguna yang melangkau video, penilaian yang diperoleh melalui ujian dalam talian atau latihan luar talian yang sebenar akan menjadi sangat tinggi. Oleh itu, bergantung pada masa menonton sahaja tidak mencukupi.
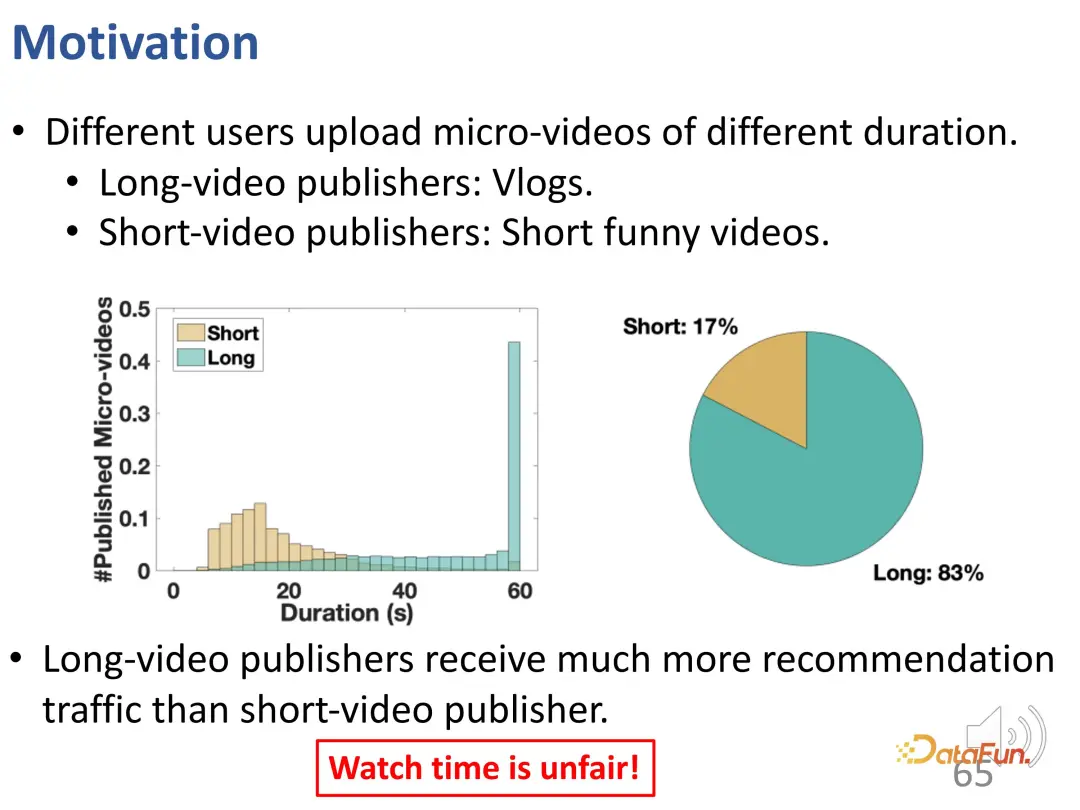
Seperti yang anda lihat, terdapat dua bentuk dalam video pendek. Satu adalah video yang lebih panjang seperti vlog, manakala satu lagi adalah video hiburan yang lebih pendek. Selepas menganalisis trafik sebenar, kami mendapati bahawa pengguna yang menerbitkan video panjang pada asasnya boleh mendapat lebih banyak trafik yang disyorkan, dan nisbah ini sangat berbeza. Menggunakan masa menonton sahaja untuk menilai bukan sahaja gagal memuaskan minat pengguna, tetapi mungkin juga tidak adil.
Dalam kerja ini, kami berharap dapat menyelesaikan dua masalah:
Bagaimana untuk menilai kepuasan pengguna dengan lebih baik tanpa berat sebelah. 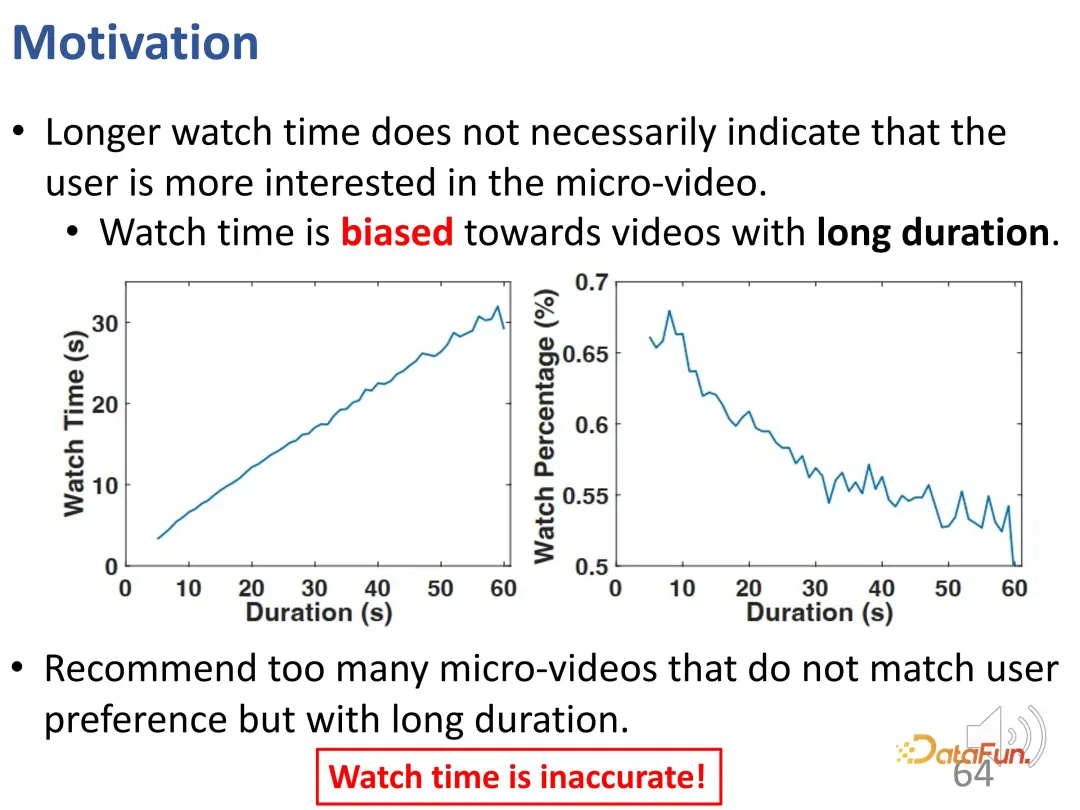
Cara mempelajari minat pengguna yang tidak berat sebelah ini untuk memberikan cadangan yang baik.
