
 Peranti teknologi
AI
Penanda aras ujian baharu dikeluarkan, sumber terbuka paling berkuasa Llama 3 memalukan
Peranti teknologi
AI
Penanda aras ujian baharu dikeluarkan, sumber terbuka paling berkuasa Llama 3 memalukan
Penanda aras ujian baharu dikeluarkan, sumber terbuka paling berkuasa Llama 3 memalukan

Jika soalan ujian terlalu mudah, kedua-dua pelajar terbaik dan pelajar lemah boleh mendapat 90 mata, dan jurang tidak boleh dilebarkan...
Dengan keluaran model yang lebih kukuh seperti Claude 3, Llama 3 dan juga GPT-5 , industri memerlukan segera model yang lebih sukar, ujian penanda aras yang lebih berbeza.
LMSYS, organisasi di sebalik arena model besar, melancarkan penanda aras generasi akan datang Arena-Hard, yang menarik perhatian meluas.
Rujukan terkini juga tersedia untuk kekuatan dua versi arahan Llama 3 yang diperhalusi.
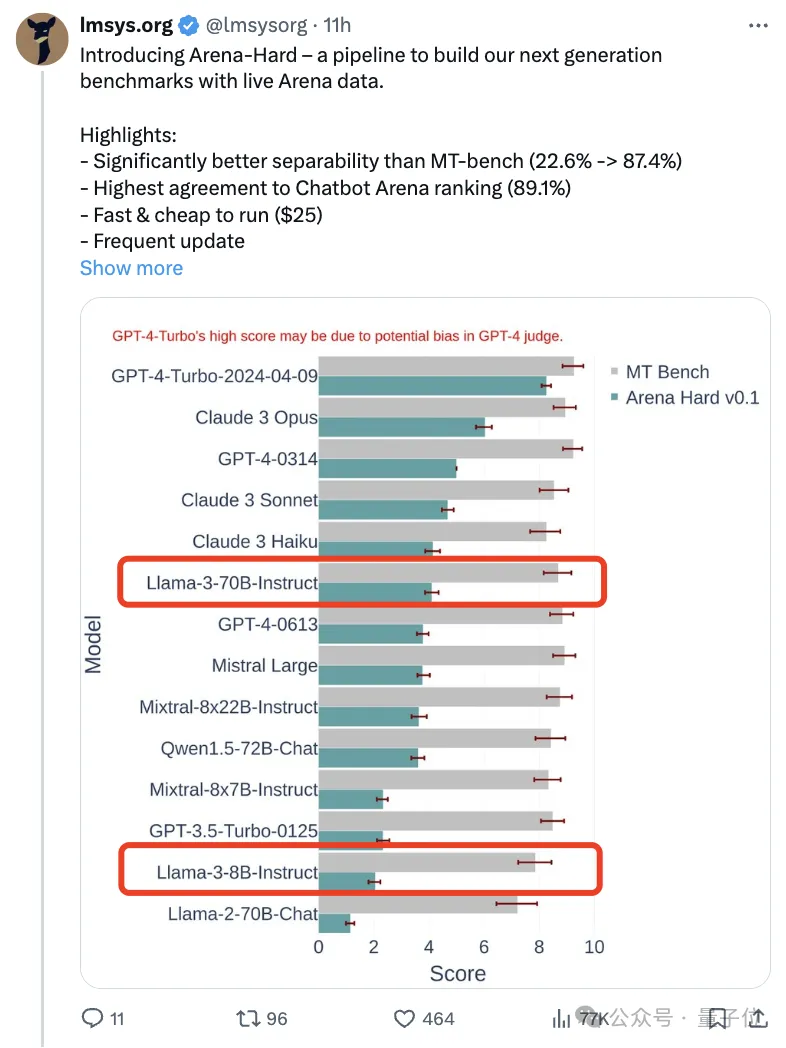
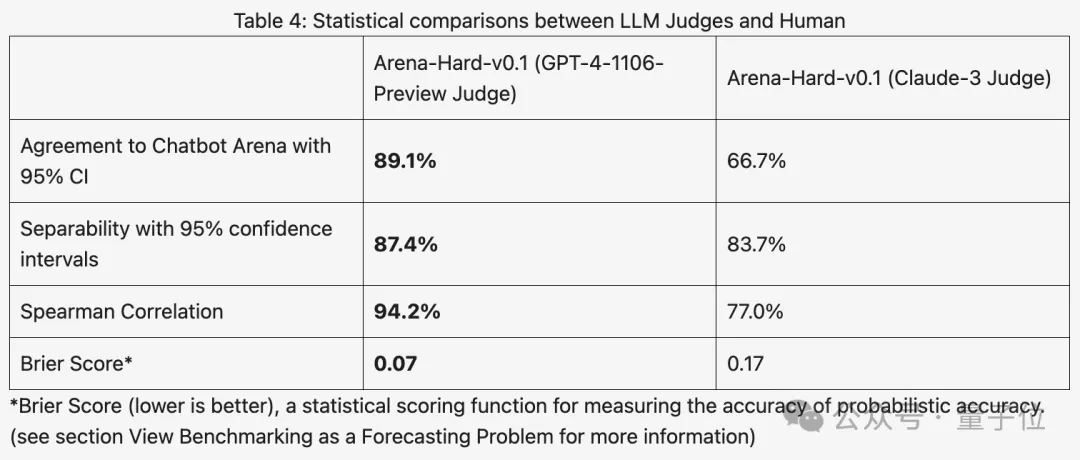
Berbanding dengan Bangku MT sebelumnya, yang mempunyai markah yang sama, diskriminasi Arena-Hard meningkat daripada 22.6% kepada 87.4%, yang jelas sekali imbas.
