
 Peranti teknologi
AI
DeepMind menaik taraf Transformer, FLOP hantaran hadapan boleh dikurangkan sehingga separuh
Peranti teknologi
AI
DeepMind menaik taraf Transformer, FLOP hantaran hadapan boleh dikurangkan sehingga separuh
DeepMind menaik taraf Transformer, FLOP hantaran hadapan boleh dikurangkan sehingga separuh

Memperkenalkan kedalaman hibrid, reka bentuk baharu DeepMind boleh meningkatkan kecekapan Transformer.
. tentang Ini menjimatkan pengiraan yang tidak perlu.



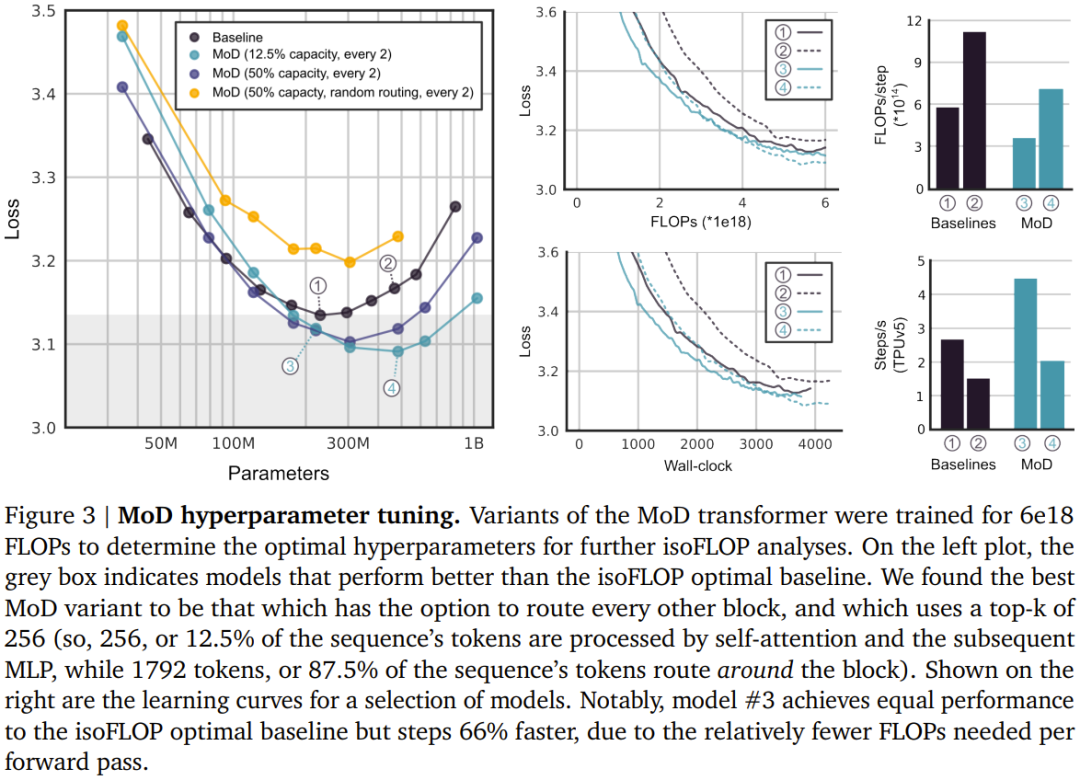
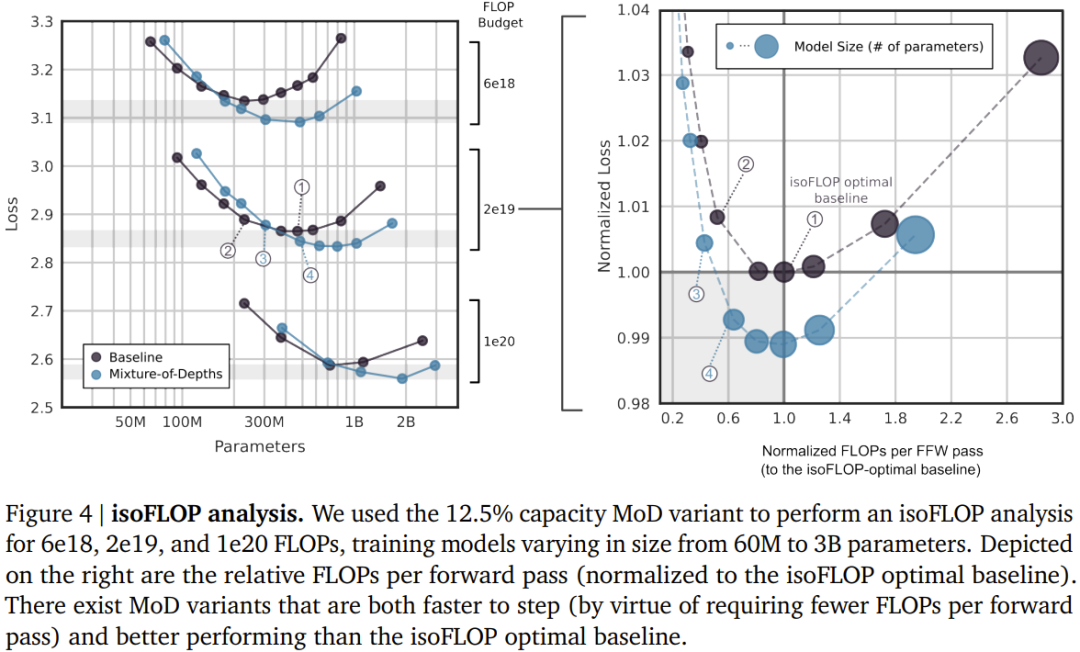
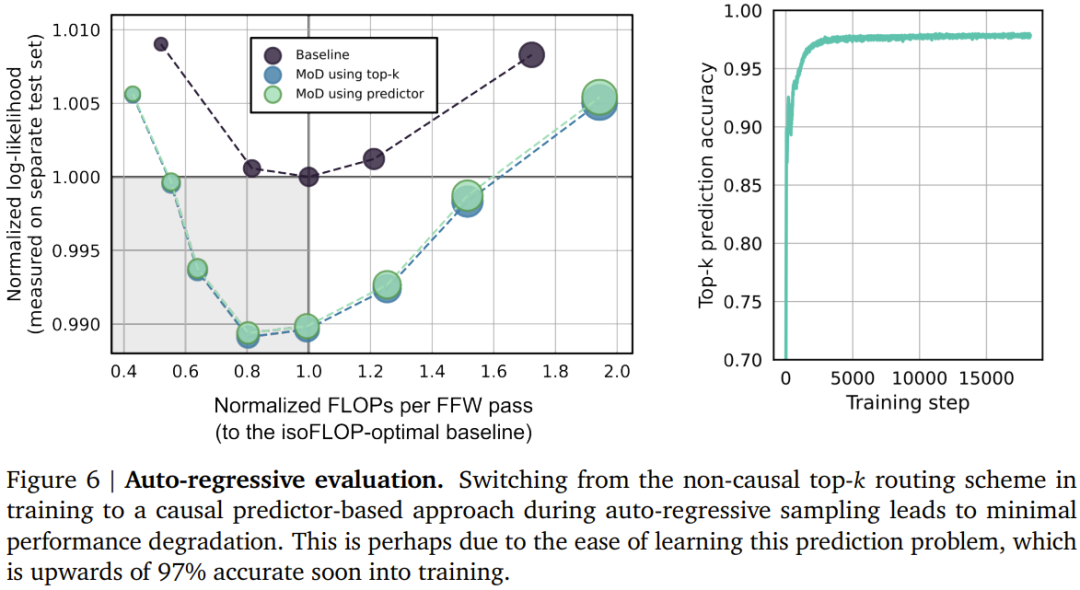
- Mereka membayangkan: Dalam setiap lapisan, rangkaian mesti belajar membuat keputusan untuk setiap token, dengan itu memperuntukkan belanjawan pengkomputeran yang tersedia secara dinamik. Dalam pelaksanaan khusus mereka, jumlah usaha pengiraan ditetapkan oleh pengguna sebelum latihan dan tidak pernah berubah, dan bukannya menjadi fungsi keputusan pelaksanaan rangkaian semasa ia berfungsi. Ini membolehkan keuntungan kecekapan perkakasan (seperti pengurangan jejak memori atau pengurangan FLOP setiap hantaran hadapan) dijangka dan dieksploitasi lebih awal. Eksperimen pasukan menunjukkan bahawa keuntungan ini boleh dicapai tanpa menjejaskan prestasi rangkaian keseluruhan.