Malah, cabaran utama ialah video pendek yang berbeza panjang tidak boleh dibandingkan secara langsung. Memandangkan masalah ini adalah semula jadi dan terdapat di mana-mana dalam sistem pengesyor yang berbeza, dan struktur sistem pengesyor yang berbeza sangat berbeza, kaedah yang direka bentuk perlu model-agnostik.
- Pertama, beberapa kaedah perwakilan telah dipilih dan latihan simulasi dijalankan menggunakan tempoh tontonan.

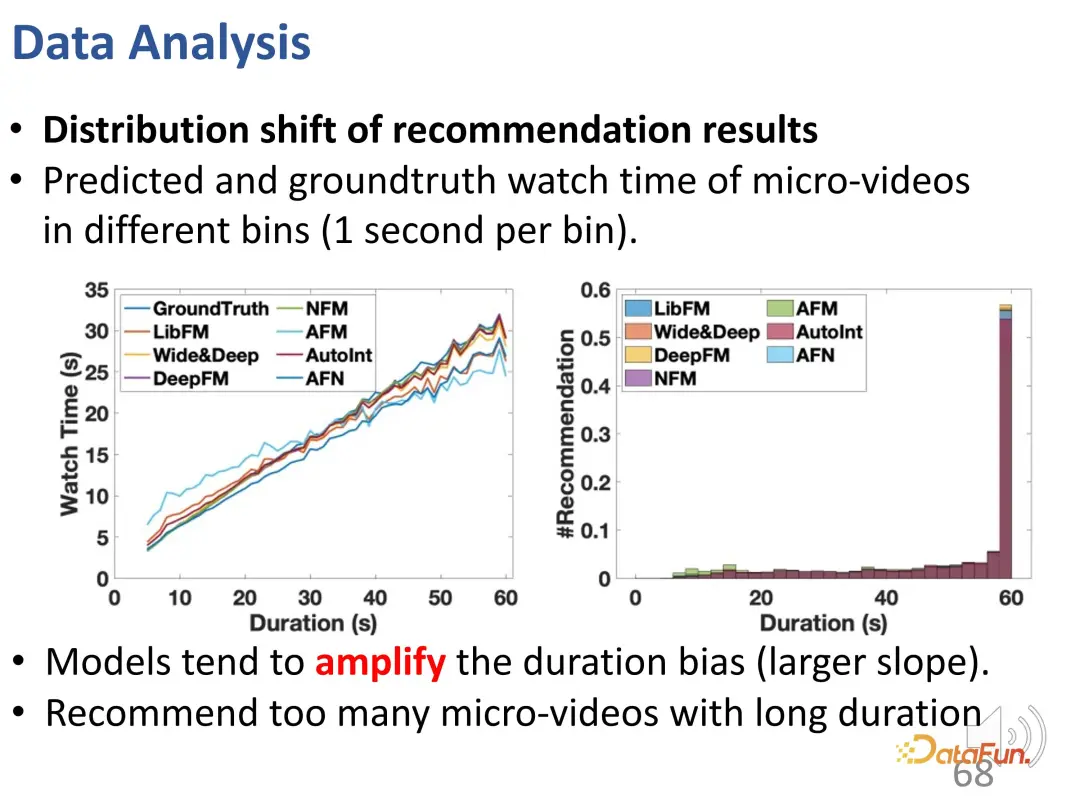
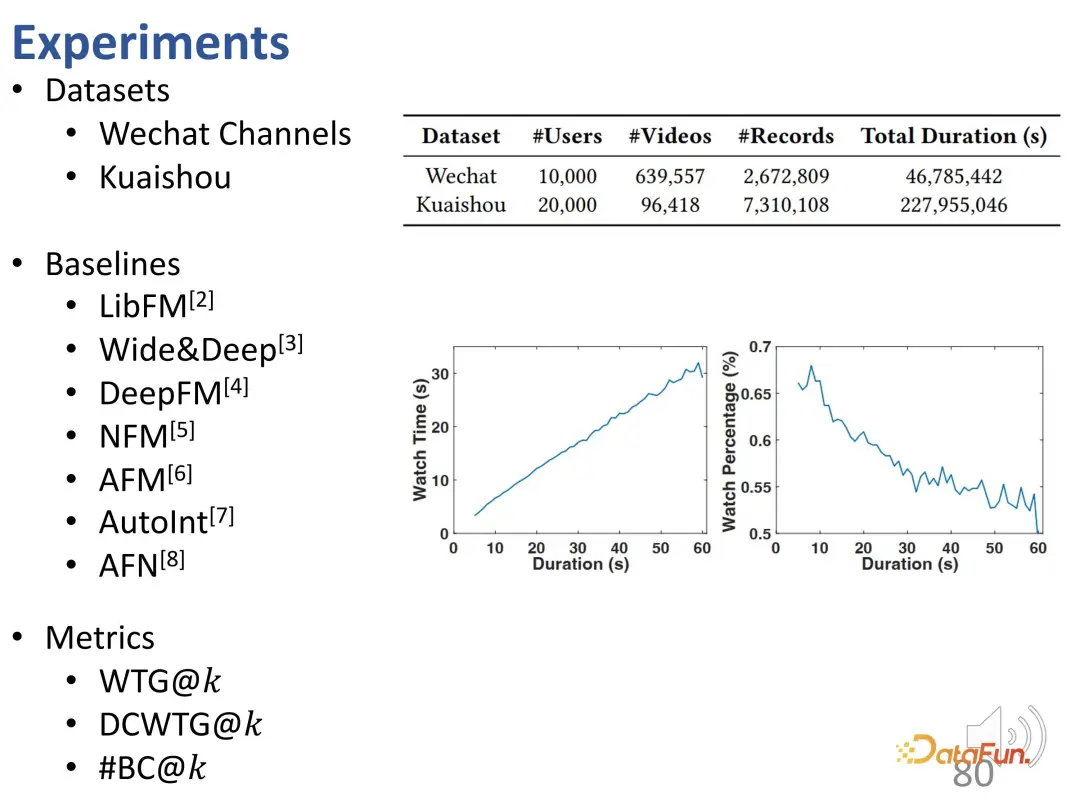
Anda boleh melihat daripada lengkung bahawa sisihan tempoh dipertingkatkan: berbanding dengan keluk kebenaran asas, model pengesyoran jauh lebih tinggi dalam keputusan ramalan masa tontonan video yang panjang. Dalam model ramalan, pengesyoran berlebihan untuk video panjang adalah bermasalah.
