
 Peranti teknologi
AI
Model besar teks panjang tanpa had Meta ada di sini: hanya parameter 7B, sumber terbuka
Peranti teknologi
AI
Model besar teks panjang tanpa had Meta ada di sini: hanya parameter 7B, sumber terbuka
Model besar teks panjang tanpa had Meta ada di sini: hanya parameter 7B, sumber terbuka

Selepas Google, Meta juga datang untuk melancarkan konteks yang sangat panjang.
Kerumitan kuadratik dan ekstrapolasi panjang yang lemah bagi Transformer mengehadkan keupayaan mereka untuk menskalakan kepada jujukan yang panjang Walaupun penyelesaian kuadratik seperti perhatian linear dan model ruang nyata wujud, dari pengalaman lepas, Mereka berprestasi rendah dari segi kecekapan pra-latihan. dan ketepatan tugas hiliran.
Baru-baru ini, Infini-Transformer yang dicadangkan oleh Google telah menarik perhatian orang ramai dengan memperkenalkan kaedah berkesan yang boleh memanjangkan model bahasa besar (LLM) berasaskan Transformer kepada input yang tidak terhingga panjang tanpa meningkatkan keperluan storan dan pengkomputeran.
Hampir pada masa yang sama, Meta juga mencadangkan teknologi teks yang tidak terhingga panjangnya.

Alamat kertas: https://arxiv.org/pdf/2404.08801.pdf
Tajuk kertas: MEGALODON: Cekap LLM Pralatihan dan Inferens Konteks🜎🜎 / /github.com/XuezheMax/megalodon
Dalam kertas kerja yang diserahkan pada 12 April, institusi dari Meta, University of Southern California, CMU, UCSD dan institusi lain memperkenalkan MEGALODON, rangkaian saraf untuk pemodelan jujukan yang cekap, panjang konteks tidak terhad.
MEGALODON membangunkan lagi struktur MEGA (Purata Pergerakan Eksponen dengan Perhatian Berpagar) dan memperkenalkan pelbagai komponen teknikal untuk meningkatkan keupayaan dan kestabilannya, termasuk Purata Pergerakan Eksponen Kompleks (CEMA), lapisan normalisasi langkah masa, mekanisme perhatian yang dinormalkan dan sambungan baki pra-normal dengan dua ciri.
 MEGALODON pada asasnya ialah seni bina MEGA yang dipertingkatkan (Ma et al., 2023), yang menggunakan mekanisme perhatian berpagar dan kaedah purata bergerak eksponen (EMA) klasik. Untuk meningkatkan lagi keupayaan dan kecekapan MEGALODON dalam pra-latihan konteks panjang berskala besar, penulis mencadangkan pelbagai komponen teknikal. Mula-mula, MEGALODON memperkenalkan komponen purata bergerak eksponen kompleks (CEMA) yang memanjangkan EMA lembap berbilang dimensi dalam MEGA kepada domain kompleks. Kedua, MEGALODON mencadangkan lapisan normalisasi langkah masa, yang menyamaratakan lapisan normalisasi kumpulan kepada tugas pemodelan jujukan autoregresif untuk membenarkan normalisasi sepanjang dimensi jujukan.
MEGALODON pada asasnya ialah seni bina MEGA yang dipertingkatkan (Ma et al., 2023), yang menggunakan mekanisme perhatian berpagar dan kaedah purata bergerak eksponen (EMA) klasik. Untuk meningkatkan lagi keupayaan dan kecekapan MEGALODON dalam pra-latihan konteks panjang berskala besar, penulis mencadangkan pelbagai komponen teknikal. Mula-mula, MEGALODON memperkenalkan komponen purata bergerak eksponen kompleks (CEMA) yang memanjangkan EMA lembap berbilang dimensi dalam MEGA kepada domain kompleks. Kedua, MEGALODON mencadangkan lapisan normalisasi langkah masa, yang menyamaratakan lapisan normalisasi kumpulan kepada tugas pemodelan jujukan autoregresif untuk membenarkan normalisasi sepanjang dimensi jujukan.
Untuk meningkatkan kestabilan pra-latihan berskala besar, MEGALODON seterusnya mencadangkan perhatian yang dinormalisasi, serta pra-penormalan dengan konfigurasi baki dua hop dengan mengubah suai kaedah pra-normalisasi dan pasca-normalisasi yang diterima pakai secara meluas. Dengan hanya memotong jujukan input ke dalam ketulan tetap, seperti yang dilakukan dalam ketulan MEGA, MEGALODON mencapai kerumitan pengiraan dan ingatan linear dalam latihan model dan inferens.