Arena-Hard dibina menggunakan data manusia masa nyata dari arena, dan kadar konsistensi dengan keutamaan manusia adalah setinggi 89.1%.
Sebagai tambahan kepada dua penunjuk di atas yang mencapai SOTA, terdapat faedah tambahan:
Data ujian masa nyata yang dikemas kini mengandungi kata-kata pantas yang baru difikirkan oleh manusia dan tidak pernah dilihat oleh AI semasa fasa latihan, mengurangkan potensi data Beri laluan .
Selepas mengeluarkan model baharu, tidak perlu lagi menunggu seminggu atau lebih untuk pengguna manusia mengundi, cuma belanjakan $25 untuk menjalankan saluran ujian dengan cepat dan dapatkan hasilnya.
Sesetengah netizen mengulas bahawa adalah sangat penting untuk menggunakan kata gesaan pengguna sebenar berbanding peperiksaan sekolah menengah untuk ujian.

Bagaimana penanda aras baharu berfungsi?
Ringkasnya, 500 perkataan gesaan berkualiti tinggi dipilih sebagai set ujian daripada 200,000 pertanyaan pengguna dalam arena model besar.
Pertama, pastikan kepelbagaian semasa proses pemilihan, iaitu set ujian harus meliputi pelbagai topik dunia sebenar.
Untuk memastikan ini, pasukan menggunakan saluran paip pemodelan topik dalam BERTopic, mula-mula menukar setiap petua menggunakan model pembenaman OpenAI (teks-benam-3-kecil), mengurangkan dimensi menggunakan UMAP dan pengelompokan menggunakan algoritma model berasaskan hierarki ( HDBSCAN) untuk mengenal pasti kelompok, dan akhirnya menggunakan GPT-4-turbo untuk pengagregatan.
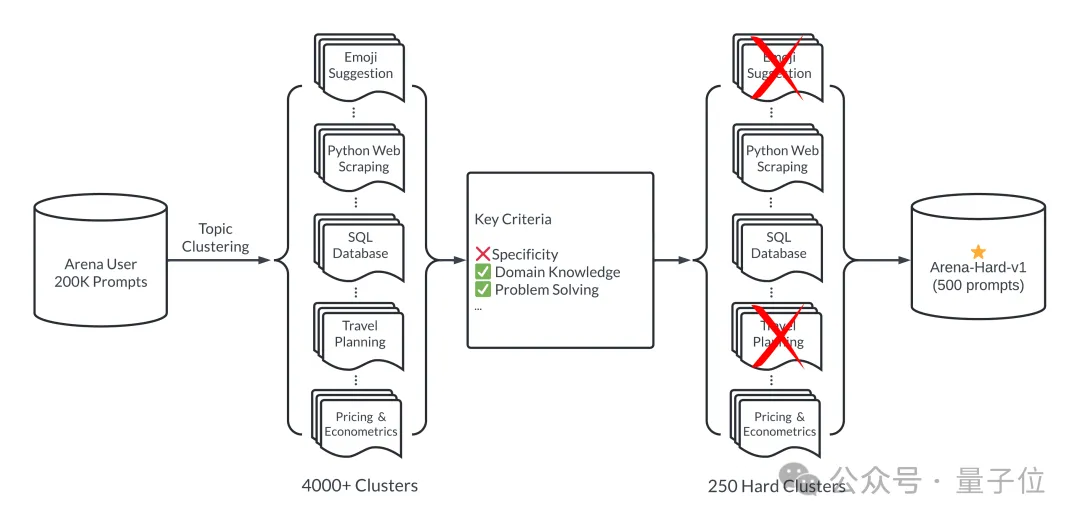
Juga pastikan bahawa kata gesaan yang dipilih adalah berkualiti tinggi, yang diukur dengan tujuh petunjuk utama:
- Kekhususan: Adakah perkataan gesaan memerlukan output khusus?
