
 Peranti teknologi
AI
Bagaimana untuk menggunakan pengubah untuk mengaitkan ciri radar-visual gelombang lidar-milimeter dengan berkesan?
Peranti teknologi
AI
Bagaimana untuk menggunakan pengubah untuk mengaitkan ciri radar-visual gelombang lidar-milimeter dengan berkesan?
Bagaimana untuk menggunakan pengubah untuk mengaitkan ciri radar-visual gelombang lidar-milimeter dengan berkesan?

Pengarang secara peribadi memahami
Salah satu tugas asas pemanduan autonomi ialah pengesanan sasaran tiga dimensi, dan banyak kaedah kini dilaksanakan berdasarkan kaedah gabungan pelbagai sensor. Jadi mengapa gabungan berbilang sensor diperlukan sama ada gabungan lidar dan kamera, atau radar gelombang milimeter dan gabungan kamera, tujuan utamanya adalah untuk menggunakan sambungan pelengkap antara awan titik dan imej untuk meningkatkan ketepatan pengesanan sasaran . Dengan aplikasi seni bina Transformer yang berterusan dalam bidang penglihatan komputer, kaedah berasaskan mekanisme perhatian telah meningkatkan ketepatan gabungan antara pelbagai sensor. Kedua-dua kertas kerja yang dikongsi adalah berdasarkan seni bina ini dan mencadangkan kaedah gabungan baru untuk menggunakan lebih banyak maklumat berguna bagi modaliti masing-masing dan mencapai gabungan yang lebih baik.
TransFusion:
Sumbangan utama
Lidar dan kamera ialah dua penderia pengesanan sasaran tiga dimensi yang penting dalam pemanduan autonomi, bagaimanapun, dalam gabungan penderia, mereka menghadapi masalah ketepatan imej pengesanan yang rendah syarat . Kaedah gabungan berasaskan titik adalah untuk menggabungkan lidar dan kamera melalui perkaitan keras, yang akan membawa kepada beberapa masalah: a) hanya penyambungan awan titik dan ciri imej, dengan kehadiran ciri imej berkualiti rendah, prestasi pengesanan akan merosot dengan serius ;b) Mencari korelasi keras antara awan titik jarang dan imej membuang ciri imej berkualiti tinggi dan sukar untuk diselaraskan. Untuk menyelesaikan masalah ini, kaedah perkaitan lembut dicadangkan. Kaedah ini menganggap lidar dan kamera sebagai dua pengesan bebas, bekerjasama antara satu sama lain dan memanfaatkan sepenuhnya kelebihan kedua-dua pengesan itu. Pertama, pengesan objek tradisional digunakan untuk mengesan objek dan menjana kotak sempadan, dan kemudian kotak sempadan dan awan titik dipadankan untuk mendapatkan skor yang mana kotak sempadan setiap titik dikaitkan. Akhir sekali, ciri imej yang sepadan dengan kotak tepi digabungkan dengan ciri yang dihasilkan oleh awan titik. Kaedah ini berkesan boleh mengelakkan penurunan ketepatan pengesanan yang disebabkan oleh keadaan jalur imej yang lemah Pada masa yang sama, kertas kerja ini memperkenalkan TransFusion, rangka kerja gabungan untuk lidar dan kamera untuk menyelesaikan masalah korelasi antara kedua-dua sensor. Sumbangan utama adalah seperti berikut:
Cadangkan model gabungan pengesanan 3D berasaskan transformer bagi lidar dan kamera, yang menunjukkan keteguhan yang sangat baik kepada kualiti imej yang lemah dan salah penjajaran penderia- Memperkenalkan beberapa kaedah untuk pertanyaan objek Pelarasan yang mudah namun berkesan untuk diperbaiki kualiti ramalan kotak sempadan awal untuk gabungan imej, dan modul pemulaan pertanyaan berpandukan imej yang direka untuk mengendalikan objek yang sukar dikesan dalam awan titik
- bukan sahaja melaksanakan pengesanan 3D lanjutan dalam prestasi nuScenes, dan juga memanjangkan model kepada; tugas pengesanan tiga dimensi dan mencapai keputusan yang baik. . . Model ini bergantung pada rangkaian tulang belakang 3D dan 2D standard untuk mengekstrak ciri LiDAR BEV dan ciri imej, dan kemudian terdiri daripada dua lapisan penyahkod Transformer: penyahkod lapisan pertama menggunakan awan titik jarang untuk menjana kotak sempadan awal, penyahkod lapisan kedua menukar yang pertama lapisan Pertanyaan objek digabungkan dengan pertanyaan ciri imej untuk mendapatkan hasil pengesanan yang lebih baik. Mekanisme perhatian modulasi spatial (SMCA) dan strategi pertanyaan berpandukan imej juga diperkenalkan untuk meningkatkan ketepatan pengesanan. Melalui pengesanan model ini, ciri imej yang lebih baik dan ketepatan pengesanan boleh diperolehi.