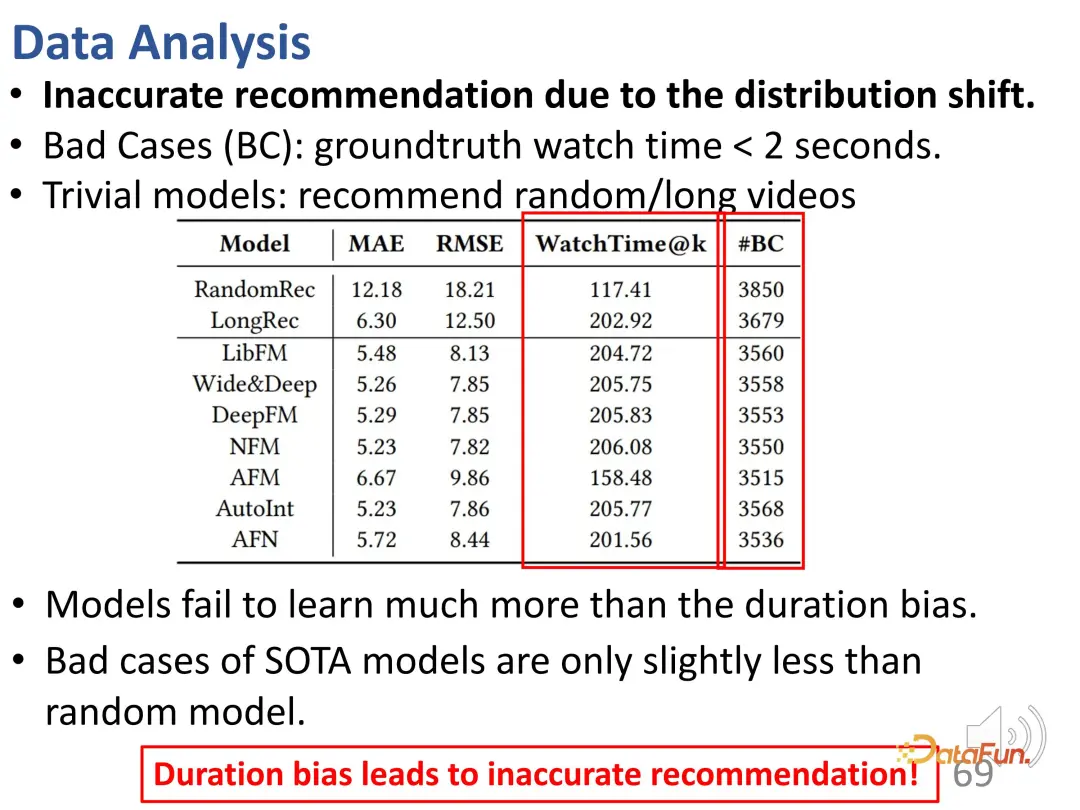
Selain itu, didapati juga terdapat banyak syor yang tidak tepat dalam keputusan syor (#BC).
Kita boleh lihat beberapa kes buruk iaitu video yang ditonton kurang dari 2 saat dan tidak disukai oleh pengguna. Walau bagaimanapun, disebabkan pengaruh berat sebelah, video ini dicadangkan secara salah. Dalam erti kata lain, model hanya mengetahui perbezaan dalam tempoh video yang disyorkan, dan pada asasnya hanya boleh membezakan panjang video. Kerana hasil ramalan yang diingini adalah mengesyorkan video yang lebih panjang untuk meningkatkan masa tontonan pengguna. Jadi model memilih video panjang dan bukannya video yang disukai pengguna. Dapat dilihat bahawa model ini malah mempunyai bilangan kes buruk yang sama dengan pengesyoran rawak, jadi berat sebelah ini membawa kepada pengesyoran yang sangat tidak tepat.
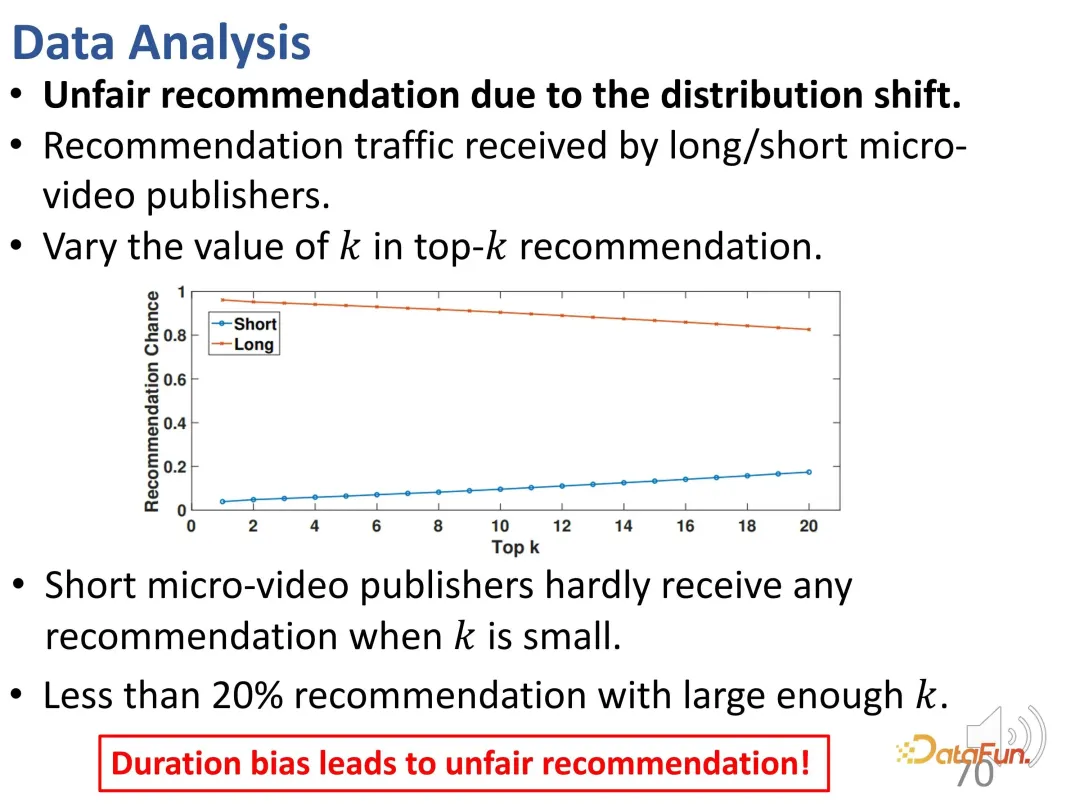
Tambahan pula, timbul isu ketidakadilan di sini. Apabila nilai k atas kawalan adalah kecil, penerbit video yang lebih pendek sukar untuk disyorkan walaupun nilai k cukup besar, perkadaran pengesyoran tersebut adalah kurang daripada 20%.