- Pengetahuan domain: Adakah perkataan gesaan meliputi satu atau lebih medan tertentu?
- Kerumitan: Adakah perkataan gesaan mempunyai pelbagai lapisan penaakulan, komponen atau pembolehubah?
- Penyelesaian masalah: Adakah perkataan segera membenarkan AI menunjukkan keupayaannya untuk menyelesaikan masalah secara proaktif?
- Kreativiti: Adakah kata gesaan melibatkan beberapa tahap kreativiti dalam penyelesaian masalah?
- Ketepatan Teknikal: Adakah perkataan segera memerlukan ketepatan teknikal bagi respons?
- Aplikasi Praktikal: Adakah kata-kata segera berkaitan dengan aplikasi praktikal?

Gunakan GPT-3.5-Turbo dan GPT-4-Turbo untuk menganotasi setiap petua dari 0 hingga 7 untuk menentukan bilangan syarat yang dipenuhi. Setiap kelompok kemudiannya dijaringkan berdasarkan skor purata isyarat.
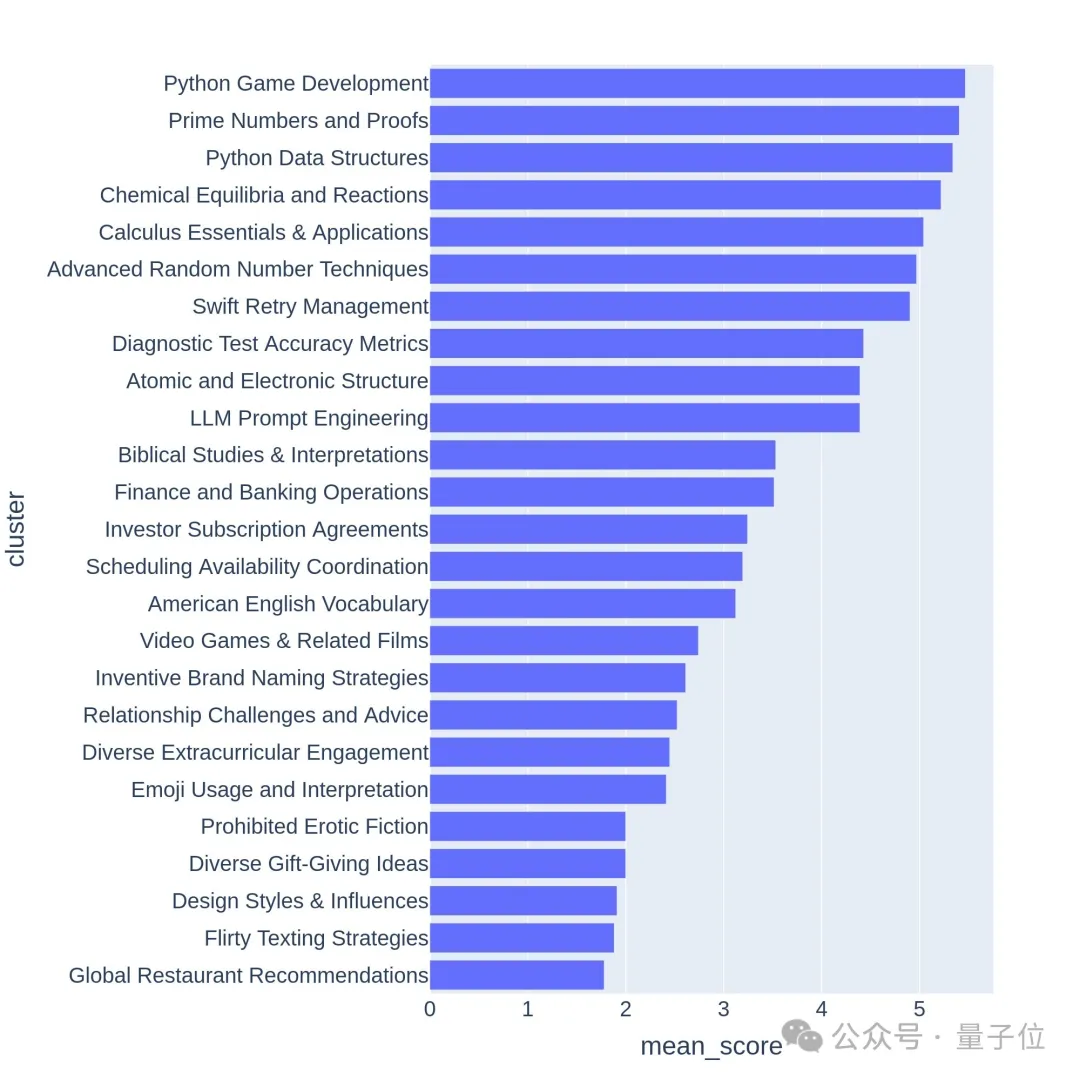
Soalan berkualiti tinggi biasanya berkaitan dengan topik atau tugasan yang mencabar, seperti pembangunan permainan atau bukti matematik.