Dalam perbandingan langsung dengan LLAMA2, sambil mengawal data dan pengiraan, MEGALODON-7B dengan ketara mengatasi varian Transformer tercanggih yang digunakan untuk melatih LLAMA2-7B dari segi kebingungan latihan. Penilaian pada pemodelan konteks panjang, termasuk kebingungan dalam pelbagai panjang konteks sehingga 2M dan tugasan QA konteks panjang dalam Tatal, menunjukkan keupayaan MEGALODON untuk memodelkan jujukan panjang tak terhingga. Hasil percubaan tambahan pada penanda aras kecil dan sederhana, termasuk LRA, ImageNet, Perintah Pertuturan, WikiText-103, dan PG19 menunjukkan keupayaan MEGALODON pada volum dan pelbagai mod.
Pengenalan kepada kaedahPertama sekali, artikel itu mengkaji secara ringkas komponen utama dalam seni bina MEGA (Moving Average Equipped Gated Attention) dan membincangkan masalah yang wujud dalam MEGA. MEGA membenamkan komponen EMA (purata bergerak eksponen) ke dalam pengiraan matriks perhatian untuk menggabungkan bias induktif merentas dimensi langkah masa. Khususnya, EMA terlembap berbilang dimensi mula-mula mengembangkan setiap dimensi jujukan input Borangnya adalah seperti berikut:
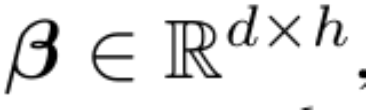 Untuk mengurangkan kerumitan kuadratik dalam mekanisme perhatian penuh, MEGA hanya membahagikan urutan pertanyaan, kunci dan nilai dalam (14-16) kepada ketulan panjang c. Perhatian dalam (17) digunakan pada setiap blok secara individu, menghasilkan kerumitan linear O (kc^2 ) = O (nc).
Untuk mengurangkan kerumitan kuadratik dalam mekanisme perhatian penuh, MEGA hanya membahagikan urutan pertanyaan, kunci dan nilai dalam (14-16) kepada ketulan panjang c. Perhatian dalam (17) digunakan pada setiap blok secara individu, menghasilkan kerumitan linear O (kc^2 ) = O (nc).
Secara teknikal, sub-lapisan EMA dalam MEGA membantu menangkap maklumat kontekstual setempat berhampiran setiap token, dengan itu mengurangkan masalah kehilangan maklumat dalam konteks melangkaui sempadan blok. Walaupun MEGA mencapai keputusan yang mengagumkan, ia menghadapi masalah berikut:
i) Disebabkan kuasa ekspresif terhad sub-lapisan EMA dalam MEGA, prestasi MEGA dengan perhatian peringkat blok masih ketinggalan berbanding MEGA tumpuan penuh.
ii) Untuk tugasan dan jenis data yang berbeza, mungkin terdapat perbezaan seni bina dalam seni bina MEGA akhir, seperti lapisan penormalan yang berbeza, mod penormalan dan fungsi perhatian f (・).
iii) Tiada bukti empirikal bahawa skala MEGA untuk pra-latihan berskala besar.


CEMA: Memperluaskan EMA redaman multidimensi ke domain kompleks
Untuk menyelesaikan masalah yang dihadapi oleh MEGA, penyelidikan ini mencadangkan MEGALODON.
