
 Peranti teknologi
AI
Di luar BEVFusion! DifFUSER: Model resapan memasuki pelbagai tugas pemanduan autonomi (segmen BEV + pengesanan dwi SOTA)
Peranti teknologi
AI
Di luar BEVFusion! DifFUSER: Model resapan memasuki pelbagai tugas pemanduan autonomi (segmen BEV + pengesanan dwi SOTA)
Di luar BEVFusion! DifFUSER: Model resapan memasuki pelbagai tugas pemanduan autonomi (segmen BEV + pengesanan dwi SOTA)

Ditulis di hadapan & pemahaman peribadi pengarang
Pada masa ini, apabila teknologi pemanduan autonomi menjadi lebih matang dan permintaan untuk tugas persepsi pemanduan autonomi meningkat, industri dan akademia sangat berharap untuk model algoritma persepsi ideal yang boleh Melengkapkan serentak pengesanan sasaran tiga dimensi dan tugas pembahagian semantik berdasarkan ruang BEV. Untuk kenderaan yang mampu memandu autonomi, ia biasanya dilengkapi dengan penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul data dalam kaedah yang berbeza. Dengan cara ini, kelebihan pelengkap antara data modal yang berbeza boleh digunakan sepenuhnya, supaya kelebihan pelengkap data antara modaliti yang berbeza boleh dicapai Contohnya, data awan titik 3D boleh memberikan maklumat untuk tugas pengesanan sasaran 3D, manakala data imej berwarna boleh memberikan lebih banyak maklumat untuk tugasan segmentasi semantik maklumat yang tepat. Memandangkan kelebihan pelengkap antara data modal yang berbeza, dengan menukar maklumat berkesan data modal yang berbeza ke dalam sistem koordinat yang sama, pemprosesan bersama seterusnya dan membuat keputusan dipermudahkan. Sebagai contoh, data awan titik 3D boleh ditukar menjadi data awan titik berdasarkan ruang BEV, dan data imej daripada kamera pandangan sekeliling boleh ditayangkan ke dalam ruang 3D melalui penentukuran parameter dalaman dan luaran kamera, dengan itu mencapai pemprosesan bersatu data modal yang berbeza. Dengan memanfaatkan data modal yang berbeza, hasil persepsi yang lebih tepat boleh diperolehi daripada data modal tunggal. Kini, kami sudah boleh menggunakan model algoritma persepsi pelbagai mod pada kereta untuk mengeluarkan hasil persepsi ruang yang lebih mantap dan tepat Melalui hasil persepsi ruang yang tepat, kami boleh memberikan jaminan yang lebih dipercayai dan selamat untuk merealisasikan fungsi pemanduan autonomi.
Walaupun banyak algoritma persepsi 3D untuk gabungan data berbilang deria dan berbilang modal berdasarkan rangka kerja rangkaian Transformer baru-baru ini telah dicadangkan dalam akademik dan industri, kesemuanya menggunakan mekanisme perhatian silang dalam Transformer untuk mencapai penyepaduan data berbilang modal. gabungan antara mereka untuk mencapai hasil pengesanan sasaran 3D yang ideal. Walau bagaimanapun, kaedah gabungan ciri berbilang modal jenis ini tidak sesuai sepenuhnya untuk tugasan segmentasi semantik berdasarkan ruang BEV. Di samping itu, selain menggunakan mekanisme perhatian silang untuk melengkapkan gabungan maklumat antara modaliti yang berbeza, banyak algoritma menggunakan penukaran vektor ke hadapan dalam LSA untuk membina ciri bercantum, tetapi terdapat juga beberapa masalah seperti berikut: (Batasan bilangan perkataan, penerangan terperinci berikut ).
- Disebabkan algoritma penderiaan 3D yang dicadangkan pada masa ini berkaitan dengan gabungan pelbagai mod, kaedah gabungan ciri data modal yang berbeza tidak direka bentuk dengan secukupnya, mengakibatkan model algoritma persepsi tidak dapat menangkap dengan tepat hubungan sambungan kompleks antara data sensor, dan dengan itu Mempengaruhi prestasi akhir model.