Adakah penanda aras baharu itu tepat?
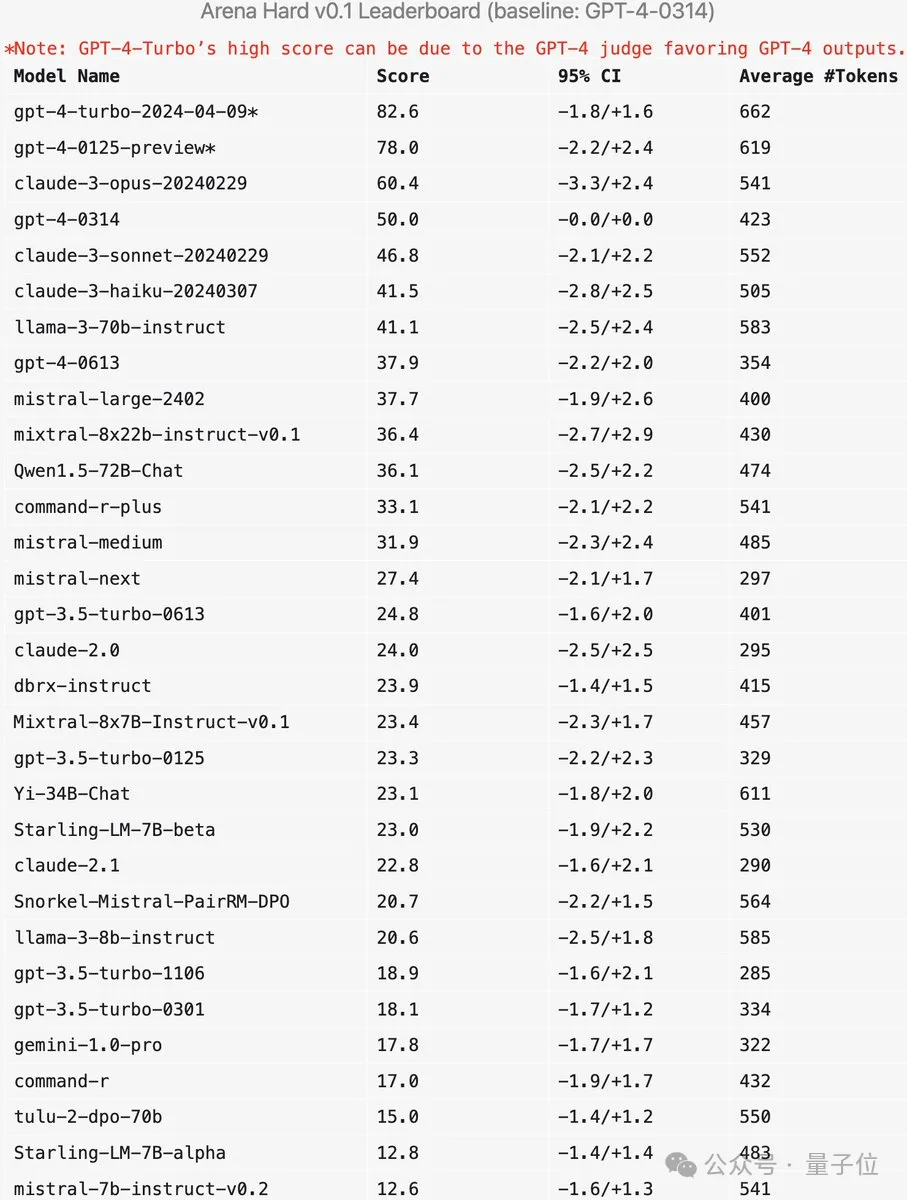
Arena-Hard pada masa ini mempunyai kelemahan: menggunakan GPT-4 sebagai pengadil lebih suka outputnya sendiri. Pegawai juga memberikan petua yang sepadan.