Secara khusus, mereka secara kreatif mencadangkan purata bergerak eksponen kompleks CEMA (purata bergerak eksponen kompleks), menulis semula persamaan di atas (1) ke dalam bentuk berikut:
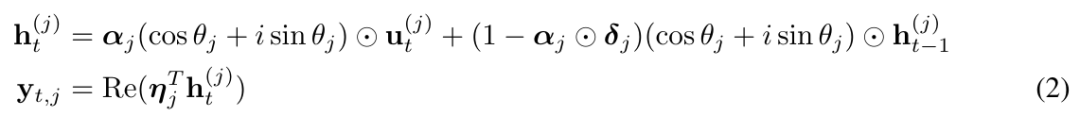
dan parameterkan θ_j dalam (2) sebagai :
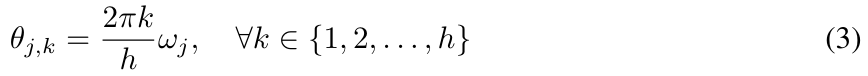
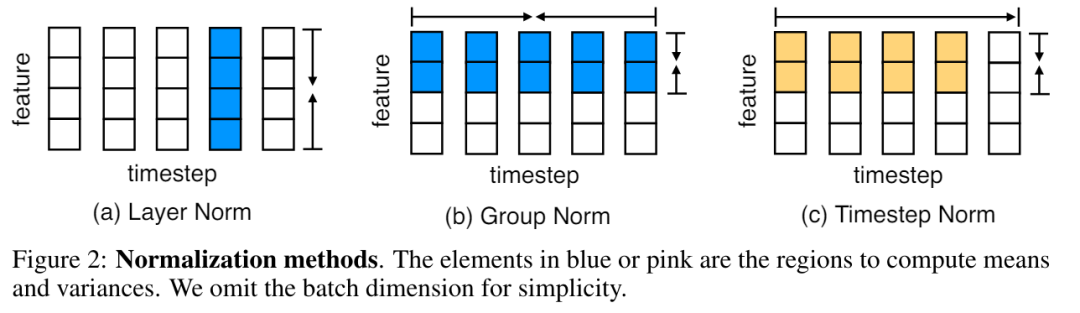
Penormalan Langkah Masa
Walaupun prestasi penormalan lapisan yang digabungkan dengan Transformer sangat mengagumkan, adalah jelas bahawa penormalan lapisan tidak dapat secara langsung mengurangkan sepanjang dimensi ruang (juga Anjakan kovariat dalaman dipanggil langkah masa atau dimensi jujukan). Dalam MEGALODON, kajian ini memanjangkan normalisasi kumpulan kepada kes autoregresif dengan mengira min dan varians kumulatif.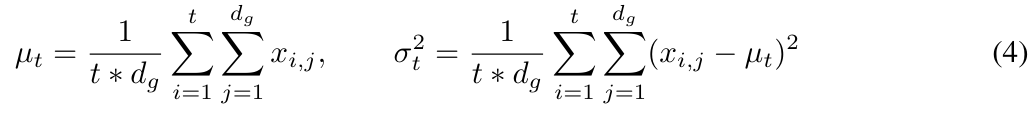
Perhatian yang dinormalkan dalam MEGALODON
Selain itu, penyelidikan itu juga mencadangkan mekanisme perhatian ternormal yang disesuaikan khusus untuk MEGA untuk meningkatkan kestabilannya. Bentuknya adalah seperti berikut:

Pra-Norma dengan baki Dua-hop didapati melalui penyiasatan, Meningkatkan saiz model boleh menyebabkan ketidakstabilan pranormalisasi. Pra-normalisasi berdasarkan blok Transformer boleh dinyatakan seperti (ditunjukkan dalam Rajah 3 (b)):

