

Fahami Tokenisasi dalam satu artikel!

Model bahasa menaakul tentang teks, yang biasanya dalam bentuk rentetan, tetapi input kepada model hanya boleh menjadi nombor, jadi teks perlu ditukar kepada bentuk berangka.
Tokenisasi ialah tugas asas pemprosesan bahasa semula jadi Ia boleh membahagikan urutan teks berterusan (seperti ayat, perenggan, dll.) ke dalam urutan aksara (seperti perkataan, frasa, aksara, tanda baca, dll.) mengikut tertentu. keperluan. Antaranya Unit itu dipanggil token atau perkataan.
Mengikut proses khusus yang ditunjukkan dalam rajah di bawah, mula-mula bahagikan ayat teks kepada unit, kemudian digitalkan elemen tunggal (petakannya ke dalam vektor), kemudian masukkan vektor ini ke dalam model untuk pengekodan, dan akhirnya keluarkannya ke tugas hiliran untuk mendapatkan lagi keputusan akhir.
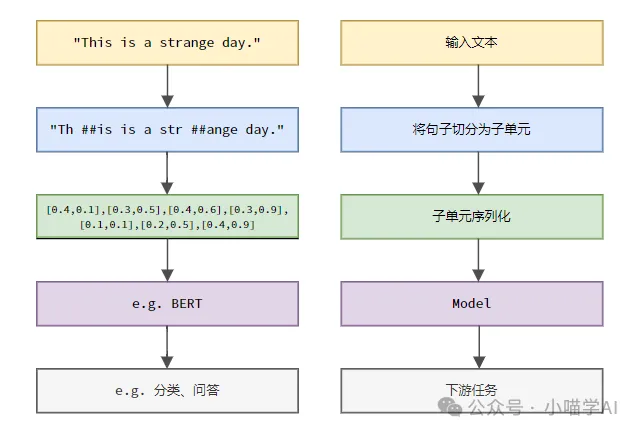
Segmentasi teks
Mengikut butiran segmentasi teks, Tokenisasi boleh dibahagikan kepada tiga kategori: Tokenisasi berbutir perkataan, Tokenisasi berbutir aksara dan Tokenisasi berbutir subkata.
1. Tokenisasi kebutiran perkataan
Tokenisasi kebutiran perkataan ialah kaedah pembahagian perkataan yang paling intuitif, yang bermaksud membahagikan teks mengikut perbendaharaan kata. Contohnya:
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
Dalam contoh ini, teks dibahagikan kepada perkataan bebas, setiap perkataan digunakan sebagai token, dan tanda baca '.' juga dianggap sebagai token bebas.
Teks bahasa Cina biasanya dibahagikan mengikut koleksi perbendaharaan kata standard yang disertakan dalam kamus atau frasa, simpulan bahasa, kata nama khas, dsb. yang dikenali melalui algoritma segmentasi perkataan.
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
Teks bahasa Cina ini terbahagi kepada lima perkataan: "Saya", "suka", "makan", "epal" dan titik ".", setiap perkataan berfungsi sebagai tanda.
2. Tokenisasi berbutir aksara
Tokenisasi berbutir aksara membahagikan teks kepada unit aksara terkecil, iaitu, setiap aksara dianggap sebagai token yang berasingan. Contohnya:
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
Tokenisasi kebutiran aksara dalam bahasa Cina adalah untuk membahagikan teks mengikut setiap aksara Cina bebas.
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
3.Tokenisasi berbutir subkata
Tokenisasi berbutir subkata ialah antara kebutiran perkataan dan kebutiran aksara Ia membahagikan teks kepada subkata (subkata) antara perkataan dan aksara sebagai token. Kaedah Tokenisasi subkata biasa termasuk Pengekodan Pasangan Byte (BPE), WordPiece, dsb. Kaedah ini menjana kamus pembahagian perkataan secara automatik dengan mengira frekuensi subrentetan dalam data teks, yang boleh menangani masalah perkataan di luar perkhidmatan (OOV) dengan berkesan sambil mengekalkan integriti semantik tertentu.
helloworld
Andaikan bahawa selepas latihan dengan algoritma BPE, kamus subkata yang dijana mengandungi entri berikut:
h, e, l, o, w, r, d, hel, low, wor, orld
Kebutiran kata kunci Keputusan Tokenized:
['hel', 'low', 'orld']
HelloHello" hel", "rendah", "orld", ini semua gabungan subrentetan frekuensi tinggi yang muncul dalam kamus. Kaedah pembahagian ini bukan sahaja boleh mengendalikan perkataan yang tidak diketahui (contohnya, "helloworld" bukan perkataan Inggeris standard), tetapi juga mengekalkan maklumat semantik tertentu (gabungan sub-perkataan boleh memulihkan perkataan asal).