- Query Initialization
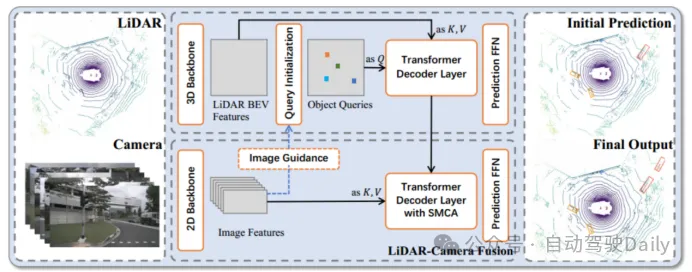 LiDAR-Camera Fusion
LiDAR-Camera Fusion
modul Silang Perhatian Bermodul Ruang (SMCA)
direka, yang melepasi Gaussian bulat 2D di sekitar pusat 2D setiap unjuran pertanyaan berat topeng merentas perhatian.Permulaan Pertanyaan Berpandukan Imej (Permulaan Pertanyaan Berpandukan Imej)

Modul Pertanyaan Berpandukan Imej 2
Modul ini menggunakan maklumat lidar dan imej sebagai pertanyaan objek pada masa yang sama, dengan menghantar ciri imej dan ciri BEV lidar ke dalam rangkaian mekanisme perhatian silang, menayangkannya pada satah BEV dan menjana ciri BEV bercantum. Seperti yang ditunjukkan dalam Rajah 2, ciri imej berbilang paparan pertama kali dilipat di sepanjang paksi ketinggian sebagai nilai utama rangkaian mekanisme perhatian silang, dan ciri BEV lidar dihantar ke rangkaian perhatian sebagai pertanyaan untuk mendapatkan ciri BEV bercantum, yang digunakan untuk ramalan peta haba , dan dipuratakan dengan peta haba lidar sahaja Ŝ untuk mendapatkan peta haba akhir Ŝ untuk memilih dan memulakan pertanyaan sasaran. Operasi sedemikian membolehkan model mengesan sasaran yang sukar dikesan dalam awan titik lidar.
Eksperimen
Set Data dan Metrik
set data nuScenes ialah set data pemanduan autonomi berskala besar untuk pengesanan dan penjejakan 3D, yang mengandungi 700, 150 dan 150, kesahihan, dan digunakan untuk latihan. Setiap bingkai mengandungi awan titik lidar dan enam imej penentukuran yang meliputi medan pandangan mendatar 360 darjah. Untuk pengesanan 3D, metrik utama ialah purata ketepatan purata (mAP) dan skor pengesanan nuScenes (NDS). mAP ditakrifkan oleh jarak pusat BEV dan bukannya IoU 3D, dan mAP akhir dikira dengan purata ambang jarak 0.5m, 1m, 2m, 4m untuk 10 kategori. NDS ialah ukuran komprehensif bagi mAP dan ukuran atribut lain, termasuk terjemahan, skala, orientasi, halaju dan atribut kotak lain. .
