
 Peranti teknologi
AI
OWASP mengeluarkan senarai semak keselamatan dan tadbir urus rangkaian model bahasa besar
Peranti teknologi
AI
OWASP mengeluarkan senarai semak keselamatan dan tadbir urus rangkaian model bahasa besar
OWASP mengeluarkan senarai semak keselamatan dan tadbir urus rangkaian model bahasa besar

Risiko terbesar yang dihadapi oleh teknologi kecerdasan buatan pada masa ini ialah pembangunan dan kelajuan aplikasi model bahasa besar (LLM) dan teknologi kecerdasan buatan generatif telah jauh melebihi kelajuan keselamatan dan tadbir urus.

Penggunaan AI generatif dan produk model bahasa besar daripada syarikat seperti OpenAI, Anthropic, Google dan Microsoft berkembang dengan pesat. Pada masa yang sama, penyelesaian model bahasa besar sumber terbuka juga berkembang pesat komuniti kecerdasan buatan sumber terbuka seperti HuggingFace menyediakan sejumlah besar model sumber terbuka, set data dan aplikasi AI.
Untuk menggalakkan pembangunan kecerdasan buatan, organisasi industri seperti OWASP, OpenSSF dan CISA sedang giat membangun dan menyediakan aset utama untuk keselamatan dan tadbir urus kecerdasan buatan, seperti OWASP AI Exchange, AI Security and Privacy Guide, dan Senarai Sepuluh Teratas Risiko Model Bahasa Besar ( LLMTop10).
Baru-baru ini, OWASP mengeluarkan senarai semak keselamatan dan tadbir urus model bahasa yang besar, mengisi jurang dalam tadbir urus keselamatan kecerdasan buatan generatif Kandungan khusus adalah seperti berikut:
Takrifan jenis AI dan ancaman OWASP
Keselamatan siber model bahasa OWASP. senarai semak mentakrifkan perbezaan antara kecerdasan buatan, pembelajaran mesin, AI generatif dan model bahasa besar.
Sebagai contoh, takrifan AI generatif OWASP ialah: sejenis pembelajaran mesin yang menumpukan pada mencipta data baharu, manakala model bahasa besar ialah model AI yang digunakan untuk memproses dan menjana "kandungan semula jadi" seperti manusia— —Mereka membuat ramalan berdasarkan input yang disediakan, dan output adalah "kandungan semula jadi" seperti manusia.
Mengenai "Senarai Ancaman Teratas Model Bahasa Besar" yang dikeluarkan sebelum ini, OWASP percaya bahawa ia boleh membantu pengamal keselamatan siber mengikuti perkembangan teknologi AI yang pesat membangun, mengenal pasti ancaman utama dan memastikan perusahaan mempunyai kawalan keselamatan asas untuk melindungi dan menyokong penggunaan. perniagaan kecerdasan buatan generatif dan model bahasa besar. Walau bagaimanapun, OWASP percaya bahawa senarai ini tidak lengkap dan perlu dipertingkatkan secara berterusan berdasarkan pembangunan kecerdasan buatan generatif.