Dapat dilihat bahawa markah dua versi terkini GPT-4 jauh lebih tinggi daripada Claude 3 Opus, tetapi perbezaan dalam markah pengundian manusia tidaklah begitu ketara.
Malah, mengenai perkara ini, penyelidikan baru-baru ini telah menunjukkan bahawa model canggih akan memilih keluaran mereka sendiri.

Pasukan penyelidik juga mendapati bahawa AI secara semulajadi boleh menentukan sama ada sekeping teks ditulis dengan sendirinya Selepas penalaan halus, keupayaan pengecaman diri boleh dipertingkatkan dan keupayaan pengecaman diri adalah berkaitan secara linear dengan diri. pilihan.
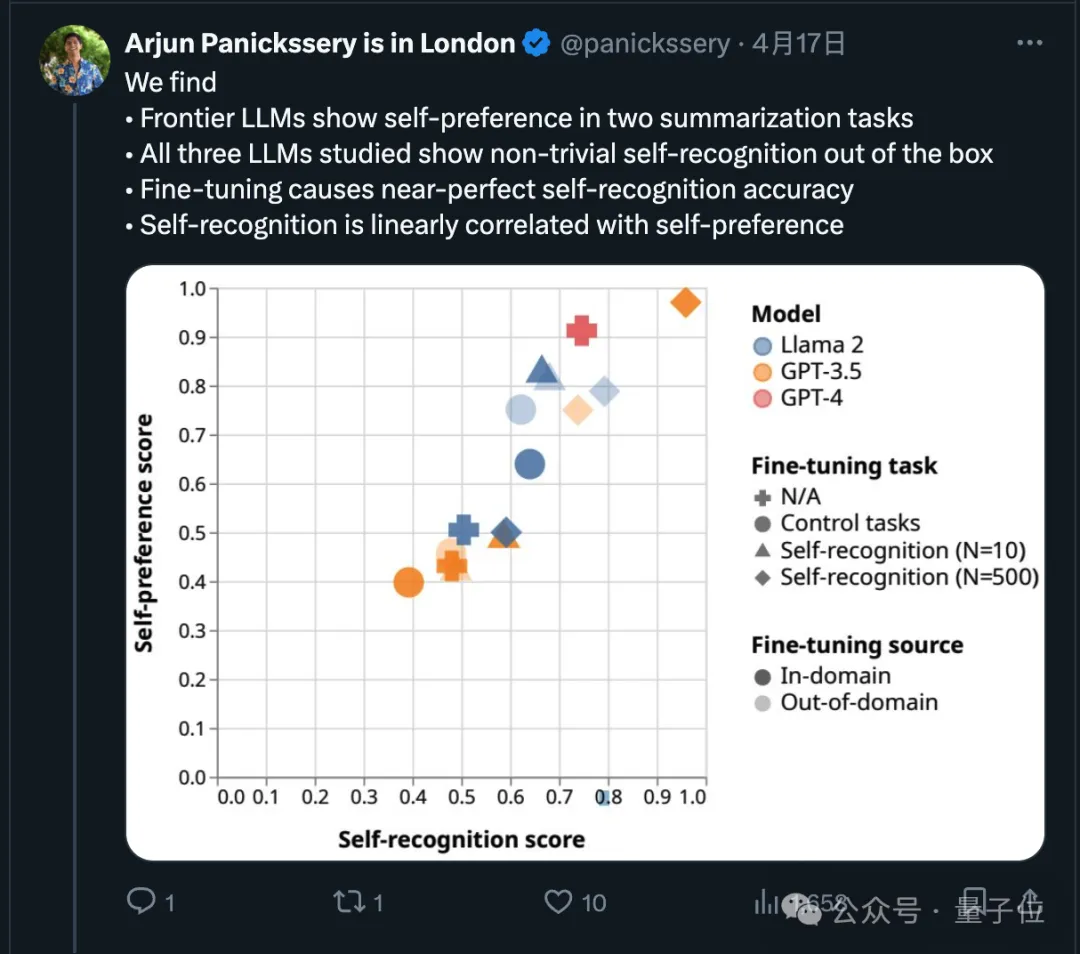
Jadi bagaimanakah penggunaan Claude 3 untuk pemarkahan akan mengubah keputusan? LMSYS juga telah melakukan eksperimen yang berkaitan.
Pertama sekali, markah siri Claude memang akan meningkat.