- Dalam proses mengumpul data daripada penderia yang berbeza, maklumat hingar yang tidak berkaitan pasti akan diperkenalkan kebisingan yang wujud antara modaliti yang berbeza ini juga akan menyebabkan hingar bercampur ke dalam proses gabungan ciri-ciri modal yang berbeza, menghasilkan gabungan ciri berbilang modal. .Ketidaktepatan menjejaskan tugas persepsi seterusnya.
Memandangkan banyak masalah yang dinyatakan di atas dalam proses gabungan pelbagai mod yang mungkin menjejaskan keupayaan persepsi model akhir, dan mengambil kira prestasi berkuasa yang ditunjukkan baru-baru ini oleh model generatif, kami meneroka model generatif menggunakan Ia digunakan untuk mencapai gabungan pelbagai mod dan tugasan penolakan antara berbilang penderia. Berdasarkan ini, kami mencadangkan algoritma persepsi model generatif DifFUSER berdasarkan penyebaran bersyarat untuk melaksanakan tugas persepsi pelbagai mod. Seperti yang dapat dilihat daripada rajah di bawah, algoritma gabungan data berbilang modal DifFUSER yang kami cadangkan boleh mencapai proses gabungan pelbagai mod yang lebih berkesan.  Algoritma gabungan data multimodal DifFUSER boleh mencapai proses gabungan multimodal yang lebih berkesan Kaedah ini merangkumi dua peringkat. Pertama, kami menggunakan model generatif untuk mengecilkan dan meningkatkan data input, menjana data multimodal yang bersih dan kaya. Kemudian, data yang dijana oleh model generatif digunakan untuk gabungan pelbagai modal untuk mencapai kesan persepsi yang lebih baik. Keputusan percubaan algoritma DifFUSER menunjukkan bahawa algoritma gabungan data berbilang modal yang kami cadangkan boleh mencapai proses gabungan berbilang modal yang lebih berkesan. Apabila melaksanakan tugas persepsi pelbagai modal, algoritma ini boleh mencapai proses gabungan pelbagai mod yang lebih berkesan dan meningkatkan keupayaan persepsi model. Di samping itu, algoritma gabungan data berbilang modal algoritma boleh mencapai proses gabungan berbilang modal yang lebih cekap. Secara keseluruhannya
Carta perbandingan visual hasil model algoritma yang dicadangkan dan model algoritma lain
Pautan kertas: https://arxiv.org/pdf/2404.04629.pdf
Keseluruhan seni bina & butiran model rangkaian
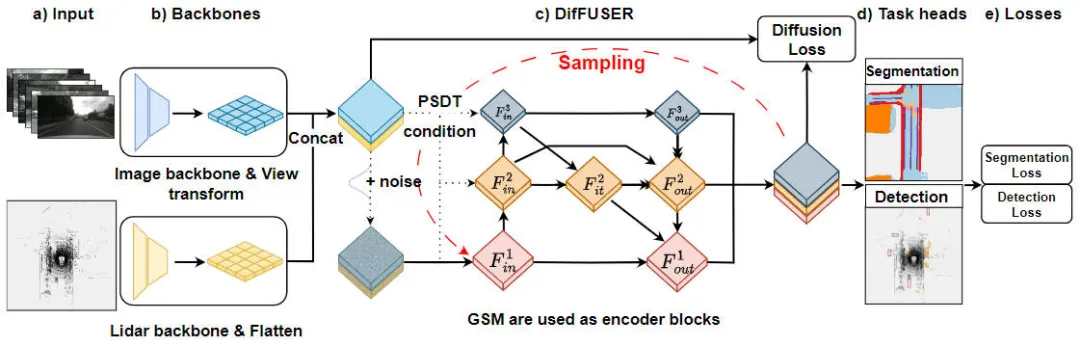
"Butiran modul algoritma DifFUSER, algoritma persepsi pelbagai tugas berdasarkan model resapan bersyarat" ialah algoritma yang digunakan untuk menyelesaikan masalah persepsi tugas. Rajah di bawah menunjukkan struktur rangkaian keseluruhan algoritma DifFUSER kami yang dicadangkan. Dalam modul ini, kami mencadangkan algoritma persepsi pelbagai tugas berdasarkan model resapan bersyarat untuk menyelesaikan masalah persepsi tugas. Matlamat algoritma ini adalah untuk meningkatkan prestasi pembelajaran pelbagai tugas dengan menyebarkan dan mengagregatkan maklumat khusus tugas dalam rangkaian. Penyepaduan algoritma DifFUSER
 Cadangan gambarajah struktur rangkaian model algoritma persepsi DifFUSER