Dataset Waymo termasuk 798 babak untuk latihan dan 202 babak untuk pengesahan. Penunjuk rasmi ialah mAP dan mAPH (mAP ditimbang mengikut ketepatan tajuk). mAP dan mAPH ditakrifkan berdasarkan ambang IoU 3D, iaitu 0.7 untuk kenderaan dan 0.5 untuk pejalan kaki dan penunggang basikal. Metrik ini dipecahkan lagi kepada dua tahap kesukaran: LEVEL1 untuk kotak sempadan dengan lebih daripada 5 mata lidar dan LEVEL2 untuk kotak sempadan dengan sekurang-kurangnya satu titik lidar. Tidak seperti kamera 360 darjah nuScenes, kamera Waymo hanya meliputi kira-kira 250 darjah secara mendatar.
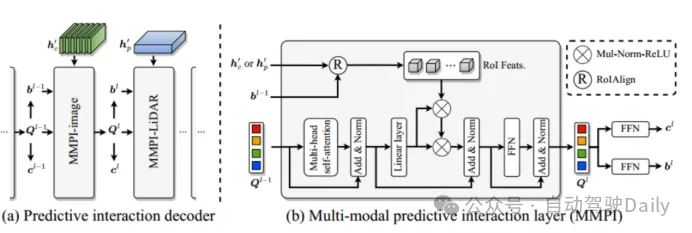
Latihan Pada set data nuScenes, gunakan DLA34 sebagai rangkaian tulang belakang 2D imej dan bekukan pemberatnya, tetapkan saiz imej kepada 448×800; pilih VoxelNet sebagai rangkaian tulang belakang 3D lidar. Proses latihan dibahagikan kepada dua peringkat: peringkat pertama hanya menggunakan data LiDAR sebagai input, dan menggunakan penyahkod lapisan pertama dan rangkaian suapan FFN untuk melatih tulang belakang 3D sebanyak 20 kali untuk menjana ramalan kotak sempadan 3D awal; -Kamera Modul pemulaan pertanyaan gabungan dan berpandukan imej dilatih selama 6 kali. Imej kiri ialah seni bina lapisan penyahkod transformer yang digunakan untuk ramalan kotak sempadan awal; imej kanan ialah seni bina lapisan penyahkod pengubah yang digunakan untuk gabungan LiDAR-Camera.
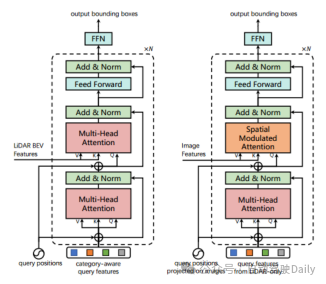
Figure 3 Reka Bentuk Lapisan Decoder
Perbandingan dengan kaedah terkini
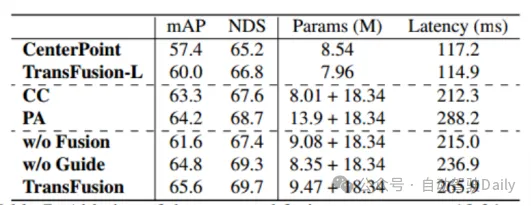
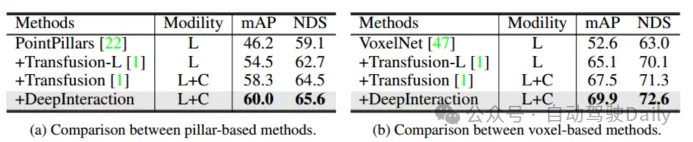
First Bandingkan prestasi transfusi dan kaedah SOTA lain pada tugas pengesanan objek 3D. set ujian nuScenes , dapat dilihat bahawa kaedah ini telah mencapai prestasi terbaik pada masa itu (mAP ialah 68.9%, NDS ialah 71.7%). TransFusion-L hanya menggunakan lidar untuk pengesanan, dan prestasi pengesanannya jauh lebih baik daripada kaedah pengesanan mod tunggal sebelumnya, malah melebihi beberapa kaedah berbilang modal Ini disebabkan terutamanya oleh mekanisme perkaitan dan strategi pemulaan pertanyaan. Jadual 2 menunjukkan keputusan TAHAP 2 mAPH pada set pengesahan Waymo. Perbandingan Jadual 1 dengan kaedah SOTA dalam ujian nuScenes rangka kerja gabungan yang