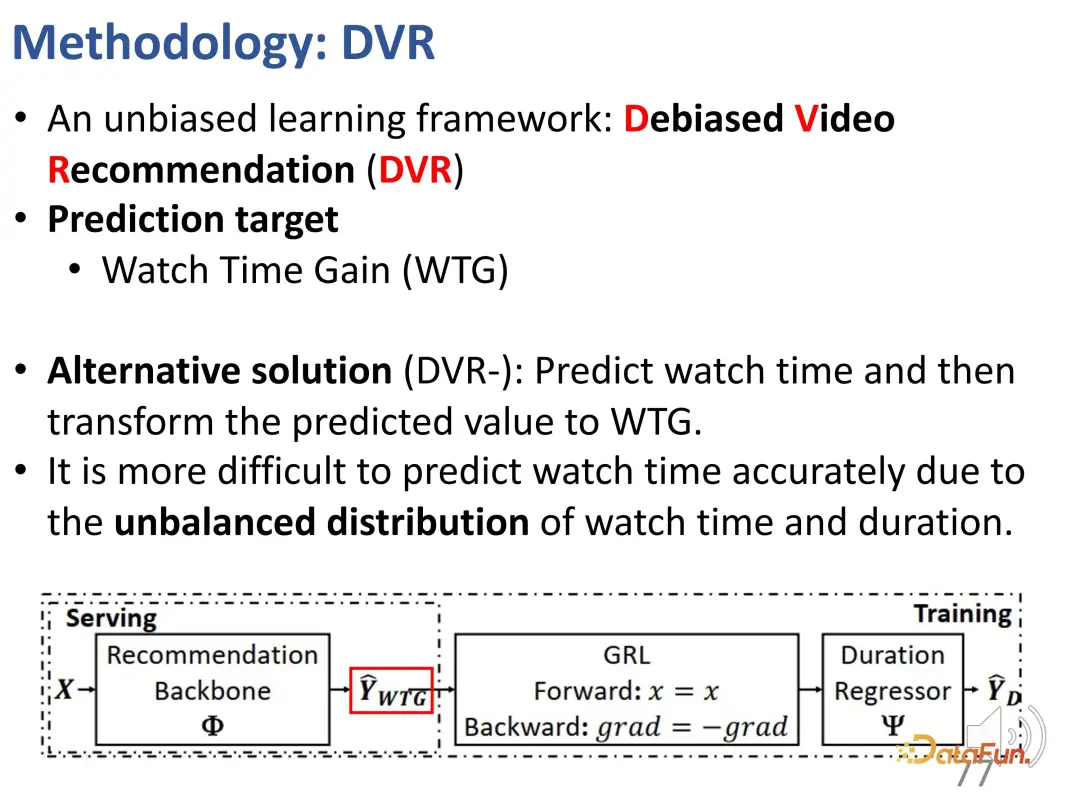
1. Penunjuk WTG
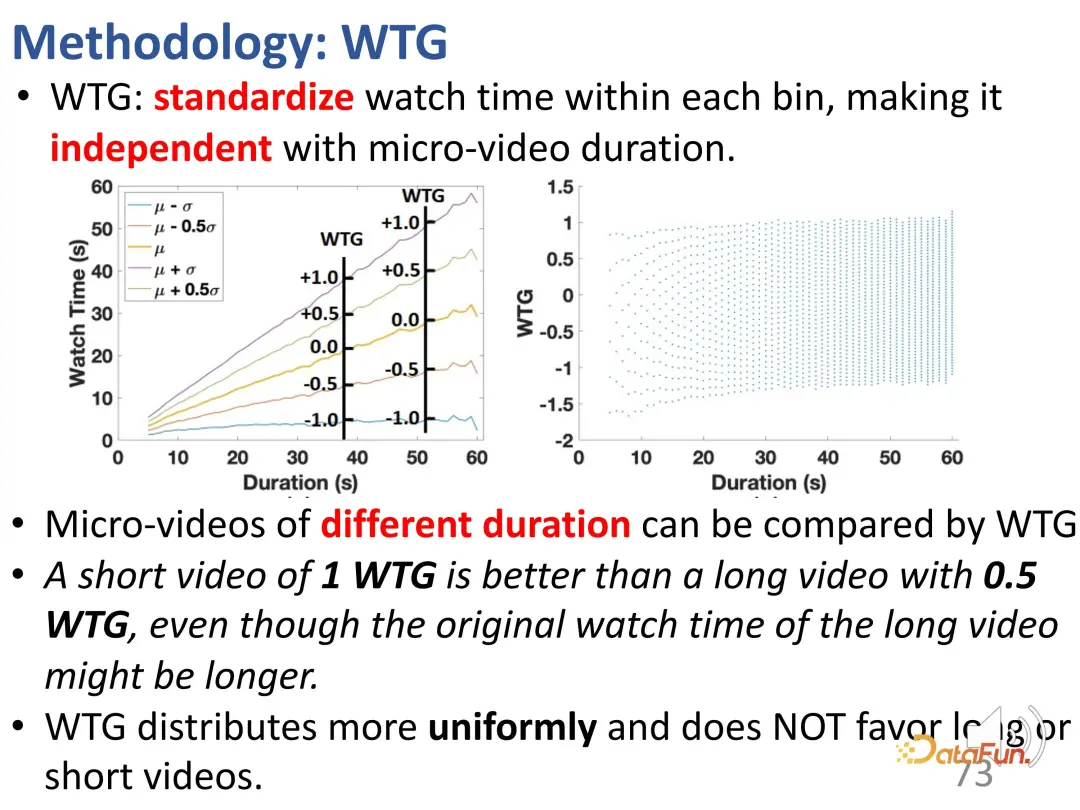
Untuk menyelesaikan masalah ini, kami mula-mula mencadangkan penunjuk baharu yang dipanggil WTG (Watch Time Gain), yang mengambil kira masa tontonan untuk cuba mencapai tanpa berat sebelah. Sebagai contoh, seorang pengguna menonton video 60 saat selama 50 saat; video lain juga berpanjangan 60 saat, tetapi hanya menonton selama 5 saat. Jelas sekali, jika anda mengawal untuk video 60 saat, perbezaan minat antara kedua-dua video adalah jelas. Ini adalah idea yang mudah tetapi berkesan Tempoh tontonan hanya bermakna apabila data video lain mempunyai tempoh yang sama.
Mula-mula bahagikan semua video kepada kumpulan tempoh yang berbeza pada selang masa yang sama, dan kemudian bandingkan intensiti minat pengguna dalam setiap kumpulan tempoh. Dalam kumpulan tempoh tetap, minat pengguna boleh diwakili oleh tempoh. Selepas pengenalan WTG, WTG sebenarnya digunakan secara langsung untuk menyatakan intensiti minat pengguna, tanpa menghiraukan tempoh asal. Di bawah penarafan WTG, pengedaran lebih sekata.