Cadangan gambarajah struktur rangkaian model algoritma persepsi DifFUSER
Seperti yang dapat dilihat daripada rajah di atas, struktur rangkaian DifFUSER yang kami cadangkan terutamanya merangkumi tiga sub-rangkaian, iaitu bahagian rangkaian tulang belakang, bahagian gabungan data berbilang modal DifFUSER dan bahagian Ketua BEV akhir tugas pembahagian semantik. Ketua bahagian tugas persepsi pengesanan objek 3D. Di bahagian rangkaian tulang belakang, kami menggunakan seni bina rangkaian pembelajaran mendalam sedia ada, seperti ResNet atau VGG, untuk mengekstrak ciri peringkat tinggi data input. Bahagian gabungan data berbilang modal DifFUSER menggunakan berbilang cawangan selari, setiap cawangan digunakan untuk memproses jenis data penderia yang berbeza (seperti imej, lidar dan radar, dsb.). Setiap cawangan mempunyai bahagian rangkaian tulang belakangnya sendiri
- : Bahagian ini terutamanya melakukan pengekstrakan ciri pada input data imej 2D oleh model rangkaian dan data awan titik lidar 3D untuk mengeluarkan ciri semantik BEV yang sepadan. Untuk rangkaian tulang belakang yang mengekstrak ciri imej, ia termasuk rangkaian tulang belakang imej 2D dan modul penukaran perspektif. Untuk rangkaian tulang belakang yang mengekstrak ciri awan titik lidar 3D, ia termasuk rangkaian tulang belakang awan titik 3D dan modul Flatten ciri.
- Bahagian gabungan data berbilang mod DifFUSER: Modul DifFUSER yang kami cadangkan dipautkan bersama dalam bentuk rangkaian piramid ciri dua arah hierarki Kami memanggil struktur ini cMini-BiFPN. Struktur ini menyediakan struktur alternatif untuk potensi penyebaran dan boleh mengendalikan maklumat ciri terperinci berbilang skala dan ketinggian lebar daripada data penderia yang berbeza dengan lebih baik.
- Segmentasi semantik BEV, bahagian kepala tugas persepsi pengesanan sasaran 3D: Memandangkan model algoritma kami secara serentak boleh mengeluarkan hasil pengesanan sasaran 3D dan hasil segmentasi semantik dalam ruang BEV, ketua tugas persepsi 3D termasuk kepala pengesanan 3D dan kepala segmentasi semantik . Selain itu, kerugian yang terlibat dalam model algoritma yang kami cadangkan termasuk kehilangan resapan, kehilangan pengesanan dan kehilangan segmentasi semantik Dengan menjumlahkan semua kerugian, parameter model rangkaian dikemas kini melalui perambatan balik.
Seterusnya, kami akan memperkenalkan dengan teliti butiran pelaksanaan setiap sub-bahagian utama model.
Reka bentuk seni bina gabungan (Conditional-Mini-BiFPN, cMini-BiFPN)
Untuk tugas persepsi dalam sistem pemanduan autonomi, adalah penting bahawa model algoritma dapat melihat persekitaran luaran semasa dalam masa nyata, jadi Ia adalah sangat penting untuk memastikan prestasi dan kecekapan modul resapan. Oleh itu, kami diilhamkan oleh rangkaian piramid ciri dua hala dan memperkenalkan seni bina resapan BiFPN dengan keadaan yang sama, yang kami panggil Struktur rangkaian khususnya ditunjukkan dalam rajah di atas.