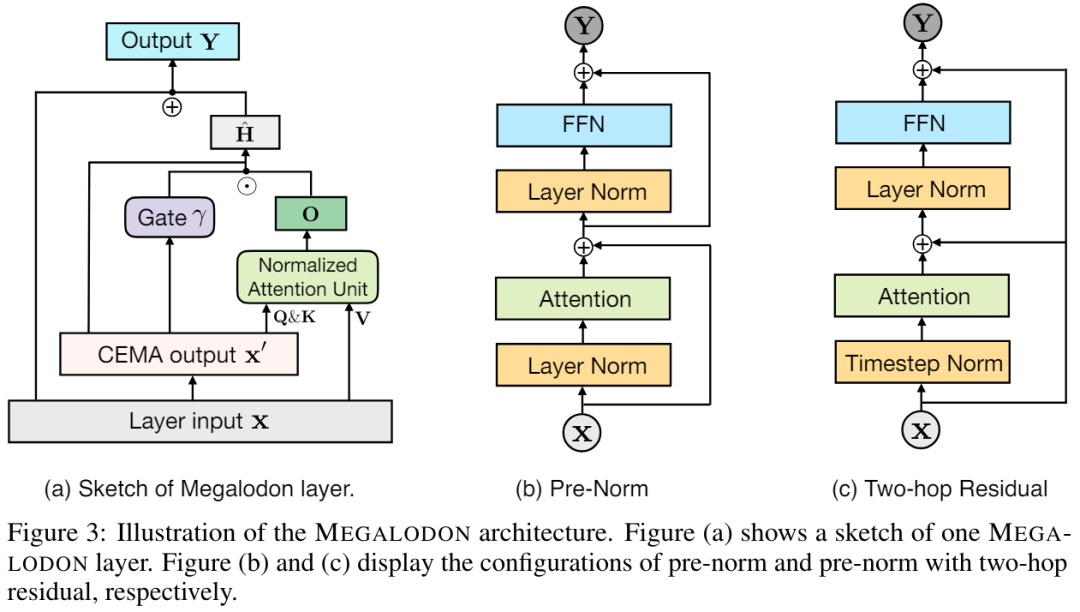 Dalam seni bina MEGA asal, φ (19) digunakan untuk sambungan baki berpagar (21 ) untuk mengurangkan masalah ini. Walau bagaimanapun, gerbang kemas kini φ memperkenalkan lebih banyak parameter model, dan masalah ketidakstabilan masih wujud apabila saiz model dikembangkan kepada 7 bilion. MEGALODON memperkenalkan konfigurasi baharu yang dipanggil pra-norma dengan baki dua hop, yang hanya menyusun semula sambungan baki dalam setiap blok, seperti yang ditunjukkan dalam Rajah 3(c):
Dalam seni bina MEGA asal, φ (19) digunakan untuk sambungan baki berpagar (21 ) untuk mengurangkan masalah ini. Walau bagaimanapun, gerbang kemas kini φ memperkenalkan lebih banyak parameter model, dan masalah ketidakstabilan masih wujud apabila saiz model dikembangkan kepada 7 bilion. MEGALODON memperkenalkan konfigurasi baharu yang dipanggil pra-norma dengan baki dua hop, yang hanya menyusun semula sambungan baki dalam setiap blok, seperti yang ditunjukkan dalam Rajah 3(c):
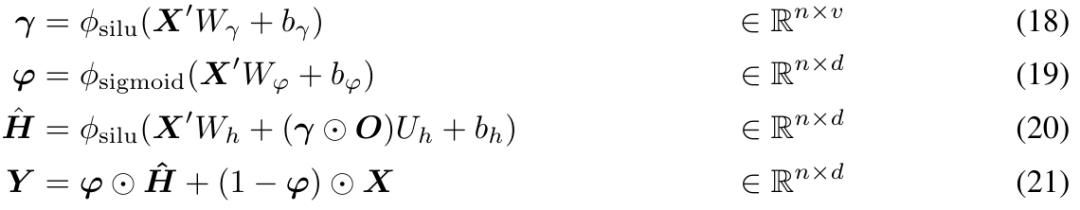
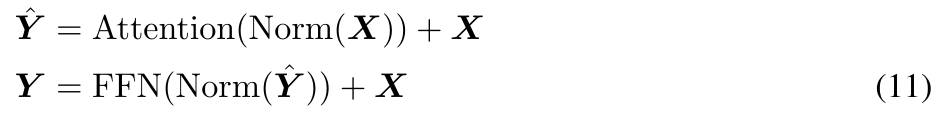
menilai kebolehskalaan dan kecekapan MEGALODON dalam pemodelan jujukan konteks panjang, makalah ini memanjangkan MEGALODON kepada skala 7 bilion.
LLM pra-latihanUntuk meningkatkan kecekapan data, penyelidik menunjukkan kemungkinan log negatif (NLL) MEGALODON-7B, LLAMA2-7B dan LLAMA2-13B semasa proses latihan, seperti ditunjukkan dalam Rajah 1.
Di bawah bilangan token latihan yang sama, MEGALODON-7B mencapai NLL yang jauh lebih baik (rendah) daripada LLAMA2-7B, menunjukkan kecekapan data yang lebih baik.