Berdasarkan WTG, kepentingan menyusun kedudukan dipertimbangkan lagi. Kerana WTG hanya mempertimbangkan satu penunjuk (satu titik), kesan kumulatif ini selanjutnya diambil kira. Iaitu, apabila mengira indeks setiap elemen dalam senarai yang diisih, kedudukan relatif setiap titik data juga mesti diambil kira. Idea ini serupa dengan NDCG. Oleh itu, atas dasar ini, DCWTG telah ditakrifkan.
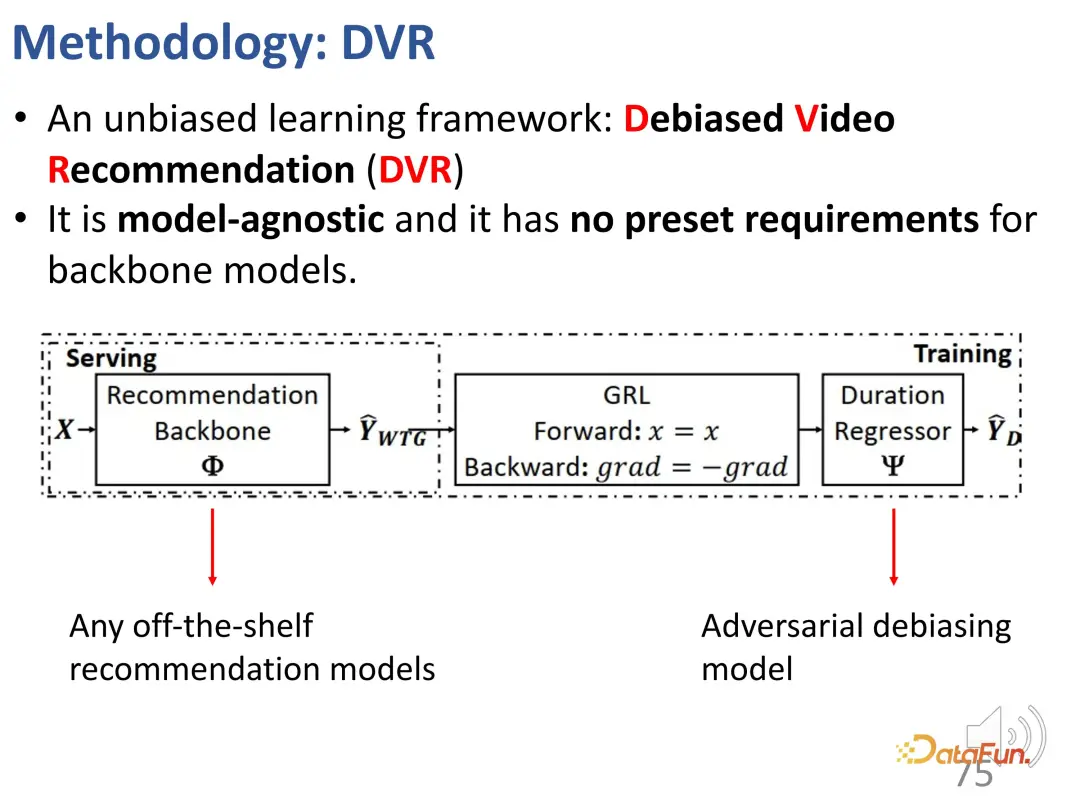
2. Kaedah yang disyorkan untuk menghapuskan berat sebelah
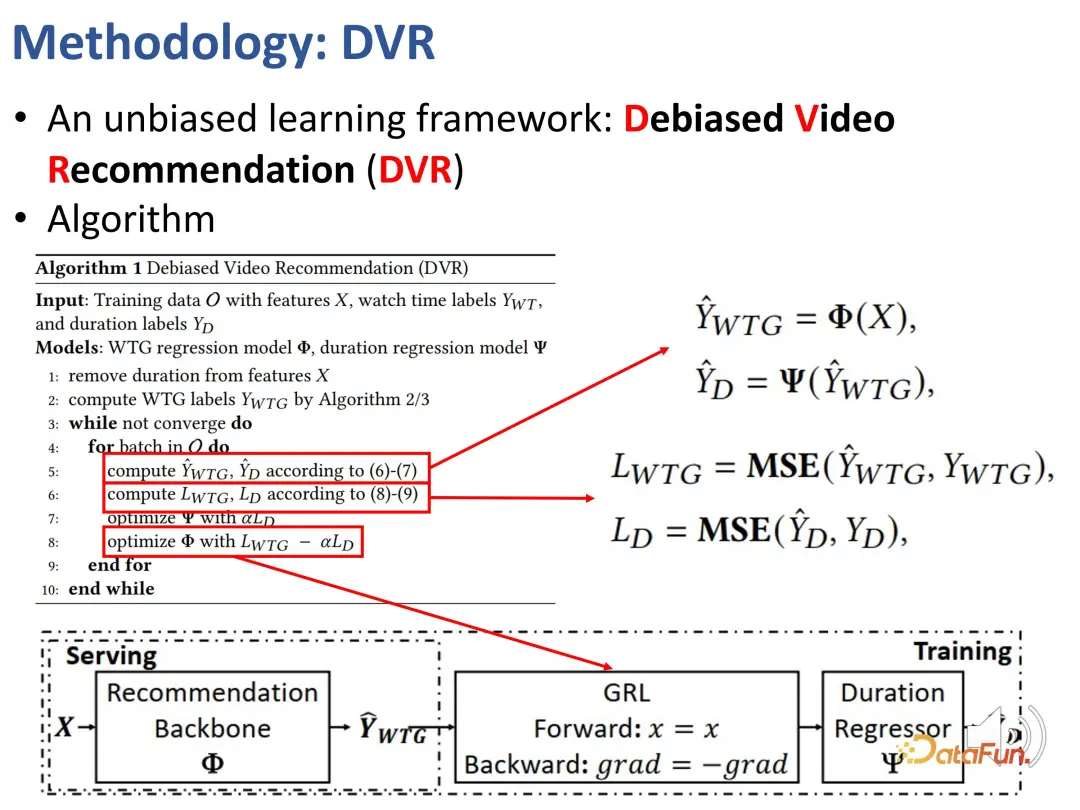
Kami sebelum ini menentukan penunjuk yang boleh mencerminkan minat pengguna tanpa mengira tempoh, iaitu WTG dan NDWTG. Seterusnya, reka kaedah pengesyoran yang boleh menghapuskan berat sebelah, bebas daripada model tertentu, dan boleh digunakan untuk tulang belakang yang berbeza. Kaedah DVR (Pengesyoran Video Debiased) dicadangkan Idea teras ialah dalam model pengesyoran, jika ciri yang berkaitan dengan tempoh boleh dialih keluar, walaupun ciri input adalah kompleks dan mungkin mengandungi maklumat berkaitan tempoh, selagi ia. boleh digunakan semasa proses pembelajaran Jika output model mengabaikan ciri tempoh ini, ia boleh dianggap sebagai tidak berat sebelah, yang bermaksud bahawa model boleh menapis ciri berkaitan tempoh untuk mencapai pengesyoran yang tidak berat sebelah. Ini melibatkan idea konfrontasi, yang memerlukan model lain untuk meramalkan tempoh berdasarkan output model pengesyoran Jika ia tidak dapat meramalkan dengan tepat tempoh, maka ia dianggap bahawa output model sebelumnya tidak mengandungi ciri tempoh. Oleh itu, kaedah pembelajaran adversarial digunakan untuk menambah lapisan regresi pada model pengesyoran, yang meramalkan tempoh asal berdasarkan WTG yang diramalkan. Jika model tulang belakang sememangnya boleh mencapai hasil yang tidak berat sebelah, maka lapisan regresi tidak akan dapat meramal semula dan memulihkan tempoh asal.