Latihan Keciciran Sensor Progresif (PSDT)
Untuk kenderaan autonomi, prestasi penderia pemerolehan pemanduan autonomi adalah penting semasa memandu harian, berkemungkinan besar kenderaan itu berautonomi sensor kamera atau sensor lidar akan disekat atau tidak berfungsi, yang akan menjejaskan keselamatan dan kecekapan pengendalian sistem pemanduan autonomi akhir. Berdasarkan pertimbangan ini, kami mencadangkan paradigma latihan keciciran sensor progresif untuk meningkatkan keteguhan dan kebolehsuaian model algoritma yang dicadangkan dalam situasi di mana sensor mungkin disekat.
Melalui paradigma latihan keciciran sensor progresif kami yang dicadangkan, model algoritma boleh membina semula ciri yang hilang dengan menggunakan pengedaran dua data modal yang dikumpul oleh sensor kamera dan sensor lidar, dengan itu mencapai penyesuaian yang sangat baik dalam prestasi dan keteguhan keadaan yang teruk. Khususnya, kami mengeksploitasi ciri daripada data imej dan data awan titik lidar dalam tiga cara berbeza, sebagai sasaran latihan, input hingar kepada modul resapan dan untuk mensimulasikan keadaan di mana penderia hilang atau tidak berfungsi Untuk mensimulasikan keadaan Kehilangan atau kegagalan sensor. kami secara beransur-ansur meningkatkan kadar kehilangan sensor kamera atau input sensor lidar daripada 0 kepada nilai maksimum yang telah ditetapkan a = 25 semasa latihan. Keseluruhan proses boleh dinyatakan dengan formula berikut:
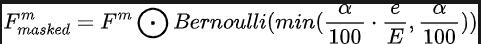
Antaranya, mewakili bilangan pusingan latihan yang model semasa berada, dan mentakrifkan kebarangkalian keciciran untuk mewakili kebarangkalian setiap ciri digugurkan. Melalui proses latihan progresif ini, model ini bukan sahaja dilatih untuk mengecilkan dan menjana ciri yang lebih ekspresif dengan berkesan, tetapi juga meminimumkan pergantungannya pada mana-mana penderia tunggal, dengan itu meningkatkan pengendalian penderia yang tidak lengkap dengan keupayaan Data yang lebih besar.
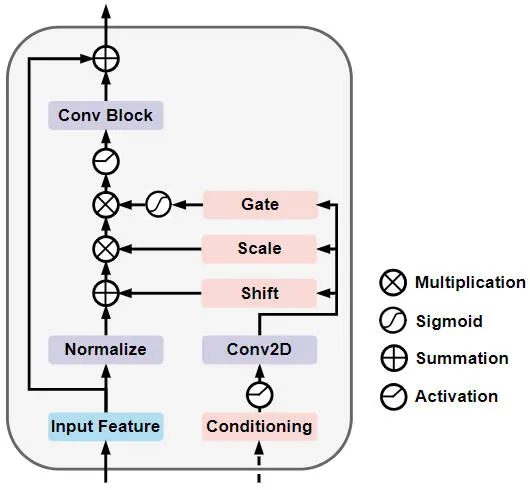
Modul Resapan Modulasi Berhawa Dingin Berpagar (Modul Resapan GSM)

Secara khusus, struktur rangkaian Modul Resapan Modulasi Berhawa Dingin Berpagar ditunjukkan dalam rajah di bawah
Gambarajah Skema Resapan Modulasi struktur rangkaian modul

Keputusan eksperimen & penunjuk penilaian
Bahagian analisis kuantitatif
Untuk mengesahkan keputusan persepsi DifksFUSER kami yang dicadangkan pada model yang dicadangkan pada data nuScenes set pengesanan sasaran 3D dan eksperimen segmentasi semantik berdasarkan ruang BEV.
