
 Peranti teknologi
AI
Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!
Peranti teknologi
AI
Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!
Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!

Ollama ialah alat super praktikal yang membolehkan anda menjalankan model sumber terbuka dengan mudah seperti Llama 2, Mistral dan Gemma secara tempatan. Dalam artikel ini, saya akan memperkenalkan cara menggunakan Ollama untuk mengvektorkan teks. Jika anda tidak memasang Ollama secara tempatan, anda boleh membaca artikel ini.
Dalam artikel ini kita akan menggunakan model nomic-embed-text[2]. Ia ialah pengekod teks yang mengatasi prestasi OpenAI text-embedding-ada-002 dan text-embedding-3-small pada konteks pendek dan tugas konteks panjang.
Mulakan perkhidmatan nomic-embed-text
Selepas anda berjaya memasang ollama, gunakan arahan berikut untuk menarik model nomic-embed-text:
ollama pull nomic-embed-text
Selepas berjaya menarik model, masukkan arahan berikut dalam terminal , mulakan perkhidmatan ollama:
ollama serve
Selepas itu, kami boleh menggunakan curl untuk mengesahkan sama ada perkhidmatan benam berjalan seperti biasa:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'Gunakan perkhidmatan nomic-embed-text
Seterusnya, kami akan memperkenalkan bagaimana untuk menggunakan perkhidmatan langchainjs dan nomic -embed-text, yang melaksanakan operasi pembenaman pada dokumen txt tempatan. Proses yang sepadan ditunjukkan dalam rajah di bawah:
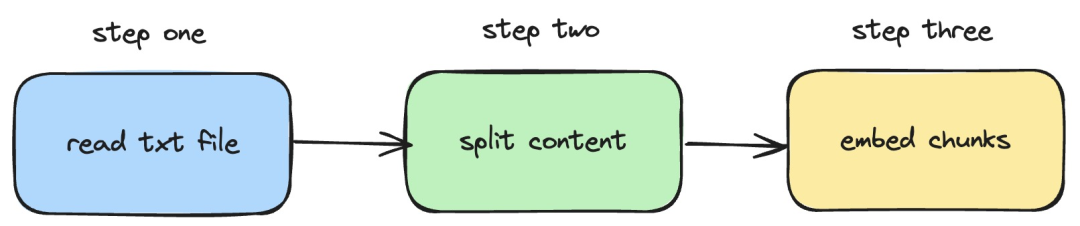 Pictures
Pictures
1 Baca fail txt setempat
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}Dalam kod di atas, kami menentukan fungsi muat, yang secara dalaman menggunakan TextLoader yang disediakan oleh langchainjs. baca Dapatkan dokumen txt tempatan.
2. Pisahkan kandungan txt kepada blok teks
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}Dalam kod di atas, kami menggunakan RecursiveCharacterTextSplitter untuk memotong teks txt yang dibaca dan menetapkan saiz setiap blok teks kepada 500.
3. Laksanakan operasi pembenaman pada blok teks
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}Dalam kod di atas, kami mentakrifkan fungsi pembenaman, di mana fungsi beban dan pembahagi yang ditakrifkan sebelum ini akan dipanggil. Kemudian rentasi blok teks yang dijana dan panggil perkhidmatan pembenaman nomic-embed-text yang dimulakan secara tempatan. Fungsi sendRequest digunakan untuk menghantar permintaan pembenaman Kod pelaksanaannya sangat mudah, iaitu menggunakan API fetch untuk memanggil API REST sedia ada.
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}Seterusnya, kami terus mentakrifkan fungsi embedTxtFile, terus memanggil fungsi pembenaman sedia ada di dalam fungsi dan menambah pengendalian pengecualian yang sepadan.
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")Akhir sekali, kami menggunakan perintah npx esno src/index.ts untuk melaksanakan fail ts setempat dengan cepat. Jika kod dalam index.ts berjaya dilaksanakan, keputusan berikut akan dikeluarkan dalam terminal:
 Pictures
Pictures
Malah, selain menggunakan kaedah di atas, kita juga boleh terus menggunakan [OllamaEmbeddings dalam @ modul langchain/komuniti ](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings"), yang secara dalaman merangkum logik untuk memanggil perkhidmatan pembenaman ollama:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);Kandungan yang diperkenalkan dalam artikel ini melibatkan pembangunan sistem RAG , proses mewujudkan indeks kandungan asas pengetahuan. Jika anda tidak tahu tentang sistem RAG, anda boleh membaca artikel berkaitan.