Di atas adalah butiran kaedah yang digunakan untuk melaksanakan pembelajaran menentang.
3. Keputusan eksperimen
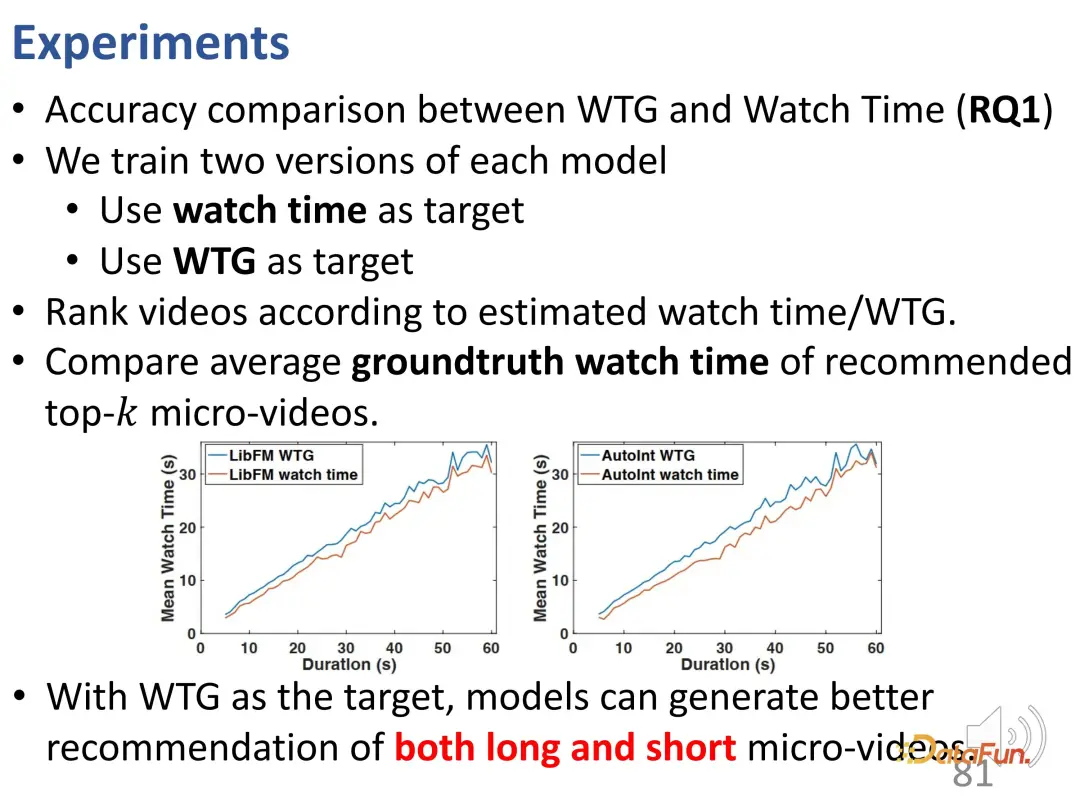
Percubaan dijalankan pada dua set data WeChat dan Kuaishou. Yang pertama ialah WTG berbanding masa tonton. Dapat dilihat bahawa kedua-dua objektif pengoptimuman digunakan secara berasingan dan dibandingkan dengan tempoh tontonan dalam kebenaran asas. Selepas menggunakan WTG sebagai sasaran, kesan pengesyoran model adalah lebih baik pada kedua-dua video pendek dan video panjang, dan keluk WTG terletak secara stabil di atas lengkung masa tontonan.
Di samping itu, menggunakan WTG sebagai sasaran membawa trafik cadangan yang lebih seimbang bagi video panjang dan pendek (bahagian cadangan video panjang jelas lebih kepada model tradisional).
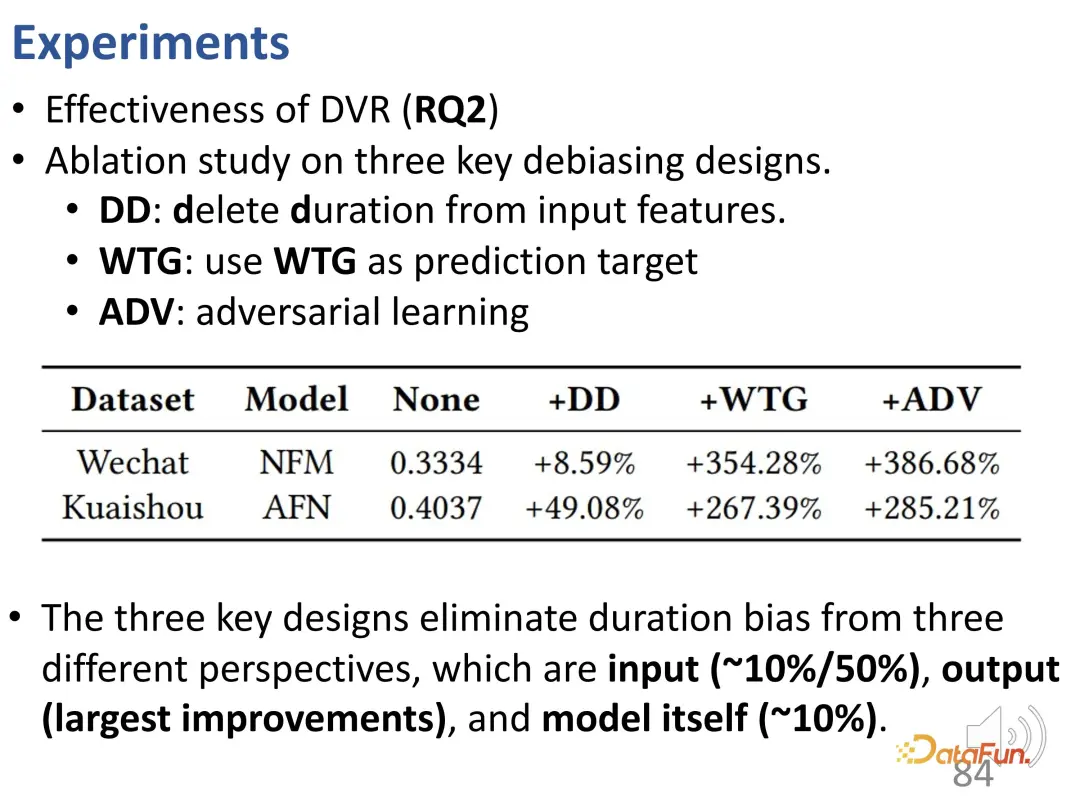
Kaedah DVR yang dicadangkan sesuai untuk model tulang belakang yang berbeza: 7 model tulang belakang biasa telah diuji, dan keputusan menunjukkan bahawa prestasi tanpa menggunakan kaedah debiasing adalah lemah, manakala DVR berprestasi baik pada semua model tulang belakang dan semua penunjuk telah ada peningkatan tertentu.