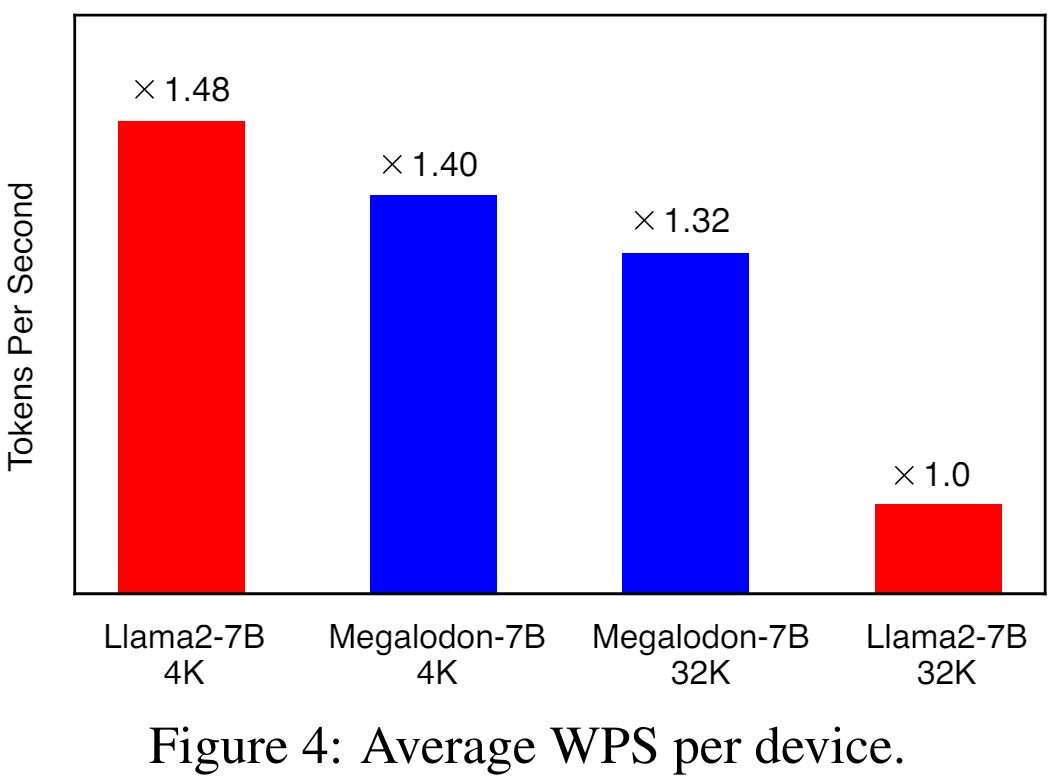
Rajah 4 menggambarkan purata WPS (perkataan/token sesaat) setiap peranti untuk LLAMA2-7B dan MEGALODON-7B masing-masing menggunakan panjang konteks 4K dan 32K. Untuk model LLAMA2, kajian menggunakan Flash-Attention V2 untuk mempercepatkan pengiraan perhatian penuh. Pada panjang konteks 4K, MEGALODON-7B adalah lebih perlahan (~6%) daripada LLAMA2-7B disebabkan pengenalan CEMA dan penormalan langkah masa. Apabila memanjangkan panjang konteks kepada 32K, MEGALODON-7B jauh lebih pantas daripada LLAMA2-7B (kira-kira 32%), yang menunjukkan kecekapan pengiraan MEGALODON untuk pra-latihan konteks yang panjang.
Penilaian Konteks Ringkas
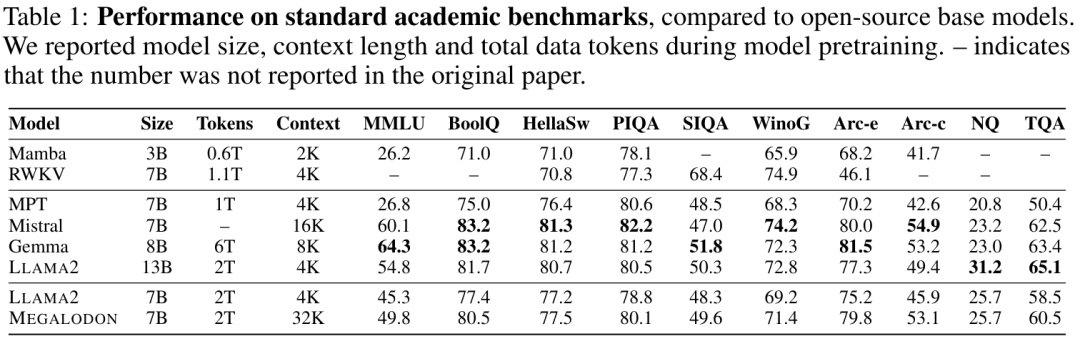
Jadual 1 meringkaskan keputusan MEGALODON dan LLAMA2 pada penanda aras akademik, serta hasil perbandingan model asas sumber terbuka lain, termasuk MPT, RWKV, dan Gemba, Mistral Selepas pra-latihan pada token 2T yang sama, MEGALODON-7B mengatasi LLAMA2-7B pada semua penanda aras. Pada sesetengah tugas, prestasi MEGALODON-7B adalah setanding atau lebih baik daripada LLAMA2-13B.