berbeza adalah direka untuk mengesahkan, kekukuhan. Tiga rangka kerja gabungan ialah penyambungan titik demi titik dan gabungan ciri lidar dan imej (CC), strategi gabungan peningkatan titik (PA) dan TransFusion. Seperti yang ditunjukkan dalam Jadual 3, dengan membahagikan set data nuScenes kepada siang dan malam, kaedah TransFusion akan membawa peningkatan prestasi yang lebih besar pada waktu malam. Semasa proses inferens, ciri-ciri imej ditetapkan kepada sifar untuk mencapai kesan membuang secara rawak beberapa imej dalam setiap bingkai Seperti yang dapat dilihat dalam Jadual 4, apabila beberapa imej tidak tersedia semasa proses inferens, prestasi pengesanan. akan menurun dengan ketara, di mana mAP CC dan PA masing-masing turun sebanyak 23.8% dan 17.2%, manakala TransFusion kekal pada 61.7%. Penderia yang tidak ditentukur juga akan sangat mempengaruhi prestasi pengesanan sasaran 3D Tetapan eksperimen secara rawak menambah offset terjemahan kepada matriks transformasi daripada kamera ke lidar, seperti yang ditunjukkan dalam Rajah 4. Apabila kedua-dua sensor diimbangi oleh 1m, mAP. TransFusion Ia hanya menurun sebanyak 0.49%, manakala mAP PA dan CC masing-masing menurun sebanyak 2.33% dan 2.85%.
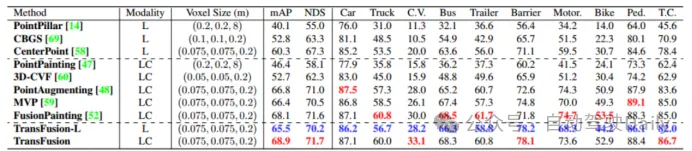
Jadual 3 mAP pada waktu siang dan malam

Jadual 4 mAP di bawah bilangan imej yang berbeza
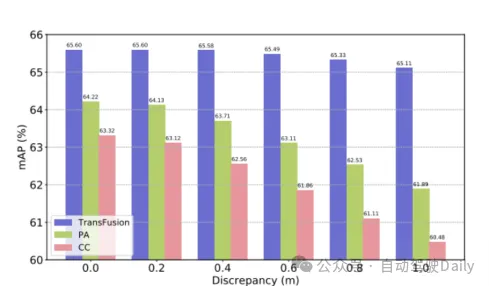
Rajah 4 mAP di bawah penjajaran penderia
Ia boleh melakukan eksperimen dengan jadual
) f) dapat dilihat daripada keputusan bahawa tanpa pemulaan pertanyaan, prestasi pengesanan menurun dengan banyak Walaupun meningkatkan bilangan pusingan latihan dan bilangan lapisan penyahkod boleh meningkatkan prestasi, ia masih tidak dapat mencapai kesan yang ideal, yang juga bermakna Ia terbukti. dari sisi bahawa strategi pertanyaan permulaan yang dicadangkan boleh mengurangkan bilangan lapisan rangkaian. Seperti yang ditunjukkan dalam Jadual 6, gabungan ciri imej dan pemulaan pertanyaan berpandukan imej membawa keuntungan mAP masing-masing sebanyak 4.8% dan 1.6%. Dalam Jadual 7, melalui perbandingan ketepatan dalam julat yang berbeza, prestasi pengesanan TransFusion dalam objek yang sukar dikesan atau kawasan terpencil telah dipertingkatkan berbanding pengesanan lidar sahaja.