melakukan beberapa eksperimen ablasi selanjutnya. Seperti yang dinyatakan dalam artikel sebelumnya, kaedah ini mempunyai tiga bahagian reka bentuk, dan ketiga-tiga bahagian ini telah dialih keluar masing-masing. Yang pertama adalah untuk mengalih keluar tempoh sebagai ciri input, yang kedua adalah untuk mengalih keluar WTG sebagai sasaran ramalan, dan yang ketiga adalah untuk menghapuskan kaedah pembelajaran yang bertentangan. Anda dapat melihat bahawa mengalih keluar setiap bahagian akan membawa kepada kemerosotan prestasi. Oleh itu, ketiga-tiga reka bentuk adalah penting.
Untuk meringkaskan kerja kami: kaji cadangan video pendek dari perspektif mengurangkan sisihan dan perhatikan sisihan tempoh. Pertama, penunjuk baharu dicadangkan: WTG. Ia berfungsi dengan baik untuk menghapuskan berat sebelah dalam tingkah laku sebenar (minat dan tempoh pengguna). Kedua, kaedah umum dicadangkan supaya model tidak lagi dipengaruhi oleh tempoh video, dengan itu menghasilkan syor yang tidak berat sebelah.
Akhirnya ringkaskan perkongsian ini. Pertama, fahami pembelajaran jalinan tentang minat dan pematuhan pengguna. Seterusnya, keterpisahan kepentingan jangka panjang dan jangka pendek dikaji dari segi pemodelan tingkah laku berurutan. Akhir sekali, kaedah pembelajaran debiasing dicadangkan untuk menyelesaikan masalah pengoptimuman tempoh tontonan dalam cadangan video pendek.
Di atas adalah kandungan yang dikongsikan kali ini, terima kasih semua.
Sastera berkaitan:
[1] Gao et al. Inferens Penyebab dalam Sistem Pengesyor: Satu Tinjauan dan Hala Tuju Masa Depan, TOIS 2024
[2] Zheng et al , WWW 2021.
[3] Zheng et al .








Atas ialah kandungan terperinci Sistem pengesyor berdasarkan inferens sebab musabab: semakan dan prospek. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Cara melaksanakan sistem pengesyoran menggunakan bahasa Go dan Redis
Oct 27, 2023 pm 12:54 PM
Cara melaksanakan sistem pengesyoran menggunakan bahasa Go dan Redis
Oct 27, 2023 pm 12:54 PM
Cara menggunakan bahasa Go dan Redis untuk melaksanakan sistem pengesyoran Sistem pengesyoran merupakan bahagian penting platform Internet moden. Ia membantu pengguna menemui dan mendapatkan maklumat yang diminati. Bahasa Go dan Redis ialah dua alatan yang sangat popular yang boleh memainkan peranan penting dalam proses melaksanakan sistem pengesyoran. Artikel ini akan memperkenalkan cara menggunakan bahasa Go dan Redis untuk melaksanakan sistem pengesyoran mudah dan memberikan contoh kod khusus. Redis ialah pangkalan data dalam memori sumber terbuka yang menyediakan antara muka simpanan pasangan nilai kunci dan menyokong pelbagai data
 Algoritma dan aplikasi sistem pengesyoran dilaksanakan dalam Java
Jun 19, 2023 am 09:06 AM
Algoritma dan aplikasi sistem pengesyoran dilaksanakan dalam Java
Jun 19, 2023 am 09:06 AM
Dengan pembangunan berterusan dan mempopularkan teknologi Internet, sistem pengesyoran, sebagai teknologi penapisan maklumat yang penting, semakin digunakan dan diberi perhatian secara meluas. Dari segi pelaksanaan algoritma sistem pengesyoran, Java, sebagai bahasa pengaturcaraan yang pantas dan boleh dipercayai, telah digunakan secara meluas. Artikel ini akan memperkenalkan algoritma sistem pengesyoran dan aplikasi yang dilaksanakan dalam Java, dan menumpukan pada tiga algoritma sistem pengesyoran biasa: algoritma penapisan kolaboratif berasaskan pengguna, algoritma penapisan kolaboratif berasaskan item dan algoritma pengesyoran berasaskan kandungan. Algoritma penapisan kolaboratif berasaskan pengguna adalah berdasarkan penapisan kolaboratif berasaskan pengguna
 Contoh aplikasi: Gunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro
Jun 18, 2023 pm 12:43 PM
Contoh aplikasi: Gunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro
Jun 18, 2023 pm 12:43 PM
Dengan populariti aplikasi Internet, seni bina perkhidmatan mikro telah menjadi kaedah seni bina yang popular. Antaranya, kunci kepada seni bina perkhidmatan mikro adalah untuk memisahkan aplikasi kepada perkhidmatan yang berbeza dan berkomunikasi melalui RPC untuk mencapai seni bina perkhidmatan yang digandingkan secara longgar. Dalam artikel ini, kami akan memperkenalkan cara menggunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro berdasarkan kes sebenar. 1. Apakah sistem pengesyoran perkhidmatan mikro? Sistem pengesyoran perkhidmatan mikro ialah sistem pengesyoran berdasarkan seni bina perkhidmatan mikro Ia menyepadukan modul yang berbeza dalam sistem pengesyoran (seperti kejuruteraan ciri, pengelasan
 Rahsia Pengesyoran Tepat: Penjelasan Terperinci mengenai Model Pengingatan Tanpa Pinggir Adaptasi Domain Dipisahkan Alibaba
Jun 05, 2023 am 08:55 AM
Rahsia Pengesyoran Tepat: Penjelasan Terperinci mengenai Model Pengingatan Tanpa Pinggir Adaptasi Domain Dipisahkan Alibaba
Jun 05, 2023 am 08:55 AM