Penilaian konteks panjang
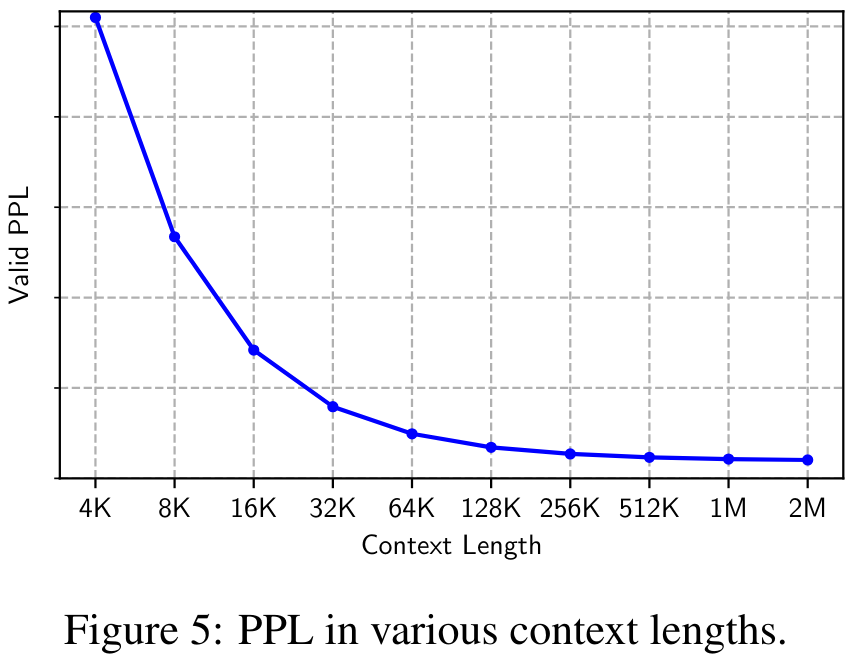
Rajah 5 menunjukkan kebingungan (PPL) set data pengesahan di bawah pelbagai panjang konteks daripada 4K hingga 2M. Dapat diperhatikan bahawa PPL berkurangan secara monoton dengan panjang konteks, mengesahkan keberkesanan dan keteguhan MEGALODON dalam memodelkan urutan yang sangat panjang.
Penalaan halus arahan
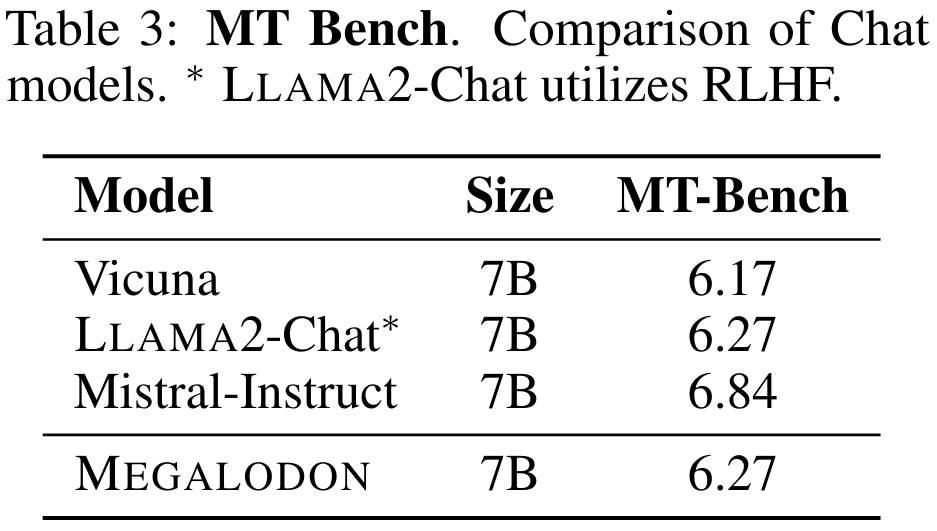
Jadual 3 meringkaskan prestasi model 7B pada MT-Bench. MEGALODON menunjukkan prestasi unggul pada MT-Bench berbanding Vicuna dan setanding dengan LLAMA2-Chat, yang menggunakan RLHF untuk penyelarasan lebih lanjut.