Pertama sekali, kami membandingkan prestasi model algoritma DifFUSER yang dicadangkan dengan algoritma gabungan berbilang mod yang lain pada tugasan segmentasi semantik Keputusan eksperimen khusus ditunjukkan dalam jadual berikut:
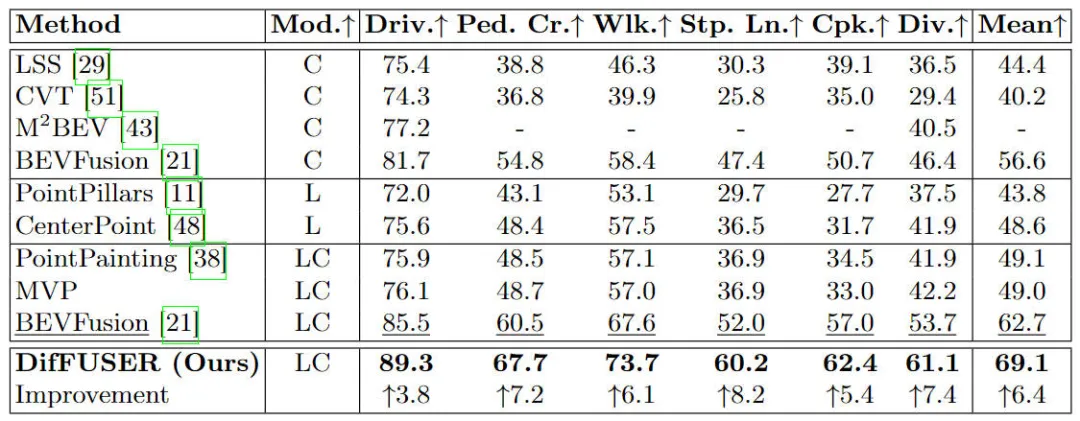 Model algoritma yang berbeza pada set data nuScenes Perbandingan. hasil eksperimen bagi tugasan segmentasi semantik berdasarkan ruang BEV
Model algoritma yang berbeza pada set data nuScenes Perbandingan. hasil eksperimen bagi tugasan segmentasi semantik berdasarkan ruang BEV
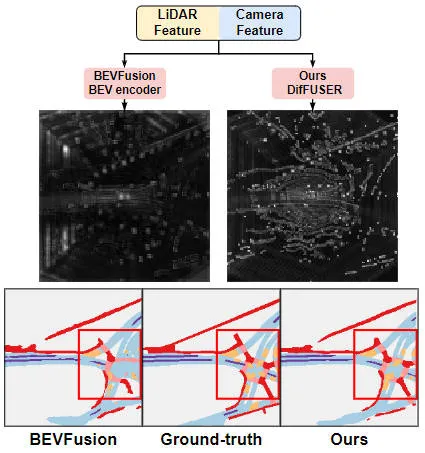
Dapat dilihat daripada keputusan eksperimen bahawa model algoritma yang kami cadangkan telah meningkatkan prestasi dengan ketara berbanding model garis dasar. Secara khusus, nilai mIoU model BEVFusion hanya 62.7%, manakala model algoritma yang kami cadangkan telah mencapai 69.1%, dengan peningkatan 6.4% mata, yang menunjukkan bahawa algoritma yang kami cadangkan mempunyai lebih banyak kelebihan dalam kategori yang berbeza. Di samping itu, rajah di bawah juga lebih intuitif menggambarkan kelebihan model algoritma yang kami cadangkan. Khususnya, algoritma BEVFusion akan mengeluarkan hasil pembahagian yang lemah, terutamanya dalam adegan jarak jauh, di mana salah jajaran sensor lebih jelas. Sebagai perbandingan, model algoritma kami mempunyai hasil pembahagian yang lebih tepat, dengan butiran yang lebih jelas dan kurang hingar.