OWASP membahagikan ancaman keselamatan AI kepada lima jenis berikut:
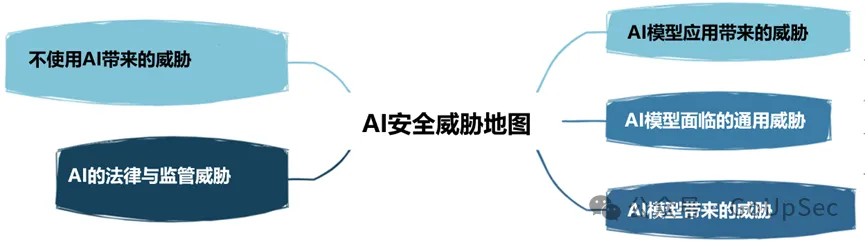
Penyerahan strategi tadbir urus keselamatan model bahasa besar OWASP dibahagikan kepada enam langkah:
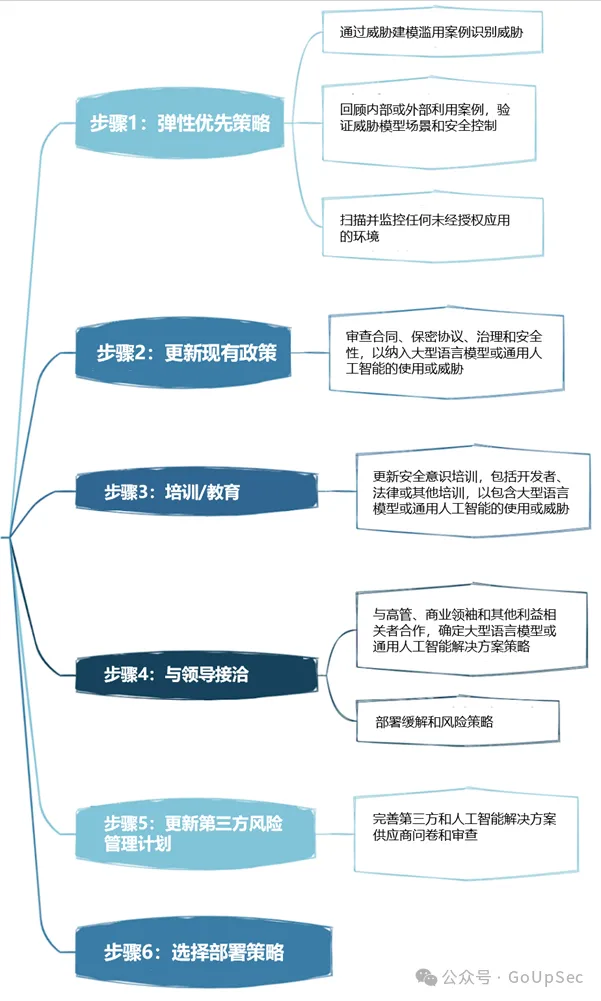
Berikut ialah senarai keselamatan rangkaian model bahasa OWASP dan besar :
1. Risiko musuh
Risiko musuh model bahasa besar bukan sahaja melibatkan pesaing, tetapi juga melibatkan penyerang bukan sahaja pada postur serangan, tetapi juga pada postur perniagaan. Ini termasuk memahami cara pesaing menggunakan AI untuk memacu hasil perniagaan, serta mengemas kini proses dan dasar dalaman, seperti pelan tindak balas insiden (IRP), untuk bertindak balas terhadap serangan dan insiden AI generatif.
2. Pemodelan Ancaman
Pemodelan ancaman ialah teknologi keselamatan yang semakin popular, semakin mendapat perhatian dengan promosi konsep sistem reka bentuk selamat, dan telah diluluskan oleh Agensi Keselamatan Siber dan Infrastruktur A.S. (CISA) ) dan organisasi berwibawa lain. Pemodelan ancaman memerlukan pemikiran tentang cara penyerang memanfaatkan model bahasa besar dan AI generatif untuk mempercepatkan eksploitasi kerentanan, keupayaan perusahaan untuk mengesan model bahasa besar yang berniat jahat, dan sama ada organisasi boleh melindungi model bahasa besar dan platform AI generatif daripada sistem dalaman dan persekitaran Sambungan.
3. Senarai Semak Aset Kecerdasan Buatan
Pepatah "Anda tidak boleh melindungi aset yang tidak diketahui" juga digunakan untuk bidang AI generatif dan model bahasa besar. Bahagian inventori OWASP ini melibatkan inventori aset AI untuk penyelesaian AI yang dibangunkan secara dalaman serta alat dan platform luaran.
OWASP menekankan bahawa perusahaan bukan sahaja mesti memahami alat dan perkhidmatan yang digunakan secara dalaman, tetapi juga memahami pemilikan mereka, iaitu, siapa yang bertanggungjawab untuk penggunaan alatan dan perkhidmatan ini. Senarai semak juga mengesyorkan memasukkan komponen AI dalam bil bahan perisian (SBOM) dan mendokumenkan sumber data AI dan sensitiviti masing-masing.
Selain menginventori alatan AI sedia ada, perniagaan juga harus mewujudkan proses selamat untuk menambahkan alatan dan perkhidmatan AI masa hadapan pada inventori.