Penilaian Penanda Aras Skala Sederhana
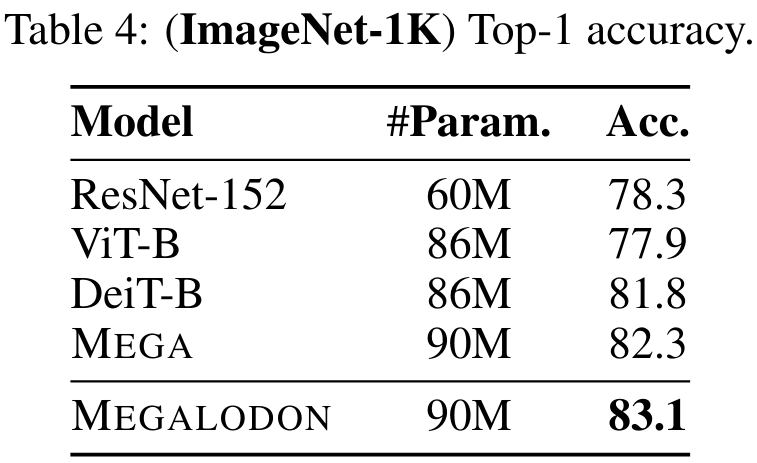
Untuk menilai prestasi MEGALODON pada tugas pengelasan imej, kajian itu menjalankan eksperimen pada dataset Imagenet-1K. Jadual 4 melaporkan ketepatan Top-1 pada set pengesahan. Ketepatan MEGALODON adalah 1.3% lebih tinggi daripada DeiT-B dan 0.8% lebih tinggi daripada MEGA.
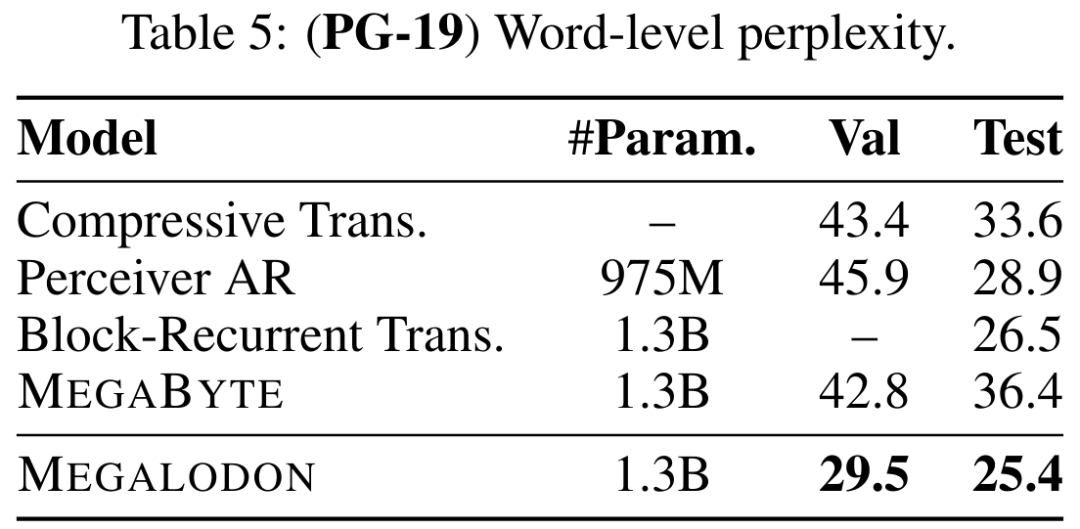
Jadual 5 menggambarkan kekeliruan peringkat perkataan (PPL) MEGALODON pada PG-19, dan perbandingan dengan model terkini yang terkini, termasuk Compressive Transformer, Perceiver AR, Perceiver AR, Block Loop Transformer dan MEGABYTE, dsb. Prestasi MEGALODON jelas di hadapan.
Sila rujuk kertas asal untuk butiran lanjut.
Atas ialah kandungan terperinci Model besar teks panjang tanpa had Meta ada di sini: hanya parameter 7B, sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
Giteepages Statik Laman Web Penggunaan Gagal: 404 Penyelesaian Masalah dan Resolusi Ralat Semasa Menggunakan Gitee ...
 Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Menjalankan projek H5 memerlukan langkah -langkah berikut: memasang alat yang diperlukan seperti pelayan web, node.js, alat pembangunan, dan lain -lain. Membina persekitaran pembangunan, membuat folder projek, memulakan projek, dan menulis kod. Mulakan pelayan pembangunan dan jalankan arahan menggunakan baris arahan. Pratonton projek dalam penyemak imbas anda dan masukkan URL Server Pembangunan. Menerbitkan projek, mengoptimumkan kod, menggunakan projek, dan menyediakan konfigurasi pelayan web.
 Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Halaman H5 perlu dikekalkan secara berterusan, kerana faktor -faktor seperti kelemahan kod, keserasian pelayar, pengoptimuman prestasi, kemas kini keselamatan dan peningkatan pengalaman pengguna. Kaedah penyelenggaraan yang berkesan termasuk mewujudkan sistem ujian lengkap, menggunakan alat kawalan versi, kerap memantau prestasi halaman, mengumpul maklum balas pengguna dan merumuskan pelan penyelenggaraan.