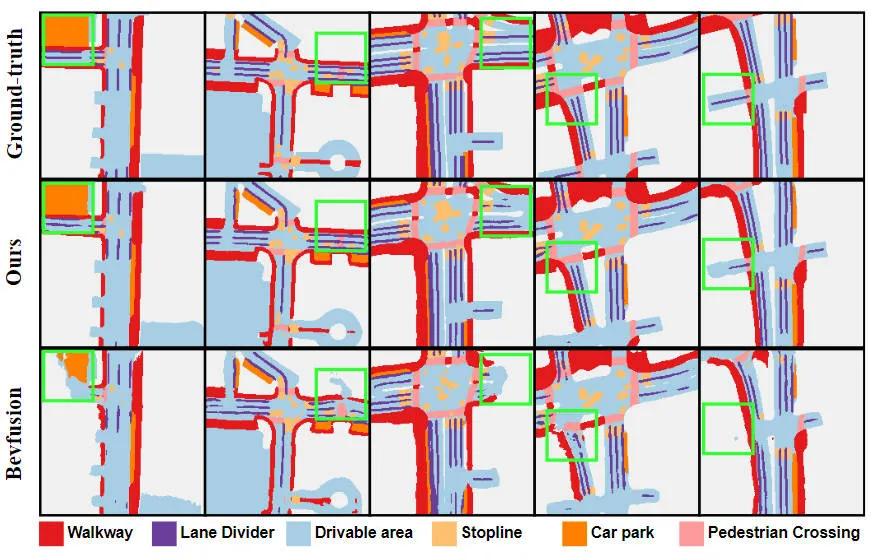
Perbandingan hasil visualisasi pembahagian model algoritma yang dicadangkan dan model garis dasar
Selain itu, kami juga membandingkan model algoritma yang dicadangkan dengan model algoritma pengesanan sasaran 3D yang lain Keputusan percubaan khusus ditunjukkan dalam jadual di bawah
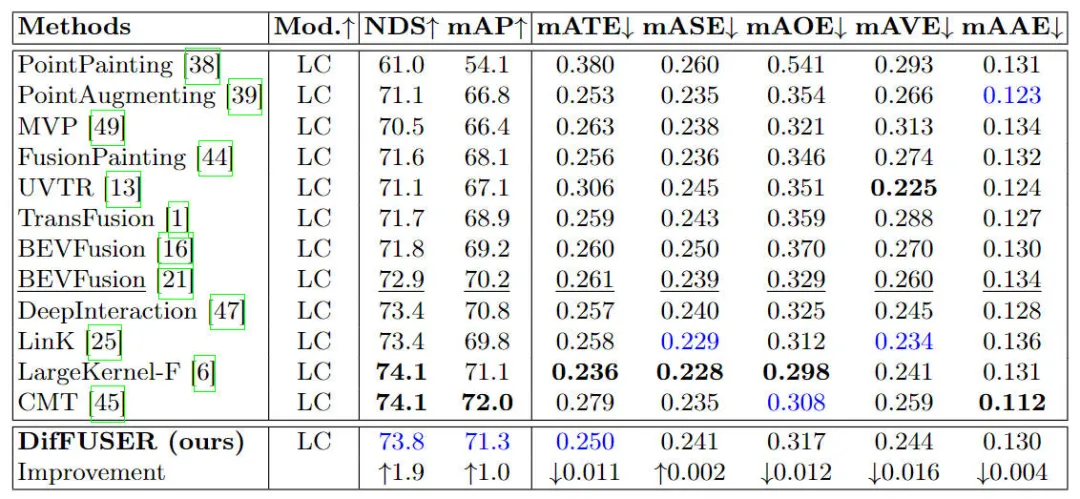
Perbandingan hasil percubaan model algoritma yang berbeza pada tugas pengesanan sasaran 3D pada dataset nuScenes
Seperti yang dapat dilihat daripada keputusan yang disenaraikan dalam jadual, model algoritma DifFUSER kami yang dicadangkan mempunyai prestasi yang lebih baik dalam kedua-dua NDS dan mAP penunjuk daripada model garis dasar Berbanding dengan 72.9% NDS dan 70.2% mAP model garis dasar BEVFusion, model algoritma kami masing-masing adalah 1.8% dan 1.0%. Penambahbaikan penunjuk yang berkaitan menunjukkan bahawa modul gabungan resapan pelbagai mod yang kami cadangkan berkesan dalam pengurangan ciri dan proses penghalusan ciri.