4. Latihan Keselamatan Kecerdasan Buatan dan Kesedaran Privasi
Sering kali dikatakan bahawa "orang ramai adalah kelemahan keselamatan terbesar". model, boleh mengurangkan risiko manusia.
Ini termasuk membantu pekerja memahami inisiatif model AI/bahasa besar generatif sedia ada, teknologi dan keupayaan mereka, serta pertimbangan keselamatan utama seperti pelanggaran data. Selain itu, membina budaya keselamatan amanah dan ketelusan adalah penting.
Budaya amanah dan ketelusan dalam perusahaan juga boleh membantu mengelakkan ancaman AI bayangan, jika tidak pekerja akan "secara rahsia" menggunakan AI bayangan tanpa memberitahu pasukan IT dan keselamatan.
5. Kes perniagaan untuk projek kecerdasan buatan
Sama seperti pengkomputeran awan, kebanyakan syarikat sebenarnya tidak membangunkan kes perniagaan strategik yang koheren untuk aplikasi teknologi baharu seperti kecerdasan buatan generatif dan model bahasa besar, dan mudah untuk mengikuti trend secara membuta tuli Terperangkap dalam gembar-gembur. Tanpa kes perniagaan yang kukuh, aplikasi AI perusahaan berkemungkinan menghasilkan hasil yang buruk dan meningkatkan risiko.
6. Tadbir Urus
Tanpa tadbir urus, syarikat tidak boleh mewujudkan mekanisme akauntabiliti dan matlamat yang jelas untuk kecerdasan buatan. Senarai semak OWASP mengesyorkan agar perusahaan membangunkan carta RACI (matriks peruntukan tanggungjawab) untuk aplikasi kecerdasan buatan, merekod dan memperuntukkan tanggungjawab risiko dan tugas tadbir urus, dan mewujudkan dasar dan prosedur kecerdasan buatan seluruh perusahaan.
7 Undang-undang
Dengan perkembangan pesat teknologi kecerdasan buatan, impak undang-undangnya tidak boleh dipandang remeh dan boleh membawa risiko kewangan dan reputasi yang ketara kepada perusahaan.
Hal ehwal undang-undang kecerdasan buatan melibatkan beberapa siri aktiviti, seperti waranti produk kecerdasan buatan, perjanjian lesen pengguna akhir kecerdasan buatan (EULA), pemilikan kod yang dibangunkan menggunakan alat kecerdasan buatan, risiko harta intelek dan klausa pampasan kontrak, dsb. Ringkasnya, pastikan pasukan undang-undang atau pakar anda memahami pelbagai aktiviti undang-undang sokongan yang perlu dilakukan oleh syarikat anda apabila menggunakan AI generatif dan model bahasa besar.
8. Peraturan kawal selia kecerdasan buatan juga berkembang pesat, seperti Akta Kepintaran Buatan EU, dan peraturan di negara dan wilayah lain akan diperkenalkan tidak lama lagi. Perniagaan harus memahami keperluan pematuhan AI negara mereka, seperti pemantauan pekerja, dan mempunyai pemahaman yang jelas tentang cara vendor AI mereka menyimpan dan memadam data serta mengawal selia penggunaannya.
9. Gunakan atau laksanakan penyelesaian model bahasa yang besar
Menggunakan penyelesaian model bahasa yang besar memerlukan risiko dan kawalan khusus untuk dipertimbangkan. Senarai semak OWASP menyenaraikan item seperti kawalan akses, keselamatan saluran paip latihan, aliran kerja data pemetaan dan memahami kelemahan sedia ada atau berpotensi dalam model model bahasa besar dan rantaian bekalan. Selain itu, audit pihak ketiga, ujian penembusan dan juga semakan kod vendor diperlukan, pada mulanya dan secara berterusan.
10. Ujian, Penilaian, Pengesahan dan Pengesahan (TEVV)
Proses TEVV ialah proses yang disyorkan secara khusus oleh NIST dalam rangka kerja kecerdasan buatannya. Ini melibatkan mewujudkan ujian berterusan, penilaian, pengesahan dan pengesahan sepanjang kitaran hayat model AI, serta menyediakan metrik pelaksanaan pada kefungsian, keselamatan dan kebolehpercayaan model AI.