Rujukan
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/library/nomic-embed-text
Atas ialah kandungan terperinci Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1389
1389
 52
52

 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Perbandingan prestasi rangka kerja Java yang berbeza
Jun 05, 2024 pm 07:14 PM
Perbandingan prestasi rangka kerja Java yang berbeza
Jun 05, 2024 pm 07:14 PM
Perbandingan prestasi rangka kerja Java yang berbeza: Pemprosesan permintaan REST API: Vert.x adalah yang terbaik, dengan kadar permintaan 2 kali SpringBoot dan 3 kali Dropwizard. Pertanyaan pangkalan data: HibernateORM SpringBoot adalah lebih baik daripada Vert.x dan ORM Dropwizard. Operasi caching: Pelanggan Hazelcast Vert.x lebih unggul daripada mekanisme caching SpringBoot dan Dropwizard. Rangka kerja yang sesuai: Pilih mengikut keperluan aplikasi Vert.x sesuai untuk perkhidmatan web berprestasi tinggi, SpringBoot sesuai untuk aplikasi intensif data, dan Dropwizard sesuai untuk seni bina perkhidmatan mikro.
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
 Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Siri penanda aras YOLO sistem pengesanan sasaran sekali lagi menerima peningkatan besar. Sejak pengeluaran YOLOv9 pada Februari tahun ini, baton siri YOLO (YouOnlyLookOnce) telah diserahkan kepada penyelidik di Universiti Tsinghua. Hujung minggu lalu, berita pelancaran YOLOv10 menarik perhatian komuniti AI. Ia dianggap sebagai rangka kerja terobosan dalam bidang penglihatan komputer dan terkenal dengan keupayaan pengesanan objek hujung ke hujung masa nyata, meneruskan legasi siri YOLO dengan menyediakan penyelesaian berkuasa yang menggabungkan kecekapan dan ketepatan. Alamat kertas: https://arxiv.org/pdf/2405.14458 Alamat projek: https://github.com/THU-MIG/yo
 Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Pada bulan Februari tahun ini, Google melancarkan model besar berbilang modal Gemini 1.5, yang telah meningkatkan prestasi dan kelajuan dengan sangat baik melalui pengoptimuman kejuruteraan dan infrastruktur, seni bina MoE dan strategi lain. Dengan konteks yang lebih panjang, keupayaan penaakulan yang lebih kukuh dan pengendalian kandungan merentas modal yang lebih baik. Jumaat ini, Google DeepMind secara rasmi mengeluarkan laporan teknikal Gemini 1.5, yang merangkumi versi Flash dan peningkatan terkini yang lain Dokumen itu sepanjang 153 halaman. Pautan laporan teknikal: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf Dalam laporan ini, Google memperkenalkan Gemini1
 Bagaimana untuk mengoptimumkan prestasi program berbilang benang dalam C++?
Jun 05, 2024 pm 02:04 PM
Bagaimana untuk mengoptimumkan prestasi program berbilang benang dalam C++?
Jun 05, 2024 pm 02:04 PM
Teknik berkesan untuk mengoptimumkan prestasi berbilang benang C++ termasuk mengehadkan bilangan utas untuk mengelakkan perbalahan sumber. Gunakan kunci mutex ringan untuk mengurangkan perbalahan. Optimumkan skop kunci dan minimumkan masa menunggu. Gunakan struktur data tanpa kunci untuk menambah baik keselarasan. Elakkan sibuk menunggu dan maklumkan urutan ketersediaan sumber melalui acara.
 ChatGPT kini tersedia untuk macOS dengan keluaran apl khusus
Jun 27, 2024 am 10:05 AM
ChatGPT kini tersedia untuk macOS dengan keluaran apl khusus
Jun 27, 2024 am 10:05 AM
Aplikasi ChatGPT Mac Buka AI kini tersedia untuk semua orang, telah dihadkan kepada mereka yang mempunyai langganan ChatGPT Plus sahaja untuk beberapa bulan lepas. Apl ini dipasang sama seperti mana-mana apl Mac asli yang lain, selagi anda mempunyai Apple S yang terkini