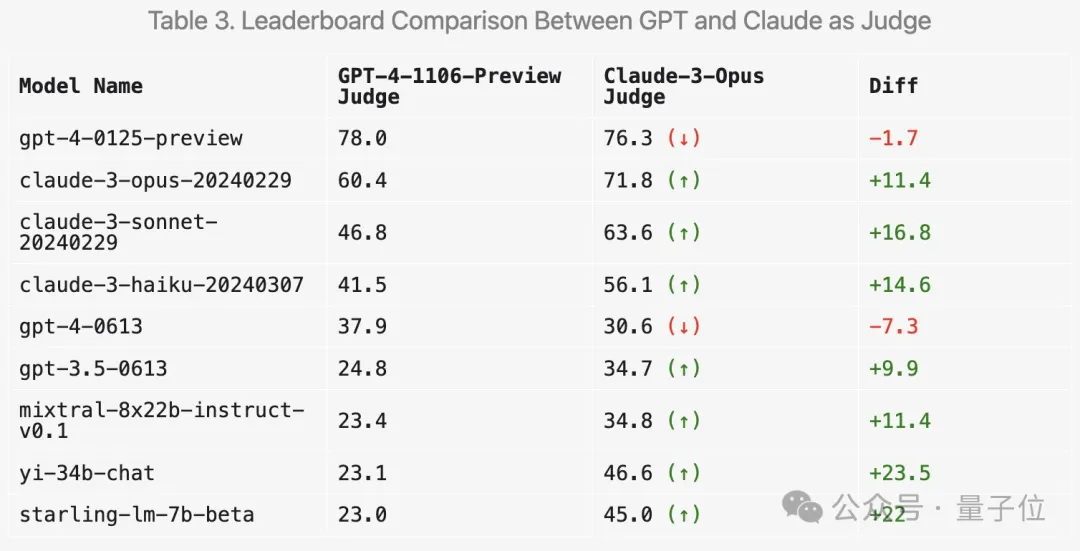
Tetapi yang menghairankan, ia lebih suka beberapa model terbuka seperti Mixtral dan Zero One Thousand Yi, malah mendapat markah yang lebih tinggi dengan ketara pada GPT-3.5.
Secara keseluruhannya, diskriminasi dan konsistensi dengan keputusan manusia yang dijaringkan menggunakan Claude 3 tidak sebaik GPT-4.
Begitu ramai netizen mencadangkan menggunakan berbilang model besar untuk pemarkahan menyeluruh.
Selain itu, pasukan itu juga menjalankan lebih banyak eksperimen ablasi untuk mengesahkan keberkesanan ujian penanda aras baharu.
Sebagai contoh, jika anda menambah "jadikan jawapan sedetail mungkin" dalam perkataan gesaan, purata panjang output akan lebih tinggi dan skor sememangnya akan bertambah baik.
Tetapi menukar perkataan gesaan kepada "suka bersembang", purata panjang output juga meningkat, tetapi peningkatan skor tidak jelas.
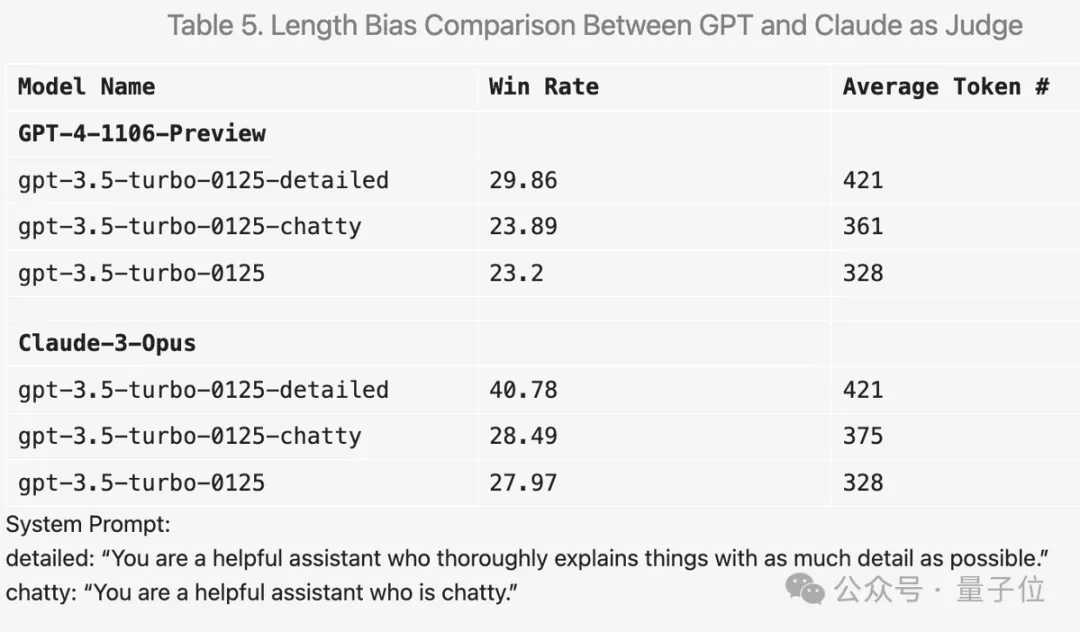
Selain itu, terdapat banyak penemuan menarik semasa percubaan.