11. Kad Model dan Kad Risiko
Untuk menggunakan model bahasa yang besar secara beretika, senarai semak OWASP memerlukan perusahaan menggunakan model dan kad risiko yang boleh digunakan untuk membolehkan pengguna memahami dan mempercayai sistem AI, dan menangani berat sebelah dan privasi secara terbuka, dan lain-lain akibat negatif yang berpotensi.
Kad ini boleh mengandungi item seperti butiran model, seni bina, kaedah data latihan dan metrik prestasi. Pertimbangan untuk AI yang bertanggungjawab dan kebimbangan tentang keadilan dan ketelusan juga diserlahkan.
12RAG: Pengoptimuman Model Bahasa Besar
Retrieval Augmented Generation (RAG) ialah kaedah mengoptimumkan keupayaan model bahasa besar untuk mendapatkan semula data yang berkaitan daripada sumber tertentu. Ia adalah salah satu cara untuk mengoptimumkan model pra-latihan atau melatih semula model sedia ada berdasarkan data baharu untuk meningkatkan prestasi. OWASP mengesyorkan agar perusahaan melaksanakan RAG untuk memaksimumkan nilai dan keberkesanan model bahasa besar.
13. AI Red Team
Akhir sekali, senarai semak OWASP menyerlahkan kepentingan AI Red Teaming, yang mensimulasikan serangan musuh ke atas sistem AI untuk mengenal pasti kelemahan dan mengesahkan kawalan dan pertahanan sedia ada. OWASP menekankan bahawa pasukan merah harus menjadi sebahagian daripada penyelesaian keselamatan yang komprehensif dengan AI generatif dan model bahasa yang besar.
Perlu diingat bahawa perusahaan juga perlu mempunyai pemahaman yang jelas tentang perkhidmatan pasukan merah dan keperluan sistem serta keupayaan vendor model AI generatif luaran dan model bahasa besar untuk mengelak daripada melanggar dasar atau malah menghadapi masalah undang-undang.
Atas ialah kandungan terperinci OWASP mengeluarkan senarai semak keselamatan dan tadbir urus rangkaian model bahasa besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Penterjemah |. Tinjauan Bugatti |. Chonglou Artikel ini menerangkan cara menggunakan enjin inferens GroqLPU untuk menjana respons sangat pantas dalam JanAI dan VSCode. Semua orang sedang berusaha membina model bahasa besar (LLM) yang lebih baik, seperti Groq yang memfokuskan pada bahagian infrastruktur AI. Sambutan pantas daripada model besar ini adalah kunci untuk memastikan model besar ini bertindak balas dengan lebih cepat. Tutorial ini akan memperkenalkan enjin parsing GroqLPU dan cara mengaksesnya secara setempat pada komputer riba anda menggunakan API dan JanAI. Artikel ini juga akan menyepadukannya ke dalam VSCode untuk membantu kami menjana kod, kod refactor, memasukkan dokumentasi dan menjana unit ujian. Artikel ini akan mencipta pembantu pengaturcaraan kecerdasan buatan kami sendiri secara percuma. Pengenalan kepada enjin inferens GroqLPU Groq
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Sebarkan model bahasa besar secara setempat dalam OpenHarmony
Jun 07, 2024 am 10:02 AM
Sebarkan model bahasa besar secara setempat dalam OpenHarmony
Jun 07, 2024 am 10:02 AM
Artikel ini akan membuka sumber hasil "Pengedaran Tempatan Model Bahasa Besar dalam OpenHarmony" yang ditunjukkan pada Persidangan Teknologi OpenHarmony ke-2 alamat sumber terbuka: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/ hap_integrate.md. Idea dan langkah pelaksanaan adalah untuk memindahkan rangka kerja inferens model LLM ringan InferLLM kepada sistem standard OpenHarmony dan menyusun produk binari yang boleh dijalankan pada OpenHarmony. InferLLM ialah L yang mudah dan cekap
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