 Cara Mengira C-SubScript 3 Subscript 5 C-SubScript 3 Subscript 5 Algoritma Tutorial
Apr 03, 2025 pm 10:33 PM
Cara Mengira C-SubScript 3 Subscript 5 C-SubScript 3 Subscript 5 Algoritma Tutorial
Apr 03, 2025 pm 10:33 PM
Pengiraan C35 pada dasarnya adalah matematik gabungan, yang mewakili bilangan kombinasi yang dipilih dari 3 dari 5 elemen. Formula pengiraan ialah C53 = 5! / (3! * 2!), Yang boleh dikira secara langsung oleh gelung untuk meningkatkan kecekapan dan mengelakkan limpahan. Di samping itu, memahami sifat kombinasi dan menguasai kaedah pengiraan yang cekap adalah penting untuk menyelesaikan banyak masalah dalam bidang statistik kebarangkalian, kriptografi, reka bentuk algoritma, dll.
 Bagaimana untuk melaksanakan susun atur penyesuaian kedudukan paksi y dalam anotasi web?
Apr 04, 2025 pm 11:30 PM
Bagaimana untuk melaksanakan susun atur penyesuaian kedudukan paksi y dalam anotasi web?
Apr 04, 2025 pm 11:30 PM
Algoritma Adaptif Kedudukan Y-Axis untuk Fungsi Anotasi Web Artikel ini akan meneroka cara melaksanakan fungsi anotasi yang serupa dengan dokumen perkataan, terutama bagaimana menangani selang antara anotasi ...
 Bagaimana untuk menjadikan ketinggian lajur bersebelahan dalam UI elemen secara automatik menyesuaikan diri dengan kandungan?
Apr 05, 2025 am 06:12 AM
Bagaimana untuk menjadikan ketinggian lajur bersebelahan dalam UI elemen secara automatik menyesuaikan diri dengan kandungan?
Apr 05, 2025 am 06:12 AM
Bagaimana untuk menjadikan ketinggian lajur bersebelahan baris yang sama secara automatik menyesuaikan diri dengan kandungan? Dalam reka bentuk web, kita sering menghadapi masalah ini: apabila terdapat banyak di meja atau baris ...
 Adakah saya perlu menggunakan Flexbox di tengah gambar bootstrap?
Apr 07, 2025 am 09:06 AM
Adakah saya perlu menggunakan Flexbox di tengah gambar bootstrap?
Apr 07, 2025 am 09:06 AM
Terdapat banyak cara untuk memusatkan gambar bootstrap, dan anda tidak perlu menggunakan Flexbox. Jika anda hanya perlu berpusat secara mendatar, kelas pusat teks sudah cukup; Jika anda perlu memusatkan elemen secara menegak atau berganda, Flexbox atau Grid lebih sesuai. Flexbox kurang serasi dan boleh meningkatkan kerumitan, manakala grid lebih berkuasa dan mempunyai kos pengajian yang lebih tinggi. Apabila memilih kaedah, anda harus menimbang kebaikan dan keburukan dan memilih kaedah yang paling sesuai mengikut keperluan dan keutamaan anda.
 Fungsi Penggunaan Fungsi Jarak Jarak Jarak Penggunaan C Tutorial Penggunaan
Apr 03, 2025 pm 10:27 PM
Fungsi Penggunaan Fungsi Jarak Jarak Jarak Penggunaan C Tutorial Penggunaan
Apr 03, 2025 pm 10:27 PM
STD :: Unik menghilangkan elemen pendua bersebelahan di dalam bekas dan menggerakkannya ke akhir, mengembalikan iterator yang menunjuk ke elemen pendua pertama. STD :: Jarak mengira jarak antara dua iterators, iaitu bilangan elemen yang mereka maksudkan. Kedua -dua fungsi ini berguna untuk mengoptimumkan kod dan meningkatkan kecekapan, tetapi terdapat juga beberapa perangkap yang perlu diberi perhatian, seperti: STD :: Unik hanya berkaitan dengan unsur -unsur pendua yang bersebelahan. STD :: Jarak kurang cekap apabila berurusan dengan Iterator Akses Bukan Rawak. Dengan menguasai ciri -ciri dan amalan terbaik ini, anda boleh menggunakan sepenuhnya kuasa kedua -dua fungsi ini.