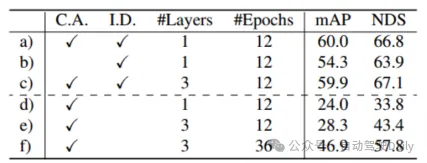
Jadual 5 Eksperimen ablasi modul permulaan pertanyaan
Jadual 6 Eksperimen ablasi bahagian gabungan

Jadual 7 Jarak antara objek
Jadual 7 Jarak antara objek Kesimpulan
Rangka kerja pengesanan 3D kamera lidar berasaskan Transformer yang berkesan dan teguh direka bentuk dengan mekanisme korelasi lembut yang boleh menyesuaikan secara adaptif lokasi dan maklumat yang perlu diperoleh daripada imej. TransFusion mencapai hasil terkini pada papan pendahulu pengesanan dan penjejakan nuScenes serta menunjukkan hasil yang kompetitif pada penanda aras pengesanan Waymo. Eksperimen ablasi yang meluas menunjukkan keteguhan kaedah ini kepada keadaan imej yang buruk.DeepInteraction:
Sumbangan Utama:
Masalah utama yang diselesaikan ialah strategi gabungan pelbagai mod sedia ada mengabaikan maklumat berguna khusus modaliti, akhirnya menghalang prestasi model. Awan titik menyediakan kedudukan yang diperlukan dan maklumat geometri pada peleraian rendah, dan imej memberikan maklumat rupa yang kaya pada resolusi tinggi, jadi gabungan maklumat rentas modal amat penting untuk meningkatkan prestasi pengesanan sasaran 3D. Modul gabungan sedia ada, seperti yang ditunjukkan dalam Rajah 1(a), mengintegrasikan maklumat kedua-dua modaliti ke dalam ruang rangkaian bersatu Walau bagaimanapun, berbuat demikian akan menghalang beberapa maklumat daripada disepadukan ke dalam perwakilan bersatu, mengurangkan beberapa maklumat khusus. Kelebihan perwakilan modaliti. Untuk mengatasi batasan di atas, artikel mencadangkan modul interaksi modal baharu (Rajah 1(b) Idea utama ialah mempelajari dan mengekalkan dua perwakilan khusus modaliti untuk mencapai interaksi antara modaliti. Sumbangan utama adalah seperti berikut:- mencadangkan strategi interaksi modal baharu untuk pengesanan sasaran 3D berbilang modal, bertujuan untuk menyelesaikan had asas strategi gabungan modal sebelumnya yang kehilangan maklumat berguna dalam setiap modaliti
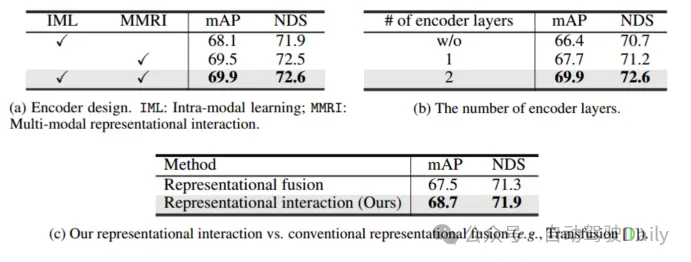
- direka seni bina Interaksi Dalam pengekod interaktif ciri berbilang modal dan penyahkod interaktif ramalan ciri berbilang modal. . dua maklumat adegan khusus modaliti yang diekstrak digunakan sebagai input, dan dua maklumat ciri yang dipertingkatkan dijana. Setiap lapisan pengekod merangkumi: i) interaksi ciri berbilang modal (MMRI); ii) pembelajaran ciri intra-modal iii) penyepaduan perwakilan.
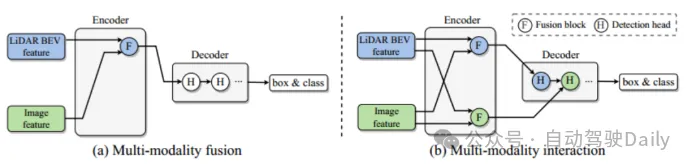
Rajah 2 Modul interaksi perwakilan multimod
.