1. Pengenalan senario Mula-mula, mari kita perkenalkan senario yang terlibat dalam artikel ini—senario "barangan bagus tersedia". Lokasinya adalah dalam grid empat persegi pada laman utama Taobao, yang dibahagikan kepada halaman pemilihan satu lompatan dan halaman penerimaan dua lompatan. Terdapat dua bentuk utama halaman penerimaan, satu ialah halaman penerimaan imej dan teks, dan satu lagi ialah halaman penerimaan video pendek. Matlamat senario ini adalah terutamanya untuk menyediakan pengguna dengan barangan yang memuaskan dan memacu pertumbuhan GMV, seterusnya memanfaatkan bekalan pakar. 2. Apakah bias populariti, dan mengapa seterusnya kita masukkan fokus artikel ini, bias populariti. Apakah bias populariti? Mengapa bias populariti berlaku? 1. Apakah bias populariti? Bias populariti mempunyai banyak alias, seperti kesan Matthew dan ruang kepompong maklumat, ia adalah karnival produk letupan tinggi, lebih mudah ia didedahkan. Ini akan mengakibatkan
 Ringkasan idea teknikal utama dan kaedah inferens sebab musabab
Apr 12, 2023 am 08:10 AM
Ringkasan idea teknikal utama dan kaedah inferens sebab musabab
Apr 12, 2023 am 08:10 AM
Pengenalan: Inferens sebab merupakan cabang penting dalam sains data Ia memainkan peranan penting dalam lelaran produk, algoritma dan penilaian strategi insentif dalam Internet dan industri Ia menggabungkan data, eksperimen atau model ekonometrik untuk mengira kesan perubahan baharu faedah adalah asas untuk membuat keputusan. Walau bagaimanapun, inferens sebab-akibat bukanlah perkara yang mudah. Pertama sekali, dalam kehidupan seharian, orang sering mengelirukan korelasi dan sebab. Korelasi selalunya bermaksud bahawa dua pembolehubah mempunyai kecenderungan untuk meningkat atau menurun pada masa yang sama, tetapi sebab musabab bermaksud bahawa kita ingin tahu apa yang akan berlaku apabila kita menukar pembolehubah, atau kita menjangkakan untuk mendapatkan hasil kontrafaktual, jika kita melakukannya dalam masa lalu Jika kita mengambil tindakan yang berbeza, adakah akan ada perubahan pada masa hadapan? Kesukarannya, walau bagaimanapun, adalah selalunya data kontrafaktual
 Bagaimanakah bahasa Go melaksanakan sistem carian dan pengesyoran awan?
May 16, 2023 pm 11:21 PM
Bagaimanakah bahasa Go melaksanakan sistem carian dan pengesyoran awan?
May 16, 2023 pm 11:21 PM
Dengan pembangunan berterusan dan mempopularkan teknologi pengkomputeran awan, carian awan dan sistem pengesyoran menjadi semakin popular. Sebagai tindak balas kepada permintaan ini, bahasa Go juga menyediakan penyelesaian yang baik. Dalam bahasa Go, kami boleh menggunakan keupayaan pemprosesan serentak berkelajuan tinggi dan perpustakaan standard yang kaya untuk melaksanakan sistem carian dan pengesyoran awan yang cekap. Berikut akan memperkenalkan cara bahasa Go melaksanakan sistem sedemikian. 1. Cari di awan Pertama, kita perlu memahami postur dan prinsip carian. Postur carian merujuk kepada halaman padanan enjin carian berdasarkan kata kunci yang dimasukkan oleh pengguna.
 Sistem pengesyoran untuk teknologi permulaan sejuk NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
Sistem pengesyoran untuk teknologi permulaan sejuk NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
1. Latar belakang masalah: Keperluan dan kepentingan pemodelan permulaan sejuk Sebagai platform kandungan, Cloud Music mempunyai sejumlah besar kandungan baharu dalam talian setiap hari. Walaupun jumlah kandungan baharu pada platform muzik awan agak kecil berbanding dengan platform lain seperti video pendek, jumlah sebenar mungkin jauh melebihi imaginasi semua orang. Pada masa yang sama, kandungan muzik jauh berbeza daripada video pendek, berita dan cadangan produk. Kitaran hayat muzik menjangkau tempoh masa yang sangat lama, selalunya diukur dalam tahun. Sesetengah lagu mungkin meletup selepas tidak aktif selama berbulan-bulan atau bertahun-tahun, dan lagu-lagu klasik mungkin masih mempunyai daya hidup yang kuat walaupun selepas lebih daripada sepuluh tahun. Oleh itu, untuk sistem pengesyoran platform muzik, adalah lebih penting untuk menemui kandungan berkualiti tinggi yang tidak popular dan berekor panjang dan mengesyorkannya kepada pengguna yang betul daripada mengesyorkan kategori lain.
 Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Jan 13, 2024 pm 12:15 PM
Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Jan 13, 2024 pm 12:15 PM
1. Latar belakang pembetulan sebab dan akibat 1. Penyelewengan berlaku dalam sistem pengesyoran Model pengesyoran dilatih dengan mengumpul data untuk mengesyorkan item yang sesuai kepada pengguna. Apabila pengguna berinteraksi dengan item yang disyorkan, data yang dikumpul digunakan untuk terus melatih model, membentuk gelung tertutup. Walau bagaimanapun, mungkin terdapat pelbagai faktor yang mempengaruhi dalam gelung tertutup ini, mengakibatkan ralat. Sebab utama ralat ialah kebanyakan data yang digunakan untuk melatih model adalah data pemerhatian dan bukannya data latihan yang ideal, yang dipengaruhi oleh faktor seperti strategi pendedahan dan pemilihan pengguna. Intipati berat sebelah ini terletak pada perbezaan antara jangkaan anggaran risiko empirikal dan jangkaan anggaran risiko ideal sebenar. 2. Kecondongan biasa Terdapat tiga jenis utama bias biasa dalam sistem pemasaran pengesyoran: Kecondongan selektif: Ini disebabkan oleh akar pengguna