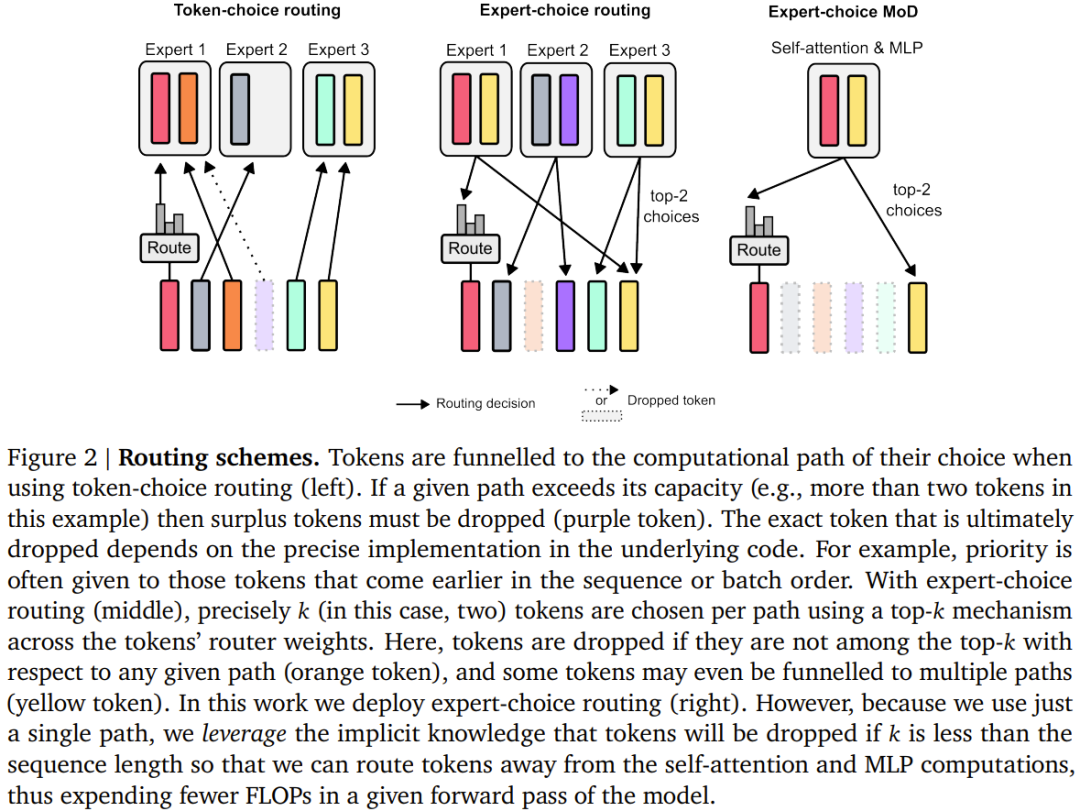
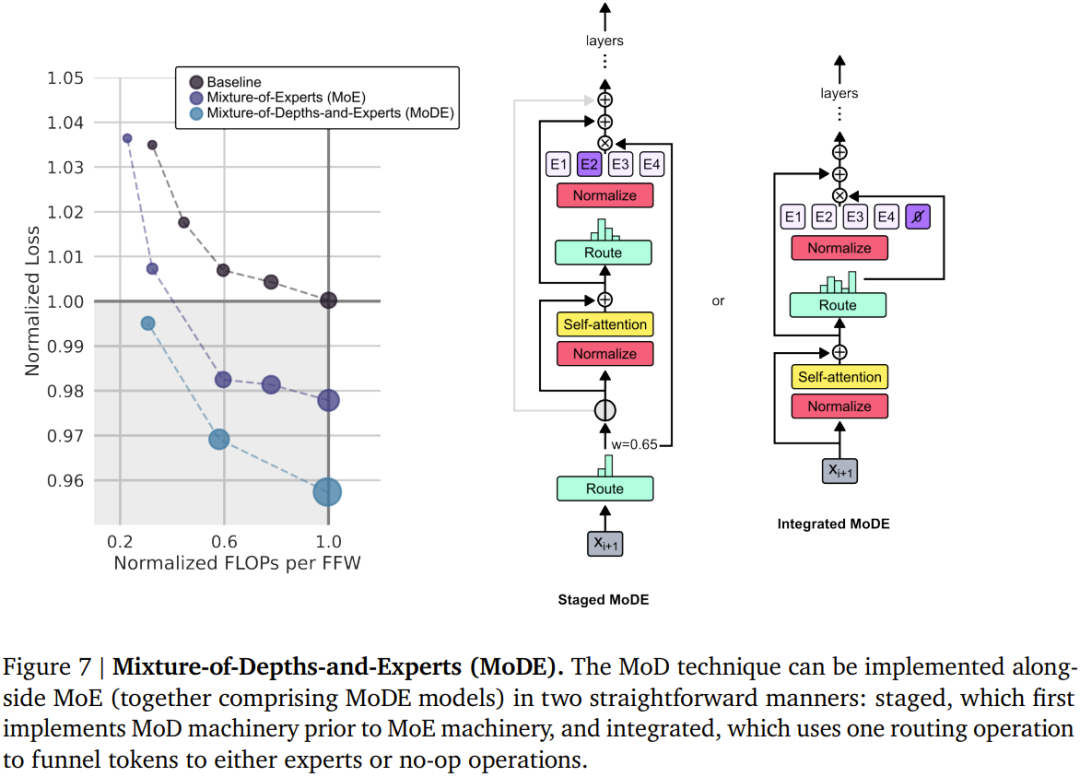
- Pasukan di DeepMind ini menggunakan pendekatan yang serupa dengan Pengubah Pakar Campuran (MoE), di mana keputusan penghalaan tahap token dinamik dilakukan merentas keseluruhan kedalaman rangkaian.