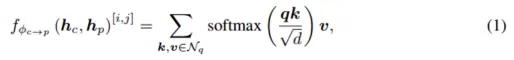
Rangkaian tulang belakang imej ialah ResNet50 Untuk menjimatkan kos pengkomputeran, imej input diubah saiznya kepada 1/2 daripada saiz asal sebelum memasuki rangkaian, dan berat cabang imej dibekukan semasa. latihan. Saiz voxel ditetapkan kepada (0.075m, 0.075m, 0.2m), julat pengesanan ditetapkan kepada [-54m, 54m] untuk paksi-X dan paksi-Y, dan [-5m, 3m] untuk Z- paksi. Reka bentuk 2 lapisan lapisan pengekod dan 5 lapisan penyahkod. Selain itu, dua model ujian penyerahan dalam talian disediakan: peningkatan masa ujian (TTA) dan penyepaduan model, dan kedua-dua tetapan itu masing-masing dipanggil DeepInteraction-large dan DeepInteraction-e. Antaranya, DeepInteraction-large menggunakan Swin-Tiny sebagai rangkaian tulang belakang imej, dan menggandakan bilangan saluran blok konvolusi dalam rangkaian tulang belakang lidar Saiz voxel ditetapkan kepada [0.5m, 0.5m, 0.2m], dan membalikkan dua arah dan Putar sudut yaw [0°, ±6.25°, ±12.5°] untuk meningkatkan masa ujian. DeepInteraction-e menyepadukan berbilang model DeepInteraction-besar, dan saiz grid BEV lidar input ialah [0.5m, 0.5m] dan [1.5m, 1.5m]. 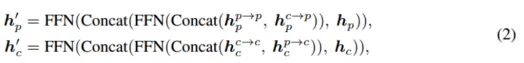

Jadual 1 Perbandingan dengan kaedah terkini pada set ujian nuScenesSeperti yang ditunjukkan dalam Jadual 1, Interaksi Dalam mencapai keadaan prestasi seni dalam semua tetapan. Jadual 2 membandingkan kelajuan inferens yang diuji pada NVIDIA V100, A6000 dan A100 masing-masing. Dapat dilihat bahawa semasa mencapai prestasi tinggi, kelajuan inferens yang tinggi masih dikekalkan, yang mengesahkan bahawa kaedah ini mencapai pertukaran unggul antara prestasi pengesanan dan kelajuan inferens. . dan kegunaan reka bentuk hibrid: lapisan penyahkod DETR biasa digunakan untuk mengagregat ciri dalam perwakilan lidar, dan penyahkod ramalan interaktif multimodal (MMPI) digunakan untuk mengagregat ciri dalam perwakilan imej (baris kedua). MMPI jauh lebih baik daripada DETR, meningkatkan 1.3% mAP dan 1.0% NDS, dengan fleksibiliti gabungan reka bentuk. Jadual 3(c) meneroka lebih lanjut kesan lapisan penyahkod yang berbeza pada prestasi pengesanan Ia boleh didapati bahawa prestasi terus bertambah baik apabila menambah 5 lapisan penyahkod. Akhirnya, kombinasi nombor pertanyaan yang berbeza yang digunakan dalam latihan dan ujian telah dibandingkan Di bawah pilihan yang berbeza, prestasi adalah stabil, tetapi 200/300 digunakan sebagai tetapan optimum untuk latihan/ujian. . meningkatkan prestasi dengan ketara; (2) MMRI dan IML boleh bekerjasama dengan baik untuk meningkatkan lagi prestasi. Seperti yang dapat dilihat daripada Jadual 4(b), menyusun lapisan pengekod untuk MMRI berulang adalah berfaedah.
Jadual 4 Eksperimen ablasi pengekod
Eksperimen ablasi rangkaian tulang belakang lidar
Menggunakan dua rangkaian tulang belakang lidar berbeza: PointPillar dan VoxelNet untuk menyemak keluasan rangka kerja. Untuk PointPillars, tetapkan saiz voxel kepada (0.2m, 0.2m) sambil mengekalkan tetapan selebihnya sama seperti DeepInteraction-base. Disebabkan oleh strategi interaksi berbilang mod yang dicadangkan, DeepInteraction menunjukkan peningkatan yang konsisten ke atas garis dasar lidar sahaja apabila menggunakan sama ada tulang belakang (5.5% mAP untuk tulang belakang berasaskan voxel dan 4.4% mAP untuk tulang belakang berasaskan tiang) ). Ini mencerminkan fleksibiliti DeepInteraction antara pengekod awan titik yang berbeza. . Idea utama adalah untuk mengekalkan dua perwakilan khusus modaliti dan mewujudkan interaksi antara mereka untuk pembelajaran perwakilan dan penyahkodan ramalan. Strategi ini direka khusus untuk menangani had asas kaedah gabungan satu sisi yang sedia ada, iaitu perwakilan imej kurang digunakan kerana pemprosesan aksara sumber tambahannya.