Selain itu, untuk menunjukkan keteguhan persepsi model algoritma kami yang dicadangkan dalam kes kegagalan sensor atau oklusi, kami membandingkan hasil tugasan segmentasi yang berkaitan, seperti yang ditunjukkan dalam rajah di bawah. . kandungan alternatif. Keupayaan model algoritma DifFUSER kami yang dicadangkan untuk menjana dan menggunakan ciri sintetik dengan berkesan mengurangkan pergantungan pada mana-mana modaliti penderia tunggal dan memastikan model boleh berjalan lancar dalam persekitaran yang pelbagai dan mencabar.
Bahagian analisis kualitatif
Rajah berikut menunjukkan visualisasi pengesanan sasaran 3D dan hasil segmentasi semantik ruang BEV model algoritma DifFUSER kami yang dicadangkan Ia boleh dilihat daripada hasil visualisasi bahawa model algoritma yang kami cadangkan mempunyai kebaikan pengesanan dan kesan Split.

Kesimpulan
Artikel ini mencadangkan model algoritma persepsi pelbagai mod DifFUSER berdasarkan model resapan, yang meningkatkan kualiti gabungan model rangkaian dengan menambah baik seni bina gabungan model rangkaian dan menggunakan sifat denoising daripada model resapan. Keputusan percubaan pada set data Nuscenes menunjukkan bahawa model algoritma yang kami cadangkan mencapai prestasi segmentasi SOTA dalam tugas segmentasi semantik ruang BEV, dan boleh mencapai prestasi pengesanan yang serupa dengan model algoritma SOTA semasa dalam tugas pengesanan sasaran 3D.
Atas ialah kandungan terperinci Di luar BEVFusion! DifFUSER: Model resapan memasuki pelbagai tugas pemanduan autonomi (segmen BEV + pengesanan dwi SOTA). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Tutorial Model Penyebaran Bernilai Masa Anda, dari Universiti Purdue
Apr 07, 2024 am 09:01 AM
Tutorial Model Penyebaran Bernilai Masa Anda, dari Universiti Purdue
Apr 07, 2024 am 09:01 AM
Penyebaran bukan sahaja boleh meniru lebih baik, tetapi juga "mencipta". Model resapan (DiffusionModel) ialah model penjanaan imej. Berbanding dengan algoritma yang terkenal seperti GAN dan VAE dalam bidang AI, model resapan mengambil pendekatan yang berbeza. Idea utamanya ialah proses menambah hingar pada imej dan kemudian secara beransur-ansur menolaknya. Cara mengecilkan dan memulihkan imej asal adalah bahagian teras algoritma. Algoritma akhir mampu menghasilkan imej daripada imej bising rawak. Dalam beberapa tahun kebelakangan ini, pertumbuhan luar biasa AI generatif telah membolehkan banyak aplikasi menarik dalam penjanaan teks ke imej, penjanaan video dan banyak lagi. Prinsip asas di sebalik alat generatif ini ialah konsep resapan, mekanisme pensampelan khas yang mengatasi batasan kaedah sebelumnya.
 Artikel yang meringkaskan aplikasi Model Resapan dalam siri masa
Mar 07, 2024 am 10:30 AM
Artikel yang meringkaskan aplikasi Model Resapan dalam siri masa
Mar 07, 2024 am 10:30 AM
Model resapan kini merupakan modul teras dalam AI generatif dan telah digunakan secara meluas dalam model AI generatif besar seperti Sora, DALL-E dan Imagen. Pada masa yang sama, model resapan semakin digunakan pada siri masa. Artikel ini memperkenalkan anda kepada idea asas model resapan, serta beberapa karya tipikal model resapan yang digunakan dalam siri masa, untuk membantu anda memahami prinsip aplikasi model resapan dalam siri masa. 1. Idea pemodelan model resapan Teras model generatif adalah untuk dapat mengambil sampel titik daripada taburan mudah rawak dan memetakan titik ini kepada imej atau sampel dalam ruang sasaran melalui satu siri transformasi. Kaedah model resapan adalah untuk membuang bunyi secara berterusan pada titik sampel sampel, dan selepas beberapa langkah penyingkiran hingar, data akhir dijana.