- Untuk setiap token, terdapat algoritma penghalaan dalam setiap modul yang memberikan pemberat skalar;
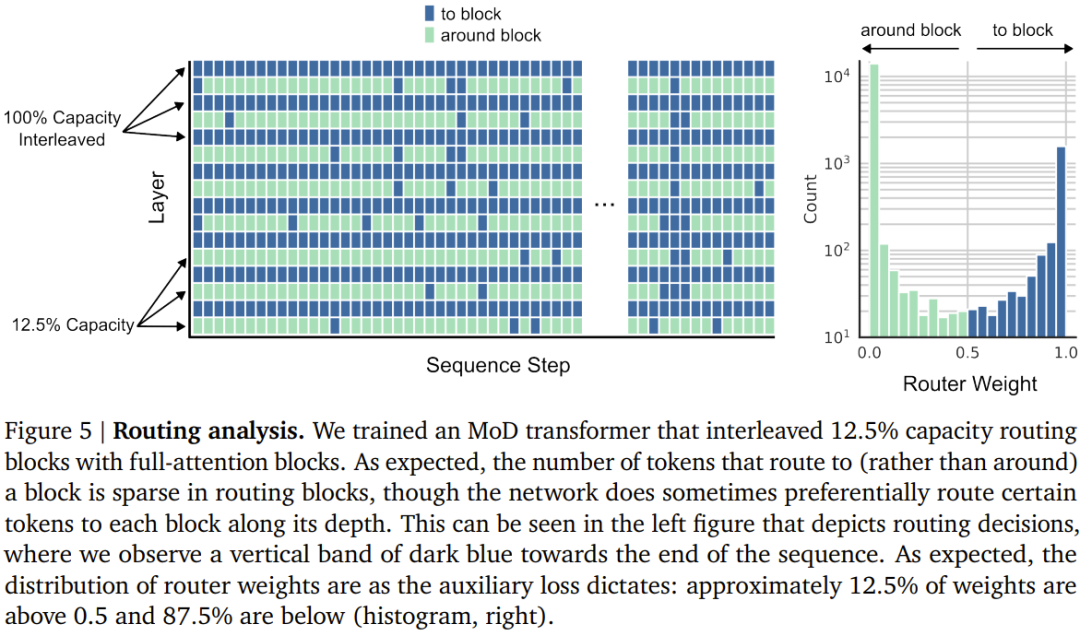
- Dalam setiap modul, cari pemberat skalar terbesar k teratas, dan token sepadannya akan mengambil bahagian dalam pengiraan modul. Memandangkan hanya token k mesti mengambil bahagian dalam pengiraan modul ini, graf pengiraan dan saiz tensornya adalah statik semasa proses latihan, token ini adalah token dinamik dan berkaitan konteks yang diiktiraf oleh algoritma penghalaan.