 Ringkasan kedua-dua kertas kerja:
Ringkasan kedua-dua kertas kerja:
Atas ialah kandungan terperinci Bagaimana untuk menggunakan pengubah untuk mengaitkan ciri radar-visual gelombang lidar-milimeter dengan berkesan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Ditulis di atas & pemahaman peribadi pengarang Gaussiansplatting tiga dimensi (3DGS) ialah teknologi transformatif yang telah muncul dalam bidang medan sinaran eksplisit dan grafik komputer dalam beberapa tahun kebelakangan ini. Kaedah inovatif ini dicirikan oleh penggunaan berjuta-juta Gaussians 3D, yang sangat berbeza daripada kaedah medan sinaran saraf (NeRF), yang terutamanya menggunakan model berasaskan koordinat tersirat untuk memetakan koordinat spatial kepada nilai piksel. Dengan perwakilan adegan yang eksplisit dan algoritma pemaparan yang boleh dibezakan, 3DGS bukan sahaja menjamin keupayaan pemaparan masa nyata, tetapi juga memperkenalkan tahap kawalan dan pengeditan adegan yang tidak pernah berlaku sebelum ini. Ini meletakkan 3DGS sebagai penukar permainan yang berpotensi untuk pembinaan semula dan perwakilan 3D generasi akan datang. Untuk tujuan ini, kami menyediakan gambaran keseluruhan sistematik tentang perkembangan dan kebimbangan terkini dalam bidang 3DGS buat kali pertama.
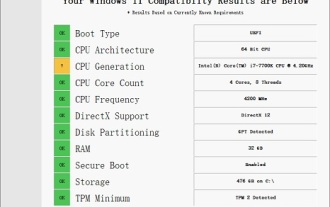 Penyelesaian kepada i7-7700 tidak dapat menaik taraf kepada Windows 11
Dec 26, 2023 pm 06:52 PM
Penyelesaian kepada i7-7700 tidak dapat menaik taraf kepada Windows 11
Dec 26, 2023 pm 06:52 PM
Prestasi i77700 adalah mencukupi untuk menjalankan win11, tetapi pengguna mendapati bahawa i77700 mereka tidak boleh dinaik taraf kepada win11 Ini terutamanya disebabkan oleh sekatan yang dikenakan oleh Microsoft, jadi mereka boleh memasangnya selagi mereka melangkau sekatan ini. i77700 tidak boleh dinaik taraf kepada win11: 1. Kerana Microsoft mengehadkan versi CPU. 2. Hanya Intel generasi kelapan dan versi ke atas boleh terus menaik taraf kepada win11 3. Sebagai generasi ke-7, i77700 tidak dapat memenuhi keperluan naik taraf win11. 4. Walau bagaimanapun, i77700 benar-benar mampu menggunakan win11 dengan lancar dari segi prestasi. 5. Jadi anda boleh menggunakan sistem pemasangan langsung win11 laman web ini. 6. Selepas muat turun selesai, klik kanan fail dan "muat"nya. 7. Klik dua kali untuk menjalankan "Satu klik
 Ketahui tentang emoji Fasih 3D dalam Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Ketahui tentang emoji Fasih 3D dalam Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Anda mesti ingat, terutamanya jika anda adalah pengguna Teams, bahawa Microsoft telah menambah kumpulan baharu emoji 3DFluent pada apl persidangan video tertumpu kerjanya. Selepas Microsoft mengumumkan emoji 3D untuk Pasukan dan Windows tahun lepas, proses itu sebenarnya telah melihat lebih daripada 1,800 emoji sedia ada dikemas kini untuk platform. Idea besar ini dan pelancaran kemas kini emoji 3DFluent untuk Pasukan pertama kali dipromosikan melalui catatan blog rasmi. Kemas kini Pasukan Terkini membawa FluentEmojis ke aplikasi Microsoft mengatakan 1,800 emoji yang dikemas kini akan tersedia kepada kami setiap hari