 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 Bagaimana untuk mempercepatkan BitGenie_Bagaimana untuk mempercepatkan kelajuan muat turun BitGenie
Apr 29, 2024 pm 02:58 PM
Bagaimana untuk mempercepatkan BitGenie_Bagaimana untuk mempercepatkan kelajuan muat turun BitGenie
Apr 29, 2024 pm 02:58 PM
1. Pertama sekali, pastikan benih BT anda sihat, mempunyai benih yang cukup, dan cukup popular, supaya ia memenuhi prasyarat untuk memuat turun BT dan kelajuannya pantas. Buka lajur "Pilih" BitComet anda sendiri, klik "Sambungan Rangkaian" dalam lajur pertama, dan laraskan kelajuan muat turun maksimum global kepada 1000 tanpa had (1000 untuk pengguna di bawah 2M adalah nombor yang tidak boleh dihubungi, tetapi tidak mengapa untuk tidak melaraskan ini, siapa yang tidak mahu memuat turunnya) Sangat pantas). Kelajuan muat naik maksimum boleh dilaraskan kepada 40 tanpa sebarang had (pilih yang sesuai berdasarkan keadaan peribadi, komputer akan membeku jika kelajuan terlalu pantas). 3. Klik Tetapan Tugas. Anda boleh melaraskan direktori muat turun lalai di dalamnya. 4. Klik Penampilan Antara Muka. Tukar bilangan maksimum rakan sebaya yang dipaparkan kepada 1000, iaitu untuk memaparkan butiran pengguna yang disambungkan kepada anda, supaya anda mempunyai ketenangan fikiran 5. Klik
 Apr 09, 2024 am 10:03 AM
Apr 09, 2024 am 10:03 AM
Arahan netsh digunakan untuk mengurus rangkaian dalam Windows 7 dan boleh melakukan perkara berikut: Lihat maklumat rangkaian Konfigurasikan tetapan TCP/IP Urus rangkaian wayarles Sediakan proksi rangkaian
 Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Pada bulan lalu, atas sebab-sebab yang diketahui umum, saya telah mengadakan pertukaran yang sangat intensif dengan pelbagai guru dan rakan sekelas dalam industri. Topik yang tidak dapat dielakkan dalam pertukaran secara semula jadi adalah hujung ke hujung dan Tesla FSDV12 yang popular. Saya ingin mengambil kesempatan ini untuk menyelesaikan beberapa buah fikiran dan pendapat saya pada masa ini untuk rujukan dan perbincangan anda. Bagaimana untuk mentakrifkan sistem pemanduan autonomi hujung ke hujung, dan apakah masalah yang sepatutnya dijangka diselesaikan hujung ke hujung? Menurut definisi yang paling tradisional, sistem hujung ke hujung merujuk kepada sistem yang memasukkan maklumat mentah daripada penderia dan secara langsung mengeluarkan pembolehubah yang membimbangkan tugas. Sebagai contoh, dalam pengecaman imej, CNN boleh dipanggil hujung-ke-hujung berbanding kaedah pengekstrak ciri + pengelas tradisional. Dalam tugas pemanduan autonomi, masukkan data daripada pelbagai penderia (kamera/LiDAR
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
Ditulis di hadapan & titik permulaan Paradigma hujung ke hujung menggunakan rangka kerja bersatu untuk mencapai pelbagai tugas dalam sistem pemanduan autonomi. Walaupun kesederhanaan dan kejelasan paradigma ini, prestasi kaedah pemanduan autonomi hujung ke hujung pada subtugas masih jauh ketinggalan berbanding kaedah tugasan tunggal. Pada masa yang sama, ciri pandangan mata burung (BEV) padat yang digunakan secara meluas dalam kaedah hujung ke hujung sebelum ini menyukarkan untuk membuat skala kepada lebih banyak modaliti atau tugasan. Paradigma pemanduan autonomi hujung ke hujung (SparseAD) tertumpu carian jarang dicadangkan di sini, di mana carian jarang mewakili sepenuhnya keseluruhan senario pemanduan, termasuk ruang, masa dan tugas, tanpa sebarang perwakilan BEV yang padat. Khususnya, seni bina jarang bersatu direka bentuk untuk kesedaran tugas termasuk pengesanan, penjejakan dan pemetaan dalam talian. Di samping itu, berat