- Skim penghalaan
Atas ialah kandungan terperinci DeepMind menaik taraf Transformer, FLOP hantaran hadapan boleh dikurangkan sehingga separuh. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1657
1657
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 Cara mengemas kini kod dalam git
Apr 17, 2025 pm 04:45 PM
Cara mengemas kini kod dalam git
Apr 17, 2025 pm 04:45 PM
Langkah -langkah untuk mengemas kini kod git: lihat kod: klon git https://github.com/username/repo.git Dapatkan perubahan terkini: Git mengambil Perubahan Gabungan: Git Gabungan Asal/Master Push Change (Pilihan): Git Push Origin Master
 Cara memuat turun projek git ke tempatan
Apr 17, 2025 pm 04:36 PM
Cara memuat turun projek git ke tempatan
Apr 17, 2025 pm 04:36 PM
Untuk memuat turun projek secara tempatan melalui Git, ikuti langkah -langkah ini: pasang git. Navigasi ke direktori projek. Pengklonan Repositori Jauh menggunakan arahan berikut: Git Clone https://github.com/username/repository-name.git
 Cara menggabungkan kod dalam git
Apr 17, 2025 pm 04:39 PM
Cara menggabungkan kod dalam git
Apr 17, 2025 pm 04:39 PM
Proses penggabungan kod Git: Tarik perubahan terkini untuk mengelakkan konflik. Beralih ke cawangan yang anda mahu bergabung. Memulakan gabungan, menyatakan cawangan untuk bergabung. Selesaikan gabungan konflik (jika ada). Pementasan dan komit gabungan, memberikan mesej komit.
 Bagaimana menyelesaikan masalah carian yang cekap dalam projek PHP? Jenis membantu anda mencapainya!
Apr 17, 2025 pm 08:15 PM
Bagaimana menyelesaikan masalah carian yang cekap dalam projek PHP? Jenis membantu anda mencapainya!
Apr 17, 2025 pm 08:15 PM
Apabila membangunkan laman web e-dagang, saya menghadapi masalah yang sukar: bagaimana untuk mencapai fungsi carian yang cekap dalam sejumlah besar data produk? Carian pangkalan data tradisional tidak cekap dan mempunyai pengalaman pengguna yang lemah. Selepas beberapa penyelidikan, saya dapati jenis enjin carian dan menyelesaikan masalah ini melalui PHP pelanggan PHP TypeSense/TypeSense-PHP, yang meningkatkan prestasi carian.
 Apa yang Harus Dilakukan Sekiranya Muat turun Git Tidak Aktif
Apr 17, 2025 pm 04:54 PM
Apa yang Harus Dilakukan Sekiranya Muat turun Git Tidak Aktif
Apr 17, 2025 pm 04:54 PM
Selesaikan: Apabila kelajuan muat turun git perlahan, anda boleh mengambil langkah -langkah berikut: periksa sambungan rangkaian dan cuba menukar kaedah sambungan. Mengoptimumkan Konfigurasi Git: Meningkatkan Saiz Penampan Pos (Git Config-Global Http.PostBuffer 524288000), dan mengurangkan had berkelajuan rendah (git config --global http.lowspeedlimit 1000). Gunakan proksi Git (seperti Git-Proxy atau Git-LFS-Proxy). Cuba gunakan klien Git yang berbeza (seperti sourcetree atau github desktop). Periksa perlindungan kebakaran
 Cara menggunakan komitmen git
Apr 17, 2025 pm 03:57 PM
Cara menggunakan komitmen git
Apr 17, 2025 pm 03:57 PM
Git Commit adalah arahan yang merekodkan fail perubahan kepada repositori git untuk menyelamatkan gambar keadaan semasa projek. Cara menggunakannya adalah seperti berikut: Tambahkan perubahan ke kawasan penyimpanan sementara Tulis mesej penyerahan ringkas dan bermaklumat untuk menyimpan dan keluar dari mesej penyerahan untuk melengkapkan penyerahan secara opsyen: Tambahkan tandatangan untuk log penyerahan Git Log untuk melihat kandungan penyerahan
 Cara mengemas kini kod tempatan di Git
Apr 17, 2025 pm 04:48 PM
Cara mengemas kini kod tempatan di Git
Apr 17, 2025 pm 04:48 PM
Bagaimana cara mengemas kini kod git tempatan? Gunakan Git Fetch untuk menarik perubahan terkini dari repositori jauh. Gabungkan perubahan jauh ke cawangan tempatan menggunakan git gabungan asal/& lt; nama cawangan jauh & gt;. Menyelesaikan konflik yang timbul daripada penggabungan. Gunakan git commit -m "gabungan cawangan & lt; nama cawangan jauh & gt;" untuk menghantar penggabungan dan memohon kemas kini.
 Cara memadam repositori dengan git
Apr 17, 2025 pm 04:03 PM
Cara memadam repositori dengan git
Apr 17, 2025 pm 04:03 PM
Untuk memadam repositori Git, ikuti langkah -langkah ini: Sahkan repositori yang anda mahu padamkan. Penghapusan repositori tempatan: Gunakan perintah RM -RF untuk memadam foldernya. Jauh memadam gudang: Navigasi ke tetapan gudang, cari pilihan "Padam Gudang", dan sahkan operasi.