 Pengesanan jatuh, berdasarkan pengecaman tindakan manusia titik rangka, sebahagian daripada kod dilengkapkan dengan Chatgpt
Apr 12, 2023 am 08:19 AM
Pengesanan jatuh, berdasarkan pengecaman tindakan manusia titik rangka, sebahagian daripada kod dilengkapkan dengan Chatgpt
Apr 12, 2023 am 08:19 AM
Salam semua. Hari ini saya ingin berkongsi dengan anda projek pengesanan jatuh, tepatnya, ia adalah pengecaman pergerakan manusia berdasarkan titik rangka. Ia secara kasarnya dibahagikan kepada tiga langkah: pengecaman badan manusia, kod sumber projek pengelasan titik rangka manusia telah dibungkus, lihat penghujung artikel untuk cara mendapatkannya. 0. chatgpt Pertama, kita perlu mendapatkan aliran video yang dipantau. Kod ini agak tetap. Kita boleh terus chatgpt melengkapkan kod yang ditulis oleh chatgpt Tiada masalah dan boleh digunakan terus. Tetapi apabila ia datang kepada tugas perniagaan kemudian, seperti menggunakan mediapipe untuk mengenal pasti titik rangka manusia, kod yang diberikan oleh chatgpt adalah tidak betul. Saya rasa chatgpt boleh digunakan sebagai kotak alat yang bebas daripada logik perniagaan Anda boleh cuba menyerahkannya kepada c
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Cat 3D dalam Windows 11: Muat Turun, Pemasangan dan Panduan Penggunaan
Apr 26, 2023 am 11:28 AM
Cat 3D dalam Windows 11: Muat Turun, Pemasangan dan Panduan Penggunaan
Apr 26, 2023 am 11:28 AM
Apabila gosip mula tersebar bahawa Windows 11 baharu sedang dibangunkan, setiap pengguna Microsoft ingin tahu bagaimana rupa sistem pengendalian baharu itu dan apa yang akan dibawanya. Selepas spekulasi, Windows 11 ada di sini. Sistem pengendalian datang dengan reka bentuk baharu dan perubahan fungsi. Selain beberapa tambahan, ia disertakan dengan penamatan dan pengalihan keluar ciri. Salah satu ciri yang tidak wujud dalam Windows 11 ialah Paint3D. Walaupun ia masih menawarkan Paint klasik, yang bagus untuk laci, doodle dan doodle, ia meninggalkan Paint3D, yang menawarkan ciri tambahan yang sesuai untuk pencipta 3D. Jika anda mencari beberapa ciri tambahan, kami mengesyorkan Autodesk Maya sebagai perisian reka bentuk 3D terbaik. suka
 Karya terbaharu MIT: menggunakan GPT-3.5 untuk menyelesaikan masalah pengesanan anomali siri masa
Jun 08, 2024 pm 06:09 PM
Karya terbaharu MIT: menggunakan GPT-3.5 untuk menyelesaikan masalah pengesanan anomali siri masa
Jun 08, 2024 pm 06:09 PM
Hari ini saya ingin memperkenalkan kepada anda artikel yang diterbitkan oleh MIT minggu lepas, menggunakan GPT-3.5-turbo untuk menyelesaikan masalah pengesanan anomali siri masa, dan pada mulanya mengesahkan keberkesanan LLM dalam pengesanan anomali siri masa. Tiada penalaan dalam keseluruhan proses, dan GPT-3.5-turbo digunakan secara langsung untuk pengesanan anomali Inti artikel ini ialah cara menukar siri masa kepada input yang boleh dikenali oleh GPT-3.5-turbo, dan cara mereka bentuk. gesaan atau saluran paip untuk membenarkan LLM menyelesaikan tugas pengesanan anomali. Izinkan saya memperkenalkan karya ini kepada anda secara terperinci. Tajuk kertas imej: Largelanguagemodelscanbezero-shotanomalydete