Sebagai contoh, GPT-4 sangat ketat dalam pemarkahan Jika terdapat kesilapan dalam jawapan, mata akan ditolak dengan teruk; manakala Claude 3 akan berlembut walaupun ia mengiktiraf kesilapan kecil.
Untuk soalan kod, Claude 3 cenderung untuk memberikan jawapan dengan struktur yang ringkas, tidak bergantung pada perpustakaan kod luaran, dan boleh membantu manusia mempelajari pengaturcaraan manakala GPT-4-Turbo memilih jawapan yang paling praktikal, tanpa mengira pendidikan mereka; nilai.
Selain itu, walaupun suhu ditetapkan kepada 0, GPT-4-Turbo mungkin menghasilkan pertimbangan yang sedikit berbeza.
Ia juga boleh dilihat daripada 64 kelompok pertama visualisasi hierarki bahawa kualiti dan kepelbagaian soalan yang ditanya oleh pengguna arena model besar sememangnya tinggi.
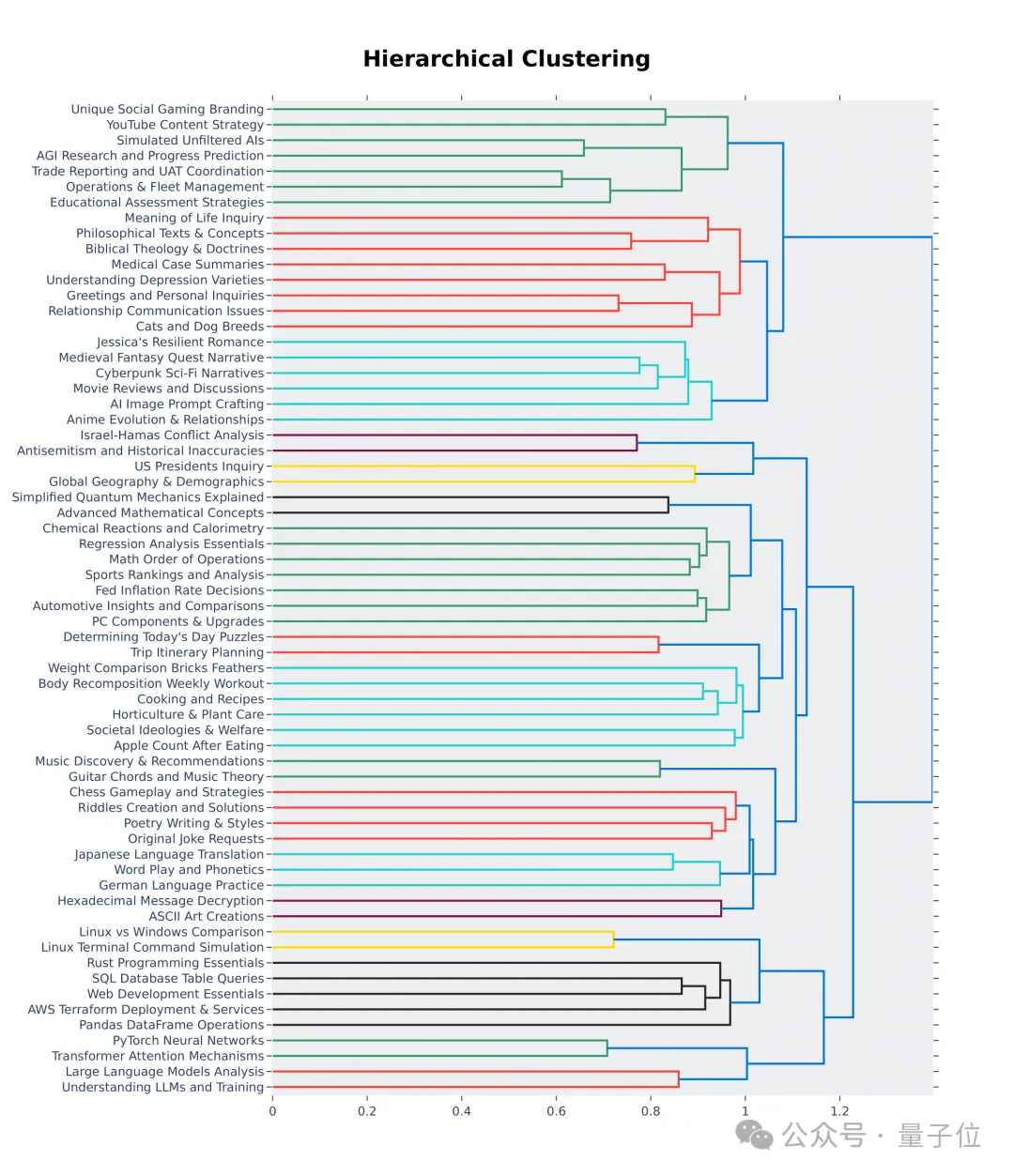
Mungkin ada sumbangan anda dalam hal ini.