Dalam bahasa Cina, Tokenisasi berbutir subkata juga membahagikan teks kepada subkata antara aksara Cina dan perkataan sebagai token. Contohnya:
我喜欢吃苹果
Andaikan selepas latihan dengan algoritma BPE, kamus subkata yang dijana mengandungi entri berikut:
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
Kebutiran kata kunci Keputusan Token:
['我', '喜欢', '吃', '苹果']
vocabulary = {'我': 0,'喜欢': 1,'吃': 2,'苹果': 3,'。': 4}indexed_tokens = [vocabulary[token] for token in token_sequence]print(indexed_tokens)
Atas ialah kandungan terperinci Fahami Tokenisasi dalam satu artikel!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Navicat menyambung ke kod ralat dan penyelesaian pangkalan data
Apr 08, 2025 pm 11:06 PM
Navicat menyambung ke kod ralat dan penyelesaian pangkalan data
Apr 08, 2025 pm 11:06 PM
Kesilapan dan penyelesaian yang biasa apabila menyambung ke pangkalan data: Nama pengguna atau kata laluan (ralat 1045) Sambungan blok firewall (ralat 2003) Timeout sambungan (ralat 10060)
 Cara Menulis Tutorial Terkini Mengenai Pernyataan Sisipan SQL
Apr 09, 2025 pm 01:48 PM
Cara Menulis Tutorial Terkini Mengenai Pernyataan Sisipan SQL
Apr 09, 2025 pm 01:48 PM
Pernyataan sisipan SQL digunakan untuk menambah baris baru ke jadual pangkalan data, dan sintaksinya ialah: masukkan ke dalam table_name (column1, column2, ..., columnn) nilai (value1, value2, ..., valuen);. Kenyataan ini menyokong memasukkan pelbagai nilai dan membolehkan nilai null dimasukkan ke dalam lajur, tetapi perlu untuk memastikan bahawa nilai yang dimasukkan bersesuaian dengan jenis data lajur untuk mengelakkan melanggar kekangan keunikan.
 Cara menambah lajur baru dalam SQL
Apr 09, 2025 pm 02:09 PM
Cara menambah lajur baru dalam SQL
Apr 09, 2025 pm 02:09 PM
Tambah lajur baru ke jadual yang sedia ada dalam SQL dengan menggunakan pernyataan Alter Table. Langkah -langkah khusus termasuk: Menentukan nama jadual dan maklumat lajur, menulis pernyataan Alter Jadual, dan melaksanakan pernyataan. Sebagai contoh, tambahkan lajur e -mel ke Jadual Pelanggan (Varchar (50)): Alter Jadual Pelanggan Tambah Varchar E -mel (50);
 Apakah sintaks untuk menambah lajur dalam SQL
Apr 09, 2025 pm 02:51 PM
Apakah sintaks untuk menambah lajur dalam SQL
Apr 09, 2025 pm 02:51 PM
Sintaks untuk menambah lajur dalam sql adalah alter table table_name tambah column_name data_type [not null] [default default_value]; Di mana table_name adalah nama jadual, column_name adalah nama lajur baru, data_type adalah jenis data, tidak null menentukan sama ada nilai null dibenarkan, dan lalai default_value menentukan nilai lalai.
 Adakah sintaks menambah lajur dalam sistem pangkalan data yang berbeza sama?
Apr 09, 2025 pm 12:51 PM
Adakah sintaks menambah lajur dalam sistem pangkalan data yang berbeza sama?
Apr 09, 2025 pm 12:51 PM
Sintaks untuk menambah lajur dalam sistem pangkalan data yang berbeza sangat berbeza, dan berbeza dari pangkalan data ke pangkalan data. Sebagai contoh: MySQL: Pengguna Table ALTER Tambahkan Varchar E -mel Lajur (255); PostgreSQL: Pengguna Table Alter Tambahkan Varchar E -mel Lajur (255) Tidak Null Unik; Oracle: Pengguna Jadual Tambah E -mel Varchar2 (255); SQL Server: Pengguna Jadual Tambah Varch E -mel
 Cara menetapkan nilai lalai semasa menambahkan lajur dalam sql
Apr 09, 2025 pm 02:45 PM
Cara menetapkan nilai lalai semasa menambahkan lajur dalam sql
Apr 09, 2025 pm 02:45 PM
Tetapkan nilai lalai untuk lajur yang baru ditambahkan, gunakan pernyataan ALTER Jadual: Tentukan Menambah Lajur dan Tetapkan Nilai Lalai: Alter Table Table_Name Tambah Column_Name Data_Type Default Default_Value; Gunakan klausa kekangan untuk menentukan nilai lalai: alter table Table_name Tambah lajur Column_name data_type kekangan default_constraint default_value;
 Jadual Jelas SQL: Petua Pengoptimuman Prestasi
Apr 09, 2025 pm 02:54 PM
Jadual Jelas SQL: Petua Pengoptimuman Prestasi
Apr 09, 2025 pm 02:54 PM
Petua untuk Meningkatkan Prestasi Pembersihan Jadual SQL: Gunakan jadual Truncate dan bukannya memadam, membebaskan ruang dan menetapkan semula lajur Identiti. Lumpuhkan kekangan utama asing untuk mengelakkan penghapusan cascading. Gunakan operasi enkapsulasi transaksi untuk memastikan konsistensi data. Batch memadam data besar dan hadkan bilangan baris melalui had. Membina semula indeks selepas membersihkan untuk meningkatkan kecekapan pertanyaan.
 SQL Classic 50 Soalan Jawapan
Apr 09, 2025 pm 01:33 PM
SQL Classic 50 Soalan Jawapan
Apr 09, 2025 pm 01:33 PM
SQL (bahasa pertanyaan berstruktur) adalah bahasa pengaturcaraan yang digunakan untuk membuat, mengurus, dan memohon pangkalan data. Fungsi utama termasuk: mewujudkan pangkalan data dan jadual, memasukkan, mengemaskini dan memadam data, menyusun dan menapis hasil, agregat fungsi, menyertai jadual, subqueries, pengendali, fungsi, kata kunci, manipulasi/definisi/bahasa kawalan,