Arena-Hard GitHub: https://github.com/lm-sys/arena-hard
Arena-Hard HuggingFace: https://huggingface.co/spaces/lmsys/arena-hard-browser
Arena Model Besar : https://arena.lmsys.org
Pautan rujukan:
[1]https://x.com/lmsysorg/status/1782179997622649330
[2]https://lmsys.org/blog/2024-04 - 19-arena-keras/
Atas ialah kandungan terperinci Penanda aras ujian baharu dikeluarkan, sumber terbuka paling berkuasa Llama 3 memalukan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan yang digunakan untuk operasi nombor terapung dalam bahasa Go memperkenalkan cara memastikan ketepatannya ...
 Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Menjalankan projek H5 memerlukan langkah -langkah berikut: memasang alat yang diperlukan seperti pelayan web, node.js, alat pembangunan, dan lain -lain. Membina persekitaran pembangunan, membuat folder projek, memulakan projek, dan menulis kod. Mulakan pelayan pembangunan dan jalankan arahan menggunakan baris arahan. Pratonton projek dalam penyemak imbas anda dan masukkan URL Server Pembangunan. Menerbitkan projek, mengoptimumkan kod, menggunakan projek, dan menyediakan konfigurasi pelayan web.
 GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
Giteepages Statik Laman Web Penggunaan Gagal: 404 Penyelesaian Masalah dan Resolusi Ralat Semasa Menggunakan Gitee ...
 Bagaimana cara menentukan pangkalan data yang berkaitan dengan model dalam beego orm?
Apr 02, 2025 pm 03:54 PM
Bagaimana cara menentukan pangkalan data yang berkaitan dengan model dalam beego orm?
Apr 02, 2025 pm 03:54 PM
Di bawah rangka kerja beegoorm, bagaimana untuk menentukan pangkalan data yang berkaitan dengan model? Banyak projek beego memerlukan pelbagai pangkalan data untuk dikendalikan secara serentak. Semasa menggunakan beego ...
 Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau projek sumber terbuka yang terkenal? Semasa pengaturcaraan di GO, pemaju sering menghadapi beberapa keperluan biasa, ...
 Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Halaman H5 perlu dikekalkan secara berterusan, kerana faktor -faktor seperti kelemahan kod, keserasian pelayar, pengoptimuman prestasi, kemas kini keselamatan dan peningkatan pengalaman pengguna. Kaedah penyelenggaraan yang berkesan termasuk mewujudkan sistem ujian lengkap, menggunakan alat kawalan versi, kerap memantau prestasi halaman, mengumpul maklum balas pengguna dan merumuskan pelan penyelenggaraan.
 Bagaimana menyelesaikan masalah penukaran jenis user_id semasa menggunakan aliran redis untuk melaksanakan beratur mesej dalam bahasa Go?
Apr 02, 2025 pm 04:54 PM
Bagaimana menyelesaikan masalah penukaran jenis user_id semasa menggunakan aliran redis untuk melaksanakan beratur mesej dalam bahasa Go?
Apr 02, 2025 pm 04:54 PM
Masalah menggunakan redisstream untuk melaksanakan beratur mesej dalam bahasa Go menggunakan bahasa Go dan redis ...
 Apabila menggunakan sql.open, mengapa tidak melaporkan ralat apabila DSN berlalu kosong?
Apr 02, 2025 pm 12:54 PM
Apabila menggunakan sql.open, mengapa tidak melaporkan ralat apabila DSN berlalu kosong?
Apr 02, 2025 pm 12:54 PM
Apabila menggunakan SQL.Open, mengapa DSN tidak melaporkan ralat? Dalam bahasa Go, sql.open ...
